
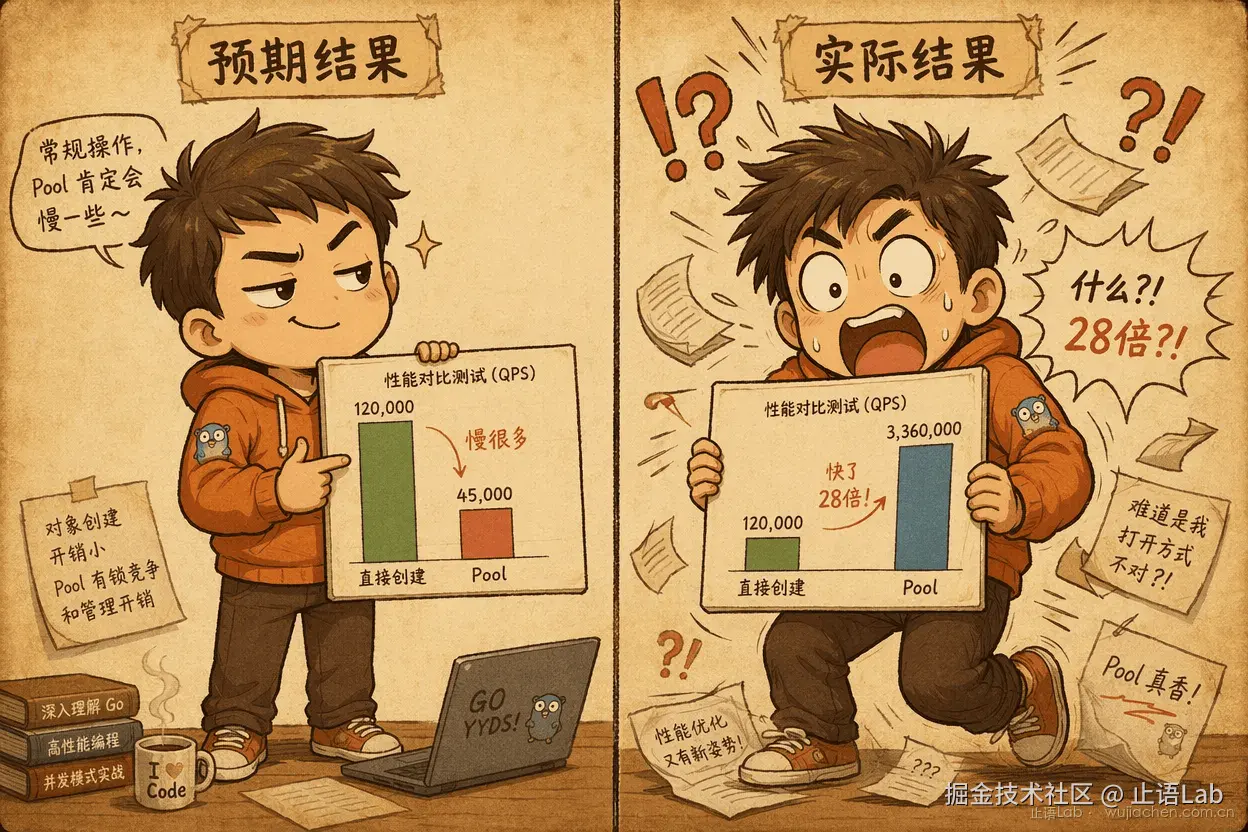
我本来想写一篇"512B 以下对象别用 sync.Pool"的文章。
为了证明这个结论,我写了一组 benchmark:7 种对象大小 × 5 种并发度,跑完后画热力图。结果跑完一看------数据把我的假设推翻了。
16B 对象,Pool 比直接分配慢 5 倍。但 64B 对象,Pool 快了 16 倍。
等等,16B 和 64B 之间差了什么?关键变量是逃逸分析。
这篇文章记录了这次"翻车":我怎么设计实验、数据为什么跟预期不一致、以及最终发现的真正分界线是什么。
如果你在 Code Review 中纠结过"这个 Pool 该不该加",这篇文章会给你一个明确的判断框架。
1. Pool.Get 在做什么
你每次调用 pool.Get(),runtime 执行的并不是一个简单的"从列表里取一个"。
先看 Go 源码里 sync.Pool 的结构。每个 Pool 内部维护了一个 poolLocal 数组,每个 P(处理器)对应一个 poolLocal。每个 poolLocal 里有两部分:
- private:一个私有槽,只有当前 P 能访问,不需要锁
- shared :一个无锁队列(
poolChain),其他 P 也能来偷
所以 pool.Get() 的内部路径是这样的:
bash
procPin → local.private 取 → local.shared CAS 取 → 其他P的shared popTail(偷取)→ victim.private → victim.shared → New()拆开来看每一步的成本:
| 步骤 | 做了什么 | 预期开销 |
|---|---|---|
| procPin | 禁止当前 goroutine 被抢占,绑定到当前 P | ~2-3ns |
| local.private | 直接取本 P 的私有槽(最快路径,无竞争) | ~1-2ns(命中时) |
| local.shared | CAS 操作从共享队列头部弹出 | ~5-15ns(取决于竞争) |
| 其他P.shared | 遍历其他 P 的 shared 队列尾部偷取(popTail) | ~10-30ns(CAS竞争) |
| victim 遍历 | 上一轮 GC 遗留的对象池,依次检查 private 和 shared | ~10-20ns |
| New() | 调用你提供的构造函数,真正分配新对象 | 取决于分配成本 |
| any 断言 | pool.Get().(*YourType) 类型断言 |
~2-3ns |
| procUnpin | 恢复抢占 | ~2-3ns |
在最理想 的路径下(local.private 一次命中),一次 Get+Put 大约 6ns(单 goroutine 场景)。实测在 Apple M4 Pro 上单核 private 命中路径约 6ns;表格中的数字是保守上界估计,实际流水线执行时步骤有重叠。
