目录
-
- [一、 归并排序 (Merge Sort)](#一、 归并排序 (Merge Sort))
-
- [1.1 算法思想](#1.1 算法思想)
- [1.2 代码实现](#1.2 代码实现)
- [1.3 运行推演](#1.3 运行推演)
- [1.4 复杂度分析](#1.4 复杂度分析)
- [二、 计数排序 (Counting Sort)](#二、 计数排序 (Counting Sort))
-
- [2.1 算法思想](#2.1 算法思想)
- [2.2 具体步骤推演](#2.2 具体步骤推演)
- [2.3 复杂度分析](#2.3 复杂度分析)
- [三、 基数排序 (Radix Sort)](#三、 基数排序 (Radix Sort))
-
- [3.1 算法思想](#3.1 算法思想)
- [3.2 LSD 基数排序步骤推演(以十进制为例)](#3.2 LSD 基数排序步骤推演(以十进制为例))
- [3.3 复杂度分析](#3.3 复杂度分析)
前言: 在之前的三篇文章中,我们拆解了插入、交换、选择三大类共八种基于比较的排序算法。它们共同遵循一条铁律:任何基于比较的排序,时间复杂度下界为 O(n log n)。然而,现实世界中存在某些数据,凭借其内在结构,可以绕过这个理论极限,直接冲击线性时间。本文将聚焦三种特殊的排序算法:归并排序(比较类中的分治典范,稳定且能处理海量数据)、计数排序与基数排序(非比较类双雄,在特定场景下可达 O(n))。我们将从算法思想、代码实现、单步推演到复杂度分析,逐一揭穿它们的高效秘密。
一、 归并排序 (Merge Sort)
1.1 算法思想
归并排序是"分而治之"思想的教科书级演绎。其核心分为两步:
- 分 (Divide):将当前序列从中间位置一分为二,并递归地对左右子序列继续切分,直到每个子序列只剩下一个元素(天然有序)。
- 治 (Merge):将两个已经有序的子序列合并成一个更大的有序序列。
关键在于"合并":想象桌面上有两叠正面朝上的扑克牌,每叠都已经从小到大排好。你每次只能看到最上面的一张,比较两张牌,将较小的那张抽出放入结果队列,重复直到某一叠空掉,再将另一叠剩余的所有牌直接接在末尾。归并排序的合并过程,正是用双指针在辅助数组上完成这个"二路归一"的动作。
1.2 代码实现
以下为归并排序的核心 C 语言实现,包括合并函数 Merge 与递归控制函数 MergeSort。代码中使用全局变量 n 表示数组长度,并动态分配了与原始数组等长的辅助数组 b。
c
// n为全局变量 static int n; n = sizeof(a) / sizeof(DataType);
