数据库模型分为层次模型,网状模型,关系模型
整数类型
| 类型 | 字节数 | 有符号范围 | 无符号范围 |
|---|---|---|---|
TINYINT |
1 | -128 ~ 127 | 0 ~ 255 |
SMALLINT |
2 | -32,768 ~ 32,767 | 0 ~ 65,535 |
MEDIUMINT |
3 | -8,388,608 ~ 8,388,607 | 0 ~ 16,777,215 |
INT / INTEGER |
4 | -2,147,483,648 ~ 2,147,483,647 | 0 ~ 4,294,967,295 |
BIGINT |
8 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 0 ~ 18,446,744,073,709,551,615 |
UNSIGNED:加在类型后面,表示无符号,不能存负数,范围翻倍。比如age TINYINT UNSIGNED存 0~255AUTO_INCREMENT:只能用于整数,自动递增,通常用INT或BIGINT
浮点数(近似值)
| 类型 | 字节数 | 有效数字 | 说明 |
|---|---|---|---|
FLOAT |
4 | 约7位 | 单精度 |
FLOAT(p) |
4或8 | p≤24为4字节 | 根据p决定 |
DOUBLE |
8 | 约15位 | 双精度 |
DOUBLE PRECISION |
8 | 约15位 | DOUBLE 同义词 |
- 不是精确存储 ,存在精度问题,如
0.1可能存成0.100000001 - 不要用于金额计算
- 适合:科学计算、统计数据、评分等可容忍微小误差的场景
定点数(精确值)
| 类型 | 说明 |
|---|---|
DECIMAL(M, D) |
M=总位数(165),D=小数位数(030) |
NUMERIC(M, D) |
与 DECIMAL 完全等价 |
DEC |
等价于 DECIMAL(10,0) |
- 精确存储,不会有浮点误差
- 以字符串形式存储,空间随 M 变化
- 默认
DECIMAL=DECIMAL(10, 0) - 适合:金额、财务数据等必须精确的场景
BIT(位类型)
| 类型 | 长度 | 说明 |
|---|---|---|
BIT |
1位 | 等价 BIT(1) |
BIT(M) |
1~64位 | 存二进制位 |
- 存储二进制的 0 和 1 序列
- 查询时显示为二进制字符,转十进制用
字段名 + 0 - 适合:开关标志、权限位掩码等
字符串类型
| 类型 | 最大长度 | 存储方式 | 特点 |
|---|---|---|---|
CHAR(M) |
255字符 | 定长 | 不够补空格,取时去空格 |
VARCHAR(M) |
65535字节 | 变长 | 额外1~2字节存长度 |
CHAR 定长:
- 声明
CHAR(10)存 "abc",实际占 10 个字符空间 - 读取快,适合固定长度数据
- 最大 255 个字符
VARCHAR 变长:
- 声明
VARCHAR(10)存 "abc",只占 3 个字符 + 1字节记录长度 - 节省空间,适合变长数据
- 最大 65535 字节(注意是字节,不是字符,utf8mb4下一个字符占4字节,所以最多65535/4=16383个字符)
sql
id_card CHAR(18) -- 身份证固定18位
name VARCHAR(50) -- 名字长短不一
email VARCHAR(100) -- 邮箱长度不固定| 场景 | 用 CHAR | 用 VARCHAR |
|---|---|---|
| 数据长度固定 | ✅ | ❌ |
| 数据长度变化大 | ❌ | ✅ |
| 频繁更新 | ✅ | ❌(可能产生碎片) |
| 短字符串 | ✅ | 差别不大 |
TEXT 系列(大文本)
| 类型 | 最大长度 | 字节 |
|---|---|---|
TINYTEXT |
255 字节 | 256B-1 |
TEXT |
64 KB | 65,535 |
MEDIUMTEXT |
16 MB | 16,777,215 |
LONGTEXT |
4 GB | 4,294,967,295 |
- 存大量文本数据
- 不能有默认值
- 查询时不会完全加载到内存,适合大段文字
- 与 VARCHAR 区别:TEXT 有独立的存储区域
sql
introduction TEXT -- 简介
article MEDIUMTEXT -- 文章内容
log_data LONGTEXT -- 超长日志BLOB 系列(二进制大对象)
| 类型 | 最大长度 | 对应 TEXT |
|---|---|---|
TINYBLOB |
255 字节 | TINYTEXT |
BLOB |
64 KB | TEXT |
MEDIUMBLOB |
16 MB | MEDIUMTEXT |
LONGBLOB |
4 GB | LONGTEXT |
- 存二进制数据(图片、音频、文件等)
- 与 TEXT 区别:TEXT 存字符有字符集,BLOB 存字节没有字符集
- 实际开发中,大文件通常存文件服务器,数据库只存路径
sql
avatar BLOB -- 头像图片
file_data MEDIUMBLOB -- 文件内容ENUM(枚举)
| 类型 | 说明 |
|---|---|
ENUM('值1','值2',...) |
单选,最多 65535 个值 |
讲解:
- 存一个字符串,但内部用数字索引存储(省空间)
- 插入时必须是列表中的值,否则报错(严格模式下)
- 排序按索引顺序,不是字母顺序
sql
gender ENUM('男','女','保密')
status ENUM('正常','禁用','待审核')SET(集合)
| 类型 | 说明 |
|---|---|
SET('值1','值2',...) |
多选,最多 64 个值 |
- 可以选多个值,内部用位掩码存储
- 查询和插入有特殊语法
sql
hobby SET('阅读','运动','音乐','旅游')| 操作 | SQL |
