DeepSeek发布DSpark:推理提速85%,高并发成本能否打下来?
 打个比方,你急着看一封万字长文,结果对方是一个字一个字给你蹦出来的,每蹦一个字还得停下来确认一下上下文。这就是传统大模型推理的"自回归"模式------每生成一个token,都要做一次完整的计算。输出越长,等待越久,GPU空转得像在摸鱼。为了提速,业界搞出了"推测解码":让一个轻量级小模型先快速打个草稿,再由大模型一次性批量"验货"。
打个比方,你急着看一封万字长文,结果对方是一个字一个字给你蹦出来的,每蹦一个字还得停下来确认一下上下文。这就是传统大模型推理的"自回归"模式------每生成一个token,都要做一次完整的计算。输出越长,等待越久,GPU空转得像在摸鱼。为了提速,业界搞出了"推测解码":让一个轻量级小模型先快速打个草稿,再由大模型一次性批量"验货"。
但这带来了新的死局。现有的主流方案分两派:自回归派 草稿质量高但生成慢,逐token串行,候选序列一长就卡;并行派 虽然一次能吐出整段草稿,但token之间缺少依赖逻辑,很容易搞出"of problem"这种上下文打架的组合,越往后错得越离谱。验证阶段,大模型对着大量垃圾候选token验算,算力浪费触目惊心。
DSpark的破局点,是走了一条"半自回归"的中间路线。
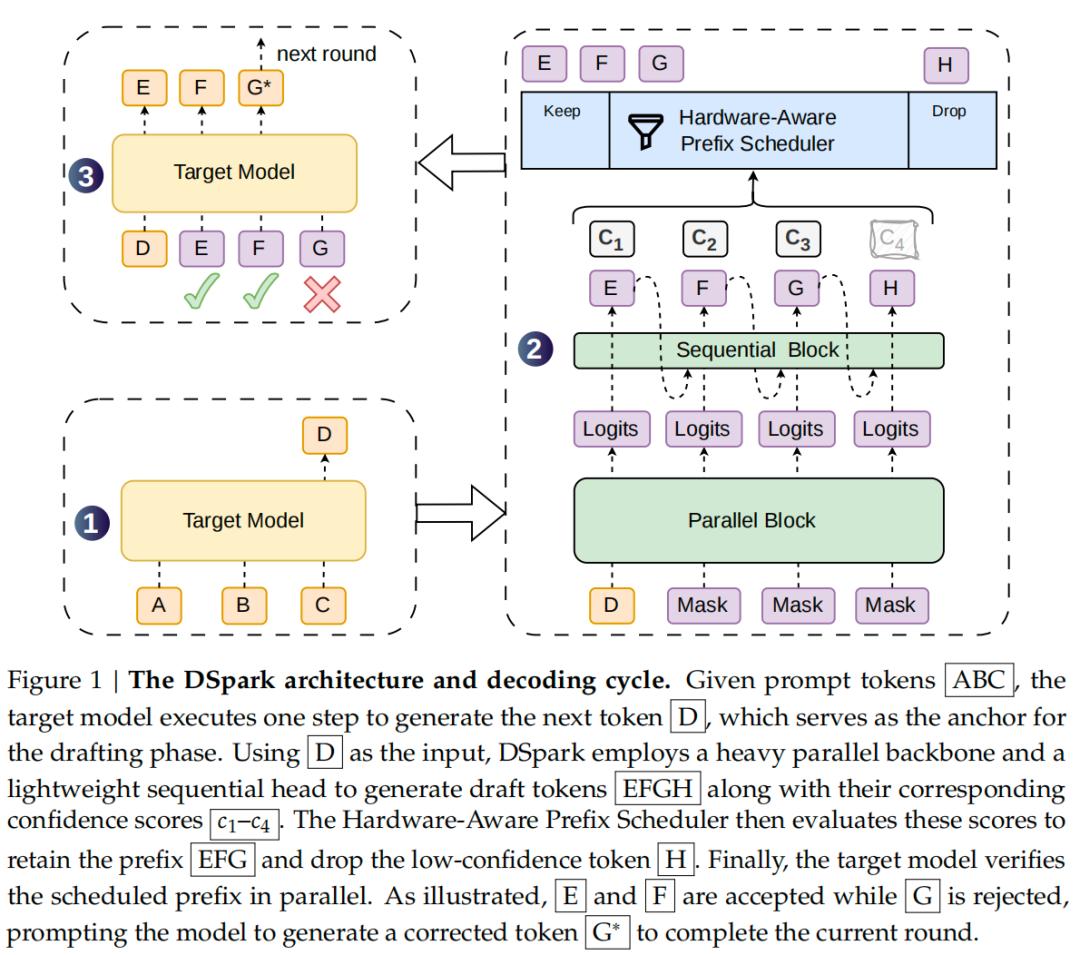
它把两派的优点拆开重组。核心设计是:保留并行派的重型骨干网络 ,一次性算出所有候选位置的隐藏状态,保证生成速度不拉胯;然后,在输出端引入一个极轻量的顺序模块,默认用马尔可夫头,只建模"前一个token到当前token"的简单转移偏置。
这相当于在大批量印刷的流水线末端,加了一个快速校对岗。大部分计算依然并行完成,只用了极小的顺序开销,就让后续token能参考前一个已采样的token,修正块内连贯性。实验数据很直观:仅两层Transformer深度的DSpark,接受长度就超过了五层DFlash。这意味着,引入少量自回归依赖在参数效率上,远比单纯堆叠并行层更划算。
草稿质量上去了,但验证环节的浪费依然存在。过去很多方案是固定验证长度,或者用静态阈值决定验几个token。这在真实服务系统里是灾难性的------低负载时多验几个无所谓,高并发时,低置信度的尾部token会挤占目标模型的批量算力,拖慢所有请求。
