一、引出ELF文件
前面我们学习gcc/g++编译器的时候,对于我们的代码文件,如何一步一步预处理、汇编、编译、链接然后成为我们的可执行程序的。
接下来我们深⼊探讨⼀下编译和链接的整个过程,来更好的理解动静态库的使⽤原理。 先来回顾下什么是编译呢?编译的过程其实就是将我们程序的源代码翻译成CPU能够直接运⾏的机器 代码。 ⽐如:在⼀个源⽂件 hello.c ⾥便简单输出"hello world!",并且调⽤⼀个run函数,⽽这个函数被 定义在另⼀个原⽂件 code.c 中。这⾥我们就可以调⽤ gcc -c 来分别编译这两个原⽂件。
可以看到,在编译之后会⽣成两个扩展名为 .o 的⽂件,它们被称作⽬标⽂件。要注意的是如果我们 修改了⼀个原⽂件,那么只需要单独编译它这⼀个,⽽不需要浪费时间重新编译整个⼯程。⽬标⽂件 是⼀个⼆进制的⽂件,⽂件的格式是 ELF ,是对⼆进制代码的⼀种封装。
二、ELF文件
上面我们提到,对于我们的.o文件和.so文件,.a文,可执行文件,那么其都是ELF格式的文件,那么我们将多个文件链接成一个文件,其本质就是将这几个文件的相同部分进行合并罢了。
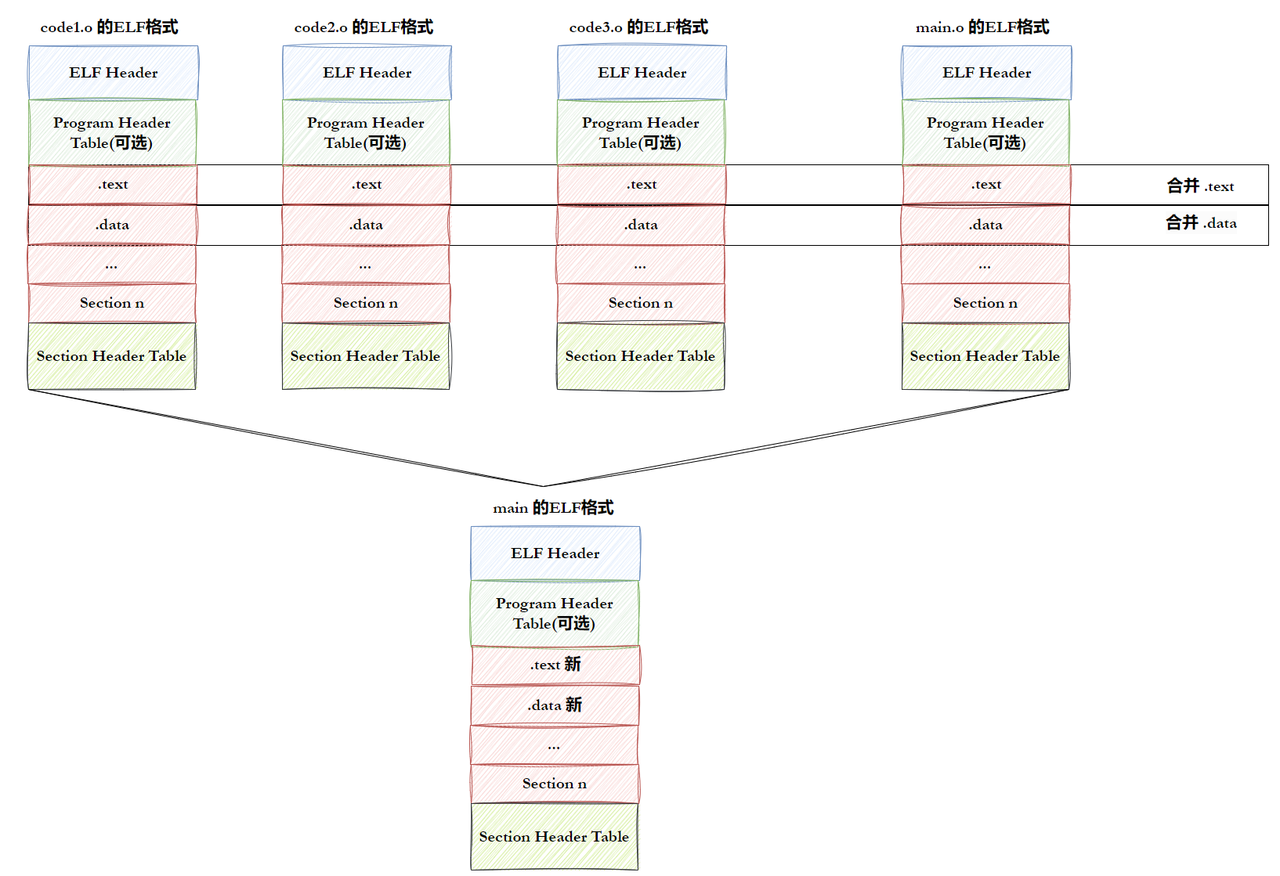
对于ELF格式文件,这个是Linux下特有的
有下面四种文件
**可重定位文件:**即.o文件,包含适合于与其他⽬标⽂件链接来创 建可执⾏⽂件或者共享⽬标⽂件 的代码和数据。
**可执行文件:**即可执行程序
**共享目标文件:**即我们的库文件.so和.a文件
**内核转储:**存放在当前进程的执行上下文,用于dump信号触发。
然后我们的ELF文件格式大致有如下的几个信息:
