目录
[5.3.1 多智能体协作原理](#5.3.1 多智能体协作原理)
[1. 核心设计理念](#1. 核心设计理念)
[2. 关键协作机制](#2. 关键协作机制)
[3. 状态传递与增量更新](#3. 状态传递与增量更新)
[4. 并发与聚合](#4. 并发与聚合)
[5. 技术实现要点](#5. 技术实现要点)
[6. 应用场景](#6. 应用场景)
[5.3.2 多智能体协作核心组件与模式分类](#5.3.2 多智能体协作核心组件与模式分类)
[1. 多智能体协作核心组件](#1. 多智能体协作核心组件)
[2. 多智能体协作模式分类](#2. 多智能体协作模式分类)
[5.3.3 实战案例:固定流水线模式的实现](#5.3.3 实战案例:固定流水线模式的实现)
[1. 场景定义](#1. 场景定义)
[2. 环境配置与工具定义](#2. 环境配置与工具定义)
[5. 构建LangGraph协作流程(流水线模式)](#5. 构建LangGraph协作流程(流水线模式))
[7. 适用场景与扩展方向](#7. 适用场景与扩展方向)
【示例5.3】多智能体数据分析协作系统实现代码(Langgraph_deepseek_multi_agent)。
LangGraph开发AI Agent实践(人工智能技术丛书)【行情 报价 价格 评测】-京东
LangGraph是LangChain生态下的图结构工作流框架,专为状态管理和多智能体协作而设计。它基于有向图模型抽象智能体交互逻辑,核心优势在于:
- 显式状态管理:支持复杂上下文流转与持久化。
- 循环与分支能力:天然适配多智能体分工、决策、迭代优化场景。
- 容错与可追溯:每一步执行轨迹可回溯,支持断点续跑。
- 生态兼容:无缝对接LangChain智能体(Agent)、工具(Tool)、模型(LLM)。
5.3.1 多智能体协作原理
LangGraph的多智能体协作原理基于有向图结构编排智能体间的交互流程,结合状态管理和控制流机制实现复杂协作逻辑。以下是其核心原理的解析。
1. 核心设计理念
1)图即工作流
- 将协作流程建模为有向图,节点代表智能体(或工具),边定义交互路径。
- 支持循环、分支、并行等拓扑结构,适应动态决策场景。
2)共享状态驱动
- 全局状态对象(State)贯穿整个图的执行过程,智能体通过读写状态实现信息同步。
- 状态更新触发节点间的条件转移,实现协作逻辑的流转。
2. 关键协作机制
1)智能体封装与专业化
每个智能体封装为独立节点,具备:
- 专用系统提示词(角色定义、能力描述)。
- 工具调用权限(API、函数、计算资源)。
- 上下文感知(读取历史消息与中间结果)。
例如:Coder、Reviewer、Executor分工处理代码任务。
2)可控交互流程
示例:条件路由实现决策分支
def should_continue(state: State):
if state"code_quality" >= 0.8:
return "end" # 质量达标则终止
else:
return "review" # 否则跳转至评审节点
3. 状态传递与增量更新
采用消息累加器模式:
- 智能体不直接修改历史记录,而是追加新消息到共享状态。
- 支持结构化状态(如{messages: ..., draft: "...", feedback: "..."})。
4. 并发与聚合
- 并行节点:多个智能体同时处理子任务(如并行调研不同数据源)。
- 聚合节点:合并并行结果,生成统一输出(如投票决策、结果合成)。
5. 技术实现要点
- 状态管理:使用Checkpointer持久化状态,支持暂停/恢复、回溯调试;使用消息剪枝策略控制上下文长度。
- 流式响应:支持实时返回中间结果(如逐节点输出),提升用户体验。
- 人类介入:预设中断点允许人工审核或修改状态,实现人机协同。
- 容错与回溯:节点失败时可触发重试或转向备用分支,支持子图嵌套复用。
6. 应用场景
- 复杂任务分解(如产品设计、技术方案制定)。
- 多角色模拟(面试训练、辩论赛)。
- 自动化流水线(CI/CD+AI评审)。
- 决策支持系统(多专家投票分析)。
5.3.2 多智能体协作核心组件与模式分类
1. 多智能体协作核心组件
LangGraph构建多智能体系统的核心元素包括:
- Graph:协作流程容器,定义节点与边的关系。
- Node:智能体实例或功能单元(如信息收集、分析、决策、执行工具)。
- Edge :节点间的流转规则(条件分支、循环、强制跳转)。
- State :全局共享状态(存储任务目标、中间结果、智能体交互记录等)。
- ConditionalEdge:条件边,根据状态内容动态决定下一个执行节点(核心协作调度逻辑)。
2. 多智能体协作模式分类
LangGraph支持主流多智能体协作范式,适配不同业务场景。
1)流水线模式(Pipeline)
- 特点:智能体按固定顺序分工执行,前一个智能体的输出作为后一个的输入。
- 适用场景:结构化任务(如数据处理、报告生成、内容创作)。
- 示例:数据采集智能体→数据清洗智能体→分析智能体→报告生成智能体。
2)决策调度模式(Router)
- 特点:存在调度智能体,根据任务状态动态分配给对应执行智能体。
- 适用场景:多任务类型混合、需要动态分工的场景。
- 示例:调度智能体→(根据任务类型)→写作智能体/数据分析智能体/工具执行智能体。
3)循环迭代模式(Loop)
- 特点:智能体协作形成闭环,持续优化结果直到满足终止条件。
- 适用场景:复杂问题求解、多轮修正(如代码调试、方案优化)。
- 示例:问题分析智能体→执行智能体→评估智能体→(若不满足条件,则返回问题分析)。
