一,Redis 持久化的好处
1.1 减少业务数据的丢失
Redis 在运行过程中所有的数据都处于内存之中,这也是读写性能高效的原因之一。但也带来一个致命的问题就是数据易丢失。一旦Redis 进程重启,或者电脑断电,服务器宕机内存里面的数据将全部丢失。并且无法做冷备份和故障回溯,Redis提供数据持久化的给业务数据上一层保险以此来减少数据的丢失。
一开始 Redis 的持久化不是一开始就完美的,它经历了三个重要阶段的演进
- RDB(Redis DataBase 快照)时代 :从 Redis 诞生之初(0.08 版本,2009年)就有了。这是最古老的持久化方式。
- AOF(Append Only File 追加文件)时代 :到了 1.1 版本(2010年),因为 RDB 可能会丢失最后一次快照后的数据,官方引入了 AOF,记录每一次写操作。
- 混合持久化时代(RDB + AOF) :到了 4.0 版本(2017年),官方发现 AOF 文件太大了恢复太慢,于是把 RDB 和 AOF 结合起来,诞生了"混合持久化"。
redis 默认采用的持久化方案取决于你使用的版本:
Redis 4.0 之前 :默认只开启 RDB。
Redis 4.0 到 6.x :默认同时开启 RDB 和 AOF (AOF 默认每秒刷盘一次 everysec)
Redis 至今(包括 7.x / 8.x) 默认只开启 RDB 持久化,AOF 默认关闭;混合持久化开关虽然默认 yes,但只有在 AOF 开启时才会生效。
1.2 向数据库能力扩展
如果 Redis 没有良好的持久化支撑,那么 Redis 的功能定位只能停留在:Cache(缓存),临时存储。但是有了持久化 Redis 可以承担轻量数据库,状态存储,分布式协调数据(锁,队列)。这也是为什么会有很多系统会用 Redis 替换部分数据库场景
1.3 满足不同场景的数据安全需求
不同业务对数据丢失的容忍度不同,持久化两种策略让用户权衡:
|------|-----------------------|---------------------|
| 特性 | RDB(快照) | AOF(追加日志) |
| 工作原理 | 某个时间点生成全量数据快照 | 记录每个写操作命令,类似日志 |
| 丢失风险 | 可能丢失上次快照后的数据(如每5分钟一次) | 最多丢失1秒或1条命令(根据配置) |
| 文件大小 | 较小,压缩后的二进制文件 | 较大,但支持 rewrite 重写压缩 |
| 恢复速度 | 快,直接加载 | 慢,需重放所有命令 |
缓存场景:可容忍少量数据丢失 → 只用 RDB 或不持久化,追求高性能。
支付/计数场景 :要求几乎零丢失 → 配合 AOF(appendfsync always)或 AOF+RDB 混合模式
二,RDB 持久化
RDB 是 Redis 快照持久化 :在指定时间节点,将内存中全量数据以二进制压缩文件 (默认 dump.rdb)落地磁盘。 在学习 RDB 持久化之前,首先我们要知道当前 redis 采用的是那种持久化方案。判断依据是什么?如果不是 RDB 我们需求给切换到 RDB 的持久化方案进行学习与讲解
2.1 查看当前 redis 持久化方案
【判断 RDB 是否开启】
cpp
CONFIG GET save
# 返回 ""(空字符串):RDB 自动持久化关闭
# 返回类似 900 1、300 10、60 10000 等配置:RDB 自动持久化开启【判断 AOF 是否开启】
cpp
CONFIG GET appendonly
# 返回 appendonly "no":AOF 关闭(Redis 默认状态)
# 返回 appendonly "yes":AOF 开启【混合判断结论】
在了解混合判断之前,我们需要理解混合的工作原理,不然对于是否开启了混合持久化会有所误解。首先需要了解的是 Redis 的混合持久化并不是独立的持久化方案,而是 AOF 的一种优化机制。
它通过在 AOF 重写时,将 RDB 快照作为文件开头,再追加增量写命令,从而兼顾了 RDB 的快速恢复能力和 AOF 的数据完整性。
需要注意的是,只有在开启 AOF(appendonly=yes)时,该机制才会生效,否则即使配置存在,也不会参与实际运行。
cs
config get aof-use-rdb-preamble
# 返回 aof-use-rdb-preamble "no" : 配置关闭
# 返回 aof-use-rdb-preamble "yes" : 配置开启
# 需要注意的是,只有在开启 AOF(appendonly=yes)时,该机制才会生效,
# 否则即使配置存在(aof-use-rdb-preamble "yes"),也不会参与实际运行。所以具体判断如下:
|------------|---------------------------------------------------------------|
| 默认出厂状态 | save 有规则 + appendonly no → 只启用 RDB,AOF 关闭(Redis 原生默认) |
| 两者都开启 | save 有规则 + appendonly yes → RDB + AOF 双持久化(生产常用) |
| 只开 AOF | save "" + appendonly yes → 仅 AOF |
| 全关闭 | save "" + appendonly no → 无任何持久化(纯缓存,宕机丢数据) |
小编环境下的 Redis 整体判断命令如下
cs
127.0.0.1:6379> config get save # 查看 RDB 的规则
1) "save"
2) "3600 1 300 100 60 10000"
127.0.0.1:6379> config get dbfilename # 查看 RDB 持久化文件名称
1) "dbfilename"
2) "dump.rdb"
127.0.0.1:6379> config get dir # 查看 RDB 持久化路径
1) "dir"
2) "/usr/local/redis"
127.0.0.1:6379> config get appendonly # 查看 AOF 持久化开关
1) "appendonly"
2) "no"
127.0.0.1:6379> config get aof-use-rdb-preamble # 查看 aof-use-rdb-preamble 配置开关
1) "aof-use-rdb-preamble"
2) "yes"【结论】很明显是 save 有规则 + appendonly no → 只启用 RDB,AOF 关闭(Redis 原生默认)也就是持久化只采用了 RDB 的方案。
【提问】假如 aof-use-rdb-preamble 返回 no 配置关闭,那会不会影响到redis的持久化?