**ELF头(ELF header):**描述⽂件的主要特性。其位于⽂件的开始位置,它的主要⽬的是定位⽂ 件 的其他部分。
**程序头表(Program header table):**列举了所有有效的段(segments)和他们的属性。表⾥ 记着每个段的开始的位置和位移(offset)、⻓度,毕竟这些段,都是紧密的放在⼆进制⽂件中, 需要段表的描述信息,才能把他们每个段分割开。
**节头表(Section header table):**包含对节的描述
节(Section):ELF⽂件中的基本组成单位,包含了特定类型的数据。ELF⽂件的各种信息和 数据都存储在不同的节中,如代码节存储了可执⾏代码,数据节存储了全局变量和静态数据等。
在ELF中,最常用的节如下:
代码节(.text):⽤于保存机器指令,是程序的主要执⾏部分。
数据节(.data):保存已初始化的全局变量和局部静态变量。
然后我们可以使用size指令查看我们ELF文件的节类型。
size 文件名
前面我们学习程序虚拟地址空间,那么我们也看到虚拟地址空间对于数据类型的地址是有分区的。那么其实和我们的ELF文件格式有关的,那么就比如正文区,那么其就通过页表映射我们的代码节。

然后我们可以使用readelf -h来查看我们的ELF头:
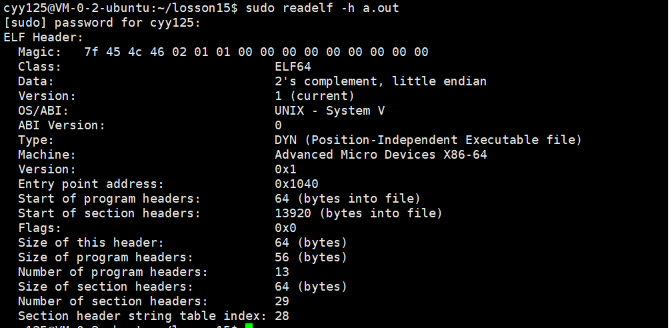
上面的信息,首先第一个class就是我们文件的类型了,然后还有Start point addess 那么这个就是我们程序的入口地址了,Start of program headers这个是我们ELF头的偏移量,然后Machine就是我们这个程序可以运行的机器的配置。
