Python进阶之-深拷贝与浅拷贝
写在前面:很多刚接触Python的小白在处理列表、字典等数据时,经常会遇到一个灵异事件:我明明只改了A列表,怎么B列表也跟着变了?! 其实,这都是Python的"赋值"、"浅拷贝"和"深拷贝"在捣鬼。今天我们就用大白话把这哥仨掰扯得明明白白!
作为Python进阶的必学知识点,深拷贝与浅拷贝直接关系到数据操作的安全性,也是面试中的高频考点。本文将从底层引用原理出发,结合可运行代码示例,带你彻底搞懂二者的差异、运行逻辑与适用场景。
文章目录
- Python进阶之-深拷贝与浅拷贝
-
- 一、核心前置知识
-
- [1.1 可变类型 vs 不可变类型](#1.1 可变类型 vs 不可变类型)
- [1.2 Python赋值的本质:引用传递](#1.2 Python赋值的本质:引用传递)
- 二、浅拷贝:只拷贝最外层
-
- [2.1 可变类型的浅拷贝](#2.1 可变类型的浅拷贝)
- [2.2 不可变类型的浅拷贝](#2.2 不可变类型的浅拷贝)
- 三、深拷贝:递归全层级拷贝
-
- [3.1 可变类型的深拷贝](#3.1 可变类型的深拷贝)
- [3.2 不可变类型的深拷贝](#3.2 不可变类型的深拷贝)
- 四、一张表总结三者核心区别
- 五、进阶话题
-
- [5.1 混合类型:嵌套中包含不可变类型](#5.1 混合类型:嵌套中包含不可变类型)
- [5.2 自定义对象的拷贝](#5.2 自定义对象的拷贝)
- [5.3 循环引用的处理](#5.3 循环引用的处理)
- [5.4 性能考量](#5.4 性能考量)
- [5.5 一键验证模板](#5.5 一键验证模板)
- 六、实战场景与避坑指南
-
- [6.1 适用场景](#6.1 适用场景)
- [6.2 常见避坑提醒](#6.2 常见避坑提醒)
- 结语
一、核心前置知识
在讲解拷贝之前,我们先理清两个必备的前置知识,这是理解深浅拷贝的前提。
1.1 可变类型 vs 不可变类型
Python中数据类型分为两类,划分依据是:在内存地址不变的前提下,对象的内容能否被修改。
- 可变类型:列表、字典、集合。内存地址不变时,内部元素可以修改。
- 不可变类型:整型、浮点型、字符串、布尔型、元组。内容一旦创建就无法修改,修改时会生成新的内存对象。
总结:
深浅拷贝的区别就是:拷贝的层级多与少。深拷贝拷贝的多,浅拷贝拷贝的少。它们一般都用来操作可变类型。
在Python中,深浅拷贝需要借用 copy 模块:
浅拷贝:copy.copy()
深拷贝:copy.deepcopy()
python
# 不可变类型:修改即生成新对象
a = 10
print(f"id(a) -> {id(a)}") # 初始地址
a = 20
print(f"id(a) -> {id(a)}") # 地址改变,生成了新对象
# 可变类型:修改不改变地址
list1 = [11, 22, 33]
print(f"id(list1) -> {id(list1)}") # 初始地址
list1[1] = 200
print(f"id(list1) -> {id(list1)}") # 地址不变,内容已修改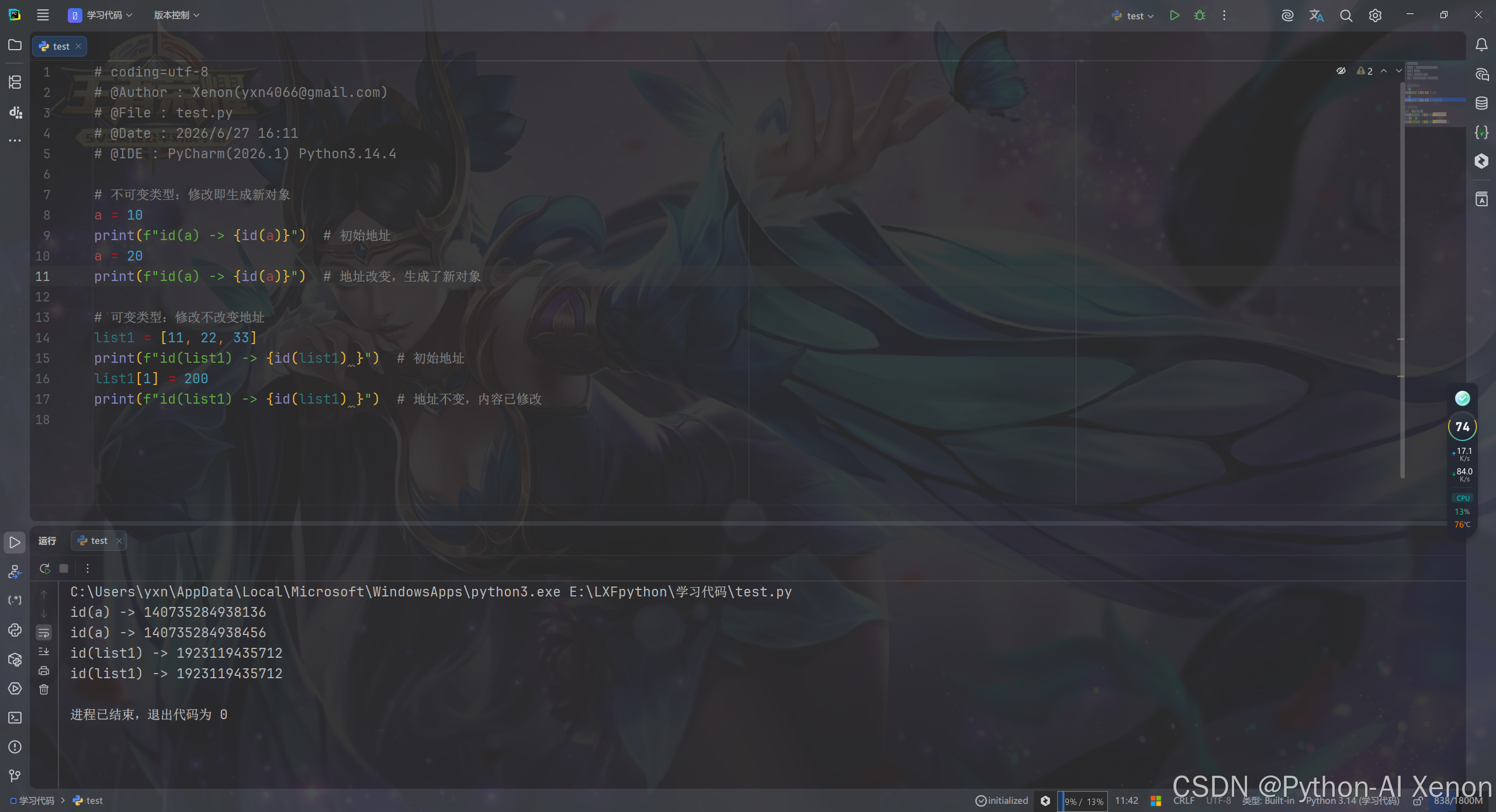
1.2 Python赋值的本质:引用传递
Python中的=赋值,本质上不是"复制值",而是传递内存地址。赋值操作只是给同一块内存多起了一个别名,并不会创建新的独立对象。
python
# python的赋值操作属于引用赋值(eg:b是a的别名, 形参是实参的别名)
def dm01_普通赋值():
# 1. python中的赋值操作, 属于引用赋值 (把a的地址赋值给b)
# 2. b是a的别名, b和a都指向相同的内存空间
a = 10
b = a
print('id(a)-->', id(a)) # 这三个输出的地址是一模一样的!
