Python进阶系列之-正则表达式
写在前面:在日常开发中,我们经常需要处理字符串------校验邮箱格式、提取手机号、过滤敏感词、解析HTML标签......如果用传统字符串方法,往往需要写大量冗长的 if-else 和循环,不仅效率低下,而且容易出错。正则表达式(Regular Expression)正是解决这类问题的利器,它用一套简洁的规则,实现对字符串的精准匹配、查找和替换,是每个 Python 开发者必须掌握的技能。
本文从正则表达式的核心概念出发,系统讲解 Python 中 re 模块的常用函数(match、search、compile、sub),深入解析各类元字符、数量词、边界符、分组与反向引用,最后通过多个实战案例(邮箱校验、HTML标签匹配、敏感词过滤)带你彻底掌握正则表达式。
文章目录
- Python进阶系列之-正则表达式
-
- 一、正则表达式基础
-
- [1.1 什么是正则表达式](#1.1 什么是正则表达式)
- [1.2 正则表达式在 Python 中的使用步骤](#1.2 正则表达式在 Python 中的使用步骤)
- [1.3 三个核心函数](#1.3 三个核心函数)
- 二、正则表达式核心规则
-
- [2.1 匹配单个字符](#2.1 匹配单个字符)
- [2.2 匹配多个字符(数量词)](#2.2 匹配多个字符(数量词))
-
- [贪婪 vs 非贪婪:经典匹配陷阱](#贪婪 vs 非贪婪:经典匹配陷阱)
- [2.3 边界匹配](#2.3 边界匹配)
- [2.4 选择与分组](#2.4 选择与分组)
- [三、re 模块进阶用法](#三、re 模块进阶用法)
-
- [3.1 `re.compile()` 编译正则](#3.1
re.compile()编译正则) - [3.2 `re.sub()` 替换字符串](#3.2
re.sub()替换字符串) - [3.3 标志位(flags)](#3.3 标志位(flags))
- [3.4 `re.split()`:按正则规则分割字符串](#3.4
re.split():按正则规则分割字符串)
- [3.1 `re.compile()` 编译正则](#3.1
- 四、综合实战案例
-
- [4.1 邮箱校验](#4.1 邮箱校验)
- [4.2 手机号提取](#4.2 手机号提取)
- [4.3 敏感词过滤](#4.3 敏感词过滤)
- [4.4 提取 URL 中的域名](#4.4 提取 URL 中的域名)
- [4.5 HTML 标签合法性校验](#4.5 HTML 标签合法性校验)
- 五、常见误区与注意事项
- 六、正则表达式速查表
- 七、全文总结
一、正则表达式基础
1.1 什么是正则表达式
正则表达式(Regular Expression,简称 regex)是一种描述字符串模式的表达式。它用特定的符号组合来定义一组字符串的规则,然后利用这些规则对目标字符串进行匹配、查找、替换等操作。