【回答】答案是不会的。原因是混合持久化 (aof-use-rdb-preamble) 是 AOF 的一个优化机制。并不是一个独立的持久化功能。
所以既然是 AOF 的一个优化机制,那么aof-use-rdb-preamble 返回 no 作用也仅仅只是关闭 AOF 的优化机制,但是这并不影响 AOF 正常持久化。
【提问】假如 AOF 持久化都关闭了,采用的是 RDB 持久化,那么 aof-use-rdb-preamble 配置无论是开启(yes)还是关闭(no)会不会对 Redis 持久化有影响?为什么?
【回答】答案是不会有影响,因为 AOF 持久化都关闭了,那么 aof-use-rdb-preamble 配置无论是开启(yes)还是关闭(no)都不会对 Redis 持久化有影响。因为混合持久化仅仅只是 AOF 的一个优化机制。现在是 AOF 整个功能都关闭了,那 AOF 的优化机制配置都没有使用的地方,所以配置是开还是关都没有影响。
如果RDB, AOF 全部都关闭,那就是表上第四种,redis 没有持久化仅仅当作 Cache 使用。
2.2 RDB 的配置参数
在使用 RDB 之前,我们先将 RDB 的配置参数给讲明白,参数如下:
|-------------------------------|---------|---------------------------|
| 配置项 | 作用 | 默认值 |
| stop-writes-on-bgsave-error | 磁盘故障写保护 | yes |
| rdbcompression | 压缩 RDB | yes |
| rdbchecksum | 校验和 | yes |
| dbfilename | 文件名 | dump.rdb |
| dir | 工作目录 | ./(编译时指定) |
| save | 自动触发条件 | 3600 1 300 100 60 10000 |
Redis 为 RDB 持久化"保驾护航"的一整套控制开关。这些参数本质上在解决 3 类问题:
|---------|----------------------------------------------|
| 类别 | 解决什么问题 |
| 📁 文件管理 | 存哪?叫什么? 比如:dbfilename, dir |
| 🛡 数据安全 | **写失败怎么办?文件坏了怎么办?比如:**磁盘故障写保护 |
| ⚙ 性能优化 | CPU / IO 怎么平衡?比如是否要开启备份文件的压缩,备份文件完整性校验等等 |
详细的参数讲解如下:
dbfilename -- 文件名
👉**作用:**定义 RDB 文件名
dbfilename dump.rdb # 位置在redis.conf 配置文件📌本质: RDB 持久化输出文件的名字
📌 **运行时行为:**当触发 BGSAVE:dir + dbfilename → 最终路径;例如
cs
dir = /usr/local/redis
dbfilename = dump.rdb
最终文件:
/usr/local/redis/dump.rdb📌生产建议:可以改备份文件名称,redis-prod-dump.rdb 。好处就是多实例数据备份更清晰容易区分
❗ 风险点 : 不影响性能, 但命名混乱会导致备份混乱
dir ./ -- 存储目录
👉**作用:**定义 RDB / AOF 存储目录
dir /usr/local/redis📌本质 : 所有持久化文件的"根目录" 包括: dump.rdb , appendonly.aof
📌 运行时行为: Redis 所有持久化文件都写在 dir 目录下
📌生产强烈建议:必须使用绝对路径 ❗例如:dir /data/redis 。以及单独挂盘(SSD)不要和系统盘混用
❗ 风险点 :如果 dir 指定目录无权限,磁盘满会导致:RDB 失败 → 触发stop-writes-on-bgsave-error
stop-writes-on-bgsave-error yes -- 磁盘故障写保护
👉 作用:RDB 失败时,是否停止写入
stop-writes-on-bgsave-error yes📌 本质:"自我保护机制"
📌 **运行时行为:**当发生磁盘满,权限问题, IO错误导致 BGSAVE 失败。配置是 yes 拒绝所有写操作,no 则表示继续写(但不会落盘)
|-----|--------------|
| 配置 | 结果 |
| yes | ❌ 拒绝所有写操作 |
| no | ✅ 继续写(但不会落盘) |
📌 举个真实事故场景
cs
磁盘满了
↓
RDB 一直失败
↓
如果 stop-writes = no
↓
Redis 继续写(用户数据正常)
↓
但全部没持久化 ❗
↓
一旦重启 → 数据全没👉 这就是灾难级问题
