目录
-
- [一、 排序算法全局图谱](#一、 排序算法全局图谱)
- [二、 内部排序:核心指标终极对比表](#二、 内部排序:核心指标终极对比表)
- [三、 多维度深度剖析与考点总结](#三、 多维度深度剖析与考点总结)
-
- [3.1 时间复杂度维度:](#3.1 时间复杂度维度:)
- [3.2 空间复杂度维度:](#3.2 空间复杂度维度:)
- [3.3 稳定性规律:](#3.3 稳定性规律:)
- [3.4 过程特征:每一趟的中间结果](#3.4 过程特征:每一趟的中间结果)
- [3.5 存储结构适用性](#3.5 存储结构适用性)
- [四、 真实业务场景](#四、 真实业务场景)
- [五、 工业级实现](#五、 工业级实现)
前言: 在前面的文章中,我们已经将插入、交换、选择、归并以及非比较类的核心排序算法逐一拆解。在掌握了各个具体算法的底层逻辑后,建立全局观、学会根据不同场景进行算法选型,是检验是否真正精通排序算法的唯一标准。本文将参考经典教材,对内部排序算法进行终极梳理与多维度大比拼。
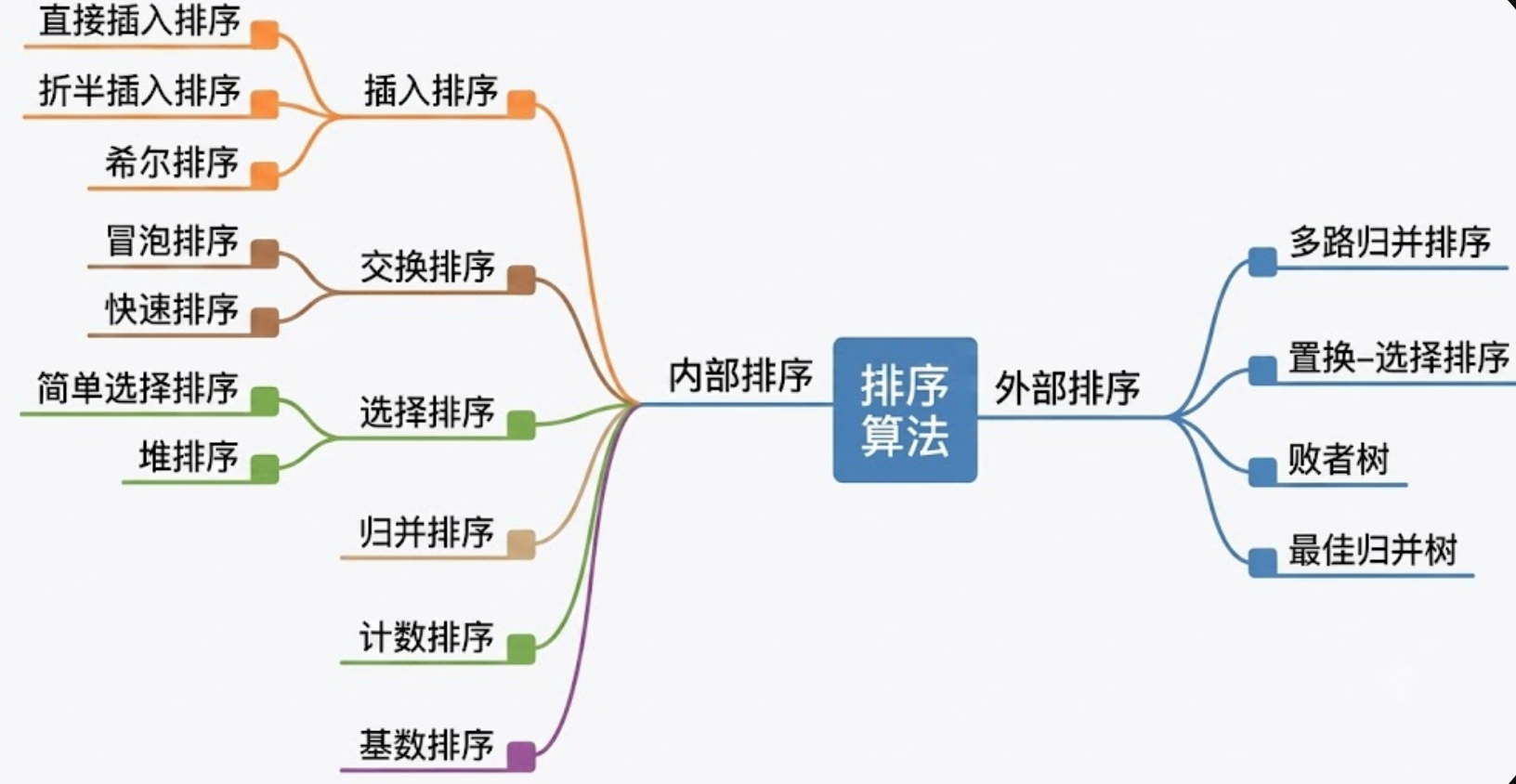
一、 排序算法全局图谱
在计算机科学中,排序算法首先按照数据是否完全在内存中处理分为两大类:
- 内部排序: 数据量不大,排序过程全部在内存中完成(本系列的核心)。
- 外部排序: 数据量过大,内存无法一次性装下,排序过程需在内存与外存(磁盘)之间不断进行数据交换。
在内部排序中,根据底层驱动机制又可分为:
- 比较类排序: 通过比较元素之间的大小来决定先后顺序。这类算法在最坏情况下的时间复杂度下界是 O ( n log n ) O(n \log n) O(nlogn)。
- 非比较类排序: 不通过比较,而是利用数据的内在特征(如按位分配、计数)进行排序,可突破 O ( n log n ) O(n \log n) O(nlogn) 的下界,达到线性时间 O ( n ) O(n) O(n)。
二、 内部排序:核心指标终极对比表
| 算法分类 | 算法名称 | 最好时间复杂度 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|---|
| 插入类 | 直接插入排序 | O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 折半插入排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 | |
| 希尔排序 | - | 约 O ( n 1.3 ) O(n^{1.3}) O(n1.3) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 | |
| 交换类 | 冒泡排序 | O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 快速排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n 2 ) O(n^2) O(n2) | O ( log n ) O(\log n) O(logn) | 不稳定 | |