DataType* b = (DataType*)malloc((n+1) * sizeof(DataType));
void Merge(DataType a[], int low, int mid, int high)
{
int i = low, j = mid + 1, k;
for (k = low; k <= high; k++)
b[k] = a[k];
k = i;
while(i <= mid && j <= high)
{
if (b[i] > b[j])
a[k++] = b[j++];
else
a[k++] = b[i++];
}
while (i <= mid) a[k++] = b[i++];
while (j <= high) a[k++] = b[j++];
}
void MergeSort(DataType a[], int low, int high)
{
if (low < high)
{
int mid = low + (high - low) / 2;
MergeSort(a, low, mid);
MergeSort(a, mid + 1, high);
Merge(a, low, mid, high);
}
}代码深度解析:
- 辅助数组
b:由于合并两个有序段时不能原地完成(直接覆盖会丢失数据),所以需要一块等长的临时空间。Merge的第一步是将待合并区间[low, high]整体拷贝到b,之后在b上做双指针比较,结果直接写回原数组a。 - 双指针合并:指针
i扫描左半段[low, mid],指针j扫描右半段[mid+1, high]。while循环每次挑选b[i]和b[j]中较小者放入a[k],同时推进对应指针。注意条件if (b[i] > b[j])是"大于时才选右",当元素相等时会走else分支放入左元素,这是保证归并排序稳定性的关键。 - 收尾:退出主循环后,要么左半段有剩余,要么右半段有剩余,直接用两个
while将剩余元素依次填入a。由于剩余部分本身已经有序,直接追加即可。 - 递归控制:
MergeSort采用标准的二分递归,mid = low + (high - low) / 2的写法可防止(low + high)溢出。递归到底层(low == high)后开始回溯合并,属于典型的后序遍历模式。
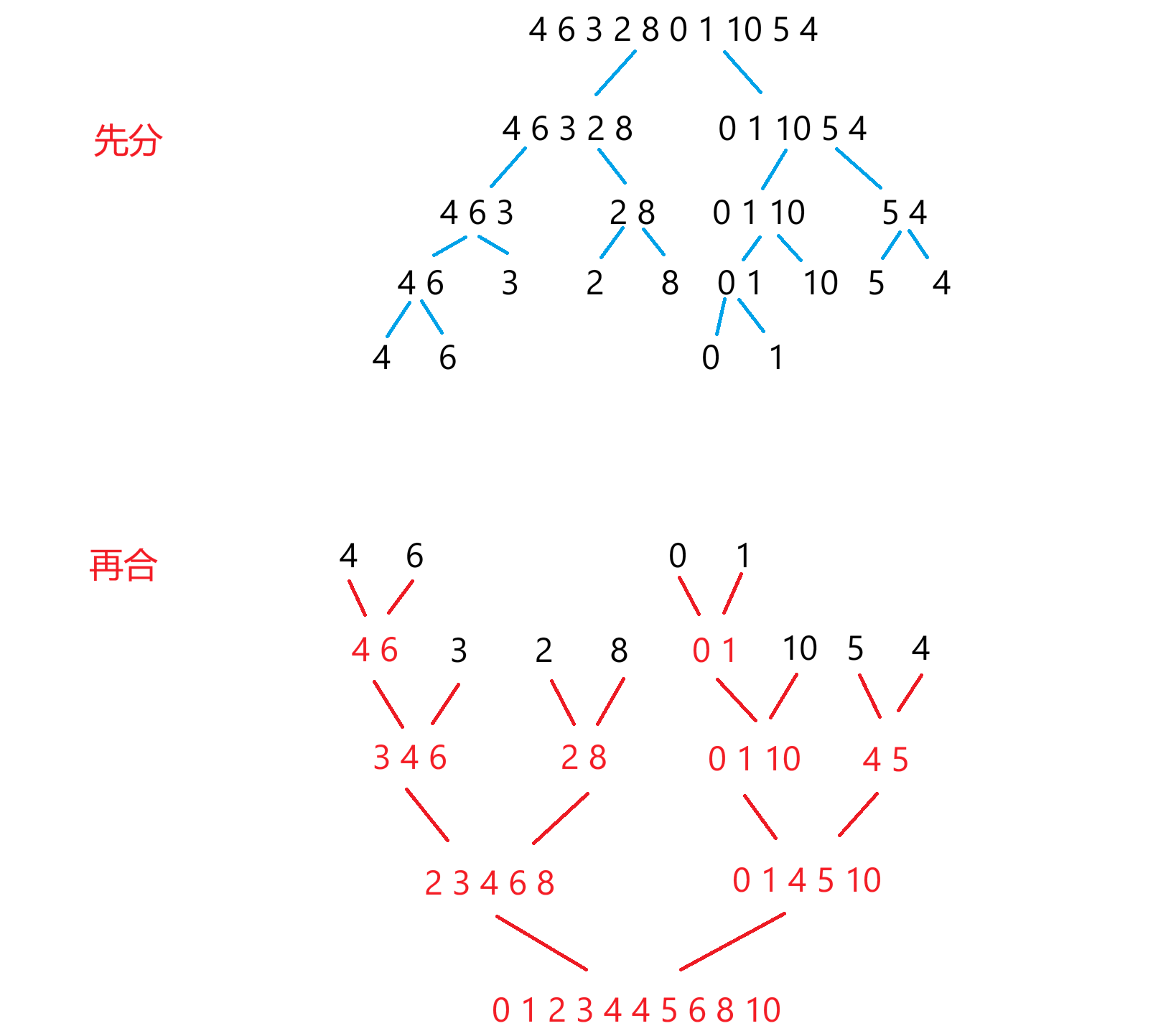
1.3 运行推演
以初始数组 4 6 3 2 8 0 1 10 5 4 为例,完整跟踪归并排序的合并过程。以下为程序输出的合并日志,清晰展示了长度由小到大的归并片段如何最终覆盖整个数组:
c
初始数组:4 6 3 2 8 0 1 10 5 4
合并 [0~0] 和 [1~1] 后: 4 6 3 2 8 0 1 10 5 4