print('id(b)-->', id(b))
print('id(10)-->', id(10))
print('-' * 31)
# 3. 同理,列表的嵌套赋值也是引用赋值,c和d指向相同的内存空间
a = [1, 2, 3]
b = [11, 22, 33]
c = [a, b]
d = c
print('id(c)-->', id(c)) # 这两个输出的地址也是一样的!
print('id(d)-->', id(d))
dm01_普通赋值()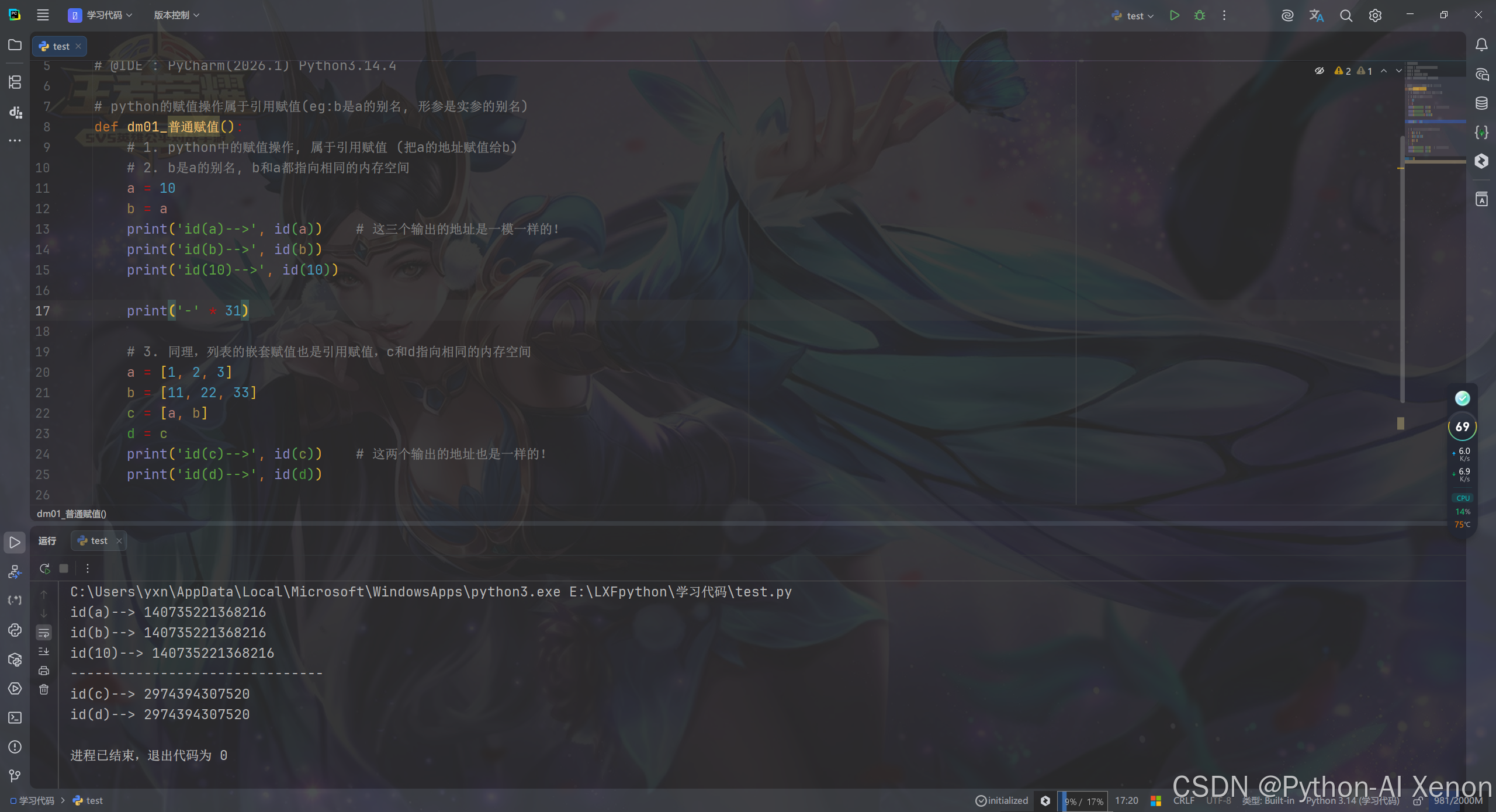
也正因为如此,对于可变类型,通过一个别名修改内容,另一个别名访问到的数据也会同步变化------这就是我们需要"拷贝"的原因。
小白理解:张三有个外号叫"三哥"。你打了张三一巴掌,"三哥"也会觉得疼,因为他们本来就是同一个人。普通赋值就是这样。
二、浅拷贝:只拷贝最外层
浅拷贝会创建一个新的对象,但是对于对象内部的元素,只是拷贝了它们的引用(地址)。
浅拷贝对应copy模块中的copy.copy()函数,核心规则可以概括为:只拷贝对象的最外层容器,内层元素依然共享内存引用。
2.1 可变类型的浅拷贝
对于嵌套的可变结构(比如列表里嵌套列表),浅拷贝只会重新创建最外层的容器,内层的子对象依然和原对象共用同一块内存。
python
import copy
# 需求1: 浅拷贝可变类型: 只拷贝第1层数据, 深层次数据不拷贝
def dm02_浅拷贝可变类型():
a = [1, 2, 3]
b = [11, 22, 33]
c = [6, 7, a, b]
# 测试1: 外层地址
d = copy.copy(c)
print('id(c)-->', id(c))
print('id(d)-->', id(d))
print("结论: id(c)和id(d)值不一样, 说明浅拷贝把【第1层(最外面一层)】拷贝了一份新的。")
print('-' * 31)
# 测试2: 内层地址
print(id(c[2])) # c[2] 就是 a
print(id(a))
print("结论: id(c[2])和id(a)值一样, 说明浅拷贝【第2层的数据】并没有拷贝,还是共享的!")
