
🚀 欢迎来到我的CSDN博客:Optimistic _ chen
✨ 一名热爱技术与分享的全栈开发者,在这里记录成长,专注分享编程技术与实战经验,助力你的技术成长之路,与你共同进步!
🚀我的专栏推荐:
| 专栏 | 内容特色 | 适合人群 |
|---|---|---|
| 🔥C语言从入门到精通 | 系统讲解基础语法、指针、内存管理、项目实战 | 零基础新手、考研党、复习 |
| 🔥Java基础语法 | 系统解释了基础语法、类与对象、继承 | Java初学者 |
| 🔥Java核心技术 | 面向对象、集合框架、多线程、网络编程、新特性解析 | 有一定语法基础的开发者 |
| 🔥Java EE 进阶实战 | Servlet、JSP、SpringBoot、MyBatis、项目案例拆解 | 想快速入门Java Web开发的同学 |
| 🔥Java数据结构与算法 | 图解数据结构、LeetCode刷题解析、大厂面试算法题 | 面试备战、算法爱好者、计算机专业学生 |
| 🔥Redis系列 | 从数据类型到核心特性解析 | 项目必备 |
🚀我的承诺:
✅ 文章配套代码:每篇技术文章都提供完整的可运行代码示例
✅ 持续更新:专栏内容定期更新,紧跟技术趋势
✅ 答疑交流:欢迎在文章评论区留言讨论,我会及时回复(支持互粉)
🚀 关注我,解锁更多技术干货!
⏳ 每天进步一点点,未来惊艳所有人!✍️ 持续更新中,记得⭐收藏关注⭐不迷路 ✨
📌 标签:#技术博客 #编程学习 #Java #C语言 #算法 #程序员
文章目录
【AI Agent 全栈开发】RAG(检索增强生成)这篇博客介绍了 Spring AI 框架中关于文本向量的内容,可以作为学习 LangChain 文本向量相关知识的参考资料。
嵌入模型EmbeddingModels
我们知道计算机底层是二进制数字,擅长处理数字相关的数据,但是不能像人类一样理解语义。而嵌入模型的核心思想就是将人类的语言语义转换为计算机能够理解的数值形式(向量),并要去这种转换能够保留原始符号的语义和关系。
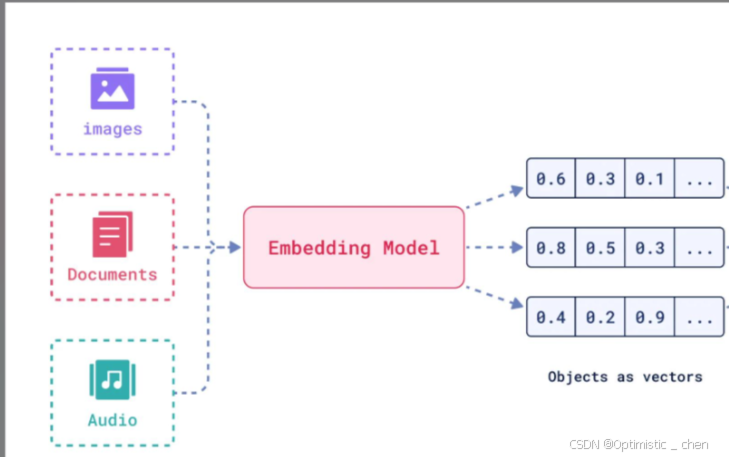
我们之前一直使用LLM(大语言模型)是生成式模型,它理解额输入并生成新的文本,内部实际上也使用嵌入式技术来理解输入。
而嵌入模型是表示型模型。它的⽬标不是⽣成⽂本,⽽是为输⼊的⽂本创建⼀个最佳的、富含语义的数值表⽰(向量)
向量的概念
首先明确,嵌⼊的结果就是⼀个向量,它本质上是⼀个数字列表(一维数组)。
- 向量维度: 嵌⼊结果得到的列表⻓度是固定的,称为向量的"维度"。维度越⾼,通常能捕捉更细微的语义信息,但也需要更多的计算和存储资源。
- 向量空间:在三维坐标系中,一个点用(x,y,z)来表示,在高维向量空间中,一个点可能是(0.2,0.6,-0.1...,0.6),一个有几百个数字的坐标。
