目录
- 第一章:MoE是什么------建立直觉理解
- 第二章:MoE的数学原理
- 第三章:门控网络------MoE的大脑
- 第四章:MoE在大模型中的应用
- 第五章:MoE的核心挑战与解决方案
- 第六章:MoE在传统机器学习中的应用
- 第七章:MoE在传统深度学习中的应用
- 第八章:MoE训练实战------从零实现
- 第九章:MoE算法选型与最佳实践
- 附录:术语表与参考资料
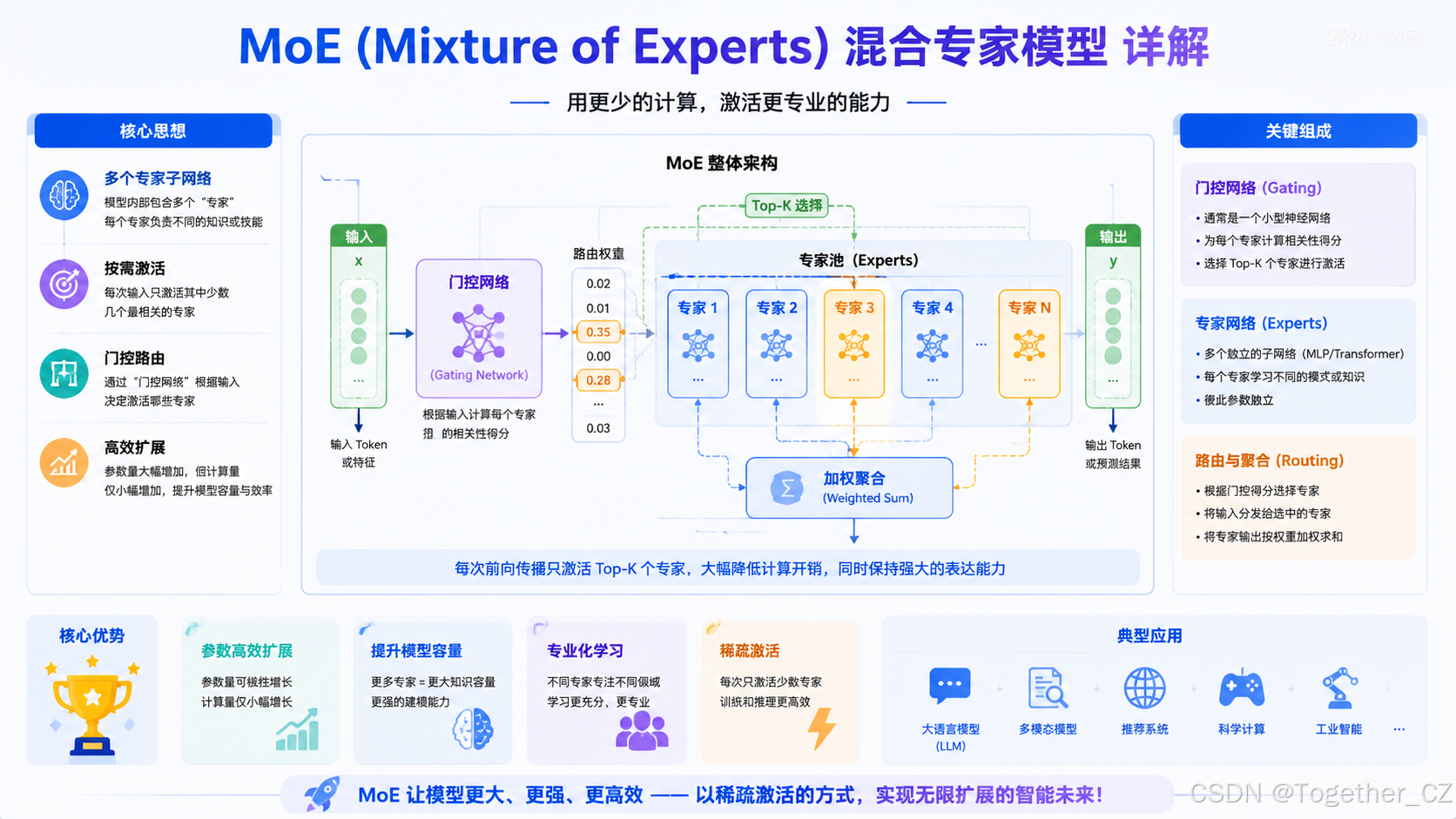
第一章:MoE是什么------建立直觉理解
1.1 一句话概括
MoE = Mixture of Experts = 混合专家模型
核心思想:
一个模型内部包含多个"专家"子网络
每次输入只激活其中少数几个最相关的专家
通过一个"门控网络"来决定激活哪些专家MoE整体架构可视化:
┌─────────────────────────────────────────────────────────────┐
│ MoE 混合专家模型 │
│ │
│ 输入 x │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 门控网络 │ │
│ │ Gating Network │ │
│ │ g(x) = Softmax│ │
│ │ (TopK(Wx)) │ │
│ └────────┬────────┘ │
│ │ │
│ 权重 [0.475, 0, 0, 0.525, 0, 0, 0, 0] │
│ (只有专家2和专家4被选中) │
│ │ │
│ ┌───────┬───────┼───────┬───────┬───────┐ │
│ ▼ ▼ ▼ ▼ ▼ ▼ │
│ ┌──────┐┌──────┐┌──────┐┌──────┐┌──────┐┌──────┐ │
│ │专家1 ││专家2 ││专家3 ││专家4 ││专家5 ││ ... │ │
│ │(冻结)││(0.47)││(冻结)││(0.53)││(冻结)││ │ │
│ │ ✗ ││ ✓ ││ ✗ ││ ✓ ││ ✗ ││ ✗ │ │
│ └──┬───┘└──┬───┘└──┬───┘└──┬───┘└──┬───┘└──┬───┘ │
│ │ │ │ │ │ │ │
│ ▼ ▼ ▼ ▼ ▼ ▼ │
│ y₁ y₂ y₃ y₄ y₅ y₆ │
│ │ │ │ │
│ ×0 ×0.475 ×0 ×0.525 ×0 ×0 │ │
│ \_______________↓_______________/ │
│ │ │
│ 加权求和 │
│ │ │
│ ▼ │
│ y = 0.475×y₂ + 0.525×y₄ │
│ (最终输出) │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 关键特性: │ │
│ │ • 总参数量 = 8个专家(知识容量大) │ │
│ │ • 每次只计算2个专家(计算量小) │ │
│ │ • 门控网络自动选择最合适的专家(智能路由) │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘类比理解------医院导诊系统:
┌─────────────────────────────────────────────────────────┐
│ 医院类比(直觉理解) │
│ │
│ 患者(输入x) │
│ │ │
│ ▼ │
│ 导诊台(门控网络) │
│ │ "这位患者有发烧和咳嗽" │
│ │ → 分配给:内科(0.6) + 呼吸科(0.4) │
│ │ │
│ ├──→ 内科医生(专家1)──→ 诊断A (×0.6) │
│ ├──→ 外科医生(专家2)──→ 不参与 (×0) │
│ ├──→ 呼吸科医生(专家3)──→ 诊断B (×0.4) │
│ ├──→ 骨科医生(专家4)──→ 不参与 (×0) │
│ └──→ 眼科医生(专家5)──→ 不参与 (×0) │
│ │ │
│ ▼ │
│ 综合诊断 = 0.6×诊断A + 0.4×诊断B │
│ │
│ ✓ 不是每个医生都看(稀疏激活)→ 省资源 │
│ ✓ 导诊台智能分配(门控网络)→ 选对专家 │
│ ✓ 综合多科室意见(加权求和)→ 更准确 │
└─────────────────────────────────────────────────────────┘1.2 为什么需要MoE?