核心价值:
- 从海量文本中快速提取目标信息
- 验证用户输入的合法性(邮箱、手机号、密码强度)
- 批量替换符合某种模式的文本
1.2 正则表达式在 Python 中的使用步骤
Python 通过内置的 re 模块提供正则支持,使用流程非常简单:
python
import re
# 1. 定义正则规则(模式)
pattern = r'\d+' # 匹配一个或多个数字
# 2. 调用 re 模块的函数进行匹配
result = re.match(pattern, '123abc')
# 3. 获取匹配结果
if result:
print(result.group()) # 输出: 123注意 :正则表达式字符串前建议加上
r(raw string),表示原始字符串,避免反斜杠\被 Python 解释器转义。
1.3 三个核心函数
| 函数 | 作用 | 匹配方式 |
|---|---|---|
re.match(pattern, string) |
从字符串的起始位置开始匹配 | 必须从头匹配,不匹配则返回 None |
re.search(pattern, string) |
在整个字符串中查找第一个匹配项 | 可以从任意位置开始匹配 |
re.findall(pattern, string) |
查找字符串中所有匹配项,返回列表 | 全局搜索 |
示例对比:
python
import re
text = 'hello 123 world 456'
# match: 从头匹配
print(re.match(r'\d+', text)) # None,因为开头是字母
# search: 查找第一个
print(re.search(r'\d+', text).group()) # 123
# findall: 查找所有
print(re.findall(r'\d+', text)) # ['123', '456']📌 快速记忆口诀:
match:从头开始匹配,开头不对直接失败search:全文扫描查找,找到第一个就返回findall:全文全部找完,返回列表形式
二、正则表达式核心规则
2.1 匹配单个字符
| 元字符 | 含义 | 等价表示 |
|---|---|---|
. |
匹配任意一个 字符(除换行符 \n) |
- |
\d |
匹配任意一个数字 | [0-9] |
\D |
匹配任意一个非数字 | [^0-9] |
\s |
匹配任意一个空白字符(空格、\t、\n、\r) |
- |
\S |
匹配任意一个非空白字符 | - |
\w |
匹配任意一个单词字符(字母、数字、下划线、汉字) | [a-zA-Z0-9_\u4e00-\u9fa5] |
\W |
匹配任意一个非单词字符 | - |
[abc] |
匹配 a、b、c 中的任意一个 |
- |
[^abc] |
匹配除了 a、b、c 以外的任意一个 |
- |
示例:
python
import re