在向量空间中,每一个点都代表一个概念,可能是一个单词,一个图片,一个电影等等。向量空间就是用数学来度量语义。通过计算两个向量之间的"距离"或"相似度"来实现这⼀点。
- 欧式距离:距离越短,相似度越⾼
- 余弦相似度 :它忽略向量的绝对⻓度(⼤⼩),只关注两个向量在⽅向上的差异。"⽅向"代表"含义",⽽"⻓度"往往只代表"⽂本的⻓度"或"词汇的多少"。实现基于内容的相似性搜索,⽽不是基于精确匹配的查询。
使用场景:
- 语义搜索:语义搜索则能将查询(苹果 )和⽂档库中的所有⽂档都转换为向量。然后计算查询向量与所有⽂档向量的相似度,返回最相似的⽂档。这样即使⽂档⾥没有词,但只要它是关于"苹果" 的,就能被找到
- RAG:当⽤⼾向LLM提问时,系统⾸先使⽤嵌⼊模型在知识库(如公司内部⽂档)中进⾏语义搜索,找到最相关的内容,然后将这些内容和问题⼀起交给LLM来⽣成答案。这极⼤地提⾼了答案的准确性和时效性。
嵌入模型类
在LangChain中,有很多的嵌⼊模型提供⽅,使⽤不同的模型提供⽅,需要安装为其各⾃包OpenAI:pip install -U langchain-openai等等
定义嵌入模型
我选择使用OpenAI来进行操作,定义OpenAIEmbeddings嵌⼊模型类与定义聊天模型类似.
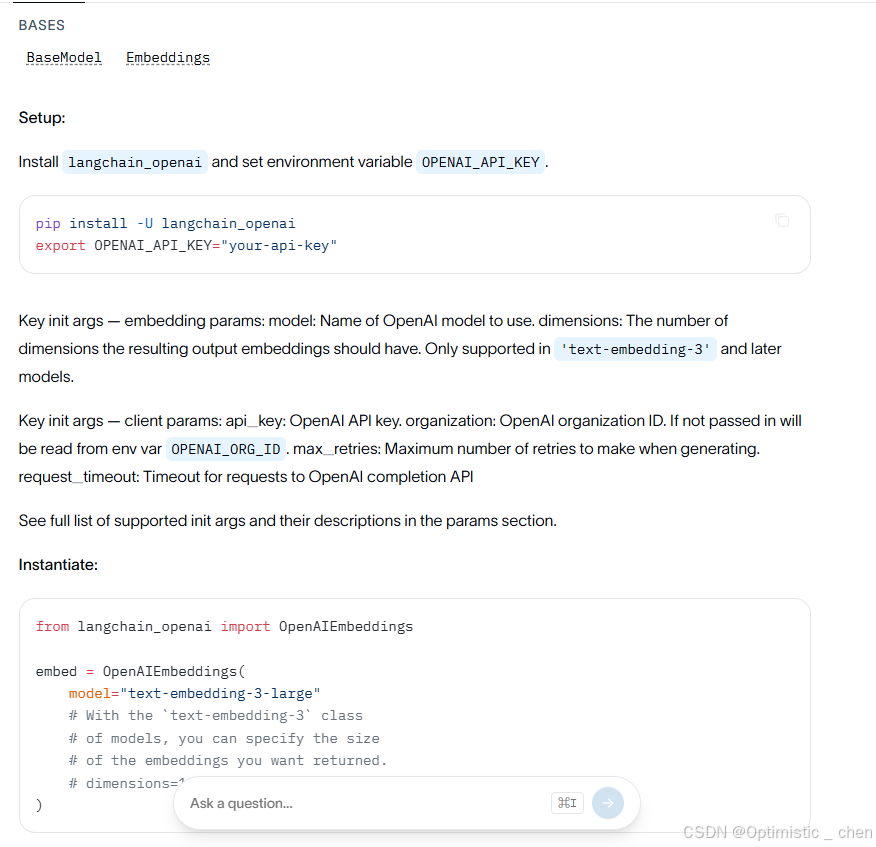
python
from langchain_openai import OpenAiEmbeddings
embeddings=OpenAiEmbeddins(
model="text-embedding-3-large"
)在LangChain框架中基础Embedding类设计了两个核心方法来处理文本嵌入:
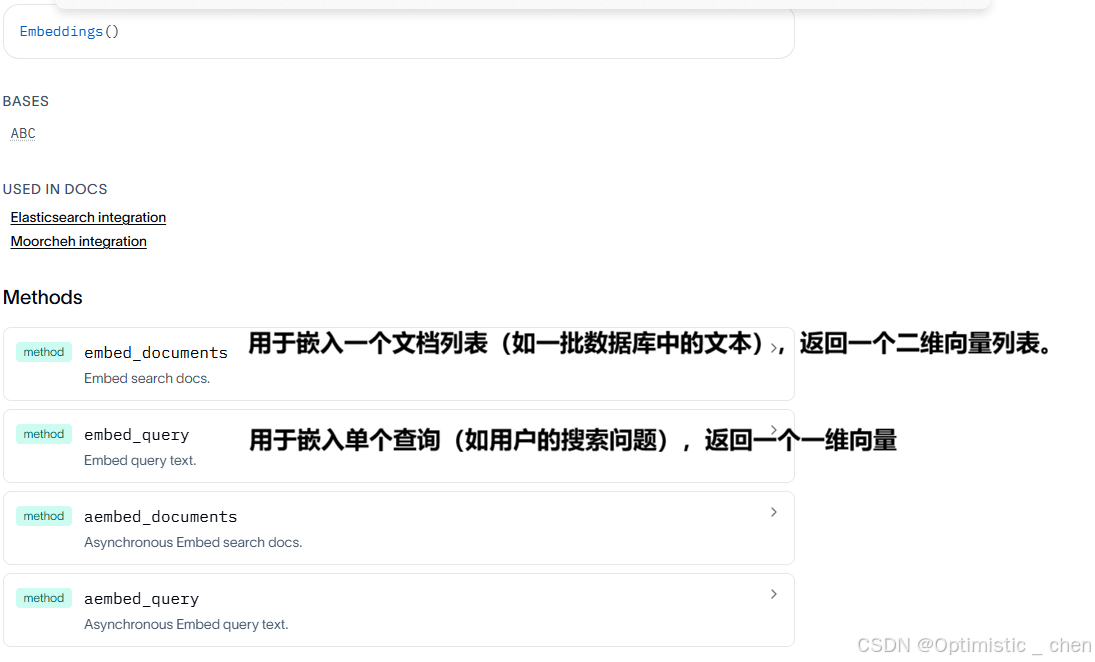
嵌入最常见的应用场景是检索增强生成(RAG):
- 在索引阶段 :使用
embed_documents将知识库中的所有文档片段转化为向量,并存入向量数据库 - 在检索阶段 :当用户提问时,使用
embed_query将问题转化为向量,然后在向量数据库中检索出最相关的文档片段
嵌入文档列表
embed_documents 的语义是"索引",目的是预处理大量文本,为他们创建向量表示,以便后续被搜索。
python
# 导入用于加载 Markdown 文件的加载器(支持表格、标题等非结构化内容)
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 导入 OpenAI 的文本嵌入模型(将文本转为向量)
from langchain_openai import OpenAIEmbeddings