|---|---|
| 插入多个 | INSERT INTO t VALUES ('阅读,音乐') |
| 查找包含 | WHERE FIND_IN_SET('音乐', hobby) |
| 精确匹配 | WHERE hobby = '阅读,音乐' |
BINARY 和 VARBINARY
| 类型 | 说明 |
|---|---|
BINARY(M) |
定长二进制,不够补 \0 |
VARBINARY(M) |
变长二进制 |
- 和 CHAR/VARCHAR 类似,但存的是字节,不涉及字符集
- BINARY 比较时按字节精确匹配
- 适合:哈希值、加密数据、UUID 等
sql
sha_hash BINARY(32) -- SHA256 哈希值
token VARBINARY(64) -- 随机令牌| 比较 | CHAR | BINARY |
|---|---|---|
| 'a' = 'A' | ✅(看排序规则) | ❌(字节不同) |
日期时间类型
| 类型 | 格式 | 范围 | 占字节 |
|---|---|---|---|
DATE |
YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 | 3 |
TIME |
HH:MM:SS | -838:59:59 ~ 838:59:59 | 3 |
DATETIME |
YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 5~8 |
TIMESTAMP |
YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 | 4~7 |
YEAR |
YYYY | 1901 ~ 2155 | 1 |
JSON 类型
| 类型 | 说明 | 引入版本 |
|---|---|---|
JSON |
存储 JSON 格式数据 | 5.7.8 |
sql
info JSON常用操作:
sql
-- 插入
INSERT INTO t VALUES ('{"name":"张三", "age":18}');
-- 插入一条数据,info 列存的是一段 JSON,里面有一个 name 字段是"张三",一个 age 字段是 18
-- 查询字段
SELECT info->'$.name' FROM t; -- 从 info 里把 name 字段取出来,返回带引号的 "张三"
-- `->` 是提取 JSON 字段的操作符
-- `'$.name'` 是路径,`$` 代表整个 JSON,`.name` 代表里面的 name
SELECT info->>'$.name' FROM t; -- 返回不带引号的 张三
SELECT JSON_EXTRACT(info, '$.age') FROM t; -- 提取值
-- 修改
UPDATE t SET info = JSON_SET(info, '$.age', 20) WHERE id = 1;JSON 就是一种数据格式,长这样:
json
{"name":"张三", "age":18, "hobby":["篮球","游戏"]}本质上就是一个字符串,但是有固定写法:用花括号包起来,里面是"键:值"对。
传统你得像这样建表,把所有可能的字段都建好:
sql
CREATE TABLE user (
id INT,
name VARCHAR(50),
wechat VARCHAR(50), -- 可能为空
qq VARCHAR(20), -- 可能为空
address VARCHAR(200), -- 可能为空
hobby1 VARCHAR(20), -- 可能为空
hobby2 VARCHAR(20), -- 可能为空
hobby3 VARCHAR(20) -- 可能为空
);列越来越多,很多都是空的,结构太死板。
用 JSON 方式:
sql
CREATE TABLE user (
id INT,
name VARCHAR(50),
info JSON -- 其他乱七八糟的都塞这里
);然后插入:
sql
INSERT INTO user VALUES (1, '张三', '{"wechat":"zhangsan","hobby":["篮球","游戏"]}');
INSERT INTO user VALUES (2, '李四', '{"qq":"123456","address":"北京市","age":25}');张三有微信和爱好,李四有QQ和地址------结构可以完全不一样,互不影响。
| 写法 | 结果 | 区别 |
|---|---|---|
info->'$.name' |
"张三" |
带双引号,仍是 JSON 格式 |
info->>'$.name' |
张三 |
去掉引号,变普通文本 |
完整类型速查总表
| 大类 | 类型 | 用途举例 |
|---|---|---|
| 整数 | TINYINT | 年龄、状态码 |
| SMALLINT | 小范围计数 | |
| MEDIUMINT | 中等计数 | |
| INT | 主键ID、普通计数 | |
| BIGINT | 大计数、自增ID | |
| 精确小数 | DECIMAL | 金额、财务数据 |
| 浮点 | FLOAT | 评分、百分比 |
| DOUBLE | 科学计算 | |
| 位 | BIT | 开关标志、权限掩码 |
| 定长文本 | CHAR | 手机号、身份证号 |
| 变长文本 | VARCHAR | 姓名、邮箱、地址 |
| 长文本 | TEXT/MEDIUMTEXT/LONGTEXT | 文章、评论、日志 |
| 二进制 | BLOB/MEDIUMBLOB/LONGBLOB | 图片、文件 |
| 定长二进制 | BINARY | 哈希值 |
| 变长二进制 | VARBINARY | 令牌 |
| 枚举 | ENUM | 性别、状态 |
| 集合 | SET | 多选标签 |
| 日期 | DATE | 生日 |
| 时间 | TIME | 时长 |
| 日期时间 | DATETIME/TIMESTAMP | 创建时间、更新时间 |