然后我们还可以使用readelf -S 查看我们程序的节点信息:
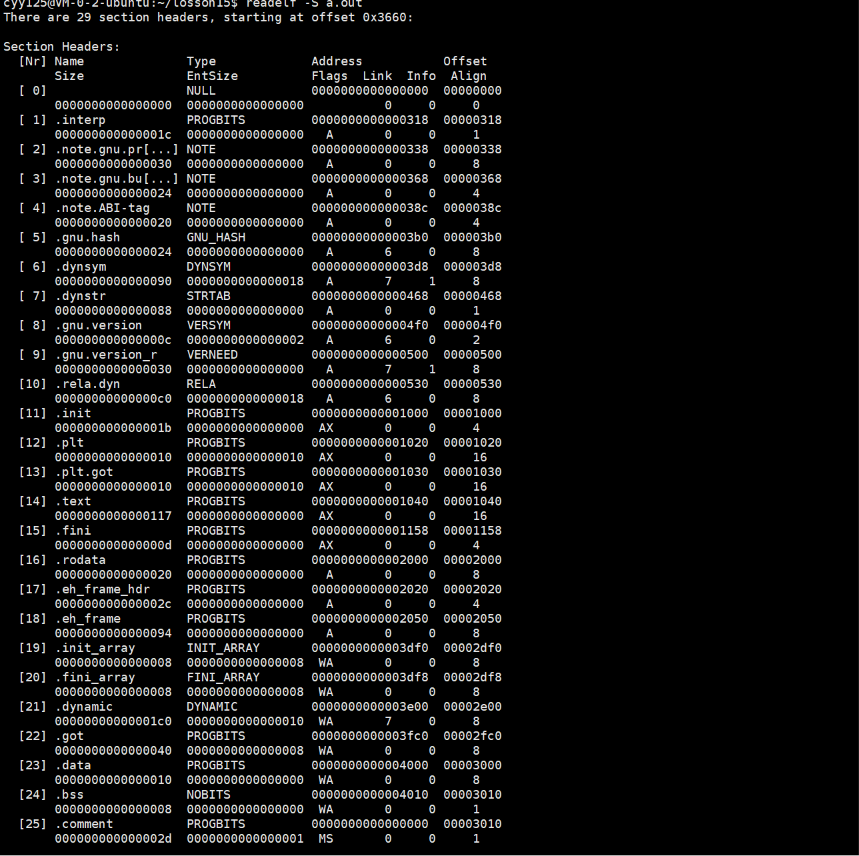
可以看到,其实际上就是一个数组列表,然后上面会存储每个节点的偏移量等信息。
实际上,我们对于ELF文件,那么其本质上,也是个文件,那么其加载,也是和我们普通文件一样的规则,那么也是通过我们的虚拟地址空间和页表的映射加载到内存中的,然后我们也知道了,我们操作系统对于文件的读取的最小单位是以一个块区为单位的,那么有个问题,我们知道ELF文件是分为多个节点的,那么其读取如果是分为节点来读的话,那么我们一个节点可能就128字节,有的可能就256字节,那么是远远小于我们的4KB的,那么如果我们是按照节点进行读,那么就会有很多的内存是被浪费的。
所以对于这个还有一个Program Header Table
这个是段,那么其是将我们文件中的权限一样的节,集合在一起,加载到内存中,那么这样就大大提高了我们内存的利用效率。
我们还是一样,可以使用readelf -l 查看段信息:
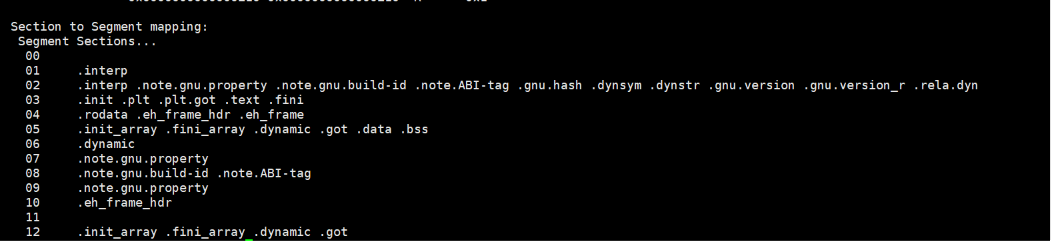
在ELF中是不存在一个一个段的,这个是操作系统进行的,在ELF文件中只存在一个一个的节,这个由加载器帮我们进行分段操作。
三、ELF文件的加载
首先,我们思考一个问题,加载一个进程是先创建其内核数据结构PCB,还是先加载ELF二进制文件。
那么可以肯定的是,我们先创建其内核数据结构,然后创建对应的虚拟地址表和页表对内存的映射。
第二个问题就是,我们的程序在没有加载到内存中的时候,其是否有地址?这个地址是啥?
