前言
数据并行(DDP)是最常用的并行策略:每张 GPU 复制一份完整的模型,各拿一份不同的数据,算完梯度后做一次 AllReduce 同步。
DDP 的问题在于冗余。每张 GPU 上都保存着完整的模型参数、梯度和优化器状态。一个 7B 模型用 Adam 优化器训练,每卡至少需要 122 GB 显存。如果你用 8 张卡做 DDP,总共消耗 8 × 122 = 976 GB,但其中 87.5% 是完全重复的数据。
DeepSpeed 的 ZeRO 优化和 PyTorch 的 FSDP 就是为了解决这个冗余问题而生的。它们的核心思路一样:把重复的部分切分到不同 GPU 上,每张卡只保留 1/N 的状态,需要时再临时收集。
一、DDP 的显存冗余到底有多大
先把 7B 模型 FP16 训练的显存构成再看一遍,这次从"冗余"的角度看:
| 组成部分 | 每卡大小 | 8 卡 DDP 总大小 | 真正需要的 |
|---|---|---|---|
| 模型参数(FP16) | 14 GB | 112 GB | 14 GB |
| 梯度(FP16) | 14 GB | 112 GB | 14 GB |
| 优化器状态(Adam) | 84 GB | 672 GB | 84 GB |
| 合计 | 112 GB | 896 GB | 112 GB |
8 张卡一共用了 896 GB,但真正不同的数据只有 112 GB。冗余比例 87.5%。GPU 越多,浪费越严重。
ZeRO(Zero Redundancy Optimizer)的名字就来源于此:目标是把冗余降到零。
二、DeepSpeed ZeRO 三阶段
DeepSpeed 是微软开发的分布式训练框架,其核心创新是 ZeRO 优化,分三个阶段逐步消除冗余。
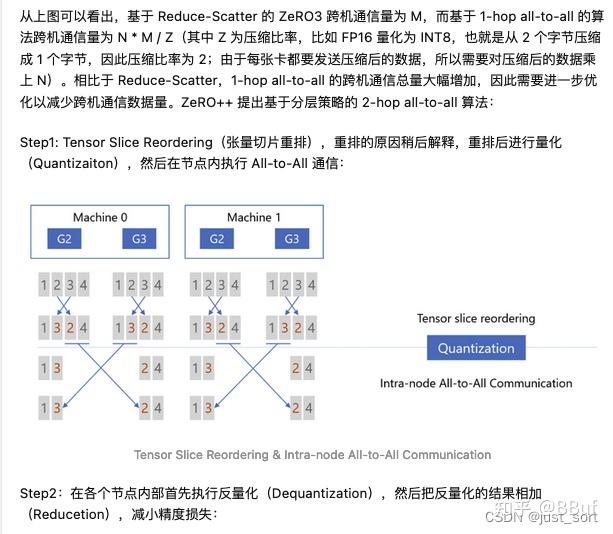
图1:ZeRO 三个阶段。Stage 1 切分优化器状态,Stage 2 进一步切分梯度,Stage 3 连模型参数也切分。切得越多越省显存,但通信开销也越大。
2.1 ZeRO-1:切分优化器状态
原理:把 Adam 优化器的状态(FP32 参数副本、一阶动量 m、二阶动量 v)平均分成 N 份,每张 GPU 只保存 1/N。模型参数和梯度仍然保持完整。
传统 DDP(8 卡):
GPU 0: 参数(14GB) + 梯度(14GB) + 优化器(84GB) = 112 GB
GPU 1: 参数(14GB) + 梯度(14GB) + 优化器(84GB) = 112 GB
...(每张卡完全一样)
ZeRO-1(8 卡):
GPU 0: 参数(14GB) + 梯度(14GB) + 优化器(84/8=10.5GB) = 38.5 GB
GPU 1: 参数(14GB) + 梯度(14GB) + 优化器(10.5GB) = 38.5 GB
...(优化器状态各不相同)显存节省 :优化器状态从 84 GB 降到 10.5 GB,每卡显存从 112 GB 降到约 38.5 GB。相比 DDP 省了约 4 倍的优化器状态开销。
通信开销:和 DDP 一样是 2Φ(Φ = 模型参数量),不增加额外通信。因为反向传播后仍然用 AllReduce 同步梯度,只是各 GPU 只用自己的那份优化器状态更新自己负责的那部分参数,然后通过 AllGather 同步更新后的参数。
适用场景 :模型参数 + 梯度能放进单卡,但优化器状态太大。这是性价比最高的阶段。
2.2 ZeRO-2:切分优化器状态 + 梯度
原理 :在 Stage 1 基础上,进一步把梯度也切分。反向传播时,不再用 AllReduce 同步完整梯度,而是用 ReduceScatter------每个 GPU 只保留自己负责的那部分参数的归约梯度。
ZeRO-2(8 卡):
GPU 0: 参数(14GB) + 梯度(14/8=1.75GB) + 优化器(10.5GB) = 26.25 GB
GPU 1: 参数(14GB) + 梯度(1.75GB) + 优化器(10.5GB) = 26.25 GB
...(梯度和优化器状态各不相同)显存节省 :每卡约 26.25 GB,相比 DDP 省了约 4 倍(112 → 26 GB)。相比 Stage 1 再省掉梯度的冗余。
通信开销:仍然是 2Φ。ReduceScatter 替代了 AllReduce,通信量相同,只是每个 GPU 最后只保留 1/N 的梯度而非完整梯度。