| 年 | YEAR | 年份 |
| JSON | JSON | 灵活数据结构 |
| 空间 | POINT/LINESTRING/POLYGON | 位置、路径、区域 |
| 布尔 | BOOLEAN | 是否启用 |
进入MySQL
sql
cd C:\Program Files\MySQL\MySQL Server 5.7\bin
SET CHARACTER_SET_DATABASE='gbk';
SET CHARACTER_SET_SERVER='gbk';
MySQL -uroot -p
13579qetuo数据库操作
数据库创建
sql
CREATE DATABASE [IF NOT EXISTS] 数据库名数据库删除
sql
DROP DATABASE [IF EXISTS] 数据库名;数据库查看和选择
sql
SHOW DATABASES; -- 查看所有数据库
USE 数据库名; -- 选择/切换数据库
SELECT DATABASE(); -- 查看当前使用的数据库表的操作
表的创建
sql
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT,-- 设置主键和自增
name VARCHAR(50) NOT NULL,-- 不允许为空
gender ENUM('男','女') DEFAULT '男',--不填默认男
age TINYINT UNSIGNED ,--无符号小整数
birthday DATE,-- DATE --- 日期类型,格式是 YYYY-MM-DD
phone CHAR(11),
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
-- TIMESTAMP --- 时间戳类型
-- DEFAULT CURRENT_TIMESTAMP --- 默认值是插入数据时的当前时间,自动记录创建时间
);列出当前数据库所有表名
sql
SHOW TABLES;查看表结构
sql
DESC student;查看建表的完整 SQL 语句
sql
SHOW CREATE TABLE 表名;查看这张表的所有数据
sql
SELECT * FROM student;删除表
sql
DROP TABLE IF EXISTS 表名;删除表中所有数据
sql
DELETE FROM 表名;插入数据
sql
INSERT INTO student (name, gender, age, birthday, phone)
VALUES ('张三', '男', 18, '2008-05-10', '13800138001');插入多行数据
sql
INSERT INTO student (name, gender, age, birthday, phone) VALUES
('李四', '女', 19, '2007-08-15', '13800138002'),
('王五', '男', 20, '2006-03-20', '13800138003');插入图片
sql
INSERT INTO xs
VALUES('221102', '程明', '计算机', 1, '2005-02-01', 15, NULL, LOAD_FILE('E:\mysql5\data\chenmin.jpg'));修改表中张三的年龄
sql
UPDATE student SET age = 21 WHERE name = '张三';
-- WHERE 会把所有人 age 都改成 21将xs1表和xs2表中所有学生的总学分都加4。
sql
UPDATE xs1,xs2
SET xs2.总学分= xs2.总学分+4, xs1.总学分= xs1.总学分+4
WHERE xs2.学号 = xs1.学号;
SELECT 学号,姓名,总学分 FROM xs1; #(a)
SELECT 学号,姓名,总学分 FROM xs2; 删除id为3 的那一行数据
sql
DELETE FROM student WHERE id = 3;查询所有男生的姓名和年龄
sql
SELECT name, age FROM student WHERE gender = '男' ORDER BY age DESC;-- (DESC 降序,ASC 升序)创建一个和 student 结构完全一样的新表,只复制结构,不复制数据
sql
CREATE TABLE student_backup LIKE student;结构和数据一起复制,但注意不会复制主键、索引、自增等约束。
sql
CREATE TABLE student_copy AS SELECT * FROM student;完全复制表
sql
-- 第一步:复制结构(含约束、索引、自增等)
CREATE TABLE student_full_copy LIKE student;
-- 第二步:复制数据
INSERT INTO student_full_copy SELECT * FROM student;复制部分数据
sql
-- 只复制 age > 18 的数据
CREATE TABLE student_adult AS
SELECT * FROM student
WHERE age > 18;
-- 只要部分列
CREATE TABLE student_brief AS
SELECT name, phone
FROM student;
-- 部分列 + 部分行
CREATE TABLE student_male AS
SELECT name, age, phone
FROM student
WHERE gender = '男';
-- 想保留主键和索引
-- 第一步:复制完整结构
CREATE TABLE student_part LIKE student;
-- 第二步:只插入符合条件的数据
INSERT INTO student_part SELECT * FROM student WHERE age > 18;添加列
sql
ALTER TABLE student ADD id_card CHAR(18) FIRST;-- 不加FIRST表示默认放在最后一列,加入放在第一行,换成after+列名表示放某列之后删除列