其实我们的程序内,对于每一行代码,其都有对应的地址,只不过这个地址,也不是我们的物理地址,我们的代码文件在编译后,会对其每一行代码进行平坦操作,都会有一个这个文件内的地址。
我们可以在Linux中使用objdump -d对我们的可执行程序进行反汇编:
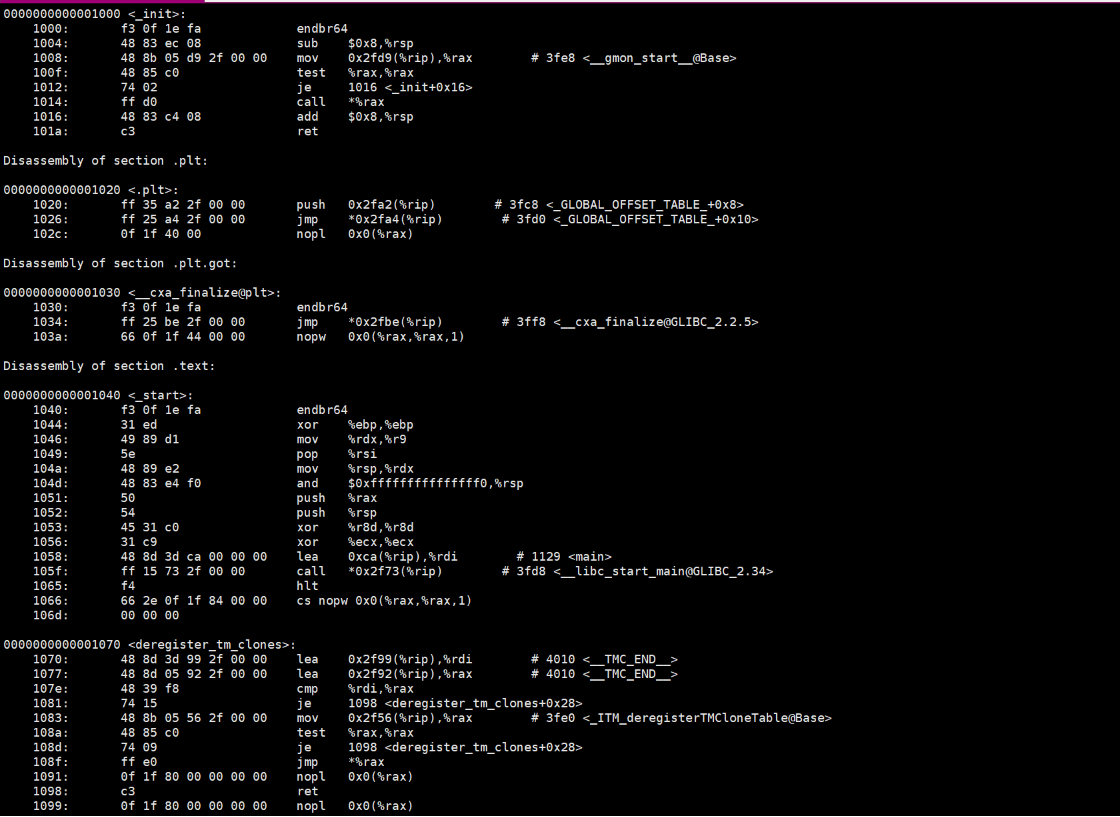
可以看到,上面有1040等,这些就是ELF文件中的地址,但是这个地址是这个文件内部的,相对于我们的程序入口的偏移量。
平坦模式下,其对于我们的程序入口是从0开始的,其地址范围,在32位机器下就是32个0的二进制,到32个1的二进制。
在我们的CPU中存在一个寄存器:cs,那么其就会先获得到我们程序文件的物理地址,然后呢就得到了我们程序的入口,然后根据这个入口,然后获取到每一行代码在ELF文件中的虚拟地址,然后就可以计算出其实际上的虚拟地址,那么就可以再通过页表映射到其物理地址了。
但是其入口地址又是如何得到的呢?
进程mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪⾥来的?从ELF各个 segment来,每个segment有⾃⼰的起始地址和⾃⼰的⻓度,⽤来初始化内核结构中的start,end 等范围数据,另外在⽤详细地址,填充⻚表。
所以,虚拟化地址,不仅我们的硬件要支持,我们的操作系统也要支持。
大致流程图如下:

一、先看懂这张图的结构
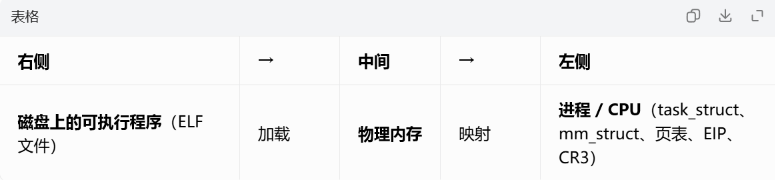
核心就是一句话:把磁盘上的 ELF 文件,按照段的规定,搬到物理内存里,再通过页表映射到进程的虚拟地址空间,最后让 CPU 跳过去执行。
二、第一步:磁盘上的 ELF 文件(最右侧)
图里右边标了 "可执行程序",你能看到几个关键信息:
- 入口点(Entry point address)
图里写了 Entry point address: 0x8060
这是 ELF 文件头里的 e_entry 字段
告诉操作系统:这个程序运行时,第一条指令应该从虚拟地址 0x8060 开始执行
注意:这是虚拟地址,不是磁盘偏移,也不是物理地址
- 程序内容(代码段 .text)
图里能看到 endbr32、push %ebp、mov %esp,%ebp 这些汇编指令,还有对应的机器码(如 f3 0f 1e fa)。
这些就是编译后生成的机器指令,存在磁盘文件里
每条指令都有对应的虚拟地址(如 08048060、08048064...)