4)混合模式
- 特点:结合以上多种模式,适配超复杂场景(如企业级AI助手、自动化办公系统)。
5.3.3 实战案例:固定流水线模式的实现
1. 场景定义
构建一个自动化数据分析系统,包含4个智能体,协作完成"用户需求→数据获取→分析→可视化→报告生成"全流程。
- 需求解析智能体:将用户自然语言需求转换为结构化分析目标(如指标定义、时间范围)。
- 数据采集智能体:根据结构化目标调用工具获取数据(模拟调用数据库/API)。
- 数据分析智能体:对采集到的数据进行计算、统计分析。
- 报告生成智能体:整合分析结果,生成自然语言报告+可视化描述。
2. 环境配置与工具定义
import os
import pandas as pd
import matplotlib.pyplot as plt
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI #支持 OpenAI 兼容 DEEPSEEK_API
from langgraph.graph import Graph, StateGraph, END
from typing import TypedDict
加载环境变量(需配置 DASHSCOPE_API_KEY)
load_dotenv()
使用 DeepSeek 的 OpenAI 兼容 API
llm = ChatOpenAI(
model="deepseek-chat", # 或 "deepseek-coder" 等
temperature=0,
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # DeepSeek 的 OpenAI 兼容端点
)
模拟数据采集工具(保持不变)
def fetch_data(metric: str, time_range: str) -> pd.DataFrame:
"""模拟根据指标和时间范围获取数据"""
print(f"数据采集工具 正在获取 {time_range} 的 {metric} 数据...")
注意:pd.np 已弃用,改用 NumPy
import numpy as np
dates = pd.date_range(start=time_range.split("-")0, end=time_range.split("-")1, freq="D")
data = pd.DataFrame({
"date": dates,
metric: np.random.randint(100, 500) for _ in dates
})
return data
模拟数据可视化工具(保持不变)
def plot_data(data: pd.DataFrame, metric: str) -> str:
"""生成数据可视化图表(返回图片路径)"""
plt.figure(figsize=(10, 4))
plt.plot(data"date", datametric, marker="o", color="#1f77b4")
plt.title(f"{metric} 趋势图", fontsize=12)
plt.xlabel("日期")
plt.ylabel(metric)
plt.xticks(rotation=45)
plt.tight_layout()
img_path = f"{metric}_trend.png"
plt.savefig(img_path)
plt.close()
return img_path
使用OpenAI LLM(ChatOpenAI)调用deepseek-chat模型的API,需要注意以下几点:
- DeepSeek官方目前未直接集成到LangChain(截至2025年初),但可通过OpenAI兼容API方式调用(DeepSeek提供了兼容OpenAI API的接口)。因此,我们仍可使用ChatOpenAI类,但需要修改base_url指向DeepSeek的API端点,并使用DeepSeek的API Key(建议统一使用阿里云百炼大模型服务)。
- 请根据你的需求选择DeepSeek模型类型,如deepseek-chat或deepseek-coder。
- 请确保你的.env文件包含DEEPSEEK_API_KEY=your_deepseek_api_key_here。
- 定义全局状态(State)
状态是多智能体共享的信息中枢,需包含任务全生命周期的关键数据:
class AnalysisState(TypedDict):
"""数据分析系统的全局状态"""
user_query: str # 用户原始查询
structured_goal: dict = None # 结构化分析目标(需求解析结果)
raw_data: pd.DataFrame = None # 原始数据(数据采集结果)
analysis_result: dict = None # 分析结果(数据分析智能体输出)
visualization_path: str = None # 可视化图片路径
final_report: str = None # 最终报告(报告生成智能体输出)
- 实现各智能体节点
每个智能体封装为独立函数,输入状态、处理后更新状态并返回:
1. 需求解析智能体:自然语言 → 结构化目标
def demand_parser_agent(state: AnalysisState) -> AnalysisState:
"""将用户自然语言需求解析为结构化目标"""
print("\n需求解析智能体 正在解析用户需求...")