sql
ALTER TABLE student DROP COLUMN address;-- 从 student 表中删除 address 这一列修改列
sql
ALTER TABLE student MODIFY name VARCHAR(100) NOT NULL;
-- 把 name 的类型从 VARCHAR(50) 改成 VARCHAR(100)。
ALTER TABLE student CHANGE phone mobile CHAR(11);
-- phone 是旧列名,mobile 是新列名,后面跟类型。设置 gender 列的默认值为"保密",之后插入数据如果不填 gender,就自动填"保密"
sql
ALTER TABLE student ALTER COLUMN gender SET DEFAULT '保密';把id设为主键
sql
ALTER TABLE student ADD PRIMARY KEY (id);删除主键约束
sql
ALTER TABLE student MODIFY id INT;
ALTER TABLE student DROP PRIMARY KEY;
-- 删除主键约束。注意:如果有自增列,必须先去掉自增才能执行这句。添加唯一约束,给 phone 列加唯一约束,保证手机号不重复。
sql
ALTER TABLE student ADD CONSTRAINT uk_phone UNIQUE (phone);删除唯一约束,MySQL 中唯一约束底层也是索引,所以用 DROP INDEX。
sql
ALTER TABLE student DROP INDEX uk_phone;重命名表,把 student 表重命名为 stu。
sql
ALTER TABLE student RENAME TO stu;
RENAME TABLE stu TO student;-- 把 stu 改回 student。ALTER TABLE 做不到,而RENAME TABLE可以
sql
-- 同时改两个表名
RENAME TABLE
student TO stu,
class TO cla;
-- 把表从一个库移到另一个库
RENAME TABLE db1.student TO db2.student;外键约束
sql
ALTER TABLE student ADD COLUMN class_id INT;
-- 在 student 表里加一个新列,叫 class_id,用来存班级编号。
ALTER TABLE student ADD CONSTRAINT fk_class
FOREIGN KEY (class_id) REFERENCES class(class_id);
-- 给 class_id 列加一个"锁",以后往 class_id 填的值,必须是 class 表中已经存在的班级编号,不能乱填。
-- fk_class --- 给这把"锁"起个名字,叫 fk_class(方便以后找到它、删掉它)
-- FOREIGN KEY (class_id) --- 把 student 表的 class_id 列设为外键(就是引用别人的键)
-- REFERENCES class(class_id) --- 它引用的对象是 class 表的 class_id 列
ALTER TABLE student DROP FOREIGN KEY fk_class;
--删除约束本身(那个校验规则),不会删除 class_id 这个列创建kc表
sql
USE xscj;
CREATE TABLE kc
(
课程号 char(3) NOT NULL PRIMARY KEY,
课程名 varchar(8) NOT NULL,
开课学期 tinyint NOT NULL,
学时 tinyint NOT NULL,
学分 tinyint NOT NULL
); 创建cj表
sql
CREATE TABLE cj
(
学号 char(6) NOT NULL,
课程号 char(3) NOT NULL,
成绩 tinyint NULL,
PRIMARY KEY(学号, 课程号)
);存储引擎在第三章PPT 68页左右
表分区也在
关系运算
选择运算
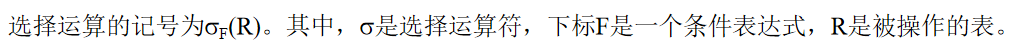
sql
-- 原表 student
SELECT * FROM student WHERE age > 18;
-- 等价于 σ_age>18_(student)投影运算

sql
SELECT DISTINCT name, age FROM student;
-- 等价于 π_name, age_(student)连接运算
等值连接

自然连接
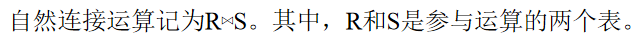
sql
-- 学生和班级按 class_id 连接
SELECT DISTINCT * FROM student s
JOIN class c ON s.class_id = c.class_id;自然连接
自动找出同名列,按这些列的值相等来连接,结果中同名列只保留一列
sql
-- 前提:student 和 class 都有 class_id 列
SELECT * FROM student NATURAL JOIN class;
-- 自动按 class_id 连接,且 class_id 只在结果中出现一次外连接(Outer Join)
保留左/右/双侧所有行,无匹配的填 NULL。
左外连接 ⟕:保留左表所有行
右外连接 ⟖:保留右表所有行
全外连接 ⟗:保留两边所有行
sql
-- 左外:所有学生,没有班级的显示NULL
SELECT * FROM student s LEFT JOIN class c ON s.class_id = c.class_id;
-- 全外(MySQL 不支持 FULL JOIN,用 UNION 模拟)
(SELECT * FROM student s LEFT JOIN class c ON ...)
