AI API 的 Token 计费其实分三种类型:
1️⃣ 输入 Token
2️⃣ 输出 Token(补全)
3️⃣ 缓存读取 Token
换算成单 Token 价格:
| 类型 | 单价 |
|---|---|
| 输入 | $0.0000025 |
| 输出 | $0.000015 |
| 缓存 | $0.00000025 |
而三者价格差距 最高能达到 60 倍。
很多 AI 产品能盈利,靠的就是 缓存机制。
今天这篇文章,我会带你彻底搞懂:
Token 到底是什么
为什么缓存读这么便宜
为什么长对话成本不会爆炸
如何把 AI API 成本降低 10 倍
如果你在做:
AI Agent
RAG 系统
AI API 网关
OpenAI 兼容接口
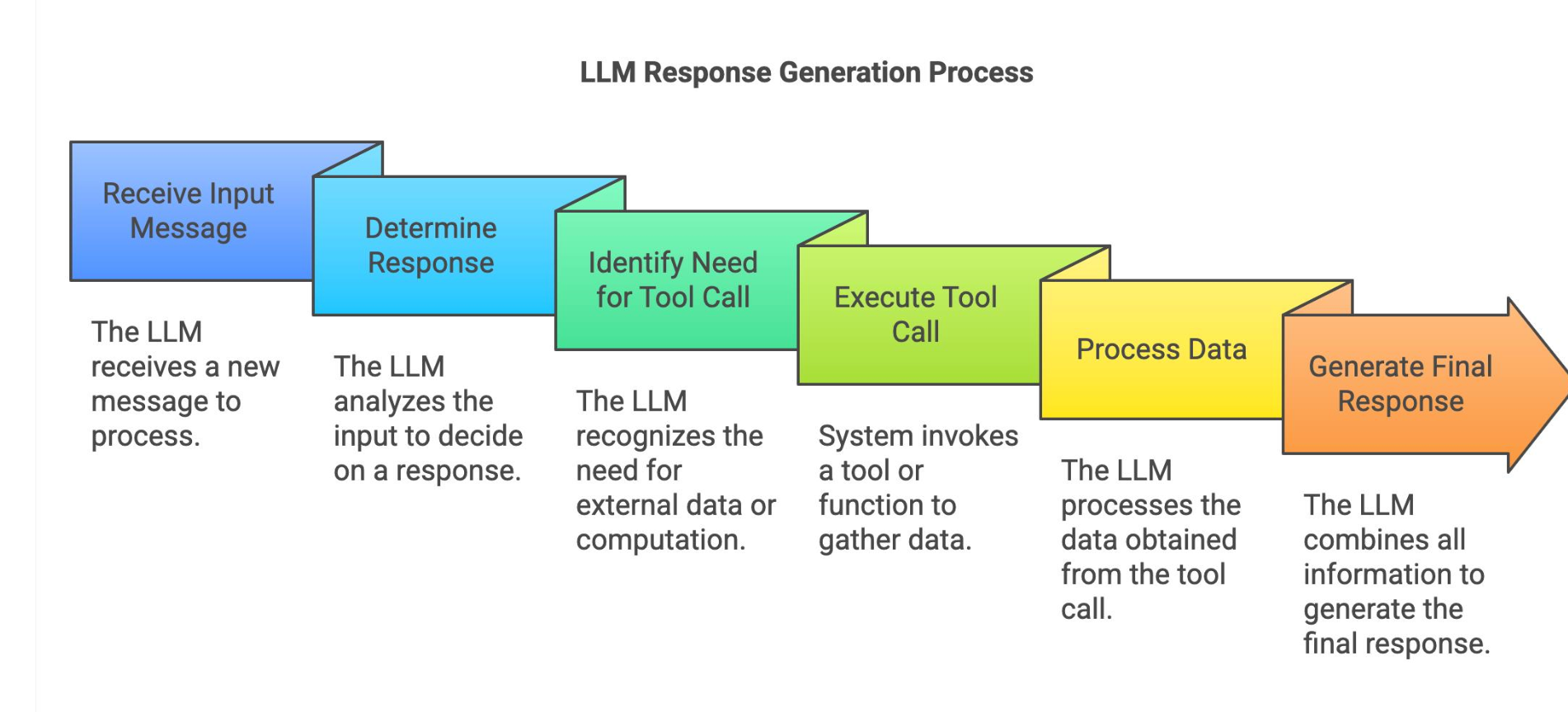
LLM 完整工具调用业务流程全解析
一、分步翻译 + 流程释义
1. Receive Input Message 接收输入消息
- 说明:大模型接收完整输入上下文,包含系统提示词、历史对话、用户最新提问、前置知识库片段等全部 Prompt 内容。
- 对应底层:进入 Prefill 预填充阶段,构建 / 复用 KV 缓存,是 Token 计费统计的起点。
2. Determine Response 预判回复逻辑
- 说明:模型对输入文本做首轮语义解析,判断两种分支: 分支 A:仅靠现有上下文就能直接回答,跳过工具调用环节,直达最终生成; 分支 B:缺少外部实时数据 / 计算能力,需要触发工具调用,进入下一环节。
3. Identify Need for Tool Call 识别工具调用需求
- 说明:模型识别当前问题存在信息缺口,输出结构化工具调用指令(Function Call),指定要调用的工具名称、入参。
- 典型场景:联网查实时时间、查询数据库、数学运算、文件检索、RAG 知识库检索。
4. Execute Tool Call 执行外部工具
