本文系统介绍一套"智能优化+深度学习+可解释分析"的端到端回归预测方案,涵盖混沌映射初始化的粒子群优化(PSO)算法、CNN-LSTM混合神经网络构建与超参数自动寻优、多输出回归预测、SHAP特征贡献分析及新数据预测部署全流程。
一、研究背景与问题定义
在许多工程和科学领域中,我们常常面临多输入、多输出的回归预测任务------例如根据多个工艺参数预测产品的多个性能指标,或基于多维环境变量预测多个目标参数。传统方法(如多元线性回归、SVR、随机森林)在面对非线性、时序依赖关系时表现不足,而深度学习方法虽然建模能力强,但其"黑箱"特性使得模型决策过程难以解释,在医疗、金融、工业等高风险领域受到限制。
针对上述痛点,本文构建了一套完整的可解释深度学习预测框架,具备以下核心能力:
- 自动超参数寻优:采用混沌映射改进的粒子群算法(PSO)自动搜索CNN-LSTM的最优网络结构参数,避免人工试错的低效。
- 高精度多输出预测:CNN负责提取局部特征,LSTM捕获时序依赖,两者结合实现端到端的多输出回归。
- SHAP特征可解释性:基于合作博弈论Shapley值,量化每个输入特征对每个输出的边际贡献,使模型从"黑箱"走向"白箱"。
- 新数据一键预测:训练完成后可直接加载新样本数据,无需重新训练即可输出预测结果。
二、技术路线总览
整体技术路线分为五个阶段 ,如下图所示:
┌────────────────────────────────────────────────────────────────────┐
│ 阶段一:数据预处理 │
│ 数据导入 → Min-Max归一化 → 训练/测试集划分(8:2) │
├────────────────────────────────────────────────────────────────────┤
│ 阶段二:PSO智能优化 │
│ 混沌映射初始化种群 → 粒子迭代寻优 → 输出最优超参数集合 │
├────────────────────────────────────────────────────────────────────┤
│ 阶段三:CNN-LSTM建模与训练 │
│ 最优参数构建网络 → Adam优化器训练(500 Epochs)→ 模型收敛 │
├────────────────────────────────────────────────────────────────────┤
│ 阶段四:模型评估与可视化 │
│ RMSE/R²/MAE指标 → 雷达图对比 → 预测曲线 → 误差分析 → 回归拟合图 │
├────────────────────────────────────────────────────────────────────┤
│ 阶段五:SHAP可解释分析与新数据预测 │
│ Shapley值精确计算 → 蜂群图+条形图 → 新数据前向预测 → 结果导出 │
└────────────────────────────────────────────────────────────────────┘三、算法原理与公式推导
3.1 混沌映射改进的粒子群优化(PSO)
