随机森林算法详解:从 Bagging 原理到分类与回归实战
随机森林(Random Forest)是一种经典的集成学习算法。它以决策树为基础,通过构建多棵相互差异较大的决策树,并综合这些树的预测结果,从而提升模型的稳定性、泛化能力和抗过拟合能力。
如果说单棵决策树像一个人独立做判断,那么随机森林就是让一组决策树共同参与投票。对于分类任务,随机森林通常采用多数投票或概率平均的方式确定最终类别;对于回归任务,随机森林则对多棵树的预测值取平均,得到最终连续数值预测结果。
相比单棵决策树,随机森林能够有效缓解过拟合问题;相比梯度提升模型,随机森林训练过程更容易并行,对参数设置也相对不那么敏感。因此,在分类、回归、特征重要性分析和结构化数据建模中,随机森林都是非常常用的机器学习模型。
本文将从 Bagging 原理、Bootstrap 抽样、OOB 估计、数学模型、主要参数、分类实战、回归实战、模型解释和超参数调优等方面,系统讲解随机森林算法的原理与 Python 实现。
1. 随机森林算法介绍
随机森林可以理解为"很多棵决策树组成的森林"。单棵决策树会根据特征和阈值不断划分样本,使每个叶节点中的样本尽可能纯净。对于分类任务,叶节点输出类别;对于回归任务,叶节点输出连续数值。
但是,单棵决策树有一个明显缺点:如果树长得太深,就容易把训练数据中的局部噪声也学习进去,从而造成过拟合。也就是说,它在训练集上表现很好,但在测试集上泛化能力较弱。
随机森林正是为了解决这个问题而提出的。它不是只训练一棵树,而是训练多棵树,并让这些树共同参与预测。
随机森林中的"随机"主要体现在两个层面:
- 样本随机
每棵树不是使用完全相同的训练集,而是通过 Bootstrap 有放回抽样,从原始训练集中抽取一批样本进行训练。 - 特征随机
每棵树在节点划分时,不是每次都考虑全部特征,而是随机选择一部分特征参与最优划分。
这两个随机机制能够让森林中的树彼此之间产生差异。最后,随机森林再综合多棵树的预测结果,得到更稳定的最终预测。
随机森林的核心思想可以概括为:
text
单棵决策树容易不稳定
↓
通过 Bootstrap 采样生成多个训练子集
↓
每棵树在节点划分时随机选择部分特征
↓
训练多棵差异化的决策树
↓
分类任务投票,回归任务平均
↓
降低方差,提高模型泛化能力2. Bagging 与 Bootstrap 抽样
随机森林属于 Bagging 思想的一种典型应用。Bagging 是 Bootstrap Aggregating 的缩写,可以翻译为"自助聚合"。
它的核心思想是:先通过 Bootstrap 抽样生成多个不同的训练子集,再分别训练多个模型,最后将多个模型的预测结果进行聚合。
2.1 Bootstrap 抽样
假设原始训练集有 NNN 个样本。Bootstrap 抽样的做法是:从这 NNN 个样本中进行有放回随机抽样,每次抽取一个样本,重复 NNN 次,得到一个新的训练子集。
由于是有放回抽样,所以同一个样本可能被多次抽中,也可能一次都没有被抽中。对于每一棵树而言,它看到的训练数据都不完全相同。
从概率上看,在一次 Bootstrap 抽样中,一个样本没有被抽中的概率为:
(1−1N)N \left(1-\frac{1}{N}\right)^N (1−N1)N
当 NNN 足够大时,有:
(1−1N)N≈e−1≈0.368 \left(1-\frac{1}{N}\right)^N \approx e^{-1} \approx 0.368 (1−N1)N≈e−1≈0.368
也就是说,每次 Bootstrap 抽样大约会有 63.2% 的原始样本被抽中,约 36.8% 的样本没有被当前这棵树用于训练。
这些没有被某棵树抽中的样本,被称为袋外样本(Out-of-Bag,OOB)。
2.2 OOB 估计
OOB 样本是随机森林中的一个重要副产品。对于某棵树来说,OOB 样本没有参与该树训练,因此可以用来评估这棵树的预测效果。
当森林中有很多棵树时,每个样本都会成为一部分树的 OOB 样本。将这些树对该样本的 OOB 预测结果汇总,就可以得到模型的 OOB 得分。
OOB 得分的优势是:它可以在不额外划分验证集的情况下,对模型泛化能力进行估计。
在 scikit-learn 中,可以通过设置 oob_score=True 启用 OOB 评分:
python
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=200,
oob_score=True,
random_state=42,
n_jobs=-1
)需要注意的是,OOB 估计依赖足够多的树。如果树的数量太少,一些样本可能无法获得稳定的 OOB 预测。因此,实际使用时不建议在 n_estimators 很小的情况下启用 OOB 评分。
2.3 为什么 Bagging 有效
Bagging 的主要作用是降低模型方差。
单棵决策树对训练数据非常敏感,数据稍有变化,树结构就可能发生明显改变。而 Bagging 通过训练多棵树并聚合结果,可以抵消单棵树的随机波动,使最终模型更加稳定。
对于分类任务,多棵树投票可以减少某一棵树错误判断对最终结果的影响;对于回归任务,多棵树预测值取平均可以平滑单棵树的预测波动。
此外,随机森林中的多棵树相对独立,因此可以并行训练,这也是它在工程实践中非常常用的重要原因。
3. 随机森林的双重随机性
随机森林相比普通 Bagging 决策树,又增加了特征随机选择机制。因此,它的随机性可以分为两个层面。
3.1 样本随机:行采样
每棵树使用不同的 Bootstrap 样本进行训练。也就是说,每棵树看到的数据行不完全相同。
这种样本随机性可以让每棵树学习到不同的数据模式,减少树与树之间的相似性。
3.2 特征随机:列采样
在每个节点分裂时,普通决策树会在所有特征中寻找最优划分;而随机森林不会每次都考虑所有特征,而是先随机选择一部分特征,再从这些特征中寻找最优划分。
假设原始特征数为 ppp,每次节点划分时只随机选择 mmm 个特征参与比较。对于分类任务,常用设置是:
m=p m = \sqrt{p} m=p
对于回归任务,也可以使用部分特征比例来控制每次划分的候选特征数量。
特征随机性的好处是:即使某些特征非常强,也不会主导所有树的分裂过程。这样可以进一步降低树与树之间的相关性,使集成效果更好。
4. 数学理论与模型
假设训练数据集为:
D=(xi,yi)i=1n D = {(x_i, y_i)}_{i=1}^{n} D=(xi,yi)i=1n