# 导入基于 tiktoken 编码器的文本分割器(按 token 数切分)
from langchain_text_splitters import CharacterTextSplitter
# 指定要处理的 Markdown 文件路径(这里留空,实际需填写有效路径)
markdown_path = ("")
# 创建加载器实例,加载 Markdown 文档
loader = UnstructuredMarkdownLoader(markdown_path)
# 执行加载,返回一个包含 Document 对象的列表(通常只有一个文档)
data = loader.load()
# 创建文本分割器,使用 OpenAI 的 cl100k_base 编码(与 text-embedding-3-large 一致)
# 每个块最大 200 个 token,块之间重叠 50 个 token(保持上下文连贯)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=200,
chunk_overlap=50 # 注意:标准参数名是 chunk_overlap,这里可能写错了
)
# 将加载的文档分割成多个小文档块(每个块包含 200 token 左右的文本)
documents = text_splitter.split_documents(data)
# 初始化 OpenAI 嵌入模型,指定使用 text-embedding-3-large(最新的大模型)
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 提取所有文档块的内容(纯文本)
texts = [doc.page_content for doc in documents]
# 调用 embed_documents 方法,一次性将所有文本块转换为向量(二维列表)
documents_vector = embeddings.embed_documents(texts)代码演示了 使用 LangChain 将一份 Markdown 文档处理成向量嵌入(Embeddings) 的典型流程,主要服务于检索增强生成(RAG)系统的索引阶段。
嵌入单个查询
embed_query的语义是"搜索".目的是在用户发起请求时,实时的将指令转换为向量,用于在已索引的文档向量中进行检索。
python
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 嵌入单个查询
query_vector=embeddings.embed_query("用户提出的指令...")向量存储(向量数据库)
LangChain中,实际并不需要我们直接⼿动调⽤嵌⼊模型去⽣成向量,然后⼿动去⽐较向量。在我们之前提到的RAG博客中,有介绍⼀个VectorStores向量存储。