# . 匹配任意一个字符
print(re.match(r'.it.', '.ita').group()) # .ita
# \d 匹配数字
print(re.match(r'\d{3}', '123abc').group()) # 123
# [abc] 匹配 a、b、c 之一
print(re.match(r'[abc]+\d', 'aaa123').group()) # aaa12.2 匹配多个字符(数量词)
| 数量词 | 含义 | 举例 |
|---|---|---|
? |
前面的字符出现 0 次或 1 次 | colou?r 可匹配 color 或 colour |
+ |
前面的字符出现 1 次或多次 | \d+ 匹配一个或多个数字 |
* |
前面的字符出现 0 次或多次 | \d* 匹配零个或多个数字 |
{n} |
前面的字符出现恰好 n 次 | \d{3} 匹配三位数字 |
{n,} |
前面的字符出现至少 n 次 | \d{3,} 匹配三位及以上数字 |
{n,m} |
前面的字符出现 n 到 m 次 | \d{2,5} 匹配二到五位数字 |
示例:
python
import re
# ? 表示0或1次
print(re.match(r'colou?r', 'color').group()) # color
print(re.match(r'colou?r', 'colour').group()) # colour
# + 表示1次或多次
print(re.match(r'\d+', '123abc').group()) # 123
# * 表示0次或多次
print(re.match(r'ab*', 'a').group()) # a
print(re.match(r'ab*', 'abbb').group()) # abbb
# {n,m} 指定次数范围
print(re.match(r'\d{2,4}', '12345').group()) # 1234(贪婪匹配,尽可能多)贪婪 vs 非贪婪:经典匹配陷阱
默认情况下,*、+、{n,m} 都是贪婪模式 :会尽可能多地匹配字符,直到无法继续为止。在数量词后加 ? 可切换为非贪婪(懒惰)模式:尽可能少地匹配,满足条件就停止。
最典型的场景是匹配 HTML 标签:
python
import re
text = '<div>第一段</div><div>第二段</div>'
# 贪婪模式:匹配到最后一个 </div> 才停止
greedy = re.match(r'<div>.*</div>', text)
print(greedy.group())
# 输出:<div>第一段</div><div>第二段</div>
# 非贪婪模式:遇到第一个 </div> 就停止
lazy = re.match(r'<div>.*?</div>', text)
print(lazy.group())