其中,xi∈Rdx_i \in \mathbb{R}^dxi∈Rd 表示第 iii 个样本的特征向量,yiy_iyi 表示对应的类别标签或连续目标值。
随机森林包含 BBB 棵决策树:
T1(x),T2(x),...,TB(x) T_1(x), T_2(x), \dots, T_B(x) T1(x),T2(x),...,TB(x)
4.1 Bootstrap 训练子集
对于第 bbb 棵树,从原始训练集 DDD 中进行有放回抽样,得到一个新的训练子集:
Db=(xi(b),yi(b))i=1n D_b = {(x_i^{(b)}, y_i^{(b)})}_{i=1}^{n} Db=(xi(b),yi(b))i=1n
每棵树都在各自的 Bootstrap 子集上训练,因此不同树之间具有一定差异。
4.2 随机特征候选集
在每棵树的每个节点处,随机森林从全部特征集合中随机选择一部分特征作为候选集合:
Mb⊂1,2,...,d,∣Mb∣=m M_b \subset {1,2,\dots,d}, \quad |M_b| = m Mb⊂1,2,...,d,∣Mb∣=m
然后只在这些候选特征中寻找最优划分。
4.3 分类任务中的节点划分
分类任务中常用基尼指数或信息熵衡量节点纯度。
基尼指数为:
Gini(D)=1−∑k=1Kpk2 Gini(D)=1-\sum_{k=1}^{K}p_k^2 Gini(D)=1−k=1∑Kpk2
其中,pkp_kpk 表示当前节点中第 kkk 类样本所占比例。
信息熵为:
H(D)=−∑k=1Kpklog2pk H(D)=-\sum_{k=1}^{K}p_k\log_2 p_k H(D)=−k=1∑Kpklog2pk
节点越纯,基尼指数或信息熵越小。随机森林中的每棵决策树都会尽量选择能够让子节点更纯的特征和阈值进行划分。
4.4 分类任务的预测
对于分类任务,第 bbb 棵树给出的预测为:
Tb(x)∈1,2,...,K T_b(x) \in {1,2,\dots,K} Tb(x)∈1,2,...,K
随机森林的最终预测类别可以表示为:
y^=argmaxk∑b=1BI(Tb(x)=k) \hat{y} = \arg\max_k \sum_{b=1}^{B} I(T_b(x)=k) y^=argkmaxb=1∑BI(Tb(x)=k)
其中,I(⋅)I(\cdot)I(⋅) 是指示函数。如果第 bbb 棵树预测为类别 kkk,则取值为 1,否则为 0。
4.5 回归任务的预测
对于回归任务,第 bbb 棵树会输出一个连续值:
Tb(x)∈R T_b(x) \in \mathbb{R} Tb(x)∈R
随机森林回归器的最终预测结果为:
y^=1B∑b=1BTb(x) \hat{y} = \frac{1}{B}\sum_{b=1}^{B}T_b(x) y^=B1b=1∑BTb(x)
也就是说,回归任务中随机森林通过对多棵树的预测值取平均来降低单棵树带来的波动。
5. 主要参数说明
scikit-learn 中随机森林主要包括两个常用模型:
python
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor其中,RandomForestClassifier 用于分类任务,RandomForestRegressor 用于回归任务。
5.1 RandomForestClassifier 分类器
python
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(
n_estimators=100, # 森林中树的数量
criterion="gini", # 节点划分标准,可选 "gini", "entropy", "log_loss"
max_depth=None, # 每棵树的最大深度,None 表示尽可能生长
min_samples_split=2, # 内部节点继续分裂所需的最小样本数
min_samples_leaf=1, # 叶节点至少包含的样本数
max_features="sqrt", # 每次划分时考虑的最大特征数
bootstrap=True, # 是否使用 Bootstrap 有放回抽样
oob_score=False, # 是否使用袋外样本评估模型
n_jobs=None, # 并行计算线程数,-1 表示使用全部 CPU
random_state=None, # 随机种子,保证实验可复现
class_weight=None, # 类别权重,可用于类别不平衡任务
ccp_alpha=0.0, # 最小成本复杂度剪枝参数
max_samples=None # Bootstrap 抽样时每棵树使用的样本数量
)5.2 RandomForestRegressor 回归器
python
from sklearn.ensemble import RandomForestRegressor
reg = RandomForestRegressor(
n_estimators=100, # 森林中树的数量
criterion="squared_error", # 回归任务的节点划分标准
max_depth=None, # 每棵树的最大深度
min_samples_split=2, # 内部节点继续分裂所需的最小样本数
min_samples_leaf=1, # 叶节点至少包含的样本数
max_features=1.0, # 每次划分时考虑的最大特征数
bootstrap=True, # 是否使用 Bootstrap 抽样
oob_score=False, # 是否使用袋外样本评估模型
n_jobs=None, # 并行计算线程数
random_state=None, # 随机种子
ccp_alpha=0.0, # 剪枝参数
max_samples=None # Bootstrap 抽样样本数
)5.3 核心参数解释
| 参数 | 作用 | 调参建议 |
|---|---|---|
n_estimators |
森林中树的数量 | 树越多结果通常越稳定,但训练时间也会增加 |
max_depth |
每棵树的最大深度 | 深度过大容易过拟合,过小容易欠拟合 |
max_features |
每次划分考虑的特征数量 | 分类常用 "sqrt",回归可使用比例值或 1.0 |
min_samples_split |
内部节点继续分裂所需的最小样本数 | 增大可抑制过拟合 |
min_samples_leaf |
叶节点至少包含的样本数 | 增大可让模型更平滑 |
bootstrap |