这些地址是链接时就确定好的(32 位程序通常从 0x08048000 开始)
- 函数符号
图里能看到 <_start>、<main> 这些标签
这是 ELF 的符号表信息,标记了函数的起始地址
比如 call 0x8049060 <main> 表示调用 main 函数
三、第二步:加载过程(箭头标注 "加载")
当你在 shell 里输入 ./a.out 时,内核做了这些事:
- 读取 ELF 文件头
内核先读 ELF 的前 64 字节(文件头),确认:
是不是合法的 ELF 文件(魔数 0x7f ELF)
是 32 位还是 64 位
入口点地址是多少(图里的 0x8060)
有几个程序头(Program Headers)
- 读取 Program Headers(段表)
ELF 文件里有一张 "加载说明书" 叫 Program Headers,告诉内核:
哪些段需要加载到内存
每个段在文件里的偏移(offset)
要加载到的虚拟地址(vaddr)
大小是多少
权限是什么(读 / 写 / 执行)
比如典型的:
.text 代码段:权限 r-x(读 + 执行)
.data 数据段:权限 rw-(读 + 写)
.bss 段:不占磁盘空间,但加载时要分配内存并清零
- 分配物理内存 + 建立页表映射
内核根据 Program Headers 的要求:
给进程分配物理页框(物理内存)
把磁盘上的代码 / 数据读进物理内存
在页表里建立映射:虚拟地址 → 物理地址
重点:图里中间的 "物理内存" 显示的地址是 0000000000001000 这种,但右边磁盘里的指令地址是 08048060------这两个地址不一样!
右边 08048060 是虚拟地址(进程视角)
中间 0000...1000 是物理内存地址(实际内存条上的位置)
它们的对应关系由页表维护
四、第三步:物理内存中的样子(中间部分)
图里中间标了 "物理内存",能看到:
- 内容和磁盘上几乎一样
加载完成后,物理内存里的机器码和磁盘 ELF 文件里的机器码是完全相同的 ------ 因为就是原封不动搬过来的。
你可以对比左右两边:
右边磁盘:f3 0f 1e fa → endbr32
左边物理内存:同样是 f3 0f 1e fa → endbr32
这就是代码段的加载:原样拷贝。
- 但地址完全不同
磁盘 / 虚拟视角:从 0x08048000 开始
物理内存视角:从某个物理地址开始(图里示意的是低地址)
为什么要这样?
每个进程都以为自己独占 0~4GB(32 位)的地址空间
但实际物理内存只有一条,大家共用
靠页表做 "翻译",让每个进程都觉得自己的代码在 0x08048000
五、第四步:进程描述符与内存描述符(左上角)
图里左上角有两个结构体:task_struct 和 mm_struct
- task_struct(进程控制块)
这是 Linux 内核里描述一个进程的结构体,里面记录了:
进程 ID(PID)
进程状态(运行 / 睡眠 / 停止...)
打开的文件列表
信号处理
指向 mm_struct 的指针
可以理解为:进程的 "身份证" + "档案袋"
- mm_struct(内存描述符)
这是描述进程虚拟地址空间的结构体,里面记录了:
代码段的起止地址(start_code / end_code)
数据段的起止地址
堆的起始地址
栈的起始地址
页表的物理地址(pgd)
各个内存区域(VMA)的链表
可以理解为:进程的 "内存地图"
图里 task_struct 指向 mm_struct,表示:每个进程都有一份自己的内存布局描述。
六、第五步:页表与地址翻译(左下角)
图里左下角有个 "页表",旁边是 CPU 里的 CR3 寄存器。
- CR3 寄存器
CR3 是 CPU 的控制寄存器 3
里面存的是当前进程页表的物理地址(页目录基址)
当内核切换进程时,会把新进程的页表地址写入 CR3
这就是进程切换的核心动作之一------ 换页表
- 页表的作用
CPU 执行指令时,拿到的都是虚拟地址(比如 0x08048060),需要翻译成物理地址才能访问内存条:
plaintext
虚拟地址 0x08048060
↓ 查页表(CR3指向页表)
物理地址 0x...某物理页框... + 偏移
这个翻译过程是CPU 硬件自动完成的(MMU 内存管理单元),软件不需要干预。
- 为什么要用虚拟地址?