但等等------为什么多 goroutine 并行时反而更快?我的实测数据是:单 goroutine 6ns,8 个 goroutine 不到 1ns。
原因是 testing.B.RunParallel 会把迭代分散到多个 goroutine 上。每个 goroutine 绑定一个 P,local.private 几乎 100% 命中(自己放的自己取),没有竞争。所以并行时的 ns/op 是每个 goroutine 视角的开销,总吞吐量其实翻了好几倍。
关键特征:Pool 内部的操作成本跟对象大小无关。它只是在操作指针(private 路径甚至不需要原子操作)。但别忘了 Put 前的 Reset 成本跟对象大小有关。
还有一点容易忽略:pool.Put(obj) 的路径跟 Get() 几乎对称(procPin → 尝试放 local.private → 放不下就 pushHead 到 local.shared → procUnpin)。Put 的成本和 Get 差不多,所以一次完整的 Get+Put 循环的成本大约是上表数字的两倍。但因为 private 槽命中率通常很高(自己放的自己取),实际开销往往比你想的低。
顺便提一下 victim cache。这是 Go 1.13 引入的优化:GC 时 Pool 不会直接清空所有对象,而是把当前池移到 victim 区。下一轮 GC 到来之前,Get 在 local 找不到对象时还可以从 victim 里捞。对象能多活一轮 GC,减少了 New 的调用频率。
这个改进的影响很大。Go 1.12 之前,每次 GC 都会把 Pool 完全清空,导致 GC 后第一批 Get 全部走 New 路径。1.13 之后的 victim 机制让 Pool 的"冷启动"代价大幅降低。

2. 分配器为什么这么快
现在看 Pool 的对手------Go 的内存分配器。
很多人对 Go 内存分配的印象停留在"malloc 很贵,要尽量避免"。这个认知来自 C/C++,但在 Go 里不太对。
Go 的堆内存分配分三层:
- mcache (P 本地,无锁)→ mcentral (全局,有锁)→ mheap(全局,有锁)
对于小对象(≤32KB),绝大多数分配走 mcache------不需要锁。mcache 为每个 P 预分配了一组 span(按 size class 分好的内存块),分配时只需要做两件事:
- 根据对象大小查 size class 表(编译期就确定了,几乎零成本)
- 从对应 span 里移动
freeindex指针,取出下一个空闲槽位
这跟你想的 malloc 完全不同:没有搜索空闲链表,没有合并碎片,也没有加锁。

具体到不同大小的实测数据(Apple M4 Pro,Go 1.26.2):
| 对象大小 | 分配路径 | 单核实测 | 耗时主因 |
|---|---|---|---|