是否使用有放回抽样 | 随机森林通常保持 True |
oob_score |
是否使用袋外样本评估 | 树数量较多时可开启 |
class_weight |
分类任务类别权重 | 类别不平衡时可设置为 "balanced" |
n_jobs |
并行训练线程数 | 大数据可设置为 -1 |
random_state |
固定随机性 | 教学和实验建议设置 |
6. 分类实战:乳腺癌诊断数据集
下面使用 Breast Cancer Wisconsin 乳腺癌诊断数据集演示随机森林分类任务。该数据集是一个二分类数据集,目标是根据肿瘤细胞相关特征判断样本属于恶性还是良性。
6.1 导入库与全局配置
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
accuracy_score,
classification_report,
confusion_matrix,
ConfusionMatrixDisplay,
RocCurveDisplay
)
sns.set_theme(style="whitegrid", font="SimHei", rc={"axes.unicode_minus": False}) # 设置主题和字体
plt.rcParams["figure.figsize"] = (8, 5)
plt.rcParams["figure.dpi"] = 120
plt.rcParams["axes.spines.top"] = False
plt.rcParams["axes.spines.right"] = False
image_dir = Path("images")
image_dir.mkdir(exist_ok=True)6.2 加载数据集
python
cancer = load_breast_cancer()
X_cls = pd.DataFrame(cancer.data, columns=cancer.feature_names)
y_cls = pd.Series(cancer.target, name="target")
target_map = {
0: "恶性",
1: "良性"
}
df_cls = X_cls.copy()
df_cls["诊断结果"] = y_cls.map(target_map)
print("特征矩阵维度:", X_cls.shape)
print("类别分布:")
print(df_cls["诊断结果"].value_counts())
# 只展示部分代表性特征,避免表格过宽
preview_cols = [
"mean radius",
"mean texture",
"mean perimeter",
"mean area",
"mean smoothness",
"worst radius",
"worst perimeter",
"worst area",
"诊断结果"
]
df_cls[preview_cols].head()
text
特征矩阵维度: (569, 30)
类别分布:
诊断结果
良性 357
恶性 212
Name: count, dtype: int64| mean radius | mean texture | mean perimeter | mean area | mean smoothness | worst radius | worst perimeter | worst area | 诊断结果 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 25.38 | 184.60 | 2019.0 | 恶性 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 24.99 | 158.80 | 1956.0 | 恶性 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 23.57 | 152.50 | 1709.0 | 恶性 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 14.91 | 98.87 | 567.7 | 恶性 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 22.54 | 152.20 | 1575.0 | 恶性 |
乳腺癌诊断数据集共有 569 条样本和 30 个数值型特征,目标变量为二分类标签,其中 0 表示恶性,1 表示良性。由于原始特征数量较多,直接展示完整数据表会导致表格过宽,因此这里只展示部分具有代表性的均值特征和 worst 特征,用于观察数据基本结构。
6.3 类别分布可视化
python
fig, ax = plt.subplots(figsize=(7, 5))
sns.countplot(
data=df_cls,
x="诊断结果",
hue="诊断结果",
palette="Set2",
edgecolor="black",
linewidth=1.0,
legend=False,
ax=ax
)
for p in ax.patches:
ax.annotate(
f"{int(p.get_height())}",
(p.get_x() + p.get_width() / 2, p.get_height()),
ha="center",
va="bottom",
fontsize=11,
xytext=(0, 4),
textcoords="offset points"
)
ax.set_title("乳腺癌数据集类别分布", pad=12, weight="bold")
ax.set_xlabel("诊断结果")
ax.set_ylabel("样本数量")
fig.tight_layout()
plt.show()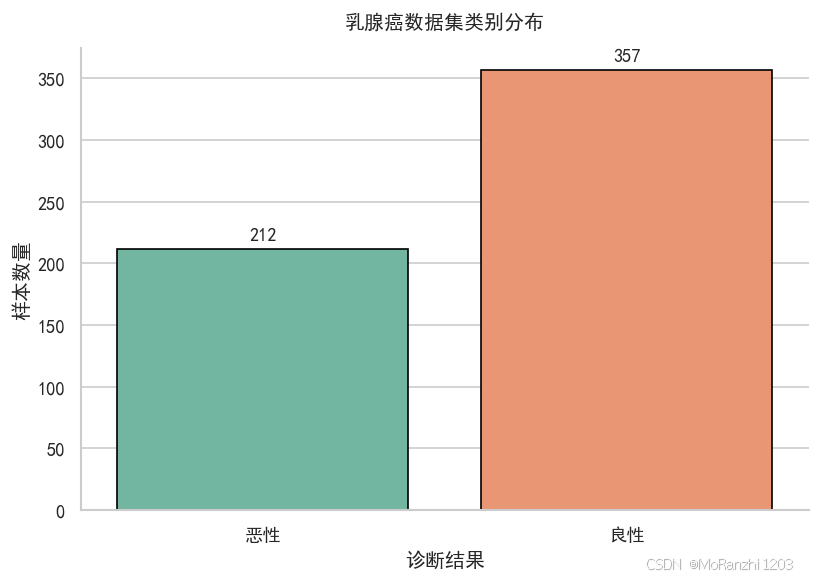
类别分布图可以帮助我们观察数据是否存在明显类别不平衡。如果类别严重不平衡,后续可以考虑设置 class_weight="balanced",或者使用更适合不平衡分类任务的评价指标。
6.4 划分分类模型训练集与测试集
python
X_train_cls, X_test_cls, y_train_cls, y_test_cls = train_test_split(
X_cls,
y_cls,
test_size=0.25,
random_state=42,