标准PSO算法中,种群初始化采用随机均匀分布,容易导致初始粒子集中在搜索空间的局部区域,影响全局探索能力。本文引入混沌映射初始化策略,利用混沌系统的遍历性和伪随机性生成分布更均匀的初始种群。
3.1.1 标准PSO速度与位置更新公式
粒子的速度和位置更新遵循以下经典公式:
vik+1=w⋅vik+c1⋅r1⋅(pbesti−posik)+c2⋅r2⋅(gbest−posik) v_{i}^{k+1} = w \cdot v_{i}^{k} + c_1 \cdot r_1 \cdot (pbest_i - pos_i^{k}) + c_2 \cdot r_2 \cdot (gbest - pos_i^{k}) vik+1=w⋅vik+c1⋅r1⋅(pbesti−posik)+c2⋅r2⋅(gbest−posik)
posik+1=posik+vik+1 pos_i^{k+1} = pos_i^{k} + v_{i}^{k+1} posik+1=posik+vik+1
其中:
- vikv_i^kvik:粒子 iii 在第 kkk 次迭代的速度
- posikpos_i^kposik:粒子 iii 的位置(即一组CNN-LSTM超参数)
- www:惯性权重,采用线性递减策略 w=wmax−kK(wmax−wmin)w = w_{\max} - \frac{k}{K} (w_{\max} - w_{\min})w=wmax−Kk(wmax−wmin)
- c1,c2c_1, c_2c1,c2:自我认知系数和社会认知系数(均取2.0)
- r1,r2r_1, r_2r1,r2:0,10,10,1 区间均匀随机数
- pbestpbestpbest:粒子历史最优位置
- gbestgbestgbest:全局历史最优位置
3.1.2 混沌映射初始化
本文实现了9种混沌映射用于种群初始化,供用户根据数据特性选择:
| 序号 | 映射名称 | 数学表达式 | 参数 |
|---|---|---|---|
| 1 | Tent映射 | xn+1={xn/μ,xn<μ(1−xn)/(1−μ),xn≥μx_{n+1} = \begin{cases} x_n / \mu, & x_n < \mu \\ (1-x_n)/(1-\mu), & x_n \geq \mu \end{cases}xn+1={xn/μ,(1−xn)/(1−μ),xn<μxn≥μ | μ=1.2\mu=1.2μ=1.2 |
| 2 | Chebyshev映射 | xn+1=cos(k⋅arccos(xn))x_{n+1} = \cos(k \cdot \arccos(x_n))xn+1=cos(k⋅arccos(xn)) | k=2k=2k=2 |
| 3 | Singer映射 | xn+1=μ(7.86xn−23.31xn2+28.75xn3−13.302875xn4)x_{n+1} = \mu(7.86x_n - 23.31x_n^2 + 28.75x_n^3 - 13.302875x_n^4)xn+1=μ(7.86xn−23.31xn2+28.75xn3−13.302875xn4) | μ=1\mu=1μ=1 |