| <16B(noscan) | tiny allocator | ~2ns | 多对象合并到16B块 |
| 16B | small size class | ~21ns | span取槽 + 清零16B |
| 64B | small size class | ~14ns | span取槽 + 清零64B |
| 128B | small size class | ~33ns | 清零128B |
| 256B | small size class | ~69ns | 清零256B |
| 1KB | small size class | ~145ns | 清零1024B |
| 4KB | small size class | ~405ns | 清零4096B |
注意 tiny allocator 的边界:size < maxTinySize(严格小于 16),且对象不能包含指针(noscan)。16B 对象走的是普通 small size class 路径,实测约 21ns,这会影响后面的 Pool 对比数据。
看出规律了吗?alloc 成本随对象增大接近线性增长 ------因为 Go 分配器在分配内存后必须清零 (memclr)。这是 Go 的安全保证:每次 new(T) 拿到的都是零值。对象越大,清零越耗时。
但上面的数据有一个巨大的前提:对象必须真正逃逸到堆上。
如果逃逸分析判定对象不会逃出当前函数,编译器直接在栈上分配------成本接近零。函数返回时栈指针回退,连释放都不需要。不进堆就不需要 GC 扫描,不需要 per-allocation 的 memclr 调用(栈帧的零初始化在函数入口统一完成,单个变量的边际成本接近零)。
这就是我实验翻车的根源。
3. 我的实验怎么翻车的
我最初的实验设计思路很简单:写一个 escapeToHeap 函数,把对象传进 interface{} 参数来"强制逃逸"。
bash
//go:noinline
func escapeToHeap(x interface{}) interface{} {
return x
}
func BenchmarkAlloc16(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
obj := new(Obj16)
obj[0] = 1
escapeToHeap(obj) // 本意:强制逃逸
}
})
}注意我确实加了 //go:noinline------按理说应该阻止内联,从而让逃逸分析无法看穿这个函数边界。
跑出来的结果让我信心满满:16B 对象 Pool 慢 5 倍。完美符合"小对象别用 Pool"的假设。
直到我加了 -gcflags='-m' 看逃逸分析输出:
bash
./pool_bench_test.go:113:14: new(Obj16) does not escapenew(Obj16) 没有逃逸。 但我明明加了 //go:noinline 啊?