stratify=y_cls
)
print(f"训练集样本数:{X_train_cls.shape[0]}")
print(f"测试集样本数:{X_test_cls.shape[0]}")
print(f"训练集正类比例:{y_train_cls.mean():.3f}")
print(f"测试集正类比例:{y_test_cls.mean():.3f}")
text
训练集样本数:426
测试集样本数:143
训练集正类比例:0.627
测试集正类比例:0.629这里使用 stratify=y_cls 进行分层划分,使训练集和测试集中的类别比例尽量保持一致。
6.5 训练随机森林分类模型
python
rf_clf = RandomForestClassifier(
n_estimators=200,
max_depth=None,
max_features="sqrt",
random_state=42,
oob_score=True,
n_jobs=-1
)
rf_clf.fit(X_train_cls, y_train_cls)
y_pred_cls = rf_clf.predict(X_test_cls)
print("测试集准确率:", accuracy_score(y_test_cls, y_pred_cls))
print("OOB 得分:", rf_clf.oob_score_)
print()
print("分类报告:")
print(classification_report(
y_test_cls,
y_pred_cls,
target_names=["恶性", "良性"]
))
text
测试集准确率: 0.958041958041958
OOB 得分: 0.9624413145539906
分类报告:
precision recall f1-score support
恶性 0.96 0.92 0.94 53
良性 0.96 0.98 0.97 90
accuracy 0.96 143
macro avg 0.96 0.95 0.95 143
weighted avg 0.96 0.96 0.96 143在这个模型中,n_estimators=200 表示构建 200 棵决策树;max_features="sqrt" 表示每次节点划分时只随机考虑部分特征;oob_score=True 表示使用袋外样本估计模型泛化能力。
6.6 混淆矩阵可视化
python
cm = confusion_matrix(y_test_cls, y_pred_cls)
fig, ax = plt.subplots(figsize=(6, 5), dpi=150)
disp = ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=["恶性", "良性"]
)
disp.plot(
cmap="Blues",
ax=ax,
colorbar=False
)
ax.set_title("随机森林分类混淆矩阵", pad=12, weight="bold")
ax.grid(False)
fig.tight_layout()
plt.show()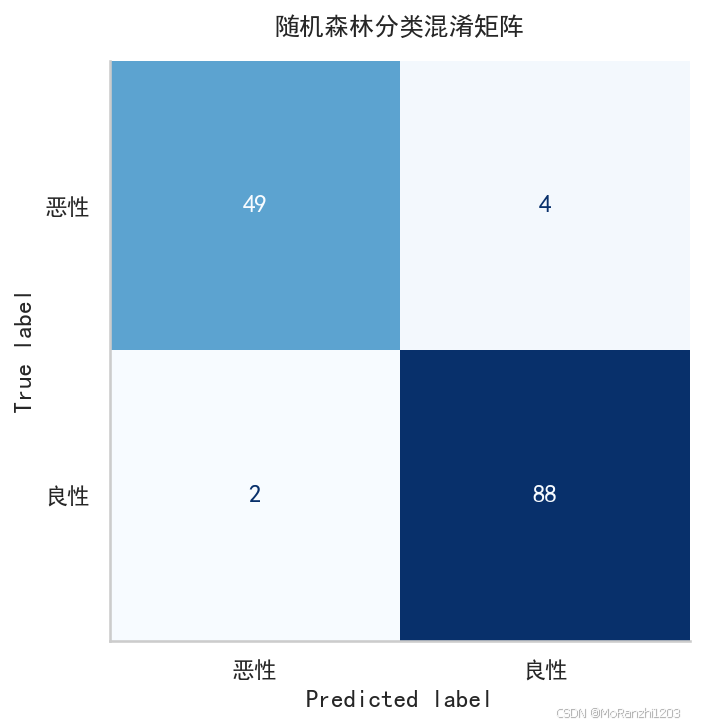
混淆矩阵可以直观展示模型在哪些类别上预测正确,哪些类别之间容易混淆。对于医疗诊断这类任务,不能只看准确率,还需要关注不同类别的召回率和误判情况。
6.7 ROC 曲线
对于二分类任务,ROC 曲线可以展示不同阈值下模型的分类能力。AUC 越接近 1,说明模型整体区分能力越强。
python
fig, ax = plt.subplots(figsize=(6, 5), dpi=150)
RocCurveDisplay.from_estimator(
rf_clf,
X_test_cls,
y_test_cls,
ax=ax,
linewidth=2
)
ax.plot(
[0, 1],
[0, 1],
linestyle="--",
linewidth=1.2,
alpha=0.6,
label="随机猜测"
)
ax.set_title("随机森林分类 ROC 曲线", pad=12, weight="bold")
ax.legend(loc="lower right", frameon=True)
fig.tight_layout()
plt.show()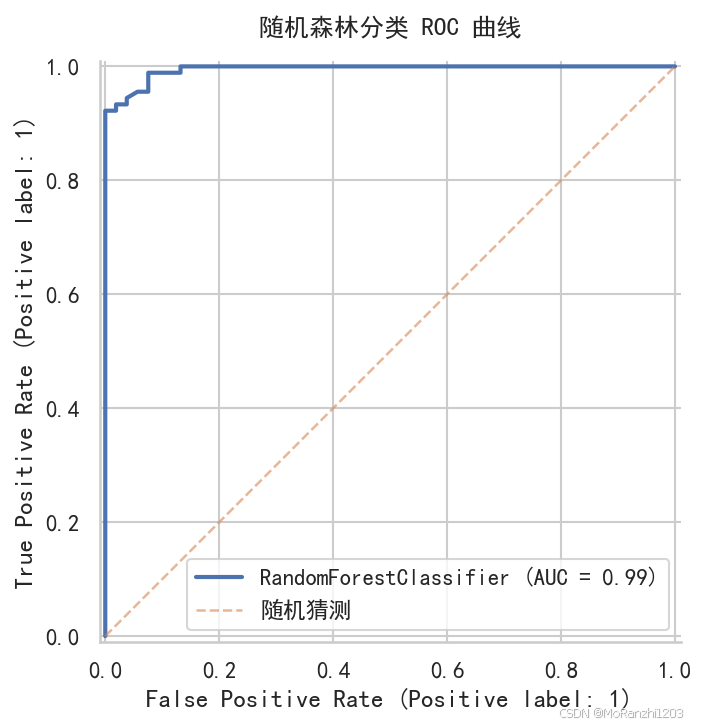
ROC 曲线比单一准确率更全面,尤其适合二分类任务中的模型比较。
7. 分类模型解释:特征重要性
随机森林可以通过 feature_importances_ 输出特征重要性。它反映了每个特征在多棵树划分过程中对降低节点不纯度的贡献。
这种方法属于基于不纯度减少的特征重要性,也称为 MDI(Mean Decrease in Impurity)。它计算速度快,但可能偏向取值范围较多或可分裂点较多的特征。因此,在正式分析中,可以进一步结合排列重要性(Permutation Importance)进行验证。
python
importance_cls_df = pd.DataFrame({
"特征": cancer.feature_names,
"重要性": rf_clf.feature_importances_
}).sort_values("重要性", ascending=False)
top_n = 15
top_importance_cls = importance_cls_df.head(top_n)
fig, ax = plt.subplots(figsize=(9, 6))
sns.barplot(
data=top_importance_cls,
x="重要性",
y="特征",
hue="特征",
palette="Blues_r",
legend=False,
ax=ax
)
# 在条形图右侧显示重要性数值
for container in ax.containers:
ax.bar_label(
container,
fmt="%.3f",
padding=4,
fontsize=10
)
# 给右侧数值预留空间,避免文字被裁剪
max_importance = top_importance_cls["重要性"].max()
ax.set_xlim(0, max_importance * 1.15)