print(f"📝 用户查询: {state'user_query'}")
在线模式:使用阿里云百炼模型
try:
prompt = f"""你是一个专业的需求分析助手。请从用户的查询中提取以下信息,并返回JSON格式:
用户查询: "{state'user_query'}"
请提取:
-
- metric: 分析指标名称
-
- time_range: 时间范围,格式为"YYYY-MM-DD-YYYY-MM-DD"
-
- analysis_type: 分析类型
可能的指标: 销售额, 日活用户数, 订单量, 访问量, 转化率
可能的时间格式: 从用户查询中提取日期
可能的分析类型: 趋势分析, 均值计算, 峰值统计, 波动分析
返回格式示例:
{{
"metric": "销售额",
"time_range": "2025-01-01-2025-01-10",
"analysis_type": "趋势分析"
}}
只返回JSON,不要其他文本。"""
response = llm.invoke(prompt)
content = response.content.strip()
清理响应内容
if content.startswith("```json"):
content = content7:-3
elif content.startswith("```"):
content = content3:-3
structured_goal = json.loads(content)
except Exception as e:
print(f"需求解析错误 使用离线模式: {e}")
structured_goal = {
"metric": "销售额",
"time_range": "2025-01-01-2025-01-10",
"analysis_type": "趋势分析"
}
state"structured_goal" = structured_goal
print(f"✅ 需求解析结果: {structured_goal}")
return state
2. 数据采集智能体:结构化目标 → 原始数据
def data_collector_agent(state: AnalysisState) -> AnalysisState:
"""根据结构化目标调用工具采集数据"""
print("\n数据采集智能体 正在采集数据...")
goal = state"structured_goal"
确保有必要的字段
if not goal or "metric" not in goal or "time_range" not in goal:
print("警告 结构化目标不完整,使用默认值")
goal = {
"metric": goal.get("metric", "销售额"),
"time_range": goal.get("time_range", "2025-01-01-2025-01-10"),
"analysis_type": goal.get("analysis_type", "趋势分析")
}
state"structured_goal" = goal
调用数据采集工具
try:
raw_data = fetch_data(metric=goal"metric", time_range=goal"time_range")
调用可视化工具生成图表
viz_path = plot_data(data=raw_data, metric=goal"metric")
更新状态
state"raw_data" = raw_data
state"visualization_path" = viz_path
print(f"✅ 数据采集完成")
print(f" 数据量: {len(raw_data)} 条记录")
print(
f" 时间范围: {raw_data'date'.iloc0.strftime('%Y-%m-%d')} 到 {raw_data'date'.iloc-1.strftime('%Y-%m-%d')}")
print(f" 指标范围: {raw_datagoal\['metric'].min()} 到 {raw_datagoal\['metric'].max()}")
except Exception as e:
print(f"数据采集错误 {e}")
import traceback
traceback.print_exc()
return state
3. 数据分析智能体:原始数据 → 分析结果
def data_analyst_agent(state: AnalysisState) -> AnalysisState:
"""对原始数据执行指定类型的分析"""
print("\n数据分析智能体 正在执行数据分析...")
