内容参考于:图灵AI大模型全栈
LightRag它的使用很简单
它的索引会在本地保存一些文件,下方是对文件的说明
faiss_index_chunks.index:
文本块向量索引文件,FAISS 格式的二进制文件。存储文档拆分后每一小段文本对应的向量数据,用于快速相似检索。纯向量检索(naive 模式)时,会优先在这个文件里匹配和问题最相似的文本段落,文件本身无法用记事本直接打开。
faiss_index_chunks.index.meta.json:
文本块向量索引的配置说明文件。记录对应索引的向量维度、构建参数等元信息,程序加载向量索引时会先读取此文件做校验,不建议手动修改内容。
faiss_index_entities.index:
实体向量索引文件,FAISS 格式的二进制文件。存储知识图谱中所有实体(人物、地点、法宝等)对应的向量数据。图检索模式下,会先通过这个文件定位和问题最相关的实体节点,再顺着关系链路查找答案。
faiss_index_entities.index.meta.json:
实体向量索引的配置说明文件。记录实体索引的向量维度、构建参数等元信息,用于程序加载索引时的校验和配置匹配。
faiss_index_relationships.index:
关系向量索引文件,FAISS 格式的二进制文件。存储知识图谱中所有实体关系对应的向量数据,配合实体索引一起使用,用于快速匹配和问题相关的实体关联链路。
faiss_index_relationships.index.meta.json:
关系向量索引的配置说明文件。记录关系索引的向量维度、构建参数等元信息,保障程序能正确加载对应的向量索引。
kv_store_doc_status.json:
文档处理状态登记表。记录所有插入过的文档信息、处理进度(切块、抽实体、向量化等步骤状态)以及文档唯一标识,用于实现增量插入去重 ------ 文档内容不变时重复运行插入会自动跳过,避免重复调用大模型。
kv_store_entity_chunks.json:
实体 - 文本块对应表。记录每个实体分别来自哪些文本段落,也能反向查询某段文本中包含哪些实体。图检索时,找到相关实体后会通过这个文件定位到对应的原文片段,用于后续生成答案。
kv_store_full_docs.json:
完整原文存储库。存放你插入的所有原始文档全文,每个文档对应唯一的文档 ID,相当于整套系统的原始素材库。
kv_store_full_entities.json:
实体详情档案库。存放知识图谱里所有实体节点的完整信息,包括实体名称、实体类型、详细描述、来源出处等,和实体向量索引一一对应 ------ 索引存向量,这里存实体的真实文本内容。
