这里写目录标题
- 前言
- 一、阶段学习目标
- 二、高级查询:聚合、分组、分页
-
- [2.1 基础环境模型(复用前文用户订单场景)](#2.1 基础环境模型(复用前文用户订单场景))
- [2.2 聚合函数:计数、求和、平均值、最大最小](#2.2 聚合函数:计数、求和、平均值、最大最小)
- [2.3 group_by分组 + having过滤分组](#2.3 group_by分组 + having过滤分组)
- [2.4 标准分页查询(接口通用模板)](#2.4 标准分页查询(接口通用模板))
- [2.5 查询结果四种读取方法区别](#2.5 查询结果四种读取方法区别)
- 三、事务控制:保证多操作原子性
-
- [3.1 基础事务规则](#3.1 基础事务规则)
- [3.2 基础事务:下单同时扣库存(模拟多表修改)](#3.2 基础事务:下单同时扣库存(模拟多表修改))
- [3.3 begin() 自动事务上下文(推荐写法)](#3.3 begin() 自动事务上下文(推荐写法))
- [3.4 Savepoint 保存点:局部回滚,不撤销全部事务](#3.4 Savepoint 保存点:局部回滚,不撤销全部事务)
- 四、批量操作优化(解决循环add慢)
-
- [4.1 批量插入 add_all(基础批量)](#4.1 批量插入 add_all(基础批量))
- [4.2 bulk_insert_mappings 无实例批量(高性能)](#4.2 bulk_insert_mappings 无实例批量(高性能))
- [4.3 批量更新(ORM批量,不逐条查询)](#4.3 批量更新(ORM批量,不逐条查询))
- 五、原生SQL安全执行(text防SQL注入)
-
- [5.1 带参数查询,返回元组](#5.1 带参数查询,返回元组)
- [5.2 原生结果映射为SQLModel对象](#5.2 原生结果映射为SQLModel对象)
- [5.3 原生增删改](#5.3 原生增删改)
- [六、综合实战:分组统计分页报表 + 事务](#六、综合实战:分组统计分页报表 + 事务)
- 七、阶段核心总结(半天必掌握)
- 八、新手高频避坑指南
前言
前3篇我们学完单表CRUD、高级字段DTO、一对多/多对多关联查询,日常基础增删改查完全够用。但真实项目中还有几类高频刚需场景:
- 报表统计:求和、计数、平均值、分组统计、筛选分组结果;
- 分页列表:接口标准分页、总条数统计;
- 数据一致性:下单扣库存、转账等多操作必须原子执行(事务);
- 批量导入/批量更新:循环add性能极低,需要批量API;
- 复杂统计SQL:ORM难以实现时,安全执行原生SQL并映射模型。
本文为系列第四阶段,半天掌握高级统计查询、分页、事务机制、批量操作、原生SQL安全写法,所有代码可直接运行,适配后台报表、数据同步、金融类强一致性业务。
一、阶段学习目标
- 掌握聚合函数
func.count/func.sum/func.avg,group_by分组+having分组过滤; - 标准分页实现:
offset/limit+ 统计总条数; - 彻底理解Session事务:
commit提交、rollback回滚、保存点savepoint局部回滚; - 批量插入、批量更新优化写法,避免循环add性能灾难;
- 使用
text()安全执行原生SQL,参数防注入,结果映射SQLModel模型; - 区分
all()/one()/one_or_none()/first()四种结果读取方法; - 报表综合实战:分组统计+分页+事务保证数据统一。
二、高级查询:聚合、分组、分页
2.1 基础环境模型(复用前文用户订单场景)
python
from sqlmodel import SQLModel, Field, create_engine, Session, select, text
from sqlalchemy import func
from typing import Optional, List
from datetime import datetime
engine = create_engine("sqlite:///stage4.db", echo=False)
class Order(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
user_id: int
goods_name: str
price: float = Field(gt=0)
num: int = Field(gt=1)
create_time: datetime = Field(default_factory=datetime.utcnow)
def init_table():
SQLModel.metadata.create_all(bind=engine)
# 测试填充数据
def init_test_data():
with Session(engine) as session:
data = [
Order(user_id=1, goods_name="Python教程", price=59.9, num=2),