goal = state"structured_goal"
data = state"raw_data"
if data is None or len(data) == 0:
print("警告 无可用数据,跳过分析")
state"analysis_result" = {"error": "无可用数据"}
return state
metric = goal"metric"
analysis_type = goal"analysis_type"
执行对应类型的分析
analysis_result = {}
if analysis_type == "趋势分析":
if len(data) > 0:
start_val = float(datametric.iloc0)
end_val = float(datametric.iloc-1)
change = end_val - start_val
change_rate = (change / start_val * 100) if start_val != 0 else 0
analysis_result = {
"分析类型": "趋势分析",
"趋势方向": "上升" if change > 0 else "下降" if change < 0 else "平稳",
"起始值": round(start_val, 2),
"结束值": round(end_val, 2),
"变化量": round(change, 2),
"变化率": f"{change_rate:.2f}%",
"最大值": round(float(datametric.max()), 2),
"最小值": round(float(datametric.min()), 2),
"平均值": round(float(datametric.mean()), 2),
"最大值日期": data.locdata\[metric.idxmax(), "date"].strftime("%Y-%m-%d"),
"最小值日期": data.locdata\[metric.idxmin(), "date"].strftime("%Y-%m-%d"),
"数据点数": len(data)
}
elif analysis_type == "均值计算":
analysis_result = {
"分析类型": "均值计算",
"平均值": round(float(datametric.mean()), 2),
"中位数": round(float(datametric.median()), 2),
"众数": float(datametric.mode()0) if not datametric.mode().empty else 0,
"标准差": round(float(datametric.std()), 2),
"方差": round(float(datametric.var()), 2),
"最小值": round(float(datametric.min()), 2),
"最大值": round(float(datametric.max()), 2),
"极差": round(float(datametric.max() - datametric.min()), 2),
"数据点数": len(data)
}
elif analysis_type == "峰值统计":
max_idx = datametric.idxmax()
min_idx = datametric.idxmin()
analysis_result = {
"分析类型": "峰值统计",
"峰值": round(float(datametric.max()), 2),
"峰值日期": data.locmax_idx, "date".strftime("%Y-%m-%d"),
"谷值": round(float(datametric.min()), 2),
"谷值日期": data.locmin_idx, "date".strftime("%Y-%m-%d"),
"峰值与均值差": round(float(datametric.max() - datametric.mean()), 2),
"谷值与均值差": round(float(datametric.mean() - datametric.min()), 2),
"波动率": f"{(datametric.std() / datametric.mean() * 100):.2f}%" if datametric.mean() != 0 else "0%",
"数据点数": len(data)
}
else:
默认综合统计
analysis_result = {
"分析类型": "综合统计分析",
"统计摘要": {
"平均值": round(float(datametric.mean()), 2),
"中位数": round(float(datametric.median()), 2),
"标准差": round(float(datametric.std()), 2),
"最小值": round(float(datametric.min()), 2),
"25%分位数": round(float(datametric.quantile(0.25)), 2),
"50%分位数": round(float(datametric.quantile(0.5)), 2),
"75%分位数": round(float(datametric.quantile(0.75)), 2),
"最大值": round(float(datametric.max()), 2)
},
"趋势指标": {
"起始值": round(float(datametric.iloc0), 2),
"结束值": round(float(datametric.iloc-1), 2),
"总变化": round(float(datametric.iloc-1 - datametric.iloc0), 2),
"总变化率": f"{((datametric.iloc-1 - datametric.iloc0) / datametric.iloc0 * 100):.2f}%" if
datametric.iloc0 != 0 else "0%"
}
}
state"analysis_result" = analysis_result
print(f"✅ 数据分析完成")
for key, value in analysis_result.items():
if isinstance(value, dict):
print(f" {key}:")
for k, v in value.items():
print(f" {k}: {v}")
else:
print(f" {key}: {value}")
return state
4. 报告生成智能体:分析结果 → 最终报告
def report_generator_agent(state: AnalysisState) -> AnalysisState:
"""整合所有结果生成自然语言报告"""
print("报告生成智能体 正在生成最终报告...")
prompt = f"""
你是专业的数据分析报告撰写师,请根据以下信息生成一份清晰、简洁的分析报告:
(1)用户需求:{state'user_query'}
(2)分析目标:{state'structured_goal'}
(3)分析结果:{state'analysis_result'}
(4)可视化说明:已生成 {state'structured_goal''metric'} 趋势图(路径:{statestate'visualization_path'})
报告要求:
-
结构清晰:包含"需求概述"、"数据来源"、"核心分析结论"、"可视化说明"4部分
-
语言通俗:避免技术术语,适合非专业人士阅读
-
数据准确:引用分析结果中的具体数值
"""
response = llm.invoke(prompt)