- 说明:系统侧动作,不消耗模型推理 Token。业务后端解析模型输出的工具指令,发起接口 / 函数请求,获取外部原始数据。
- 例:调用搜索引擎 API、SQL 查询、代码解释器执行计算。
5. Process Data 处理工具返回数据
- 说明:将工具返回的原始数据格式化、拼接进对话上下文,作为新的输入重新送入大模型。
- 关键影响:新增数据会增加输入 Token,若每次工具返回内容都变化,会破坏 KV 缓存复用,大幅拉高成本。
6. Generate Final Response 生成最终回复
- 说明:模型整合原始上下文 + 工具返回数据,逐 Token 解码生成面向用户的自然语言回答。
- 计费特征:此阶段生成的输出 Token 统一按高价补全计费,无缓存折扣。
二、两种运行分支
- 无工具调用简化流程 接收输入 → 判断直接回复 → 生成最终回答
- 带工具调用完整流程 接收输入 → 判断需工具 → 识别工具指令 → 执行工具 → 拼接工具数据 → 生成最终回答
三、结合 KV 缓存 & 计费的关键业务启示(关联你之前的计费截图)
- 工具调用会破坏缓存复用,拉高成本 每次工具返回的数据属于动态可变内容,上下文前缀发生改变,下一轮请求无法复用历史 KV Cache,全部输入 Token 按原价计费,失去缓存读低价优惠。
- 降本优化方案 将固定不变的知识库、系统角色放在上下文最前端;把工具动态返回数据放在末尾,尽可能保留前缀文本不变,提升缓存命中率。
- Token 消耗分层
- 步骤 1、5 属于输入 Prefill 阶段:分「全新输入 Token(高价)/ 缓存复用 Token(1 折低价)」两类计费;
- 步骤 6 属于 Decode 输出阶段:统一高价补全 Token 计费;
- 步骤 4 纯系统接口调用:不产生任何模型 Token 费用。
- 多轮工具循环损耗 复杂场景会出现「调用工具→返回数据→再次调用工具」多轮循环,每一轮都会新增输入 Token,持续增加计费成本,工程上需限制最大工具调用轮次。