ax.set_title("随机森林分类特征重要性 Top 15", pad=12, weight="bold")
ax.set_xlabel("重要性得分")
ax.set_ylabel("特征名称")
ax.grid(axis="x", linestyle="--", alpha=0.3)
fig.tight_layout()
plt.show()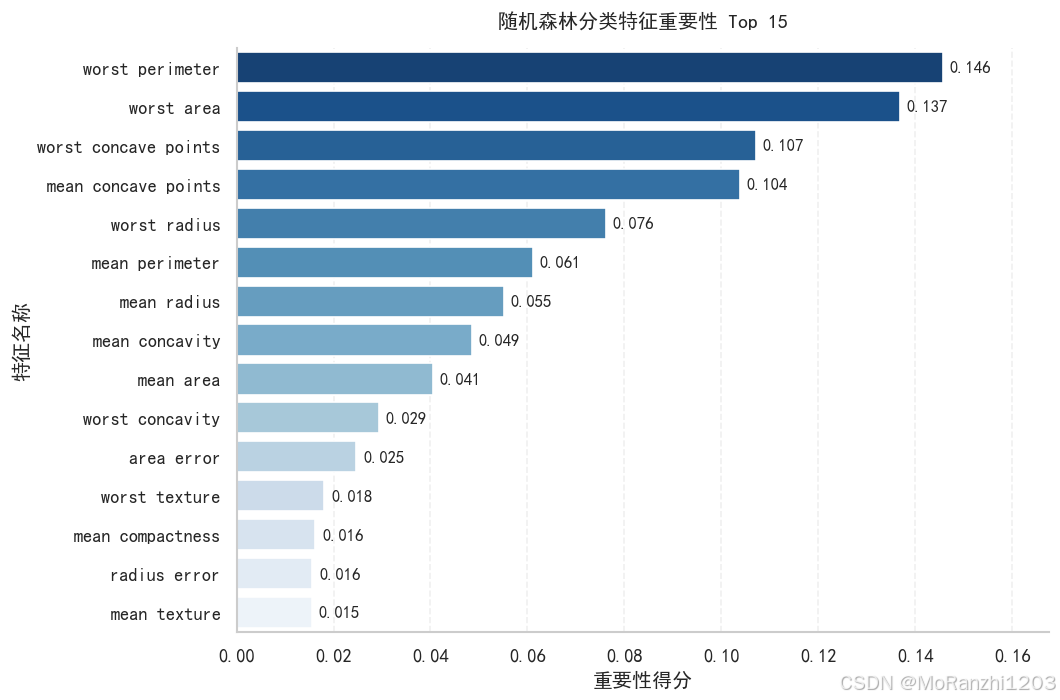
特征重要性可以帮助我们理解模型主要依赖哪些变量进行预测。在乳腺癌数据集中,一些与细胞半径、周长、面积、凹陷度相关的特征通常会对分类结果产生较大影响。
不过,特征重要性只能说明模型在当前数据和当前划分方式下更依赖哪些特征,并不等同于因果关系。
8. 分类任务超参数调优
在实际建模中,可以使用 GridSearchCV 对随机森林分类器进行参数搜索。由于乳腺癌数据集规模不大,分类任务使用轻量级网格搜索通常可以较快完成。
为了避免外层交叉验证并行和模型内部并行互相争抢 CPU,这里在网格搜索阶段将模型内部的 n_jobs 设置为 1,让 GridSearchCV 负责外层并行。
python
param_grid_cls = {
"n_estimators": [100, 200, 300],
"max_depth": [3, 5, None],
"min_samples_leaf": [1, 2, 4],
"max_features": ["sqrt", None]
}
grid_search_cls = GridSearchCV(
estimator=RandomForestClassifier(random_state=42, n_jobs=1),
param_grid=param_grid_cls,
cv=5,
scoring="accuracy",
n_jobs=-1,
verbose=1
)
grid_search_cls.fit(X_train_cls, y_train_cls)
print("最佳参数:", grid_search_cls.best_params_)
print("最佳交叉验证得分:", grid_search_cls.best_score_)
best_rf_clf = grid_search_cls.best_estimator_
print("测试集准确率:", best_rf_clf.score(X_test_cls, y_test_cls))
text
Fitting 5 folds for each of 54 candidates, totalling 270 fits
最佳参数: {'max_depth': None, 'max_features': 'sqrt', 'min_samples_leaf': 1, 'n_estimators': 300}
最佳交叉验证得分: 0.9624076607387142
测试集准确率: 0.958041958041958通过网格搜索,可以在多个参数组合中选择交叉验证表现最好的模型。对于分类任务,常用评分指标包括 accuracy、f1_macro、roc_auc 等。如果数据类别不平衡,应优先考虑 F1、召回率、AUC 等指标,而不是只看准确率。
9. 回归实战:加州房价预测
随机森林不仅可以用于分类,也可以用于回归。下面使用加州房价数据集演示随机森林回归任务。
回归任务的目标变量是连续数值,因此需要使用 RandomForestRegressor,评估指标也应使用 MAE、MSE、RMSE、R2 等回归指标。
9.1 导入库与加载数据
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import (
mean_absolute_error,
mean_squared_error,
r2_score
)
sns.set_theme(style="whitegrid", font="SimHei", rc={"axes.unicode_minus": False}) # 设置主题和字体
plt.rcParams["figure.figsize"] = (8, 5)
plt.rcParams["figure.dpi"] = 120
plt.rcParams["axes.spines.top"] = False
plt.rcParams["axes.spines.right"] = False
image_dir = Path("images")
image_dir.mkdir(exist_ok=True)
housing = fetch_california_housing()
X_reg = pd.DataFrame(housing.data, columns=housing.feature_names)
y_reg = pd.Series(housing.target, name="MedHouseVal")
df_reg = X_reg.copy()
df_reg["target"] = y_reg
print("特征矩阵维度:", X_reg.shape)
print("目标变量统计:")
print(y_reg.describe())
df_reg.head()
text
特征矩阵维度: (20640, 8)
目标变量统计:
count 20640.000000
mean 2.068558
std 1.153956
min 0.149990
25% 1.196000
50% 1.797000
75% 2.647250
max 5.000010
Name: MedHouseVal, dtype: float64| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | target | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 | 4.526 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 | 3.585 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 | 3.521 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 | 3.413 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 | 3.422 |