问题:模型越大,能力越强,但计算成本也越高
传统方法的困境:
- 增加模型参数 → 增加计算量 → 更慢更贵
- 7B模型比1B模型强,但推理成本也高7倍
- 能不能"鱼和熊掌兼得"?
MoE的解决方案:
- 增加总参数量(更多专家)→ 知识容量增大
- 但每次只激活少数专家 → 计算量不增加
- 效果:用3B的计算成本,获得35B的知识容量
实际案例:
Qwen3.6-35B-A3B:35B总参数,3B激活参数
Mixtral 8x7B:47B总参数,13B激活参数
Switch Transformer:1.6T总参数,但计算量和T5-Base相当1.3 MoE的历史
MoE的发展历程:
1991年:Jacobs等人提出MoE的基本概念
- 最初用于简单的分类任务
- 专家是小型网络
2017年:Shazeer等人将MoE引入深度学习
- 论文:"Outrageously Large Neural Networks"
- 引入了稀疏门控机制
- 首次在大规模语言模型中使用MoE
2020年:GShard(Google)
- 将MoE扩展到600B参数
- 引入了容量因子和负载均衡
2021年:Switch Transformer(Google)
- 简化为只选择Top-1专家
- 扩展到1.6T参数
2022年:ST-MoE(Google)
- 稳定训练的MoE技术
2024年:Mixtral 8x7B(Mistral AI)
- 8个7B专家,每次激活2个
- 性能接近LLaMA2-70B
- 开源,引爆了MoE的普及
2025-2026年:Qwen3.6-35B-A3B等
- MoE成为大模型的主流架构之一1.4 MoE的直觉理解------用一个例子
假设你要教一个AI识别动物图片
方案A:传统方法(密集模型)
训练一个大网络,学习所有动物的特征
猫、狗、鸟、鱼、蛇... 全部混在一起学
问题:网络需要很大的容量来记住所有动物的特征
方案B:MoE方法
训练4个"专家":
专家1:擅长识别毛茸茸的动物(猫、狗、兔子)
专家2:擅长识别有翅膀的动物(鸟、蝴蝶、蝙蝠)
专家3:擅长识别水生动物(鱼、海豚、章鱼)
专家4:擅长识别爬行动物(蛇、蜥蜴、鳄鱼)
加上一个"门控网络":
看到猫的图片 → 门控说"让专家1来处理"
看到鱼的图片 → 门控说"让专家3来处理"
看到蝙蝠的图片 → 门控说"让专家2和专家4都看看"
效果:每个专家只需要精通自己领域,不需要懂所有动物第二章:MoE的数学原理
2.1 MoE的基本公式
MoE的输出是所有专家输出的加权和:
y = Σᵢ gᵢ(x) × Eᵢ(x)
其中:
x: 输入
Eᵢ(x): 第i个专家的输出
gᵢ(x): 门控网络为第i个专家分配的权重
Σᵢ gᵢ(x) = 1(权重归一化)
门控网络的输出:
g(x) = Softmax(TopK(Wg · x))
其中:
Wg: 门控网络的权重矩阵
TopK: 只保留前K个最大的值,其余设为0
Softmax: 对保留的K个值做归一化2.2 稀疏激活------MoE的核心
密集模型 vs MoE稀疏激活 对比图:
┌─────────────────────────────────────────────────────────────┐
│ 密集模型(Dense Model)vs MoE稀疏模型 │
│ │
│ ════════════ 密集模型 ════════════ │
│ │
│ 输入 x │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────┐ │
│ │ FFN层(全部参数都参与计算) │ ← 计算量 = 全部参数 │
│ │ W₁, W₂, W₃, W₄, W₅, W₆... │ │
│ │ 所有权重矩阵同时运算 │ │
│ └─────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ 输出 y │
│ │
│ ════════════ MoE稀疏模型 ════════════ │
│ │
│ 输入 x │
│ │ │
│ ▼ │
│ ┌──────────┐ │
│ │ 门控网络 │ → 选择 Top-2: 专家2和专家4 │
│ └────┬─────┘ │
│ │ │
│ ┌────┴────────────────────────────────────┐ │
│ │ MoE FFN层(8个专家,只激活2个) │ │
│ │ │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │ │
│ │ │专家1 │ │专家2 │ │专家3 │ │专家4 │ │ │
│ │ │ ✗ │ │ ✓ │ │ ✗ │ │ ✓ │ │ │
│ │ │冻结 │ │激活 │ │冻结 │ │激活 │ │ │
│ │ └──────┘ └──────┘ └──────┘ └──────┘ │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │ │
│ │ │专家5 │ │专家6 │ │专家7 │ │专家8 │ │ │
│ │ │ ✗ │ │ ✗ │ │ ✗ │ │ ✗ │ │ │
│ │ └──────┘ └──────┘ └──────┘ └──────┘ │ │
│ └────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 输出 y = w₂·E₂(x) + w₄·E₄(x) ← 计算量 = 2/8 = 25% │
│ │
│ ════════════ 性能对比 ════════════ │
│ │
│ 指标 密集模型 MoE (8专家, Top-2) │
│ ───────────────────────────────────────── │
│ 总参数量 7B 56B (8×7B) │
│ 每次计算量 7B FLOPs 14B FLOPs │
│ 知识容量 7B 56B │
│ 计算效率 100% 25% (省75%) │
│ 效果 基准 接近56B密集模型 │
│ │
│ 核心洞察:用25%的计算成本,获得8倍的知识容量! │
└─────────────────────────────────────────────────────────────┘
计算量对比:
8个专家,每个7B参数,每次激活2个
总参数:8 × 7B = 56B
计算量:2 × 7B = 14B(比56B少4倍!)