Order(user_id=1, goods_name="机械键盘", price=199, num=1),
Order(user_id=2, goods_name="鼠标", price=49.9, num=3),
Order(user_id=2, goods_name="显示器", price=899, num=1),
Order(user_id=1, goods_name="耳机", price=129, num=2),
]
session.add_all(data)
session.commit()
init_table()
init_test_data()2.2 聚合函数:计数、求和、平均值、最大最小
sqlalchemy.func提供全套统计函数,搭配select直接查询数值:
python
# 1. 使用上下文管理器创建数据库会话
# 优点:代码块执行完毕后,session 会自动关闭并释放数据库连接,无需手动处理异常
with Session(engine) as session:
# 2. 构建聚合查询语句 (Aggregate Query)
stmt = select(
# func.count(Order.id): 统计订单总数。使用主键 id 进行 COUNT 操作效率最高
# .label("total_order"): 为这个聚合列指定一个别名,方便后续通过属性名获取结果
func.count(Order.id).label("total_order"),
# func.sum(Order.price * Order.num): 计算总销售额。
# 在数据库层面直接进行列的乘法运算并求和,避免了将大量数据拉到 Python 内存中计算
func.sum(Order.price * Order.num).label("total_amount"),
# func.avg(Order.price): 计算所有订单的平均单价
func.avg(Order.price).label("avg_price"),
# func.max(Order.price): 获取所有订单中的最高单价
func.max(Order.price).label("max_price")
)
# 3. 执行查询并获取单条结果
# session.exec(stmt): 将构建好的 SQL 语句发送给数据库执行
# .one(): 专门用于获取聚合查询的结果。
# 因为聚合函数(没有 GROUP BY 时)只会返回一行数据,使用 .one() 可以安全地提取这一行。
# 返回的 res 是一个元组(Row)对象,可以通过前面定义的 label 别名来访问对应的值
res = session.exec(stmt).one()
# 4. 打印统计结果
# 通过 .label() 定义的别名,可以像访问对象属性一样直接读取聚合结果
print("订单总数:", res.total_order)
print("总交易额:", res.total_amount)
print("平均价格:", res.avg_price)
print("最高价格:", res.max_price)
2.3 group_by分组 + having过滤分组
where过滤原始行,having过滤分组后的统计结果,不可混用聚合函数在where中。
python
with Session(engine) as session:
# 按用户分组,统计每个用户下单数量、总消费,只保留消费>300的用户
stmt = select(
Order.user_id,
func.count(Order.id).label("order_cnt"),
func.sum(Order.price * Order.num).label("user_total")
).group_by(Order.user_id).having(func.sum(Order.price * Order.num) > 300)
rows = session.exec(stmt).all()
for row in rows:with Session(engine) as session:
# 1. 构建分组聚合查询语句
stmt = select(
# 查询分组依据的字段:用户ID
Order.user_id,
# 统计每个用户的下单数量
func.count(Order.id).label("order_cnt"),
# 计算每个用户的总消费金额(单价 × 数量 的总和)
func.sum(Order.price * Order.num).label("user_total")
# 2. 按用户ID进行分组
# 相当于 SQL 中的 GROUP BY user_id
# 执行后,后续的聚合函数(count, sum)将针对每个用户单独计算
# 3. 对分组后的结果进行过滤
# 相当于 SQL 中的 HAVING SUM(price * num) > 300
# 注意:HAVING 是在分组之后执行的,用于过滤聚合计算的结果;
# 而 WHERE 是在分组之前执行的,用于过滤原始行数据。
# 这里只保留总消费金额大于 300 的用户记录
).group_by(Order.user_id).having(func.sum(Order.price * Order.num) > 300)