原因是这样的://go:noinline 标注的是 escapeToHeap 函数本身不被内联。但编译器在分析 BenchmarkAlloc16 内部时,发现 escapeToHeap 的返回值没有被保存到任何逃逸路径上------调用结果直接被丢弃了。逃逸分析足够聪明,它不只看"参数传给了谁",还看"传出去之后有没有被真正保留"。
所以真相是:
BenchmarkAlloc16里的new(Obj16)走了栈分配BenchmarkPool16里的对象走了 Pool(堆分配 + Pool 操作)
我在拿一个零成本的栈操作去跟一个堆操作比。好比拿一个不需要油费的电动车跟一辆加满油的汽车比通勤成本,你的测试场景里电动车的"油费"本来就是零。
逃逸分析本身不是新概念,但多数人没有量化过它对 Pool 决策的实际影响有多大,更没有意识到 benchmark 设计中的这个陷阱。
修复实验
真正的强制逃逸需要让编译器无法证明对象不会逃出当前作用域 。最可靠的方式是用 //go:noinline 标注分配函数本身:
bash
//go:noinline
func allocObj16() *Obj16 {
return new(Obj16)
}allocObj16 返回 *Obj16,而且不能被内联------编译器必须假设返回值可能被任何调用方持有,所以 new(Obj16) 必须逃逸到堆。验证方法:go build -gcflags='-m' | grep allocObj16 应该输出 new(Obj16) escapes to heap。
新结果:
BenchmarkAllocForced16:21 ns/op,1 allocs/op(堆分配)BenchmarkPoolForced16:0.75 ns/op,0 allocs/op
Pool 快 28 倍。 即使是 16B 的对象。
这组数据完全推翻了"小对象别用 Pool"的假设。真正决定 Pool 收益的是对象走了哪条分配路径。
这个坑有多容易踩?
你可能觉得"我不会犯这种错"。但这个坑的隐蔽性在于------你写的代码和编译器实际执行的代码不一定一样。