四、技术适用范围
这套工具调用流程是通用标准,OpenAI、Claude、通义千问、DeepSeek、Gemini 等主流大模型 API 均遵循相同业务逻辑,仅各厂商的工具调用格式、缓存计费优惠规则存在差异。
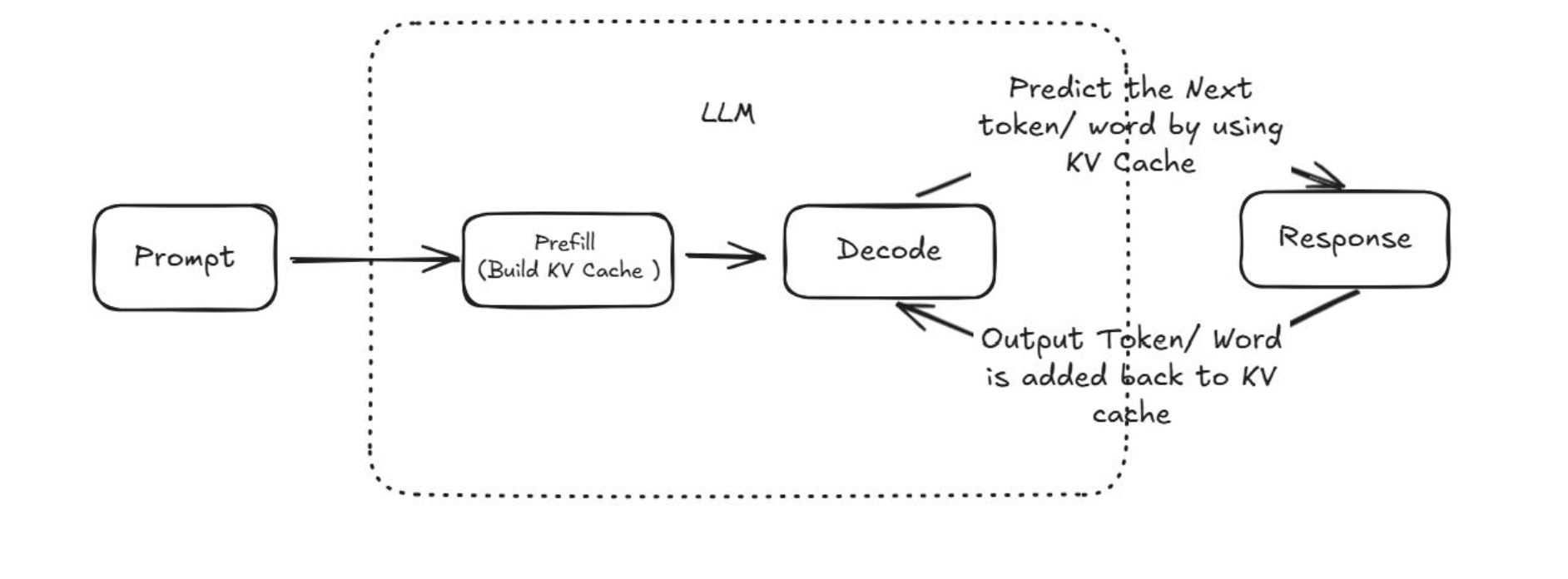
图中 LLM 底层 KV Cache 推理流程完整解读
一、流程逐环节翻译与原理拆解
1. Prompt(输入提示词)
用户传入全部上下文:系统角色、历史对话、知识库文档、当前提问,是模型所有输入 Token 的来源。
2. Prefill(预填充阶段,构建 KV Cache)
- 行为:一次性对整段 Prompt 做并行编码计算,生成 Key、Value 向量缓存(KV Cache)存入显存。
- 两种计费场景(对应你之前的计费截图):
- 全新无匹配上下文:完整计算全部 Token → 标准输入原价计费
- 前缀文本和历史请求完全一致:直接复用旧 KV 缓存,仅计算新增片段 → 缓存读低价计费(仅原价 10%)
- 算力特征:并行计算,速度快,长文本的主要算力消耗集中在此阶段。
3. Decode(解码生成阶段)
Predict the Next token/ word by using KV Cache依靠 Prefill 生成好的 KV 缓存,串行逐字预测下一个输出 Token,无需重复计算前置上下文,大幅降低重复算力开销。Output Token/ Word is added back to KV cache每生成 1 个输出 Token,就把该 Token 对应的 KV 向量追加进缓存,用于下一轮对话复用。
- 计费规则:所有生成的输出 Token 统一按高价「补全 Token」计费,无缓存折扣。
4. Response(模型输出结果)
拼接所有 Decode 阶段生成的 Token,整理成自然语言返回给调用方。
