IOCP完成端口映射详解
如果要在Windows上开发响应时间短、并发量百万级以上的服务器就不得不谈一下IOCP完成端口映射了,IOCP全称为I/O Completion Port,顾名思义从名字上就能看出一些东西,首先IOCP使用系统内核来调度控制,并且大家看到Completion完成这个单词了,这个的意思就是一些东西由系统来处理,处理完后通知给我们,然后我们就可以去获取做进一步的处理。而这与传统的模型相比就省去了不少东西,就比如使用传统的recv去接收数据,传统的recv是在调用的时候才去接收消息,因此这里的接收数据是由程序来完成的,所以其中的所消耗的时间就是由程序来承担了,但是对于IOCP的WSArecv函数来说,他就是通知系统去帮我干这个事,有这个事并且你(系统)干完了你就通知我把数据给我我来进一步的处理,所以与传统的相比就少了去接收数据的时间,而这段时间我们就可以用来再去处理别的事情,这样效率不就提高了,所以总结一下IOCP去传统的网络通信模型的优点有以下几条:
-
无须服务器再去承担系统级操作(send/recv......)所带来的间消耗问题
-
无须服务器在系统间频繁线程切换带来的时间消耗,以及处理慢的问题。如果线程开的非常多,则CPU的时间大半都会浪费在线程切换上(因为这里同一个进程开启的线程大多都是同优先级的)("one-thread-per-client"模型存在的主要问题)
-
在通信的连接、接收和发送上都是异步处理,避免了同步中常见的阻塞问题
"one-thread-per-client"模型架构
不知道大家有没有听说过"one-thread-per-client"每个客户端一个线程这种服务器模型,我们就来说一下这种模型的特点以及存在的问题
"one-thread-per-client"这个模型其实就是大家常说的利用多线程实现高并发的模型,什么意思呢,就是当有一个客户端连接上来了,服务器就给这个客户端开一个线程专门去处理这个客户端来的消息,该模型的示意图如下
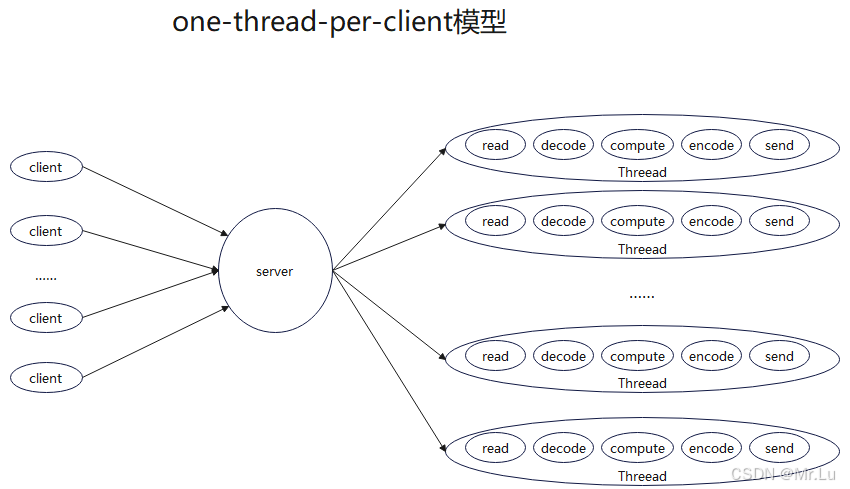
这个模型解决了单线程下处理客户端请求会出现的程序卡死的问题并且这种模式理解起来也是比较容易的并且代码实现也是比较简单的,只要你学过多线程编程这种模式代码的编写应该是不在话下的,但是又带来的更大的问题,就是实时性以及处理速度的问题,如果这种模型是使用在服务器活跃用户数不超过1万的情况下还是没有什么问题的,但是对于哪些服务器在某一时刻的请求数据数达到百万级以上或者每日活跃用户超过10万人次,哪你要是使用这样的模型去开发服务器,哪就等着用户骂娘吧。这种情况下的服务器他不是偶尔有点延时的问题,而是在整个使用的过程中,你会发现这个软件都是非常的慢,进行的操作好久都得不到响应。
其实每个人在使用软件的时候都有一个心理,就比如你在双11秒杀一个东西,当你完成下单请求,你可以迅速给我反映我是买到了还是没买到,买到了我会感到高兴,没买到我会认为是我自己手速的问题,但是如果我买完之后一直卡在哪里也不知道是不是买上了,哪这样用户可能就会口吐芬芳了,他就不会认为买不到是它自己的问题而是你的问题,所以你真正上线的项目如果真是存在这样的问题,哪使用者可能就剩下没办法必须使用的人了。(说到这大家是不是想到了,好像学校选课时的场景......)