print('-' * 31)
# 测试3: 修改内层数据看效果
a[2] = 22
print('c->', c) # [6, 7, [1, 2, 22], [11, 22, 33]]
print('d->', d) # [6, 7, [1, 2, 22], [11, 22, 33]]
# 结论:因为a变了,而c和d里面的第二层都指向a,所以c和d都变了!这就是浅拷贝的坑!
dm02_浅拷贝可变类型()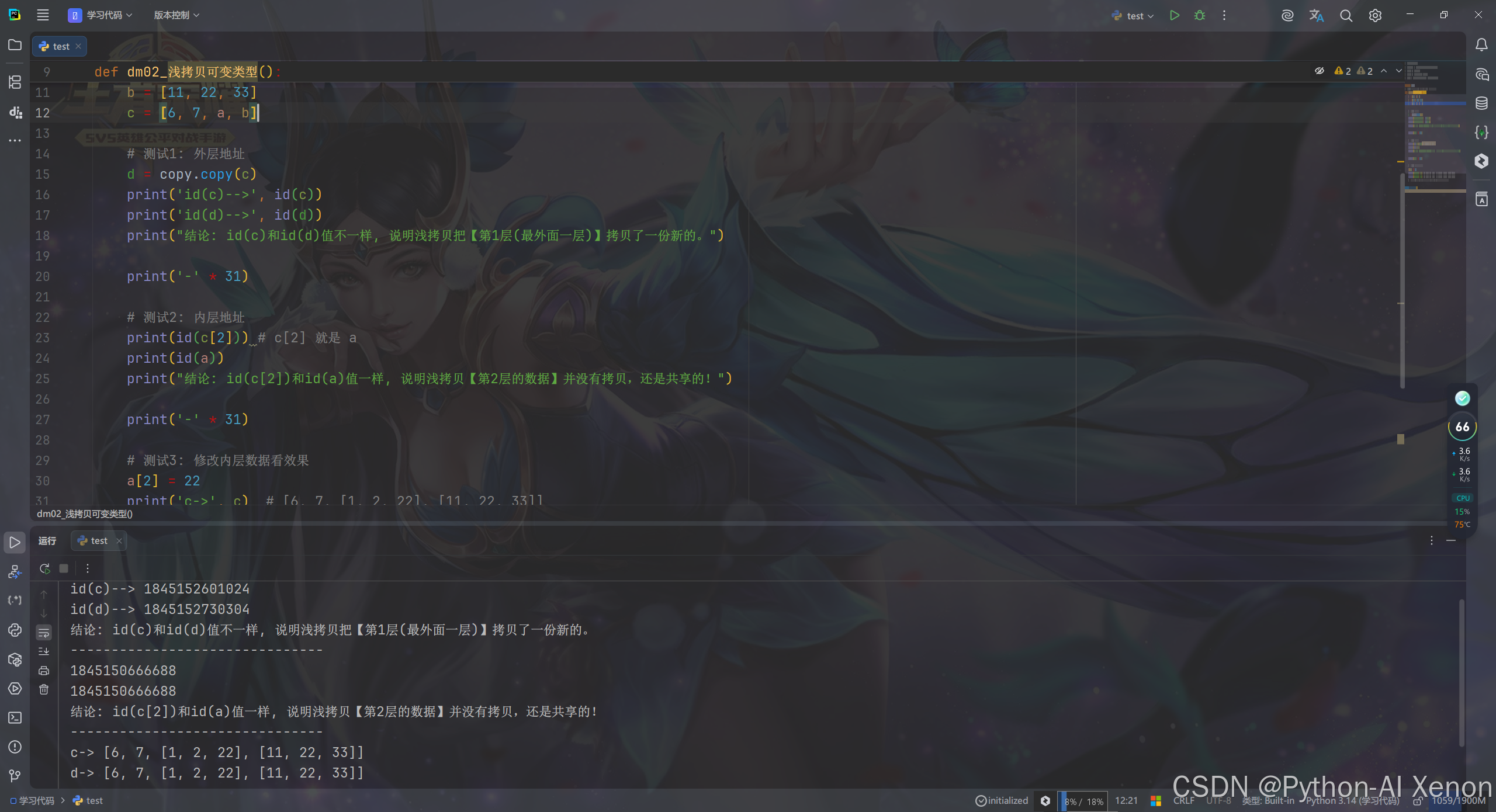
拓展:除了
copy.copy(),列表切片list[:]、list()构造、dict()构造、set.copy()等常用写法,本质也都是浅拷贝。
2.2 不可变类型的浅拷贝
如果拷贝的对象本身是不可变类型,浅拷贝不会创建新对象,会直接返回原对象的引用。
原因很简单:不可变类型本身无法修改内容,共享引用不会产生任何副作用,Python 解释器做了内存优化,避免不必要的空间浪费。
python
import copy
# 浅拷贝不可变类型: 不会给拷贝的对象c开辟新的内存空间, 而只是拷贝了这个对象的引用
def dm03_浅拷贝不可变类型():
# 不可变类型 a b c (元组是不可变类型)
a = (1, 2, 3)
b = (11, 22, 33)
c = (6, 7, a, b)
d = copy.copy(c)
print('id(c)-->', id(c))
print('id(d)-->', id(d))
print("结论: id(c)和id(d)值一样, 说明c和d指向相同的内存空间")