state'final_report' = response.content
return state
5. 构建LangGraph协作流程(流水线模式)
使用StateGraph定义节点流转关系,形成多智能体协作流水线:
def build_analysis_graph() -> Graph:
"""构建数据分析多智能体协作图"""
1. 初始化状态图(绑定全局状态类)
graph_builder = StateGraph(AnalysisState)
2. 添加智能体节点(每个节点对应一个智能体函数)
graph_builder.add_node("demand_parser",demand_parser_agent) # 需求解析节点
graph_builder.add_node("data_collector",data_collector_agent) # 数据采集节点
graph_builder.add_node("data_analyst", data_analyst_agent) # 数据分析节点
graph_builder.add_node("report_generator", report_generator_agent) # 报告生成节点
3. 定义节点流转规则(流水线模式:固定顺序执行)
graph_builder.set_entry_point("demand_parser") # 入口节点:需求解析
graph_builder.add_edge("demand_parser", "data_collector") # 解析 → 采集
graph_builder.add_edge("data_collector", "data_analyst") # 采集 → 分析
graph_builder.add_edge("data_analyst", "report_generator") # 分析 → 报告生成
graph_builder.add_edge("report_generator", END) # 报告生成 → 流程结束
4. 编译图(生成可执行的协作流程)
return graph_builder.compile()
构建协作图
analysis_graph = build_analysis_graph()
- 运行多智能体系统并查看结果
if name == "main":
输入用户需求
user_query = "请分析2025年1月1日到2025年1月10日的日销售额趋势,生成分析报告和趋势图"
运行协作流程(传入初始状态)
result = analysis_graph.invoke({
"user_query": user_query
})
输出最终结果
print("\n" + "="*50)
print("📊 多智能体协作分析报告")
print("="*50)
print(result"final_report")
print(f"\n📈 可视化图表已保存至:{result'visualization_path'}")
上述案例是固定流水线模式,若需支持多类型任务(如同时处理"趋势分析""均值计算""异常检测"),可添加调度函数或者调度智能体实现动态分工。
7. 适用场景与扩展方向
(1)适用场景
- 自动化办公(报告生成、数据处理、邮件分类)。
- 智能客服(多技能客服分流、复杂问题协作解答)。
- 研发辅助(需求分析→代码生成→测试→调试)。
- 数据分析(数据采集→清洗→分析→可视化→报告)。
(2)扩展方向
- 集成开源模型:使用DeepSeek、Qwen等开源LLM,实现私有化部署。
- 工具扩展:对接数据库(MySQL、BigQuery)、API(Excel、Slack)、RAG知识库。
- 多模态支持:添加图像识别智能体、语音转文字智能体,处理多模态输入。
- 监控与可观测性:使用LangSmith跟踪智能体执行轨迹,优化协作流程。
- 动态智能体生成:根据任务复杂度动态创建临时智能体,提升协作灵活性。
5.3.4 实战案例:调度函数模式的实现
【示例5.3】多智能体数据分析协作系统实现代码(Langgraph_deepseek_multi_agent)。
import os
import sys
import json
import requests
import numpy as np # 直接导入 NumPy
import pandas as pd
import matplotlib.pyplot as plt
from dotenv import load_dotenv
from typing import Optional, Dict, Any
from langgraph.graph import StateGraph, END, START
-------------------------- 基础配置 --------------------------
load_dotenv()
os.environ"TOKENIZERS_PARALLELISM" = "false"
安全退出函数
def safe_exit(code: int = 0):
sys.exit(code)
----------------------- DeepSeek API 封装(无依赖) ----------------------
class DeepSeekAPI:
def init(self, api_key: str):
self.api_key = api_key
self.base_url = "https://api.deepseek.com/v1/chat/completions"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
def invoke(self, prompt: str, temperature: float = 0.1, max_tokens: int = 2048) -> str:
payload = {
"model": "deepseek-chat",
"messages": {"role": "user", "content": prompt},
"temperature": temperature,
"max_tokens": max_tokens
}
try:
response = requests.post(
self.base_url,
headers=self.headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
return result"choices"0"message""content".strip()
except requests.exceptions.RequestException as e:
print(f"❌ DeepSeek API 调用失败:{e}")
if hasattr(e, 'response') and e.response is not None:
print(f"API 响应:{e.response.text}")
safe_exit(1)
初始化LLM
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
print("❌ 未配置 DASHSCOPE_API_KEY")
print("请前往阿里云百炼平台获取 API Key,并添加到.env文件")
safe_exit(1)
llm = DeepSeekAPI(api_key=api_key)
print("✅ DeepSeek API 初始化成功")
---------------------- 工具函数(修复 pandas.np 问题) ----------------------
def fetch_data(metric: str, time_range: str) -> pd.DataFrame:
"""模拟数据采集(使用 NumPy 生成随机数,兼容所有 Pandas 版本)"""
print(f"数据采集工具 正在获取 {time_range} 的 {metric} 数据...")