为什么这个模型会这么卡呢,那我们就得从系统对线程的调度方式说起了,这样的架构模型可能会开启数以万计的同优先级的线程,就会使得系统都忙着去完成线程切换了,实际线程体的执行时间就会大大减少,在加上线程切换是非常费时间的原因,就会导致大量的客户端请求就会都卡在哪里没有及时的给与客户端反馈,甚至更恶劣的情况就是大家都卡在哪里谁也动弹不得,服务器看起来就像死了一样,但实际上服务在哪里玩命的处理数以千计请求,但是每个都没处理完,这就是"one-thread-per-client"存在的巨大的问题,Windows也意识到了这种问题,所以就在系统级设计和提出了IOCP完成端口架构模型,IOCP模型充分利用对象的调度,只使用少量的几个线程来处理和客户端的所有通信,消除了无谓的线程切换,最大限度提高了网络通信的性能。
下面我们先来介绍一下编写IOCP所用到的API接口,然后再来给出整个IOCP架构的流程最后我会给出一个通过IOCP实现的代码
API接口
注意,我们这里默认认为大家都有网络编程的经验,所以这里只介绍IOCP相关的API函数
更详细的说明大家可以去MSDN上查看:https://learn.microsoft.com/
CreateIoCompletionPort()
该函数的功能是创建IOCP句柄,并可用于将SOCKET和已存在的IOCP句柄进行绑定
函数声明
HANDLE CreateIoCompletionPort(
_In_ HANDLE FileHandle,
_In_opt_ HANDLE ExistingCompletionPort,
_In_ ULONG_PTR CompletionKey,
_In_ DWORD NumberOfConcurrentThreads
);
// FileHandle 要绑定到IOCP上的句柄(该参数用于已创建好的IOCP句柄中)
// ExistingCompletionPort 表示已经存在的IOCP句柄
// CompletionKey 该参数用于绑定时,当被绑定的句柄有事件触发时,在IOCP消息队列中就会带上绑定时设置的这个参数的值
// NumberOfConcurrentThreads 该参数表示使用IOCP的线程数
// 返回值 如果创建或绑定成功,则返回对应的句柄;如果创建失败则返回NULL这里的FileHandle是指示让IOCP去监听的文件句柄,这里的句柄可以是套接字或者其它的
ExistingCompletionPort()前面的这两个参数主要是用在创建好IOCP句柄后,向句柄上绑定句柄操作所用的,所以创建IOCP时可以将这两个参数填为NULL
PostQueuedCompletionStatus()
该函数的功能是向IOCP消息队列中投递一条消息
函数声明
BOOL PostQueuedCompletionStatus(
_In_ HANDLE CompletionPort,
_In_ DWORD dwNumberOfBytesTransferred,
_In_ ULONG_PTR dwCompletionKey,
_In_opt_ LPOVERLAPPED lpOverlapped
);
// CompletionPort 创建好的IOCP的句柄
// dwNumberOfBytesTransferred 要投递数据所占的字节数
// dwCompletionKey 要投递的数据的指针
// lpOverlapped 要传递的重叠结构的指针
// 返回值 如果投递成功,则返回值为TRUE;返回值为FALSE则表示投递失败,详情可以通过GetLastError()获取GetQueuedCompletionStatus()
该函数的功能是从IOCP消息队列中获取一条消息
函数声明
BOOL GetQueuedCompletionStatus(
_In_ HANDLE CompletionPort,
_Out_ LPDWORD lpNumberOfBytesTransferred,
_Out_ PULONG_PTR lpCompletionKey,
_Out_ LPOVERLAPPED* lpOverlapped,
_In_ DWORD dwMilliseconds
);
// CompletionPort 创建好的IOCP的句柄
// lpNumberOfBytesTransferred 用于保存接受到的数据字节数的变量指针
// lpCompletionKey 消息数据指针,可以是由CreateIoCompletionPort()绑定的句柄或者PostQueuedCompletionStatus()投递的消息中而来
// lpOverlapped 重叠结构指针,可以接收套接字或者PostQueuedCompletionStatus设置的重叠结构
// dwMilliseconds 等待的时间,单位毫秒。-1(INFINITE)表示无限等待
// 返回值 如果成功,则返回值为TRUE,如果发生错误,则返回值为FALSE详情可以通过GetLastError()获取触发GetQueuedCompletionStatus()这个函数可以是通过PostQueuedCompletionStatus()函数投递的消息,也可以是绑定到IOCP句柄上的文件描述符触发的消息
AcceptEx()
该函数的功能是在套接字上设置非阻塞连接请求,当有客户端连接上时则会通知我们的IOCP服务器
函数声明
BOOL AcceptEx (