适用场景 :大多数场景的默认推荐。通信量不增加,显存进一步降低。
2.3 ZeRO-3:切分优化器状态 + 梯度 + 参数
原理 :把模型参数也切分到 N 张 GPU 上,每张卡只保存 1/N 的参数。前向和反向计算时,需要临时用 AllGather 收集完整参数,计算完立刻丢弃,只保留本地那份。
这个策略可以用一句话概括:"边借边算边还"------向前一个 layer 借参数、计算、还回去,再借下一个 layer 的。
ZeRO-3(8 卡):
GPU 0: 参数(14/8=1.75GB) + 梯度(1.75GB) + 优化器(10.5GB) = 14 GB
GPU 1: 参数(1.75GB) + 梯度(1.75GB) + 优化器(10.5GB) = 14 GB
...(参数、梯度、优化器状态各不相同)显存节省 :每卡约 14 GB。理论上显存和 GPU 数量成反比------N 卡就省 N 倍。8 卡时从 112 GB 降到 14 GB,64 卡时降到约 1.75 GB(仅状态部分)。
通信开销 :增加到约 3Φ。因为前向和反向各需要一次 AllGather 参数,加上反向后的 ReduceScatter 梯度。相比 Stage 1/2 的 2Φ 多了 50%。
适用场景:模型参数本身也放不进单卡时(比如 13B、70B 模型)。代价是通信量增加,需要 NVLink 级别的带宽才不会成为瓶颈。
三阶段通信量速查表
| 阶段 | 切分内容 | 每卡显存(7B/8卡) | 通信量 | 额外通信 |
|---|---|---|---|---|
| DDP(基线) | 无 | 112 GB | 2Φ | --- |
| ZeRO-1 | 优化器状态 | 38.5 GB | 2Φ | 无 |
| ZeRO-2 | 优化器 + 梯度 | 26.25 GB | 2Φ | 无 |
| ZeRO-3 | 优化器 + 梯度 + 参数 | 14 GB | ~3Φ | +50% |
选型判断:模型参数 + 梯度能放进单卡 → 用 ZeRO-2(零额外通信成本);模型参数本身放不下 → 用 ZeRO-3(通信增加但能训练更大的模型)。
三、ZeRO-Offload 与 ZeRO-Infinity
即使 ZeRO-3 把显存压缩到极限,有些场景仍然不够用。比如在消费级 GPU(RTX 4090,24 GB)上微调 7B 模型,或者用少量 GPU 训练 70B 模型。DeepSpeed 提供了两种"越界"方案。
ZeRO-Offload:用 CPU 内存换 GPU 显存
核心思路:把优化器状态和参数更新计算卸载到 CPU 内存上。GPU 只负责前向和反向传播(计算密集),优化器更新(内存密集)交给 CPU 做。
GPU 显存: 参数 + 梯度 + 激活值 ← 计算密集的部分留在 GPU
CPU 内存: 优化器状态 + FP32 参数副本 ← 内存密集的部分搬到 CPU
PCIe 通道: GPU ← → CPU 之间异步传输更新后的参数DeepSpeed 通过异步流水线隐藏传输延迟:当 GPU 在算第 k+1 层的反向传播时,CPU 同时在更新第 k 层的参数,PCIe 同时在传输第 k-1 层更新好的参数。三者重叠,PCIe 的带宽瓶颈被有效掩盖。
ZeRO-Infinity:三层存储层次
ZeRO-Infinity 在 Offload 基础上更进一步,构建了 GPU 显存 → CPU 内存 → NVMe SSD 的三级存储层次:
GPU 显存(~80 GB): 当前正在计算的参数和激活值
CPU 内存(~512 GB): 优化器状态 + 暂时不用的参数分片
NVMe SSD(~数 TB): 装不下的参数分片 + 激活值 checkpoint通过异步预取和流水线调度,NVMe 的高延迟(~100 μs)被 GPU 计算时间掩盖。这使得在单台 8 × A100 的机器上训练万亿参数模型成为可能------虽然速度会慢一些,但"能跑起来"本身就是巨大突破。
实际使用建议:优先用 ZeRO-3。实在显存不够,再开 Offload(CPU 内存通常比 GPU 大得多)。极端场景(极少 GPU + 超大模型)才用 Infinity。Offload 会牺牲约 20-40% 的训练速度。
四、PyTorch FSDP:原生全分片数据并行