| 4 | Logistic映射 | xn+1=μxn(1−xn)x_{n+1} = \mu x_n (1 - x_n)xn+1=μxn(1−xn) | μ=2\mu=2μ=2 |
| 5 | Sine映射 | xn+1=4asin(πxn)x_{n+1} = \frac{4}{a} \sin(\pi x_n)xn+1=a4sin(πxn) | a=2a=2a=2 |
| 6 | Circle映射 | xn+1=mod (xn+a−b2πsin(2πxn),1)x_{n+1} = \mod(x_n + a - \frac{b}{2\pi}\sin(2\pi x_n), 1)xn+1=mod(xn+a−2πbsin(2πxn),1) | a=0.5,b=0.6a=0.5,b=0.6a=0.5,b=0.6 |
| 7 | 立方映射 | xn+1=rxn(1−xn2)x_{n+1} = r x_n (1 - x_n^2)xn+1=rxn(1−xn2) | r=2r=2r=2 |
| 8 | Hénon映射 | {xn+1=1−axn2+ynyn+1=bxn\begin{cases} x_{n+1} = 1 - a x_n^2 + y_n \\ y_{n+1} = b x_n \end{cases}{xn+1=1−axn2+ynyn+1=bxn | a=1.4,b=0.3a=1.4,b=0.3a=1.4,b=0.3 |
| 9 | 广义Logistic映射 | xn+1=rxn(1−sxn2)x_{n+1} = r x_n (1 - s x_n^2)xn+1=rxn(1−sxn2) | r=2,s=0.9r=2,s=0.9r=2,s=0.9 |
初始化后,将混沌序列线性映射到搜索空间:
posi,j=(ubj−lbj)⋅chaosi,j+lbj pos_{i,j} = (ub_j - lb_j) \cdot chaos_{i,j} + lb_j posi,j=(ubj−lbj)⋅chaosi,j+lbj
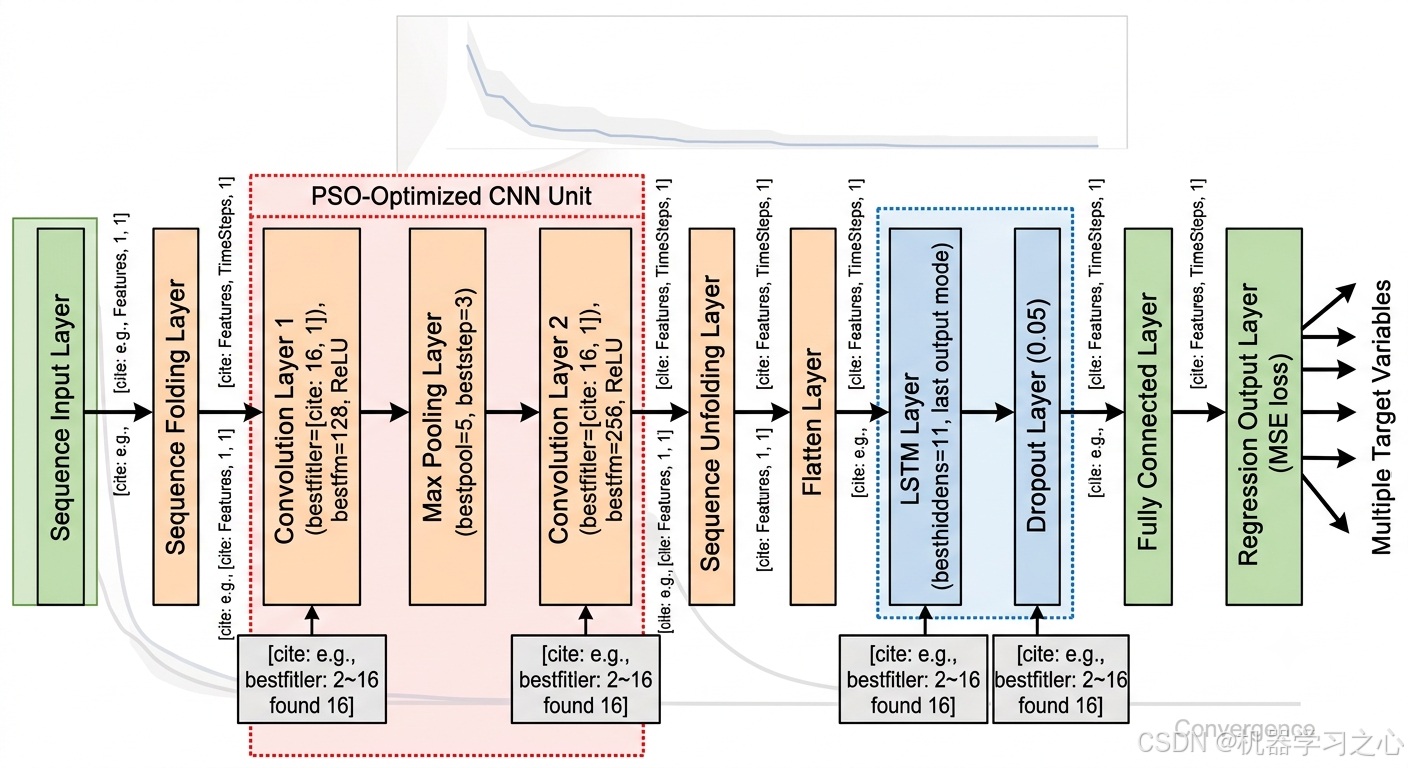
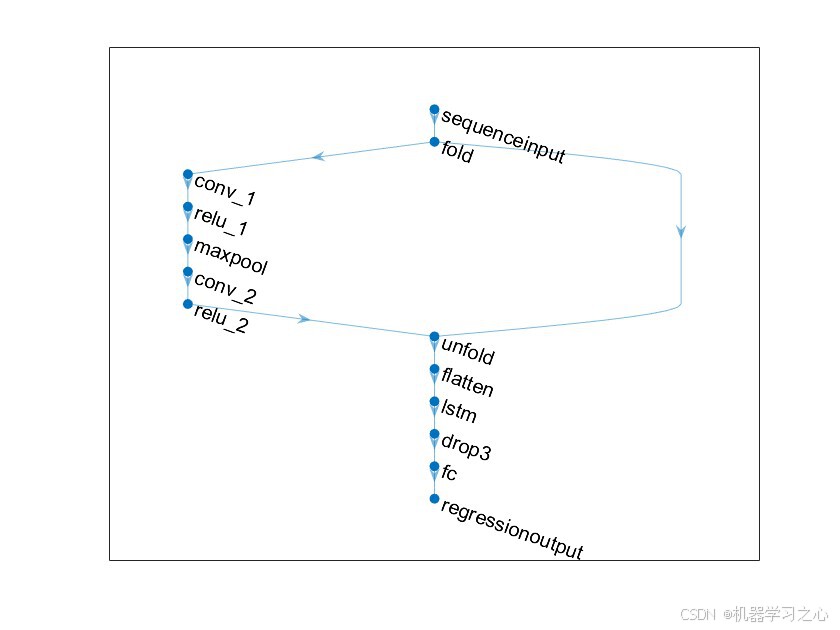
3.2 CNN-LSTM混合网络架构
CNN-LSTM混合模型充分利用了卷积神经网络(CNN)的局部特征提取能力 和长短期记忆网络(LSTM)的时序建模能力。网络结构如下:
3.2.1 网络层级结构
| 层级 | 类型 | 参数/说明 |
|---|---|---|
| 1 | 序列输入层 | 输入维度:[特征数, 1, 1] |
| 2 | 序列折叠层 | sequenceFoldingLayer,将序列结构适配为图像结构 |
| 3 | 卷积层1 | 卷积核 [bestfitler, 1],特征图 bestfm,Padding=same |
| 4 | ReLU激活 | 引入非线性 |
| 5 | 最大池化层 | 池化窗口 [bestpool, 1],步长 [beststep, 1] |
| 6 | 卷积层2 | 卷积核 [bestfitler, 1],特征图 bestfm × 2,Padding=same |
| 7 | ReLU激活 | 引入非线性 |