# 输出:<div>第一段</div>记忆技巧:加 ? 就是"别贪了,够了就停"。
2.3 边界匹配
| 元字符 | 含义 |
|---|---|
^ |
匹配字符串的开头 |
$ |
匹配字符串的结尾 |
\b |
匹配单词的边界 |
示例:
python
import re
# ^ 开头匹配
print(re.search(r'^\d+', '123abc').group()) # 123
print(re.search(r'^\d+', 'a123')) # None
# $ 结尾匹配
print(re.search(r'\d+$', 'abc123').group()) # 123
print(re.search(r'\d+$', '123abc')) # None
# 同时使用 ^ 和 $ 进行全匹配
print(re.match(r'^\d{3}$', '123').group()) # 123
print(re.match(r'^\d{3}$', '1234')) # None2.4 选择与分组
| 元字符 | 含义 |
|---|---|
| ` | ` |
() |
分组,将括号内的内容作为一个整体,并可以捕获匹配结果 |
\num |
反向引用,引用第 num 个分组匹配到的内容 |
(?P<name>) |
给分组命名 |
(?P=name) |
引用命名分组匹配到的内容 |
示例:使用分组提取信息
python
import re
# 提取 QQ 号和号码
result = re.match(r'(qq):(\d{5,11})', 'qq:12306')
if result:
print(result.group(0)) # qq:12306
print(result.group(1)) # qq
print(result.group(2)) # 12306示例:反向引用校验 HTML 标签
python
import re
# 匹配单级标签,确保前后标签一致
result = re.match(r'<([a-zA-Z]+)>.*</\1>', '<html>hello</html>')
print(result.group()) # <html>hello</html>
# 匹配多级嵌套标签
result = re.match(r'<([a-zA-Z]+)><([a-zA-Z]+)>.*</\2></\1>', '<div><span>text</span></div>')
print(result.group()) # <div><span>text</span></div>示例:命名分组
python
result = re.match(r'<(?P<tag>\w+)>.*</(?P=tag)>', '<p>content</p>')
print(result.group()) # <p>content</p>三、re 模块进阶用法
3.1 re.compile() 编译正则