📌 推荐配置
必须 yes(默认就是)rdbcompression yes -- 压缩 RDB 文件
👉 作用:是否压缩 RDB 文件
rdbcompression yes📌 本质:用 LZF 算法压缩 RDB
📌 运行时行为:
|---------|--------|
| 开启 | 关闭 |
| 文件更小 | 文件更大 |
| CPU 有开销 | CPU 更省 |
📌 场景选择
🟢 推荐开启(默认) :磁盘敏感,数据量大
🔴 可以关闭: CPU 很紧张,极致性能场景
📌 实际影响
压缩率:约 30%~60%
CPU 开销:可接受rdbchecksum yes -- RDB 文件完整性校验
👉 作用:RDB 文件完整性校验
rdbchecksum yes📌 本质:在 RDB 文件末尾加 CRC 校验值
📌 什么时候用: 👉 Redis 启动加载 RDB 时:会校验文件是否损坏
📌 运行时行为:
|-------------|-----|
| 开启 | 关闭 |
| 更安全 | 更快 |
| 多 ~10% CPU | 无校验 |
📌 场景建议:
🟢 强烈建议开启(默认):生产环境,数据重要
🔴 可关闭:极致性能测试环境
📌 **风险点:**关闭后:RDB 损坏 → Redis 可能加载异常数据 ❗
repl-diskless-sync -- 是否无盘同步
👉 作用:主从复制时是否"无盘同步"
bash
repl-diskless-sync yes📌 **背景:**Redis 主从同步流程:
cpp
主节点生成 RDB
↓
发给从节点📌 两种模式
🟢 传统模式(默认)
cs
主节点:
生成 RDB 文件 → 写磁盘 → 再发送
# 👉 缺点:多一次磁盘 IO -- 慢 🔵 无盘模式(diskless)
主节点:
直接通过 socket 发送 RDB
(不落盘)📌 对比
|----|---------|
| 模式 | 特点 |
| 有盘 | 稳定 |
| 无盘 | 更快、低 IO |
📌 使用建议
🟢 推荐开启(大规模集群)
repl-diskless-sync yes🔴 不建议 小规模部署,或者网络不稳定不建议开启
更改 RDB 相关参数
当了解完参数的作用之后,我们就可以根据自己的服务环境来决定哪些配置参数开启。
比如小编,这边想将
数据备份文件改为:toast-redis-dump.rdb
数据备份存储路径改为:/usr/local/redis/data
cs
# 所以完整的备份文件路径如下:
/usr/local/redis/data/toast-redis-dump.rdb然后我还想开启数据备份失败写保护策略,这样 RDB 备份失败之后将禁止写入操作。
然后至于备份文件的压缩节省空间,以及备份文件完整性的校验都采用默认状态
至于生产的备份数据要不要落盘在发送,还是不落盘直接发送(无盘同步)。采用默认 直接落盘再同步。
所有配置参数完整内容如下:
cs
dbfilename toast-redis-dump.rdb # RDB 备份文件名称
dir /usr/local/redis/data # 存储目录
stop-writes-on-bgsave-error yes # RDB 备份失败,是否禁止写操作,默认开启禁止
rdbcompression yes # RDB 备份文件压缩是否开启,默认开启压缩
rdbchecksum yes # RDB 备份文件完整性校验是否开启,默认开启然后杀死 redis.conf。重新启动一下redis,
cs
[root@toast-server redis]# pkill redis-server
[root@toast-server redis]# bin/redis-server conf/redis.conf2.3 触发 RDB 持久化
2.3.1 save 规则触发 RDB 持久化
现在是所有的准备工作都完毕。现在正式开讲 RDB 业务流程。以及 RDB 持久化触发的机制。
首先,我们得先了解 save 的配置规则
cs
# 以下是一个通用生产配置示例:(配置在redis.conf) 中
save 3600 1 # 1小时内至少1次写入 → 备份
save 300 100 # 5分钟内至少100次写入 → 备份
save 60 10000 # 1分钟内至少10000次写入 → 备份
# save 规则解释
# 1. save 秒 写次数 这是一条规则。表示 在多少秒内,至少发生了多少次写操作,则触发 RDB 持久化
# 2. 一次性可以设置多条规则,多条规则之间的连接关系是 OR/或 关系。 只要触发了其中一条规则
# 就会发生 RDB 持久化。
# 3. 多条规则之间不会重复触发。因为在任何一次检查周期(每 1 秒)中,
# 一旦满足了某一条规则并触发了 BGSAVE,Redis 就会立即停止本轮检查,
# 不会再去判断剩下的规则是否也满足查看我当前 Redis 的 save 规则有哪些,打开 redis.conf。我的redis.conf 默认是没有写 save 的规则的。
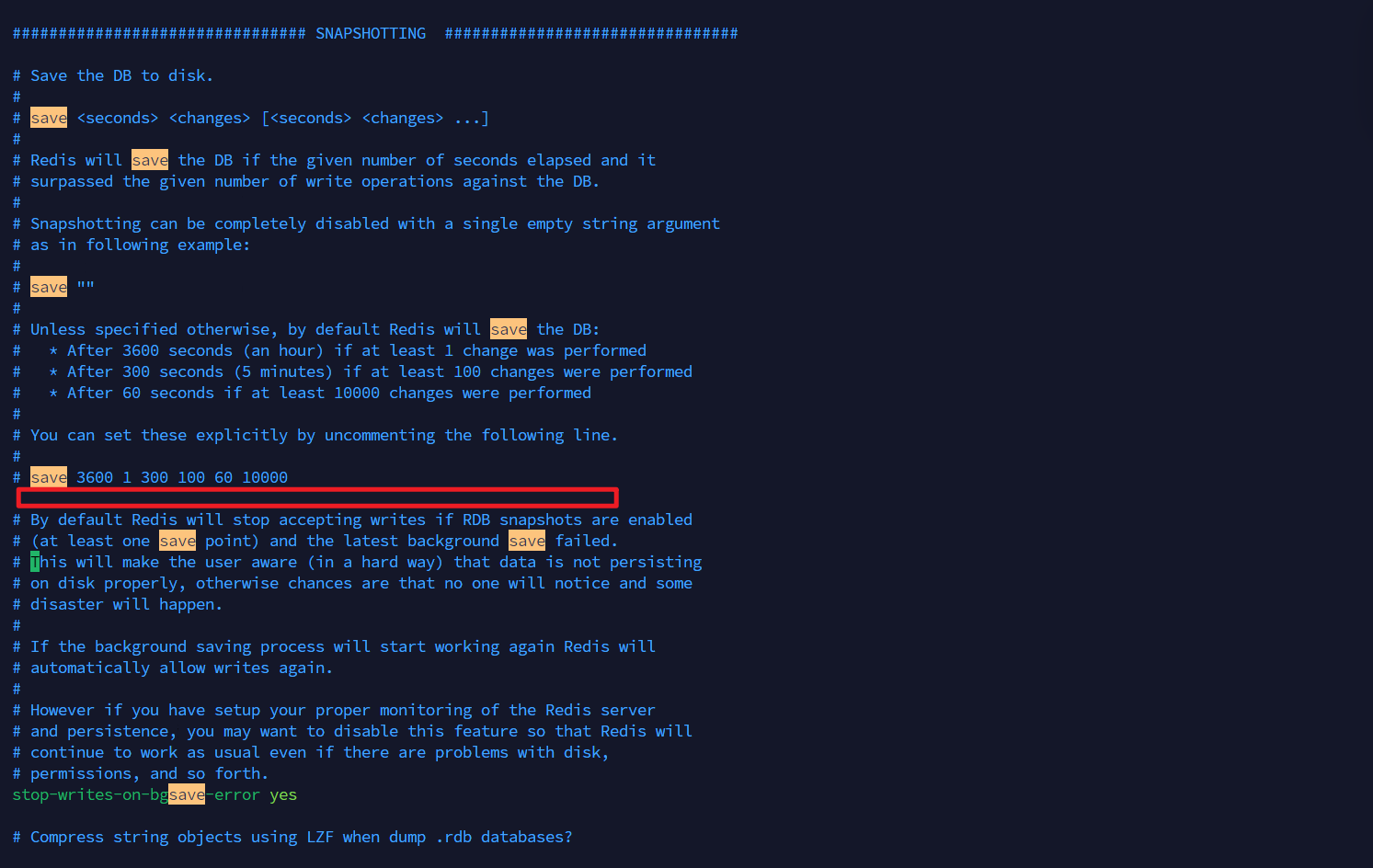