合并 [0~1] 和 [2~2] 后: 3 4 6 2 8 0 1 10 5 4
合并 [3~3] 和 [4~4] 后: 3 4 6 2 8 0 1 10 5 4
合并 [5~5] 和 [6~6] 后: 2 3 4 6 8 0 1 10 5 4
合并 [8~8] 和 [9~9] 后: 2 3 4 6 8 0 1 10 4 5
合并 [0~2] 和 [3~4] 后: 2 3 4 6 8 0 1 10 5 4
合并 [5~6] 和 [7~7] 后: 2 3 4 6 8 0 1 10 5 4
合并 [5~7] 和 [8~9] 后: 2 3 4 6 8 0 1 4 5 10
合并 [0~4] 和 [5~9] 后: 0 1 2 3 4 4 5 6 8 10
0 1 2 3 4 4 5 6 8 10步骤详解:
- 最底层合并:数组被逐层拆分,最先合并的是相邻的单个元素对,如
[0~0]的4与[1~1]的6合并后依然为4 6。注意[8~8]和[9~9](5和4)合并后变为4 5,局部有序。 - 中间层合并:长度为 2 的有序段再合并成长度为 4 的段。例如
[0~2](3 4 6) 与[3~4](2 8) 合并,得到2 3 4 6 8。右半区也同步进行类似操作。 - 顶层收束:最终
[0~4]的2 3 4 6 8与[5~9]的0 1 4 5 10合并,完整有序序列诞生。整个过程如同一棵倒置的二叉树,叶子长出有序片段,根结点汇成最终结果。
1.4 复杂度分析
- 时间复杂度:任何情况下均为 O(n log n)。归并排序的递归深度为 log n,每一层需要对所有 n 个元素进行一次合并,总操作次数严格稳定。无论数据有序与否,分割与合并的动作都不会减少。这种"不挑食"的特性使它特别适合外部排序。
- 空间复杂度:O(n)。辅助数组
b占据了与原始数组同等规模的空间。递归调用栈的深度为 O(log n),可忽略不计。因此,归并排序不是原地排序算法,内存开销是其唯一明显的短板。 - 稳定性:稳定。在
Merge函数中,当b[i] == b[j]时,我们会优先放置左半段的元素(即b[i]),这保证了相等元素的原始相对顺序不会在合并过程中被破坏。
二、 计数排序 (Counting Sort)
2.1 算法思想
计数排序彻底抛弃了元素之间的两两比较。它假设输入数据是落在某个已知范围 [min, max] 内的整数(或者可以映射为整数的对象),核心思想是:统计每个可能的值出现了多少次,然后按照值的顺序,依次"复制"出相应数量的元素,直接构建有序序列。
想象一场按年龄分组的排队:你已知所有人的年龄都在 0~120 岁之间,于是可以提前准备好 121 个空桶,每遇到一个人,就往对应年龄的桶里投一枚代币。投完后,从 0 岁到 120 岁逐个清点桶里的代币数,每清点一个年龄,就让该数量的该年龄的人出列,最终队伍必然按年龄有序。计数排序正是这样的非比较排序。