UNION
(SELECT * FROM student s RIGHT JOIN class c ON ...);选择输出
按专业查询学生表中各个学生的学号、姓名和总学分。
sql
SELECT * FROM xs WHERE 专业= '计算机';
SELECT 学号 AS ID, 姓名 AS NAME, 总学分 AS 'Total credit'
FROM xs
WHERE 专业= '通信工程';把成绩表百分制成绩分成等级
sql
SELECT 学号,成绩,
CASE
WHEN 成绩>=90 THEN '优秀'
WHEN 成绩>=80 AND 成绩<90 THEN '良好'
WHEN 成绩>=70 AND 成绩<80 THEN '中等'
WHEN 成绩>=60 AND 成绩<70 THEN '及格'
ELSE '不及格'
END AS 等级
FROM cj
WHERE 课程号 = '206';查询2022年入学学生的年龄。
sql
SELECT 学号, 姓名, 出生日期, year(now())-year(出生日期)+1 AS年龄
FROM xs
WHERE left(学号,2)='22';消除重复行
sql
SELECT DISTINCT 课程号
FROM cj;聚合函数
以下是 MySQL 中全部聚合函数的完整列表(基于 MySQL 8.0):
| 函数名 | 说明 |
|---|---|
COUNT() |
返回查询结果的行数。用法:COUNT(*) 统计所有行,COUNT(列) 忽略 NULL,COUNT(DISTINCT 列) 去重统计 |
MAX() |
返回指定列的最大值 |
MIN() |
返回指定列的最小值 |
SUM() |
返回指定列所有值的总和(忽略 NULL) |
AVG() |
返回指定列所有值的平均值(忽略 NULL) |
STD() |
STDDEV_POP() 的同义词,返回总体标准差 |
STDDEV() |
STDDEV_POP() 的同义词,返回总体标准差 |
STDDEV_POP() |
返回总体标准差 |
STDDEV_SAMP() |
返回样本标准差 |
VARIANCE() |
VAR_POP() 的同义词,返回总体方差 |
VAR_POP() |
返回总体方差 |
VAR_SAMP() |
返回样本方差 |
GROUP_CONCAT() |
将分组中的列值连接成一个字符串,可自定义分隔符、排序、去重 |
BIT_AND() |
返回所有位的按位与结果 |
BIT_OR() |
返回所有位的按位或结果 |
BIT_XOR() |
返回所有位的按位异或结果 |
JSON_ARRAYAGG() |
将分组中的值聚合为一个 JSON 数组 |
JSON_OBJECTAGG() |
将分组中的键值对聚合为一个 JSON 对象 |
STD、STDDEV、VARIANCE是旧版本函数,推荐使用STDDEV_POP、VAR_POP等更明确的函数。BIT_AND、BIT_OR、BIT_XOR用于位运算聚合。GROUP_CONCAT常用于将多行某列的值拼接,如GROUP_CONCAT(name SEPARATOR ', ')。JSON_ARRAYAGG和JSON_OBJECTAGG是 MySQL 5.7.22 后引入的,用于直接生成 JSON 结构。
求选修101号课程的学生的人数、最高分、最低分和平均成绩。
sql
SELECT COUNT(成绩),MAX(成绩), MIN(成绩), AVG(成绩)
FROM cj
WHERE 课程号 = '101';求选修了206号课程的学生的学号。
sql
SELECT GROUP_CONCAT(学号)
FROM cj
WHERE 课程号= '206';查询(xsk)学生表共同的爱好和所有的爱好。
sql
SELECT * FROM xsk; #(a)
SELECT BIT_OR(爱好), BIT_AND(爱好) FROM xsk; #(b)限制输出行
sql
SELECT 学号, 姓名, 专业, 性别, 出生日期, 总学分
FROM xs
ORDER BY 学号
LIMIT 5;
-- 第一行到第五行 #(a)
SELECT 学号, 姓名, 专业, 性别, 出生日期, 总学分
FROM xs
ORDER BY 学号
LIMIT 5, 5;
-- 第五行到第十行全连接
查找所有学生选过的课程信息。
sql
SELECT DISTINCT kc.课程名, cj.课程号,学时,学分
FROM kc, cj
WHERE kc.课程号=cj.课程号;join连接
内连接
查找所有学生选过的课程名和课程号。
sql
SELECT DISTINCT 课程名, cj.课程号
FROM KC INNER JOIN cj
ON (kc.课程号=cj.课程号); 查找选修了206号课程且成绩80分以上的学生的姓名及成绩。
sql
SELECT姓名,成绩
FROM xs JOIN cj ON xs.学号 = cj.学号
WHERE 课程号='206' AND 成绩>=80;查找选修了计算机基础课程且成绩不少于80分的学生的学号、姓名、课程名及成绩。
sql
SELECT xs.学号, 姓名, 课程名, 成绩
FROM cj JOIN xs ON cj.学号 = xs.学号
JOIN kc ON cj.课程号 = kc.课程号
WHERE 课程名='计算机导论' AND 成绩>=80 ;自连接
查找相同成绩的学生的学号、课程号和成绩
sql
SELECT a.学号,a.课程号,b.课程号,a.成绩
FROM cj as a JOIN cj as b