隔离:每个进程互相看不见对方的内存
安全:用户态不能随便访问内核空间
方便:程序链接时可以用固定地址(如 0x08048000),不用管实际物理内存在哪
效率:可以换页、内存共享、写时复制等
七、第六步:CPU 开始执行(左下角 CPU)
图里 CPU 里有两个寄存器:EIP 和 CR3
- CR3:已经设置好了
加载完成后,内核把进程的页表地址写入 CR3,CPU 就知道该用哪张页表来翻译地址了。
- EIP:指令指针寄存器
EIP 存的是下一条要执行的指令的地址
加载完成后,内核把 ELF 入口点地址(图里的 0x8060,完整是 0x08048060)设置到 EIP 里
然后 CPU 就从这个地址开始取指执行
这就是程序的第一条指令!从 _start 开始,而不是 main。
图里也能看到最上面是 endbr32(_start 的开头),下面才是 call <main>。
- 执行流程
CPU 开始执行后:
从 EIP 指向的虚拟地址取指令
MMU 通过 CR3 + 页表翻译成物理地址
从物理内存拿到机器码
执行这条指令
EIP 自动指向下一条指令
循环往复...
八、完整流程串一遍(总结)
把整个过程按时间顺序串起来:
第 1 步:用户执行 ./a.out
Shell 调用 fork() 创建子进程,然后调用 execve() 系统调用。
第 2 步:内核读取 ELF 文件头
检查魔数,确认是 ELF 文件
读取入口点 e_entry = 0x08048060
读取 Program Headers,知道有哪些段要加载
第 3 步:创建进程地址空间
内核创建 task_struct 和 mm_struct
初始化进程的虚拟地址空间布局(代码段、数据段、堆、栈等)
第 4 步:建立页表映射(加载段)
为代码段、数据段分配物理页框
把磁盘上的指令 / 数据读到物理内存
在页表里建立映射:虚拟地址 → 物理地址
设置权限(代码段只读可执行,数据段可读写)
第 5 步:设置运行上下文
设置 CR3 寄存器,指向新进程的页表
设置 EIP 寄存器,值为 ELF 入口点(0x08048060)
设置栈指针 ESP,指向用户栈顶
其他寄存器初始化
第 6 步:切换到用户态,开始执行
内核从系统调用返回
CPU 切换到用户态(ring 3)
EIP 指向 _start,程序开始运行
执行到 call main 时,才进入我们写的 main 函数
如上,是我使用AI生成的具体流程,可以参考一下。
四、理解链接和加载
1、静态链接
首先,我们准备下面两个.c文件:
run.c
code.c
然后我们将其编译,形成ELF格式文件,然后反汇编看其内部代码的逻辑地址:
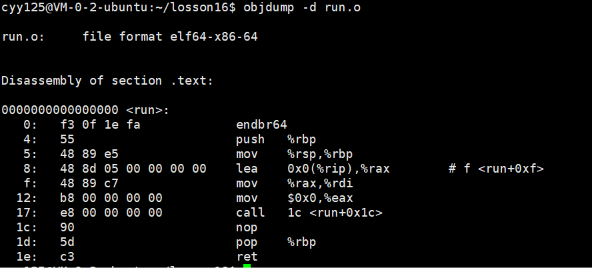
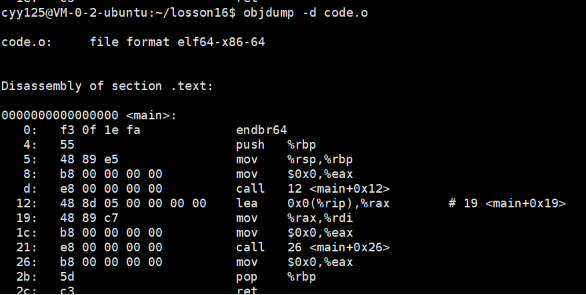
我们看到在我们的run.o文件中,其不认识printf函数,其地址是空的,只是预留了位置。
在我们的code.o文件中也是如此,对于别的文件定义的函数也是不认识,然后对于库函数也是不认识的。
我们可以看到这⾥的call指令,它们分别对应之前调⽤的printf和run函数,但是你会发现他们的跳转地 址都被设成了0。那这是为什么呢?