redis 在启动的时候会默认填充 save 规则,可以通过 redis-cli 进行查询
cs
127.0.0.1:6379> config get save
1) "save"
2) "3600 1 300 100 60 10000"
# 这里的配置就是
save 3600 1 # 1小时内至少1次写入 → 备份
save 300 100 # 5分钟内至少100次写入 → 备份
save 60 10000 # 1分钟内至少10000次写入 → 备份这边为了学习和测试 RDB ,小编进行 save 的临时更改
cs
# save 15 1 15秒内至少1次写入 → 备份
# save 30 3 30秒内至少3次写入 → 备份
# save 60 5 60秒内至少5次写入 → 备份
# 对应的命令如下# 将 RDB 自动触发规则修改为短期测试规则
# CONFIG SET save "15 1 30 3 60 5"
# 已设置
127.0.0.1:6379> CONFIG SET save "15 1 30 3 60 5"
OK
127.0.0.1:6379> config get save
1) "save"
2) "15 1 30 3 60 5"这边进行测试
cs
# 写操作执行前 无RDB备份文件
[root@toast-server redis]# ll /usr/local/redis/data/
total 0
# 执行写操作,
[root@toast-server redis]# bin/redis-cli
127.0.0.1:6379> auth ToastR#16
OK
127.0.0.1:6379> set testkey valuetest
OK
127.0.0.1:6379> set testkey2 valuetest2
OK
# 过了10 秒 满足 save 10 1 规则 10秒内至少1次写入 → 备份
# 可以看到数据已备份
[root@toast-server ~]# ll /usr/local/redis/data/
total 4
-rw-r--r-- 1 root root 133 Jun 16 18:44 toast-redis-dump.rdb查看对应的日志
cs
[root@toast-server redis]# tail -f logs/redis_6379.log
# 15秒内出现了1次数据变化,所以触发 RDB
1 changes in 15 seconds. Saving...
# 启用 BGSAVE 命令,并且为其分配系统进程ID
Background saving started by pid 3341938
# 数据存储到磁盘
BGSAVE done, 5 keys saved, 0 keys skipped, 200 bytes written.
DB saved on disk
# 子进程的数据处理
Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
# 子进程写入完成
Background saving terminated with success2.3.2 主动触发 RDB 持久化
这边我们可以看到通过 save 规则来触发 RDB 持久化机制。现在我们将 save 规则恢复默认
cs
127.0.0.1:6379> config set save "3600 1 300 100 60 10000"
OK
127.0.0.1:6379> config get save
1) "save"
2) "3600 1 300 100 60 10000"
# 这里的配置就是
save 3600 1 # 1小时内至少1次写入 → 备份
save 300 100 # 5分钟内至少100次写入 → 备份
save 60 10000 # 1分钟内至少10000次写入 → 备份之所以恢复我为了讲解另一种情况,就是由于 RDB 是需要触发 save 规则条件才会执行 RDB 持久化。那这种触发是属于被动触发。只有达到条件才可以执行RDB持久化。缺少主动的执行RDB持久化。
比如,在五分钟内我执行了90条写操作,但是还并没有达到 save 规则来触发RDB持久化进行备份。
5分钟内(300秒)执行了90次写操作------这不符合300 100规则(因为90 < 100),也不符合3600 1规则(因为时间还没到3600秒),也不符合60 10000规则。因此,不会触发被动保存。