_In_ SOCKET sListenSocket,
_In_ SOCKET sAcceptSocket,
_Out_writes_bytes_to_(dwReceiveDataLength+dwLocalAddressLength+dwRemoteAddressLength,
*lpdwBytesReceived) PVOID lpOutputBuffer,
_In_ DWORD dwReceiveDataLength,
_In_ DWORD dwLocalAddressLength,
_In_ DWORD dwRemoteAddressLength,
_Out_ LPDWORD lpdwBytesReceived,
_Inout_ LPOVERLAPPED lpOverlapped
);
// sListenSocket 标识服务器的套接字(已绑定端口和监听的套接字)
// sAcceptSocket 标识接受连接的套接字的描述符
// lpOutputBuffer 指向缓冲区的指针,用于接收来自该套接字上的第一个数据块以及服务器本地地址和客户端远程地址
// dwReceiveDataLength 用于指定lpOutputBuffer缓冲区上接收数据的实际大小字节数,不应包含本地地址和远程地址所占字节部分。如果该参数为0,则表示不等待第一个数据块来在连接完成,而是立即完成
// dwLocalAddressLength 本地地址信息保留的字节数,必须为保存地址结构体(sockaddr_in)所占的字节数+16
// dwRemoteAddressLength 远程地址信息保留的字节数,必须为保存地址结构体(sockaddr_in)所占的字节数+16
// lpdwBytesReceived 指向一个用来保存所接收数据的字节数,可以理解为是缓冲区的索引
// lpOverlapped 指向重叠结构的指针,当套接字绑定到IOCP上并有事件触发时,就会传递到GetQueuedCompletionStatus函数中
// 返回值 返回TRUE则表示未发生错误,返回FALSE时,则返回发生错误详情可以通过WSAGetLastError()获取通常与之配合使用的还有GetAcceptExSockaddrs()函数,该函数可以从AcceptEx函数设置的缓冲区中提取出连接上来的套接字的本地地址和远程地址
WSARecv()
该函数的功能是通知IOCP帮我监听指定套接字上的消息,如果指定套接字上有数据发过来,则你帮我完成接收,并通知我处理这个数据
如果不使用该函数的非阻塞机制(也就是不使用重叠结构),则该函数的功能和recv()函数是一样的
函数声明
int WSARecv(
_In_ SOCKET s,
_In_reads_(dwBufferCount) __out_data_source(NETWORK) LPWSABUF lpBuffers,
_In_ DWORD dwBufferCount,
_Out_opt_ LPDWORD lpNumberOfBytesRecvd,
_Inout_ LPDWORD lpFlags,
_Inout_opt_ LPWSAOVERLAPPED lpOverlapped,
_In_opt_ LPWSAOVERLAPPED_COMPLETION_ROUTINE lpCompletionRoutine
);
// s 等待接收数据的套接字描述符
// lpBuffers 指向WSABUF结构数组的指针
// dwBufferCount 数组中WSABUF结构的个数
// lpNumberOfBytesRecvd 如果接收操作立即完成,指向此调用接收的数据数的指针
// lpFlags 指向用于修改WSARecv函数调用行为的标志指针,初始值为0
// lpOverlapped 指向重叠结构的指针。对于非重叠结构套接字忽略该参数(置NULL)
// lpCompletionRoutine 指向完成接收操作时调用的完成例程的指针 如果该参数不为NULL,则当接收数据完成时,则会调用这个例程函数让用户对数据进行处理;该参数为NULL时,当接收数据完成时,则会触发事件,就可以通过IOCP捕获到进行处理
// 返回值 返回值为0,则表示未发生错误;否则则表示可能发生错误,详情可以通过WSAGetLastError()获取这个函数并不是真正意义上的接收数据,而是去告诉内核帮我去从网卡上如果这个数据来了并且数据过来全了,通知我IOCP,这时IOCP的获取事件就可以捕获到,这时通知到我们,我们再去使用recv就可以接收到数据
WSASend()
该函数的功能是在已连接的套接字上进行数据发送,该函数为非阻塞方式,调用之后会立即返回
如果不使用该函数的非阻塞机制(也就是不使用重叠结构),则该函数的功能和send()函数是一样的
函数声明
int WSASend(
_In_ SOCKET s,
_In_reads_(dwBufferCount) LPWSABUF lpBuffers,
_In_ DWORD dwBufferCount,
_Out_opt_ LPDWORD lpNumberOfBytesSent,
_In_ DWORD dwFlags,
_Inout_opt_ LPWSAOVERLAPPED lpOverlapped,
_In_opt_ LPWSAOVERLAPPED_COMPLETION_ROUTINE lpCompletionRoutine