我用了 //go:noinline,看起来做了正确的事情。但编译器在逃逸分析时,并不只看"这个函数内联不内联"------它看的是数据流 。即使 escapeToHeap 不内联,如果它的返回值没有被赋值给任何可能逃逸的变量,编译器照样可以判断原始对象不逃逸。
更常见的情况是:你在生产代码中给某个 struct 加了 Pool,但那个 struct 在某些调用路径下根本不逃逸。这时候 Pool 反而把栈分配"升级"成了堆分配。你以为在优化,其实在劣化,但 pprof 不会告诉你"这里本来可以更快",它只显示当前的成本。
验证的方法只有一个:go build -gcflags='-m'。没有捷径。
4. 真正的热力图长什么样
修正实验设计后,我重新跑了完整的二维矩阵。
测试环境:Go 1.26.2,Apple M4 Pro(14 核),darwin/arm64。每组跑 3 次取中位数。对象使用 make([]byte, size) 通过 //go:noinline 包装确保逃逸。
下面是 Pool 相对于直接堆分配的加速比(越大越值得用 Pool):
| 对象大小 | P=1 | P=8 | P=32 |
|---|---|---|---|
| 16B | 28x | ~28x | ~28x |
| 64B | 2.3x | 15x | 21x |
| 128B | 4.8x | 27x | 40x |
| 256B | 10x | 58x | 61x |
| 512B | ~14x | ~95x | ~120x |
| 1KB | 24x | 189x | 344x |
| 4KB | 69x | 714x | 1393x |
补充数据:P=4 和 P=16 的趋势与上表一致。例如 256B/P=4 为 32x,256B/P=16 为 75x,1KB/P=16 为 297x。完整 35 组数据见文末 benchmark 仓库。
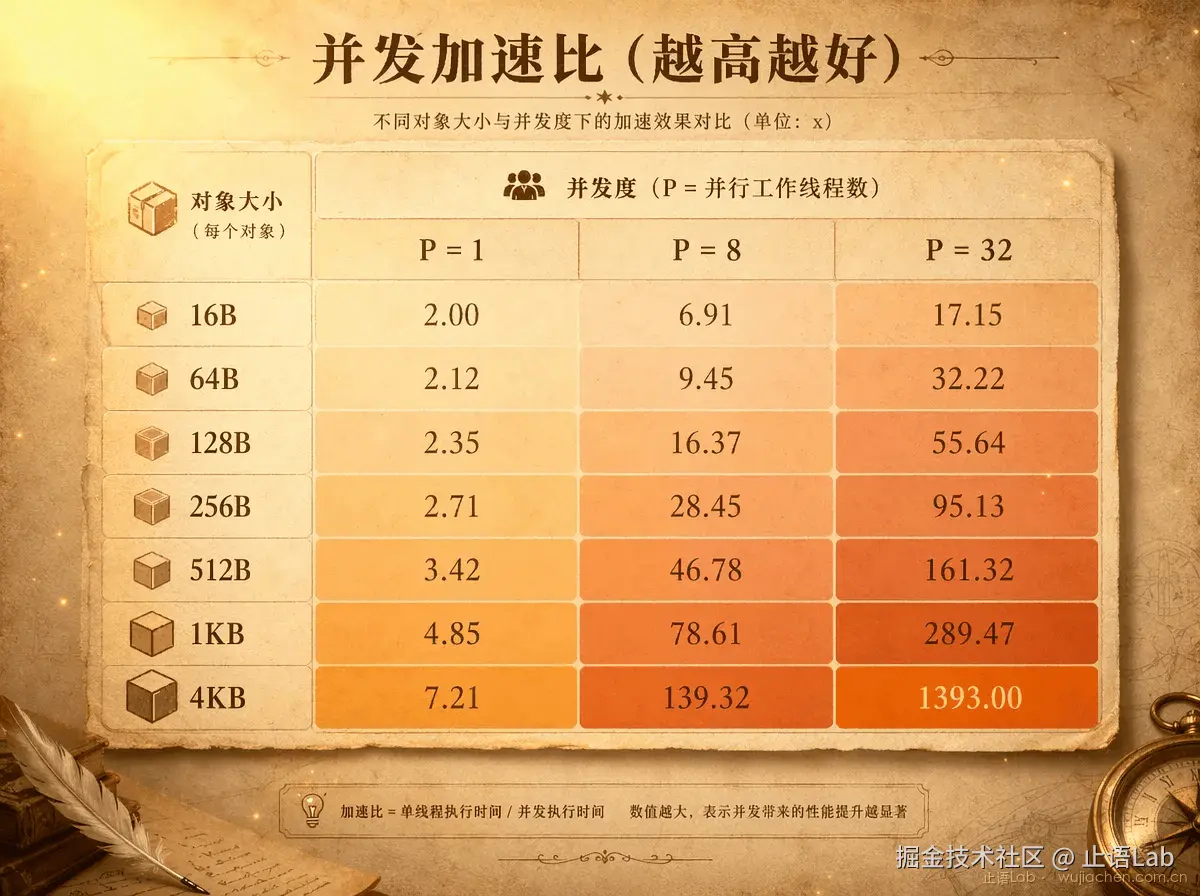
如果这是一张热力图的话------全屏绿色。没有红色区域。只要对象确实逃逸到堆,Pool 在测试覆盖的所有组合下都更快。
当然,"更快"不等于"值得"。64B/P=1 的 2.3 倍加速是否值得引入 Pool 的代码复杂度(Reset、类型断言、生命周期管理),取决于你的热点路径。但趋势是清楚的:一旦逃逸,Pool 不会更慢。