# 为什么会这样?因为不可变类型本身值都是不能被修改的,没有再浪费内存空间的必要,
# 所以程序员要copy不可变类型时,Python解释器直接返回原对象的地址(别名/引用),主打一个省钱省内存!
dm03_浅拷贝不可变类型()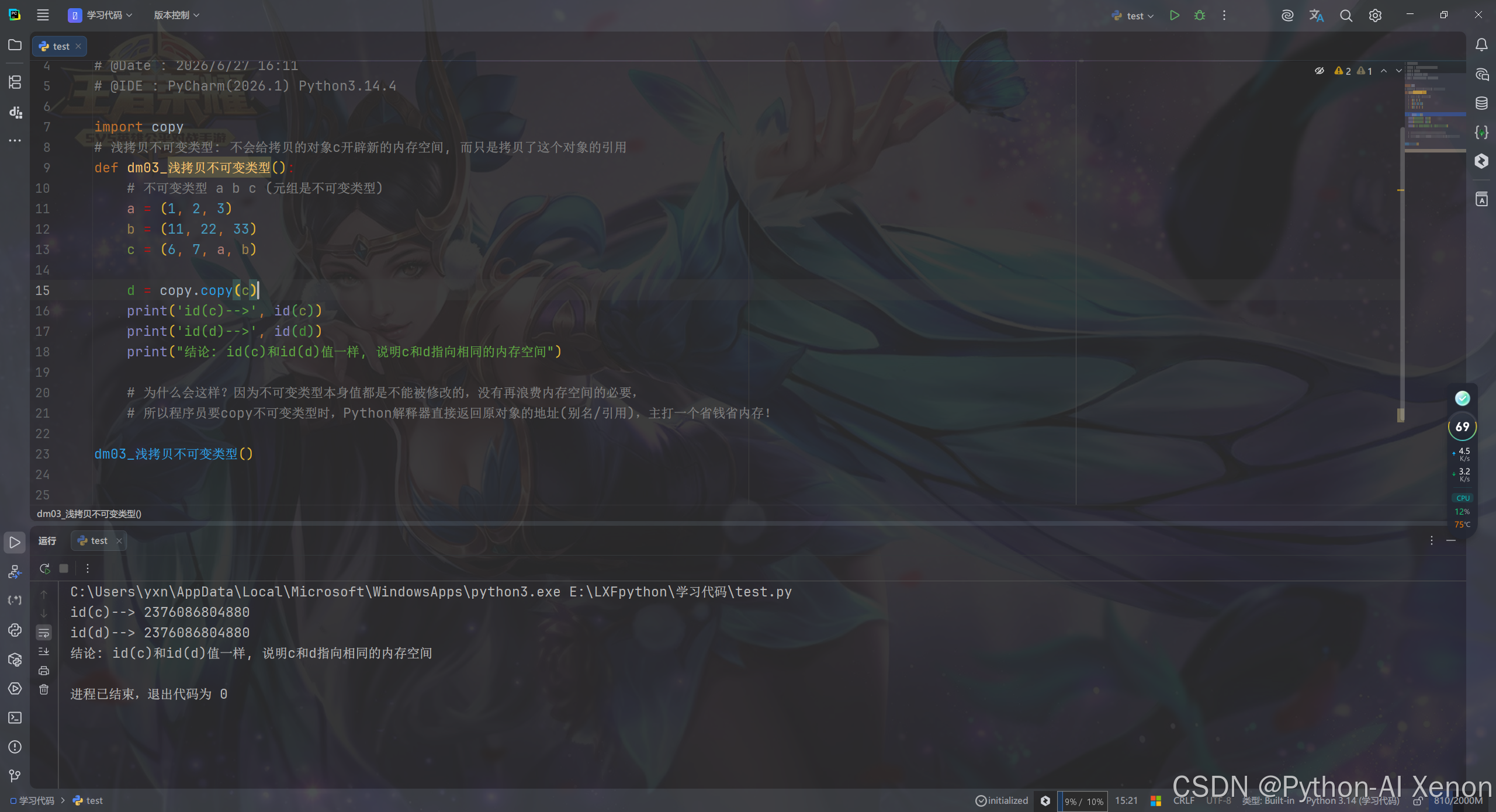
三、深拷贝:递归全层级拷贝
深拷贝会创建一个全新的对象,并且递归地把所有层级内部的对象也都拷贝一份。
深拷贝对应copy模块中的copy.deepcopy()函数,核心规则是:递归遍历所有层级,只要是可变类型就重新创建独立内存。拷贝完成后,新对象与原对象完全独立,无论怎么改,互不影响!
3.1 可变类型的深拷贝
对于嵌套可变结构,深拷贝会逐层深入,每一层可变容器都会重新创建,彻底切断与原对象的引用关联。
python
import copy
# 需求1: 深拷贝可变类型: 只要是可变类型, 每一层都会拷贝.
def dm02_深拷贝可变类型():
a = [1, 2, 3]
b = [11, 22, 33]
c = [6, 7, a, b]
# 测试1: 外层地址
d = copy.deepcopy(c)
print('id(c)-->', id(c))
print('id(d)-->', id(d)) # 地址不同,外层拷贝了
print('-' * 31)
# 测试2: 内层地址
print(id(c[2])) # c[2]是a
print(id(a)) # 说明c[2]和a还是同一个
# 注意:虽然c[2]和a一样,但d[2]和a绝对不一样了!深拷贝在d内部全新造了一个列表
print('-' * 31)
# 测试3: 修改内层数据看效果
a[2] = 22
print('c->', c) # [6, 7, [1, 2, 22], [11, 22, 33]]
print('d->', d) # [6, 7, [1, 2, 3], [11, 22, 33]] ---> d完全没有受到影响!