try:
date_parts = time_range.replace(" ", "").split("-")
if len(date_parts) != 6:
raise ValueError("格式错误")
start_date = f"{date_parts0}-{date_parts1}-{date_parts2}"
end_date = f"{date_parts3}-{date_parts4}-{date_parts5}"
dates = pd.date_range(start=start_date, end=end_date, freq="D")
except:
print("警告 时间范围格式错误,自动使用:2025-01-01 至 2025-01-10")
dates = pd.date_range(start="2025-01-01", end="2025-01-10", freq="D")
修复:使用 np.random 替代 pd.np.random(兼容新版本 Pandas)
data = pd.DataFrame({
"date": dates,
metric: np.random.randint(100, 500) for _ in dates
})
return data
def plot_data(data: pd.DataFrame, metric: str) -> str:
"""生成中文可视化图表"""
中文显示适配
try:
plt.rcParams'font.sans-serif' = 'SimHei' # Windows
except:
try:
plt.rcParams'font.sans-serif' = 'Microsoft YaHei'
except:
plt.rcParams'font.sans-serif' = 'Arial Unicode MS' # Mac
plt.rcParams'axes.unicode_minus' = False
plt.figure(figsize=(10, 4))
plt.plot(data"date", datametric, marker="o", color="#1f77b4", linewidth=2)
plt.title(f"{metric} 趋势图", fontsize=14, pad=20)
plt.xlabel("日期", fontsize=12)
plt.ylabel(metric, fontsize=12)
plt.xticks(rotation=45)
plt.grid(alpha=0.3)
plt.tight_layout()
safe_metric = metric.replace(" ", "").replace("/", "")
img_path = f"{safe_metric}_trend.png"
plt.savefig(img_path, dpi=150, bbox_inches="tight")
plt.close()
return img_path
-------------------------- 全局状态定义 --------------------------
from typing_extensions import TypedDict
class AnalysisState(TypedDict):
user_query: str
structured_goal: OptionalDict\[str, str] = None
raw_data: Optionalpd.DataFrame = None
analysis_result: OptionalDict\[str, Any] = None
visualization_path: Optionalstr = None
final_report: Optionalstr = None
-------------------------- 多智能体节点 --------------------------
def demand_parser_agent(state: AnalysisState) -> AnalysisState:
"""需求解析智能体"""
print("需求解析智能体 正在解析用户需求...")
prompt = f"""
严格按以下格式输出JSON,字段不可缺、不可增:
{{
"metric": "具体量化指标(如销售额、日活用户数)",
"time_range": "YYYY-MM-DD-YYYY-MM-DD",
"analysis_type": "趋势分析/均值计算/异常检测"
}}
规则:用户未明确的字段用默认值:时间范围默认2025-01-01-2025-01-10,分析类型默认趋势分析
输出仅保留JSON字符串,无任何额外内容!
用户需求:{state'user_query'}
"""
response_text = llm.invoke(prompt)
容错解析
try:
if response_text.startswith("```"):
response_text = response_text.split("```")1.strip().lstrip("json").strip()
structured_goal = json.loads(response_text)
for field in "metric", "time_range", "analysis_type":
if field not in structured_goal:
raise ValueError(f"缺失{field}")
except Exception as e:
print(f"警告 JSON解析失败({e}),使用默认配置")
structured_goal = {
"metric": "销售额",
"time_range": "2025-01-01-2025-01-10",
"analysis_type": "趋势分析"
}
print(f"需求解析结果 {structured_goal}")
return {**state, "structured_goal": structured_goal}
def data_collector_agent(state: AnalysisState) -> AnalysisState:
"""数据采集智能体"""
print("数据采集智能体 正在采集数据...")
goal = state"structured_goal"
raw_data = fetch_data(metric=goal"metric", time_range=goal"time_range")
viz_path = plot_data(data=raw_data, metric=goal"metric")
print(f"数据采集完成 共{len(raw_data)}条数据,图表:{viz_path}")
return {**state, "raw_data": raw_data, "visualization_path": viz_path}
def data_analyst_agent(state: AnalysisState) -> AnalysisState:
"""数据分析智能体"""
print("数据分析智能体 正在执行分析...")
goal = state"structured_goal"
data = state"raw_data"
metric = goal"metric"
analysis_type = goal"analysis_type"
analysis_result = {}
try:
if analysis_type == "趋势分析":
start_val = datametric.iloc0
end_val = datametric.iloc-1
trend = "上升" if end_val > start_val*1.05 else "下降" if end_val < start_val*0.95 else "平稳"
analysis_result = {
"趋势": trend, "起始值": int(start_val), "结束值": int(end_val),
"增长率": f"{((end_val-start_val)/start_val*100):.2f}%",
"峰值日期": data.locdata\[metric.idxmax(), "date"].strftime("%Y-%m-%d"),
"谷值日期": data.locdata\[metric.idxmin(), "date"].strftime("%Y-%m-%d")
}
elif analysis_type == "均值计算":
analysis_result = {
"平均值": f"{datametric.mean():.2f}", "中位数": f"{datametric.median():.2f}",
"标准差": f"{datametric.std():.2f}", "数据范围": f"{int(datametric.min())}-{int(datametric.max())}",
"有效条数": len(data)
}
elif analysis_type == "异常检测":
mean, std = datametric.mean(), datametric.std()
anomalies = data(data\[metric > mean+3*std) | (datametric < mean-3*std)]
analysis_result = {
"算法": "3σ原则", "异常条数": len(anomalies),
"正常范围": f"{mean-3*std:.2f}~{mean+3*std:.2f}",
"异常日期": d.strftime("%Y-%m-%d") for d in anomalies\["date".tolist()] if len(anomalies) else "无"
}
except Exception as e:
analysis_result = {"错误": str(e)}
print(f"警告 分析失败:{e}")
print(f"分析完成 结果:{analysis_result}")
return {**state, "analysis_result": analysis_result}
def report_generator_agent(state: AnalysisState) -> AnalysisState:
"""报告生成智能体"""
print("报告生成智能体 正在生成报告...")