DSpark的解法是"看人下菜碟"。它为每个候选位置预测一个置信度分数,估算该token在前缀全部被接受条件下的存活概率。调度器再结合当前引擎的吞吐曲线,动态决定这一轮验证多长的前缀。
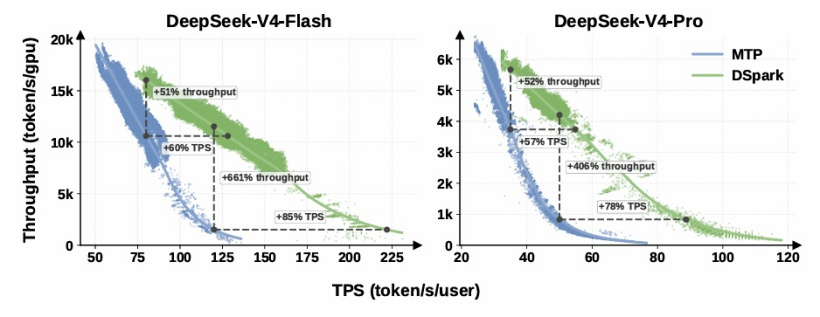
简化理解就是:系统空闲时激进,多验几个;高负载时保守,只把验证预算花在全局存活概率最高的token上 。这种硬件感知的调度,把验证长度选择变成了全局吞吐量最大化问题,而不是一刀切的死规则。在DeepSeek-V4的线上实测中,当服务等级协议收紧到120token/s时,单token基线已经接近运行边界,而DSpark在维持可用并发的前提下,实现了标称661%的吞吐量优势。这验证了一个关键洞察:真正的加速,不是让每一步都跑得更快,而是精准地把算力喂给最值得计算的地方。
 ## 二、落地检验:85%提速背后,真实表现与潜在局限
## 二、落地检验:85%提速背后,真实表现与潜在局限
DSpark的论文数据确实亮眼,但任何技术从实验室到生产环境,中间都隔着一条"工程鸿沟"。DeepSeek显然清楚这一点,所以在发布时同步公开了跨模型基准测试和线上部署数据------这种透明度在开源社区并不多见。
实测迁移表现:从V4线上系统到Qwen等第三方模型的通用性验证
DSpark并非为DeepSeek定制的"特调版"方案。团队在离线测试中选取了Qwen3系列(4B/8B/14B)和Gemma4-12B作为目标模型,覆盖数学推理、代码生成和日常对话三类任务。
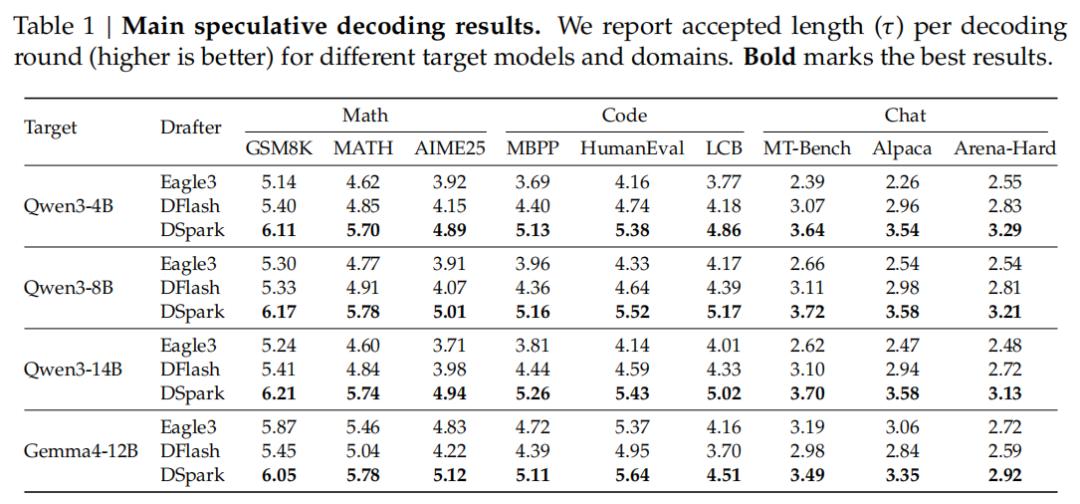
核心指标是平均每轮接受长度 ------草稿模型生成的token中,能被目标模型连续接受的越多,加速效果就越实在。在Qwen3-4B上,DSpark相比自回归草稿模型Eagle3提升约30.9% ,相比并行草稿模型DFlash提升约16.3%。在8B和14B规模上,提升幅度稳定在**26.7%至30.0%**之间。
这验证了一个关键判断:半自回归架构的泛化性不依赖特定模型。DSpark继承了并行架构的首位容量优势,同时通过顺序依赖缓解后续位置衰减------这种设计在Qwen、Gemma上同样奏效,意味着任何采用类似架构的开源模型都可接入这套方案。
线上部署数据更直接。在DeepSeek-V4-Flash引擎上,当SLA保证单用户生成速度不低于80 token/s 时,DSpark的聚合吞吐量相比基线提升51% ;当SLA收紧至120 token/s时,基线已接近运行边界,DSpark却实现了661%的吞吐量优势。在V4-Pro引擎上,35 token/s的SLA下提升52% ,50 token/s下提升406%。