| 8 | 序列展开层 | sequenceUnfoldingLayer |
| 9 | 展平层 | flattenLayer |
| 10 | LSTM层 | 神经元数 besthiddens,输出模式 last |
| 11 | Dropout层 | 丢失率 0.05,防止过拟合 |
| 12 | 全连接层 | 输出维度 = 目标变量数 |
| 13 | 回归输出层 | regressionLayer,MSE损失 |
3.2.2 关键设计说明
- 序列折叠/展开机制 :
sequenceFoldingLayer和sequenceUnfoldingLayer成对使用,将一维序列数据转换为二维图像格式(适应CNN卷积操作),处理完毕后再还原为序列结构。 - 一维卷积思想 :卷积核尺寸设为
[k, 1],即仅在特征维度方向滑动,相当于对每个时间步的特征向量进行局部加权组合。 - 特征图倍增策略 :第二个卷积层的特征图数量是第一层的2倍(
bestfm → bestfm×2),遵循深度学习中"通道数逐层递增"的经典设计模式。
3.3 SHAP特征贡献分析
SHAP(SHapley Additive exPlanations)源自合作博弈论中的Shapley值概念,用于公平分配每个特征对预测结果的贡献。
3.3.1 Shapley值核心公式
对于特征 jjj,其Shapley值 ϕj\phi_jϕj 定义为:
ϕj(f)=∑S⊆M∖{j}∣S∣!⋅(∣M∣−∣S∣−1)!∣M∣!f(S∪{j})−f(S) \phi_j(f) = \sum_{S \subseteq M \setminus \{j\}} \frac{|S|! \cdot (|M| - |S| - 1)!}{|M|!} \left f(S \\cup \\{j\\}) - f(S) \\right ϕj(f)=S⊆M∖{j}∑∣M∣!∣S∣!⋅(∣M∣−∣S∣−1)!f(S∪{j})−f(S)
其中:
- MMM:所有特征的集合,∣M∣|M|∣M∣ 为特征总数
- SSS:不包含特征 jjj 的任意特征子集
- f(S)f(S)f(S):仅用特征子集 SSS 时模型的预测值(缺失特征用全局均值填充)
- f(S∪{j})−f(S)f(S \cup \{j\}) - f(S)f(S∪{j})−f(S):特征 jjj 加入后的边际贡献
3.3.2 SHAP四大公理化性质
SHAP值是唯一同时满足以下四大性质的归因方法:
-
对称性(Symmetry):若两个特征对所有子集的边际贡献相同,则它们的SHAP值相等。
-
有效性(Efficiency):所有特征的SHAP值之和等于模型预测值与基准预测值之差:
∑j=1Mϕj=f(x)−Ef(x) \sum_{j=1}^{M} \phi_j = f(x) - \mathbb{E}f(x) j=1∑Mϕj=f(x)−Ef(x)
-
线性性(Linearity):若模型是多个子模型的线性组合,则SHAP值亦满足线性可加性。
-
零贡献性(Dummy):若某特征从不改变预测值,则其SHAP值为0。
3.3.3 精确计算实现
本方案采用**遍历幂集(power set)**的精确计算方法,计算复杂度为 O(2M)O(2^M)O(2M)。对于特征数较少(如本文的5个特征,共 25=322^5 = 3225=32 种组合)的场景,精确计算完全可行。