但总知识容量(参数量)仍然是56B!2.3 门控函数详解
门控函数的核心作用:决定每个输入应该由哪些专家处理
最简单的门控函数------TopK Softmax:
Step 1: 计算每个专家的分数
s_i = W_g[i] · x (线性变换)
Step 2: TopK选择
只保留分数最高的K个专家,其余设为-inf
Step 3: Softmax归一化
g_i = exp(s_i) / Σⱼ exp(s_j)
(只对保留的K个专家做归一化)
示例(8个专家,Top-2):
原始分数: [0.5, 0.8, 0.2, 0.9, 0.1, 0.3, 0.7, 0.4]
Top-2选择: [0, 0.8, 0, 0.9, 0, 0, 0, 0] (保留第2和第4个)
Softmax归一化: [0, 0.475, 0, 0.525, 0, 0, 0, 0]
最终:专家2权重0.475,专家4权重0.525,其余专家不参与2.4 计算量分析
设:
N = 总专家数
K = 每次激活的专家数
d = 每个专家的参数量
D = 总参数量 = N × d + 门控参数
传统密集模型:
计算量 = O(D) = O(N × d)
MoE模型:
计算量 = O(K × d) = O(K/N × D)
示例:
N=8, K=2, d=7B
密集模型计算量: 56B FLOPs
MoE计算量: 14B FLOPs
节省: 75%
但总知识容量(参数量)仍然是56B!第三章:门控网络------MoE的大脑
3.1 门控网络的作用
门控网络是MoE中最关键的组件:
- 它决定"谁来处理这个输入"
- 好的门控 → 把输入分配给最合适的专家 → 效果好
- 差的门控 → 把输入分配给不合适的专家 → 效果差
门控网络的设计直接影响:
1. 模型效果(分配准确性)
2. 训练稳定性(负载均衡)
3. 推理效率(激活专家数)3.2 常见的门控策略
策略1:Top-K门控(最常用)
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class TopKGating(nn.Module):
"""Top-K稀疏门控"""
def __init__(self, input_dim, num_experts, top_k=2):
super().__init__()
self.gate = nn.Linear(input_dim, num_experts)
self.top_k = top_k
def forward(self, x):
# 计算所有专家的分数
logits = self.gate(x) # [batch, num_experts]
# Top-K选择
top_k_logits, top_k_indices = logits.topk(self.top_k, dim=-1)
# Softmax归一化(只在Top-K上)
top_k_gates = F.softmax(top_k_logits, dim=-1)
# 构造完整的门控向量(未选中的为0)
gates = torch.zeros_like(logits)
gates.scatter_(1, top_k_indices, top_k_gates)
return gates, top_k_indices策略2:Expert Choice门控(专家选择)
传统方法:每个token选择K个专家(token选择专家)
Expert Choice:每个专家选择K个token(专家选择Token)
优势:
- 天然保证负载均衡(每个专家处理固定数量的token)
- 不需要额外的负载均衡损失
- 训练更稳定策略3:Soft MoE(软MoE)
不硬性选择专家,而是用软权重
每个专家都参与,但权重可能非常小(接近0)
优势:
- 训练更稳定
- 不需要特殊的负载均衡技术
- 可以微分(端到端训练)策略4:Hash门控
用哈希函数将token映射到专家
完全随机,不需要学习门控网络
优势:
- 最简单
- 天然负载均衡
- 没有门控网络的额外参数第四章:MoE在大模型中的应用
4.1 为什么大模型特别适合MoE?
大模型的特点:
1. 参数量巨大(7B-1T+)
2. 训练和推理成本高
3. 需要处理多样化的任务
MoE解决的问题:
1. 用更少的计算获得更好的效果
2. 不同的专家可以专注于不同类型的知识
3. 推理时只需要激活少数专家,成本低4.2 大模型中MoE的架构设计
标准Transformer vs MoE Transformer 架构对比:
┌─────────────────────────────────────────────────────────────┐
│ 标准Transformer vs MoE Transformer │
│ │
│ ══════ 标准Transformer层(Dense)══════ │
│ │
│ 输入 x (token embedding) │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ Self-Attention │ ← 所有token共享 │
│ │ Q, K, V, O 投影 │ │
│ └────────┬─────────┘ │
│ │ + 残差连接 │
│ ▼ │
│ ┌──────────────────┐ │
│ │ LayerNorm │ │
│ └────────┬─────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ FFN (前馈网络) │ ← 单个FFN,所有token共用同一组参数 │
│ │ Gate → Up → Down │ │
│ └────────┬─────────┘ │
│ │ + 残差连接 │
│ ▼ │
│ ┌──────────────────┐ │
│ │ LayerNorm │ │
│ └────────┬─────────┘ │
│ │ │
│ ▼ │
│ 输出 y │
│ │
│ ══════ MoE Transformer层(Sparse)══════ │
│ │
│ 输入 x (token embedding) │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ Self-Attention │ ← 注意力层保持不变(共享) │
│ │ Q, K, V, O 投影 │ │
│ └────────┬─────────┘ │
│ │ + 残差连接 │
│ ▼ │
│ ┌──────────────────┐ │
│ │ LayerNorm │ │
│ └────────┬─────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────┐ │
│ │ MoE-FFN 层 │ │
│ │ │ │
│ │ ┌──────────────────────┐ │ │
│ │ │ 门控网络(Router) │ │ │
│ │ │ 输入x → 分数 → Top-K │ │ │
│ │ └──────────┬───────────┘ │ │
│ │ │ │ │
│ │ ┌──────────┴──────────┐ │ │
│ │ ▼ ▼ ▼ │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │ │
│ │ │FFN-1 │ │FFN-2 │ │FFN-3 │ │FFN-8 │ │ │
│ │ │ │ │ ✓选中│ │ │ │ ✓选中│ │ │
│ │ │完整FFN│ │完整FFN│ │完整FFN│ │完整FFN│ │ │
│ │ │Gate↑ │ │Gate↑ │ │Gate↑ │ │Gate↑ │ │ │
│ │ │Up ↓ │ │Up ↓ │ │Up ↓ │ │Up ↓ │ │ │
│ │ │Down │ │Down │ │Down │ │Down │ │ │
│ │ └──────┘ └──────┘ └──────┘ └──────┘ │ │
│ │ │ │ │ │
│ │ ▼ ▼ │ │
│ │ w₂·FFN₂(x) + w₈·FFN₈(x) │ │
│ └──────────────────────────────────────┘ │
│ │ + 残差连接 │
│ ▼ │
│ ┌──────────────────┐ │
│ │ LayerNorm │ │
│ └────────┬─────────┘ │
│ │ │
│ ▼ │
│ 输出 y │
│ │
│ 关键区别: │
│ • 注意力层: 保持共享,不使用MoE │
│ • FFN层: 替换为多个FFN专家 + 门控网络 │