当需要多次使用同一个正则表达式时,可以先编译成正则对象,提高匹配效率。
python
import re
# 编译正则
pattern = re.compile(r'\d+')
# 使用编译后的对象进行匹配
print(pattern.findall('abc123def456')) # ['123', '456']
print(pattern.search('abc123').group()) # 1233.2 re.sub() 替换字符串
re.sub() 用于替换字符串中符合正则的部分,功能比字符串的 replace() 强大得多。
python
import re
# 将敏感词替换为 *
text = '车主说: 你的刹车片应该换了啊, 嘿嘿'
pattern = r'啊|阿|嘿|呵|哈|啦|嘻|桀'
result = re.sub(pattern, '*', text)
print(result) # 车主说: 你的刹车片应该换了*, 嘿*
# 支持回调函数
def repl(match):
return '*' * len(match.group())
result = re.sub(r'\d+', repl, '我的电话是123456789')
print(result) # 我的电话是*********3.3 标志位(flags)
re 模块支持多种标志位,用于改变匹配行为:
| 标志 | 缩写 | 作用 |
|---|---|---|
re.I |
IGNORECASE |
忽略大小写 |
re.M |
MULTILINE |
多行模式,^ 和 $ 匹配每行的开头和结尾 |
re.S |
DOTALL |
让 . 匹配包括换行符在内的任意字符 |
python
import re
# 忽略大小写
print(re.match(r'hello', 'HELLO', re.I).group()) # HELLO
# 多行模式
text = 'first line\nsecond line'
print(re.findall(r'^\w+', text, re.M)) # ['first', 'second']
# re.S 让 . 匹配换行符,实现跨行匹配
text = '''<div>
第一行内容
第二行内容
</div>'''
# 默认 . 不匹配换行,匹配失败
print(re.search(r'<div>.*</div>', text)) # None
# 加 re.S 后成功匹配跨行内容
result = re.search(r'<div>.*?</div>', text, re.S)
print(result.group()) # 完整输出包含换行的div标签内容3.4 re.split():按正则规则分割字符串
字符串原生的 split() 只能按固定字符分割,re.split() 支持按正则规则分割,能同时处理多种分隔符。
python