kv_store_full_relations.json:
关系详情档案库。存放知识图谱里所有关系连线的完整信息,包括源实体、目标实体、关系描述、关系强度、关键词等,和关系向量索引一一对应。
kv_store_llm_response_cache.json:
大模型调用缓存文件。保存所有大模型的调用返回结果(比如实体抽取、关系抽取的输出)。重复处理相同内容时直接读取缓存,无需重复调用大模型,节省 API 费用和运行时间,执行清缓存操作会清空此文件内容。
kv_store_relation_chunks.json:
关系 - 文本块对应表。记录每条关系分别来自哪些文本段落,用于检索时追溯关系的原文出处,支撑答案溯源。
kv_store_text_chunks.json:
文本块原文存储库。存放文档拆分后所有小段文本的原文内容,每个文本块有唯一 ID,同时记录了它所属的文档、在原文中的位置。和文本块向量索引一一对应 ------ 索引存向量,这里存向量对应的真实文本内容。
运行下图红框的代码,就出现下图蓝框的文件,文件说明如上,它们就是LightRag保存的源文件、向量、json、关系等数据,下图红框的代码如果之前已经保存的数据不会进行添加
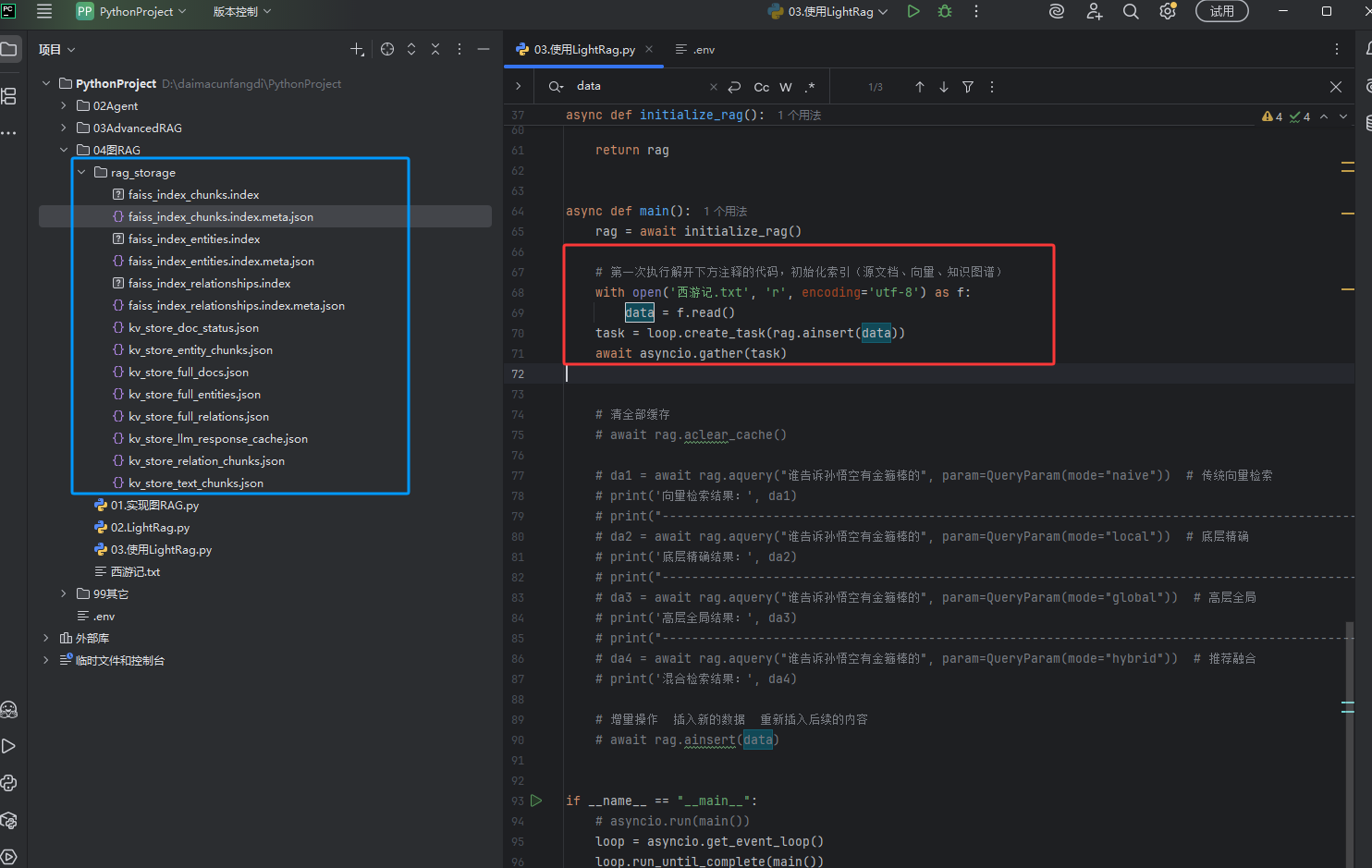
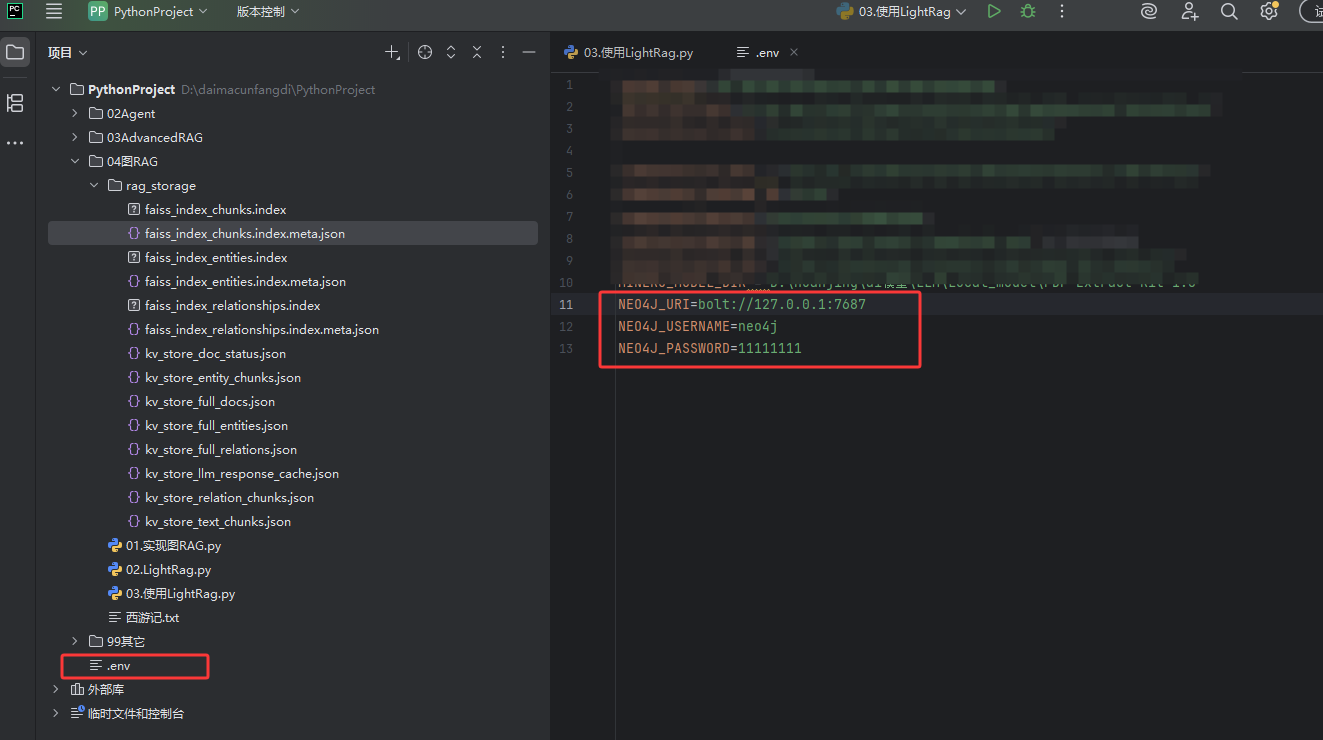
代码中用到了neo4j,需要配置环境变量,如下图红框的内容,neo4j的地址、用户名、密码信息
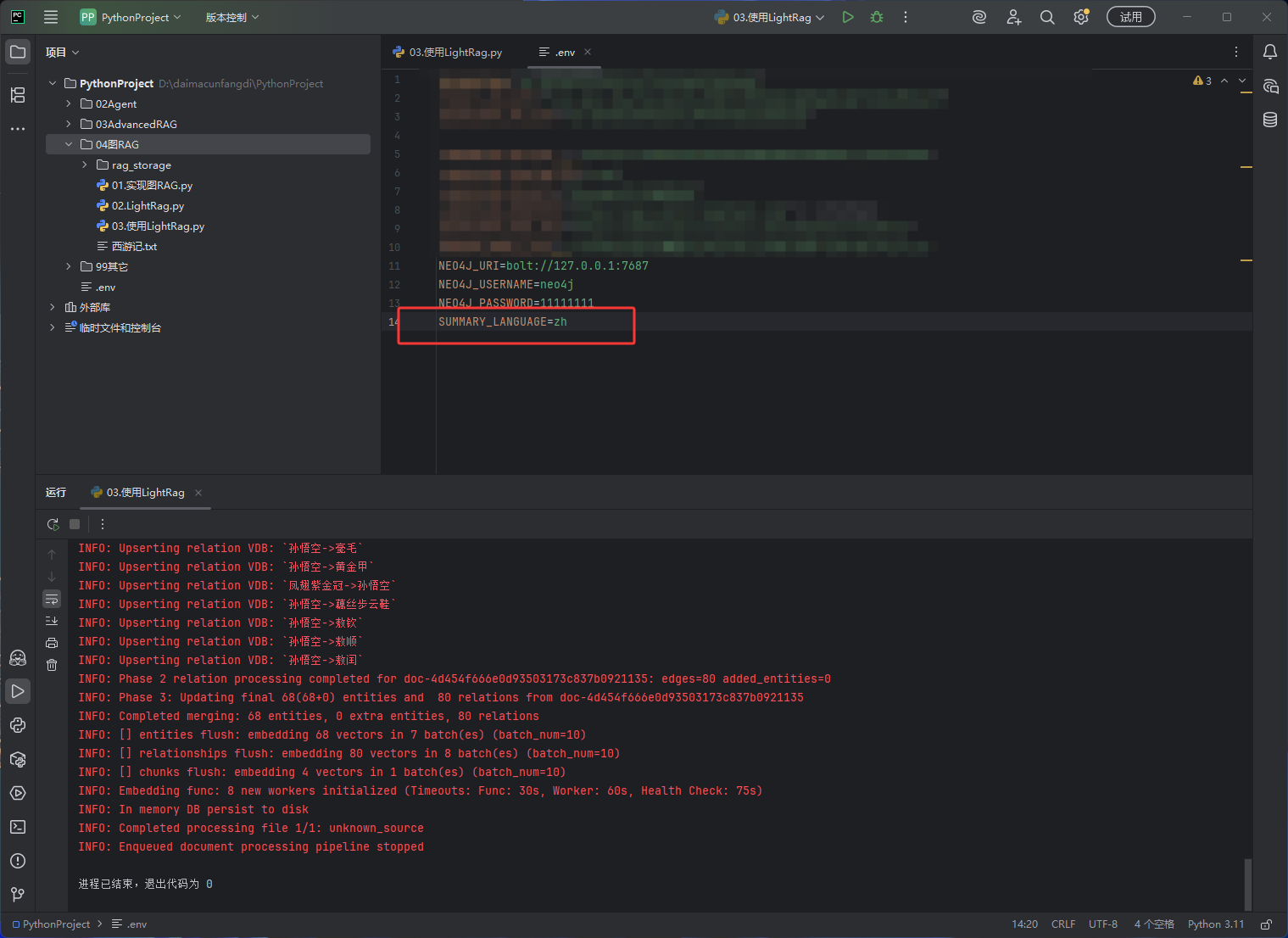
LightRag默认生成的内容是英文的,需要在配置文件中添加下图红框的内容SUMMARY_LANGUAGE=zh
或者写下图红框的内容让它生成中文内容
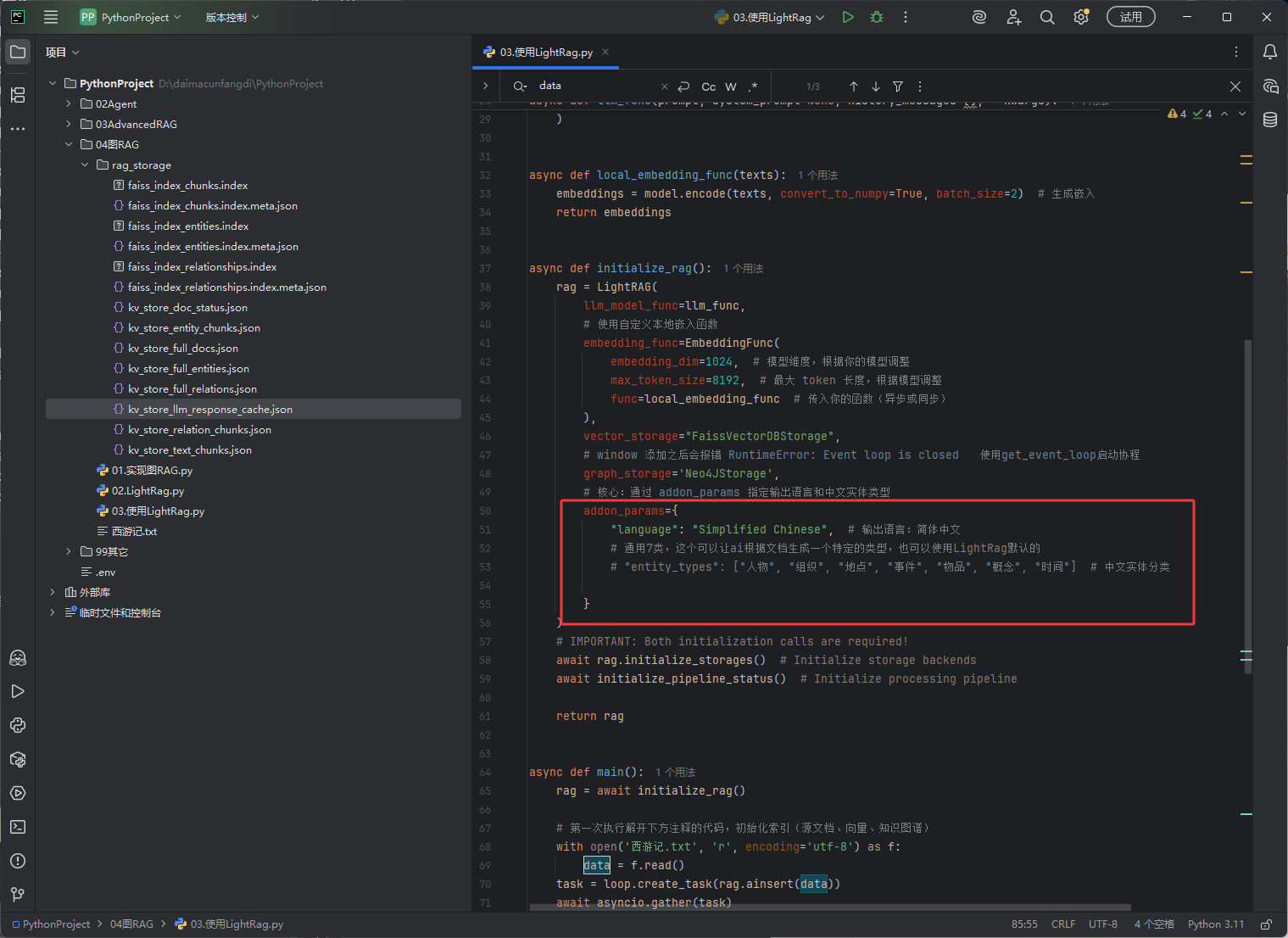
知识图谱,它的生成好不好取决于使用的模型
代码,下方的代码只是一个实例,实际场景不会写就去问ai,可以让ai基于下方的代码添加
python# 导入异步编程模块,用来写异步函数、管理事件循环,调用大模型/数据库时不卡住程序 import asyncio # 导入操作系统模块,用来读取环境变量、操作文件路径 import os # 导入 LightRAG 核心类和查询参数类 # LightRAG:是一个轻量级的图增强RAG框架,自动从文本里提取知识图谱,结合向量+图谱做问答 # QueryParam:查询参数对象,用来指定问答模式(向量检索/局部图谱/全局图谱/混合) from lightrag import LightRAG, QueryParam # 导入 LightRAG 封装好的 OpenAI 