此时Redis 确实不会自动执行备份 。如果此时Redis突然宕机 ,这90次写入就会丢失 。所以这个时候可以采用主动执行 RDB 持久化的方式进行。针对这种情况,Redis提供了两种主动执行RDB持久化的方式。下面我们来详细拆解:
SAVE 命令 (同步阻塞 - 严禁在生产环境使用)
127.0.0.1:6379> SAVERedis 服务器会阻塞所有客户端的请求,在主线程中直接创建 RDB 文件。在文件生成完毕之前,Redis 无法处理任何读写操作。
业务场景 :如果数据量太大,RDB期间你的业务程序会报连接超时。仅建议在内存非常小、数据量极少,或者维护关机时使用,绝对不要在运行中的生产环境执行
【测试执行】
cs
[root@toast-server redis]# rm data/* # 先删除之前的 RDB 备份文件
rm: remove regular file 'data/toast-redis-dump.rdb'? y
[root@toast-server redis]# ll data/ # 现在没有数据
# redis-cli 端
127.0.0.1:6379> set save:key save:value
OK
127.0.0.1:6379> set save:key1 save:value1
OK
127.0.0.1:6379> SAVE
OK
[root@toast-server redis]# ll data/
total 4
-rw-r--r-- 1 root root 177 Jun 17 10:31 toast-redis-dump.rdbBGSAVE 命令(异步后台执行 - 生产环境标准方案)
127.0.0.1:6379> BGSAVERedis 会调用 fork() 系统调用创建一个子进程,由子进程在后台异步生成 RDB 文件。父进程(主线程)继续处理客户端的读写请求,完全不影响业务。
业务场景 :当你发现 5 分钟内执行了 90 次写入,担心数据安全时,直接在客户端执行 BGSAVE,Redis 会立即开始备份当前内存中的全量数据。
cs
127.0.0.1:6379> BGSAVE
Background saving started
127.0.0.1:6379> 验证 :执行后,可以用 127.0.0.1:6379> LASTSAVE 命令查看最后一次成功备份的时间戳,确认是否执行完毕。
cs
127.0.0.1:6379> LASTSAVE # 2026-06-17 约 02:46 UTC / 北京时间 10:46
(integer) 1781664387
127.0.0.1:6379> 三,AOF 持久化
3.1 AOF 简介
RDB 持久化可生成完整的数据集备份,但该持久化模式存在性能损耗问题:每次触发持久化流程时,Redis 会派生全新子进程,依托子进程完成数据持久化写入。频繁派生子进程将产生较高的系统资源开销,对业务性能影响显著。针对这一短板,Redis 内置了 AOF 持久化机制作为轻量化补充方案,该机制的核心特性为增量记录所有写数据操作指令。
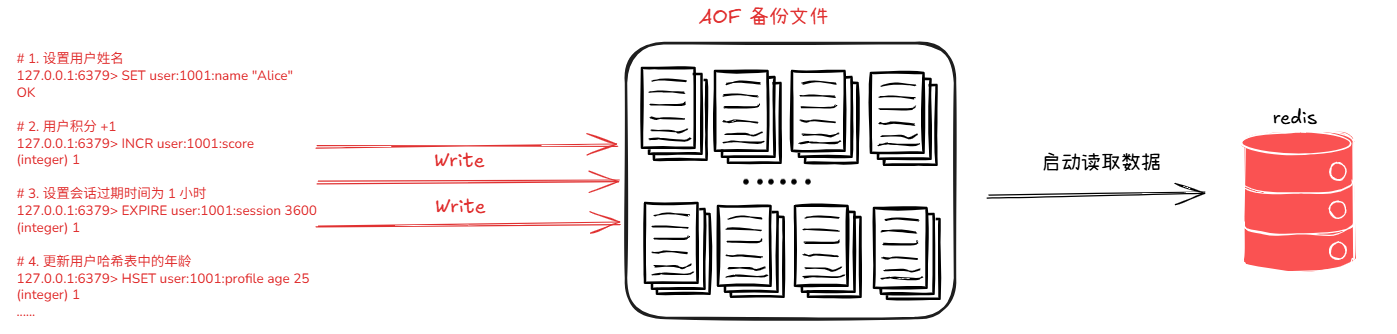
如上图所示,每执行一次写操作,AOF 都会将操作命令记录到 AOF 的备份文件里面。然后Redis 重启的时候读取数据。
3.2 AOF 命令压缩
AOF 持久化会逐条记录全部数据操作指令,数据恢复时只需重放文件内存储的命令即可完成数据集还原。该模式采用增量追加写入逻辑,无需像 RDB 持久化那样 fork 子进程执行落盘操作,理论上能够实现极致完整的数据留存,但 AOF 机制仍存在两处核心缺陷:
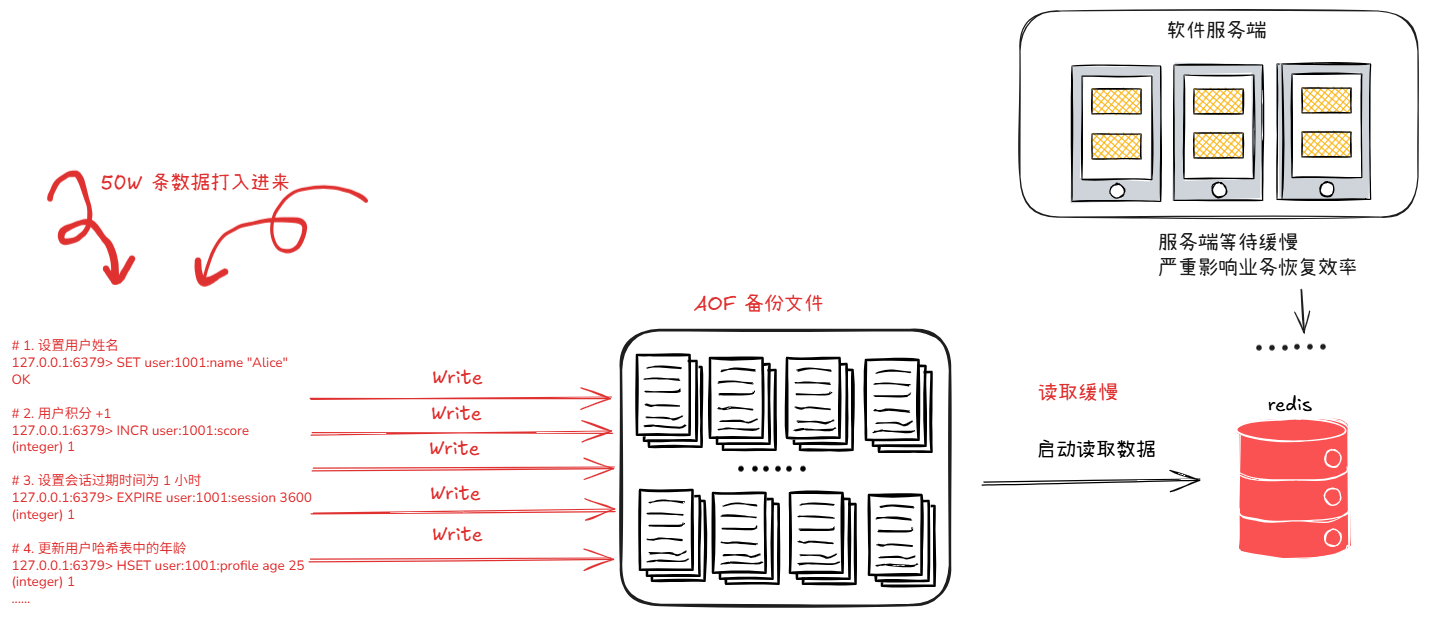
【文件体积膨胀问题】高并发场景下 AOF 文件会快速增大。例如每秒承载 30 万并发请求时,每条业务操作指令均会追加写入文件,海量指令会直接造成 AOF 文件体量急剧膨胀。
【启动恢复耗时过长】AOF 文件持续膨胀后,Redis 重启加载数据阶段需要逐条解析、执行文件内全部历史命令,大幅拉长服务启动耗时,严重影响业务恢复效率。效果如下图
为解决 AOF 文件持续膨胀的问题,Redis 引入 AOF 重写机制实现指令压缩。举个例子:若多个客户端连续执行多条LPUSH写入指令,重写流程会将多条同类合并逻辑压缩为单条等效指令,最终仅在新 AOF 文件内留存一条命令,以此缩减文件占用空间。
模拟命令重写压缩
cs
LPUSH toast-queue a
LPUSH toast-queue b
LPUSH toast-queue c
LPUSH toast-queue d
LPUSH toast-queue e
LPUSH toast-queue f
....