prompt = f"""
生成4部分结构的报告:需求概述、数据说明、核心结论、可视化说明
语言通俗,300~500字,不使用列表/表格,直接引用以下数据:
用户需求:{state'user_query'}
分析目标:{state'structured_goal'}
分析结果:{state'analysis_result'}
图表路径:{state'visualization_path'}
"""
final_report = llm.invoke(prompt)
return {**state, "final_report": final_report}
---------------------- 调度函数(适配 LangGraph 1.0+) ----------------------
def router_function(state: AnalysisState) -> str:
"""调度函数:返回下一个节点名称"""
analysis_type = state"structured_goal""analysis_type"
print(f"调度智能体 分析类型:{analysis_type} → 分配至数据分析节点")
return "data_analyst"
--------------------- 构建协作图(适配 LangGraph 1.0.5) ---------------------
def build_analysis_graph() -> StateGraph:
"""构建 LangGraph 1.0+ 兼容的协作图"""
graph_builder = StateGraph(AnalysisState)
添加节点
graph_builder.add_node("demand_parser", demand_parser_agent)
graph_builder.add_node("data_collector", data_collector_agent)
graph_builder.add_node("data_analyst", data_analyst_agent)
graph_builder.add_node("report_generator", report_generator_agent)
定义流转规则
graph_builder.add_edge(START, "demand_parser")
graph_builder.add_edge("demand_parser", "data_collector")
graph_builder.add_conditional_edges(
source="data_collector",
path=router_function
)
graph_builder.add_edge("data_analyst", "report_generator")
graph_builder.add_edge("report_generator", END)
return graph_builder.compile()
-------------------------- 主程序 --------------------------
if name == "main":
1. 构建协作流程
print("🔧 正在构建多智能体协作图...")
analysis_graph = build_analysis_graph()
print("✅ 多智能体协作图构建完成")
2. 用户需求
user_query="请分析2025年2月1日到2025年2月20日的日销售额趋势,生成报告和图表"
print(f"\n 接收用户需求:{user_query}")
接收用户需求:{user_query}")
print("-" * 80)
3. 运行协作流程
result = analysis_graph.invoke({"user_query": user_query})
4. 输出结果
print("\n" + "="*80)
print(" 最终分析报告(DeepSeek 生成)")
最终分析报告(DeepSeek 生成)")
print("="*80)
print(result"final_report")
print(f"\n 图表保存路径:{result'visualization_path'}")
图表保存路径:{result'visualization_path'}")
print(f"\n 执行总结:")
执行总结:")
print(f"- 解析目标:{result'structured_goal'}")
print(f"- 数据量:{len(result'raw_data')} 条")
print(f"- 核心结论:{result'analysis_result'}")
运行输出:
 正在构建多智能体协作图...
正在构建多智能体协作图...
✅ 多智能体协作图构建完成
 接收用户需求:请分析2025年2月1日到2025年2月20日的日销售额趋势,生成报告和图表
接收用户需求:请分析2025年2月1日到2025年2月20日的日销售额趋势,生成报告和图表
需求解析智能体 正在解析用户需求...
需求解析结果 {'metric': '日销售额', 'time_range': '2025-02-01-2025-02-20', 'analysis_type': '趋势分析'}
数据采集智能体 正在采集数据...
数据采集工具 正在获取 2025-02-01-2025-02-20 的日销售额数据...
数据采集完成 共20条数据,图表:日销售额_trend.png
调度智能体 分析类型:趋势分析 → 分配至数据分析节点
数据分析智能体 正在执行分析...
分析完成 结果:{'趋势': '上升', '起始值': 333, '结束值': 419, '增长率': '25.83%', '峰值日期': '2025-02-12', '谷值日期': '2025-02-19'}
报告生成智能体 正在生成报告...