);
// s 表示连接的套接字描述符
// lpBuffers 指向WSABUF结构数组的指针
// dwBufferCount 数组中WSABUF结构的个数
// lpNumberOfBytesSent 如果I/O操作立即完成,则指向此调用发生的数字的指针
// lpFlags 指向用于修改WSASend函数调用行为的标志指针
// lpOverlapped 指向重叠结构的指针。对于非重叠结构套接字忽略该参数(置NULL)
// lpCompletionRoutine 指向完成发生操作时调用的完成例程的指针
// 返回值 返回值为0,则表示未发生错误;否则则表示可能发生错误,详情可以通过WSAGetLastError()获取IOCP例程代码及性能测试
下面我们就要开始写简单的IOCP代码以及对IOCP进行性能测试,在进行这些之前我们下说一下多线程数据同步方面的知识
多线程数据同步
1、 互斥进制
缺点:依赖开发人员编程规范
会形成线程阻塞,导致效率降低,违背开多线程的意义(实际意义开多线程是为了可以更快的处理业务或命令)
2、 消息
缺点:传输的数据量有限,对于大数据的传输不方便
用现象进行传输,会把数据存放在消息队列中,这里面存放了整个程序的所有消息,所以效率是受限于消息循环的,并且传输数据受限与消息发送的规则
消息在并发处理上是存在问题的,因为消息的处理通常是一个一个处理,一个消息处理完才可以处理下一个消息
3、 网络
好处:传输速度不慢,可以传输较大的数据
一个东西可以服务多个请求(一个服务器服务多个客户端)
网络在不同系统里面存在现成的高并发处理模型(Windows:IOCP Linux:Epoll)
IOCP例程代码
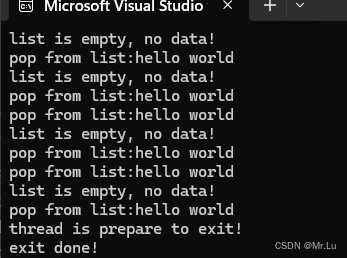
代码说明:使用IOCP每隔1.3秒从list容器中POP一个元素,每个2秒向list容器中push一个元素
enum {
IOCP_CLOSE = 0,
IOCP_LIST_PUSH = 1,
IOCP_LIST_POP,
IOCP_LIST_EMPTY
};
void func(void* arg) {
if (arg == NULL) {
printf("list is empty, no data!\r\n");
return;
}
std::string* pstr = (std::string*)arg;
printf("pop from list:%s\r\n", pstr->c_str());
delete pstr;
}
typedef struct IOCPParam {
IOCPParam(int op, const char* data = NULL, _beginthread_proc_type cb = NULL) {
nOperator = op;
if (data)
strData = data;
cbFunc = cb;
}
IOCPParam() {
nOperator = -1;
cbFunc = NULL;
}
int nOperator; // 操作
std::string strData; // 数据
_beginthread_proc_type cbFunc; // 回调
}IOCPPARAM;
void threadmain(void* arg)
{
std::list<std::string> lstString;
HANDLE hIocp = arg;
DWORD dwTransferred = 0;
ULONG_PTR CompletionKey = 0;
OVERLAPPED* pOverlapped = NULL;
while (GetQueuedCompletionStatus(hIocp, &dwTransferred, &CompletionKey,
&pOverlapped, INFINITE)) {
if (dwTransferred == 0 || (CompletionKey == NULL)) {
printf("thread is prepare to exit!\r\n");
break;
}
IOCPPARAM* pParam = (IOCPPARAM*)CompletionKey;
switch (pParam->nOperator)
{
case IOCP_LIST_PUSH:
lstString.emplace_back(pParam->strData);
break;
case IOCP_LIST_POP: {
std::string* pStr = NULL;
if (lstString.size() > 0) {
pStr = new std::string(lstString.front());
lstString.pop_front();
}
if (pParam->cbFunc) {
pParam->cbFunc(pStr);
}
else if (pStr) {
delete pStr;
}
break;
}
case IOCP_LIST_EMPTY:
lstString.clear();
break;
}
delete pParam;
}
lstString.clear(); //
}
void threadQueueEntry(void* arg)
{
threadmain(arg);
