第一阶段:理论起源(2005--2019)
这一阶段主要解决:
如何学习一个复杂数据分布的梯度(score)?
1. Score Matching(理论基础)
代表论文:
Estimation of Non-Normalized Statistical Models by Score Matching
Hyvärinen, JMLR 2005
研究背景
传统生成模型通常采用最大似然估计(Maximum Likelihood Estimation,MLE)训练。然而,对于许多复杂概率模型,其概率密度函数通常写为
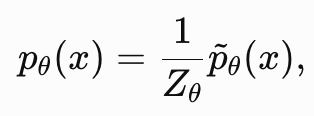
其中配分函数(Partition Function)(是要计算所有图片概率分布的总和)难以计算,从而导致最大似然估计难以优化。
因此,提出:不直接学习概率密度,而是学习概率密度的梯度(Score Function)。
贡献
- 提出 Score Matching
- 不需要计算配分函数
- 通过最小化模型 Score 与真实数据 Score 的差异来训练模型:
后来所有 Score-based Diffusion 都建立在这里。
2. Denoising Score Matching
代表论文:
A Connection Between Score Matching and Denoising Autoencoders
Pascal Vincent, 2011
研究背景
虽然 Score Matching 提供了理论框架,但需要计算高阶导数,其训练过程难以扩展到高维数据。因此,需要寻找一种更加简单、高效的 Score 学习方式。
贡献
在前人已经发现"可以通过学数据分布的梯度来学数据分布"的基础上提出让网络通过学会"去噪",来计算数据分布的梯度 。
- 建立了 去噪(Denoising)与 Score Matching 间的联系
- 将复杂的 Score Matching 优化转化为简单的去噪回归问题,降低了训练难度。
3. 第一篇 Diffusion Model
代表论文:
Deep Unsupervised Learning Using Nonequilibrium Thermodynamics
Sohl-Dickstein et al., ICML 2015
首次提出:
- Forward diffusion(不断加噪)
- Reverse diffusion(逐步去噪)
首次将"逐步加噪---逐步去噪"作为生成模型的核心思想,是现代 diffusion 的雏形。
但是:
- 太慢
- 网络不好训练
- 图像质量一般
4. Score-based Model
代表论文:
Generative Modeling by Estimating Gradients of the Data Distribution
Song & Ermon, NeurIPS 2019
研究背景
Denoising Score Matching 已经解决了 Score 的学习问题,但只能学习单一噪声水平下的 Score Function。而扩散过程涉及多个不同噪声阶段,因此需要建立能适应不同噪声水平的统一模型。
贡献
提出 Noise Conditional Score Network(NCSN), 将噪声水平作为网络输入,使模型能够同时学习多个噪声尺度下的数据分布梯度: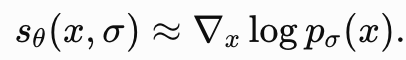 提出 Noise Conditional Score Network,实现多噪声尺度下的 Score 学习。
提出 Noise Conditional Score Network,实现多噪声尺度下的 Score 学习。
- 提出 Annealed Langevin Dynamics,首次构建完整的 Score-based 图像生成流程。
- 将 Score Matching 从一种训练方法发展成完整的生成模型框架,是现代 Score-based Diffusion 的开始。
第二阶段:现代 Diffusion 的诞生(2020)
这一阶段真正引爆整个领域。
DDPM
代表论文:
Denoising Diffusion Probabilistic ModelsHo, Jain, Abbeel,NeurIPS 2020
这是最重要的一篇。
研究背景
NCSN 已经证明利用 Score Function 可以进行高质量图像生成,但依赖 Langevin Dynamics 多次迭代采样,训练和推理过程均较复杂,计算开销巨大,生成速度慢。因此,希望构建一种训练更稳定、采样过程更规范的扩散生成框架。
把 diffusion 简化成:
Forward:不断加 Gaussian Noise,最终得到标准高斯分布。
Reverse:预测噪声,从随机噪声恢复真实图像。
训练目标简化为: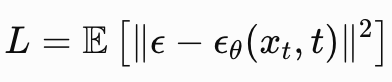
这是今天几乎所有 diffusion 的基础。几乎所有 Stable Diffusion、Imagen、DALL-E2 都继承自 DDPM。
主要贡献
- 建立了现代扩散模型的标准框架,包括前向扩散与反向去噪两个阶段。
- 将复杂的概率建模问题转化为简单的噪声预测问题
- 从变分推断(Variational Inference)角度推导了扩散模型的理论基础。
第三阶段:采样速度革命(2020--2021)
DDPM 的最大问题:需要1000 step生成一张图。于是进入采样优化时代,研究重点转向如何减少采样步数,提高扩散模型的生成速度。
DDIM
代表论文:
Denoising Diffusion Implicit Models
