目录
前言: 交换排序的本质是通过"比较相邻元素、逆序则交换"逐步消除逆序对。冒泡排序作为最朴素的交换排序,以稳定的相邻交换保证稳定性;快速排序则凭借分治策略与高效的划分操作,成为实际应用中最快的通用排序算法。本文将从冒泡排序的迭代优化讲起,直至快速排序的递归分治与复杂度陷阱,结合代码与状态日志逐帧剖析。
一、冒泡排序
1.1 算法思想
冒泡排序重复地遍历待排序序列,每次比较相邻的两个元素,如果它们的顺序错误(前大于后)就交换。每一趟遍历完成后,当前未排序部分中的最大元素会像气泡一样"浮"到末尾。经过 n-1 趟遍历后,整个序列有序。

1.2 代码实现
c
void BubbleSort(DataType a[], int n)
{
int i, j;
for (i = 0; i < n - 1; i++)
{
int flag = 0; // 优化标志位:记录本趟是否发生过交换
for (j = 0; j < n - 1 - i; j++)
{
if (a[j] > a[j + 1])
{
DataType temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
flag = 1;
}
}
if (flag == 0) {
break; // 整趟无交换,已经有序
}
}
}代码解析:
- 外层循环
i控制趟数,每完成一趟,末尾就多一个排好序的元素,因此内层循环的终点为n - 1 - i。 flag标志位是冒泡排序的重要优化:如果某一趟完整遍历后没有发生任何交换,说明数组已经完全有序,可以直接结束排序。这将最好情况的时间复杂度从 O ( n 2 ) O(n^2) O(n2) 降至 O ( n ) O(n) O(n)。
1.3 运行推演
初始数据: 4 6 3 2 8 0 1 10 5 4
状态日志(每一趟结束后的数组):
4 3 2 6 0 1 8 5 4 10
3 2 4 0 1 6 5 4 8 10
2 3 0 1 4 5 4 6 8 10
2 0 1 3 4 4 5 6 8 10
0 1 2 3 4 4 5 6 8 10 步骤解析: 第一趟排序中,从索引0开始逐对比较。4>6? 不交换;6>3? 交换得 4,3,6,...;6>2? 交换......最大值 10 逐渐被推至末端。每趟过后,数组尾部的有序序列逐步加长。到第五趟时发现未发生任何交换,算法提前终止。可以看到冒泡排序的"有序尾部"是从后向前逐渐构建的。
1.4 复杂度分析
- 时间复杂度:
- 最好情况:序列已有序且启用
flag优化,一趟扫描即可退出, O ( n ) O(n) O(n)。 - 最坏情况:完全逆序,需 n − 1 n-1 n−1 趟完整遍历, O ( n 2 ) O(n^2) O(n2)。
- 平均: O ( n 2 ) O(n^2) O(n2)。
- 最好情况:序列已有序且启用
- 空间复杂度: O ( 1 ) O(1) O(1)。
- 稳定性: 稳定。相邻元素若相等,不发生交换,相对顺序不变。
二、快速排序
2.1 算法思想
快速排序采用分治策略:从序列中选取一个元素作为"基准"(pivot),通过一趟划分(Partition)将序列分成左右两部分,使得左边所有元素不大于基准,右边所有元素不小于基准,此时基准就落在了它的最终正确位置上。然后递归地对左右两部分进行同样的操作,直到每个子区间只剩一个元素或为空。
2.2 代码实现
c
int Partition(DataType a[], int low, int high)
{
DataType pivot = a[low]; //将第一个元素作为基准
while (low < high)