_endthread(); // 会导致内存泄露 ,因为代码到此为止会导致本地对象无法自动析构导致内存泄露
}
// 完成端口测试代码
void IocpTestCode()
{
// 完成端口核心设计理念是把请求与实现分离
// Input/Output Completion Port IO完成端口
HANDLE hIOCP = INVALID_HANDLE_VALUE;
hIOCP = CreateIoCompletionPort(INVALID_HANDLE_VALUE,
NULL, NULL, 1);
if (hIOCP == NULL) {
return;
}
HANDLE hThred = (HANDLE)_beginthread(threadQueueEntry, 0, hIOCP);
ULONGLONG tick = GetTickCount64();
ULONGLONG tick0 = GetTickCount64();
while (_kbhit() == 0) {
if (GetTickCount64() - tick0 > 1300) {
PostQueuedCompletionStatus(hIOCP, sizeof(IOCPPARAM), (ULONG_PTR)new IOCPPARAM(IOCP_LIST_POP, NULL, func), NULL);
tick0 = GetTickCount64();
}
if (GetTickCount64() - tick > 2000) {
PostQueuedCompletionStatus(hIOCP, sizeof(IOCPPARAM), (ULONG_PTR)new IOCPPARAM(IOCP_LIST_PUSH, "hello world"), NULL);
tick = GetTickCount64();
}
Sleep(1);
}
if (hIOCP != NULL) {
// TODO:唤醒完成端口
PostQueuedCompletionStatus(hIOCP, 0, NULL, NULL);
WaitForSingleObject(hThred, INFINITE);
}
CloseHandle(hIOCP);
printf("exit done!\r\n");
return;
}运行结果:
IOCP性能测试代码
代码说明:这里使用IOCP和互斥体分别实现了两个线程安全的队列,并对其进行1秒的输入输出性能测试
// 线程安全的队列(利用IOCP实现)
template<class T>
class CQueue
{
public:
enum {
EQNone,
//写
EQPush,
//读
EQPop,
//大小
EQSize,
//清空
EQClear
};
typedef struct IocpParam {
size_t nOperator;//操作(插入/删除)
T Data;//数据
HANDLE hEvent; //pop操作需要的
IocpParam(int op, const T& data, HANDLE hEve = NULL) {
nOperator = op;
Data = data;
hEvent = hEve;
}
IocpParam() {
nOperator = EQNone;
hEvent = INVALID_HANDLE_VALUE;
}
}PPARAM; //Post Parameter 用于投递信息的结构体
public:
CQueue() {
m_lock = false;
m_hCompletionPort = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, NULL, 1/*epoll的区别点1*/); //创建IOCP
m_hThread = INVALID_HANDLE_VALUE;
if (m_hCompletionPort != NULL) {
m_hThread = (HANDLE)_beginthread(&CQueue<T>::threadEntry, 0, this);
}
}
virtual ~CQueue() {//虚析构函数
if (m_lock)return;
m_lock = true;
PostQueuedCompletionStatus(m_hCompletionPort, 0, NULL, NULL);
WaitForSingleObject(m_hThread, INFINITE);
if (m_hCompletionPort != NULL) {
HANDLE hTemp = m_hCompletionPort;
m_hCompletionPort = NULL;
CloseHandle(hTemp);
}
//CloseHandle(m_hThread);
}
bool PushBack(const T& data) {
IocpParam* pParam = new IocpParam(EQPush, data);
if (m_lock) {
if (pParam)delete pParam;
return false;
}
bool ret = PostQueuedCompletionStatus(m_hCompletionPort, sizeof(PPARAM), (ULONG_PTR)pParam, NULL);
if (ret == false)delete pParam;