FSDP(Fully Sharded Data Parallel)是 PyTorch 原生的全分片实现,从 PyTorch 1.11 开始引入,在 PyTorch 2.x 中逐步成熟(FSDP2)。它的设计理念和 DeepSpeed ZeRO 一脉相承,但完全集成在 PyTorch 生态中,不需要额外的第三方库。
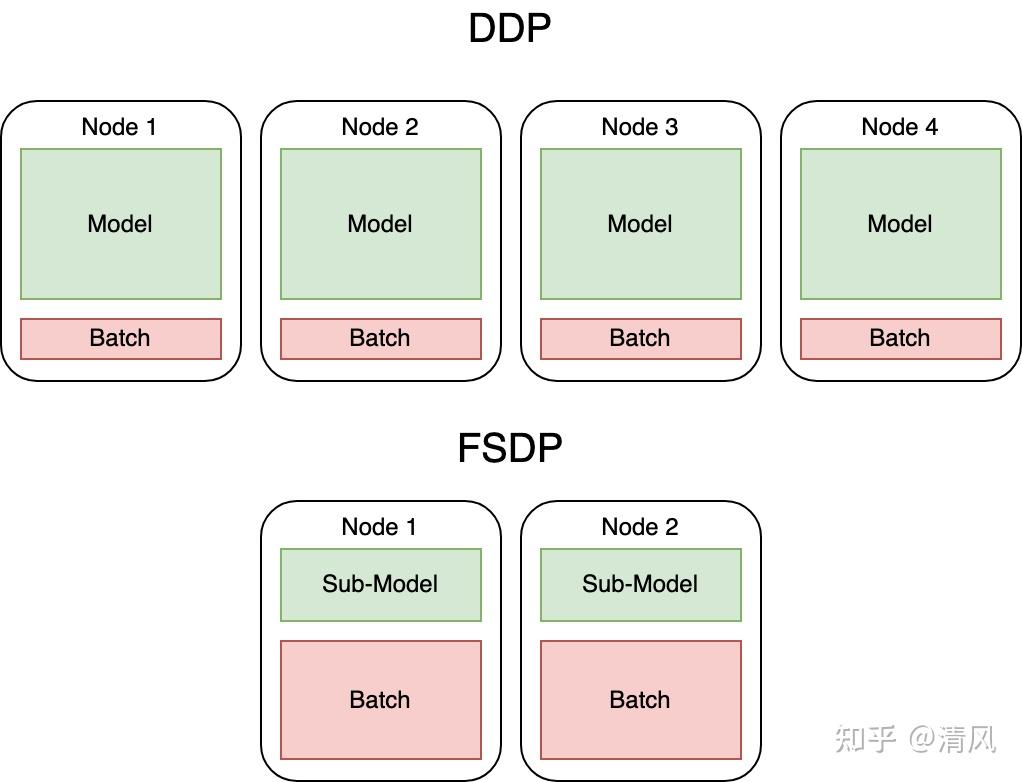
图2:FSDP 全分片数据并行。每个 FSDP Unit 持有 1/N 的参数,前向/反向时 AllGather 临时收集完整参数,反向后用 ReduceScatter 同步梯度。
4.1 FSDP 的工作流程
FSDP 把模型分成多个 FSDP Unit(通常按 Transformer 层划分),每个 Unit 的行为如下:
前向传播:
1. AllGather: 从所有 GPU 收集本 Unit 的完整参数
2. 执行前向计算
3. 丢弃非本地参数分片(释放显存)
反向传播:
1. AllGather: 再次收集完整参数(需要算梯度)
2. 执行反向计算
3. ReduceScatter: 归约梯度,每个 GPU 只保留自己那 1/N
4. 丢弃非本地参数分片
优化器更新:
每个 GPU 用自己的 1/N 梯度更新自己的 1/N 参数这个过程和 DeepSpeed ZeRO-3 几乎一样。区别在于 FSDP 是 PyTorch 原生功能,不需要 DeepSpeed 的 JSON 配置和引擎初始化。
4.2 FSDP 的三种分片策略
FSDP 提供三个级别的 ShardingStrategy:
| 策略 | 对应 ZeRO | 分片内容 | 说明 |
|---|---|---|---|
FULL_SHARD |
ZeRO-3 | 参数 + 梯度 + 优化器 | 极致省显存,通信量最大 |
SHARD_GRAD_OP |
ZeRO-2 | 梯度 + 优化器 | 默认推荐,平衡速度和显存 |
NO_SHARD |
等同 DDP | 不分片 | 标准数据并行 |
SHARD_GRAD_OP 是大多数场景的最佳选择:前向时不需要 AllGather(参数完整保留在每卡),只在反向后用 ReduceScatter 分片梯度,通信量比 FULL_SHARD 少约 1/3。
4.3 FSDP 基本使用
python
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from functools import partial
# 定义分片策略:按 Transformer 层切分
auto_wrap_policy = partial(
transformer_auto_wrap_policy,
transformer_layer_cls={TransformerBlock} # 你的 Transformer 层类名
)
# 用 FSDP 包装模型
model = FSDP(
model,
auto_wrap_policy=auto_wrap_policy,
sharding_strategy=ShardingStrategy.SHARD_GRAD_OP, # ZeRO-2 等效
mixed_precision=MixedPrecision(
param_dtype=torch.bfloat16,
reduce_dtype=torch.bfloat16,
buffer_dtype=torch.bfloat16,
),
)
# 正常训练
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
for batch in dataloader:
loss = model(batch).loss
loss.backward()
optimizer.step()
optimizer.zero_grad()FSDP1 的一个重要约束:必须先用 FSDP 包装模型,再创建 optimizer。因为 FSDP 会把参数替换为分片版本,optimizer 需要引用这些分片后的参数。顺序反了会导致参数不一致。
4.4 FSDP2(PyTorch 2.x)
FSDP2 是 PyTorch 2.x 中的重写版本,基于 DTensor 实现,有几个关键改进:
- 去中心化:所有 GPU 地位平等,没有 master-slave 关系
