文章目录
GraphAPI之Graph(图)
定义
- 图是一种由节点和边组成的用于描述节点之间关系的数据结构,分为无向图和有向图。
- 有向图是带有方向的图,LangGraph通过有向图定义AI工作流中的执行步骤和执行顺序,从而实现复杂、有状态、可循环的应用程序逻辑。
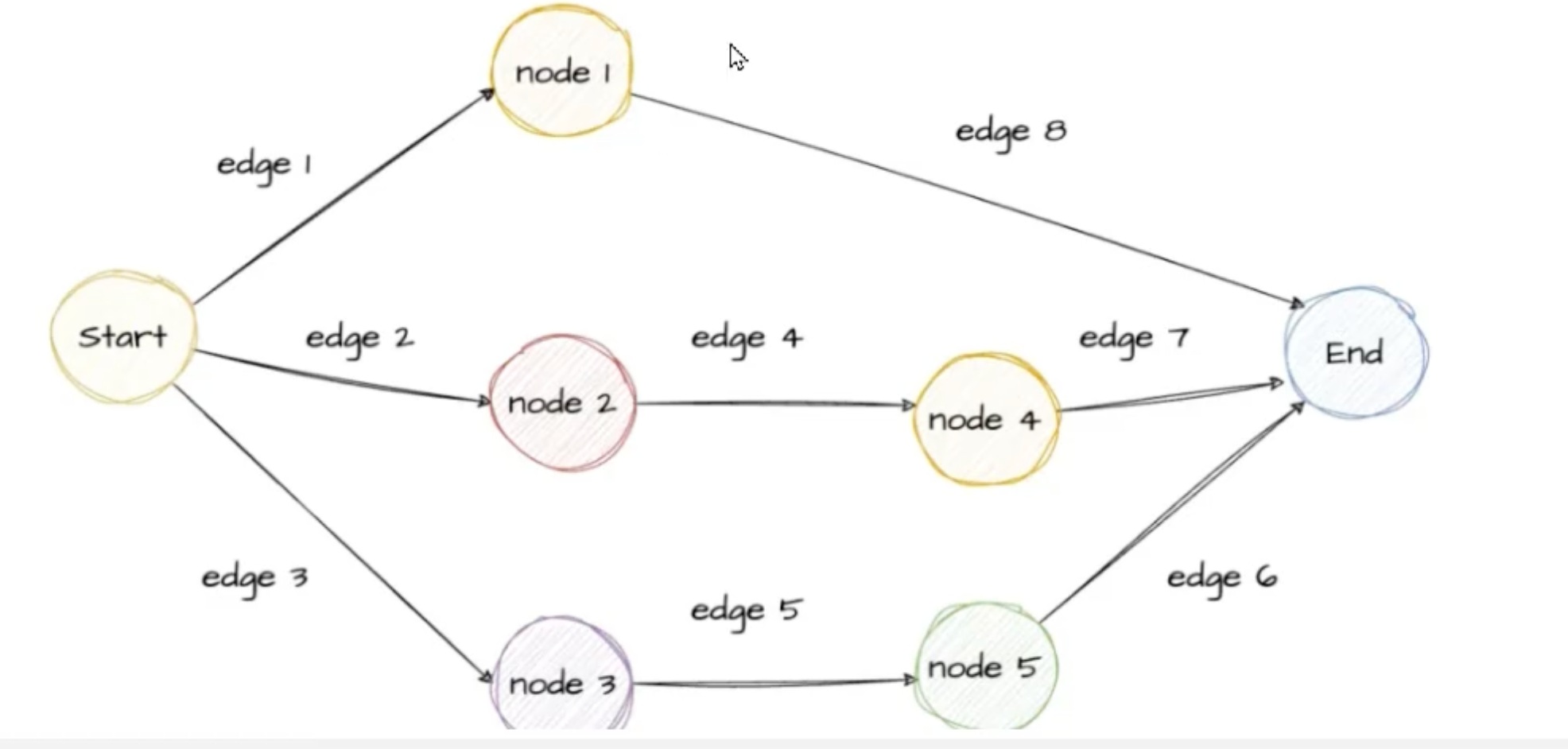
核心
- State(状态):图的全局上下文。你可以把它理解为图的"共享内存"。所有的节点都可以读取和修改这个状态。
- Nodes(节点) :代表具体的执行步骤(通常是一个 Python 函数或工具)。每个节点接收当前的
State,执行某些逻辑(如调用大模型、查询数据库),然后返回更新后的State。 - Edges(边):定义了节点之间的流转方向和控制流。
构建流程
- 定义状态(可选,但推荐)
- 定义各节点(节点就是方法)
- 初始化一个StateGraph实例
- 添加节点
- 添加边(将所有的节点连接起来)
- 编译图
- 执行工作流
java
from typing import TypedDict
from langgraph.constants import START, END
from langgraph.graph import StateGraph
# 1. 定义State(可选,但推荐)
class GraphState(TypedDict):
process_data: dict
# 2.定义节点Node
def input_node(graph_state: GraphState) -> GraphState:
print(f'input_node: {graph_state["process_data"]}')
return {"process_data": {"input": "111"}}
def process_node(graph_state: GraphState) -> GraphState:
print(f'process_node: {graph_state["process_data"]}')
return {"process_data": {"input": "222"}}
def output_node(graph_state: GraphState) -> GraphState:
print(f'output_node: {graph_state["process_data"]}')
return {"process_data": {"output": "333"}}
# 4.构建图Graph
graph = StateGraph(GraphState)
# 4.1 添加节点
graph.add_node("input_node", input_node)
graph.add_node("process_node", process_node)
graph.add_node("output_node", output_node)
graph.add_edge(START, "input_node")
graph.add_edge("input_node", "process_node")
graph.add_edge("process_node", "output_node")
graph.add_edge("output_node", END)
# 5.编译
app = graph.compile()
# 6.运行
result = app.invoke({"process_data": {"input": "xxx"}})
print(result)GraphAPI之State(状态)
定义
State状态是整个图的基石,图的"共享内存",类似于全局上下文,所有的节点都能读写这个状态。
在 LangGraph 中,通常使用 Python 的 TypedDict 或 Pydantic 的 BaseModel来定义状态。
java
方式 A:使用 TypedDict(最常用、最轻量)
from typing import TypedDict
class MyGraphState(TypedDict):
input_query: str
generation: str
steps_count: int
方式 B:使用 Pydantic(适合需要数据校验、类型转换的复杂场景)
from pydantic import BaseModel, Field
class MyPydanticState(BaseModel):
input_query: str
generation: str = ""