# 4. 执行查询并获取所有符合条件的结果
# 因为经过了分组,结果可能有多条(每个符合条件的用户一条),所以使用 .all() 获取列表
rows = session.exec(stmt).all()
# 5. 遍历结果并格式化打印
# 每一行 (row) 都包含前面 select 中定义的字段,可以直接通过别名访问
for row in rows:
print(f"用户{row.user_id}:订单{row.order_cnt}笔,消费{row.user_total}")
print(f"用户{row.user_id}:订单{row.order_cnt}笔,消费{row.user_total}")
2.4 标准分页查询(接口通用模板)
分页固定公式:offset((page-1)*page_size).limit(page_size),搭配count获取总条数。
python
def get_order_page(page: int = 1, page_size: int = 2):
# 使用上下文管理器创建数据库会话,确保执行完毕后自动释放连接
with Session(engine) as session:
# 1. 构建分页查询语句
stmt = (
# .order(Order.create_time.desc()): 按照创建时间倒序排列(最新的订单排在最前面)
# .offset((page-1)*page_size): 设置偏移量(跳过前面的记录)。
# 核心分页公式:(当前页码 - 1) * 每页条数。
# 例如:第1页跳过0条,第2页跳过2条,第3页跳过4条。
# .limit(page_size): 限制本次查询最多返回的记录数(即每页的条数)
select(Order).order_by(Order.create_time.desc()).offset((page-1)*page_size).limit(page_size)
)
# 2. 执行查询并获取当前页的数据列表
# 返回的是一个包含 Order 对象的列表
items = session.exec(stmt).all()
# 3. 查询满足条件的总记录数(用于前端计算总页数)
count_stmt = select(func.count(Order.id))
# .scalar(): 专门用于获取聚合查询(如 count, sum)返回的单个值。
# 它会自动提取结果集中的第一行第一列,直接返回一个整数,而不是一个 Row 对象
total = session.exec(count_stmt).one()
# 4. 封装并返回标准的分页数据结构
return {
"page": page, # 当前页码
"page_size": page_size, # 每页条数
"total": total, # 总记录数
"items": items # 当前页的数据列表
}
# 调用分页接口进行测试
# 获取第1页,每页2条数据
print(get_order_page(page=1, page_size=2))
2.5 查询结果四种读取方法区别
| 方法 | 适用场景 | 报错规则 |
|---|---|---|
.all() |
列表数据、分页 | 永远返回列表,空列表不报错 |
.first() |
只取第一条 | 返回第一条/None,不抛异常 |
.one() |
必须有且仅有1条 | 0条/多条都会抛异常 |
.one_or_none() |
最多一条 | 无数据返回None,多条报错 |
.scalar() |
仅单个数值(count/sum) | 直接取出单个值 |
三、事务控制:保证多操作原子性
3.1 基础事务规则
- Session默认自动事务,修改仅存在缓存,必须
commit()才持久化; - 任意操作异常,执行
rollback()撤销本次所有修改; with Session.begin()自动管理提交回滚,代码更简洁。
3.2 基础事务:下单同时扣库存(模拟多表修改)
python
def create_order_with_stock():
try:
with Session(engine) as session:
# 1. 新增订单
new_order = Order(user_id=3, goods_name="U盘", price=39.9, num=1)
session.add(new_order)
# 2. 模拟扣减库存(此处省略库存表逻辑)
# 手动抛出异常测试回滚
# raise Exception("库存不足")
session.commit()
print("事务提交成功")
except Exception as e:
session.rollback()
print("事务回滚,所有操作撤销:", e)