- 可组合 API:可以和 Tensor Parallel、Pipeline Parallel 自由组合(FSDP1 组合 TP/PP 比较困难)
- 零代码侵入 :直接
fully_shard(model)即可,不需要改变模型结构 - 性能提升:官方测试比 FSDP1 快 30% 以上
python
from torch.distributed.fsdp import fully_shard
# FSDP2: 更简洁的 API
model = fully_shard(model)
# 注意:调用时用 model(input),不要直接调 model.forward(input)
# 因为 FSDP2 的 hook 需要通过 __call__ 触发五、DeepSpeed 与 FSDP 对比
图3:Hugging Face Transformers Trainer 同时集成了 DeepSpeed(左)和 FSDP(右),用户只需切换配置文件即可在两种方案间切换。
5.1 核心特性对比
| 维度 | DeepSpeed | PyTorch FSDP |
|---|---|---|
| 开发方 | 微软 | Meta / PyTorch |
| ZeRO 支持 | Stage 1/2/3 全阶段 | FULL_SHARD(=3)、SHARD_GRAD_OP(=2) |
| Offload | CPU Offload + NVMe Offload | 仅 CPU Offload(PyTorch 2.x) |
| 混合精度 | FP16/BF16 + Loss Scaling | FP16/BF16 |
| 配置方式 | JSON 配置文件 | Python API / YAML |
| 代码侵入 | 中等(需替换 optimizer、用 DeepSpeed engine) | 低(包装模型即可) |
| 生态集成 | HuggingFace、Megatron | PyTorch 原生 |
| TP/PP 组合 | 需要额外集成 Megatron | FSDP2 原生可组合 |
5.2 性能对比
根据多个实际训练项目的测试数据:
- DeepSpeed ZeRO-3 在同等硬件配置下通常比 FSDP
FULL_SHARD快 5%~15%,得益于更成熟的通信调度和 overlap 优化 - FSDP2 相比 FSDP1 提升了约 30%,已接近 DeepSpeed 水平
- ZeRO-2 / SHARD_GRAD_OP 两者性能差距很小,通常 < 5%
- Offload 场景:DeepSpeed 有明显优势(NVMe Offload 是独家能力)
5.3 选型建议
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 快速上手、少改代码 | FSDP | PyTorch 原生,API 简洁 |
| 模型能放进单卡 | ZeRO-2 / SHARD_GRAD_OP | 零额外通信成本,性价比最高 |
| 模型参数放不进单卡 | ZeRO-3 / FULL_SHARD | 必须切分参数 |
| GPU 显存极端不足 | DeepSpeed + Offload | 用 CPU/NVMe 换显存 |
| 需要 3D 并行(DP+TP+PP) | Megatron + DeepSpeed | 最成熟的超大规模方案 |
| PyTorch 生态深度用户 | FSDP2 | 可组合 TP/PP,API 持续演进 |
六、配套优化技巧
6.1 Activation Checkpointing(激活重算)
激活值(中间计算结果)在反向传播时需要用到,默认会一直保存在显存中。对于大模型,激活值可能占 10-50 GB。
Activation Checkpointing 的策略是:前向传播时丢弃中间激活值,反向传播时重新计算。用计算换显存。
python
# DeepSpeed 配置
"activation_checkpointing": {
"partition_activations": true,
"cpu_checkpointing": true,
"contiguous_memory_optimization": true
}
# PyTorch 原生
from torch.utils.checkpoint import checkpoint