# 提供默认值和校验
steps_count: int = Field(default=0, ge=0)在LangGraph中,State状态是一个贯穿整个工作流执行过程中的共享数据的结构 ,代表当前快照,它存储了从工作流开始到结束的所有必要的信息(历史对话、检索到的文档、工具执行结果等)。状态在各个节点中共享,且每个节点都可以修改,状态包含两部分:
- 图的模式(schema)
- 规约函数(reducer functions):指明如何把更新应用到状态上。图的schema

包含:
- state_schema
定义:图的完整内部状态,包含了所有节点可能读写的字段,必须指定,不能为空
特点:
1. 是图的"全局状态空间"
2. 所有节点都可以访问和写入这个schema中的任何字段- input_schema
定义:定义图接受什么输入,是state_schema的子集
特点:
1. 可选参数,如果不指定,默认等于state_schema
2. 限制图的输入接口,只能传入这些字段- output_schema
定义:定义图返回什么输出,是state_schema的子集
特点:
1. 可选参数,如果不指定,默认等于state_schema
2. 限制图的输出接口,只返回这些字段学术上指定3种schema,但实践过程中只使用state_schema即可
图的Reducer
- 定义
**规约函数决定了节点产生的重新如何作用到State,State中的每个字段都拥有自己的独立规约函数。规约函数有多种类型,如果未显式指定,则默认所有对该字段的更新都会直接覆盖**旧值。
一句话:规约函数就是字段级合并策略,它让节点只需吐出增量,框架负责按规则把增量写入全局状态State
常见合并策略:
-
default:默认,覆盖更新
-
add_messages:消息列表追加
-
operator.add:将元素追加到现有元素中,支持列表、字符串、数值类型的追
-
operator.mul:用于数值相乘
-
自定义Reducer: 支持用户自定义合并逻辑
-
案例
java
from typing import TypedDict, List
from langgraph.constants import START, END
from langgraph.graph import StateGraph
# 需求:如果未指定reducer函数,默认对该字段进行覆盖行为
# 1. 定义State
# 未指定合并策略reducer,默认覆盖
class DefaultReducerState(TypedDict):
name: str
hobby: List[str]
# 2.定义节点Node
def node_1(state: DefaultReducerState) -> dict:
print(f'node_1: {state["name"]}')
print(f'node_1: {state["hobby"]}')
return {"name": "Alice", "hobby": ["篮球"]}
def node_2(state: DefaultReducerState) -> dict:
print(f'node_2: {state["name"]}')
print(f'node_2: {state["hobby"]}')
return {"name": "Bob", "hobby": ["足球", "乒乓球"]}
# 4.构建图Graph
graph = StateGraph(DefaultReducerState)
# 4.1 添加节点
graph.add_node("node_1", node_1)
graph.add_node("node_2", node_2)
graph.add_edge(START, "node_1")
graph.add_edge("node_1", "node_2")
graph.add_edge("node_2", END)
# 5.编译
app = graph.compile()
# 6.运行
result = app.invoke({"name": "Alice", "hobby": ["nothing"]})
print(result)
BN最佳实践建议
- 按需使用 Annotated: 只有需要历史留痕(如 messages、logs)或需要累加的字段才加 Reducer,其余字段(如状态开关、临时变量)保持默认的覆盖模式。
- 结构清晰: 即使使用TypedDict,也尽量为字段写好类型注解,配合 IDE(如 VSCode/PyCharm)的类型推导,编写节点时能极大减少因拼错 key 导致的 Bug。
- 不要在节点内直接修改输入: 始终通过return {"key": "value" 的方式让 LangGraph 去更新状态,不要在节点内部做类似state"list".append(x) 的原位修改(In-place mutation),这会导致时间旅行(Time Travel)和调试功能失效。