{
while (low < high && a[high] >= pivot) --high;
a[low] = a[high];
while (low < high && a[low] <= pivot) ++low;
a[high] = a[low];
}
a[low] = pivot;
return low;
}
void QuickSort(DataType a[], int low, int high)
{
if (low < high)
{
int pivotpos = Partition(a, low, high);
QuickSort(a, low, pivotpos - 1);
QuickSort(a, pivotpos + 1, high);
}
}
///////// 调用 ///////////
QuickSort(a, 0, n - 1);
////////////////////////代码解析:
Partition函数采用经典的"左右指针填坑法"。选取a[low]作为基准并保存,low位置即成为一个"坑"。右指针high向左移动,找到第一个小于 pivot 的元素填入左坑,此时high位置变成新坑;左指针low向右移动,找到第一个大于 pivot 的元素填入右坑。如此交替直至low == high,将 pivot 填入最后的坑位,返回划分点。- 递归主函数
QuickSort接收low和high,若区间长度大于 1 则划分并递归处理左右子区间。 - 注意
while循环中的>=和<=保证了相等的元素不会陷入无限交换,但也因此可能使相等元素分布不均,不过这并不影响正确性。
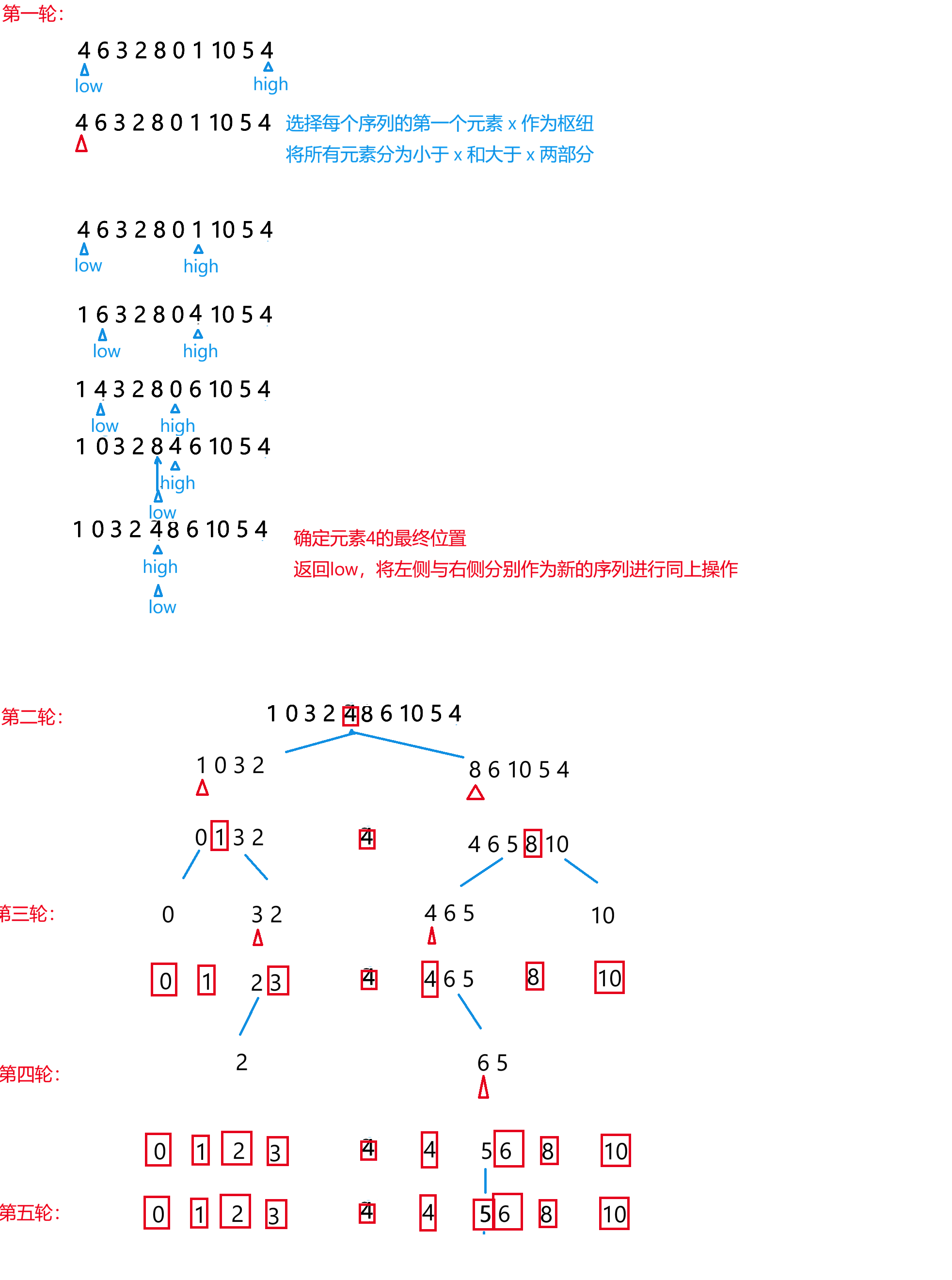
2.3 运行推演
初始数据: 4 6 3 2 8 0 1 10 5 4
状态日志(每次划分后的数组状态):
以 4 为基准划分后: 1 0 3 2 4 8 6 10 5 4
以 1 为基准划分后: 0 1 3 2 4 8 6 10 5 4
以 3 为基准划分后: 0 1 2 3 4 8 6 10 5 4
以 8 为基准划分后: 0 1 2 3 4 4 6 5 8 10
以 4 为基准划分后: 0 1 2 3 4 4 6 5 8 10
以 6 为基准划分后: 0 1 2 3 4 4 5 6 8 10
0 1 2 3 4 4 5 6 8 10 步骤解析: 第一轮以首个元素 4 为基准。右指针从尾端向左找到 4(索引9处)>=4 停止,但继续向左找到 1 不大于4,将 1 填到左坑(索引0);左指针向右找到 6>4,填入右坑......最后基准 4 归位到索引4,左侧全部 <=4,右侧全部 >=4。后面递归直至全数组有序。日志清晰展现了分治的过程和基准逐步归位的工作方式。
2.4 复杂度分析
- 时间复杂度:
- 最好/平均:每次划分将序列均分,递归深度为 log n \log n logn,每层操作总和 O ( n ) O(n) O(n),总时间 O ( n log n ) O(n \log n) O(nlogn)。
- 最坏:每次划分极不平衡(如原序列已有序且始终取首元素为基准),递归深度退化为 n n n,复杂度 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度: 主要由递归调用栈深度决定。最好/平均 O ( log n ) O(\log n) O(logn),最坏 O ( n ) O(n) O(n)。
- 稳定性: 不稳定。划分过程中的远距离填坑交换会改变相同元素的相对顺序。
下一篇我们将进入选择排序的世界,剖析简单选择排序与堆排序,敬请期待。