ON a.成绩=b.成绩 AND a.课程号!=b.课程号
WHERE a.成绩>=85;查询课程表中所有学生选过的课程号和课程名。
sql
SELECT DISTINCT 课程号,课程名
FROM kc INNER JOIN cj
USING (课程号);查询前5个成绩记录学生的学号、课程名和成绩。
sql
SELECT 学号,课程名,成绩
FROM kc INNER JOIN cj
USING (课程号)
LIMIT 5;
USING (课程号);外连接
左外连接(LEFT JOIN)保留左表的所有行,右表匹配不上则填 NULL。
sql
SELECT s.id, s.name, s.class_id, c.class_name
FROM student s
LEFT JOIN class c ON s.class_id = c.class_id;右外连接(RIGHT JOIN)保留右表的所有行,左表匹配不上则填 NULL。
sql
SELECT s.id, s.name, c.class_id, c.class_name
FROM student s
RIGHT JOIN class c ON s.class_id = c.class_id;全外连接(FULL JOIN)保留左右两表的所有行,任何一边匹配不上都填 NULL。
sql
-- 模拟全外连接
SELECT s.id, s.name, s.class_id, c.class_name
FROM student s
LEFT JOIN class c ON s.class_id = c.class_id
UNION
SELECT s.id, s.name, c.class_id, c.class_name
FROM student s
RIGHT JOIN class c ON s.class_id = c.class_id;查找所有学生情况及他们选修的课程号,若学生未选修任何课程,也要包括其情况。
sql
SELECT xs.* , 课程号, 成绩
FROM xs LEFT OUTER JOINcjON xs.学号 = cj.学号;查找被选修了的课程的选修情况和所有开设的课程名。
sql
SELECT 课程名,cj.*
FROM cj RIGHT JOIN kc ON cj.课程号=kc.课程号
LIMIT 40,10;使用自然连接查询成绩表中的课程号和课程名。
sql
SELECT课程名, 课程号
FROM kc
WHERE课程号IN
(SELECT DISTINCT 课程号 FROM kc NATURAL RIGHT OUTER JOIN cj);交叉连接
假设左表有 M 行,右表有 N 行,交叉连接的结果就是 M × N 行,没有任何过滤或匹配条件。每一行都和其他所有行配对。
查询学生表所有可能的选课情况。
sql
SELECT xs.学号, 姓名, 课程号
FROM xs CROSS JOIN cj
LIMIT 40,10;查询条件
| 运算符 | 示例 | 说明 |
|---|---|---|
= |
age = 18 |
等于 |
<=> |
phone <=> NULL |
NULL 安全等于 |
<> / != |
status <> 1 |
不等于 |
<, <=, >, >= |
score >= 90 |
大小比较 |
BETWEEN |
score BETWEEN 60 AND 80 |
闭区间范围 |
IN |
class_id IN (1,2) |
属于列表 |
NOT IN |
id NOT IN (1,2) |
不属于列表 |
LIKE |
name LIKE '张%' |
通配符匹配 |
NOT LIKE |
name NOT LIKE '张%' |
否定通配 |
REGEXP |
name REGEXP '^A' |
正则匹配 |
IS NULL |
phone IS NULL |
是空值 |
IS NOT NULL |
phone IS NOT NULL |
非空 |
模式匹配
REGEXP运算符
| 符号 | 说明 | 示例 | 匹配结果 |
|---|---|---|---|
^ |
字符串开头 | '^A' |
以 A 开头的字符串 |
$ |
字符串结尾 | 'ing$' |
以 ing 结尾 |
. |
匹配任意单个字符(除换行符) | 'a.b' |
a + 任意字符 + b |
* |
前一个字符重复 0 次或多次 | 'go*' |
g, go, goo, gooo... |
+ |
前一个字符重复 1 次或多次 | 'go+' |
go, goo, gooo... (不含 g) |
? |
前一个字符重复 0 次或 1 次 | 'colou?r' |
color 或 colour |
{n} |
恰好 n 次 | 'a{3}' |
aaa |
{n,} |
至少 n 次 | 'a{2,}' |
aa, aaa, aaaa... |
{n,m} |
n 到 m 次 | 'a{2,4}' |
aa, aaa, aaaa |
[abc] |
匹配括号内任意一个字符 | '[aeiou]' |
元音字母 |
[^abc] |
匹配不在括号内的任意字符 | '[^0-9]' |
非数字 |
[a-z] |
范围,a 到 z | '[A-Z]' |
大写字母 |
| `(abc | def)` | 分组,匹配 abc 或 def | `'^(Tom |
\ |
转义特殊字符 | '\\.' |
匹配字面点号 . |
\\b |
单词边界 | '\\bcat\\b' |
匹配单独的单词 cat |