兼容大模型调用函数,带缓存功能 # 作用:只要是兼容 OpenAI 接口的大模型(比如通义千问),都可以用这个函数统一调用 from lightrag.llm.openai import openai_complete_if_cache, openai_embed # 导入 dotenv 的环境变量加载函数,读取 .env 文件里的配置 from dotenv import load_dotenv # 导入向量函数封装类,用来把自定义的向量模型包装成 LightRAG 能识别的格式 from lightrag.utils import EmbeddingFunc # 导入流水线状态初始化函数,LightRAG 要求必须初始化处理流水线 from lightrag.kg.shared_storage import initialize_pipeline_status # 导入 sentence-transformers 库的 SentenceTransformer,用来加载本地向量模型 from sentence_transformers import SentenceTransformer # 导入 LightRAG 的提示词模板,这里默认使用内置模板 from lightrag.prompt import PROMPTS # 执行加载 .env 文件,把里面的 API 密钥、接口地址等配置读到系统环境变量里 # 好处:敏感信息不写死在代码里,换环境直接改 .env 文件就行 load_dotenv() # ========== 全局配置变量 ========== # 本地向量模型的文件路径,这里用的是中文效果很好的 bge-large-zh-v1.5 模型 # 前面加 r 是原始字符串语法,避免路径里的反斜杠被当成转义符 model_name = r'D:\huanjing\ai模型\BAAI\bge-large-zh-v1___5' # LightRAG 的工作目录,用来存缓存、日志、临时文件 WORKING_DIR = 'light_test' # 加载本地向量模型到内存,后面生成向量都用这个模型 # 为什么用本地模型:1. 中文语义匹配效果更好;2. 不用调API,不花钱;3. 速度更快 model = SentenceTransformer(model_name) # 自定义大模型调用函数(异步函数,前面加 async 表示是异步的) # 作用:把通义千问的调用封装成 LightRAG 要求的格式,LightRAG 提取图谱、生成回答都会调用这个函数 # 固定写法,只需要改 model 参数和接口配置就行 async def