Song et al., ICLR 2021
核心思想
DDIM发现,扩散模型的反向过程并不一定要保持随机性,可以构造一个确定性(Deterministic)采样过程。
通过重新设计反向更新公式,DDIM 能够在保持生成质量的同时,大幅减少采样步数。
贡献:
提出非马尔可夫扩散过程,随机采样 **→**变成确定性采样。
结果:1000 step **→**50 step甚至20 step。
这是第一次真正让 diffusion 可用。
Improved DDPM
代表论文:
Improved Denoising Diffusion Probabilistic Models
Nichol & Dhariwal,ICML 2021
研究背景
DDPM 在训练稳定性和生成质量方面仍有进一步优化空间,例如噪声调度方式和方差估计方式仍较为简单。
核心思想
从多个方面改进 DDPM:
- 提出 Cosine Noise Schedule,优化噪声添加过程;
- 学习反向扩散方差,提高生成质量;
- 改进损失函数设计。
主要贡献
- 提高了图像生成质量、减少了采样步数、提升了训练稳定性。
Diffusion Models Beat GANs
代表论文:
Diffusion Models Beat GANs on Image Synthesis
Dhariwal & Nichol, NeurIPS 2021
Diffusion第一次正式超过 GAN。从这一刻开始,GAN 基本退出图像生成主流。
第四阶段:统一理论(2021)
随着 DDPM 和 Score-based Model 的快速发展,人们逐渐意识到两条技术路线具有高度相似性。因此,Song 等人进一步从随机微分方程(SDE)的角度统一了两种模型
Score SDE
代表论文:
Score-Based Generative Modeling through Stochastic Differential Equations
Song et al. ICLR 2021
这是理论上最重要的一篇。
研究背景
DDPM 与 NCSN 分别从概率模型和 Score Learning 两个角度描述扩散过程,两者理论联系尚不明确。
核心思想
论文将扩散过程推广为连续时间随机微分方程(SDE):
在这一框架下:
- DDPM 可视为离散时间扩散过程;
- NCSN 可视为连续时间 Score Learning。
论文进一步提出 Probability Flow ODE,使扩散采样可以采用 ODE 数值积分方法完成。
主要贡献
- 首次统一 DDPM 与 Score-based Model。
- 建立连续时间扩散理论。
- 为后续高阶采样器提供理论基础。
于是:DDPM → Score Model**→**SDE 统一起来。
第五阶段:条件生成时代(2021--2022)
研究重点开始转向文本条件控制以及高分辨率图像生成。
代表工作:
Classifier Guidance
论文:
Diffusion Models Beat GANs on Image Synthesis
Dhariwal & Nichol, NeurIPS 2021
研究背景
DDPM 生成结果完全随机,无法指定生成"猫""汽车"等特定类别。需要一种机制,在扩散采样过程中利用条件信息约束生成方向。
核心思想
论文首次提出 Classifier Guidance,即利用一个额外训练好的分类器,在反向扩散过程中引入类别信息,对采样方向进行引导。
设扩散模型预测的 Score 为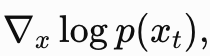 分类器能计算样本属于目标类别 y 的概率
分类器能计算样本属于目标类别 y 的概率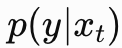
根据贝叶斯公式,条件分布的 Score:
在每一步去噪过程中,都用分类器梯度修正采样轨迹,使生成结果逐渐靠近目标类别。
主要贡献
- 首次提出 Guidance(引导采样) 的概念,使扩散模型具备条件生成能力。
- 将分类器梯度融入反向扩散过程,实现类别可控生成。
Classifier-Free Guidance(CFG)
代表论文:
Classifier-Free Diffusion Guidance
Ho & Salimans, NeurIPS Workshop 2021
研究背景
虽然 Classifier Guidance 存在以下不足:
-
需要额外训练分类器 扩散模型之外,还需要训练一个能够识别不同噪声水平图像的分类器,增加了训练成本。
-
分类器容易产生噪声 扩散早期图像噪声较大,分类器预测往往不准确,影响引导效果。
-
训练流程复杂 需要分别训练扩散模型和分类器,工程实现繁琐。
核心思想
提出无需分类器,通过随机丢弃条件信息,同时训练有条件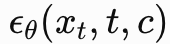 和无条件模型
和无条件模型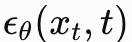 ,在推理阶段线性组合两者预测结果
,在推理阶段线性组合两者预测结果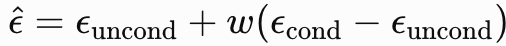 ,实现条件控制。
,实现条件控制。
其中 w 为 Guidance Scale,w 增大时,模型更加遵循条件信息;当 w=1时,相当于普通条件生成。
主要贡献
- 无需额外分类器。
- 提高了文本控制能力。
- Guidance Scale可灵活调节生成质量与条件一致性之间的平衡。
第六阶段:Latent Diffusion(2022)