return ret;
}
virtual bool PopFront(T& data) {
HANDLE hEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
if (hEvent == NULL)return false;
IocpParam Param(EQPop, data, hEvent);
if (m_lock) {
if (hEvent)CloseHandle(hEvent);
return false;
}
bool ret = PostQueuedCompletionStatus(m_hCompletionPort, sizeof(Param), (ULONG_PTR)&Param, NULL);
if (ret == false) {
CloseHandle(hEvent);
return ret;
}
ret = WaitForSingleObject(hEvent, INFINITE) == WAIT_OBJECT_0;
if (ret) {
data = Param.Data;
}
CloseHandle(hEvent);
return ret;
}
size_t Size() {
HANDLE hEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
if (hEvent == NULL)return -1;
IocpParam Param(EQSize, T(), hEvent);
if (m_lock) {
if (hEvent)CloseHandle(hEvent);
return -1;
}
bool ret = PostQueuedCompletionStatus(m_hCompletionPort, sizeof(Param), (ULONG_PTR)&Param, NULL);
if (ret == false) {
CloseHandle(hEvent);
return -1;
}
ret = WaitForSingleObject(hEvent, INFINITE) == WAIT_OBJECT_0;
if (ret) {
return Param.nOperator;
}
CloseHandle(hEvent);
return -1;
}
bool Clear() {
IocpParam* pParam = new IocpParam(EQClear, T());
if (m_lock) {
if (pParam)delete pParam;
return false;
}
bool ret = PostQueuedCompletionStatus(m_hCompletionPort, sizeof(PPARAM), (ULONG_PTR)pParam, NULL);
if (ret == false)delete pParam;
return ret;
}
protected:
//某个命令的处理函数
virtual void DealParam(PPARAM* pParam) {
switch (pParam->nOperator)
{
case EQPush: {
m_lstData.push_back(pParam->Data);
delete pParam;
break;
}
case EQPop: {
if (m_lstData.size() > 0) {
pParam->Data = m_lstData.front();
m_lstData.pop_front();
}
if (pParam->hEvent != NULL)
SetEvent(pParam->hEvent);
break;
}
case EQSize: {
pParam->nOperator = m_lstData.size();
if (pParam->hEvent != NULL)
SetEvent(pParam->hEvent);
break;
}
case EQClear: {
m_lstData.clear();
delete pParam;
break;
}
default:
OutputDebugStringA("unknown operator!\r\n");
break;
}
}
static void threadEntry(void* arg) {
CQueue<T>* thiz = (CQueue<T>*)arg;
thiz->threadMain();
_endthread();
}
virtual void threadMain() {
DWORD dwTransferred = 0;
ULONG_PTR CompletionKey = 0;
OVERLAPPED* pOverlapped = NULL;
PPARAM* pParam = NULL;
while (GetQueuedCompletionStatus(m_hCompletionPort, &dwTransferred, &CompletionKey, &pOverlapped, INFINITE)) {
if ((dwTransferred == 0) || (CompletionKey == NULL)) {
printf("thread is prepare to exit!\r\n");