llm_func(prompt, system_prompt=None, history_messages=[], **kwargs): """ 功能:调用大模型生成回复,带缓存功能,相同的问题会直接读缓存不用重复调用 入参说明: prompt : str 当前给大模型的用户提示词(比如提取图谱的指令、问答的问题) system_prompt : str = None 系统提示词,给大模型设定角色规则,可选 history_messages : list = [] 历史对话消息列表,多轮对话用,默认空 **kwargs : 其他额外参数,会透传给大模型接口 返回值:大模型返回的文本结果 预期数据类型:str """ # 调用 LightRAG 封装好的 OpenAI 兼容调用函数 # 为什么用这个:通义千问兼容 OpenAI 的接口格式,直接用这个封装就能接入,不用自己写请求代码 return await openai_complete_if_cache( model="qwen-plus", # 指定用的大模型名称,这里是通义千问 plus 版 prompt=prompt, # 传入用户提示词 system_prompt=system_prompt, # 传入系统提示词 history_messages=history_messages, # 传入历史消息 base_url=os.getenv("DASHSCOPE_BASE_URL"), # 从环境变量读接口地址 api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量读 API 密钥 **kwargs # 透传其他所有额外参数 ) # 本地向量生成函数(异步) # 作用:把文本转换成向量(embedding),供向量检索使用,这里用我们本地加载的 bge 模型 async def local_embedding_func(texts): """ 功能:批量把文本转换成向量数组 入参说明: texts : List[str] 待转换的文本列表,一次可以传多条 返回值:numpy 数组格式的向量,每一行对应一条文本的向量 预期数据类型:numpy.ndarray """ # 调用本地模型生成向量 # convert_to_numpy=True:返回 numpy 数组格式,向量库能直接用 # batch_size=2:每批处理2条文本,避免内存占满,电脑配置高可以调大 embeddings = model.encode(texts, convert_to_numpy=True, batch_size=2) # 返回生成好的向量 return embeddings # 初始化 LightRAG 实例的异步函数 async def