二、Prefill vs Decode 核心对比
表格
| 维度 | Prefill(预填充) | Decode(解码生成) |
|---|---|---|
| 计算方式 | 并行一次性计算全部输入 | 串行逐个生成输出 Token |
| KV Cache 作用 | 创建 / 复用缓存 | 读取缓存 + 追加新缓存 |
| Token 计费 | 全新输入 / 缓存读两档低价 | 统一高价输出计费 |
| 耗时占比 | 长输入占大头 | 输出越长耗时越高 |
三、和业务工具流程图联动,解释成本变化
- 若工具调用新增动态数据,Prompt 前缀发生变化 → Prefill 无法复用历史 KV 缓存,全部输入按原价收费,成本上升;
- 固定系统提示、固定知识库放在 Prompt 最前端,仅末尾放动态提问 → 前缀完全匹配,大量 Token 走缓存低价,就是你 15 万 Token 仅 0.058 美元案例的底层原理;
- 每一轮对话生成的回答会追加进 KV 缓存,下一轮带完整历史对话请求时,能持续复用。
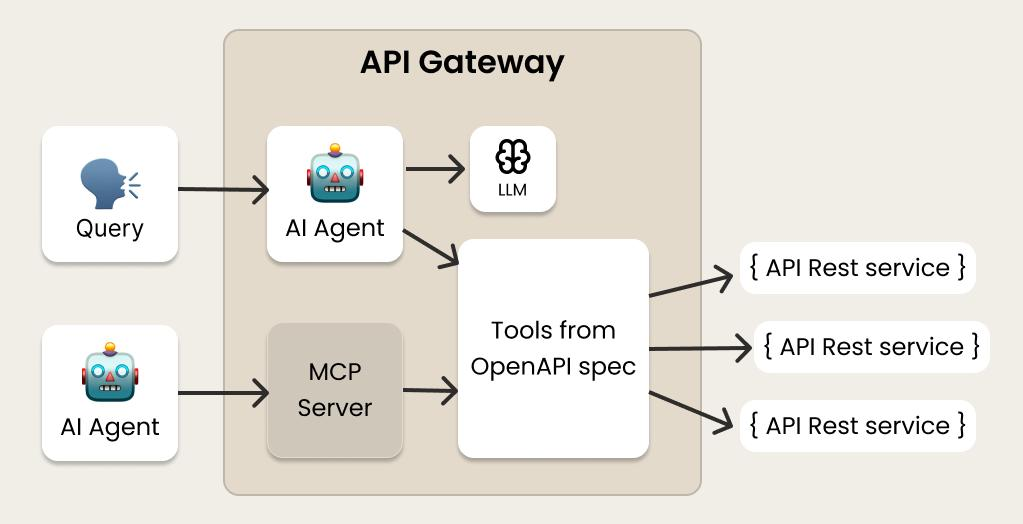
完整闭环链路梳理(纠正流程断点,对齐两张图逻辑)
你说的完全正确:LLM 识别工具需求 → MCP 执行 API → 工具结果回传给 LLM 二次推理,是完整闭环,这张架构图只画出了单向调用分支,省略了「工具数据回流 LLM」的回程链路,下面把完整闭环补齐。
一、先拆分图里两条主线 + 完整闭环走向
链路 1:终端用户 Query(内置 Agent 流程,最完整)
- 用户 Query 进入网关内置
AI Agent - Agent 将上下文送入
LLM(对应上层流程图Receive Input Message) - LLM 分析输入,识别需要调用工具 (
Identify Need for Tool Call),输出结构化 Function Call 指令 - Agent 把工具指令转发给