def forward(self, x):
# 对这个 block 做 checkpointing
x = checkpoint(self.layer1, x, use_reentrant=False)
x = self.layer2(x)
return x6.2 混合精度训练
用 FP16/BF16 做前向和反向计算(省显存、加速),用 FP32 做参数更新(保精度):
- BF16(Ampere 及以上架构推荐):动态范围和 FP32 一样大,不需要 Loss Scaling,训练更稳定
- FP16(老架构):需要 Loss Scaling 防止梯度下溢,调参更敏感
6.3 梯度累积
多个 micro-batch 累积梯度后再做一次参数更新,等效于增大 batch size,同时降低通信频率:
python
# 每 4 个 micro-batch 更新一次
accumulation_steps = 4
for i, batch in enumerate(dataloader):
loss = model(batch).loss / accumulation_steps
loss.backward()
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()6.4 通信与计算重叠
DeepSpeed 的 overlap_comm 配置让通信和计算同时进行:当第 k 层在做 ReduceScatter 梯度时,第 k+1 层已经在计算反向传播。FSDP 默认就做了这个优化(通过 forward/backward hook 自动触发 AllGather 和 ReduceScatter)。
七、常见坑与排查
坑一:ZeRO-3 训练速度骤降
ZeRO-3 的 AllGather 参数在前向和反向各做一次,通信量是 ZeRO-2 的 1.5 倍。如果 GPU 间走 PCIe 而非 NVLink,通信会严重拖慢训练。排查:用 nvidia-smi topo -m 确认 GPU 拓扑,确保同机 GPU 之间走 NVLink。
坑二:FSDP 包装后模型参数对不上
FSDP1 要求先 wrap 模型,再创建 optimizer。如果顺序反了,optimizer 引用的参数和 FSDP 包装后的参数不一致,训练会报错或静默出错。FSDP2 已经放宽了这个限制。
坑三:Offload 后训练速度断崖式下降
CPU Offload 的性能取决于 PCIe 带宽和 CPU 计算能力。如果 PCIe 传输时间 > GPU 计算时间,GPU 会大量空等。解决:增大 micro-batch size(让计算时间变长),或开启梯度累积(减少 Offload 频率)。
坑四:FSDP + Activation Checkpointing 显存不降反升
可能是 checkpoint 的 use_reentrant 参数没设置。PyTorch 2.x 推荐 use_reentrant=False(非重入模式),和 FSDP 兼容性更好。
坑五:多机训练时 ZeRO-3 OOM
ZeRO-3 的 AllGather 需要临时分配和模型参数等大的缓冲区。如果 prefetch_bucket_size 设置太大,峰值显存会飙升。解决:在 DeepSpeed 配置中调小 stage3_prefetch_bucket_size,或用 FSDP 的 limit_all_gathers=True 限制同时进行的 AllGather 数量。
八、总结
DeepSpeed ZeRO 和 PyTorch FSDP 解决的是同一个问题------DDP 的显存冗余。它们的核心思路是把模型状态切分到多张 GPU 上,用通信换显存。三个阶段逐步递进:切优化器 → 切梯度 → 切参数,省得越来越多,通信开销也越来越大。
一个实用的选型框架:先看模型能不能放进单卡。能,用 ZeRO-2 / SHARD_GRAD_OP(零额外通信,省显存效果明显);不能,用 ZeRO-3 / FULL_SHARD(必须切参数,接受额外通信);GPU 显存还是不够,再开 Offload(用速度换空间)。选 DeepSpeed 还是 FSDP,取决于你的生态偏好和是否需要 Offload/NVMe 等高级特性。在大多数中等规模(7B-70B)的训练场景下,两者性能差距已不大。