initialize_rag(): """ 功能:创建并初始化 LightRAG 对象,配置好大模型、向量模型、存储方式、中文参数 入参:无 返回值:初始化完成的 LightRAG 实例 预期数据类型:LightRAG """ # 创建 LightRAG 实例,传入所有核心配置 rag = LightRAG( # 指定大模型调用函数,LightRAG 提取图谱、生成回答都会调用这个函数 llm_model_func=llm_func, # 配置向量模型:用 EmbeddingFunc 包装一下,告诉 LightRAG 向量的维度、最大长度、调用函数 embedding_func=EmbeddingFunc( embedding_dim=1024, # 向量维度,bge-large-zh-v1.5 输出的向量就是1024维,必须和模型对应 max_token_size=8192, # 单次最多处理的token数,超过会自动截断,根据模型能力设置 func=local_embedding_func # 传入我们自定义的本地向量生成函数 ), # ========== 向量存储方式配置 ========== # 作用:存储文本块、实体、关系的向量数据,负责语义相似度检索 # 可选值及说明: # NanoVectorDBStorage :默认值,纯Python实现零依赖,本地文件持久化,适合小数据量快速调试 # FaissVectorDBStorage :Facebook开源高性能向量库,检索快、省内存,单机性能优秀,无需额外服务(当前使用) # PGVectorStorage :PostgreSQL + pgvector插件,适合已有PG技术栈的生产环境,数据统一管理 # MilvusVectorDBStorage :工业级分布式向量数据库,适合十万/百万级以上大数据量生产环境 # QdrantVectorDBStorage :易用性强,支持丰富元数据过滤,部署简单,适合中大数据量 # ChromaVectorDBStorage :轻量向量库,LangChain生态兼容好,适合快速原型验证 # MongoVectorDBStorage :基于MongoDB向量能力,适合已有MongoDB技术栈的团队,不用额外引入组件 # 注意:切换非默认存储需要提前安装对应的依赖包,否则会报导入错误 vector_storage="FaissVectorDBStorage", # ========== 知识图谱存储方式配置 ========== # 作用:存储知识图谱的实体节点和关系边,负责局部/全局图谱推理、多跳关联查询 # 可选值及说明: # NetworkXStorage :默认值,纯Python内存图计算库,本地文件持久化,零依赖,适合小数据量调试 # Neo4JStorage :工业级主流原生图数据库,支持Cypher查询语言,功能完善生态成熟(当前使用) # PGGraphStorage :基于PostgreSQL的AGE图插件,可与pgvector共用数据库,适合统一PG技术栈 # MemgraphStorage :高性能内存图数据库,兼容Cypher语法,查询速度极快,适合高实时性场景 # 注意:注释里说明,开启window相关功能时,用asyncio.run启动会报「Event loop is closed」错误 # 所以后面主程序用 get_event_loop 的方式启动协程来规避这个问题 graph_storage='Neo4JStorage', # 核心:通过 addon_params 指定输出语言和中文实体类型 addon_params={ "language": "Simplified Chinese", # 输出语言:简体中文 # 通用7类,这个可以让ai根据文档生成一个特定的类型,也可以使用LightRag默认的 # "entity_types": ["人物", "组织", "地点", "事件", "物品", "概念", "时间"] # 中文实体分类 } ) # IMPORTANT: Both initialization calls are required! # 1. 初始化所有存储后端(向量库、图谱库),建立连接、创建必要的数据结构 await rag.initialize_storages() # 2. 初始化文本处理流水线的状态,保证图谱提取的全流程能正常运行 await initialize_pipeline_status() # 返回初始化好的 RAG 实例 return rag # 主函数:程序的核心业务逻辑都在这里 async def main(): # 先调用初始化函数,拿到 LightRAG 实例 rag = await initialize_rag() # 第一次执行解开下方注释的代码,初始化索引(源文档、向量、知识图谱) # 打开本地西游记文本文件,只读模式,utf-8编码防止中文乱码 with open('西游记.txt', 'r', encoding='utf-8') as f: data = f.read() # 创建异步任务:把文本插入到 RAG 系统里(自动切分、提取图谱、生成向量、存入存储) task = loop.create_task(rag.ainsert(data)) # 等待插入任务执行完成 await asyncio.gather(task) # 清全部缓存 # 作用:清空 LightRAG 