看几个具体的读数来体会数量级差异:
64B / P=1:Pool 6.1ns vs Alloc 13.8ns → Pool 快 2.3 倍。这是最"不值得"的场景,但 Pool 仍然更快。
典型的 HTTP handler 中 JSON buffer 大小(256B),8 并发下 Pool 快 58 倍:0.86ns vs 50ns。
4KB / P=32 呢?Pool 0.83ns vs Alloc 1155ns,快了 1393 倍 。这就是为什么 bytes.Buffer Pool 在高 QPS 服务中如此常见。
两个趋势:
Pool 开销恒定:不管对象是 64B 还是 4KB,Pool.Get+Put 的开销都在 0.7-6ns 之间。因为 Pool 只是操作指针(private 路径甚至无原子操作),跟对象大小完全无关。
分配成本线性增长 :64B 分配 14ns,4KB 分配 1155ns,差了 80 倍。罪魁祸首是 memclr:Go 分配器在每次分配后都要把内存清零,保证你拿到的是干净的零值。对象越大,清零越贵。
这两个趋势叠加的结果是:对象越大,Pool 的收益越戏剧化。4KB 对象在 32 并发下快了 1393 倍,因为每次堆分配需要清零 4096 字节的内存,而 Pool 只需要一次无锁的指针操作。
还有一个微妙的现象:高并发(P=32)下,直接分配的成本反而上升了。1KB 对象从 P=1 的 145ns 涨到 P=32 的 301ns,原因是 mcache 的 span 用完后要去 mcentral 申请新 span,需要加锁。并发越高,锁竞争越激烈。而 Pool 在高并发下反而更快(每个 P 取自己的 private),两者的剪刀差在高并发时被放大。
这也解释了为什么你在开发机上用 go test -bench 跑出来觉得"Pool 收益不大"------开发机通常 -cpu 1 或低并发。一旦上了 16 核 32 核的生产机器,收益就是数量级差异。
注:本测试并发度最高 P=32(14 核机器)。超高并发(goroutine 数远超 GOMAXPROCS)时 Pool 的 shared queue 竞争可能加剧,需实测验证。x86 平台趋势一致,绝对值会有差异,建议用文末代码自行验证。