\\d |
数字(等价 [0-9]) |
'^\\d+$' |
纯数字 |
\\w |
单词字符(字母数字下划线) | '\\w+' |
至少一个单词字符 |
\\s |
空白字符 | 'a\\sb' |
a空格b 或 a制表符b |
查询学生表中姓"王"的学生的学号、姓名及性别。
sql
SELECT 学号,姓名,性别
FROM xs
WHERE姓名LIKE '王%';查询学生表中大三(学号第二个数字为0)的学生的学号、姓名及专业。
sql
SELECT 学号,姓名,专业
FROM xs
WHERE学号LIKE '_0%';查询学生表姓"李"的学生的学号、姓名和专业。
sql
SELECT 学号,姓名,专业
FROM xs
WHERE姓名REGEXP '^李';
sql
SELECT学号,姓名,专业
FROM xs
WHERE学号REGEXP '[4,5,6]';查询学生表学号以22开头、以01结尾的学生的学号、姓名和专业。
sql
SELECT学号,姓名,专业
FROM xs
WHERE学号REGEXP '^22.*01$';范围比较的关键字有两个:BETWEEN和IN。
查询学生表中2004年出生的学生的情况。
sql
SELECT 学号, 姓名, 专业, 出生日期
FROM xs
WHERE出生日期BETWEEN '2004-1-1' AND '2004-12-31';查询学生表中计算机、通信工程或电气工程专业的学生的情况。
sql
SELECT *
FROM xs
WHERE专业IN ('计算机', '通信工程', '电气工程');空值判断
查询学生表备注为空的学生的情况。
sql
SELECT *
FROM xs
WHERE备注 IS NULL;子查询
查找xscj数据库中选修了206号课程的学生的姓名、学号。
sql
SELECT姓名,学号
FROM xs
WHERE 学号IN
( SELECT 学号
FROM cj
WHERE 课程号 = '206'
);查找未选修离散数学课程的学生的姓名、学号、专业。
sql
SELECT 姓名,学号,专业
FROM xs
WHERE 学号 NOT IN
(SELECT 学号
FROM cj
WHERE 课程号 IN
( SELECT 课程号
FROM kc
WHERE课程名 = '离散数学'
)
);查找选修了离散数学课程的学生的学号。
sql
SELECT count(学号)
FROM cj
WHERE 课程号 =
(SELECT 课程号
FROM kc
WHERE课程名 ='离散数学'
);查找学生表中比所有计算机专业的学生出生日期都大的学生的学号、姓名、专业、出生日期。
sql
SELECT 学号, 姓名, 专业, 出生日期
FROM xs
WHERE 出生日期> ALL
(SELECT 出生日期
FROM xs
WHERE 专业='计算机'
);查找课程号为206的成绩不低于课程号为102的最低成绩的学生的学号。
sql
SELECT学号
FROMcj
WHERE 课程号 = '206' AND 成绩>=ANY
(SELECT 成绩
FROMcj
WHERE课程号 ='102'
);查找选修206号课程的学生的姓名。
sql
SELECT姓名
FROM xs
WHERE EXISTS
(SELECT *
FROM cj
WHERE学号 = xs.学号AND课程号 = '206'
);查找选修了全部课程的学生的姓名。
sql
SELECT 姓名
FROM xs
WHERE NOT EXISTS
(SELECT *
FROM kc
WHERE NOT EXISTS
( SELECT *
FROMcj
WHERE学号=xs.学号AND课程号=kc.课程号
)
);从xs表中查找总学分大于50分的男学生的姓名、学号和总学分。
sql
SELECT 姓名,学号,性别,总学分
FROM xs
WHERE 总学分>50
) AS student
WHERE 性别;从学生表中查找所有女学生的姓名、学号,以及与221101号学生的年龄差距。
sql
SELECT 学号,姓名, YEAR(出生日期)-YEAR(
( SELECT 出生日期
FROM xs
WHERE学号='221101'
) ) AS年龄差距
FROM xs
WHERE 性别=FALSE;查找与学号为221101的学生性别相同、总学分相同的学生的学号和姓名。
sql
SELECT学号,姓名
FROM xs
WHERE (性别,总学分)=( SELECT性别,总学分
FROM xs
WHERE学号='221101'
);查询分组
求xscj数据库中各专业的学生数。
sql
SELECT 专业,COUNT(*) AS '学生数'
FROM xs
GROUP BY专业;求被选修的各门课程的平均成绩和选修该课程的人数。
sql
SELECT 课程号, AVG(成绩) AS '平均成绩' ,COUNT(学号) AS' 选修人数'
FROM cj
GROUP BY 课程号;查询每个专业的男生人数、女生人数、总人数,以及学生总人数。
sql
SELECT专业, 性别, count(*) AS '人数'
FROM xs
GROUP BY专业,性别
WITH ROLLUP;查询每门课程各专业的平均成绩、每门课程的总平均成绩和所有课程的总平均成绩。
sql
SELECT 课程名, 专业, AVG(成绩) AS '平均成绩'
FROMcj, kc,xs
WHEREcj.课程号 = kc.课程号ANDcj.学号 = xs.学号
GROUP BY 课程名, 专业
WITH ROLLUP;分组后过滤
查询平均成绩在85分以上的学生的学号和平均成绩。