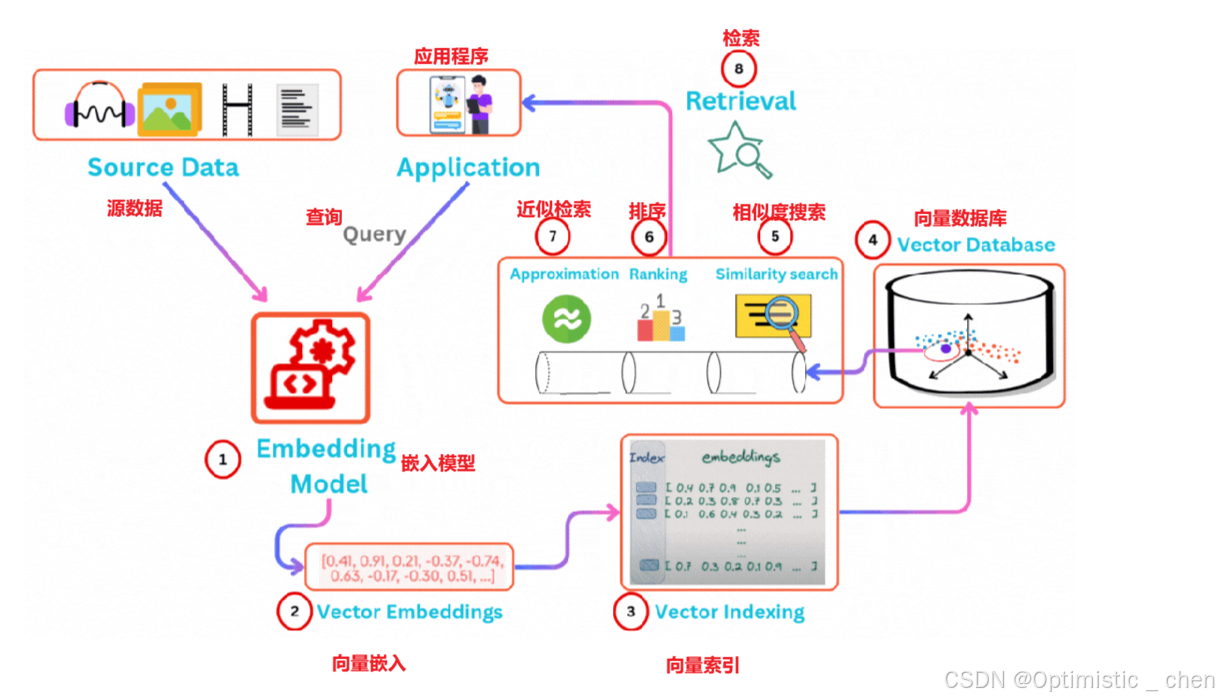
向量是被管理在专⻔的向量存储介质中,如向量数据库,基于内容的相似性搜索。
向量数据库则提供了专⻔⽤于⾼效存储、管理和检索⾼维向量的能⼒。其核⼼就是"⾼效地组织和检索这些数据"
内存存储
内存存储:我们将使⽤LangChain的InMemoryVectorStore来实现向量的内存存储。
初始化:LangChain 中的⼤多数向量在初始化向量存储时接受嵌⼊模型作为参数
python
# 定义嵌入模型
embeddings=OpenAIEmbeddings(model="text-embedding-3-large")
#内存储存初始化
vector_store=InMemoryVecrore(embedding=embeddings)添加文档:使用add_documents方法,向内存存储中添加文档
注意:该⽅法会为添加的⽂档编排索引,索引列表随着该⽅法返回。也就是RAG数据检索的两个步骤:
- 编制索引:从源数据中摄取数据并为其编制索引
- 检索和生成:接收用户查询并从索引中检索相关数据,然后传递给模型
python
#文档分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=200,
chunk_overlap=50
)
#文档加载器
markdown_path = ("")
# 创建加载器实例,加载 Markdown 文档
loader = UnstructuredMarkdownLoader(markdown_path)
# 执行加载,返回一个包含 Document 对象的列表(通常只有一个文档)
data = loader.load()
#分割文档
dcouments=text_splitter.split_documents(data)
#添加文档
ids=vector_store.add_documents(documents=dcouments)获取文档:使用get_by_ids的方法,通过索引列表获取对应的文档列表
python
doc_3=vector_store.get_by_ids(ids[:3])删除文档:使用delete方法,删除传入索引列表对应的文档列表;若不传入索引列表,则认为是全量删除。
python
vector_store.delete(ids=ids[:3])向量搜索
如果我们传入一个查询,向量存储将嵌入该查询,在所有的嵌入文档中执行相似性搜索,并返回最相似的文档。
想要获取根据相似性搜索的结果(即嵌入单个查询),并查找相似文档,并将它们作为文档列表返回,这可以用similarity_search方法实现
python
search_docs=vector_store.similarity_search(query="要查询的内容?",k=2)