Tools from OpenAPI spec(底层由 MCP 能力承载执行) - MCP 调度对应
Rest API,完成接口请求(Execute Tool Call) - 回程(图中省略的关键回流步骤):API 返回业务数据 → MCP 格式化工具结果 → 塞回 AI Agent 上下文
- Agent 携带「原始提问 + 工具返回数据」再次发给
LLM(Process Data) - LLM 整合全部信息,生成最终自然语言回答(
Generate Final Response)返回用户
链路 2:外部独立 AI Agent 接入 MCP 通道
- 外部 AI Agent 请求网关内
MCP Server - MCP Server 携带 Agent 下发的工具调用指令,调度
Tools from OpenAPI spec - 调用 Rest API 拿到业务数据
- 回程:工具数据原路返回 MCP Server → 返还给外部 AI Agent
- 外部 Agent 自行拼接上下文,再主动发起 LLM 推理请求(这套链路 LLM 不在网关内部,由外部 Agent 管控回流)
六、Token 计费结构图

Token 计费结构图完整解读(结合前面 KV 缓存、分层定价体系)
一、左右两类任务基础翻译与定义
左图:Input Heavy: Summarization(输入重任务:文档摘要 / 长文本总结)
原文翻译:在长文档摘要这类任务中,输入 Token 的数量远大于输出 Token。
- 图例:深绿色 = Input Tokens(输入 Token),浅青色 = Output Tokens(输出 Token)
- 特征:环形占比输入部分占绝大多数,输出仅很小一块。
- 典型场景:RAG 知识库问答、合同总结、论文提炼、工具调用批量拉取参考资料。
右图:Output Heavy: Elaboration(输出重任务:扩写 / 创意生成)
原文翻译:对于短篇提示词写故事这类创意任务,输出 Token 数量会远超输入。