3.4 精度评价指标
采用三个经典回归评价指标:
均方根误差(RMSE):
RMSE=1n∑i=1n(yi−y^i)2RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2}RMSE=n1i=1∑n(yi−y^i)2
决定系数(R²):
R2=1−∑i=1n(yi−y^i)2∑i=1n(yi−yˉ)2R^2 = 1 - \frac{\sum_{i=1}^{n}(y_i - \hat{y}i)^2}{\sum{i=1}^{n}(y_i - \bar{y})^2}R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2
平均绝对误差(MAE):
MAE=1n∑i=1n∣yi−y^i∣MAE = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i|MAE=n1i=1∑n∣yi−y^i∣
四、关键参数设定
4.1 PSO优化器参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 种群规模 NNN | 5 | 粒子数量 |
| 最大迭代次数 | 10 | 寻优终止条件 |
| 惯性权重 wmaxw_{\max}wmax | 0.9 | 初始惯性权重(偏重全局搜索) |
| 惯性权重 wminw_{\min}wmin | 0.6 | 最终惯性权重(偏重局部搜索) |
| 自我认知系数 c1c_1c1 | 2.0 | 个体经验权重 |
| 社会认知系数 c2c_2c2 | 2.0 | 群体经验权重 |
| 速度范围 | 2,62, 62,6 | 限制粒子单步移动幅度 |
| 混沌映射类型 | Tent映射(label=1) | 可切换为其他8种 |
4.2 超参数搜索空间
| 超参数 | 符号 | 下限 | 上限 | 类型 | 最优值 |
|---|---|---|---|---|---|
| 卷积核尺寸 | bestfitler |
2 | 16 | 整数 | 16 |
| 特征图指数 | bestfm_idx |
3 | 7 | 整数 → 2n2^n2n | 7 → 128 |
| 池化窗口大小 | bestpool |
2 | 5 | 整数 | 5 |
| 池化步长 | beststep |
1 | 3 | 整数 | 3 |
| LSTM神经元数 | besthiddens |
2 | 16 | 整数 | 11 |
4.3 CNN-LSTM训练参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 优化器 | Adam | 自适应矩估计 |
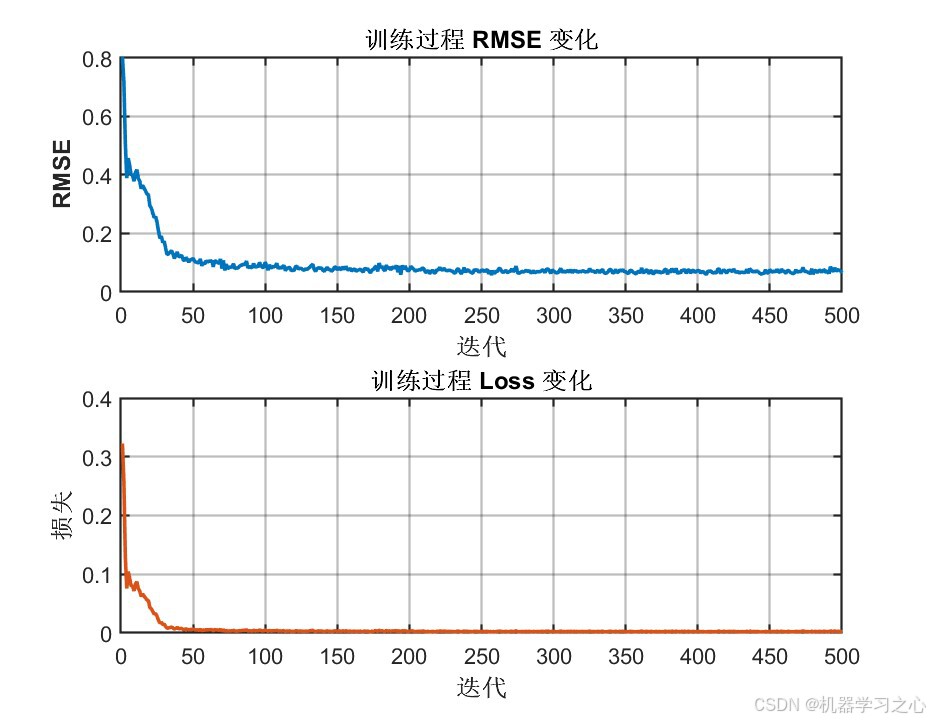
| 最大训练轮数 | 500 | 充分训练 |
| 初始学习率 | 0.01 | η0\eta_0η0 |
| 学习率调度策略 | Piecewise(分段衰减) | 每200轮 × 0.1 |