│ • 每个token独立选择专家(不同token可能选不同专家) │
│ • FFN层占总参数约2/3,替换效果最大 │
└─────────────────────────────────────────────────────────────┘Mixtral 8x7B 架构详细可视化:
┌─────────────────────────────────────────────────────────────┐
│ Mixtral 8x7B MoE架构详解 │
│ │
│ 输入 tokens: "The cat sat on the mat" │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Token Embedding (词嵌入) │ │
│ └──────────────────────┬──────────────────────────────┘ │
│ │ │
│ ┌──────────────────────┴──────────────────────────────┐ │
│ │ Transformer Block × 32层 (重复32次) │ │
│ │ │ │
│ │ ┌─────────────────────────────────────────────┐ │ │
│ │ │ Shared Attention (共享注意力层) │ │ │
│ │ │ 所有token、所有层共用同一个注意力层 │ │ │
│ │ │ 参数量: 约25%的总参数 │ │ │
│ │ └─────────────────────┬───────────────────────┘ │ │
│ │ │ │ │
│ │ ┌─────────────────────┴───────────────────────┐ │ │
│ │ │ MoE-FFN层 (混合专家FFN) │ │ │
│ │ │ │ │ │
│ │ │ ┌───────────────────────────────────────┐ │ │ │
│ │ │ │ Router (门控网络) │ │ │ │
│ │ │ │ 输入维度: 4096 → 8个专家分数 │ │ │ │
│ │ │ │ 选择: Top-2 专家 │ │ │ │
│ │ │ └────────────────┬──────────────────────┘ │ │ │
│ │ │ │ │ │ │
│ │ │ ┌────────┬───────┼───────┬────────┐ │ │ │
│ │ │ ▼ ▼ ▼ ▼ ▼ │ │ │
│ │ │ FFN_0 FFN_1 FFN_2 ... FFN_7 │ │ │
│ │ │ 每个FFN约7B参数 │ │ │
│ │ │ │ │ │
│ │ │ Token "The": 选择 FFN_2(0.6) + FFN_5(0.4) │ │ │
│ │ │ Token "cat": 选择 FFN_1(0.7) + FFN_3(0.3) │ │ │
│ │ │ Token "sat": 选择 FFN_2(0.5) + FFN_7(0.5) │ │ │
│ │ │ (不同token可以选择不同的专家组合!) │ │ │
│ │ └───────────────────────────────────────────────┘ │ │
│ │ 参数量: 约75%的总参数(8个FFN × 7B = 56B) │ │
│ └───────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ LM Head → 输出 logits │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 模型规格总结: │ │
│ │ • 总参数: ~47B │ │
│ │ • 每次推理激活: ~13B (2个专家) │ │
│ │ • 推理速度: 接近13B密集模型 │ │
│ │ • 效果: 接近70B密集模型 │ │
│ │ • 显存需求: 需要存储全部47B参数 │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘通常只将FFN层替换为MoE,注意力层保持不变。
因为FFN层的参数量占比最大(约2/3),替换效果最明显。
4.3 代表模型分析
Mixtral 8x7B
架构:
- 8个专家,每个约7B参数
- 每次激活Top-2专家
- 总参数:约47B
- 激活参数:约13B
效果:
- 性能接近LLaMA2-70B(密集模型)
- 但推理速度快6倍(13B vs 70B的计算量)
关键设计:
- 每个MoE层有8个独立的FFN专家
- 门控网络选择Top-2
- 注意力层是共享的(不是MoE)Qwen3.6-35B-A3B
架构:
- 总参数35B,激活参数3B
- MoE架构,大量专家
- 每次只激活少数专家
意义:
- 用3B的计算成本获得35B的知识容量
- 非常适合推理密集型应用
- Qwable-v1就是基于这个模型Switch Transformer
架构:
- 最多1.6T参数
- 每个token只选择Top-1专家(最极端的稀疏)
关键创新:
- 简化为Top-1选择(减少通信开销)
- 容量因子(Capacity Factor):控制每个专家最多处理多少token
- 专家并行(Expert Parallelism):不同专家放在不同GPU上4.4 MoE大模型的训练挑战
挑战1:负载不均衡
某些专家被过度使用,其他专家闲置
→ 解决:辅助负载均衡损失
挑战2:训练不稳定
门控网络的离散选择导致梯度估计困难
→ 解决:使用Straight-Through Estimator或软门控
挑战3:通信开销
专家分布在不同GPU上,需要大量通信
→ 解决:专家并行 + 混合专家并行
挑战4:内存占用
总参数量大,需要分布式存储
→ 解决:专家分片、模型并行第五章:MoE的核心挑战与解决方案
5.1 负载均衡问题
问题:
训练过程中,门控网络可能学会"偏爱"某些专家
导致这些专家被过度训练,其他专家几乎不用
结果:大部分专家浪费了,模型退化为密集模型
解决方案1:辅助负载均衡损失
L_balance = α × N × Σᵢ fᵢ × Pᵢ
其中:
- fᵢ: 分配给专家i的token比例
- Pᵢ: 门控网络给专家i的平均概率
- α: 平衡损失系数(通常很小,如0.01)
- N: 专家数量
这个损失鼓励门控网络将token均匀分配给所有专家
解决方案2:Expert Choice门控
每个专家主动选择固定数量的token
天然保证负载均衡
解决方案3:噪声门控
在门控分数上添加随机噪声
鼓励探索不同的专家组合
python
def load_balancing_loss(gates, num_experts):
"""
辅助负载均衡损失
参数:
gates: 门控权重 [batch_size, num_experts]
num_experts: 专家数量
返回:
标量损失值
"""
# f_i: 每个专家被选中的频率
# (通过计算有多少token分配给了每个专家)
expert_mask = (gates > 0).float()
f = expert_mask.mean(dim=0) # [num_experts]
# P_i: 门控概率的平均值
P = gates.mean(dim=0) # [num_experts]
# 负载均衡损失
loss = num_experts * (f * P).sum()
return loss5.2 训练稳定性
问题:
MoE训练比密集模型更容易不稳定
梯度可能在某些专家上爆炸或消失
解决方案1:Router Z-Loss
惩罚门控logits的绝对值过大
L_z = (1/B) × Σ (log Σ exp(x_i))²
解决方案2:梯度裁剪
对每个专家的梯度分别裁剪
解决方案3:学习率调整
门控网络使用较小的学习率
专家网络使用正常的学习率
解决方案4:混合精度训练
门控网络用fp32计算
专家网络可以用bf165.3 推理效率
问题:
MoE模型总参数量大,即使只激活部分专家
内存中仍然需要存储所有专家的权重
解决方案1:专家并行
不同专家放在不同GPU上
通信只在门控决策后发生
解决方案2:专家offloading
不活跃的专家可以放在CPU或磁盘上
需要时再加载到GPU
解决方案3:专家共享
不同层共享部分专家
减少总参数量
解决方案4:专家剪枝
训练后删除不重要的专家
减少推理时的参数量第六章:MoE在传统机器学习中的应用
6.1 MoE可以用于传统ML吗?
答案:完全可以!