sql
SELECT 学号, AVG(成绩) AS 平均成绩
FROMcj
GROUP BY 学号
HAVING 平均成绩>=85;查找选修课程超过2门且成绩都在70分以上的学生的学号。
sql
SELECT 学号
FROM cj
WHERE 成绩>= 70
GROUP BY 学号
HAVING COUNT(*) > 2;查找通信工程专业平均成绩在85分以上的学生的学号和平均成绩。
sql
SELECT 学号,AVG(成绩) AS '平均成绩'
FROMcj
WHERE学号 IN
( SELECT 学号
FROM xs
WHERE 专业= '通信工程'
)
GROUP BY学号
HAVING AVG(成绩) >=85;输出排序
将计算机专业学生的计算机导论课程成绩按降序排列。
sql
SELECT xs.学号,姓名,成绩
FROM xs,kc,cj
WHERE xs.学号= cj.学号
ANDcj.课程号= kc.课程号
AND课程名= '计算机导论'
AND 专业= '计算机'
ORDER BY 成绩 DESC;将出生日期2003年后的学生按专业名拼音排序,相同专业按照出生日期从小到大排序
sql
SELECT 学号,姓名,专业,出生日期
FROM xsb
WHERE 出生日期 >= '2004-1-1'
ORDER BY 专业 DESC, 出生日期将通信工程专业学生的情况按平均成绩升序排列。
sql
SELECT学号, 姓名, 总学分
FROM xs
WHERE 专业= '通信工程'
ORDER BY ( SELECT AVG(成绩)
FROM cj
GROUP by cj.学号
HAVING xs.学号=cj.学号
);联合查询
联合计算机专业和通信工程专业2022学生信息。
sql
SELECT *
FROM xs_jsj
WHERE 学号 LIKE '22%'
UNION
SELECT *
FROM xs_txgc
WHERE 学号 LIKE '22%';视图
创建视图
创建只包含学生部分信息的视图
sql
CREATE VIEW v_student AS
SELECT 学号, 姓名, 性别
FROM xs;创建一个包含成绩和课程名的视图,并重命名列
sql
CREATE VIEW v_score(学号, 姓名, 课程, 成绩) AS
SELECT xs.学号, xs.姓名, kc.课程名, cj.成绩
FROM xs
JOIN cj ON xs.学号 = cj.学号
JOIN kc ON cj.课程号 = kc.课程号;创建xscj数据库上的cs_kc视图,包括计算机专业各学生的学号、选修的课程号及成绩。要保证对该视图的修改都符合专业为计算机这个条件。
sql
CREATE OR REPLACE VIEW xscj.cj_kc
AS
SELECT xs.学号,课程号,姓名,成绩
FROM xscj.xs, xscj.cj
WHERE xs.学号 = cj.学号 and xs.专业 = '计算机'
WITH CHECK OPTION;创建计算机专业学生平均成绩视图cj_kc_avg视图,包括学号(在视图中的列名为vnum)和平均成绩(在视图中的列名为vavg)。
sql
USE xscj;
CREATE VIEW cj_kc_avg(vnum, vavg)
AS
SELECT 学号,AVG(成绩)
FROM cj_kc
GROUP BY 学号;查看视图
sql
-- 查看所有视图(MySQL中视图和表在同一列表里,可通过 TABLE_TYPE 区分)
SHOW FULL TABLES WHERE TABLE_TYPE = 'VIEW';
-- 查看视图创建语句
SHOW CREATE VIEW 视图名;删除视图
sql
DROP VIEW [IF EXISTS] 视图名;使用视图
视图查询和表完全一样:
sql
SELECT * FROM v_score WHERE 成绩 > 80;在视图cs_kc中查找计算机专业学生的学号和选修的课程号。
sql
SELECT 学号,姓名,课程号,成绩
FROM cj_kc
LIMIT 5;查找计算机专业平均成绩在75分以上的学生的学号和平均成绩。
sql
SELECT *
FROM cj_kc_avg
WHEREvavg>=75;创建视图,包含计算机专业的学生信息,并向视图中插入一条记录:
('221255','李牧','计算机',1,'2004-10-14',13,NULL,NULL)。
sql
CREATE OR REPLACE VIEW xs_vjsj
AS
SELECT *
FROM xs
WHERE专业 = '计算机'
WITH CHECK OPTION;
INSERT INTO xs_vjsj
VALUES('221155', '李牧', '计算机', 1, '2004-10-14', 50, NULL, NULL);视图本身不存数据,但可以作为代理将数据插入到基表。
只有结构简单、映射清晰的视图才能进行增删改。
插入时,MySQL 会自动把操作翻译成对基表的操作,就像你间接操作基表。
复杂视图(含聚合、分组、多表连接)则无法进行数据修改。
显示插入视图记录效果:
sql
ELECT *
FROM xs_vjsj
WHERE 学号='221155';显示插入视图记录对源表的效果:
sql
SELECT *
FROM xs
WHERE 学号='221155';在xs_vjsj视图中修改'李牧'的学号为"221150"
UPDATE xs_vjsj
SET 学号 = '221150'
WHERE 学号 = '221155';