| 选择类 | 简单选择排序 | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 |
| 堆排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( 1 ) O(1) O(1) | 不稳定 | |
| 归并类 | 二路归并排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n ) O(n) O(n) | 稳定 |
| 非比较类 | 计数排序 | O ( n + k ) O(n+k) O(n+k) | O ( n + k ) O(n+k) O(n+k) | O ( n + k ) O(n+k) O(n+k) | O ( n + k ) O(n+k) O(n+k) | 稳定 |
| 基数排序 | O ( d ( n + r ) ) O(d(n+r)) O(d(n+r)) | O ( d ( n + r ) ) O(d(n+r)) O(d(n+r)) | O ( d ( n + r ) ) O(d(n+r)) O(d(n+r)) | O ( r ) O(r) O(r) | 稳定 | |
| (注: k k k 为计数范围, d d d 为数据位数, r r r 为基数) |
三、 多维度深度剖析与考点总结
3.1 时间复杂度维度:
- O ( n 2 ) O(n^2) O(n2) 阵营: 简单选择排序、直接插入排序、冒泡排序。其中,简单选择排序最死板 ,无论初始状态如何都是 O ( n 2 ) O(n^2) O(n2);而直接插入和冒泡(带优化)最聪慧 ,在数组"基本有序"时,可迅速降级为 O ( n ) O(n) O(n)。
- O ( n log n ) O(n \log n) O(nlogn) 阵营: 快速排序、堆排序、归并排序。
- 快速排序: 平均情况下实测最快,但极其忌讳"基本有序"的数据,最坏会退化到 O ( n 2 ) O(n^2) O(n2)。
- 堆排序与归并排序: 极其稳健,最好、最坏、平均时间永远死死锁定在 O ( n log n ) O(n \log n) O(nlogn)。
3.2 空间复杂度维度:
- 原地排序 ( O ( 1 ) O(1) O(1)): 插入类、冒泡、简单选择、堆排序。
- 快速排序 ( O ( log n ) O(\log n) O(logn)): 并非原地排序,其空间开销来源于递归调用栈。最坏情况下(单支树)空间会退化到 O ( n ) O(n) O(n)。
- 归并排序 ( O ( n ) O(n) O(n)): 典型的空间换时间,需要一个与原数组等大的辅助数组用于合并。
3.3 稳定性规律:
- 业务意义: 在多关键字排序中(例如:先按销量排,相同的再按价格排),稳定的算法能保留上一次排序的相对顺序。
- 规律口诀: "长距离、大跨步交换的算法通常不稳定,相邻交换或顺次挪位的算法通常稳定。"
- 希尔排序(按 gap 跨步交换)、快速排序(跨越整个数组填坑)、选择排序(跨越无序区交换)、堆排序(首尾直接交换)均不稳定。
- 直接插入、冒泡、归并排序均稳定。
3.4 过程特征:每一趟的中间结果
- 能确定最终位置的算法: 冒泡排序、简单选择排序、快速排序、堆排序。这四种算法,每完成一趟处理,必定能将至少一个元素放到它的最终确切位置上。