MoE的核心思想------"多个模型各有所长,通过门控选择组合"------是一个通用的框架,不局限于神经网络。
MoE在传统ML中的应用方式:
传统ML中的MoE = 多个基模型 + 门控选择器
基模型可以是:
- XGBoost
- Random Forest
- SVM
- 线性回归
- KNN
- 任何其他模型
门控选择器可以是:
- 简单的线性模型
- Softmax分类器
- 甚至规则引擎
本质:MoE是一种"模型集成+自适应选择"的策略6.2 实战:MoE用于分类任务
python
# moe_classification.py
"""
MoE混合专家用于分类任务
使用传统ML模型(XGBoost, SVM, KNN等)作为专家
用神经网络作为门控网络
这证明了MoE的思想可以跨模型层级使用
"""
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris, load_wine, load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
# ============================================================
# 第1部分:定义专家(传统ML模型)
# ============================================================
class SklearnExpert:
"""将sklearn模型包装为MoE专家"""
def __init__(self, model, name):
self.model = model
self.name = name
self.is_fitted = False
def fit(self, X, y):
self.model.fit(X, y)
self.is_fitted = True
def predict_proba(self, X):
"""返回概率预测"""
if hasattr(self.model, 'predict_proba'):
return self.model.predict_proba(X)
else:
# 如果模型没有predict_proba,用决策函数
preds = self.model.predict(X)
n_classes = len(np.unique(preds))
proba = np.zeros((len(preds), n_classes))
for i, p in enumerate(preds):
proba[i, int(p)] = 1.0
return proba
# ============================================================
# 第2部分:定义门控网络
# ============================================================
class GatingNetwork(nn.Module):
"""
门控网络:决定每个样本应该由哪些专家处理
输入:样本特征
输出:每个专家的权重(Softmax归一化)
"""
def __init__(self, input_dim, num_experts, hidden_dim=32):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, num_experts),
nn.Softmax(dim=-1)
)
def forward(self, x):
return self.net(x)
# ============================================================
# 第3部分:MoE分类器
# ============================================================
class MoEClassifier:
"""
MoE混合专家分类器
工作流程:
1. 每个专家独立训练
2. 门控网络学习如何选择专家
3. 最终预测 = 专家预测的加权和
"""
def __init__(self, experts, gating_hidden_dim=32, lr=0.01, epochs=100):
self.experts = experts
self.num_experts = len(experts)
self.gating_hidden_dim = gating_hidden_dim
self.lr = lr
self.epochs = epochs
self.gating_net = None
def fit(self, X_train, y_train, X_val=None, y_val=None):
"""
训练MoE分类器
步骤1:独立训练每个专家
步骤2:训练门控网络
"""
n_classes = len(np.unique(y_train))
input_dim = X_train.shape[1]
# ========== 步骤1:训练每个专家 ==========
print("步骤1:训练各专家模型...")
for expert in self.experts:
expert.fit(X_train, y_train)
train_pred = expert.model.predict(X_train)
train_acc = accuracy_score(y_train, train_pred)
print(f" {expert.name}: 训练准确率 = {train_acc:.4f}")
# ========== 步骤2:训练门控网络 ==========
print("\n步骤2:训练门控网络...")
# 获取每个专家的概率预测
expert_probas = []
for expert in self.experts:
proba = expert.predict_proba(X_train)
expert_probas.append(proba)
expert_probas = np.array(expert_probas) # [n_experts, n_samples, n_classes]
# 转换为PyTorch张量
X_tensor = torch.FloatTensor(X_train)
y_tensor = torch.LongTensor(y_train)
expert_probas_tensor = torch.FloatTensor(expert_probas)
# 创建门控网络
self.gating_net = GatingNetwork(input_dim, self.num_experts, self.gating_hidden_dim)
optimizer = optim.Adam(self.gating_net.parameters(), lr=self.lr)
# 训练门控网络
for epoch in range(self.epochs):
# 前向传播
gates = self.gating_net(X_tensor) # [n_samples, n_experts]
# 加权组合专家预测
# gates: [n_samples, n_experts]
# expert_probas: [n_experts, n_samples, n_classes]
mixed_proba = torch.zeros(len(X_train), n_classes)
for i in range(self.num_experts):
mixed_proba += gates[:, i:i+1] * expert_probas_tensor[i]
# 计算交叉熵损失
loss = nn.CrossEntropyLoss()(mixed_proba, y_tensor)
# 添加负载均衡损失(防止门控偏爱某些专家)
balance_loss = self._load_balance_loss(gates)
total_loss = loss + 0.01 * balance_loss
# 反向传播
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
with torch.no_grad():
pred = mixed_proba.argmax(dim=1)
acc = accuracy_score(y_train, pred.numpy())
print(f" Epoch {epoch+1}/{self.epochs}: "
f"Loss={total_loss.item():.4f}, Acc={acc:.4f}")
# 打印门控统计
self._print_gate_stats(X_train)
return self
def predict(self, X):
"""预测"""
# 获取每个专家的预测
expert_probas = []
for expert in self.experts:
proba = expert.predict_proba(X)
expert_probas.append(proba)
expert_probas = np.array(expert_probas)
# 获取门控权重
X_tensor = torch.FloatTensor(X)
with torch.no_grad():
gates = self.gating_net(X_tensor).numpy()
# 加权组合
mixed_proba = np.zeros((len(X), expert_probas.shape[2]))
for i in range(self.num_experts):
mixed_proba += gates[:, i:i+1] * expert_probas[i]
return mixed_proba.argmax(axis=1)
def _load_balance_loss(self, gates):
"""负载均衡损失"""
f = (gates > 1e-6).float().mean(dim=0)
P = gates.mean(dim=0)
return self.num_experts * (f * P).sum()
def _print_gate_stats(self, X):
"""打印门控统计信息"""
X_tensor = torch.FloatTensor(X)
with torch.no_grad():
gates = self.gating_net(X_tensor).numpy()
print(f"\n 门控权重统计:")
avg_gates = gates.mean(axis=0)
for i, expert in enumerate(self.experts):
print(f" {expert.name}: 平均权重 = {avg_gates[i]:.4f}")
# ============================================================
# 第4部分:运行实验
# ============================================================
def run_experiment(dataset_name, dataset_loader):
"""运行一个完整的MoE分类实验"""
print(f"\n{'='*60}")
print(f"数据集: {dataset_name}")
print(f"{'='*60}")
# 加载数据
data = dataset_loader()
X, y = data.data, data.target
# 数据预处理
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 定义专家
experts = [