越是高负载、高要求的场景,DSpark的边际收益越大------这不是简单的线性加速,而是在系统濒临崩溃时撑住了天花板。
复杂场景下的挑战:并行主干算力浪费能否回收,以及异步调度的适配成本
 但DSpark并非零成本加速。论文明确指出了一个结构性局限:即使后缀token最终被调度器截断,并行主干仍需为所有请求生成完整的初始候选块。
但DSpark并非零成本加速。论文明确指出了一个结构性局限:即使后缀token最终被调度器截断,并行主干仍需为所有请求生成完整的初始候选块。
这意味着什么?对于数学推理和代码生成这类高确定性任务,草稿接受率高,算力投入物有所值。但在开放域闲聊等低确定性场景,大量并发生成的候选token最终被丢弃,计算开销无法回收。这恰好暴露了半自回归架构的任务敏感性------不是所有场景都能享受到85%的加速。
异步调度也带来工程复杂度。DSpark的调度器需要兼容CUDA图重放和零开销调度,必须将调度逻辑改造为异步模式:以当前轮置信度排序候选token,但截断长度依据两轮前的历史预测来确定。这种"滞后决策"虽然隐藏了调度延迟,却也引入了预测偏差的累积风险------调度器在"看后视镜开车"。
另一个适配门槛在于动态变长验证前缀。标准解码内核在面对长度不一致的验证序列时,会因填充和负载不均而利用率下降。团队通过将物理执行与逻辑序列跟踪解耦来解决,但需要修改索引注意力与压缩内核------这对想要复现的中小团队构成实实在在的工程门槛。
核心矛盾在于:DSpark在高负载时通过动态缩减验证长度来保护吞吐量,低负载时则激进分配验证预算。这套机制的有效性高度依赖置信度校准的精度------校准一旦偏移,调度器要么过度保守浪费算力,要么过度激进导致大量无效验证。这不是理论问题,而是线上运行中随时可能出现的漂移风险。
三、战略卡位:开源DSpark,DeepSeek在算力效率时代的新棋局
DSpark的发布时间点耐人寻味------恰在DeepSeek完成500亿融资 之后。首轮融资后的第一张牌,不是新模型,而是推理加速框架。这个选择本身,已经传递出清晰的战略信号:DeepSeek的竞争重心,正在从模型能力转向算力效率。
从模型能力到推理优化:为何说高并发下的成本控制是下一个竞争制高点?