create_order_with_stock()
3.3 begin() 自动事务上下文(推荐写法)
with session.begin()块结束无异常自动commit,出现异常自动rollback,无需手动写回滚代码:
python
with Session(engine) as session:
with session.begin():
session.add(Order(user_id=3, goods_name="耳机", price=89, num=1))
# 出错自动回滚,不用手动rollback
# 1 / 0
3.4 Savepoint 保存点:局部回滚,不撤销全部事务
大循环批量导入时,单条失败只回滚当前条目,不撤销整批数据。
python
with Session(engine) as session:
with session.begin():
# 第一条正常插入
session.add(Order(user_id=4, goods_name="笔记本", price=4999, num=1))
# 创建保存点
# 1. 开启一个嵌套事务(保存点)
# 在关系型数据库中,这相当于执行了 SAVEPOINT 命令。
# 它允许你在当前的主事务中,开启一个"子事务"或"检查点"
sp = session.begin_nested()
try:
# 异常数据
session.add(Order(user_id=4, goods_name="平板", price=-10, num=1))
except Exception:
# 仅回滚保存点内操作,第一条保留
sp.rollback()
四、批量操作优化(解决循环add慢)
4.1 批量插入 add_all(基础批量)
多条数据统一加入会话,单次提交,远优于循环add+多次commit:
python
batch = [
Order(user_id=5, goods_name="充电宝", price=69, num=1),
Order(user_id=5, goods_name="支架", price=19, num=2)
]
with Session(engine) as session:
session.add_all(batch)
session.commit()
4.2 bulk_insert_mappings 无实例批量(高性能)
无需创建SQLModel实例,直接传字典列表,百万级数据推荐:
python
from sqlalchemy.orm import bulk_insert_mappings
data_list = [
{"user_id": 6, "goods_name": "风扇", "price": 29.9, "num": 1},
{"user_id": 6, "goods_name": "台灯", "price": 45, "num": 1}
]
with Session(engine) as session:
bulk_insert_mappings(session, Order, data_list)
session.commit()4.3 批量更新(ORM批量,不逐条查询)
python
from sqlmodel import update
with Session(engine) as session:
stmt = update(Order).where(Order.user_id == 1).values(price=Order.price * 0.9)
session.exec(stmt)
session.commit()
五、原生SQL安全执行(text防SQL注入)
业务复杂统计ORM难以实现时,使用text(),必须params传参拼接,禁止字符串格式化拼接SQL,杜绝注入漏洞。
5.1 带参数查询,返回元组
python
with Session(engine) as session:
sql = text("SELECT * FROM `order` WHERE user_id = :uid AND price > :min_price")
res = session.exec(sql, params={"uid": 1, "min_price": 50}).all()
for row in res:
print(row.goods_name, row.price)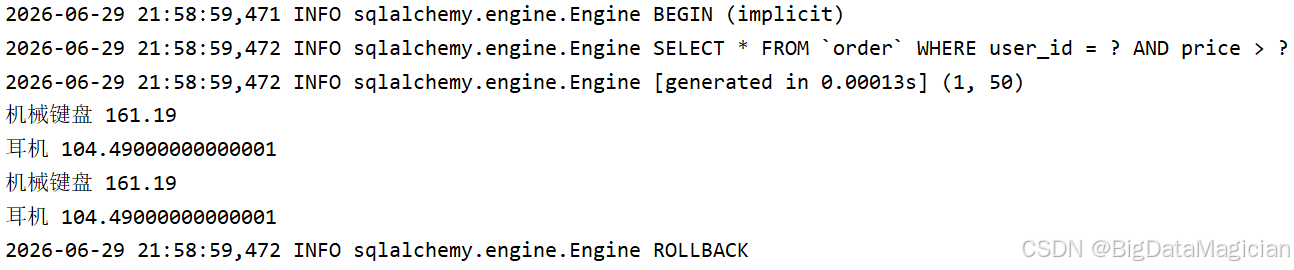
5.2 原生结果映射为SQLModel对象
python
from sqlalchemy import select as sa_select
with Session(engine) as session:
# 1. 编写原生 SQL 语句
# text(): 将普通的字符串转换为 SQLAlchemy 的文本 SQL 对象,使其能被 ORM 识别。
# :uid: 这是一个参数化占位符,用于防止 SQL 注入攻击,后续会通过 params() 传入实际值。
sql = text("SELECT id, user_id, goods_name FROM `order` WHERE user_id=:uid")