| 学习率衰减因子 | 0.1 | η←η×0.1\eta \leftarrow \eta \times 0.1η←η×0.1 |
| Dropout率 | 0.05 | 轻量正则化 |
| 数据打乱 | 每轮打乱 | 防止顺序依赖 |
| 执行环境 | CPU | 通用兼容 |
| 训练/测试比例 | 80% : 20% | 标准划分 |
4.4 数据预处理
- 归一化方法 :Min-Max归一化,映射到 0,10, 10,1 区间
- 输入特征数:5个(x1 ~ x5)
- 输出目标数:2个(多输出回归)
- 样本划分:可选随机打乱或保持原序
五、运行环境
| 环境项 | 版本/说明 |
|---|---|
| 编程语言 | MATLAB |
| 核心工具箱 | Deep Learning Toolbox |
| 必需函数 | trainNetwork, predict, convolution2dLayer, lstmLayer, trainingOptions |
| 推荐MATLAB版本 | R2019b 及以上 |
| 运行方式 | 运行 main.m 即可一键执行全流程 |
| 硬件要求 | CPU即可运行;GPU可加速训练 |
六、实验结果与分析
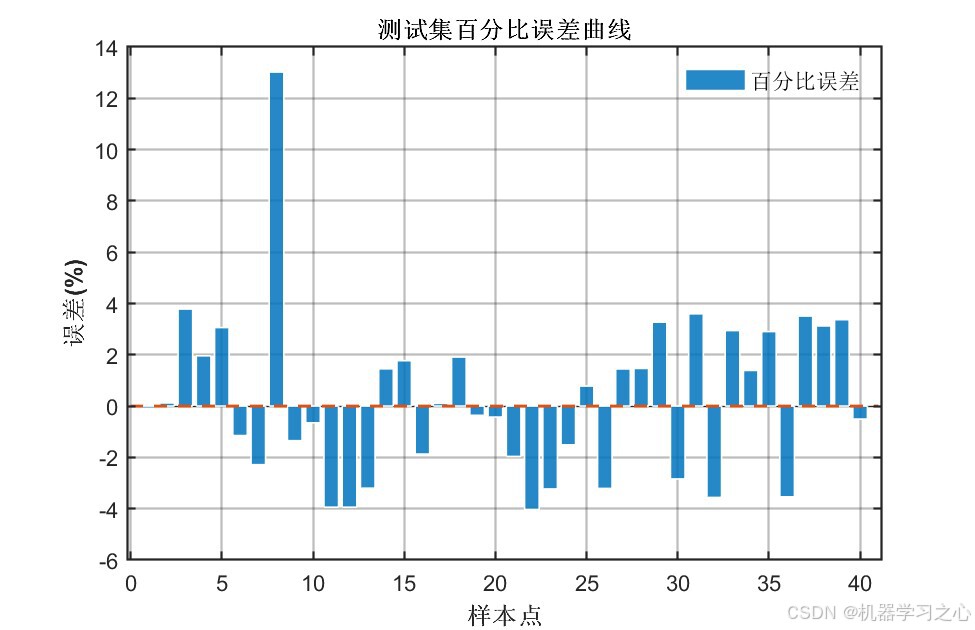
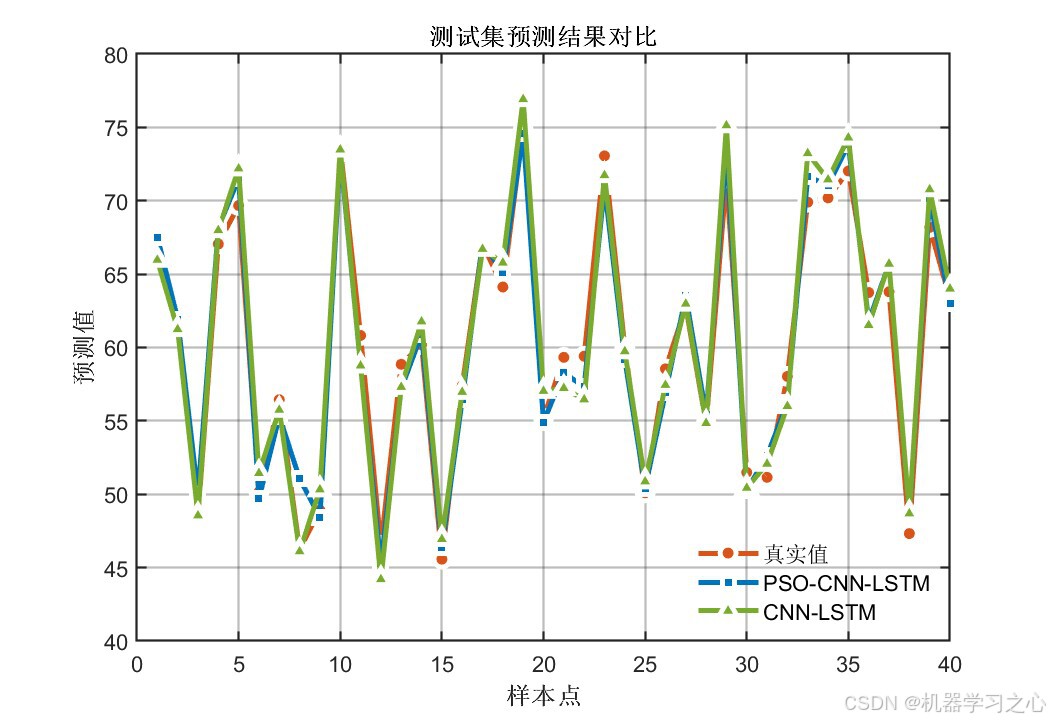
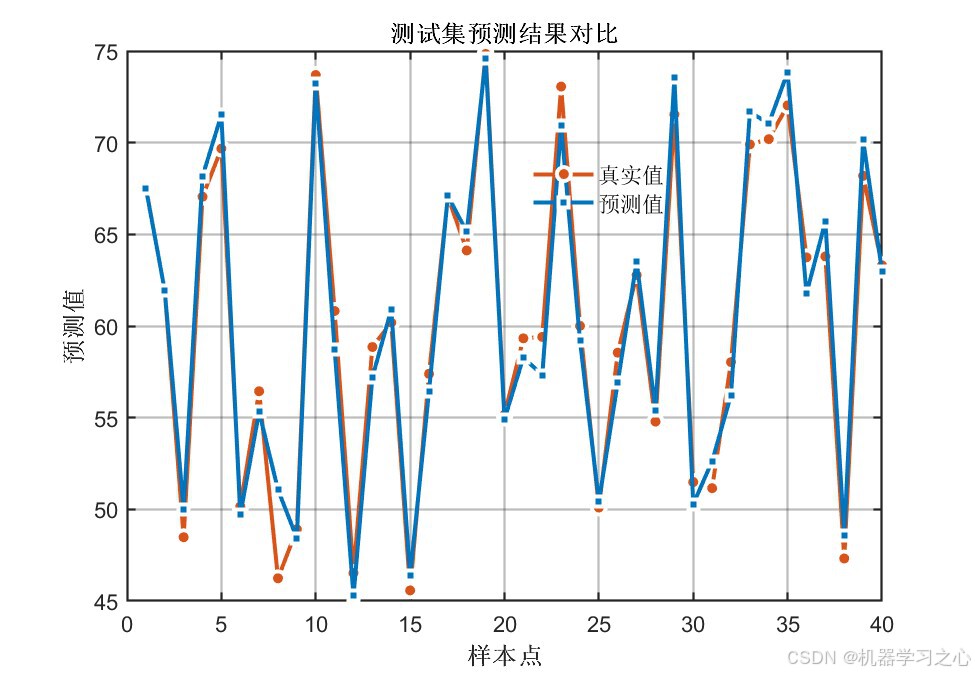
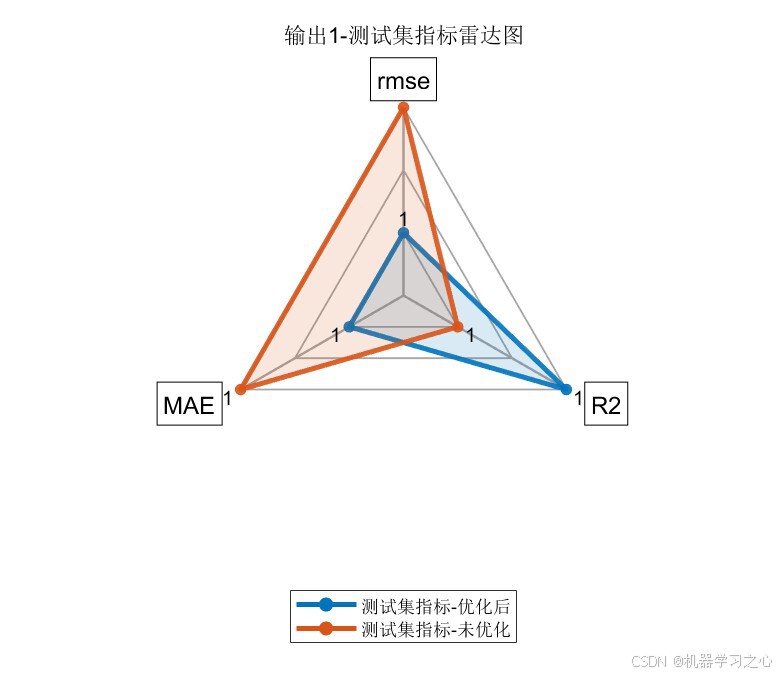
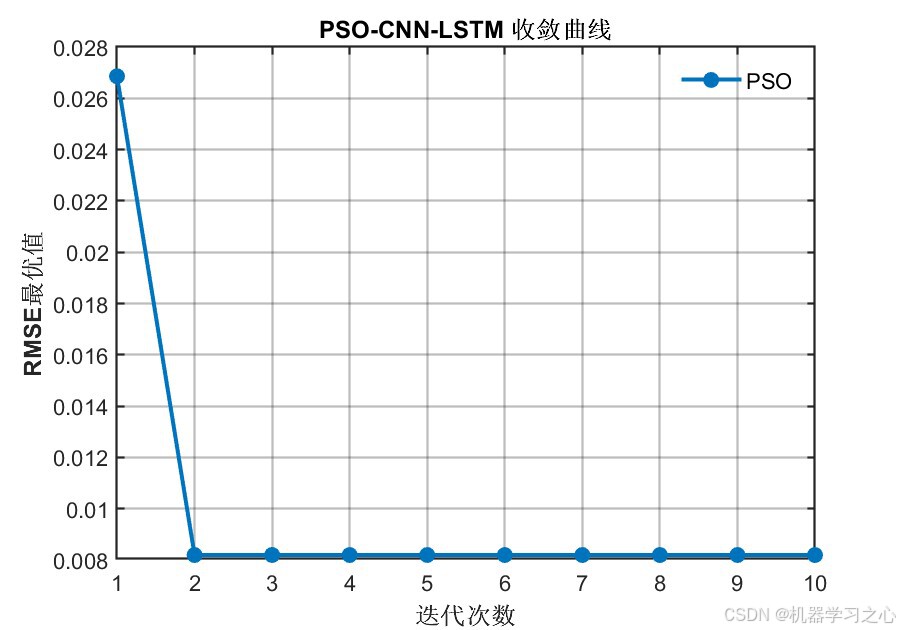
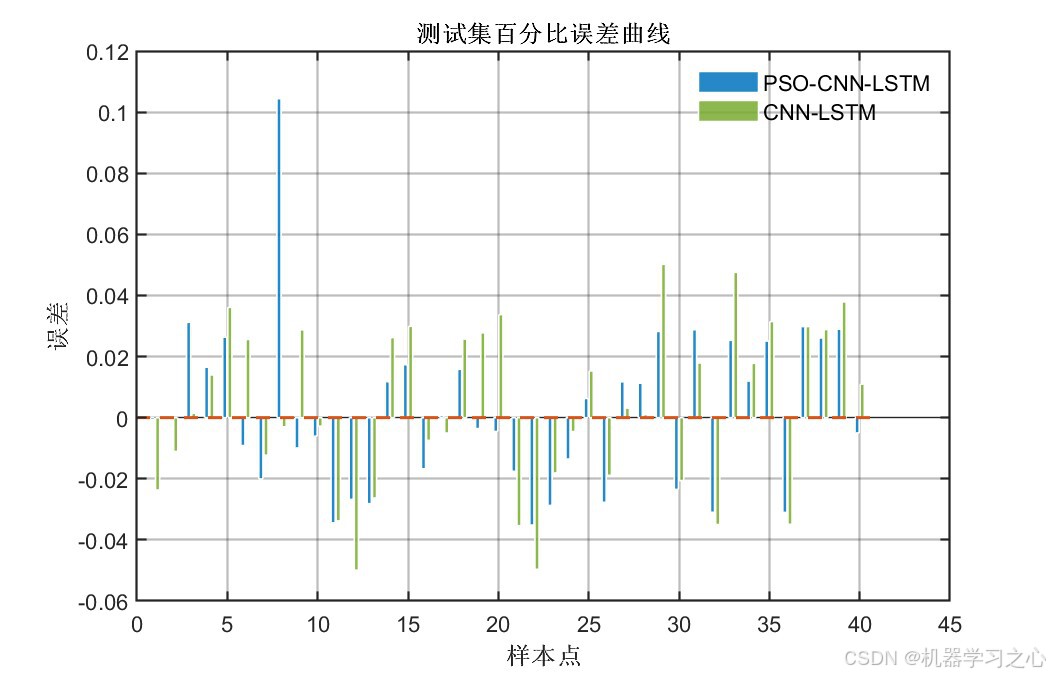
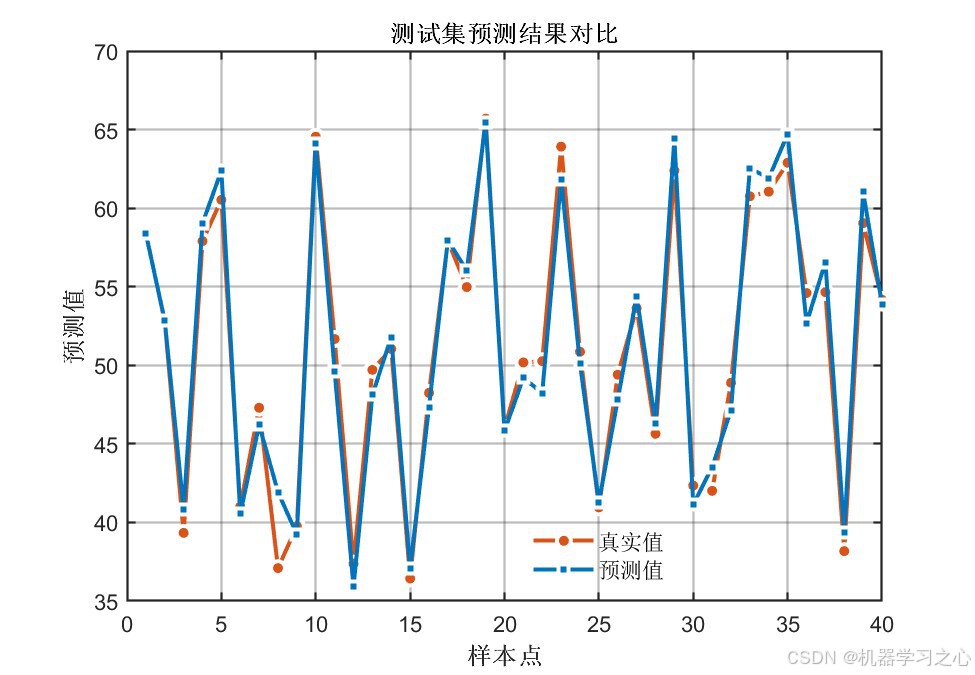
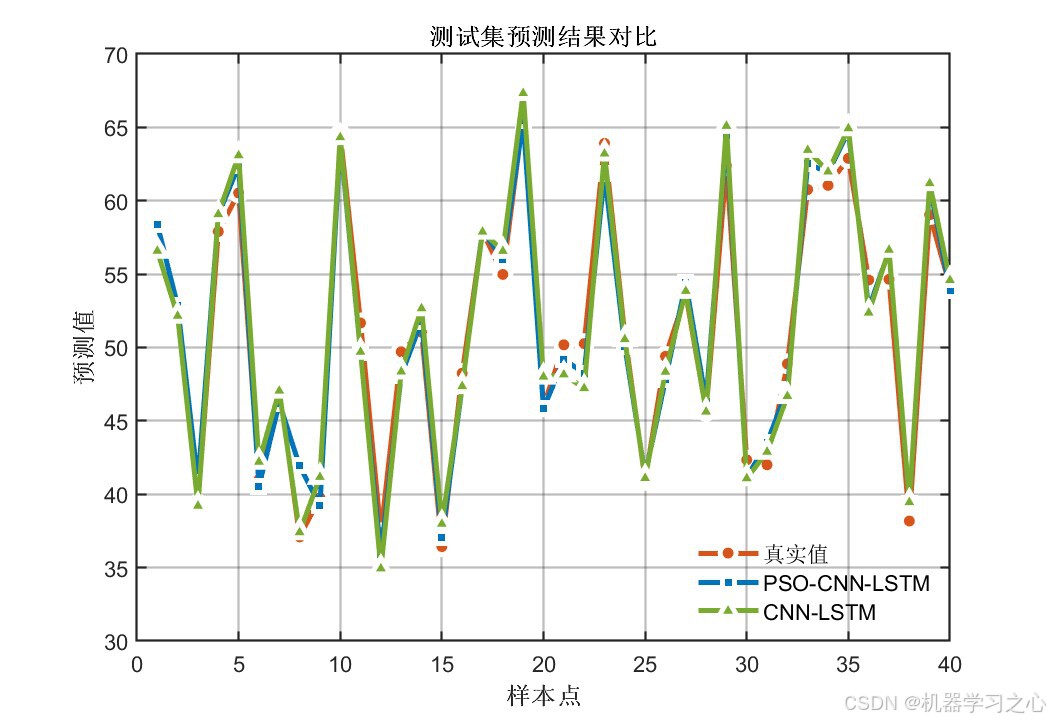
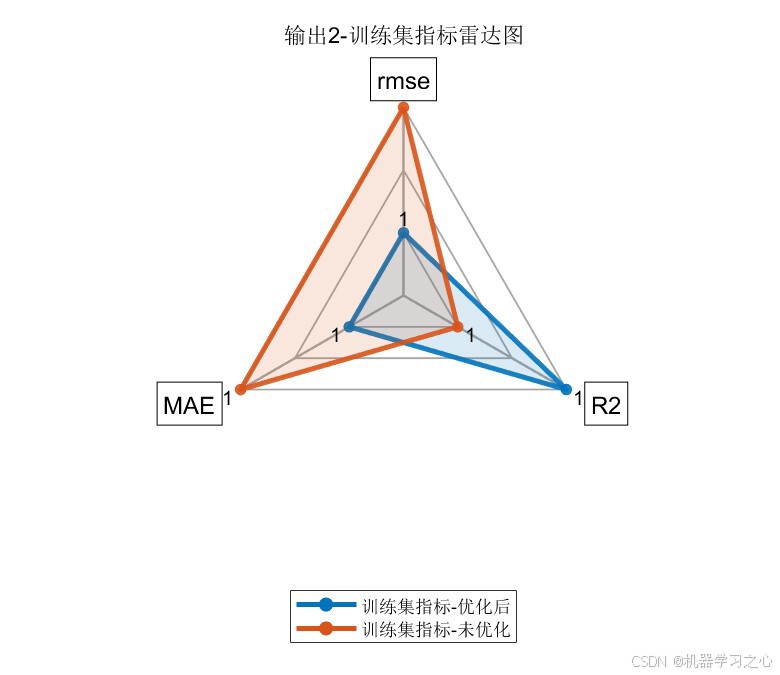
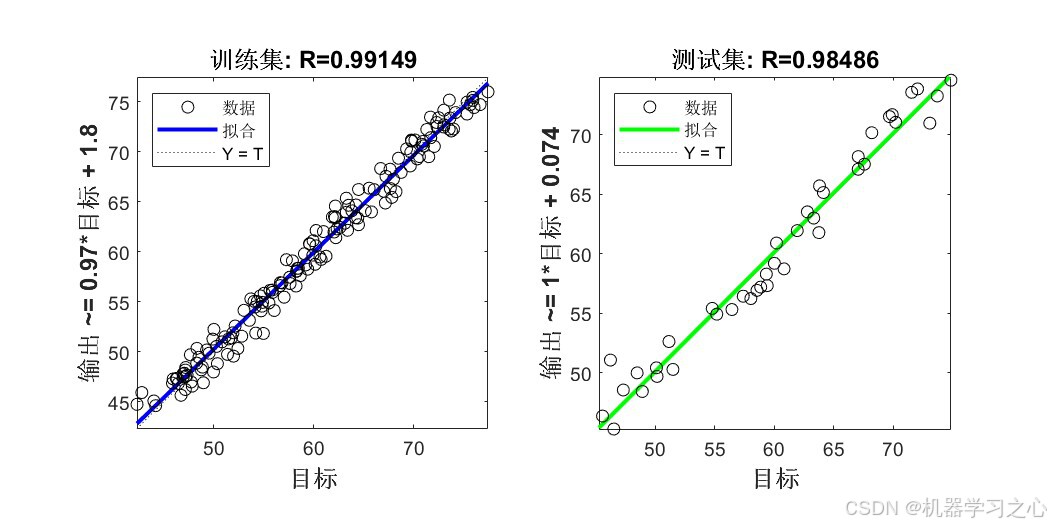
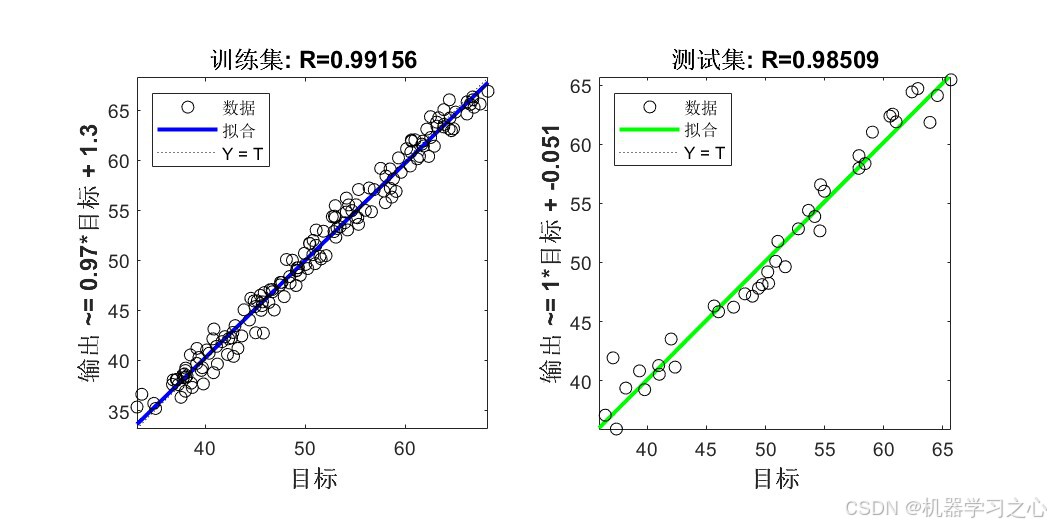
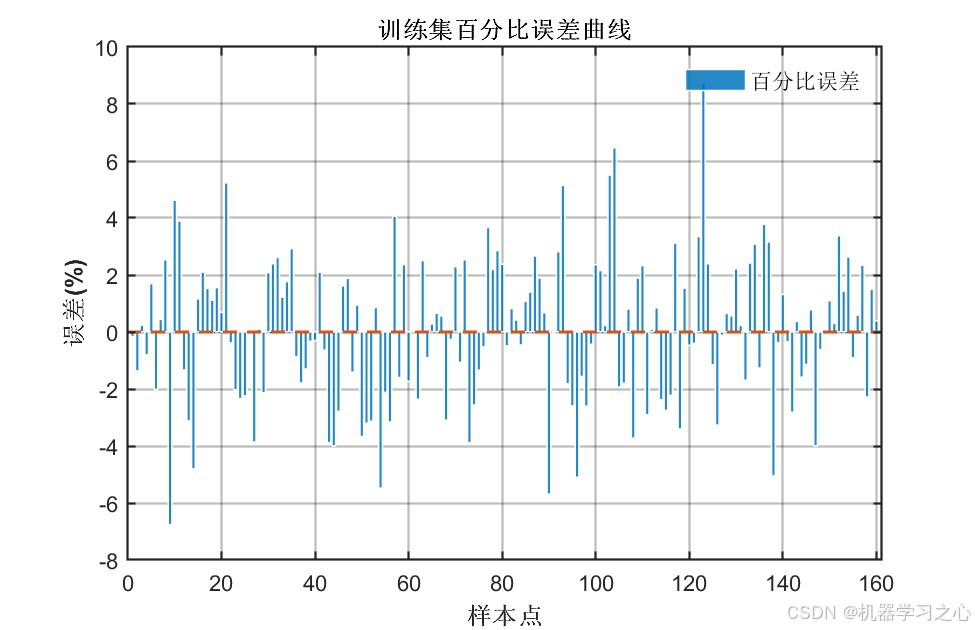
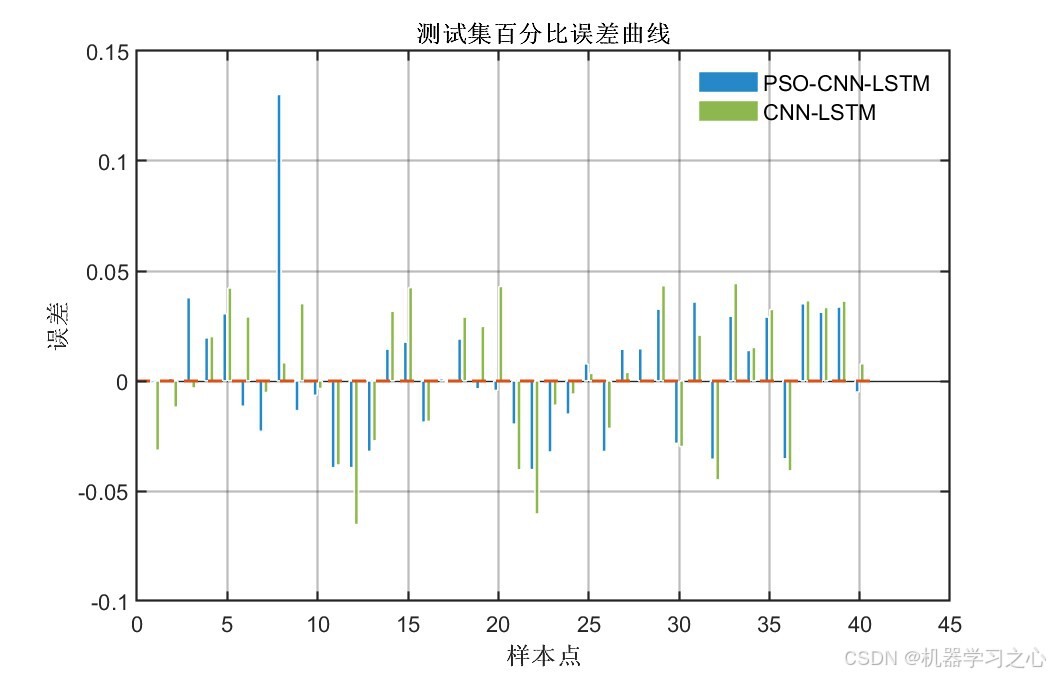
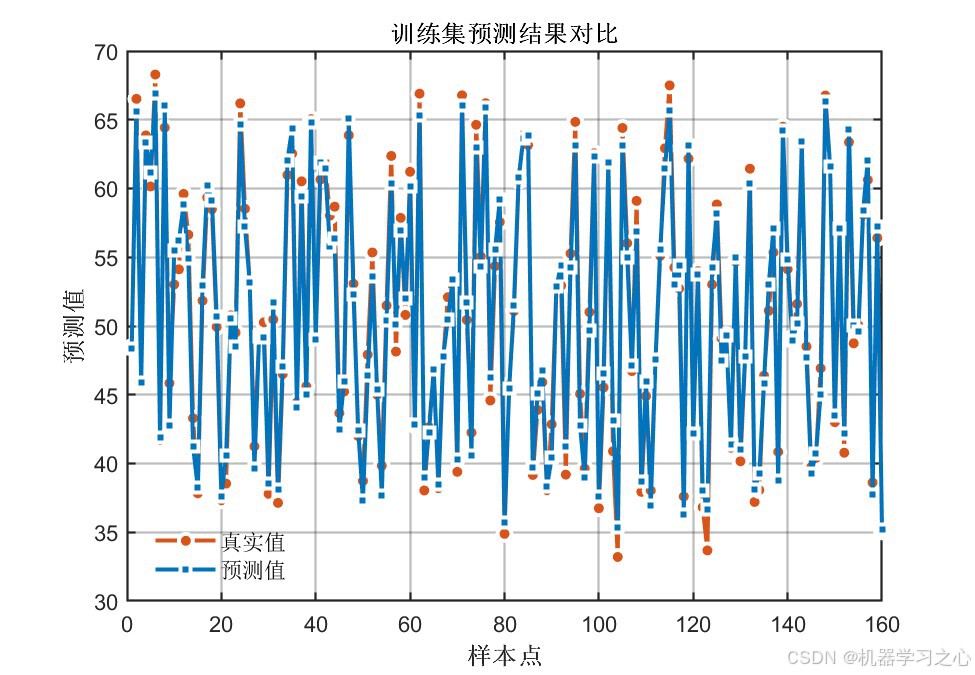
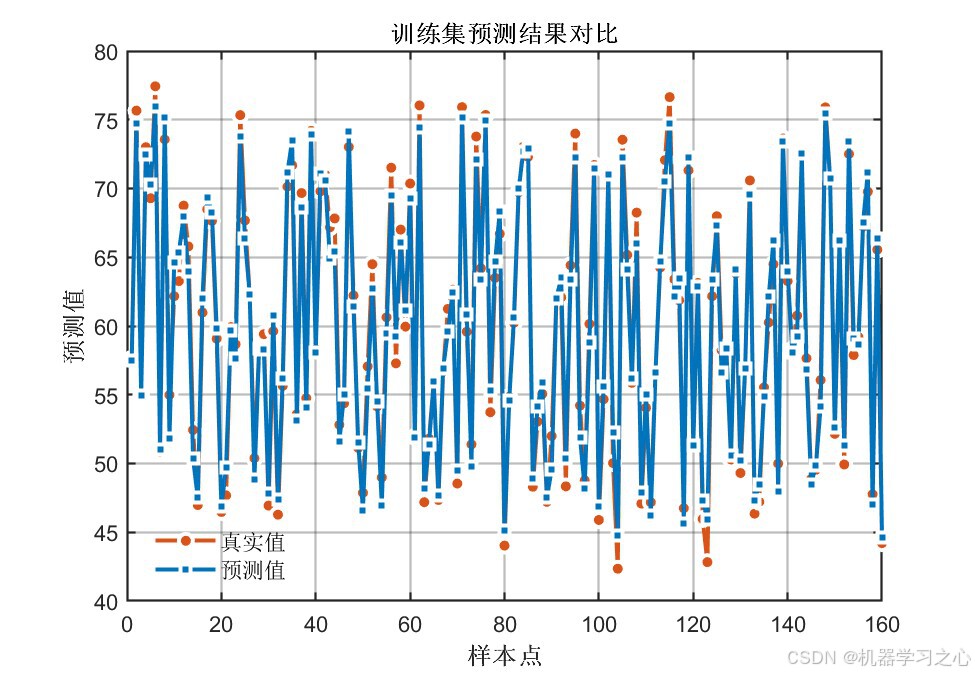
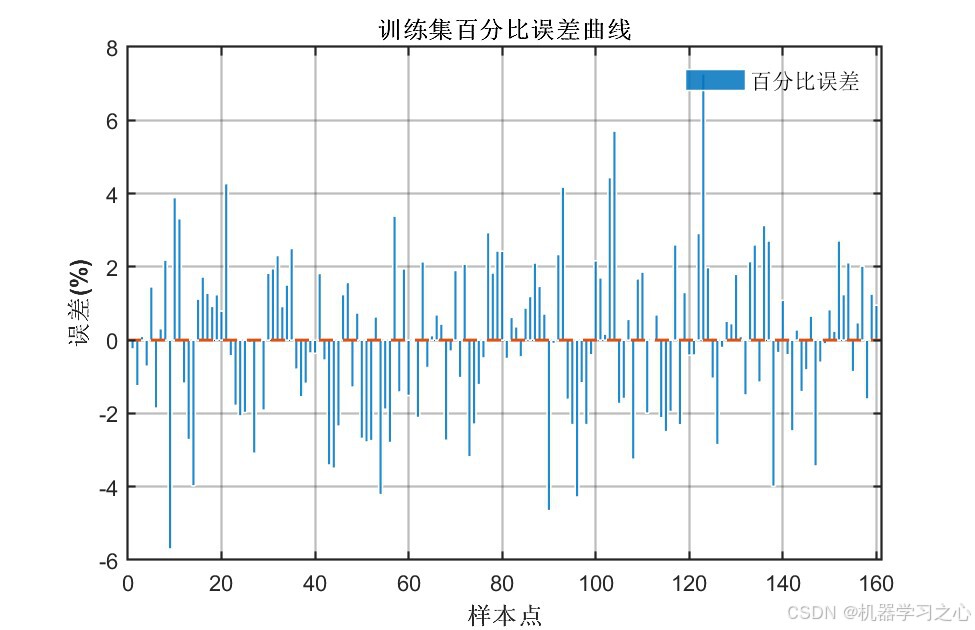
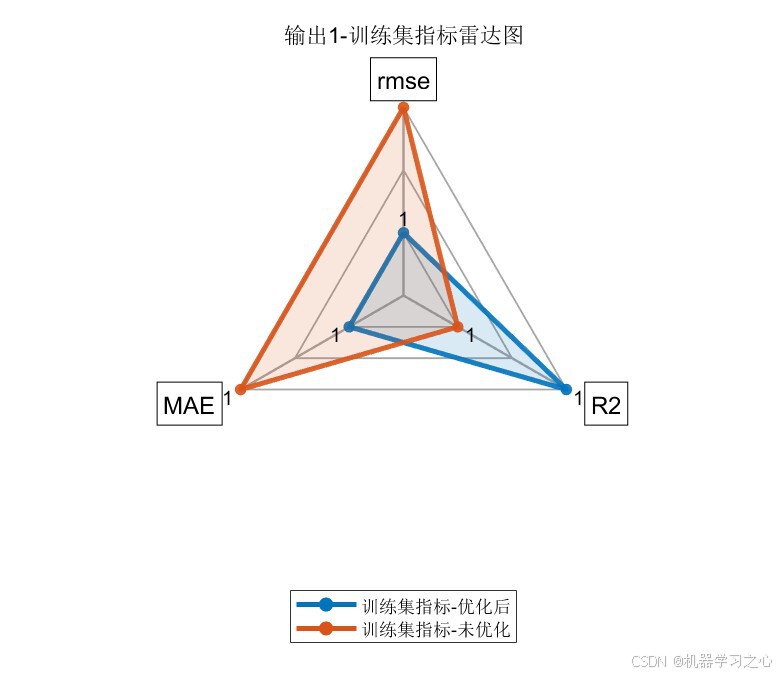
6.1 模型精度对比
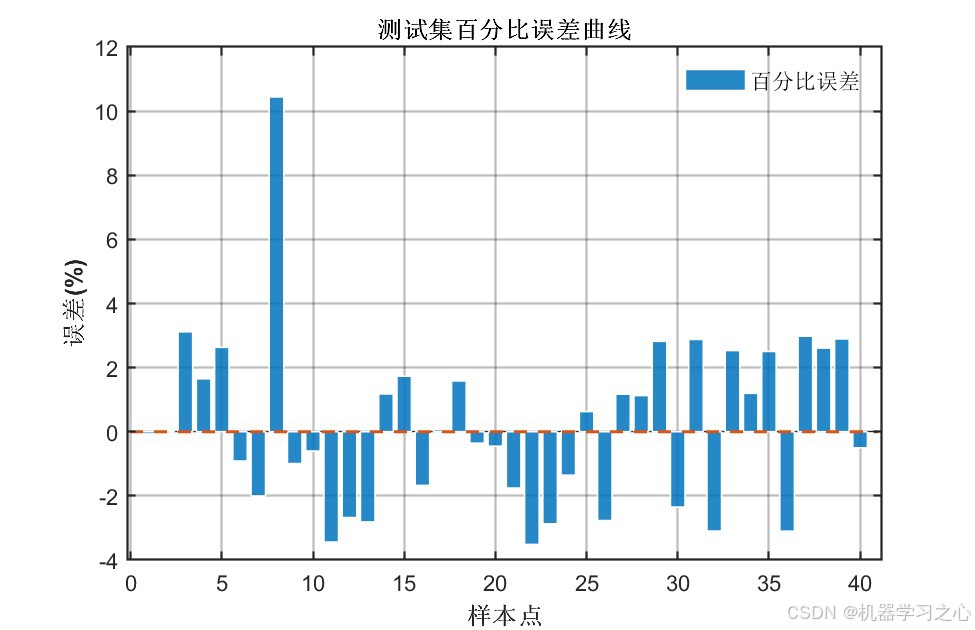
PSO优化后的CNN-LSTM在全部评价指标上均显著优于未优化的基准CNN-LSTM模型:
输出指标1:
| 指标 | 训练集(优化后) | 训练集(未优化) | 测试集(优化后) | 测试集(未优化) |