大模型竞赛已进入下半场。当各家模型的能力差距逐渐缩小,一个残酷的现实浮出水面:"跑得快"比"跑得聪明"更致命。
 传统自回归生成模式下,每生成一个token都需要一次完整前向传播,GPU利用率极低。这意味着,即便模型参数完全相同,推理效率的差异会直接转化为数十个百分点的成本鸿沟。在高并发场景下,这种差距会被指数级放大------固定长度的验证策略迫使目标模型将宝贵的批量处理能力,消耗在高拒绝风险的尾部token上,导致整体吞吐量崩塌。
传统自回归生成模式下,每生成一个token都需要一次完整前向传播,GPU利用率极低。这意味着,即便模型参数完全相同,推理效率的差异会直接转化为数十个百分点的成本鸿沟。在高并发场景下,这种差距会被指数级放大------固定长度的验证策略迫使目标模型将宝贵的批量处理能力,消耗在高拒绝风险的尾部token上,导致整体吞吐量崩塌。
DSpark的置信度调度机制,本质上是在做算力资源的精细化运营。系统空闲时更激进地分配验证预算,高负载时则只把算力用在全局存活概率最高的token上。这种负载自适应的能力,让DeepSeek在严格交互时延约束下,避免了吞吐率的大幅滑坡,推高了整套服务系统的帕累托最优边界。
当模型能力趋同,推理效率就是定价权。
开源生态的挤压效应:DeepSpec全栈工具链会否重塑中小模型的生存逻辑?
DSpark并非孤立发布。伴随它一同开源的,还有DeepSpec全栈工具链------包含数据准备、草稿模型训练、评估脚本的完整代码库,支持Qwen3、Gemma等第三方模型。
 这一举动的影响远超技术本身。此前,推测解码的工程实践散落于各研究团队内部,复现成本极高。DeepSpec将其整合为标准化工具链后,任何团队都可以为自己的模型训练定制草稿模型,跳过基础设施的重复搭建。 开源降低了门槛,但也意味着推理加速不再是少数团队的独门秘籍。
这一举动的影响远超技术本身。此前,推测解码的工程实践散落于各研究团队内部,复现成本极高。DeepSpec将其整合为标准化工具链后,任何团队都可以为自己的模型训练定制草稿模型,跳过基础设施的重复搭建。 开源降低了门槛,但也意味着推理加速不再是少数团队的独门秘籍。
但硬币的另一面是,开源生态的成熟会加速行业洗牌。当推理加速成为"标配"而非"溢价能力",中小模型的生存空间将被进一步压缩------它们不仅要面对模型能力的差距,还要承受推理效率带来的成本劣势。DeepSeek通过开源,既巩固了技术话语权,也在客观上抬高了整个行业的效率基准。
值得注意的是,DSpark本身也存在局限:即使后缀token最终被调度器截断,并行主干仍需为所有请求生成完整的初始候选块。对于接受率较低的复杂查询,这部分草稿计算开销无法回收。这意味着,推理优化的收益并非均匀分布------简单对话场景的加速效果,远优于复杂推理任务。
DeepSeek的这步棋,本质上是将"高并发下的成本控制"从技术优势转化为生态壁垒。开源的既是工具,也是一张新的竞争入场券。