这里将回归任务的数据统一命名为 X_reg 和 y_reg,划分后使用 X_train_reg、X_test_reg、y_train_reg、y_test_reg,避免与分类任务变量混用。
9.2 目标变量分布可视化
在训练回归模型之前,先观察目标变量分布,有助于理解预测任务的难度。
python
fig, ax = plt.subplots(figsize=(8, 4))
ax.hist(
y_reg,
bins=60,
edgecolor="white",
alpha=0.85
)
ax.axvline(
y_reg.median(),
linewidth=2,
linestyle="--",
label=f"中位数: {y_reg.median():.3f}"
)
ax.set_title("加州房价目标变量分布", pad=12, weight="bold")
ax.set_xlabel("房价中位数")
ax.set_ylabel("频数")
ax.legend(frameon=True)
fig.tight_layout()
plt.show()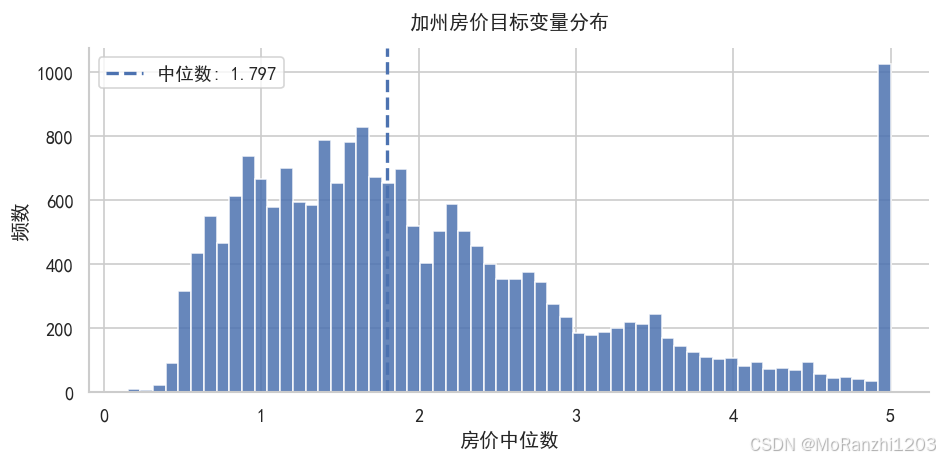
如果目标变量分布偏斜明显,模型在高值区间和低值区间的预测误差可能会有所不同,因此后续需要结合残差分析进一步观察预测效果。
9.3 划分回归模型训练集与测试集
python
X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(
X_reg,
y_reg,
test_size=0.2,
random_state=42
)
print(f"训练集样本数:{X_train_reg.shape[0]}")
print(f"测试集样本数:{X_test_reg.shape[0]}")
text
训练集样本数:16512
测试集样本数:41289.4 训练随机森林回归模型
python
rf_reg = RandomForestRegressor(
n_estimators=300,
max_depth=None,
min_samples_leaf=2,
random_state=42,
n_jobs=-1,
oob_score=True
)
rf_reg.fit(X_train_reg, y_train_reg)
y_pred_reg = rf_reg.predict(X_test_reg)
mae = mean_absolute_error(y_test_reg, y_pred_reg)
mse = mean_squared_error(y_test_reg, y_pred_reg)
rmse = np.sqrt(mse)
r2 = r2_score(y_test_reg, y_pred_reg)
print(f"MAE : {mae:.4f}")
print(f"MSE : {mse:.4f}")
print(f"RMSE: {rmse:.4f}")
print(f"R2 : {r2:.4f}")
print(f"OOB : {rf_reg.oob_score_:.4f}")
text
MAE : 0.3263
MSE : 0.2540
RMSE: 0.5040
R2 : 0.8062
OOB : 0.8110这里使用 MAE、MSE、RMSE 和 R2 对回归模型进行评估。
其中:
- MAE 表示平均绝对误差;
- MSE 表示均方误差;
- RMSE 表示均方根误差;
- R2 表示模型对目标变量方差的解释能力;
- OOB 得分可以作为模型泛化性能的参考。
在图表和输出中统一使用 R2,避免部分中文字体对上标字符支持不足的问题。
9.5 真实值与预测值对比
python
fig, ax = plt.subplots(figsize=(7, 6))
sns.scatterplot(
x=y_test_reg,
y=y_pred_reg,
alpha=0.45,
edgecolor=None,
ax=ax
)
min_val = min(y_test_reg.min(), y_pred_reg.min())
max_val = max(y_test_reg.max(), y_pred_reg.max())
ax.plot(
[min_val, max_val],
[min_val, max_val],
linestyle="--",
linewidth=2,
label="理想预测线"
)
ax.set_title(f"随机森林回归:真实值与预测值对比\nR2={r2:.3f}, RMSE={rmse:.3f}", pad=12, weight="bold")
ax.set_xlabel("真实值")
ax.set_ylabel("预测值")
ax.legend(frameon=True)
fig.tight_layout()
plt.show()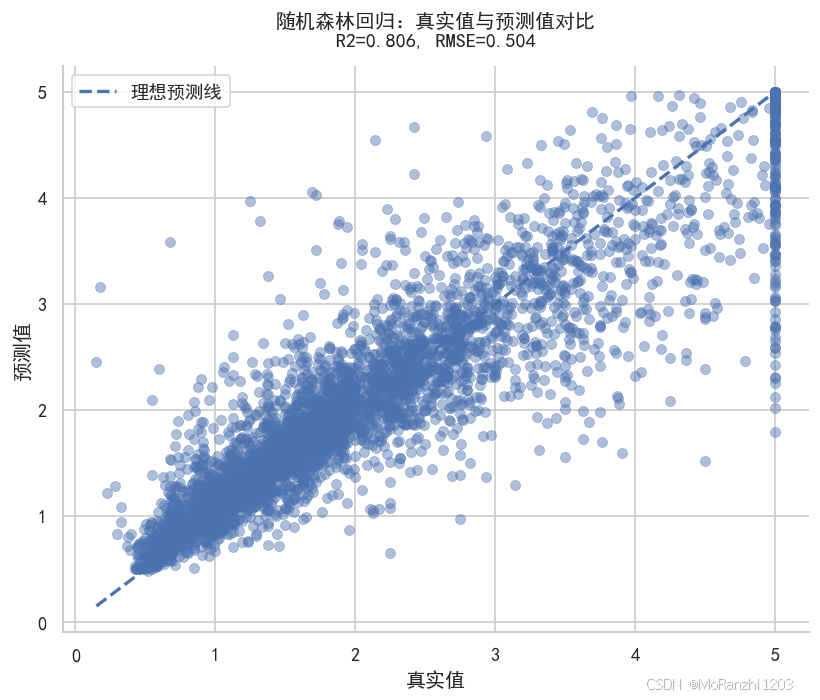
如果散点越接近理想预测线,说明模型预测越准确。随机森林回归器通过平均多棵树的结果,能够较好地处理非线性关系,因此在房价预测、销量预测、风险评分等任务中经常被使用。
9.6 残差分析
仅观察真实值和预测值对比还不够。为了进一步分析模型误差,可以绘制残差图。
残差定义为:
ei=yi−y^i e_i = y_i - \hat{y}_i ei=yi−y^i
其中,yiy_iyi 是真实值,y^i\hat{y}_iy^i 是预测值。
python
residuals = y_test_reg - y_pred_reg
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
ax = axes[0]
sns.scatterplot(
x=y_pred_reg,
y=residuals,
alpha=0.4,
edgecolor=None,
ax=ax
)
ax.axhline(
0,
linestyle="--",
linewidth=1.5
)
ax.set_title("残差与预测值关系", pad=12, weight="bold")
ax.set_xlabel("预测值")
ax.set_ylabel("残差")
ax = axes[1]
ax.hist(
residuals,
bins=40,
edgecolor="white",
alpha=0.85
)
ax.axvline(
0,
linestyle="--",
linewidth=1.5