import re
# 按逗号、分号、空格分割字符串
text = 'apple,banana; orange grape'
result = re.split(r'[,; ]+', text)
print(result)
# 输出:['apple', 'banana', 'orange', 'grape']四、综合实战案例
4.1 邮箱校验
python
import re
def validate_email(email):
pattern = r'^[a-zA-Z0-9_]{4,20}@(163|126|qq|gmail)\.(com|cn)$'
if re.match(pattern, email):
return True
return False
# 测试
emails = ['hello@163.com', 'test@qq.cn', 'bad@email', 'toolongusername@163.com']
for e in emails:
print(f'{e}: {"有效" if validate_email(e) else "无效"}')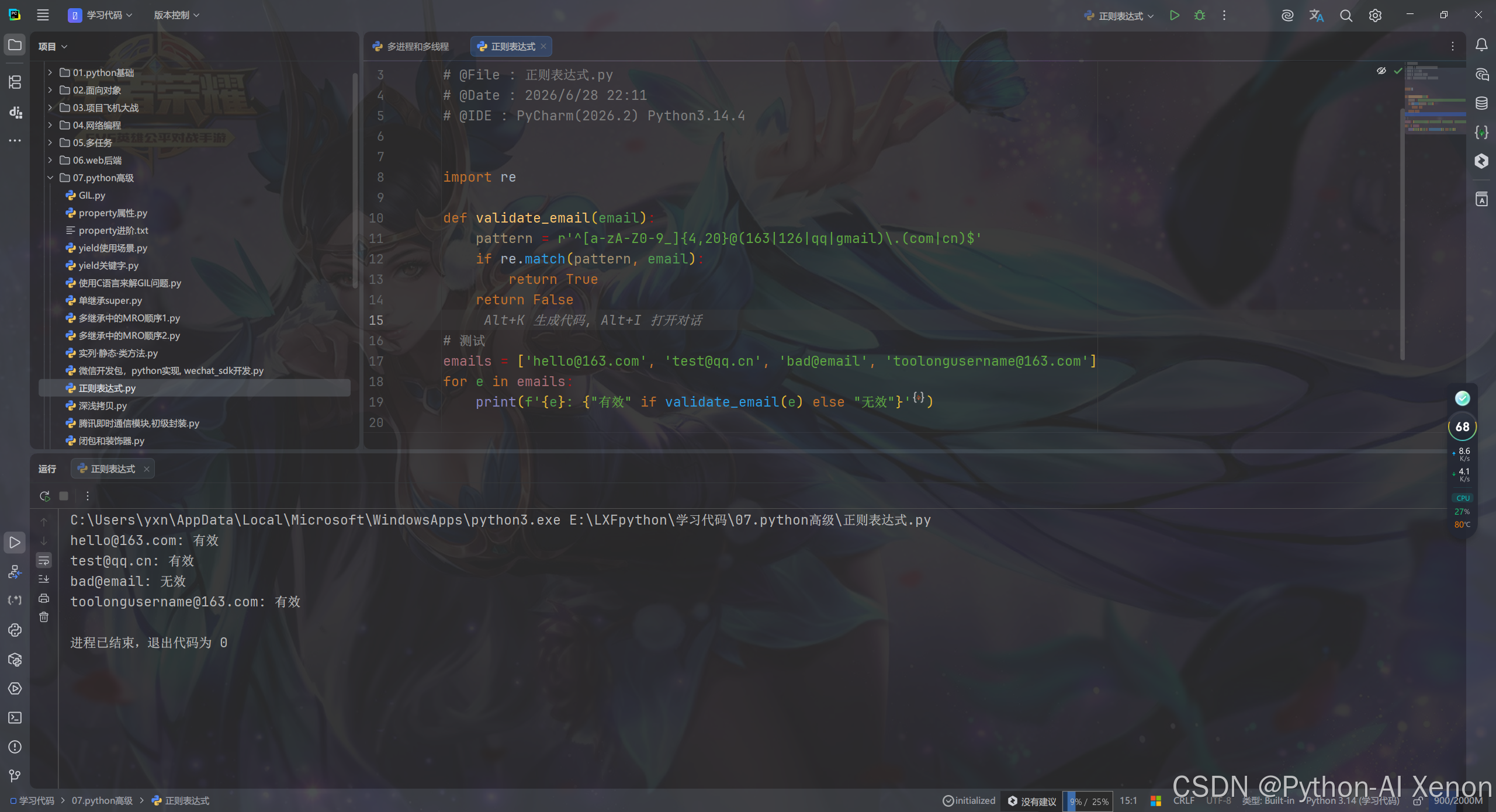
4.2 手机号提取
python
import re
text = '我的手机是13800138000,他的手机是13912345678'
pattern = r'1[3-9]\d{9}'
phones = re.findall(pattern, text)
print(phones) # ['13800138000', '13912345678']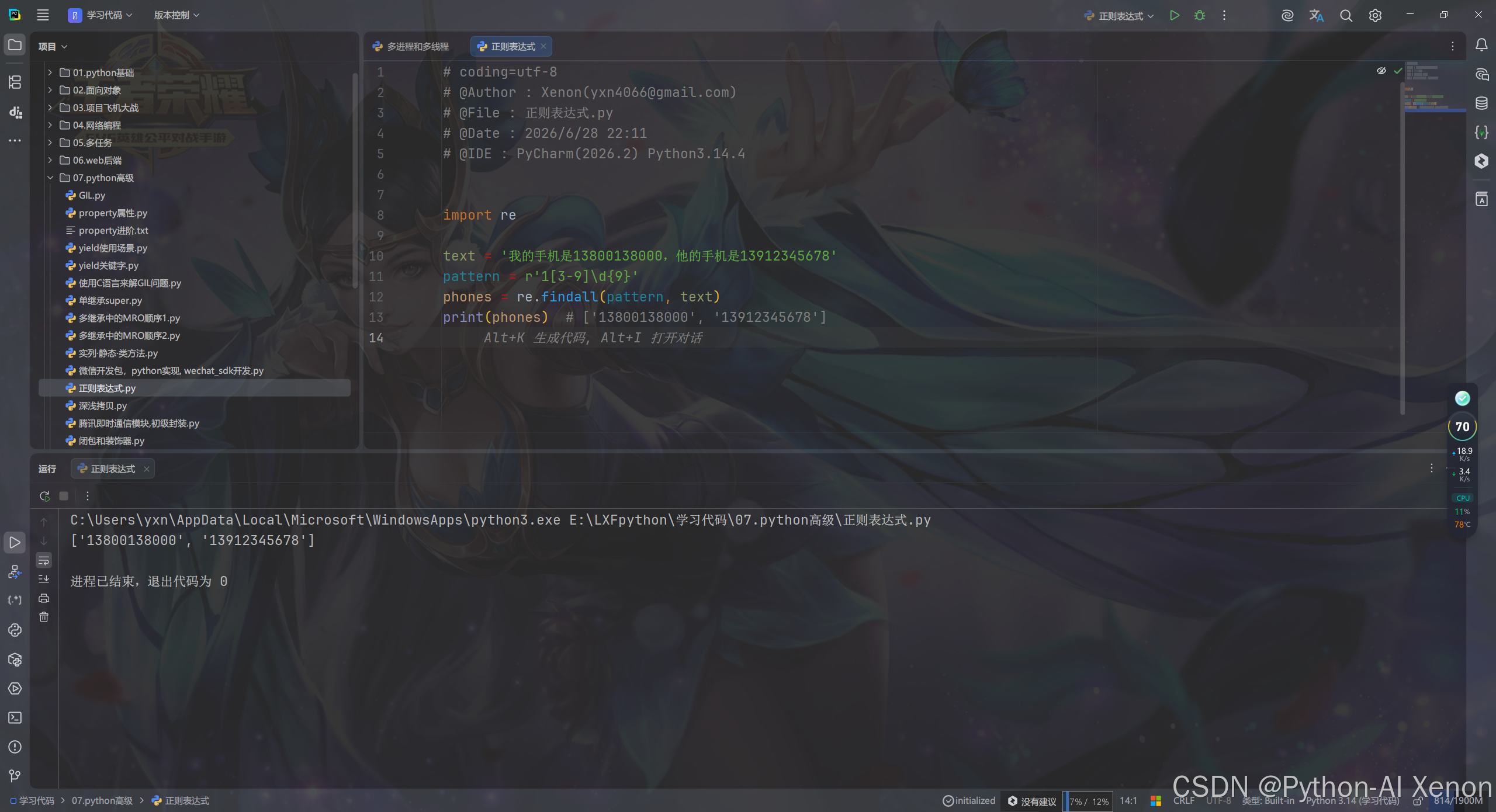
4.3 敏感词过滤
python
import re
def filter_sensitive(text, sensitive_words):
# 将敏感词列表拼接成正则
pattern = '|'.join(sensitive_words)
return re.sub(pattern, '***', text)
words = ['暴力', '色情', '赌博']
text = '这是一个包含暴力和色情的文本,请勿赌博。'
print(filter_sensitive(text, words))
# 这是一个包含***和***的文本,请勿***。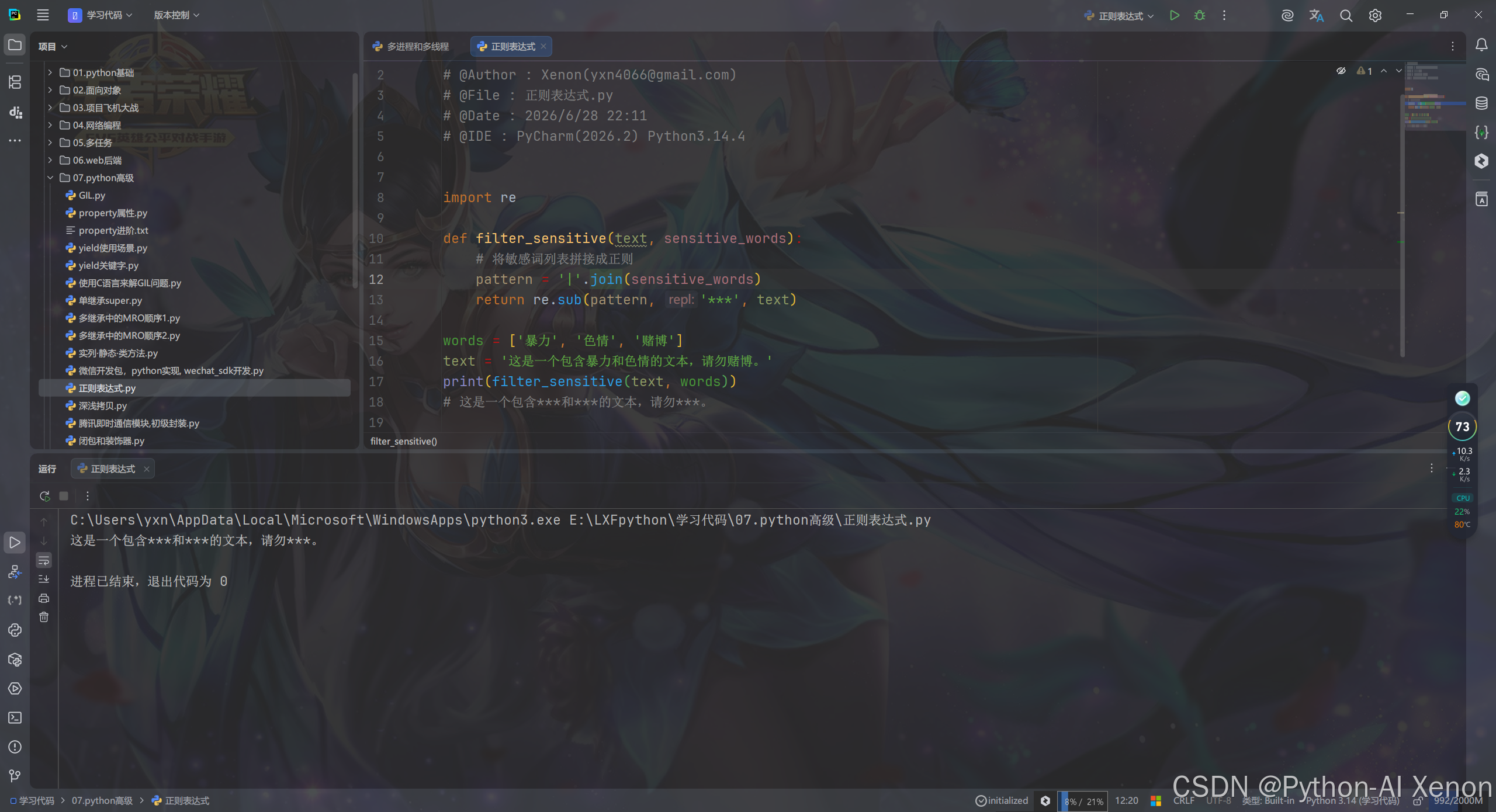
4.4 提取 URL 中的域名
python
import re
url = 'https://www.baidu.com/s?wd=python'
pattern = r'https?://([^/]+)'
result = re.search(pattern, url)
if result:
print(result.group(1)) # www.baidu.com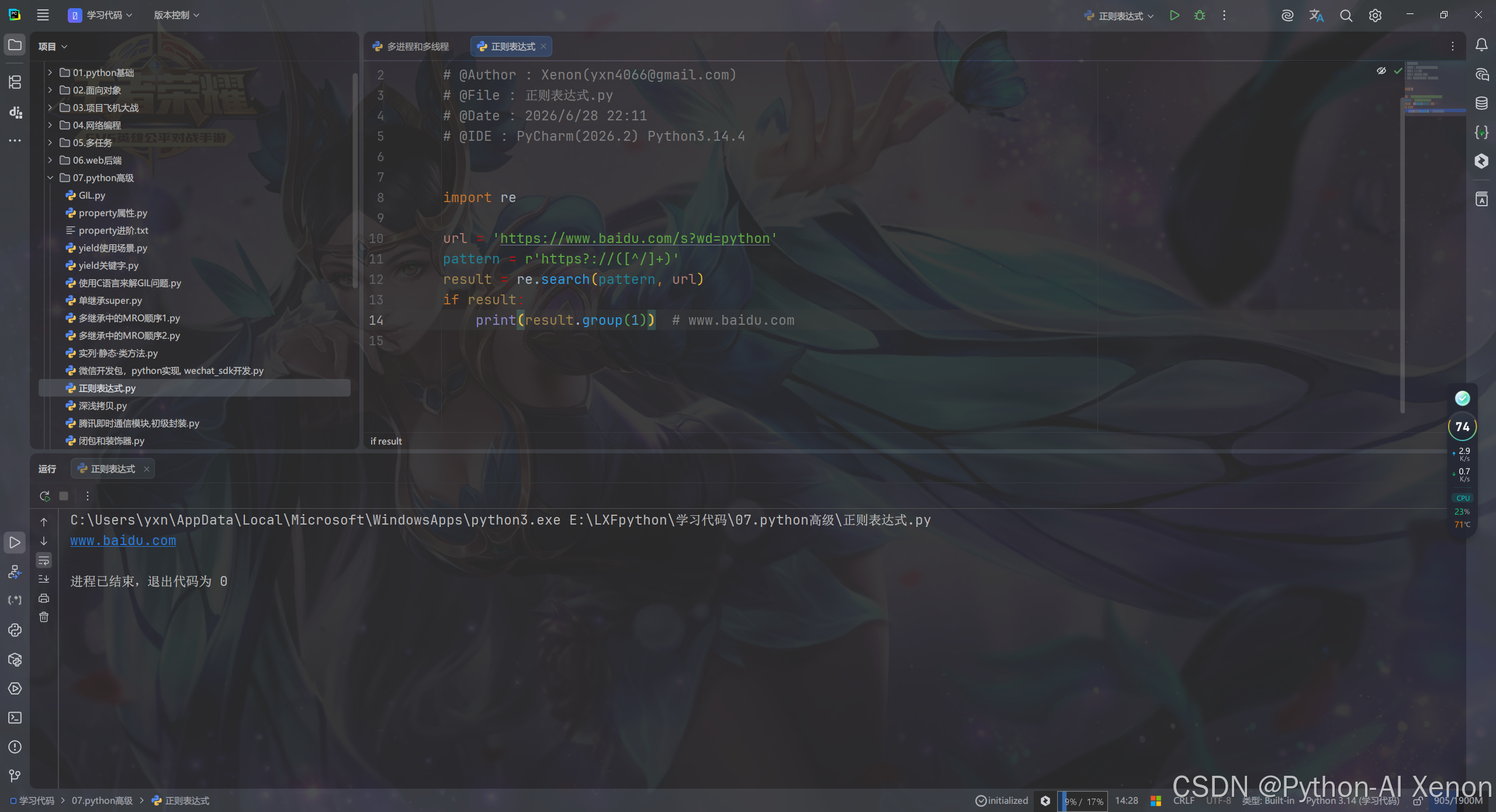