for doc in search_docs:
print(doc.page_content)接下来,把搜索出来的文档和用户提出的问题打包发给LLM,这样大大提高了答案的准确性和时效性,这就是当前LLM的核心RAG的基本流程。
元数据过滤:因为每个Document对象都包含了id,page_content(字符串文本),metadata(与内容相关的任意元数据)。整体对象较大,考虑LLM上下文的影响,给搜索方法加入filter参数,表⽰我们可以根据条件选择是否过滤某些⽂档。
Redis向量存储
既然我们能使用内存存储,redis当然也可以用来存储向量。使用Redis来存储向量,需要将环境配置好
- 启动Redis客户端:使用docker启动redis实例
powershell
docker run -d -p 6379:6379 -it redis:latest- 安装Redis客户端包,来定义客户端,以及运行搜索和查询命令
powershell
pip install redis- LangChain中使用Redis向量库,需要安装langchain-redis包
powershell
pip install -U langchian-redis- 定义Redis连接URL ,客户端连接Redis
python
redis_url = "redis://localhost:6379"LangChain 中使⽤RedisVectorStore 初始化Redis 向量存储
python
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
redis_url="redis://192.168.114.23:6379"
config=RedisConfig( # RedisConfig对象
index_name="qa" #Redis中索引的名称
redis_url=redis_url #RedisKey的前缀
metadata_schema=[ #元数据字段的schema
{"name":"category","type":"tag"}
],
)
# redis存储初始化
vector_store=RedisVectorStore(embeddings,config=config)添加文档(add_documents)、获取文档(get_by_ids)、删除文档(delete)、相似性检索(similarity_search)、元数据过滤(filter)等方法和内存存储向量一致。
完结撒花!🎉
如果这篇博客对你有帮助,不妨点个赞支持一下吧!👍
你的鼓励是我创作的最大动力~
✨ 想获取更多干货? 欢迎关注我的专栏 → optimistic_chen
📌 收藏本文,下次需要时不迷路!
我们下期再见!💫 持续更新中......