- 特征:环形占比输出部分占绝大多数,输入仅很小一块。
- 典型场景:小说创作、文案扩写、代码完整生成、长报告撰写。
八、缓存机制对 AI 产品的意义
缓存机制对于 AI 产品来说极其重要。
例如这些场景:
系统Prompt
工具描述
历史对话
RAG 系统
RAG 请求通常包含:
用户问题 历史对话 知识库片段
AI API 网关
如果你做:
- OpenAI API 代理
- AI 聚合平台
- AI SaaS
缓存策略甚至会决定:
你的产品是盈利还是亏钱。
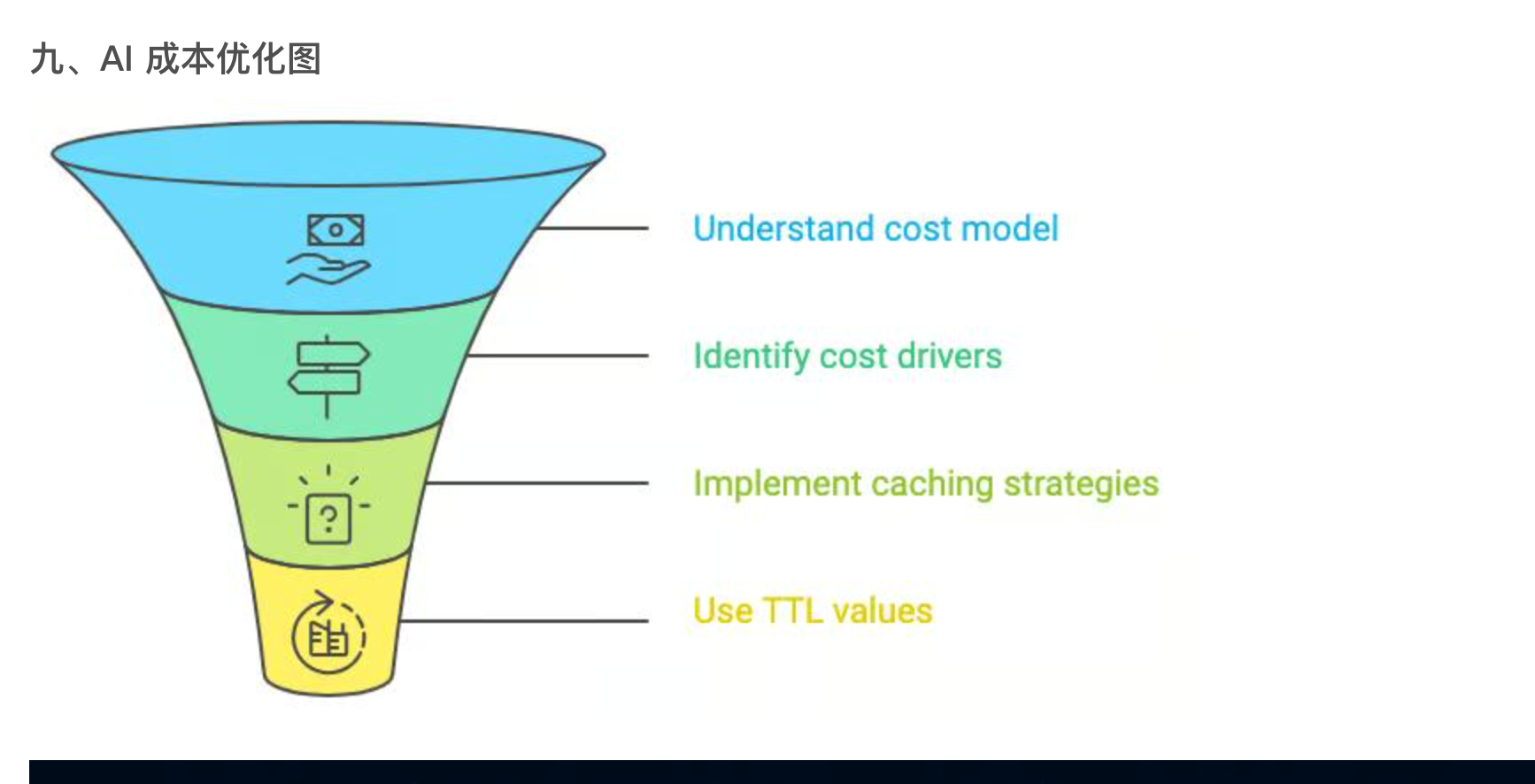
AI 成本优化漏斗图完整解读(串联前面 KV 缓存、Token 计费、RAG 全知识点)
漏斗从上到下是循序渐进、由基础到落地的 4 层优化执行步骤,越往下落地,降本效果越直接、幅度越大。
1. 第一层:Understand cost model | 吃透计费模型(基础前提)
释义
先完整搞懂厂商分层 Token 计价规则,是所有优化的前置条件:
- 区分三类 Token 定价:全新输入、缓存读输入、输出补全 Token;
- 分清两类业务负载:输入重(RAG / 文档摘要)、输出重(创意写作);
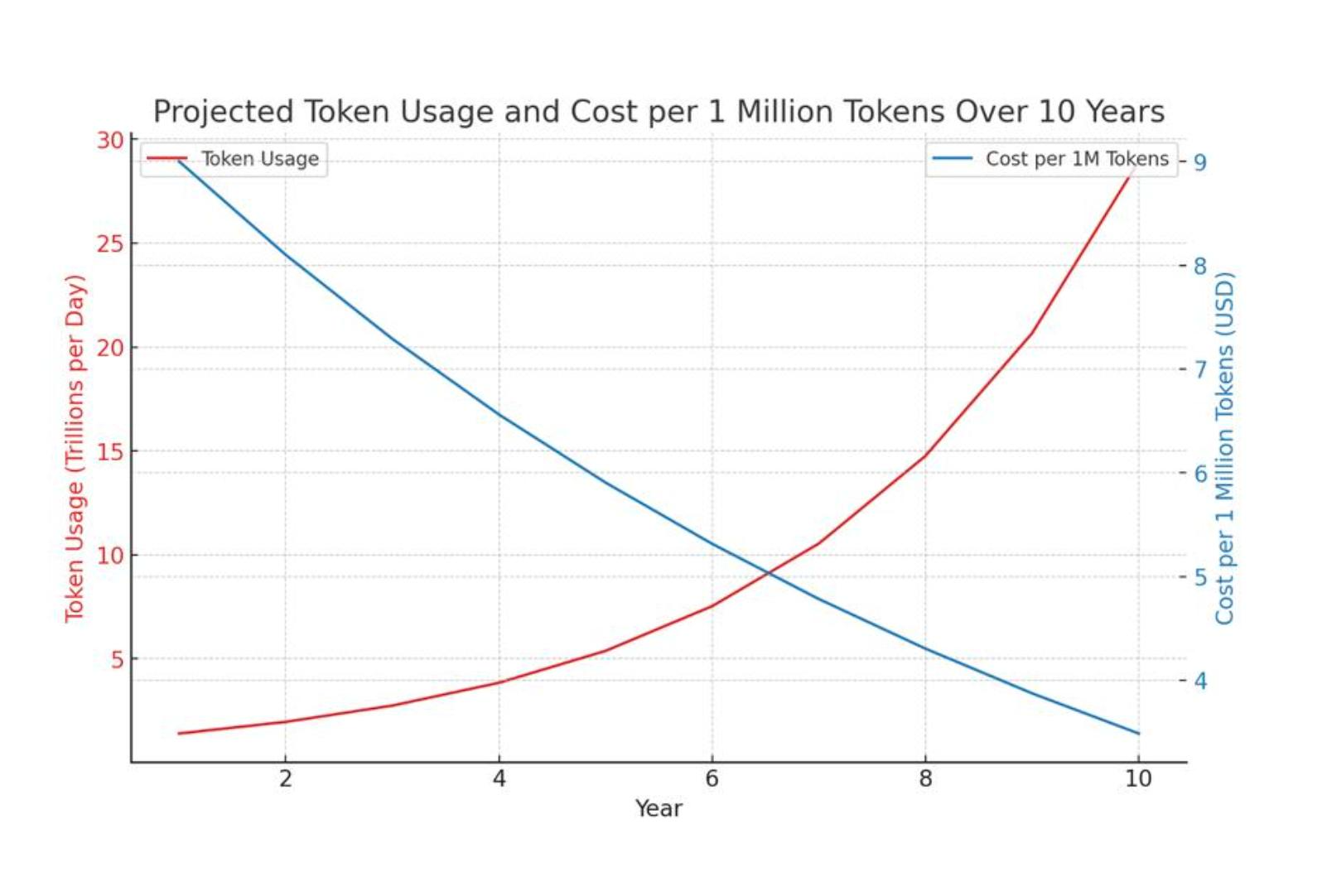
- 看懂用量预测曲线:Token 总量上涨、单价逐年下跌的对冲关系。
对应前文知识点
OpenAI v1/responses 分层计费、输入 / 输出环形占比图、10 年 Token 成本预测图都属于这一层认知基础;没搞懂计价规则,缓存、限流等优化都无从下手。
2. 第二层:Identify cost drivers | 定位成本消耗源头
释义
量化拆解账单,找出高额消耗的业务场景,精准锁定浪费点:
- 按场景拆分:RAG 知识库、Agent 工具调用、创意生成、客服对话分别消耗多少 Token;
- 定位无效开销:超长冗余上下文、无限制 max_tokens、频繁变更前缀破坏缓存、重复检索文档;