# 结论:深拷贝连内部的列表都重新克隆了一份,原数据a怎么改,都影响不到d了。
dm02_深拷贝可变类型()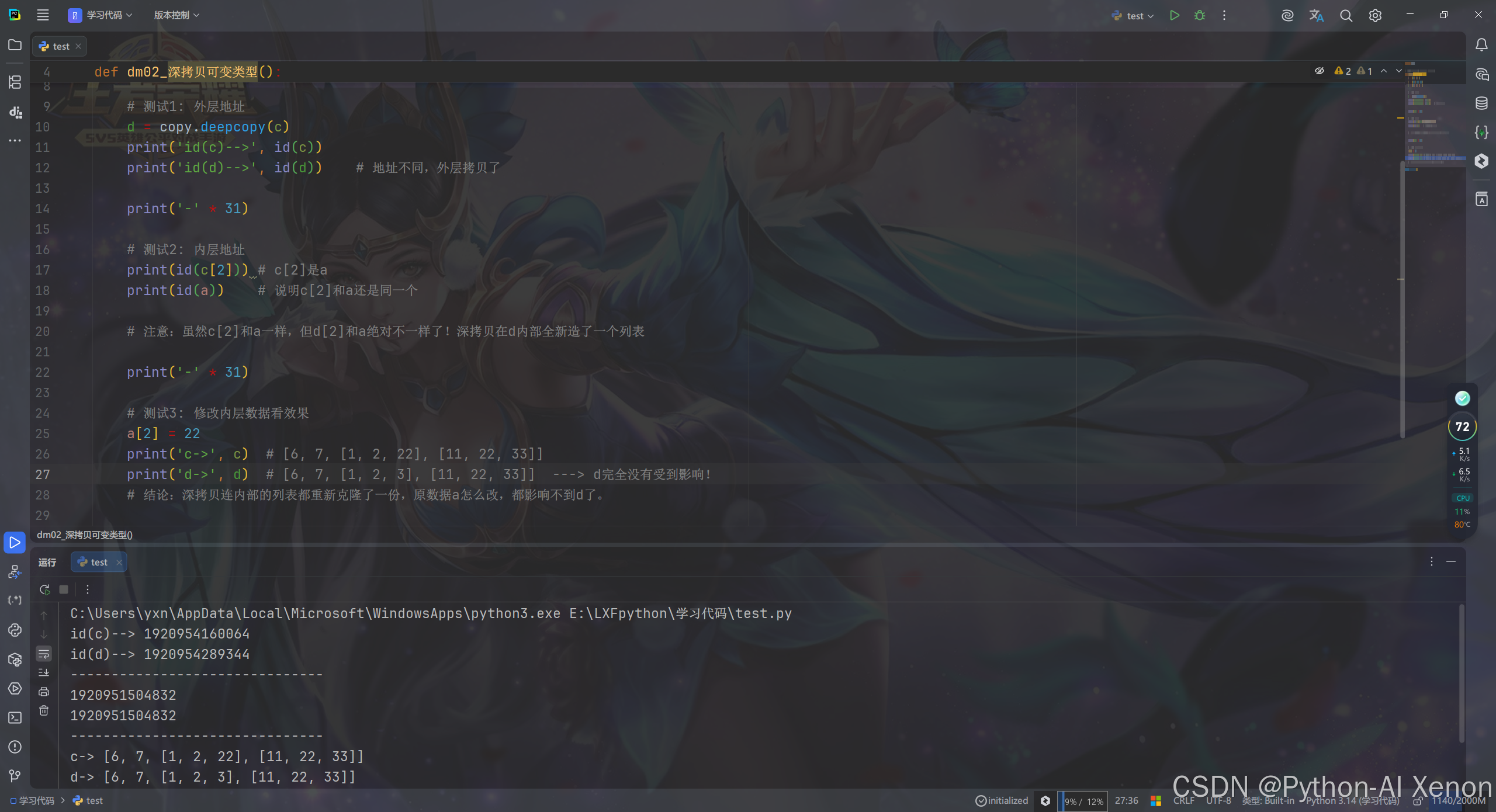
3.2 不可变类型的深拷贝
对于纯不可变类型,深拷贝与浅拷贝效果一致,都会直接复用原对象引用。
需要注意一个细节:如果不可变容器(比如元组)内部嵌套了可变类型,深拷贝依然会递归拷贝内层的可变元素,保证最终副本完全独立。
python
# 深拷贝不可变类型: 同浅拷贝一样,不会开辟新内存,只是拷贝引用
def dm03_深拷贝不可变类型():
# 不可变类型 a b c
a = (1, 2, 3)
b = (11, 22, 33)
c = (6, 7, a, b)
d = copy.deepcopy(c)
print('id(c)-->', id(c))
print('id(d)-->', id(d))
print("结论: id(c)和id(d)值一样, 说明c和d指向相同的内存空间")
# 原理同浅拷贝不可变类型:不可变类型不能改,没必要浪费内存重新造,直接返回原地址。
dm03_深拷贝不可变类型()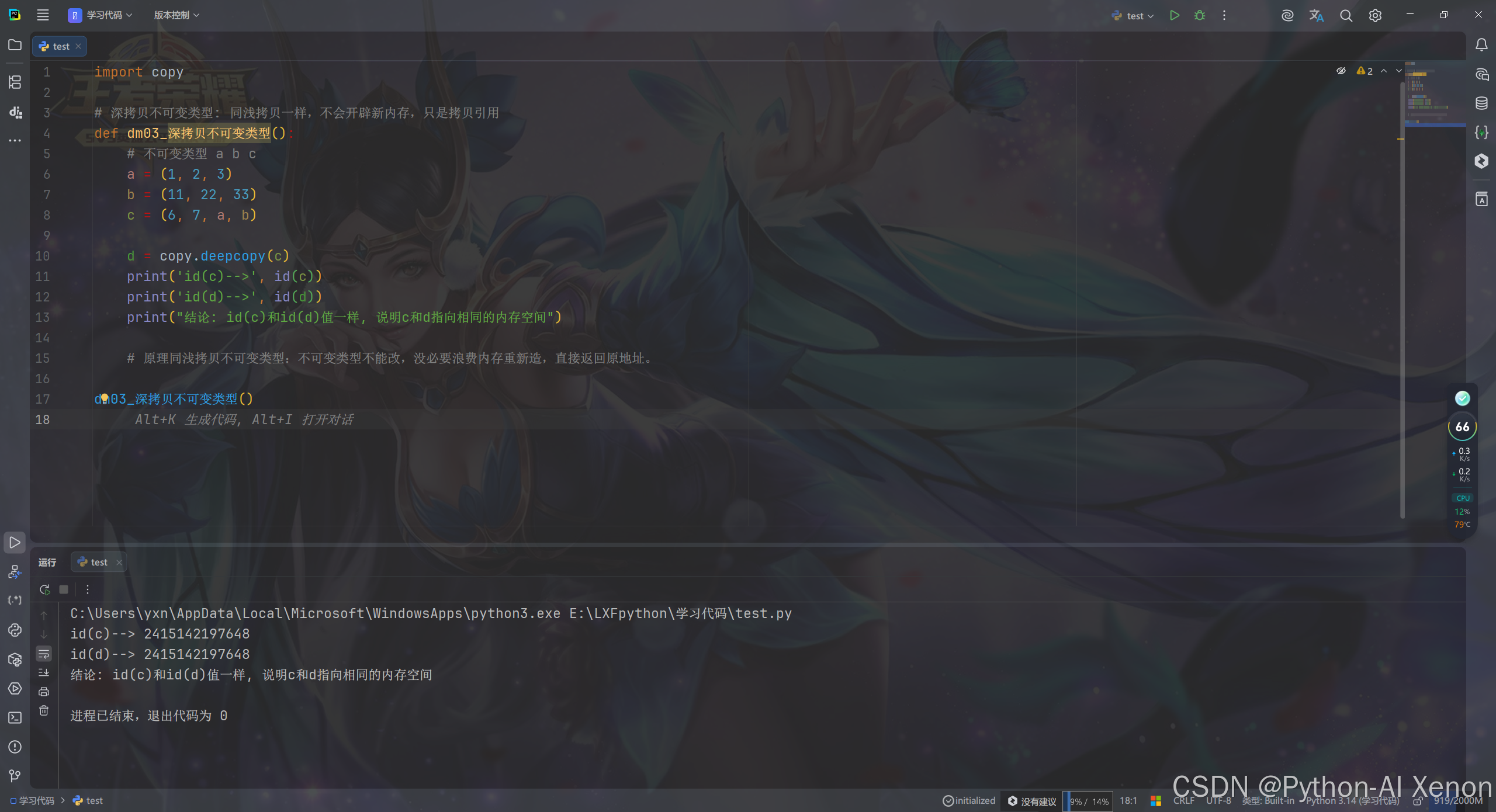
四、一张表总结三者核心区别
| 操作方式 | 外层可变类型 | 内层可变类型 | 纯不可变类型 | 数据联动程度 |
|---|---|---|---|---|
直接赋值 = |
共享引用 | 共享引用 | 共享引用 | 完全同步,修改一处全影响 |
浅拷贝 copy.copy() |
创建新对象 | 共享引用 | 复用原对象 | 修改内层数据会同步变化 |
深拷贝 copy.deepcopy() |
创建新对象 | 创建新对象 | 复用原对象 | 完全独立,互不影响 |
!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/a5b35424a1534bdda0ac7377f774bd05.png
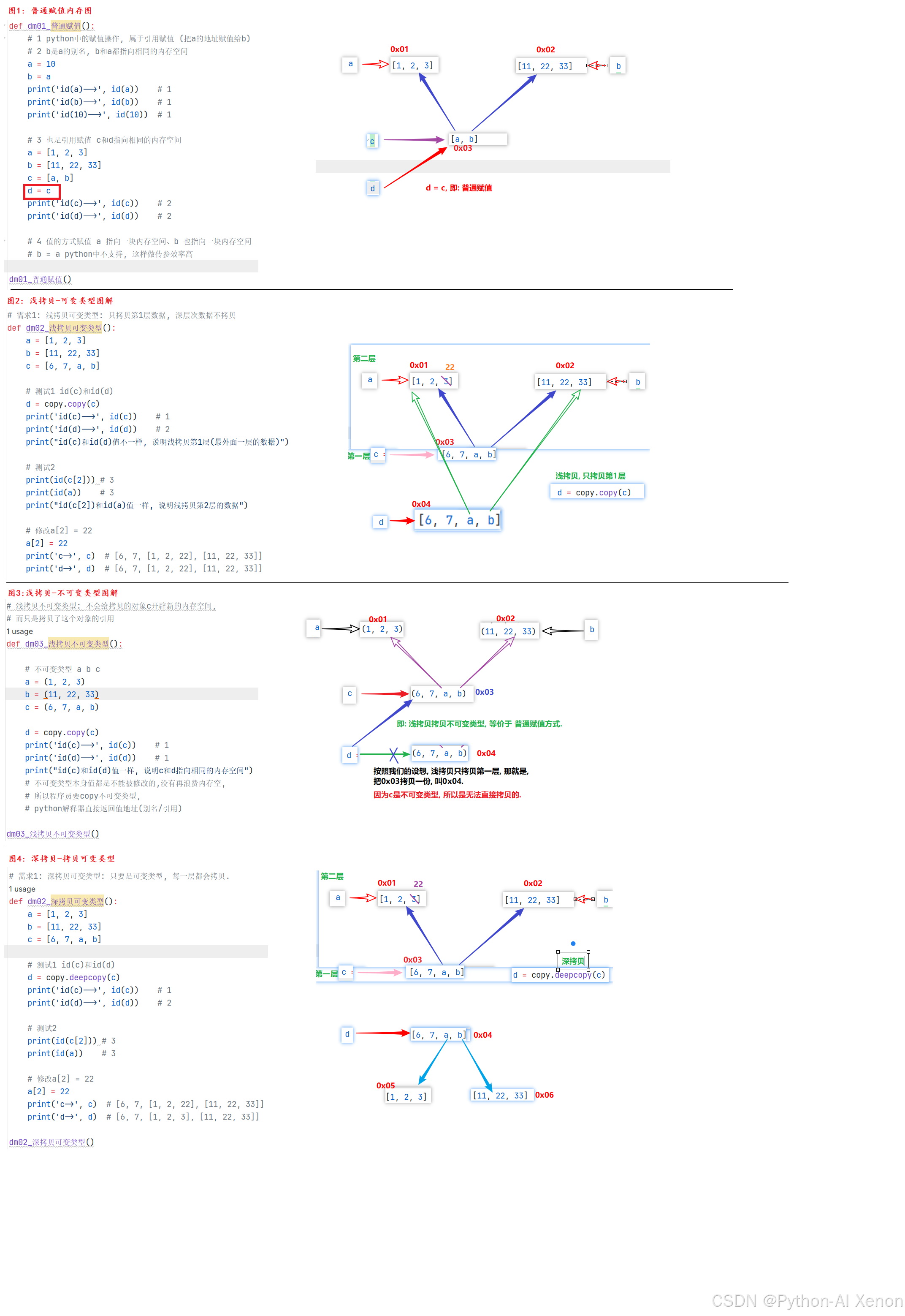
普通赋值内存图解
普通赋值的内存结构可以拆分为两层:第 1 层是引用层(地址层),存储变量指向的内存地址;第 2 层是数据层,存储实际的对象内容。
- 引用层:变量c和d都指向同一个内存地址0x03
- 数据层:二者完全共用同一套数据,内层的a、b列表也共享原始地址
- 结论:普通赋值仅复制了地址,没有复制数据,两个变量完全共享同一份数据,修改可变内容会双向同步
浅拷贝可变类型内存图解
从内存分层模型可以清晰看到浅拷贝的边界:
- 引用层:外层c(地址0x03)和d(地址0x04)是两个独立的地址,说明最外层容器被重新创建
- 数据层:内层的a(地址0x01)、b(地址0x02)列表依然指向原始地址,没有重新生成
- 直观结论:浅拷贝只 "复制了第一层目录",内层数据还是原来的那份,修改内层可变元素,两边会同步变化