4.5 HTML 标签合法性校验
利用分组+反向引用,可以校验 HTML 标签是否成对闭合,避免出现<div></span>这种标签不匹配的错误。
python
import re
# 案例1:校验单级标签(普通反向引用)
pattern1 = r'<([a-zA-Z]{1,6})>.*</\1>'
print(re.match(pattern1, '<p>你好</p>').group()) # 匹配成功
print(re.match(pattern1, '<p>你好</div>')) # None,标签不匹配
# 案例2:校验多级嵌套标签(命名分组写法)
pattern2 = r'<(?P<outer>[a-z]+)><(?P<inner>h[1-6])>.*</(?P=inner)></(?P=outer)>'
html = '<div><h3>标题</h3></div>'
print(re.match(pattern2, html).group()) # 匹配成功
五、常见误区与注意事项
-
忘记加
r前缀 :\d在普通字符串中会被转义为d,导致匹配失败。始终使用r'\d'。 -
混淆
match和search:match必须从头匹配,search可以匹配任意位置。 -
贪婪匹配陷阱 :默认
*和+是贪婪的,如果需要最小匹配,加?。 -
分组编号从 1 开始 :
group(0)是整个匹配,group(1)是第一个分组。 -
正则性能问题 :过于复杂的正则可能导致回溯爆炸,建议拆分成多个简单正则或使用
re.compile预编译。 -
特殊字符转义坑 :正则里
. * + ? | () [] {} ^ $ \都是有特殊含义的元字符,如果要匹配它们本身,必须加反斜杠转义。pythonimport re # 匹配小数点,必须转义 print(re.match(r'3\.14', '3.14').group()) # 正确 print(re.match(r'3.14', '3x14').group()) # 也能匹配,因为.代表任意字符 # 匹配反斜杠,需要写两次(原生字符串下) print(re.match(r'\\', '\\').group()) # 匹配单个\记忆:元字符想当普通字符用,前面加
\就对了。 -
不要滥用正则 :正则不是万能的。
- 解析 HTML/XML 结构:用 BeautifulSoup、lxml 等专门库,正则无法完美处理嵌套结构
- 解析 JSON 数据:用内置
json模块,比正则更稳健 - 简单固定字符串替换:直接用
str.replace(),性能比正则更好
正则的定位是处理符合某种模式的纯文本,复杂结构化数据优先用专用工具。
六、正则表达式速查表
| 类别 | 符号 | 说明 |
|---|---|---|
| 字符 | . |
任意字符(除 \n) |
| 字符集 | [abc] |