)
ax.set_title("残差分布", pad=12, weight="bold")
ax.set_xlabel("残差")
ax.set_ylabel("频数")
fig.tight_layout()
plt.show()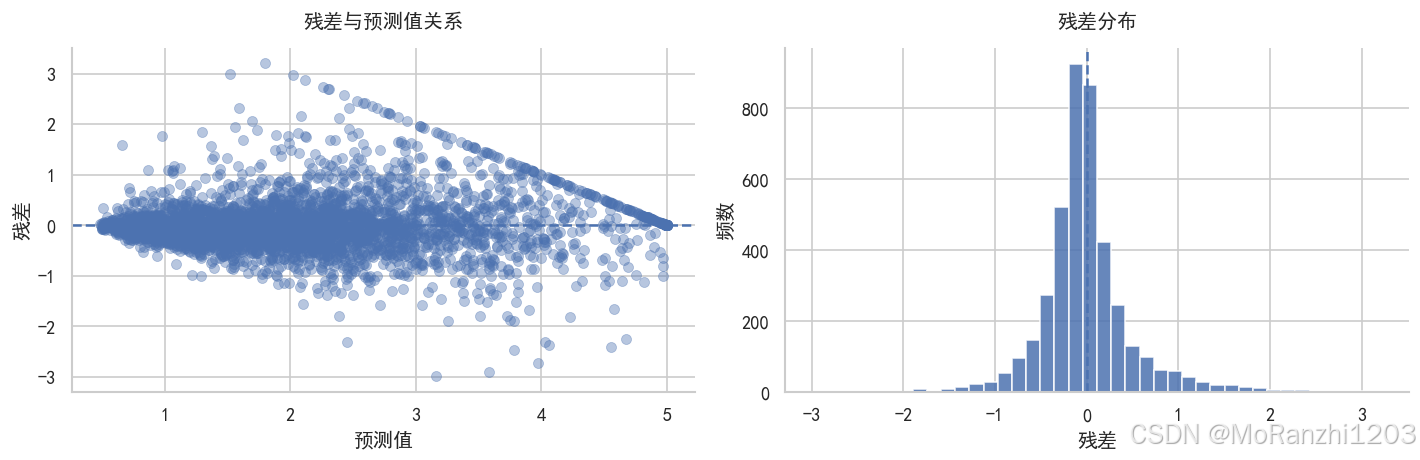
残差分析可以帮助我们判断模型误差是否存在明显模式。如果残差围绕 0 随机分布,说明模型拟合较为稳定;如果残差随着预测值增大而呈现明显趋势,则说明模型可能在某些区间存在系统性偏差。
10. 回归模型解释:特征重要性
下面分析随机森林回归模型中的特征重要性。
python
importance_reg_df = pd.DataFrame({
"特征": housing.feature_names,
"重要性": rf_reg.feature_importances_
}).sort_values("重要性", ascending=False)
fig, ax = plt.subplots(figsize=(8, 5))
sns.barplot(
data=importance_reg_df,
x="重要性",
y="特征",
hue="特征",
palette="Greens_r",
legend=False,
ax=ax
)
# 在条形图右侧显示重要性数值
for container in ax.containers:
ax.bar_label(
container,
fmt="%.3f",
padding=4,
fontsize=10
)
# 给右侧数值预留空间,避免文字被裁剪
max_importance = importance_reg_df["重要性"].max()
ax.set_xlim(0, max_importance * 1.15)
ax.set_title("随机森林回归特征重要性", pad=12, weight="bold")
ax.set_xlabel("重要性得分")
ax.set_ylabel("特征名称")
ax.grid(axis="x", linestyle="--", alpha=0.3)
fig.tight_layout()
plt.show()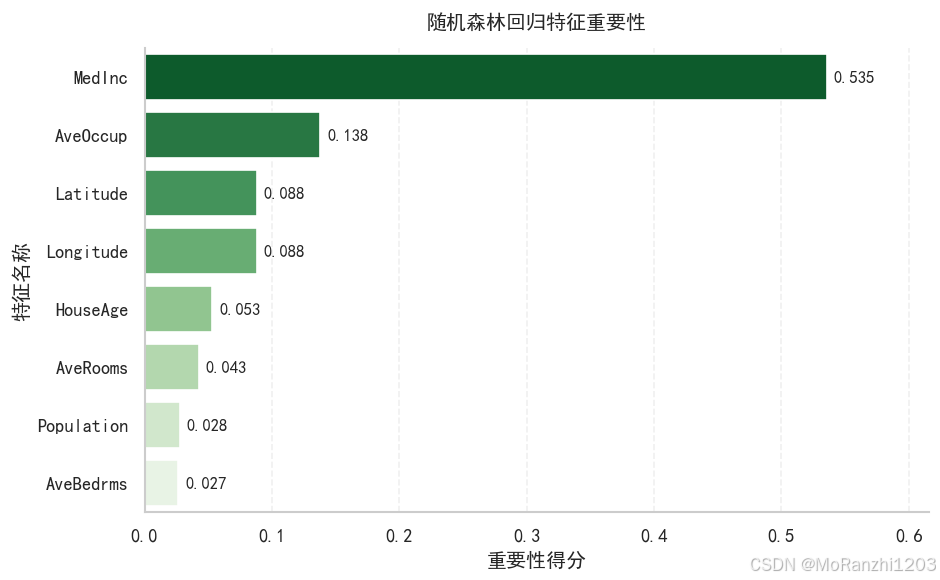
在加州房价预测任务中,收入中位数、地理位置、居住密度等变量通常会对房价预测产生重要影响。
需要注意的是,feature_importances_ 是基于模型分裂过程计算得到的特征重要性。它适合快速了解模型依赖哪些特征,但在正式分析中仍需要结合业务背景、数据分布和其他解释方法综合判断。
11. 回归任务超参数调优
对于加州房价这种数据量较大的回归任务,如果直接使用大范围 GridSearchCV,运行时间可能很长。因为全量网格搜索会遍历所有参数组合,再乘以交叉验证折数,训练次数很容易达到几百次。
例如:
text
3 × 3 × 3 × 3 = 81 组参数
81 × 5 折交叉验证 = 405 次模型训练而每次随机森林训练又包含大量决策树,因此整体耗时会非常明显。
在正式博客和普通电脑环境中,更推荐使用 RandomizedSearchCV。它不是遍历全部参数组合,而是在给定参数空间中随机采样一部分组合进行搜索,运行速度更快,也更适合演示。
11.1 随机搜索调参
python
param_dist_reg = {
"n_estimators": [80, 120, 160, 200],
"max_depth": [6, 10, None],
"min_samples_leaf": [1, 2, 4],
"max_features": [0.6, 0.8, 1.0]
}
random_search_reg = RandomizedSearchCV(
estimator=RandomForestRegressor(random_state=42, n_jobs=1),
param_distributions=param_dist_reg,
n_iter=12,
cv=3,
scoring="neg_mean_squared_error",
n_jobs=-1,
random_state=42,
verbose=1
)
random_search_reg.fit(X_train_reg, y_train_reg)
best_cv_rmse = np.sqrt(-random_search_reg.best_score_)
print("最佳参数:", random_search_reg.best_params_)
print(f"最佳交叉验证 RMSE: {best_cv_rmse:.4f}")
text
Fitting 3 folds for each of 12 candidates, totalling 36 fits
最佳参数: {'n_estimators': 200, 'min_samples_leaf': 2, 'max_features': 0.6, 'max_depth': None}
最佳交叉验证 RMSE: 0.5038这里设置:
n_iter=12:只随机搜索 12 组参数;cv=3:使用 3 折交叉验证;n_jobs=-1:让外层搜索并行;estimator内部设置n_jobs=1,避免内外两层同时抢占 CPU。
这样可以在保持调参效果的同时,明显缩短运行时间。
11.2 使用最佳参数训练最终模型
python
best_params_reg = random_search_reg.best_params_
best_rf_reg = RandomForestRegressor(
**best_params_reg,
random_state=42,
n_jobs=-1
)
best_rf_reg.fit(X_train_reg, y_train_reg)
y_pred_best_reg = best_rf_reg.predict(X_test_reg)
best_rmse = np.sqrt(mean_squared_error(y_test_reg, y_pred_best_reg))
best_r2 = r2_score(y_test_reg, y_pred_best_reg)
print(f"测试集 RMSE: {best_rmse:.4f}")
print(f"测试集 R2 : {best_r2:.4f}")
text
测试集 RMSE: 0.4967