break;
}
pParam = (PPARAM*)CompletionKey;
DealParam(pParam);
}
while (GetQueuedCompletionStatus(m_hCompletionPort, &dwTransferred, &CompletionKey, &pOverlapped, 0)) {
if ((dwTransferred == 0) || (CompletionKey == NULL)) {
printf("thread is prepare to exit!\r\n");
continue;
}
pParam = (PPARAM*)CompletionKey;
DealParam(pParam);
}
m_lstData.clear();
CloseHandle(m_hCompletionPort);
m_hCompletionPort = NULL;
}
protected:
std::list<T> m_lstData;
HANDLE m_hCompletionPort;
HANDLE m_hThread;
std::atomic<bool> m_lock; //队列正在析构
};
// 线程安全的队列(利用互斥体实现)
template<class T>
class CMutexQueue
{
public:
CMutexQueue() {}
virtual ~CMutexQueue() {//虚析构函数
Clear();
}
bool PushBack(const T& data) {
{
std::unique_lock<std::mutex> lock(m_lock);
m_lstData.push_back(data);
}
return true;
}
virtual bool PopFront(T& data) {
{
std::unique_lock<std::mutex> lock(m_lock);
if (m_lstData.size() > 0) {
data = m_lstData.front();
m_lstData.pop_front();
}
}
return true;
}
size_t Size() {
size_t ret = 0;
{
std::unique_lock<std::mutex> lock(m_lock);
ret = m_lstData.size();
}
return ret;
}
bool Clear() {
{
std::unique_lock<std::mutex> lock(m_lock);
m_lstData.clear();
}
return true;
}
protected:
std::list<T> m_lstData;
std::mutex m_lock;
};
// 测试代码
template<typename T>
void QueueWriteTest(T* pQueue)
{
ULONGLONG total = GetTickCount64();
while (GetTickCount64() - total <= 1000) {
pQueue->PushBack("hello world");
}
}
template<typename T>
void QueueReadTest(T* pQueue)
{
ULONGLONG total = GetTickCount64();
std::string str;
while (GetTickCount64() - total <= 1000) {
pQueue->PopFront(str);
}
}
// 测试每秒中读速度
template<typename T>
void testWriteEntry(void* arg)
{
QueueWriteTest<T>((T*)arg);
_endthread();
}
// 测试每秒中读速度
template<typename T>
void testReadEntry(void* arg)
{
QueueReadTest<T>((T*)arg);
_endthread();
}
// IOCP写入和读出平均速度
static long long IOCPWriteTotalAVG = 0, IOCPReadTotalAVG = 0;
// mutex写入和读出平均速度
static long long MutexWriteTotalAVG = 0, MutexReadTotalAVG = 0;
// IOCP和互斥锁安全队列性能测试
void test()
{
// std::cout << "============IOCP=================\n";
CQueue<std::string> queStrings;
HANDLE hThreads[4] = {};
for (int i = 0; i < 4; i++) {
hThreads[i] = (HANDLE)_beginthread(testWriteEntry<CQueue<std::string>>, 0, &queStrings);
}
for (int i = 0; i < 4; i++) {
WaitForSingleObject(hThreads[i], INFINITE);
}
size_t count = queStrings.Size();