===========================================================================
 最终分析报告(DeepSeek 生成)
最终分析报告(DeepSeek 生成)
===========================================================================
需求概述
本次分析旨在了解2025年2月1日至2025年2月20日期间日销售额的整体变化情况。用户希望看到这段时间内销售额是上升、下降还是保持平稳,并找出其中的关键高点与低点,以便把握销售动态。
数据说明
分析基于从2月1日到2月20日共20天的每日销售额数据。数据显示,销售额在这段时间内整体呈现上升趋势,起始日的销售额为333元,到结束日已增长至419元。其间销售额的最高点出现在2月12日,而最低点则出现在2月19日。
核心结论
在观察的20天里,日销售额整体增长了约25.83%,表明销售表现有显著提升。虽然过程中存在波动,例如在2月19日出现了谷值,但最终销售额仍较期初有明显增长。这一趋势说明该时间段内的销售活动总体向好。
可视化说明
已生成名为"日销售额_trend.png"的趋势图。图中以日期为横轴、销售额为纵轴,通过折线清晰展示了每日销售额的波动与整体上升轨迹。峰值点与谷值点已进行标注,可直观看到2月12日的销售高峰及后续的波动情况,帮助快速把握趋势变化。
 图表保存路径:日销售额_trend.png
图表保存路径:日销售额_trend.png
 执行总结:
执行总结:
-
解析目标:{'metric': '日销售额', 'time_range': '2025-02-01-2025-02-20', 'analysis_type': '趋势分析'}
-
数据量:20 条
-
核心结论:{'趋势': '上升', '起始值': 333, '结束值': 419, '增长率': '25.83%', '峰值日期': '2025-02-12', '谷值日期': '2025-02-19'}
最终生成日销售额图,如图5.1所示。
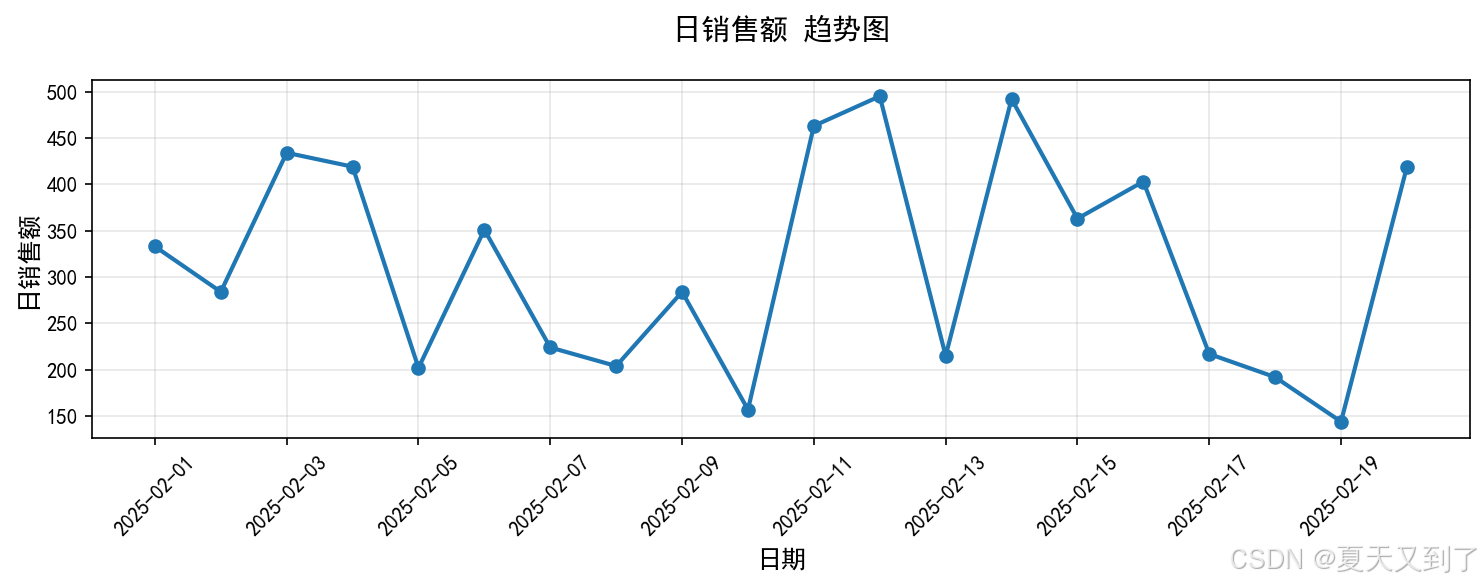
图5.1 日销售额图(日销售_trend.png)