的所有缓存(大模型调用缓存、中间结果缓存),改了提示词/配置后可以清一下重新跑 # await rag.aclear_cache() # da1 = await rag.aquery("谁告诉孙悟空有金箍棒的", param=QueryParam(mode="naive")) # 传统向量检索 # print('向量检索结果:', da1) # print("---------------------------------------------------------------------------------------------------------") # da2 = await rag.aquery("谁告诉孙悟空有金箍棒的", param=QueryParam(mode="local")) # 底层精确 # print('底层精确结果:', da2) # print("---------------------------------------------------------------------------------------------------------") # da3 = await rag.aquery("谁告诉孙悟空有金箍棒的", param=QueryParam(mode="global")) # 高层全局 # print('高层全局结果:', da3) # print("---------------------------------------------------------------------------------------------------------") # da4 = await rag.aquery("谁告诉孙悟空有金箍棒的", param=QueryParam(mode="hybrid")) # 推荐融合 # print('混合检索结果:', da4) # 增量操作 插入新的数据 重新插入后续的内容 # 作用:后续有新的文档,可以继续调用 ainsert 追加进去,不用重建整个知识库 # await rag.ainsert(data) if __name__ == "__main__": # asyncio.run(main()) # 为什么不用 asyncio.run:Windows 环境下,LightRAG 内部多协程交互后容易出现 RuntimeError: Event loop is closed 报错 # 替代方案:手动获取事件循环,运行主函数,兼容性更好,能规避上述报错 loop = asyncio.get_event_loop() loop.run_until_complete(main())