IOCPWriteTotalAVG += count;
printf("[IOCP]:write size:%d\r\n", count);
// printf("write total size:%d\r\n", count);
for (int i = 0; i < 4; i++) {
hThreads[i] = (HANDLE)_beginthread(testReadEntry<CQueue<std::string>>, 0, &queStrings);
}
for (int i = 0; i < 4; i++) {
WaitForSingleObject(hThreads[i], INFINITE);
}
size_t count1 = count - queStrings.Size();
IOCPReadTotalAVG += count1;
printf("[IOCP]:read size:%d\r\n", count1);
// printf("read total size:%d\r\n", count - queStrings.Size());
queStrings.Clear();
// std::cout << "============mutex=================\n";
CMutexQueue<std::string> MQueStrings;
for (int i = 0; i < 4; i++) {
hThreads[i] = (HANDLE)_beginthread(testWriteEntry<CMutexQueue<std::string>>, 0, &MQueStrings);
}
for (int i = 0; i < 4; i++) {
WaitForSingleObject(hThreads[i], INFINITE);
}
count = MQueStrings.Size();
MutexWriteTotalAVG += count;
printf("[LOCK]:write size:%d\r\n", count);
// printf("write total size:%d\r\n", count);
for (int i = 0; i < 4; i++) {
hThreads[i] = (HANDLE)_beginthread(testReadEntry<CMutexQueue<std::string>>, 0, &MQueStrings);
}
for (int i = 0; i < 4; i++) {
WaitForSingleObject(hThreads[i], INFINITE);
}
count1 = count - MQueStrings.Size();
MutexReadTotalAVG += count1;
printf("[LOCK]:read size:%d\r\n", count1);
// printf("read total size:%d\r\n", count - MQueStrings.Size());
MQueStrings.Clear();
// 单线程,不加任何处理
/*
// 多线程环境测试数据无效
std::list<std::string> lstData;
ULONGLONG total = GetTickCount64();
while (GetTickCount64() - total <= 1000) {
lstData.emplace_back("hello world");
}
printf("lstData size=%d\r\n", lstData.size());
total = GetTickCount64();
while (GetTickCount64() - total <= 1000) {
if (lstData.size() > 0)
lstData.pop_front();
}
printf("lstData size=%d\r\n", lstData.size());
*/
}
int main()
{
for (int i = 0; i < 10; i++) {
test();
}
printf("IOCP线程安全队列,平均写入速度为%lld次/s 平均读取速度为%lld次/s\r\n", IOCPWriteTotalAVG / 10, IOCPReadTotalAVG / 10);
printf("Mutex线程安全队列,平均写入速度为%lld次/s 平均读取速度为%lld次/s\r\n", MutexWriteTotalAVG / 10, MutexReadTotalAVG / 10);
return 0;
}运行结果:
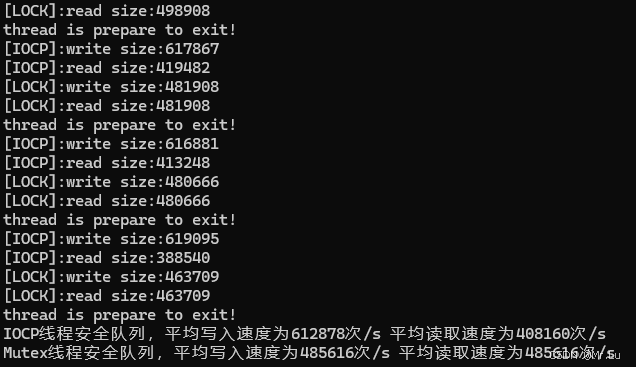
结论:
CQueue push性能高 pop性能仅1/4 CMutexQueue push性能比pop低 pop性能高,因为这里一秒内写入多少个元素,都能给他读出来
到这里关于IOCP使用的简单介绍就结束了
感谢观看学习,大佬们多多指点,愿明天的自己会感谢当下的努力!!!!
参考文献
- 完成端口(CompletionPort)详解 - 手把手教你玩转网络编程系列之三. PiggyXP. https://blog.csdn.net/PiggyXP/article/details/6922277