SklearnExpert(GradientBoostingClassifier(n_estimators=50, random_state=42),
"XGBoost/GBM"),
SklearnExpert(RandomForestClassifier(n_estimators=50, random_state=42),
"RandomForest"),
SklearnExpert(SVC(probability=True, random_state=42),
"SVM"),
SklearnExpert(KNeighborsClassifier(n_neighbors=5),
"KNN"),
SklearnExpert(LogisticRegression(max_iter=1000, random_state=42),
"LogisticReg"),
]
# ========== 对比:单独专家 vs MoE ==========
print(f"\n--- 单独专家性能 ---")
for expert in experts:
expert.fit(X_train, y_train)
pred = expert.model.predict(X_test)
acc = accuracy_score(y_test, pred)
print(f" {expert.name}: 测试准确率 = {acc:.4f}")
print(f"\n--- MoE集成性能 ---")
moe = MoEClassifier(experts, gating_hidden_dim=32, lr=0.01, epochs=100)
moe.fit(X_train, y_train)
moe_pred = moe.predict(X_test)
moe_acc = accuracy_score(y_test, moe_pred)
print(f"\n MoE测试准确率 = {moe_acc:.4f}")
# 对比
print(f"\n--- 对比总结 ---")
print(f" {'模型':<20} {'准确率':>10}")
print(f" {'-'*30}")
for expert in experts:
pred = expert.model.predict(X_test)
acc = accuracy_score(y_test, pred)
print(f" {expert.name:<20} {acc:>10.4f}")
print(f" {'MoE(本方法)':<20} {moe_acc:>10.4f}")
# 主程序
if __name__ == "__main__":
print("=" * 60)
print("MoE混合专家 - 传统ML分类实验")
print("=" * 60)
# 实验1:Iris数据集
run_experiment("Iris", load_iris)
# 实验2:Wine数据集
run_experiment("Wine", load_wine)
# 实验3:Digits数据集(更大更复杂)
run_experiment("Digits", load_digits)
print(f"\n{'='*60}")
print("总结")
print(f"{'='*60}")
print("""
MoE在传统ML中的价值:
1. 不同专家擅长不同类型的数据模式
2. 门控网络学习"什么数据交给什么模型"
3. 自适应集成比简单平均更智能
4. 可解释性强:可以看到每个样本分配给了哪个专家
与传统集成学习的区别:
- 集成学习(如Voting/Stacking):所有模型都参与预测
- MoE:只选择最相关的专家参与预测
- MoE的计算效率更高(不需要运行所有模型)
""")6.3 实战:MoE用于回归任务
python
# moe_regression.py
"""
MoE混合专家用于回归任务
展示MoE如何在不同数据分布区域自动选择最优模型
"""
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import StandardScaler
class MoERegressor:
"""MoE回归器"""
def __init__(self, experts, hidden_dim=32, lr=0.01, epochs=200):
self.experts = experts
self.num_experts = len(experts)
self.hidden_dim = hidden_dim
self.lr = lr
self.epochs = epochs
self.gating_net = None
def fit(self, X, y, X_val=None, y_val=None):
input_dim = X.shape[1]
# 训练专家
for expert in self.experts:
expert['model'].fit(X, y)
# 获取专家预测
expert_preds = np.column_stack([
expert['model'].predict(X) for expert in self.experts
])
# 训练门控网络
self.gating_net = nn.Sequential(
nn.Linear(input_dim, self.hidden_dim),
nn.ReLU(),
nn.Linear(self.hidden_dim, self.hidden_dim),
nn.ReLU(),
nn.Linear(self.hidden_dim, self.num_experts),
nn.Softmax(dim=-1)
)
optimizer = optim.Adam(self.gating_net.parameters(), lr=self.lr)
X_t = torch.FloatTensor(X)
y_t = torch.FloatTensor(y)
expert_t = torch.FloatTensor(expert_preds)
for epoch in range(self.epochs):
gates = self.gating_net(X_t)
# 加权组合
pred = (gates * expert_t).sum(dim=1)
# MSE损失
loss = nn.MSELoss()(pred, y_t)
# 负载均衡
balance = self.num_experts * (gates.mean(0) * (gates > 0.01).float().mean(0)).sum()
optimizer.zero_grad()
(loss + 0.001 * balance).backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
print(f" Epoch {epoch+1}: MSE={loss.item():.4f}")
return self
def predict(self, X):
expert_preds = np.column_stack([
expert['model'].predict(X) for expert in self.experts
])
X_t = torch.FloatTensor(X)
with torch.no_grad():
gates = self.gating_net(X_t).numpy()
return (gates * expert_preds).sum(axis=1)
def get_gate_weights(self, X):
X_t = torch.FloatTensor(X)
with torch.no_grad():
return self.gating_net(X_t).numpy()
# 运行回归实验
if __name__ == "__main__":
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
# 生成非均匀数据(不同区域适合不同模型)
np.random.seed(42)
X = np.random.randn(500, 5)
y = np.zeros(500)
# 区域1:线性关系
mask1 = X[:, 0] > 0
y[mask1] = 2 * X[mask1, 0] + X[mask1, 1]
# 区域2:非线性关系
mask2 = X[:, 0] <= 0
y[mask2] = X[mask2, 0]**2 + 3 * X[mask2, 2]
y += np.random.randn(500) * 0.1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
experts = [
{'name': 'Linear', 'model': LinearRegression()},
{'name': 'Ridge', 'model': Ridge(alpha=1.0)},
{'name': 'GBM', 'model': GradientBoostingRegressor(n_estimators=50)},
{'name': 'RF', 'model': RandomForestRegressor(n_estimators=50)},
]
# 单独专家
print("单独专家性能:")
for exp in experts:
exp['model'].fit(X_train, y_train)
pred = exp['model'].predict(X_test)
mae = mean_absolute_error(y_test, pred)
print(f" {exp['name']}: MAE={mae:.4f}")
# MoE
print("\nMoE训练:")
moe = MoERegressor(experts, hidden_dim=32, lr=0.01, epochs=200)
moe.fit(X_train, y_train)
moe_pred = moe.predict(X_test)
moe_mae = mean_absolute_error(y_test, moe_pred)
print(f"\nMoE测试MAE: {moe_mae:.4f}")
# 门控分析
print("\n门控权重分析(前10个测试样本):")
gates = moe.get_gate_weights(X_test[:10])
for i in range(10):
weights = " | ".join([f"{exp['name']}={gates[i,j]:.2f}" for j, exp in enumerate(experts)])
true_region = "线性" if X_test[i, 0] > 0 else "非线性"
print(f" 样本{i} ({true_region}): {weights}")6.4 MoE在传统ML中的总结
MoE在传统ML中的应用方式:
┌─────────────────────────────────────────────┐
│ MoE在传统ML中的架构 │
│ │
│ 输入 x │
│ │ │
│ ├──→ 专家1 (XGBoost) ──→ 预测1 │
│ ├──→ 专家2 (SVM) ──→ 预测2 │
│ ├──→ 专家3 (KNN) ──→ 预测3 │
│ │ │
│ └──→ 门控网络 ──→ 权重[w1,w2,w3] │
│ ↓ │
│ 最终预测 = w1×预测1 + w2×预测2 + w3×预测3 │
└─────────────────────────────────────────────┘
与传统集成方法的区别:
- Bagging:所有模型等权投票
- Boosting:模型按顺序训练,逐步修正
- Stacking:用一个元模型组合,但对所有样本用相同的组合方式