- 拓展:除了copy.copy(),列表切片list:、list()构造、dict()构造、set.copy()等常用写法,本质也都是浅拷贝。
浅拷贝不可变类型内存图解
因为元组本身不可修改,不存在 "改副本影响原数据" 的风险,所以浅拷贝直接复用原对象地址,效果和普通赋值完全一致。
深拷贝可变类型内存图解
深拷贝会递归复制所有层级的可变对象:
- 引用层:外层c(地址0x03)和d(地址0x04)是独立地址
- 数据层:内层的列表也被完整拷贝,生成了新的独立地址0x05、0x06,和原对象彻底切断关联
- 直观结论:深拷贝是完完整整复制了全量数据,两个对象完全独立,修改任意层级都不会互相干扰
五、进阶话题
5.1 混合类型:嵌套中包含不可变类型
当嵌套结构中既有可变类型又有不可变类型时,深拷贝的表现如何?
python
import copy
original = [1, (2, 3), [4, 5]]
copied = copy.deepcopy(original)
print(id(original[1])) # 地址1
print(id(copied[1])) # 地址1(不可变类型,不复制)
print(id(original[2])) # 地址2
print(id(copied[2])) # 地址3(可变类型,复制)深拷贝只对可变类型进行递归复制,不可变类型直接共享引用。
5.2 自定义对象的拷贝
对于自定义类,默认的 copy.copy() 和 copy.deepcopy() 也会按照上述规则工作。如果需要自定义拷贝行为,可以实现 __copy__() 和 __deepcopy__() 方法。
python
import copy
class MyClass:
def __init__(self, data):
self.data = data
obj = MyClass([1, 2, 3])
shallow = copy.copy(obj) # 浅拷贝 obj
deep = copy.deepcopy(obj) # 深拷贝 obj5.3 循环引用的处理
深拷贝能够正确处理循环引用,不会陷入无限递归。
python
import copy
a = [1, 2]
b = [a, 3]
a.append(b) # 形成循环引用:a -> b -> a
c = copy.deepcopy(a) # 正常完成,不会死循环
print(c) # [[1, 2, [...]], 3] (... 表示循环引用)5.4 性能考量
- 浅拷贝:时间复杂度 O(n),n 是第一层元素个数。
- 深拷贝:时间复杂度 O(N),N 是所有可变元素的总数,且递归复制会消耗更多内存。
在性能敏感的场合,应优先使用浅拷贝,只有在确实需要完全隔离时才使用深拷贝。
5.5 一键验证模板
python
import copy
def analyze_copy(data, copy_type='deep'):
"""分析拷贝行为的通用工具函数"""