2.2 具体步骤推演
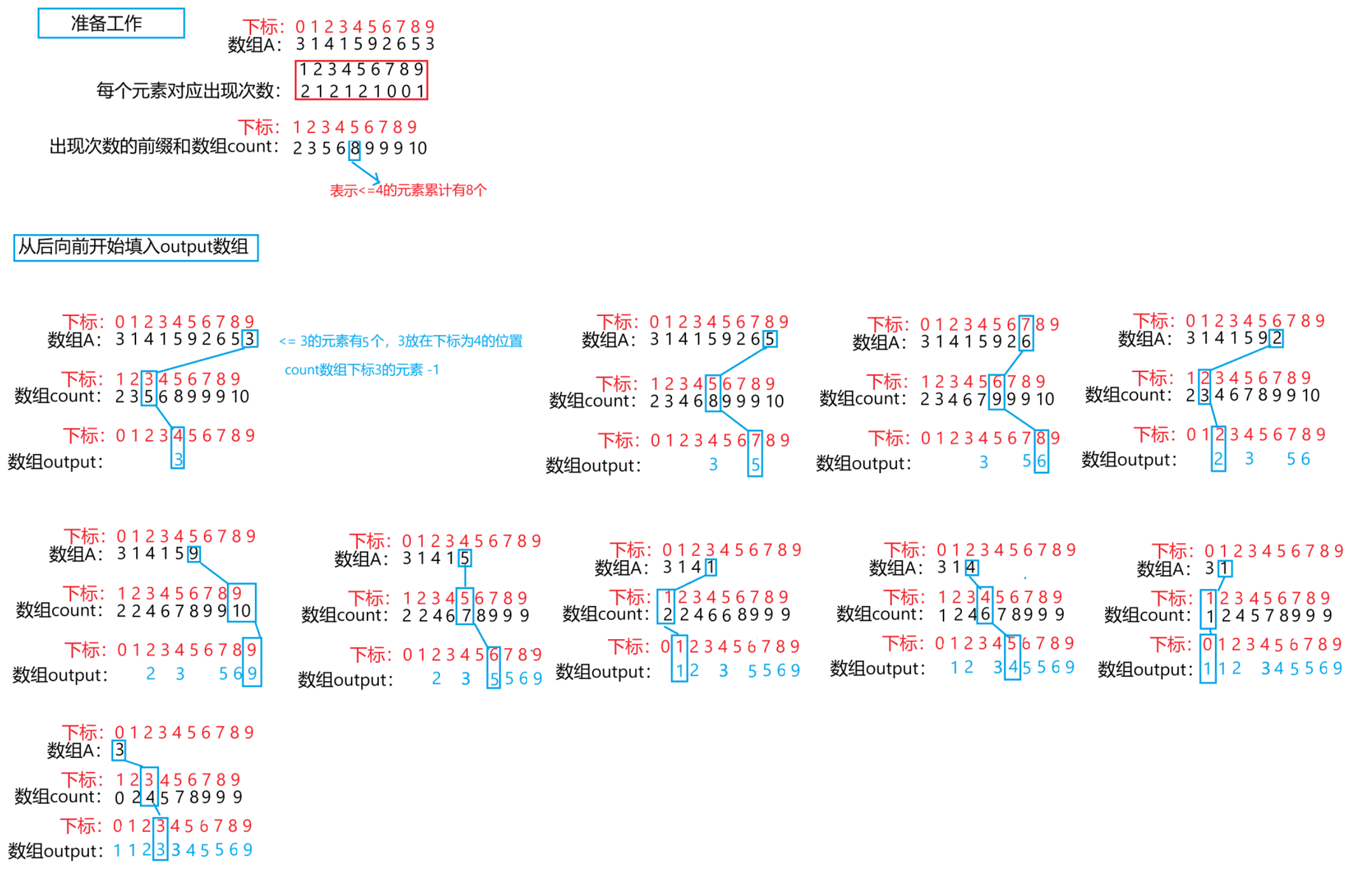
设原始数组 A = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3],已知所有元素取值范围在 1~9 之间(或更宽,但确定为 0~9)。执行过程如下:
- 确定范围:找到最小值
min = 1,最大值max = 9,则计数数组长度为max - min + 1 = 9。 - 初始化计数数组:开辟长度为 9 的数组
count并全部初始化为 0。 - 统计频次:遍历
A,对每个元素x,执行count[x - min]++。遍历后:- 值 1:出现 2 次
- 值 2:出现 1 次
- 值 3:出现 2 次
- 值 4:出现 1 次
- 值 5:出现 2 次
- 值 6:出现 1 次
- 值 9:出现 1 次 (其余为 0)
- 累加计数(为稳定排序做准备):对
count数组进行前缀和操作,count[i] += count[i-1]。累加后count表示每个值在最终有序数组中的"最后一个位置的下一位置":- 值 1→2,值 2→3,值 3→5,值 4→6,值 5→8,值 6→9,值 9→10。
- 反向填充输出数组:开辟与
A等长的输出数组output。为确保稳定性,从A的末尾向前遍历:- 取
A[9] = 3,count[3-1]为 5,将 3 放入output[5-1] = output[4],count[3-1]减 1 变为 4。 - 取
A[8] = 5,count[5-1]为 8,放入output[7],计数减为 7。 - 依此类推,最终
output = [1,1,2,3,3,4,5,5,6,9]。
- 取
- 回写原数组(如果需要原地效果):将
output拷贝回A。
2.3 复杂度分析
- 时间复杂度:O(n + k),其中 k 是取值范围的宽度(max-min+1)。统计、累加、反向填充均只需常数趟线性扫描,没有元素间的比较。当 k 与 n 处于同一数量级或更小时,计数排序接近 O(n);但若 k 极大(例如取值范围遍布整个 32 位整数),复杂度将退化到不可接受。
- 空间复杂度:O(n + k)。需要计数数组(大小 k)和输出数组(大小 n)。原地计数排序存在但会破坏稳定性,且实现复杂。
- 稳定性:稳定,前提是上述反向填充的实现方式。正向填充也能正确排序但会破坏稳定性。
- 局限性:仅适用于整数或可离散映射的数据;要求数据范围不能过大,否则空间和时间都不可控。