其实就是在编译 hello.c 的时候,编译器是完全不知道 printf 和 run 函数的存在的,⽐如他们 位于内存的哪个区块,代码⻓什么样都是不知道的。因此,编译器只能将这两个函数的跳转地址先暂 时设为0。这个地址会在哪个时候被修正?链接的时候!为了让链接器将来在链接时能够正确定位到这些被修正 的地址,在代码块(.data)中还存在⼀个重定位表,这张表将来在链接的时候,就会根据表⾥记录的 地址将其修正。
然后我们再查看一下其节点:
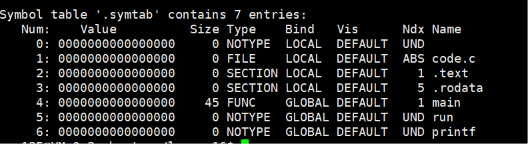
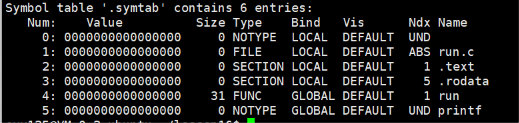
可以看到,在两个文件中,其外部函数的都是UND,也就是未定义,在本文件中找不到的意思。
那么我们将其链接:
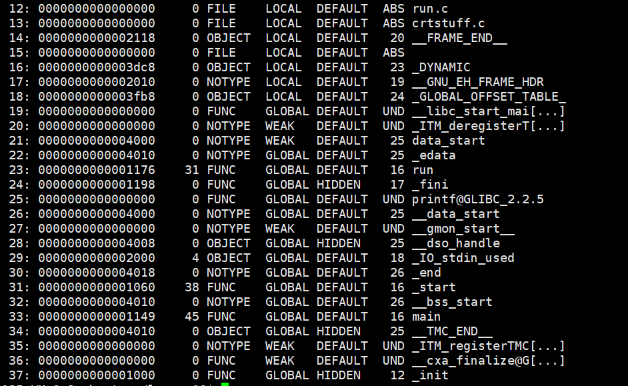
可以看到,此时main和run之间都是认识的,而且我们还发现,main和run前面的数字都是16,这是说明这两个函数都被分配到我们这个文件的第16个节点了。
我们上面对这个文件是使用的动态链接,因为静态链接的文件实在太大了,不方便查看。
我们可以查看main.exe中的节信息:

静态链接就是把库中的.o进⾏合并,和上述过程⼀样 所以链接其实就是将编译之后的所有⽬标⽂件连同⽤到的⼀些静态库运⾏时库组合,拼装成⼀个独⽴ 的可执⾏⽂件。其中就包括我们之前提到的地址修正,当所有模块组合在⼀起之后,链接器会根据我 们的.o⽂件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从⽽修正它们的地址。这 其实就是静态链接的过程。
2、动态链接
首先,动态链接就是在程序运行的时候才会去链接库的。是运行时加载。
那么其是如何加载的呢?而且我们写代码的时候,并没有进行指定去加载这些?
当我们执行一个程序的时候,其第一个执行的入口并不是我们的main函数。实际程序的入口点是_start,这个是一个C运行时库,一般是我们的链接器提供的特殊函数,也就是说我们的程序在链接的时候,是被动了手脚的。

我们提到,这个是我们程序的入口地址,而且我们知道这个地址是虚拟地址,那么我们查看我们程序中的函数,看看那个地址和这个一样。
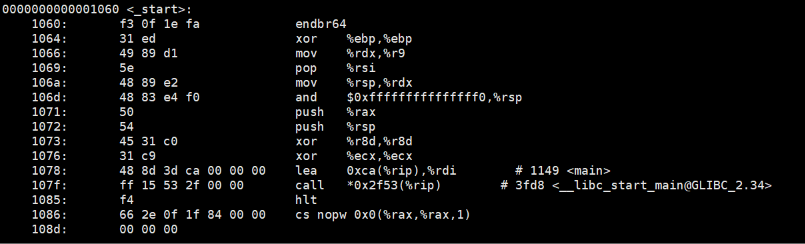
可以看到这个入口就是_srart。
在 _start 函数中,会执⾏⼀系列初始化操作,这些操作包括:
-
设置堆栈:为程序创建⼀个初始的堆栈环境。
-
初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位 置,并清零未初始化的数据段。
-
动态链接:这是关键的⼀步, _start 函数会调⽤动态链接器的代码来解析和加载程序所依赖的 动态库(shared ibraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调 ⽤和变量访问能够正确地映射到动态库中的实际地址。
那么我们是如何找到对应的库方法的呢?