- 不能确定最终位置的算法: 直接插入排序、折半插入排序。它们只是局部有序,新元素的插入可能导致前面已排好的所有元素集体后移。
3.5 存储结构适用性
- 仅适用于顺序存储(数组): 折半插入排序、希尔排序、快速排序、堆排序。它们严重依赖随机访问(通过下标跳跃查找)。
- 顺序与链式存储皆可: 直接插入排序、冒泡排序、简单选择排序、归并排序、基数排序。如果数据节点特别大,移动数据代价极高,使用链表结合这些算法(仅修改指针)是绝佳选择。
四、 真实业务场景
在实际的软件工程中,没有一种算法能包打天下。我们需要根据具体的数据环境进行智能选型:
- 当数据量 n n n 极小 ( n < 50 n < 50 n<50**) 时:**
- 优先选择 直接插入排序 或 简单选择排序。
- 原因: 虽然理论复杂度是 O ( n 2 ) O(n^2) O(n2),但在 n n n 极小的情况下,它们没有递归调用栈的开销,且常数项极小,实测速度往往超过快排。
- 当数据量 n n n 极大,且对内存没有严格限制时:
- 首选 快速排序。
- 原因: 它是基于比较的排序中常数因子最小的算法,缓存命中率极高,综合性能制霸全场。
- 当数据量 n n n 极大,且要求最坏情况绝不能卡顿(如航天、军工、实时系统):
- 选择 堆排序 或 归并排序。
- 原因: 快速排序在极端恶劣数据下会退化,而堆排和归并能将时间严格控制在 O ( n log n ) O(n \log n) O(nlogn)。若内存极为受限,选堆排序( O ( 1 ) O(1) O(1) 空间);若要求稳定,选归并排序。
- 当数据初始状态"基本有序"时:
- 强烈推荐 直接插入排序 或 冒泡排序。
- 原因: 此时它们的比较和移动次数极少,时间复杂度趋近于线性的 O ( n ) O(n) O(n),比快排还要快。
- 当数据是范围密集的整数(如全省高考成绩排行):
- 直接使用 计数排序 或 基数排序。
- 原因: 降维打击,直接突破 O ( n log n ) O(n \log n) O(nlogn) 极限,实现 O ( n ) O(n) O(n) 级别的神速排序。
五、 工业级实现
如果你去阅读 C++ 的 std::sort 或 Java/Python 的内部排序源码,你会发现真实的工业界从来不单纯使用某一种单一算法。
以大名鼎鼎的 IntroSort(内省式排序) 为例:
- 起手: 对于庞大的数据,首先使用快速排序进行宏观分治,追求极致速度。
- 监控: 算法内部会监控递归的深度。如果发现递归深度超过了 2 log n 2 \log n 2logn,说明遭遇了恶劣数据,有退化为 O ( n 2 ) O(n^2) O(n2) 的风险。
- 切换: 此时,算法会立刻"急刹车",停止快排,切换为绝对稳健的堆排序 ,守住 O ( n log n ) O(n \log n) O(nlogn) 的底线。
- 收尾: 当快排将数组划分成长度极小(如小于 16)的子区间时,算法停止递归,对整个接近有序的数组来一次直接插入排序,完成最后的精修。
结语与下篇预告:
至此,我们关于内部排序的盘点已圆满收官。但是,挑战并未结束------当数据规模暴涨到 GB 甚至 TB 级别,连内存都无法一次性装下时,我们该如何打破物理内存的枷锁?下篇带你深入了解。