a、b、c 之一 |
| 否定字符集 | [^abc] |
非 a、b、c |
| 数字 | \d |
数字 [0-9] |
| 非数字 | \D |
[^0-9] |
| 空白 | \s |
空格、\t、\n、\r |
| 非空白 | \S |
非空白 |
| 单词字符 | \w |
字母、数字、下划线、汉字 |
| 非单词字符 | \W |
特殊字符 |
| 数量 | ? |
0 或 1 次 |
| 数量 | + |
1 次或多次 |
| 数量 | * |
0 次或多次 |
| 数量 | {n} |
恰好 n 次 |
| 数量 | {n,} |
至少 n 次 |
| 数量 | {n,m} |
n 到 m 次 |
| 边界 | ^ |
开头 |
| 边界 | $ |
结尾 |
| 边界 | \b |
单词边界 |
| 选择 | ` | ` |
| 分组 | () |
捕获分组 |
| 反向引用 | \1 |
引用第 1 个分组 |
| 命名分组 | (?P<name>) |
命名 |
| 引用命名 | (?P=name) |
引用命名分组 |
常用正则开箱即用速查
整理了开发中最高频的正则规则,收藏后可以直接调用:
| 场景 | 正则表达式 | 说明 |
|---|---|---|
| 手机号 | 1[3-9]\d{9} |
中国大陆11位手机号 |
| 邮箱 | [a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+ |
通用邮箱格式 |
| 身份证号 | \d{17}[\dXx] |
18位身份证号 |
| 中文汉字 | [\u4e00-\u9fa5]+ |
匹配纯中文 |
| URL地址 | https?://[\w\-]+(\.[\w\-]+)+[/#?]?.* |
匹配http/https链接 |
| IPv4地址 | \d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} |
基础IP格式校验 |
| 正整数 | [1-9]\d* |
大于0的整数 |
七、全文总结
- 正则表达式是用特定符号描述字符串模式的工具,广泛应用于校验、查找、替换。
- Python 的
re模块 提供了match、search、findall、sub、compile、split等核心函数。 - 元字符包括字符类、数量词、边界符、分组与反向引用,掌握它们就能写出大部分正则。
- 实战案例:邮箱校验、手机号提取、敏感词过滤、URL 解析、HTML标签校验等,都是日常开发的常用场景。
- 最佳实践 :使用
r前缀、预编译正则、注意贪婪/懒惰、合理使用分组,避免滥用正则。
正则表达式是程序员的瑞士军刀,初学时可能觉得晦涩难懂,但只要多写多用,很快就能得心应手。希望这篇博客能帮你打开正则的大门,从此面对字符串处理游刃有余。
如果觉得有帮助,欢迎点赞收藏,持续更新中 🚀