真正改变产业。
代表论文:
High-Resolution Image Synthesis with Latent Diffusion Models
Rombach et al. CVPR 2022
贡献:首次提出潜空间扩散
以前:Diffusion直接在 Pixel 上,高分辨率图像计算量巨大。
现在:先经过 VAE → Latent Space → Diffusion **→**VAE解码恢复图像,计算量下降约几十倍。
Stable Diffusion 就来自这里。
第七阶段:大模型时代(2022--2023)
开始和 Transformer 融合。
代表模型:
- OpenAI 的 DALL·E 2
- Google Imagen
- Stable Diffusion
- SDXL
共同特点:Transformer + Diffusion。
第八阶段:Sampling Solver(2022--2023)
模型已经很好。瓶颈变成:如何更快采样。
代表论文:
DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling
Lu et al., NeurIPS 2022
把采样看成 ODE 数值积分。20 step 甚至 10 step 即可生成高质量图片。
第九阶段:Diffusion Transformer(2023)
代表论文:
Scalable Diffusion Models with Transformers (DiT)
Peebles & Xie,ICCV 2023
核心思想
用 Vision Transformer 替代 U-Net 作为去噪网络,使扩散模型能更好地利用 Transformer 的大规模建模能力。
主要贡献
- Transformer 成为新的扩散骨干网络。
- 提高模型扩展能力和生成质量。
第十阶段:Flow Matching(2023--至今)
近年来最热门方向。
代表论文:
Flow Matching for Generative Modeling
Lipman et al. ICLR 2023
研究背景
扩散模型虽然生成质量优秀,但仍需要模拟随机扩散过程,训练和采样成本较高。
核心思想
Flow Matching 不再模拟随机扩散,直接学习数据分布与简单分布(如高斯分布)之间的连续流场(Vector Field)。
优点:
- 更稳定
- 更容易训练
- 更适合 与 Transformer 结合
- 更快采样
整体发展脉络(建议牢记)
Score Matching (2005)
│
▼
Denoising Score Matching (2011)
│
▼
Diffusion Model (2015)
│
▼
NCSN / Score Model (2019)
│
├─────────────┐
▼ │
DDPM (2020) │
│ │
▼ │
DDIM (2021) │
▼ │
Improved DDPM │
▼ │
Diffusion > GAN │
▼ │
Score SDE (统一理论) ──┘
│
▼
Classifier-Free Guidance
│
▼
Latent Diffusion (Stable Diffusion)
│
▼
DPM Solver
│
▼
DiT (Transformer)
│
▼
Flow Matching推荐阅读顺序(10 篇经典论文)
如果目标是系统掌握扩散模型,我建议按下面顺序阅读:
| 顺序 | 论文 | 作用 |
|---|---|---|
| 1 | Deep Unsupervised Learning Using Nonequilibrium Thermodynamics (2015) | 扩散模型起源 |
| 2 | Generative Modeling by Estimating Gradients of the Data Distribution (2019) | Score-based 思想 |
| 3 | Denoising Diffusion Probabilistic Models (DDPM) (2020) | 现代扩散模型基础 |
| 4 | Denoising Diffusion Implicit Models (DDIM) (2021) | 快速采样 |
| 5 | Improved Denoising Diffusion Probabilistic Models (2021) | DDPM 改进 |
| 6 | Score-Based Generative Modeling through Stochastic Differential Equations (2021) | SDE 统一理论 |
| 7 | Classifier-Free Diffusion Guidance (2021) | 条件生成核心技术 |
| 8 | High-Resolution Image Synthesis with Latent Diffusion Models (2022) | Stable Diffusion 基础 |
| 9 | Scalable Diffusion Models with Transformers (DiT) (2023) | Transformer 化扩散模型 |
| 10 | Flow Matching for Generative Modeling (2023) | 最新生成范式方向 |
这个顺序基本覆盖了扩散模型从理论基础 → DDPM → SDE 统一 → Latent Diffusion → Transformer → Flow Matching的完整技术演进。