三、 基数排序 (Radix Sort)
3.1 算法思想
基数排序同样不是基于比较,它利用数字的基数表示(如十进制、二进制)来排序。核心思想是:从最低有效位(LSD)到最高有效位(MSD),依次对每一位进行稳定排序。由于稳定排序的性质,高位排序不会打乱低位已经排好的顺序,最终实现全局有序。
LSD 基数排序的过程可以类比为一副按花色和点数分类的扑克牌:先按点数(低位)分成 13 摞,然后把各摞按顺序收集起来;再按花色(高位)分成 4 摞,收集后整副牌就变成按花色优先、点数有序的序列。用于每一位的稳定排序通常采用计数排序(或桶排序),因为每一位的取值空间很小(十进制为 0~9,二进制为 0~1)。
3.2 LSD 基数排序步骤推演(以十进制为例)
待排序数组:[329, 457, 657, 839, 436, 720, 355]。所有数字均为三位十进制整数(位数不足可高位补零统一视之)。
- 第一趟:按个位数排序(使用计数排序等稳定排序):
- 个位:9,7,7,9,6,0,5
- 排序后数组变为:
[720, 355, 436, 457, 657, 329, 839](个位 0,5,6,7,7,9,9)
- 第二趟:按十位数排序:
- 基于上一步的结果,十位:2,5,3,5,5,2,3
- 排序后:
[720, 329, 436, 839, 355, 457, 657](十位 2,2,3,3,5,5,5)
- 第三趟:按百位数排序:
- 百位:7,3,4,8,3,4,6
- 排序后:
[329, 355, 436, 457, 657, 720, 839](百位 3,3,4,4,6,7,8)
最终得到完全有序的数组。注意每一步都必须使用稳定排序,否则低位的有序性会被高位排序破坏。
3.3 复杂度分析
- 时间复杂度:O(d × (n + k)),其中 d 是最大数字的位数,k 是每位可能的取值基数(如十进制 k=10)。若 k 相对 n 为常数(通常如此),且 d 也是常数或近似 O(1),则基数排序可达到 O(n) 的线性时间。实际中,在 d 很大时,可以通过扩大基数(如以 65536 为基)来减少趟数,这也是一种常见的工程优化。
- 空间复杂度:O(n + k),主要是每趟计数排序所需的计数数组和输出数组。
- 稳定性:稳定(LSB 基数排序),因为每一趟稳定排序确保了全局顺序的正确构建。
- 适用范围:适用于整数、定长字符串等可分解为"位"的数据。对于浮点数,可通过 IEEE 754 的位表示进行基数排序,但需注意符号位和阶码的处理。
- 与比较排序的关系:基数排序能够突破 O(n log n) 下界,正是因为它没有使用元素之间的比较,而是利用了值的位级结构信息。这也意味着它对数据的假设更强,应用范围自然受限。