# 重写压缩成一条
LPUSH toast-queue a b c d e f ...3.3 AOF 重写也要依托子进程执行,为何不直接使用 RDB 持久化?
尽管 AOF 重写可有效压缩文件体积,但该重写逻辑同样交由子进程执行;重写期间主进程可持续正常对外提供读写服务,若仅依靠子进程生成压缩后的 AOF 文件,新产生的业务数据会存在丢失风险。由此容易产生疑问:既然 AOF 重写也要依托子进程执行,为何不直接使用 RDB 持久化?
面试题:RDB 与 AOF 持久化均通过子进程执行,重写 / 快照阶段主进程仍持续接收数据变更,二者理论上都存在数据快照不全的情况,Redis 为何仍保留 AOF 持久化方案?
【答案】
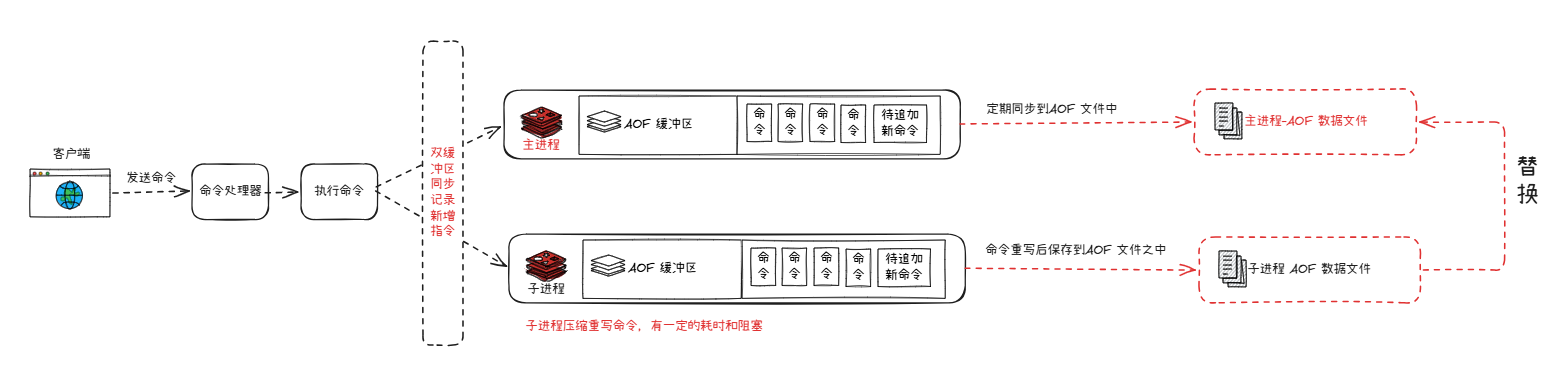
核心原因是 AOF 的数据完备性远优于 RDB,AOF 机制专门设计了配套缓冲区机制,用于同步持久化重写期间主进程新增的数据变更,而 RDB 快照流程无对应补偿方案。
开启 AOF 重写时,Redis 会维护两块独立缓冲区:一是主进程持有的 AOF 缓冲区,二是专属子进程的 AOF 重写缓冲区。重写期间客户端新下发的所有操作指令,会同步写入这两块缓冲区:
(1) 主进程持续向原有 AOF 文件逐条追加完整原始指令,保障数据实时落地;
(2) 子进程依托重写缓冲区执行指令合并压缩,生成体积更小的全新 AOF 文件。
待子进程完成重写、生成压缩后的完整 AOF 文件后,Redis 会原子替换旧的 AOF 文件。整套机制兼顾两大优势:一方面通过指令压缩控制 文件体积 ,另一方面依靠双缓冲区同步记录新增指令,保证数据不丢失。即便重写过程中子进程发生异常崩溃,主进程持续写入的原始 AOF 文件依旧完整,可独立完成全量数据恢复。
3.4 Redis 7.x 系版本以上 AOF 的新特性
在 Redis-6.x 系版本里面,AOF 就只有那么一个文件会存在数据目录之中,但是在 Redis 7.x 系列版本开始,采用了多 AOF 文件的存储设计。
Redis 7.0 引入的 Multipart AOF (MP-AOF) 机制 ,将单个 AOF 文件拆分为一组文件,其核心设计目的是为了解决旧版 AOF 重写(AOFRW)机制存在的内存 和磁盘开销问题。
旧版 AOF 重写(AOFRW)的痛点
在解释新设计前,先回顾旧版的问题:重写时,主进程会 fork 一个子进程来生成新的 AOF 文件。为了保证数据完整性,主进程需要将重写期间的增量写命令同时记录到两个缓冲区:
aof_buf:常规 AOF 缓冲区,用于写入旧的 AOF 文件。
aof_rewrite_buf:专门为重写子进程准备的缓冲区
"双写"模式在高写入场景下会带来两大问题:
- 内存开销巨大 :
aof_rewrite_buf和aof_buf的内容高度重复,可能导致内存占用翻倍。 - 额外的磁盘 I/O 与 CPU 开销 :重写后期,主进程需通过管道将
aof_rewrite_buf的数据发给子进程,增加了额外的系统开销。重写完成后,还需将残留数据再次写入临时文件。
Redis 7.0 MP-AOF 的新设计
MP-AOF 的核心思路是:将对单个文件的复杂操作,转变为对多个文件的清晰管理,从根本上解决上述问题。
1. 三种文件与清单文件
MP-AOF 将数据拆分到同一个目录下的三类文件:
- BASE 文件 :基础 AOF 文件,存储某一时刻的完整数据快照(经过压缩重写),最多只有一个。
- INCR 文件 :增量 AOF 文件,存储 BASE 文件之后产生的所有增量写命令,可以有多个。
- HISTORY 文件 :历史文件,每次重写成功后,旧的 BASE 和 INCR 文件会被标记为 HISTORY 并自动删除。
- Manifest 清单文件 :一个清单文件(
<appendfilename>.manifest),用于记录当前生效的 BASE 和 INCR 文件列表,是 Redis 启动时加载数据的"目录"。
2. 新机制如何工作
重写过程被简化为"创建新文件"和"更新清单"两步,不再需要复杂的数据拷贝:
- 子进程直接基于当前内存数据,创建一个新的 BASE 文件。
- 重写期间,主进程的写命令照常追加到当前的 INCR 文件中。
- 新 BASE 文件生成后,主进程更新 Manifest 文件,将新 BASE 文件和重写期间产生的 INCR 文件标记为最新。
- 旧的 BASE 和 INCR 文件被标记为 HISTORY 并随后删除。
新设计带来的核心优势
- 显著降低内存使用 :彻底消除了
aof_rewrite_buf。主进程只需正常写入当前的 INCR 文件,子进程直接读取内存数据生成 BASE 文件,无需额外的缓冲区和数据传输。 - 减少磁盘 I/O 和 CPU 消耗:消除了主、子进程间的数据拷贝和额外的写入操作,逻辑更简单、高效。
- 提升数据恢复速度:启动时,Redis 只需按顺序加载一个 BASE 文件(RDB 格式,加载快)和最新的 INCR 文件(命令少,回放快),比加载单个巨大的 AOF 文件更快。
- 为高级特性奠定基础 :这种文件组织方式为实现按时间点恢复(PITR) 等高级特性提供了可能。
总而言之,Redis 7.0 的 MP-AOF 机制通过"化整为零"的文件管理和清晰的"基线+增量"思路,优雅地解决了旧版 AOF 重写的资源消耗问题,是 AOF 持久化机制的一次重要演进
3.5 AOF 实操
在操作之前,先开启 AOF 持久化配置,然后重启 Redis 服务。
cs
[root@toast-server redis]# vim conf/redis.conf
# appendonly no 改为 appendonly yes
# wq! 保存并退出
# 重启redis服务
[root@toast-server redis]# pkill redis-server
[root@toast-server redis]# bin/redis-server conf/redis.conf