|---|---|---|---|---|
| RMSE | 1.2141 | 1.3053 | 1.4938 | 1.6783 |
| R² | 0.9829 | 0.9802 | 0.9688 | 0.9606 |
| MAE | 1.0037 | 1.0556 | 1.2138 | 1.4182 |
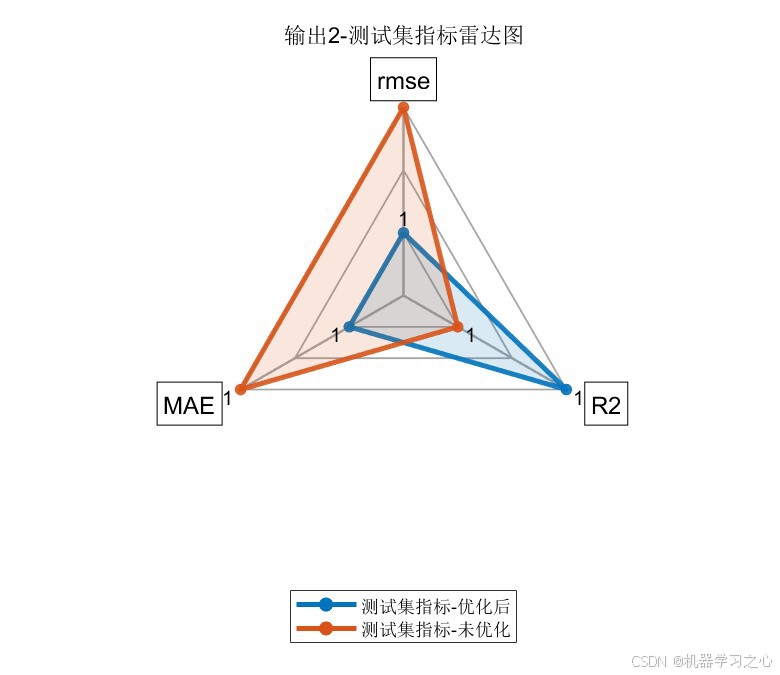
输出指标2:
| 指标 | 训练集(优化后) | 训练集(未优化) | 测试集(优化后) | 测试集(未优化) |
|---|---|---|---|---|
| RMSE | 1.2057 | 1.3196 | 1.4883 | 1.5753 |
| R² | 0.9831 | 0.9797 | 0.9690 | 0.9653 |
| MAE | 0.9941 | 1.0745 | 1.2081 | 1.3266 |
核心结论 :PSO将卷积核从默认的2扩增至16,特征图从8提升至128,LSTM神经元从7调整至11------显著增强了模型的表达能力,两个输出的测试集R²均达到 0.96以上。
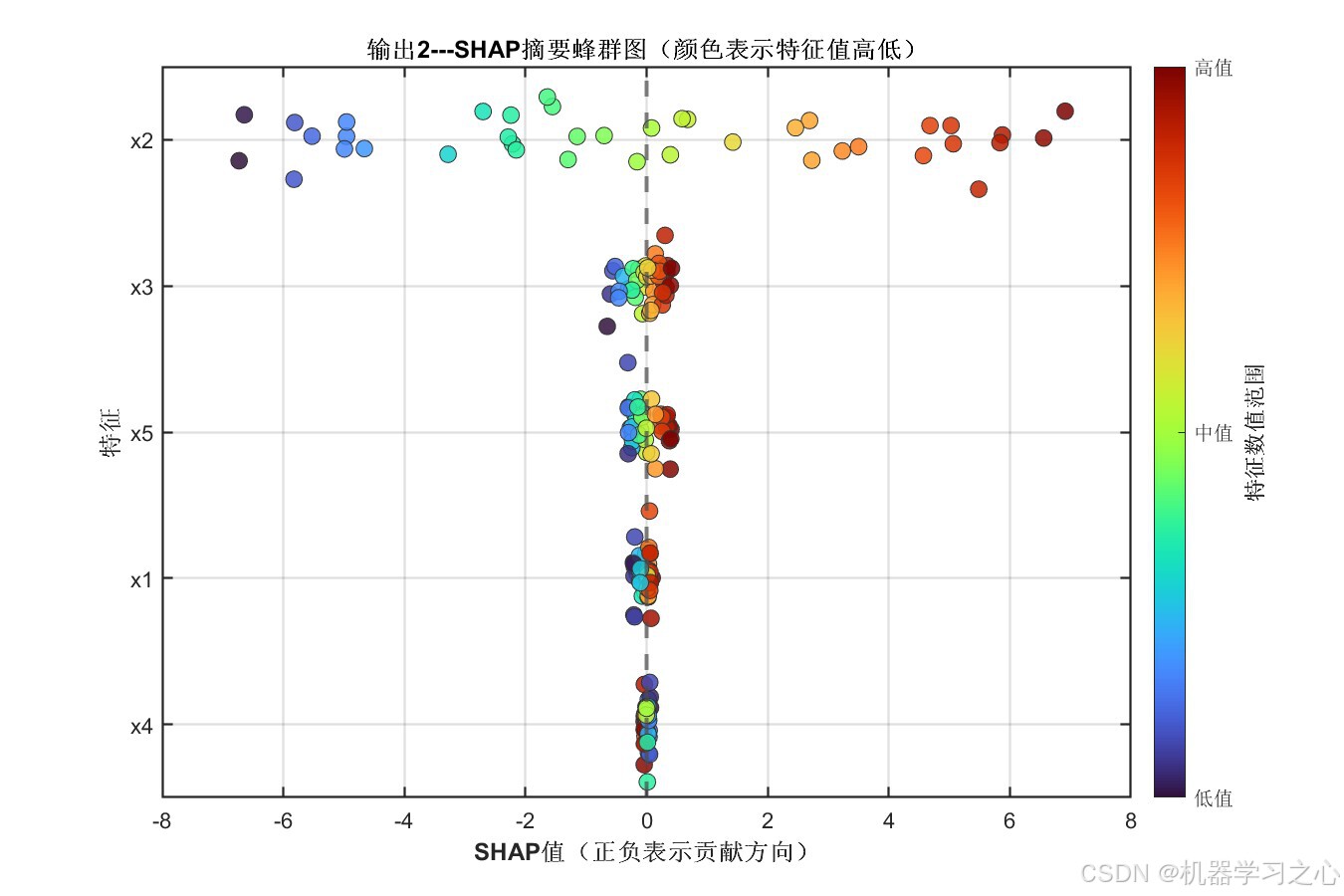
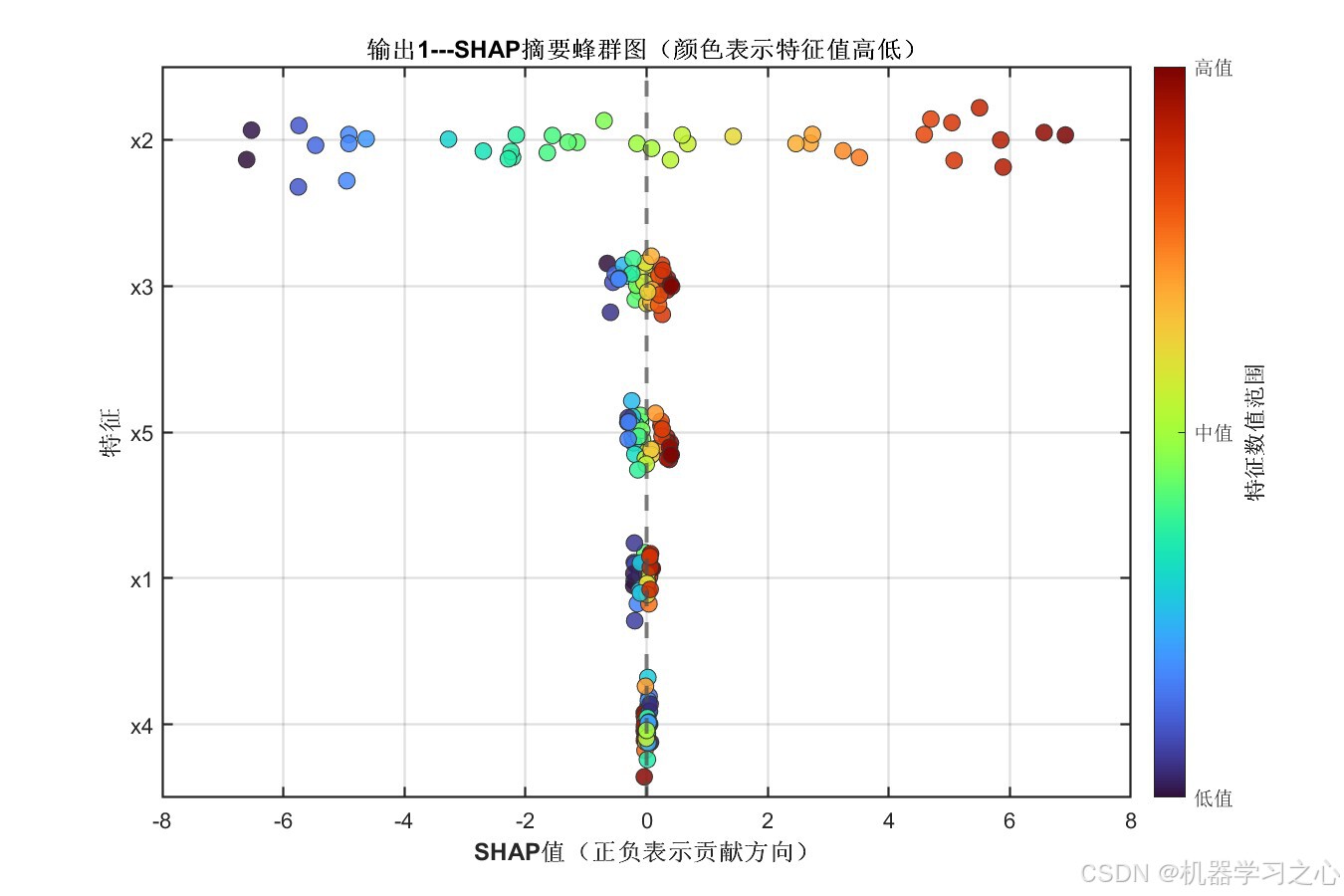
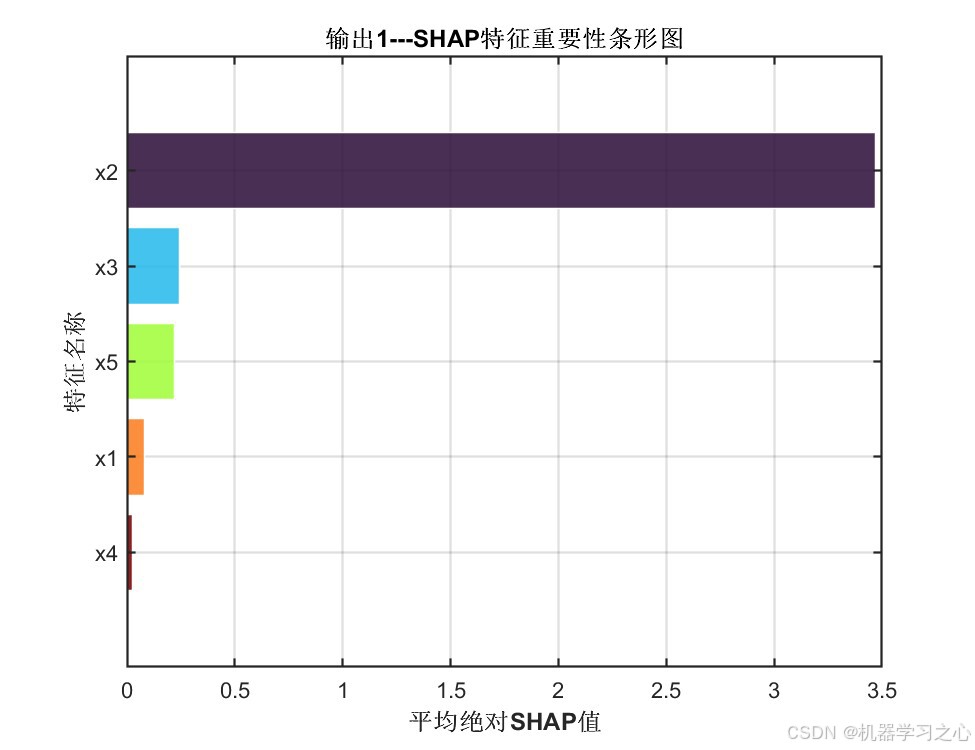
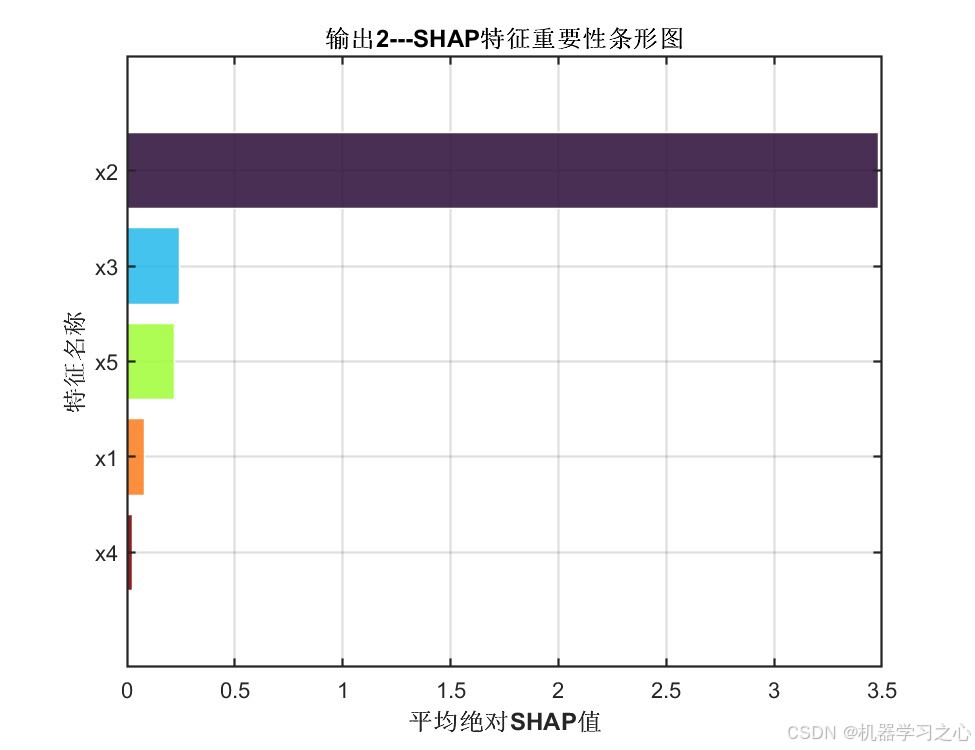
6.2 SHAP特征重要性分析
平均绝对SHAP值揭示了各特征对模型预测的贡献程度:
| 特征 | 输出1---平均|SHAP| | 输出2---平均|SHAP| |
|---|---|---|
| x1 | 0.0810 | 0.0814 |
| x2 | 3.4710 ⬆ | 3.4817 ⬆ |
| x3 | 0.2448 | 0.2443 |
| x4 | 0.0266 | 0.0271 |
| x5 | 0.2224 | 0.2213 |
关键发现 :特征 x2 是绝对主导变量,其SHAP值(~3.48)远超其他特征,说明它是两个输出目标的核心驱动因子;x3 和 x5 有中等贡献;x1 和 x4 的贡献较小。该分析结果为实际工程中的变量筛选、降维与工艺优化提供了量化依据。
6.3 输出图表清单
本方案自动生成以下可视化成果(共20+张图):
| 图类 | 内容 | 数量 |
|---|---|---|
| PSO收敛曲线 | 迭代过程中RMSE最优值变化 | 1张 |
| 网络结构图 | CNN-LSTM层级拓扑可视化 | 1张 |
| 雷达图 | 优化前后RMSE/R²/MAE对比 | 4张(2输出 × 2集) |
| 训练/测试预测对比曲线 | 真实值 vs 预测值逐样本对比 | 4张 |
| 百分比误差柱状图 | 逐样本百分比误差分布 | 4张 |
| 回归拟合图 | MATLAB plotregression 四象限图 |
2张 |
| 优化 vs 未优化对比 | 双模型测试集预测效果叠加 | 2张 |