original = data
copied = copy.copy(original) if copy_type == 'shallow' else copy.deepcopy(original)
print(f"\n=== {copy_type.upper()} COPY ANALYSIS ===")
print(f"Original ID: {id(original)}")
print(f"Copied ID: {id(copied)}")
# 检查第一个嵌套可变对象
if isinstance(original, (list, dict)) and len(original) > 0:
if isinstance(original, list):
nested = original if len(original) > 0 else None
nested_copied = copied if len(copied) > 0 else None
else: # dict
nested = list(original.values()) if len(original) > 0 else None
nested_copied = list(copied.values()) if len(copied) > 0 else None
if nested is not None and isinstance(nested, (list, dict)):
print(f"Nested object ID (original): {id(nested)}")
print(f"Nested object ID (copied): {id(nested_copied)}")
print(f"Nested objects are {'identical' if id(nested) == id(nested_copied) else 'independent'}")
# 通过键或索引访问
if isinstance(original, list) and len(original) > 0 and isinstance(original, list):
original = 'MODIFIED' # 修改第一个嵌套列表的第一个元素
elif isinstance(original, dict) and len(original) > 0:
first_key = next(iter(original)) # 获取第一个键
if isinstance(original[first_key], list):
original[first_key] = 'MODIFIED' # 修改第一个值(列表)的第一个元素
elif isinstance(original[first_key], dict):
first_nested_key = next(iter(original[first_key]))