# 查看 redis 的存储目录:小编设置的是存储目录:/usr/local/redis/data
[root@toast-server data]# pwd
/usr/local/redis/data
[root@toast-server data]# ll
total 4
drwxr-xr-x 2 root root 4096 Jun 17 16:36 appendonlydir
# 所有的 AOF 相关文件都存储在 appendonlydir 目录中
[root@toast-server data]# tree appendonlydir/
appendonlydir/
├── appendonly.aof.1.base.rdb
├── appendonly.aof.1.incr.aof
└── appendonly.aof.manifest现在已经开启了 AOF 持久化处理。顺便查看一下 redis 的启动日志
cs
[root@toast-server redis]# tail -f logs/redis_6379.log
oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
# redis 版本信息
Redis version=8.8.0, bits=64, commit=00000000, modified=0, pid=3392721, just started
Configuration loaded
monotonic clock: POSIX clock_gettime
Running mode=standalone, port=6379.
Server initialized
BGSAVE done, 0 keys saved, 0 keys skipped, 88 bytes written.
# 这里创建了 base file 和 incr file
Creating AOF base file appendonly.aof.1.base.rdb on server start
Creating AOF incr file appendonly.aof.1.incr.aof on server start
Ready to accept connections tcp写入一些数据操作,然后观察 AOF 的持久化
cs
127.0.0.1:6379> LPUSH stack left-A
(integer) 1
127.0.0.1:6379> LPUSH stack left-B
(integer) 2
127.0.0.1:6379> LPUSH stack left-C
(integer) 3
127.0.0.1:6379> LPUSH stack left-D left-E left-F left-J
(integer) 7观察 appendonlydir 目录信息
查看 appendonly.aof.1.base.rdb 文件内存
cs
[root@toast-server data]# vim appendonlydir/appendonly.aof.1.base.rdb
REDIS0014ú redis-ver^E8.8.0ú
redis-bitsÀ@ú^EctimeÂ<94>\2jú^Hused-memÂÀ6^K^@ú^Haof-baseÀ^Aÿ^EÚË<9d>v^A^B 打开看到一堆乱码、开头 REDIS0014,这是标准 RDB 二进制快照文件,不是文本,不能用 vim 正常阅读。
生成时机:上一次 AOF 重写(BGREWRITEAOF)时,子进程把当时 Redis 里全部存量数据一次性导出成 RDB 快照;
作用:作为数据恢复的基准底本,加载速度远快于纯命令日志
乱码原因:二进制存储,包含版本、内存占用、创建时间、所有 key-value 数据,vim 打开只会显示不可读字符,不要直接编辑。
查看 appendonly.aof.1.incr.aof 文件内容
cs
[root@toast-server data]# vim appendonlydir/appendonly.aof.1.incr.aof
*2
$6
SELECT
$1
0
*3
$5
LPUSH
$5
stack
$6
left-A
*3
$5
LPUSH
$5
stack
$6
left-B
*3
$5
LPUSH
$5
stack
$6
left-C
*6
$5
LPUSH
$5
stack
$6
left-D
$6
left-E
$6
left-F
$6
left-J里面是可读的 Redis 原始 AOF 协议文本,记录重写完成之后新增的所有写命令,你只操作了两三条写入,这里只会追加你执行过的指令:
cs
解析这段协议:
*2:本条命令一共 2 个参数
$6:第一个参数长度 6 → SELECT
$1:第二个参数长度 1 → 0
对应命令:SELECT 0(切换到 0 号库,客户端连接默认会执行这条,不算业务写操作)
*3:本条命令一共 3 个参数
$5:LPUSH
$5:key stack
对应你的写入操作:LPUSH stack xxxRedis 重启恢复流程: 先加载 base.rdb 拿到完整存量数据,再按顺序逐条执行 incr.aof 里的新增命令,最终还原全部数据。
查看 appendonly.aof.manifest 文件内容
cs
[root@toast-server data]# vim appendonlydir/appendonly.aof.manifest
file appendonly.aof.1.base.rdb seq 1 type b
file appendonly.aof.1.incr.aof seq 1 type i startoffset 0该文件是元数据,记录着appendonly.aof.1.incr.aof 和 appendonly.aof.1.base.rdb。因为随着数据量的增大,这些文件也可以增多。增多的文件都会记录在这个文件里面。
什么时候会生成新的 base、新 incr?