- MoE:用门控网络对每个样本自适应选择专家(最灵活)第七章:MoE在传统深度学习中的应用
7.1 MoE + LSTM
python
# moe_lstm.py
"""
MoE-LSTM:用多个LSTM专家处理不同模式的时序数据
应用场景:
- 不同类型的时序模式(趋势、季节性、突变)
- 不同频率的数据(高频噪声 vs 低频信号)
- 多源传感器数据融合
"""
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class LSTMExpert(nn.Module):
"""LSTM专家:处理时序数据"""
def __init__(self, input_dim, hidden_dim, output_dim, n_layers=1):
super().__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, n_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x: [batch, seq_len, input_dim]
lstm_out, _ = self.lstm(x)
# 取最后一个时间步
last_out = lstm_out[:, -1, :]
return self.fc(last_out)
class MoELSTM(nn.Module):
"""
MoE-LSTM模型
多个LSTM专家 + 门控网络
门控网络根据输入序列的特征选择最合适的专家
"""
def __init__(self, input_dim, hidden_dim, output_dim,
num_experts=4, gating_hidden=32):
super().__init__()
# 多个LSTM专家
self.experts = nn.ModuleList([
LSTMExpert(input_dim, hidden_dim, output_dim)
for _ in range(num_experts)
])
# 门控网络
self.gating = nn.Sequential(
nn.Linear(input_dim, gating_hidden),
nn.ReLU(),
nn.Linear(gating_hidden, num_experts),
nn.Softmax(dim=-1)
)
self.num_experts = num_experts
def forward(self, x):
"""
x: [batch, seq_len, input_dim]
"""
# 门控:用序列的最后一个时间步来决定专家权重
gate_input = x[:, -1, :] # [batch, input_dim]
gates = self.gating(gate_input) # [batch, num_experts]
# 每个专家的预测
expert_outputs = []
for expert in self.experts:
out = expert(x) # [batch, output_dim]
expert_outputs.append(out)
expert_outputs = torch.stack(expert_outputs, dim=1) # [batch, num_experts, output_dim]
# 加权组合
gates = gates.unsqueeze(-1) # [batch, num_experts, 1]
output = (gates * expert_outputs).sum(dim=1) # [batch, output_dim]
return output, gates.squeeze(-1)
# 测试
if __name__ == "__main__":
# 创建模拟数据
batch_size = 32
seq_len = 10
input_dim = 5
output_dim = 1
x = torch.randn(batch_size, seq_len, input_dim)
y = torch.randn(batch_size, output_dim)
# 创建模型
model = MoELSTM(input_dim, hidden_dim=32, output_dim=output_dim, num_experts=4)
# 训练
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(100):
pred, gates = model(x)
loss = nn.MSELoss()(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch {epoch+1}: Loss={loss.item():.4f}")
print(f" 专家权重均值: {gates.mean(0).detach().numpy()}")7.2 MoE + CNN
python
# moe_cnn.py
"""
MoE-CNN:用多个CNN专家处理不同类型的图像特征
应用场景:
- 不同尺度的特征(纹理、形状、语义)
- 不同领域的图像(医学影像、自然图像、卫星图像)
- 多任务学习
"""
import torch
import torch.nn as nn
import torch.optim as optim
class CNNExpert(nn.Module):
"""CNN专家"""
def __init__(self, in_channels, num_classes):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels, 16, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, 3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d(4),
)
self.classifier = nn.Sequential(
nn.Linear(32 * 4 * 4, 64),
nn.ReLU(),
nn.Linear(64, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
return self.classifier(x)
class MoECNN(nn.Module):
"""MoE-CNN模型"""
def __init__(self, in_channels, num_classes, num_experts=4):
super().__init__()
self.experts = nn.ModuleList([
CNNExpert(in_channels, num_classes)
for _ in range(num_experts)
])
# 门控网络:用全局平均池化后的特征
self.gating = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(in_channels, 32),
nn.ReLU(),
nn.Linear(32, num_experts),
nn.Softmax(dim=-1)
)
self.num_experts = num_experts
def forward(self, x):
gates = self.gating(x) # [batch, num_experts]
expert_outputs = []
for expert in self.experts:
out = expert(x) # [batch, num_classes]
expert_outputs.append(out)
expert_outputs = torch.stack(expert_outputs, dim=1)
gates = gates.unsqueeze(-1)
output = (gates * expert_outputs).sum(dim=1)
return output, gates.squeeze(-1)
# 测试
if __name__ == "__main__":
batch_size = 16
in_channels = 3
num_classes = 10
x = torch.randn(batch_size, in_channels, 32, 32)
y = torch.randint(0, num_classes, (batch_size,))
model = MoECNN(in_channels, num_classes, num_experts=4)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(100):
pred, gates = model(x)
loss = nn.CrossEntropyLoss()(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
acc = (pred.argmax(1) == y).float().mean()
print(f"Epoch {epoch+1}: Loss={loss.item():.4f}, Acc={acc:.4f}")
print(f" 专家权重均值: {gates.mean(0).detach().numpy()}")7.3 MoE + MLP(最基础的实现)
python
# moe_mlp.py
"""
MoE-MLP:最基础的MoE实现
用全连接网络作为专家,用于理解MoE的核心机制
这是理解MoE的最佳入门代码
"""
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class MLPExpert(nn.Module):
"""MLP专家"""
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
)
def forward(self, x):
return self.net(x)
class SimpleMoE(nn.Module):
"""
最简单的MoE实现
结构:
- N个MLP专家
- 1个门控网络
- Top-K稀疏选择
"""
def __init__(self, input_dim, hidden_dim, output_dim,
num_experts=4, top_k=2):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
# 专家网络
self.experts = nn.ModuleList([
MLPExpert(input_dim, hidden_dim, output_dim)
for _ in range(num_experts)
])
# 门控网络
self.gate = nn.Linear(input_dim, num_experts)
def forward(self, x):
# 计算门控分数
gate_logits = self.gate(x) # [batch, num_experts]
# Top-K选择
top_k_logits, top_k_indices = gate_logits.topk(self.top_k, dim=-1)
top_k_gates = torch.softmax(top_k_logits, dim=-1)
# 构造稀疏门控向量
gates = torch.zeros_like(gate_logits)
gates.scatter_(1, top_k_indices, top_k_gates)
# 计算每个专家的输出
expert_outputs = torch.stack([
expert(x) for expert in self.experts