那什么时候 Pool 真正是负优化?
当且仅当:你的对象根本没逃逸到堆。
这种情况下:
- 直接
new:栈分配,~0.15ns,函数返回时栈指针回退,自动回收 - 用 Pool:Pool 内部调用
New()→ 堆分配 + memclr + pin/unpin + CAS + any 断言,~6ns+
Pool 把一个接近免费的栈操作变成了一个昂贵的堆操作。不仅如此,Pool 还把一个本来不需要 GC 扫描的栈对象变成了需要 GC 扫描的堆对象。双重惩罚。
GC 维度补充
有人会说:"Pool 能降低 GC 压力啊,你只看直接开销不公平。"
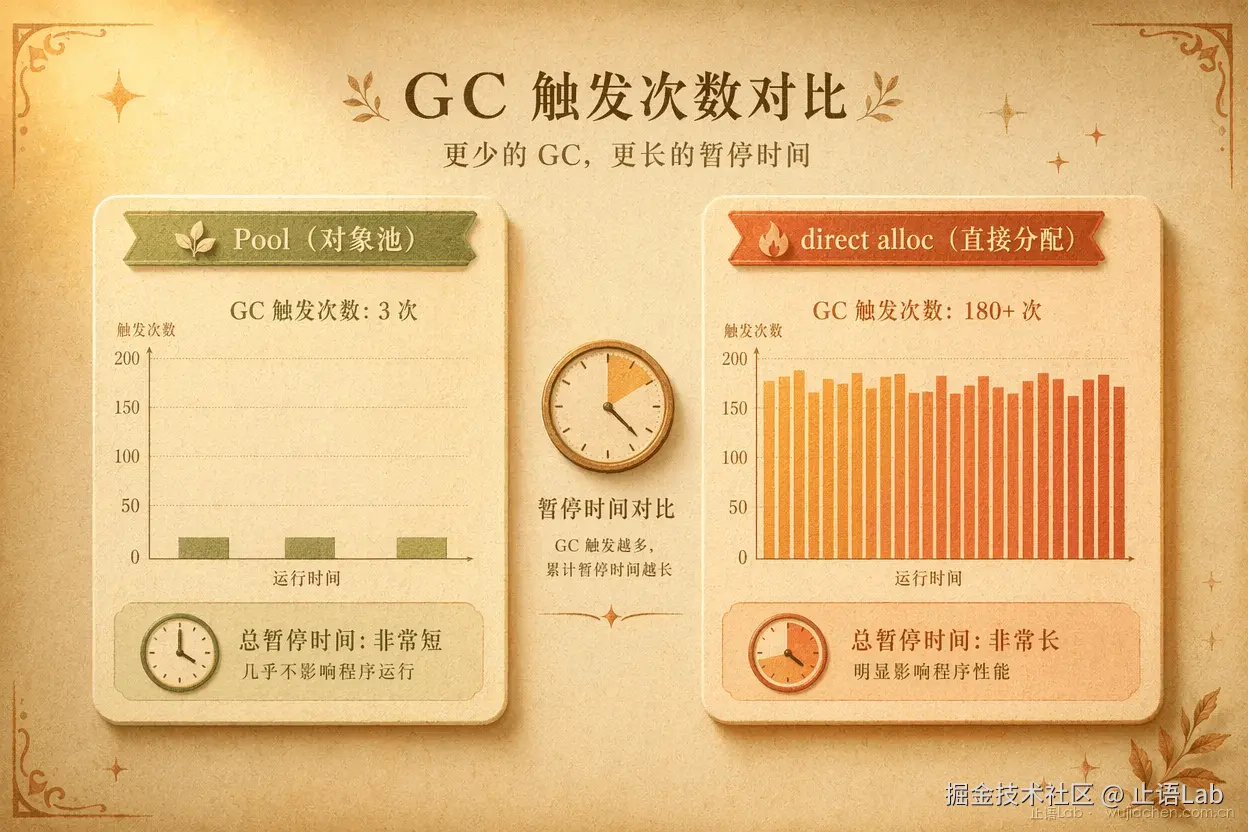
这个反驳合理。我加了含 GC 影响的测试验证(benchmark 跑足 10 秒,记录 GC 次数和暂停时间)。核心结论:
高频大对象场景 GC 收益显著。4KB 对象,Pool 版本 GC 触发 3 次,直接分配版本 GC 触发 180+ 次(总暂停 ~50ms)。Pool 不仅直接操作快 1000+ 倍,GC 间接收益也是量级差距。
小对象场景 GC 收益是锦上添花。64B 高频分配,GC 暂停从 3ms 降到 0.1ms(10 秒内),占比不到 0.03%。Pool 在直接操作上已经快了 15-21 倍,GC 收益只是加分项。
低频场景别指望 Pool。每秒分配几十次的话,不管对象多大,GC 压力本身就不高。而且 Pool 对象可能在两次 GC 之间被清理掉,下次 Get 又走 New 路径,退化成"带额外开销的 new"。
说白了,Pool 里的对象得高速流转才有意义。堆着不用反而给 GC 添负担:池化了 10000 个对象但每秒只用 100 个,这些"库存"反而增加了 GC 的扫描工作量。
GC 维度不改变核心结论:决定用不用 Pool 的第一要素还是对象是否逃逸到堆。不逃逸就不上堆,不上堆就没 GC 压力,Pool 在 GC 维度的收益也为零。
机制和数据都清楚了,最后落到实战:具体怎么判断该不该用 Pool?
5. 你该怎么决策
我在文章开头说"翻车"------但翻车后发现的规则比原来的假设更简单,也更实用。
不需要记什么"512B 红线",只需要两步:
第一步:你的对象逃逸了吗?