测试集 R2 : 0.8117随机搜索得到的参数不一定保证是全局最优,但在大多数实际场景中,它能够以较低的计算成本找到较好的参数组合,适合作为随机森林调参的常用方法。
12. 随机森林的优缺点
12.1 优点
1)泛化能力强。
随机森林通过多棵树集成,能够显著降低单棵决策树的方差,使模型在测试集上的表现更加稳定。
2)能处理非线性关系。
随机森林基于决策树,不要求特征与目标之间是线性关系,因此适合处理复杂的非线性数据。
3)对特征缩放不敏感。
与逻辑回归、支持向量机、KNN 等模型不同,随机森林通常不需要强制标准化特征。
4)可用于分类和回归。
RandomForestClassifier 适合分类任务,RandomForestRegressor 适合回归任务。
5)可输出特征重要性。
随机森林可以用于特征筛选、变量解释和建模分析。
6)支持并行训练。
多棵树之间相对独立,可以通过 n_jobs=-1 使用多个 CPU 核心加速训练。
7)可使用 OOB 估计泛化能力。
在启用 Bootstrap 的情况下,随机森林可以使用袋外样本估计模型表现,减少对额外验证集的依赖。
12.2 缺点
1)模型体积较大。
树的数量越多,模型越大,占用内存越高。
2)解释性弱于单棵决策树。
单棵树可以直接导出规则,但随机森林包含大量树,整体规则不如单棵树直观。
3)预测速度可能较慢。
当 n_estimators 很大时,每次预测都需要经过多棵树。
4)特征重要性存在偏差。
默认特征重要性可能偏向连续特征或高基数特征,因此需要谨慎解释。
5)对高维稀疏数据不一定最优。
对于文本分类等高维稀疏数据,线性模型、朴素贝叶斯或深度学习模型可能更合适。
6)对外推能力有限。
随机森林本质上是基于训练数据中的局部划分进行预测,对于训练数据范围之外的外推任务,表现可能不如某些参数模型。
13. 与决策树、梯度提升的对比
随机森林、决策树和梯度提升都属于树模型体系,但三者的建模方式和适用侧重点并不相同。决策树是最基础的单模型方法,随机森林是在多棵决策树基础上进行并行集成,梯度提升则是通过多轮迭代逐步修正预测误差。
| 模型 | 核心思想 | 主要优点 | 主要局限 | 适用场景 |
|---|---|---|---|---|
| 决策树 | 通过单棵树逐层划分样本,最终在叶节点给出预测结果 | 结构直观、规则清晰、可解释性强 | 容易受训练数据扰动影响,树过深时容易过拟合 | 适合教学演示、规则解释、简单分类或回归任务 |
| 随机森林 | 构建多棵相互差异较大的决策树,并通过投票或平均得到最终结果 | 稳定性强、抗过拟合能力较好、对参数不太敏感 | 模型体积较大,整体解释性弱于单棵决策树 | 适合作为分类、回归和特征重要性分析中的强基线模型 |
| 梯度提升 | 依次训练多棵弱学习器,后一棵树重点修正前一轮模型的预测误差 | 预测精度高、表达能力强、适合复杂非线性建模 | 训练过程更慢,参数调节更敏感,过拟合风险更高 | 适合对预测精度要求较高的结构化数据任务 |
从模型结构上看,决策树是单模型,随机森林和梯度提升都是集成模型。随机森林采用并行集成思想,每棵树相对独立,通过样本随机和特征随机增强树之间的差异,最终利用多棵树的综合结果降低方差。因此,随机森林通常具有较好的稳定性,适合作为实际项目中的基线模型。
梯度提升采用串行集成思想,每一棵新树都依赖前面模型的预测结果,重点学习前一轮尚未拟合好的部分。也就是说,随机森林更强调"让多棵树独立判断后综合决策",而梯度提升更强调"逐步修正误差、不断逼近最优模型"。
在实际应用中,如果希望模型稳定、调参成本较低,并且需要一定的特征解释能力,可以优先尝试随机森林;如果任务对预测精度要求更高,并且可以投入更多时间进行参数调优,则可以进一步尝试梯度提升类模型。
14. 实际应用场景
随机森林适用于分类、回归和特征分析等多种机器学习任务,尤其适合结构化数据场景。由于它能够处理非线性关系,并且对特征缩放不敏感,因此在实际项目中经常被用作稳定可靠的基线模型。
在金融风控中,随机森林可以用于信用评分、欺诈检测、贷款违约预测和客户风险分层。模型可以根据用户的历史行为、资产情况、交易记录等特征,判断用户是否存在较高风险。
在医疗诊断中,随机森林可以用于疾病分类、风险预测和医学指标重要性分析。例如,可以根据患者的检查指标、年龄、病史等信息,辅助判断疾病风险,并分析哪些指标对预测结果影响较大。
在市场营销中,随机森林可以用于用户流失预测、客户转化预测、广告点击率预测和用户价值评估。通过特征重要性分析,还可以帮助业务人员理解影响用户行为的关键因素。
在工业制造中,随机森林可以用于设备故障预测、质量检测和异常原因分析。由于它能够处理复杂的非线性关系,因此适合分析多传感器数据、生产过程数据和设备运行状态数据。
在交通与环境预测中,随机森林可以用于交通流量预测、空气质量预测、能耗预测和异常事件识别。例如,在交通流量预测任务中,可以结合历史流量、时间特征、天气信息和道路属性等变量建立预测模型。
此外,随机森林还常用于特征筛选 。通过 feature_importances_ 可以初步判断哪些变量对模型预测贡献较大,为后续建模、变量解释和业务分析提供参考。不过,特征重要性并不等同于因果关系,在正式分析中仍需要结合业务背景和其他解释方法综合判断。
15. 总结
随机森林是机器学习中非常实用的集成学习算法。它以决策树为基础,通过 Bootstrap 抽样和随机特征选择构造多棵差异化的树,再通过投票或平均得到最终预测结果。
从原理上看,随机森林的核心可以概括为三点:第一,通过 Bootstrap 抽样让不同树看到不同训练数据;第二,通过随机特征选择降低树与树之间的相关性;第三,通过集成投票或平均降低单棵树的方差。
在分类任务中,随机森林可以结合准确率、分类报告、混淆矩阵和 ROC 曲线评估模型效果;在回归任务中,可以结合 MAE、RMSE、R2、真实值与预测值对比图以及残差分析判断预测性能。通过特征重要性,还可以进一步理解模型主要依赖哪些变量进行判断。
相比单棵决策树,随机森林显著提升了模型的稳定性和泛化能力;相比梯度提升,它的训练过程更容易并行,参数敏感性相对较低。在实际使用中,n_estimators、max_depth、max_features、min_samples_leaf 和 class_weight 是最值得关注的参数。
总体来看,随机森林既继承了决策树处理非线性关系的能力,又通过集成学习缓解了单棵树不稳定、易过拟合的问题。它训练稳定、适用范围广、调参成本相对较低,是分类、回归和特征分析任务中都值得优先尝试的强基线模型。