original[first_key][first_nested_key] = 'MODIFIED' # 修改嵌套字典的值
print(f"Original after modify: {original}")
print(f"Copied after modify: {copied}")
# 使用示例
test_data = [[1, 2], {'key': [3, 4]}]
analyze_copy(test_data, 'shallow')
analyze_copy(test_data, 'deep')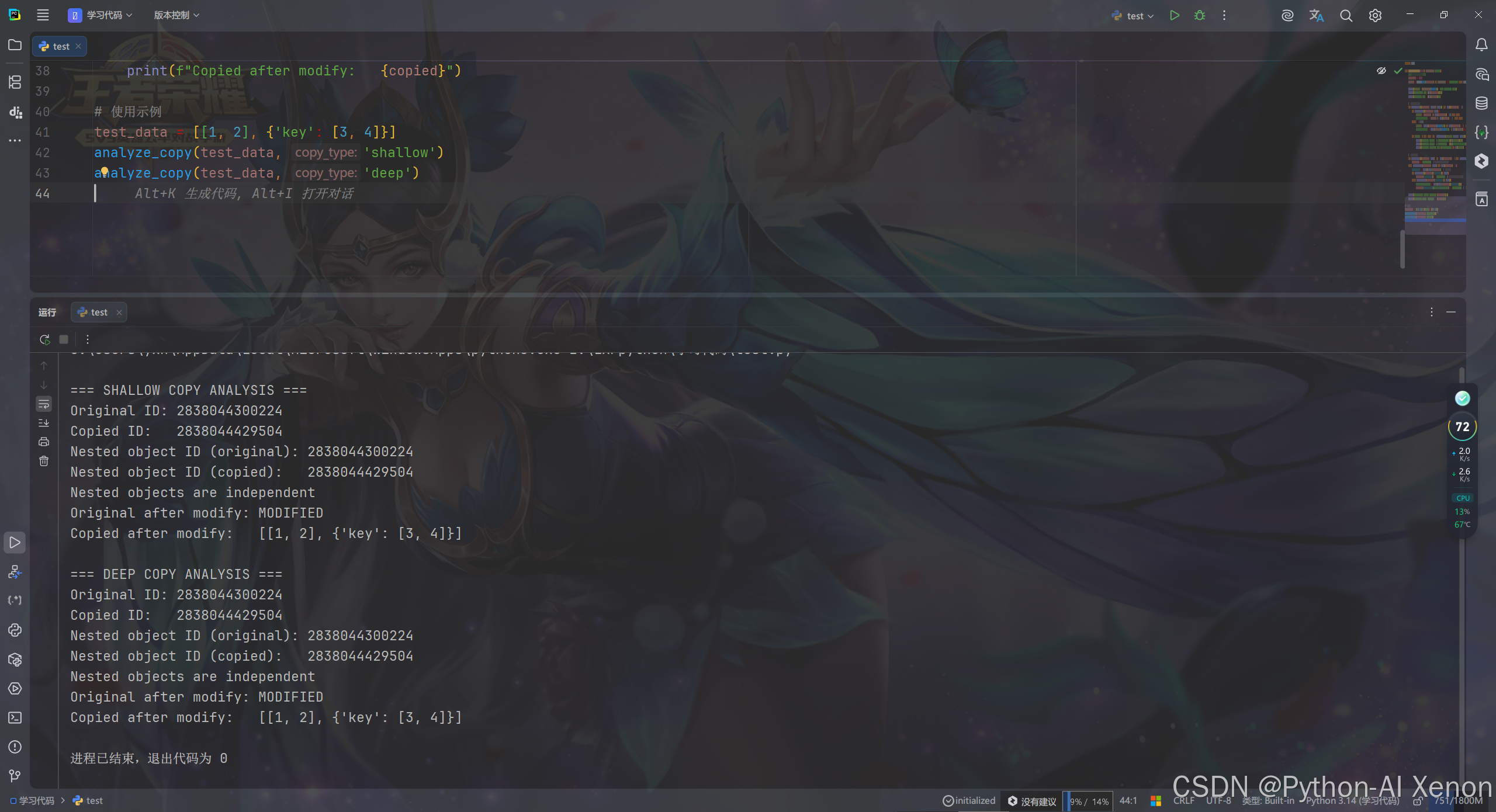
六、实战场景与避坑指南
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 函数传参,仅读取 | 普通赋值 | 零开销,效率最高 |
| 配置模板复用,内部不变 | 浅拷贝 | 节省内存,结构复用 |
| 多线程/异步修改副本 | 深拷贝 | 避免竞态条件,数据安全 |
| 复制大型嵌套结构(如JSON树) | ⚠️ 谨慎使用 | 可能导致内存爆炸或延迟 |
| 复制含自引用对象 | 必须用深拷贝 | copy.deepcopy 自动处理循环引用 |
6.1 适用场景
-
浅拷贝适用场景
- 数据是单层扁平结构,内层全是数字、字符串等不可变类型
- 追求拷贝性能,不需要完全独立的副本
- 典型场景:复制单层列表、扁平化的配置字典
-
深拷贝适用场景
- 数据是嵌套结构,内层包含列表、字典等可变类型
- 需要完全独立的副本,修改副本不能污染原数据
- 典型场景:复制复杂配置项、深拷贝自定义类对象、传递嵌套业务数据
6.2 常见避坑提醒
- 不要误以为
list()、列表切片就是"完全复制",它们都只是浅拷贝,嵌套结构依然会联动 - 不要不分场景滥用深拷贝:复杂嵌套结构下深拷贝有遍历性能开销,数据量大时会影响效率
- 自定义类对象的拷贝规则一致:浅拷贝只复制实例本身,属性中的可变对象依然共享引用
| 误区 | 正解 |
|---|---|
| "深拷贝会复制所有数据,包括数字、字符串" | ❌ 错误。不可变对象仍共享引用,深拷贝只复制可变对象的层级 |
| "浅拷贝只对列表有效" | ❌ 错误。对 dict、set 同样适用:copy.copy(my_dict) |
| "深拷贝太慢,永远别用" | ❌ 错误。在需要数据隔离的场景(如测试、并发、缓存)中,它是唯一安全选择 |
| list.copy() 和 copy.copy(list) 不一样 | ❌ 错误。二者完全等价,都是浅拷贝 |
| "深拷贝会破坏原对象" | ❌ 错误。深拷贝是只读复制,原对象毫发无损 |
结语
深拷贝与浅拷贝的核心差异,本质就是拷贝的层级深度不同。理解了Python的引用传递机制,再结合可变、不可变类型的特性,就能轻松避开"改副本影响原数据"的常见坑,根据业务场景选择最合适的拷贝方式,写出更安全、更健壮的代码。