- 区分成本大头:输入重场景成本在长文档输入,输出重场景成本在超长生成内容。
落地动作
在 API 网关 / 聚合平台开启 Token 用量日志,按接口、用户、业务场景做账单分片统计,定位高消耗链路。
3. 第三层:Implement caching strategies | 落地缓存优化(核心降本手段)
释义
部署 KV 上下文缓存机制,复用重复上下文获取低价计费,是输入重场景(RAG)最有效的降本方案,对应你开篇 15 万 Token 仅 $0.058 的案例。
实操规范
- 固定 System Prompt、静态知识库放在上下文最前端,最大化缓存命中;
- 动态提问、工具返回数据放在上下文末尾,避免破坏可缓存前缀;
- 聚合平台 / API 网关统一托管全局缓存,跨用户、跨请求复用 KV 向量;
- 区分隐式短期缓存、显式持久缓存两种模式适配不同业务。
降本幅度
缓存命中高的 RAG 业务,输入 Token 成本可直接降低 90%。
4. 第四层:Use TTL values | 设置缓存过期时间(精细化管控)
释义
给 KV 缓存配置 TTL(生存时间),平衡算力开销、缓存命中率与数据新鲜度:
- 静态不变知识库:长 TTL(几小时 / 全天),长期复用缓存,最大化省钱;
- 实时动态业务(实时订单、当日资讯):短 TTL(几分钟),定时淘汰过期缓存,避免基于过时数据推理;
- 清理冷缓存:自动淘汰长期无访问的 KV 缓存,释放 GPU 显存,降低推理闲置算力成本。
业务价值
防止无限堆积无效缓存占用硬件资源,同时保证业务数据时效性,兼顾成本与推理准确性。
漏斗逻辑总结与落地顺序
- 顺序不可颠倒:先懂计费 → 找到花钱的地方 → 做缓存降本 → 用 TTL 精细化管控缓存生命周期;
- 收益逐级放大:越往下执行,单位 Token 节省的成本越高,缓存 + TTL 是落地后能直接体现在账单上的优化;