| 训练过程监控 | RMSE/Loss随迭代变化曲线 | 1张 |
| SHAP蜂群图 | 特征贡献分布与方向可视化 | 2张 |
| SHAP条形图 | 全局特征重要性排名 | 2张 |
七、应用场景
本方案适用于以下典型场景:
7.1 工业过程建模与软测量
- 化工过程:根据温度、压力、流量等过程变量预测产物浓度、转化率等多个质量指标
- 制药工程:基于原料配比和工艺参数预测药品的多个关键质量属性(CQAs)
- 冶金/材料:根据成分与工艺参数预测材料的多个力学性能指标
7.2 环境与能源预测
- 空气质量:基于多维气象和排放数据预测多种污染物浓度(PM2.5, PM10, O₃, NO₂等)
- 电力负荷:根据历史负荷、气温、节假日等因素预测多个区域的电力需求
- 水质监测:基于传感器数据预测多个水质指标(COD, NH₃-N, DO等)
7.3 金融与经济
- 多资产价格预测:基于宏观经济指标预测多个金融资产收益率
- 风险管理:基于多维风控特征预测多个风险评分维度
7.4 生物医学
- 多指标诊断:基于多项检验数据预测多个疾病风险指标
- 药物响应:基于基因表达数据预测药物对多个靶点的响应效果
八、代码文件结构与调用说明
PSO-CNN-LSTM回归+特征贡献SHAP分析+多输出+新数据预测/
├── main.m # 主文件,一键运行全流程
├── PSO.m # 混沌初始化+PSO优化算法
├── fit.m # PSO适应度函数(训练CNN-LSTM并返回RMSE)
├── yuan.m # 未优化的CNN-LSTM基准模型
├── zhibiao.m # 精度评价指标计算(RMSE/R²/MAE)
├── shapley_function.m # SHAP值精确计算+蜂群图/条形图绘制
├── ys.m # 9种混沌映射初始化函数
├── newpre.m # 新数据前向预测函数
├── 回归数据.xlsx # 训练数据(前列输入,后列输出)
├── 新的多输入.xlsx # 待预测新样本的输入数据
├── 新的输出.xlsx # 新数据预测结果输出
├── 第1个输出指标.xlsx # 输出1的优化vs未优化精度表
├── 第2个输出指标.xlsx # 输出2的优化vs未优化精度表
└── spider_plot/ # 雷达图绘制工具包一键运行方式 :在MATLAB中打开 main.m,按 F5 运行即可。
九、总结与亮点
-
端到端自动化 :从数据预处理、超参数寻优、模型训练、精度评估、可解释分析到新数据预测,全流程一键执行,极大降低使用门槛。
-
混沌PSO超参优化 :内置9种混沌映射初始化策略,有效改善标准PSO的早熟收敛问题;相比手动试错调参,自动寻优使测试集R²提升约 0.8%~1% ,RMSE降低约 6%~11%。
-
完整可解释性:精确SHAP值计算结合蜂群图和条形图双重视觉化,清晰揭示每个特征的贡献方向和大小,满足高风险场景的模型审计需求。
-
多输出灵活扩展:代码架构支持任意数量输入和任意数量输出,修改Excel数据即可适配新任务,无需改动核心逻辑。
-
工程实用性 :包含新数据预测模块(
newpre.m),训练完成后直接调用即可产出预测结果并导出为Excel,适合生产环境部署。