], dim=1) # [batch, num_experts, output_dim]
# 加权组合
gates = gates.unsqueeze(-1) # [batch, num_experts, 1]
output = (gates * expert_outputs).sum(dim=1)
return output, gates.squeeze(-1)
# 测试
if __name__ == "__main__":
# 生成非均匀数据
np.random.seed(42)
X = np.random.randn(1000, 10).astype(np.float32)
y = np.zeros(1000, dtype=np.float32)
# 不同区域不同关系
mask = X[:, 0] > 0
y[mask] = np.sin(X[mask, 1]) + X[mask, 2]
y[~mask] = X[~mask, 3]**2 - X[~mask, 4]
y += np.random.randn(1000) * 0.1
X_train = torch.FloatTensor(X[:800])
y_train = torch.FloatTensor(y[:800]).unsqueeze(1)
X_test = torch.FloatTensor(X[800:])
y_test = torch.FloatTensor(y[800:]).unsqueeze(1)
model = SimpleMoE(10, 32, 1, num_experts=4, top_k=2)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(200):
pred, gates = model(X_train)
loss = nn.MSELoss()(pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
with torch.no_grad():
test_pred, _ = model(X_test)
test_loss = nn.MSELoss()(test_pred, y_test)
print(f"Epoch {epoch+1}: Train Loss={loss.item():.4f}, Test Loss={test_loss.item():.4f}")
print(f" 专家使用率: {(gates > 0).float().mean(0).detach().numpy()}")第八章:MoE训练实战------从零实现
8.1 完整的MoE训练流程
python
# moe_training_complete.py
"""
完整的MoE训练流程
从数据准备到模型训练到评估,包含所有关键技巧
"""
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class MoELayer(nn.Module):
"""
MoE层:可以插入到任何神经网络中
关键特性:
1. Top-K稀疏门控
2. 负载均衡损失
3. 噪声门控(训练时)
"""
def __init__(self, input_dim, output_dim, num_experts=8, top_k=2,
noise_std=0.1, balance_coef=0.01):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
self.noise_std = noise_std
self.balance_coef = balance_coef
# 专家网络
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(input_dim, input_dim * 2),
nn.GELU(),
nn.Linear(input_dim * 2, output_dim),
)
for _ in range(num_experts)
])
# 门控网络
self.gate = nn.Linear(input_dim, num_experts)
def forward(self, x):
# 门控分数
gate_logits = self.gate(x)
# 训练时添加噪声(促进探索)
if self.training:
noise = torch.randn_like(gate_logits) * self.noise_std
gate_logits = gate_logits + noise
# Top-K选择
top_k_logits, top_k_indices = gate_logits.topk(self.top_k, dim=-1)
top_k_gates = torch.softmax(top_k_logits, dim=-1)
# 稀疏门控
gates = torch.zeros_like(gate_logits)
gates.scatter_(1, top_k_indices, top_k_gates)
# 专家计算(只计算被选中的专家)
expert_outputs = []
for i, expert in enumerate(self.experts):
# 创建mask:只对选中了这个专家的样本做计算
mask = (top_k_indices == i).any(dim=-1)
if mask.any():
out = expert(x[mask])
expert_outputs.append((mask, out))
# 合并输出
output = torch.zeros(x.size(0), self.experts[0][-1].out_features,
device=x.device)
for mask, out in expert_outputs:
output[mask] += (gates[mask] * out.unsqueeze(1)).sum(dim=1)
# 负载均衡损失
if self.training:
self.aux_loss = self._compute_balance_loss(gates)
else:
self.aux_loss = 0.0
return output
def _compute_balance_loss(self, gates):
"""计算负载均衡损失"""
f = (gates > 1e-6).float().mean(dim=0)
P = gates.mean(dim=0)
return self.balance_coef * self.num_experts * (f * P).sum()
# 测试完整训练流程
if __name__ == "__main__":
# 模拟数据
torch.manual_seed(42)
X = torch.randn(500, 32)
y = torch.randn(500, 1)
# 创建带MoE层的模型
model = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
MoELayer(64, 64, num_experts=8, top_k=2), # MoE层
nn.ReLU(),
nn.Linear(64, 1),
)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(200):
pred = model(X)
# 主损失
main_loss = nn.MSELoss()(pred, y)
# MoE的辅助损失(负载均衡)
aux_loss = model[2].aux_loss # 获取MoE层的辅助损失
total_loss = main_loss + aux_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
print(f"Epoch {epoch+1}: Main Loss={main_loss.item():.4f}, "
f"Aux Loss={aux_loss.item() if isinstance(aux_loss, torch.Tensor) else aux_loss:.4f}")第九章:MoE算法选型与最佳实践
9.1 MoE变体对比
MoE变体对比:
变体 选择策略 负载均衡 训练稳定性 适用场景
─────────────────────────────────────────────────────────
Top-K MoE Top-K选择 需要辅助损失 中等 通用
Switch MoE Top-1选择 容量因子 好 大规模预训练
Expert Choice 专家选Token 天然均衡 好 训练稳定性优先
Soft MoE 软权重 天然均衡 最好 微调、小模型
Hash MoE 哈希映射 天然均衡 好 极简实现9.2 何时使用MoE?
MoE适合的场景:
✓ 模型需要处理多样化的输入(不同类型的数据模式)
✓ 需要在有限计算预算下增大模型容量
✓ 多任务学习(不同专家专注不同任务)
✓ 数据有明显的聚类结构
✓ 推理时需要高吞吐量
MoE不适合的场景:
✗ 数据量非常小(专家学不到有意义的分工)
✗ 所有输入都相似(没有需要不同专家的理由)
✗ 对推理延迟极其敏感(门控引入额外延迟)
✗ 部署环境内存极度受限(总参数量大)9.3 超参数选择指南
专家数量(N):
- 入门:4-8个专家
- 大模型:8-64个专家
- 经验法则:N越大效果越好,但收益递减
Top-K:
- K=1:最稀疏,计算最少,但可能不稳定
- K=2:最常用,平衡效果和效率
- K=4:更稳定,但计算量增加
负载均衡系数(α):
- 太小(<0.001):负载不均衡
- 太大(>0.1):可能损害模型效果
- 推荐:0.01
隐藏维度:
- 通常和输入维度相同
- 可以比输入维度大2-4倍(增加专家容量)附录:术语表与参考资料
术语表
MoE: Mixture of Experts,混合专家模型
Top-K: 只选择分数最高的K个专家
门控网络(Gating Network): 决定每个输入分配给哪些专家
专家(Expert): MoE中的子网络,专注于特定模式
负载均衡(Load Balancing): 确保各专家被均匀使用
容量因子(Capacity Factor): 控制每个专家最多处理的token数
Expert Parallelism: 不同专家放在不同GPU上并行计算
Sparse MoE: 稀疏激活的MoE(每次只激活少数专家)
Dense MoE: 所有专家都参与计算(少见)
Router: 门控网络的另一种称呼参考论文
1. Jacobs et al., "Adaptive Mixtures of Local Experts", 1991
2. Shazeer et al., "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer", 2017
3. Lepikhin et al., "GShard: Scaling Giant Models with Conditional Computation", 2020
4. Fedus et al., "Switch Transformers: Scaling to Trillion Parameter Models", 2021
5. Zoph et al., "ST-MoE: Designing Stable and Transferable Sparse Expert Models", 2022
6. Jiang et al., "Mixtral of Experts", 2024
7. Zhou et al., "Mixture-of-Experts with Expert Choice Routing", 2022
8. Puigcerver et al., "From Sparse to Soft Mixtures of Experts", 2023