- 适配架构:这套流程适配 OpenAI 代理、AI 聚合平台、自建 MCP+Agent 整套体系,企业 RAG 知识库场景收益最显著;创意输出类场景缓存收益有限,重点放在第二层控制输出 Token 长度。
配套落地优先级建议
- 短期(1-3 天):完成 1、2 层,梳理账单、定位高消耗接口;
- 中期(1-2 周):落地第三层 KV 上下文缓存,快速削减输入 Token 成本;
- 长期:配置 TTL 缓存过期策略,搭建自动化成本监控告警闭环。
常见 AI 成本优化方式:
1 控制上下文长度
建议:
只保留最近 10 轮对话
AI写代码
1
2 使用 Prompt 压缩
例如:
摘要历史对话
AI写代码
1
减少 Token。
3 提高缓存命中率
例如:
系统Prompt缓存
知识库缓存
工具描述缓存
AI写代码
1
2
3
4 控制输出 Token
输出 Token 是最贵的:
$15 / 1M tokens
AI写代码
1
比输入贵 6倍。
5 选择合适模型
很多轻量模型价格更低:
DeepSeek
Qwen
Doubao
适合高并发调用。
十、为什么 /v1/responses 更先进?
这条调用记录使用接口:
/v1/responses
AI写代码
1
而不是传统:
/v1/chat/completions
AI写代码
1
原因是:
responses API 支持:
多模态输入
推理模型
streaming
工具调用
reasoning
示例:
POST /v1/responses
{
"model": "xxx",
"input": "你好",
"stream": true
}
AI写代码
json
1
2
3
4
5
6
7
未来很多 AI 平台都会逐步迁移到这个接口。
版权声明:本文为CSDN博主「码农阿豪@新空间」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44976692/article/details/160154227