动态库,其也是ELF文件,在编译的时候,也是遵循平坦模式的,那么就会对其文件中的代码进行编址,这个地址就是各个方法在文件内相对于文件入口的偏移量。
我们进程先加载的内核数据结构,然后会先加载我们要使用到的动态库,最后再加载我们的代码和数据的。
在对程序代码和数据加载的过程中,会对我们的程序使用到的函数完成重定位操作。那么此时就会使得我们代码和数据被修改,但是有个疑问就是,我们代码和数据不是只可读的吗,那么是咋实现修改的。
所以:动态链接采⽤的做法是在 .data (可执⾏程序或者库⾃⼰)中专⻔预留⼀⽚区域⽤来存放函数 的跳转地址,它也被叫做全局偏移表GOT,表中每⼀项都是本运⾏模块要引⽤的⼀个全局变量或函数 的地址。
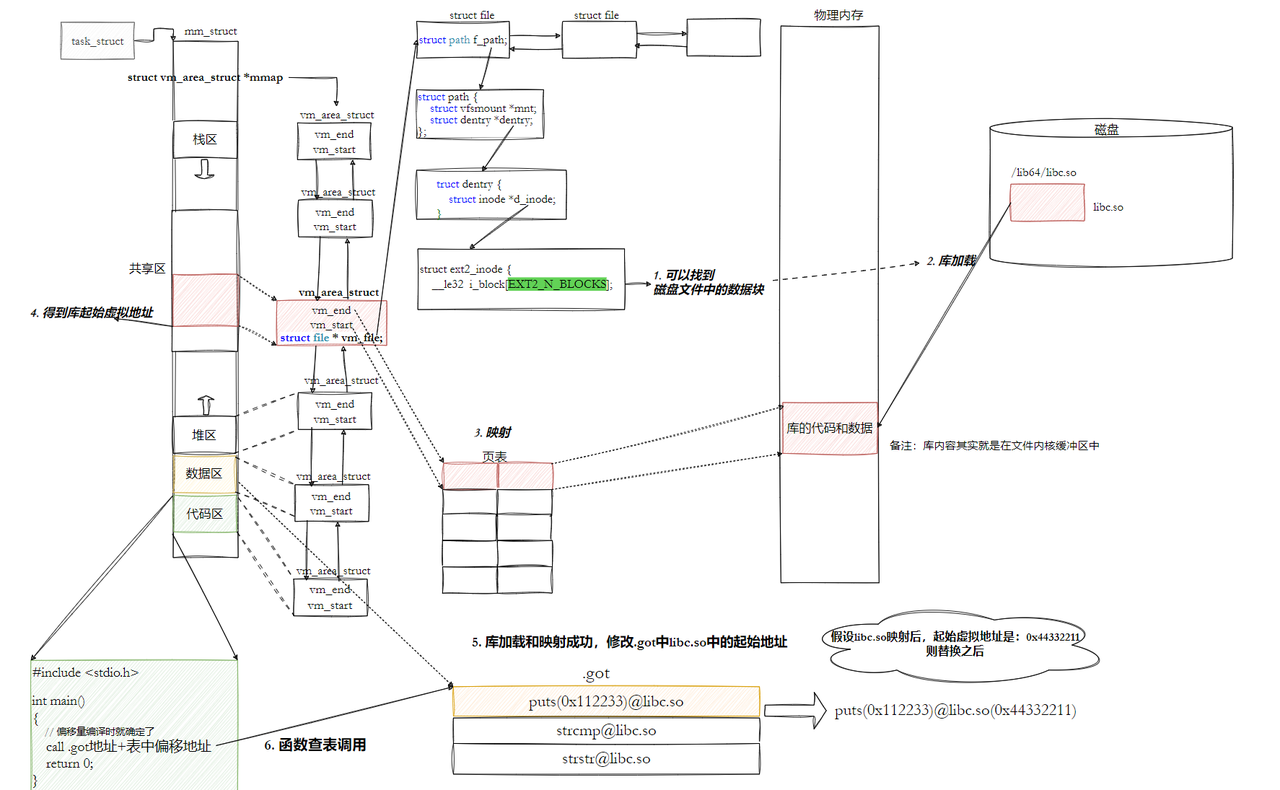
-
由于代码段只读,我们不能直接修改代码段。但有了GOT表,代码便可以被所有进程共享。但在不 同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到GOT表上,就是每个进程的 每个动态库都有独⽴的GOT表,所以进程间不能共享GOT表。
-
在单个.so下,由于GOT表与 .text 的相对位置是固定的,我们完全可以利⽤CPU的相对寻址来找 到GOT表。
-
在调⽤函数的时候会⾸先查表,然后根据表中的地址来进⾏跳转,这些地址在动态库加载的时候会 被修改为真正的地址。
-
这种⽅式实现的动态链接就被叫做 PIC 地址⽆关代码 。换句话说,我们的动态库不需要做任何修 改,被加载到任意内存地址都能够正常运⾏,并且能够被所有进程共享,这也是为什么之前我们给 编译器指定-fPIC参数的原因,PIC=相对编址+GOT。
由于动态链接在程序加载的时候需要对⼤量函数进⾏重定位,这⼀步显然是⾮常耗时的。为了进⼀ 步降低开销,我们的操作系统还做了⼀些其他的优化,⽐如延迟绑定,或者也叫PLT(过程连接表 (Procedure Linkage Table))。与其在程序⼀开始就对所有函数进⾏重定位,不如将这个过程 推迟到函数第⼀次被调⽤的时候,因为绝⼤多数动态库中的函数可能在程序运⾏期间⼀次都不会被 使⽤到。