# 2. 将原生 SQL 与 ORM 模型绑定
# sa_select(Order): 创建一个以 Order 模型为目标的 select 语句(sa_select 是 sqlalchemy.select 的别名)。
# .from_statement(sql): 告诉 ORM:"不要自动生成 SQL,而是使用我提供的原生 SQL 语句,
# 但请将查询出来的结果,按照 Order 模型的字段映射成 ORM 对象"。
# .params(uid=1): 为原生 SQL 中的占位符 :uid 绑定具体的参数值 1。
stmt = sa_select(Order).from_statement(sql).params(uid=1)
# 3. 执行查询并获取结果列表
# 返回的 order_list 是一个包含 Order ORM 对象的列表,而不是普通的字典或元组
order_list = session.exec(stmt).all()
# 4. 将 ORM 对象转换为字典格式并打印
# model_dump(): Pydantic V2 的方法,将 ORM 对象序列化为 Python 字典。
# 这样处理后,数据就可以非常方便地转换为 JSON 格式返回给前端了。
print([item for item in order_list])
5.3 原生增删改
python
with Session(engine) as session:
insert_sql = text("INSERT INTO `order`(user_id,goods_name,price,num,create_time) VALUES(:u,:g,:p,:n,:ct)")
session.exec(insert_sql, params={"u": 7, "g": "数据线", "p": 19.9, "n": 1, "ct": datetime.now()})
session.commit()
六、综合实战:分组统计分页报表 + 事务
整合聚合、分页、事务、原生SQL完整业务流程:
python
def order_report():
# 事务包裹报表同步统计数据
with Session(engine) as session:
with session.begin():
# 1. 批量新增测试订单
batch = [Order(user_id=8, goods_name="键盘膜", price=15, num=1)]
session.add_all(batch)
# 2. 分组统计各用户消费
group_stmt = select(
Order.user_id,
func.sum(Order.price * Order.num).label("total")
).group_by(Order.user_id)
group_data = session.exec(group_stmt).all()
# 3. 分页订单列表
page_data = get_order_page(page=1, page_size=3)
# 4. 原生SQL查询高价订单
high_sql = text("SELECT goods_name, price FROM `order` WHERE price>200")
high_orders = session.exec(high_sql).all()
return {"group_stat": group_data, "page": page_data, "high_price": high_orders}
print(order_report())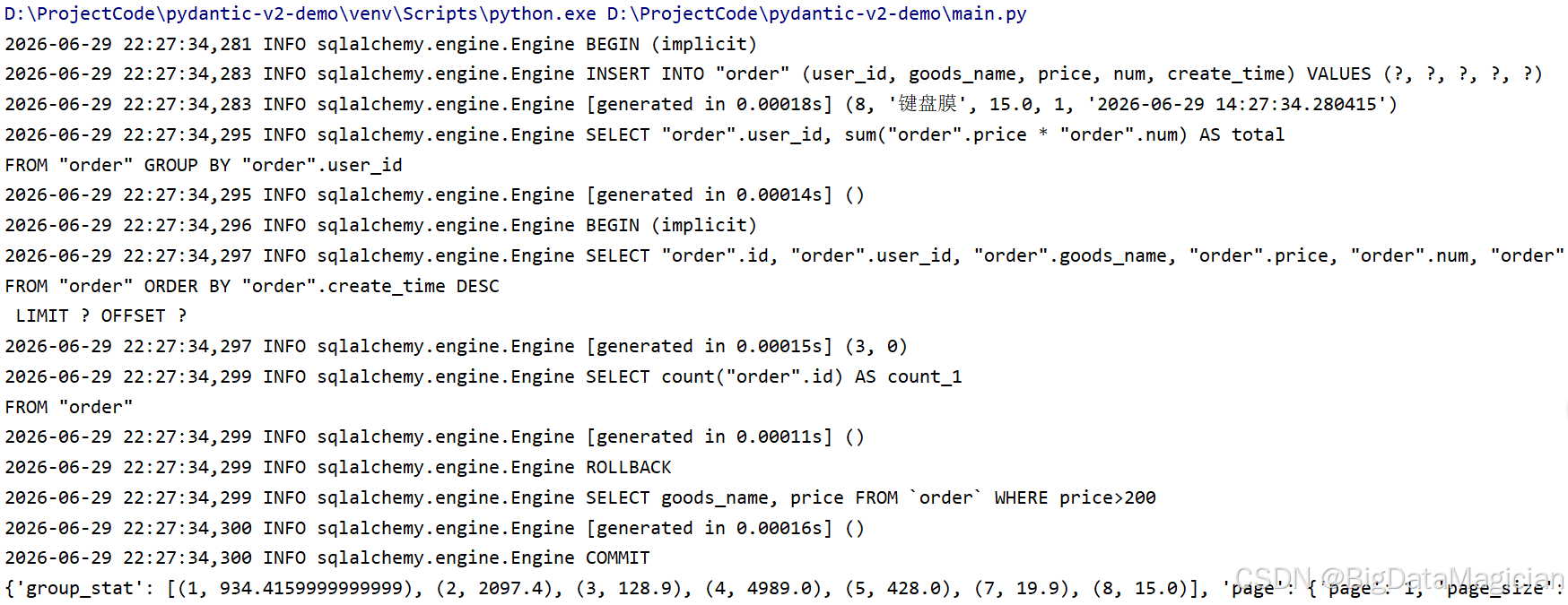
七、阶段核心总结(半天必掌握)
- 聚合统计 :
func系列函数配合group_by分组,having过滤分组结果; - 分页模板 :
offset((page-1)*page_size)+limit+count统计总条数; - 事务核心 :
commit持久化、rollback回滚,session.begin()自动事务,begin_nested()保存点局部回滚; - 批量优化 :
add_all、bulk_insert_mappings、update()批量更新,避免循环操作; - 原生SQL规范 :统一
text()+params传参,禁止字符串拼接防注入,支持映射模型; - 结果读取:分清all/first/one/one_or_none/scalar使用场景。
八、新手高频避坑指南
- ❌ 在
where中使用聚合函数,必须改用having; - ❌ 分页不写
order_by,数据库返回顺序不稳定; - ❌ 多步业务操作不包事务,中途异常导致数据不一致;
- ❌ 原生SQL用f-string拼接参数,存在SQL注入风险;
- ❌ 循环执行add+commit,大批量数据性能极差;
- ❌ 事务异常忘记rollback,会话残留脏数据;
- ✅ 报表统计优先ORM聚合,极复杂SQL再使用text原生语句。