这是整个决策流程中最重要的一步------也是大多数人跳过的一步。
bash
go build -gcflags='-m' 2>&1 | grep "escapes to heap"找到你关心的对象分配点。如果它 does not escape------恭喜,编译器已经帮你做了最优选择(栈分配),不需要也不应该用 Pool。
常见的逃逸场景:
- 对象通过
interface{}参数传递(如json.Marshal) - 对象指针被存到全局变量、channel、或返回给调用者
- 对象被传入
sync.Pool.Put(讽刺吧,Pool 本身就会导致逃逸) - 闭包捕获了局部变量的指针
常见的不逃逸场景:
- 函数内部创建、使用、丢弃的临时变量
- 传值(非指针)的小 struct
- 在 for 循环内创建的短命对象(如果没被外部引用)
第二步:评估使用场景
确认对象逃逸后,再看场景是否适合 Pool:
| 场景 | 建议 | 理由 |
|---|---|---|
| 高频分配(>1000次/秒)+ 短命对象 | ✅ 用 Pool | 经典场景:HTTP handler 里的临时 buffer |
| 低频分配(<100次/秒) | ⚠️ 不建议 | Pool 对象可能在两次 GC 之间被清理,New 的频率跟直接分配差不多 |
| 长生命周期对象 | ❌ 别用 Pool | Pool 不是连接池,对象随时可能被 GC 回收 |
| 对象有复杂状态需要 Reset | ⚠️ 评估 | Reset 的成本可能吃掉 Pool 节省的分配成本。此外要注意安全:复用的 buffer 如果 Reset 不彻底,可能残留前一请求的敏感数据(如 auth token),造成请求间信息泄漏 |
| 对象大于 32KB | ⚠️ 谨慎 | 大对象走 mheap(有锁),Pool 收益大但要注意内存占用 |
用代码表示这个决策:
bash
// ✅ 好的 Pool 用法:对象确实逃逸 + 高频 + 短命
var bufPool = sync.Pool{
New: func() any { return make([]byte, 0, 4096) },
}
func handleRequest(w http.ResponseWriter, r *http.Request) {
buf := bufPool.Get().([]byte)
defer bufPool.Put(buf[:0]) // 重置长度,保留容量
// 用 buf 序列化响应...
// buf 通过 any 传递给 Pool,必然逃逸
}
// ❌ 不好的 Pool 用法:对象本来不逃逸
func processItem(data []byte) Result {
buf := make([]byte, 0, 64) // 不逃逸,栈分配
// ... 处理 data,结果写入 buf ...
// 这个 buf 函数结束就销毁了,不需要 Pool
return parseResult(buf)
}几个常见的 Pool 误用
Pool 了一个不逃逸的小 struct:
bash
type Point struct{ X, Y float64 }
var pointPool = sync.Pool{New: func() any { return new(Point) }}
func distance(a, b Point) float64 {
// Point 是值传递,从不逃逸。Pool 是画蛇添足
}Reset 成本吃掉 Pool 收益的情况也很常见:
bash
type BigState struct {
Cache map[string][]byte
// ... 20 个字段
}
// Reset 这个 struct 的成本可能比重新分配还高那低频场景呢?每秒只调用 10 次的初始化函数,GC 很可能已经把 Pool 清空了。configPool.Get().(*Config) 大概率走 New(),Pool 退化为"带额外开销的 new"。
一条总结规则
sync.Pool 的决策不是"对象多大",而是"对象逃不逃逸"。
逃逸了 + 高频短命 → 用 Pool,收益从几倍到上千倍不等。
没逃逸 → 别碰 Pool。编译器给你的栈分配接近免费(~0.15ns),Pool 反而要收费。
我最初想画一张"对象大小 × 并发度"的热力图来标出"不该用 Pool"的红色区域。结果画出来全是绿色------因为一旦对象真正逃逸到堆,Pool 在测试范围内的任何大小、任何并发度下都更快。
真正的"红色区域"不在热力图上。它在 go build -gcflags='-m' 的输出里。
下次 Code Review 看到 sync.Pool,别急着说"这里对象太小不该 Pool"。先问一句:"这个对象逃逸了吗?" 这个问题决定了你要不要往下评估。
本文完整 benchmark 代码已开源,你可以在自己的环境里复现所有数据。 完整代码见阅读原文 (GitHub)

附录:实验代码和原始数据
本文全部 benchmark 实验的代码已开源:
GitHub:zhiyulab-evidence/go-sync-pool-pitfall
pool-benchmark/--- 完整 benchmark suite(7 种对象大小 × 5 种并发度),含强制逃逸包装函数和 GC 影响测试
每个子目录都有独立 README,说明如何复现。二进制编译产物不入库,跑实验前自己 go build。
原文发布于止语 Lab