cs
当满足 AOF 重写触发条件(文件增长比例 / 手动执行 BGREWRITEAOF),会:
新建一份新的 base 快照;
新建一个全新编号的 incr 增量文件;
旧的 base、旧 incr 标记为 history 历史文件,后台异步删除。手动触发 AOF -- BGREWRITEAOF
127.0.0.1:6379> BGREWRITEAOF
Background append only file rewriting started查看 redis 服务日志
3392721:M:M 代表 Master 主进程 进程 PID=3392721 3412211:C:C 代表 Child 子进程
cs
# 触发 AOF 后台重写的瞬间,主进程立刻新建全新增量文件 appendonly.aof.2.incr.aof
3392721:M 17 Jun 2026 17:04:40.055 * Creating AOF incr file appendonly.aof.2.incr.aof on background rewrite
# 主进程 fork 出子进程,子进程 PID=3412211,正式启动 AOF 后台重写任务
# fork 操作采用 Copy-On-Write 写时复制,不阻塞主进程对外读写
3392721:M 17 Jun 2026 17:04:40.055 * Background append only file rewriting started by pid 3412211
# 子进程执行 BGSAVE,将 fork 瞬间内存中所有全量数据导出为 RDB 快照;
# 当前数据库仅 1 条有效 key,无过期 / 跳过键,快照文件总大小 146 字节
3412211:C 17 Jun 2026 17:04:40.057 * BGSAVE done, 1 keys saved, 0 keys skipped, 146 bytes written.
# 子进程把生成的 RDB 快照写入临时 BASE 文件,文件名携带子进程 PID 做隔离,防止多轮重写文件冲突
# 临时文件不会对外生效,旧数据文件依然完好,重写中途崩溃不会损坏原有持久化文件
3412211:C 17 Jun 2026 17:04:40.059 * Successfully created the temporary AOF base file temp-rewriteaof-bg-3412211.aof
3412211:C 17 Jun 2026 17:04:40.060 * Fork CoW for AOF rewrite: current 0 MB, peak 0 MB, average 0 MB
3392721:M 17 Jun 2026 17:04:40.085 * Background AOF rewrite terminated with success
3392721:M 17 Jun 2026 17:04:40.085 * Successfully renamed the temporary AOF base file temp-rewriteaof-bg-3412211.aof into appendonly.aof.2.base.rdb
# 上一轮生效的旧基准文件 .1.base.rdb、旧增量文件 .1.incr.aof 全部标记为 HISTORY 历史文件
3392721:M 17 Jun 2026 17:04:40.089 * Removing the history file appendonly.aof.1.incr.aof in the background
3392721:M 17 Jun 2026 17:04:40.089 * Removing the history file appendonly.aof.1.base.rdb in the background
3392721:M 17 Jun 2026 17:04:40.093 * Background AOF rewrite finished successfully查看 appendonlydir 目录,确实已经有新版本的文件
cs
[root@toast-server redis]# ll data/appendonlydir/
total 8
-rw-r--r-- 1 root root 146 Jun 17 17:04 appendonly.aof.2.base.rdb
-rw-r--r-- 1 root root 0 Jun 17 17:04 appendonly.aof.2.incr.aof
-rw-r--r-- 1 root root 102 Jun 17 17:04 appendonly.aof.manifest3.6 混合持久化讲解
在 Redis 4.0 的时候引入了 混合持久化,是通过 RDB + AOF 两种方式实现持久化存储。现在这个多文件 MP-AOF 好像也是 RDB + AOF;因为从 appendonlydir 目录当中 base.rdb 是一个 RDB 全量生成的二进制备份文件,而 incr.aof 是一个 AOF 增量命令写入的文件。
那他们之间的区别是什么?
Redis 4.0 引入了混合持久化(aof-use-rdb-preamble yes),其中 AOF 重写会生成一个以 RDB 格式开头、后跟增量 AOF 数据的文件。
Redis 7.0 的 MP-AOF(多文件 AOF) 在逻辑上 采用了"RDB + AOF"的混合思路,但在物理存储上和传统的"RDB + AOF"是两码事。
1. 传统意义上的"RDB + AOF"(Redis 4.0~6.x)
在旧版本中,如果你同时开启了 RDB 和 AOF,它们是两个独立的文件:
dump.rdb(二进制快照)
appendonly.aof(命令日志)此时所谓的"混合",指的是 aof-use-rdb-preamble**(AOF 前置 RDB 头)** 功能。即:AOF 重写时,新生成的 appendonly.aof 文件前半部分是 RDB 二进制数据 ,后半部分是增量 AOF 命令。但物理上,它们合并在同一个文件里。
2. Redis 7.0 MP-AOF 的"RDB + AOF"(逻辑混合)
在 Redis 7.x 的多文件设计中,BASE 文件 和INCR 文件的关系,本质上就是 RDB 和 AOF 的关系:
【BASE 文件 (基础文件)】实际上就是 RDB 格式 (如果开启了 aof-use-rdb-preamble yes)。它存储的是重写那一刻的全量内存快照(二进制压缩格式),加载极快。
【INCR 文件 (增量文件)】是纯 AOF 格式。它存储的是 BASE 文件生成之后,新产生的所有增量写命令(文本协议格式)。
所以从逻辑上看:
Redis 7.0 加载数据时 = 加载 BASE(即 RDB 快照) + 重放 INCR(即 AOF 增量日志)。这不就是典型的"混合持久化"吗?
3. 它们最核心的区别(物理 vs 逻辑)
既然逻辑上都是"RDB + AOF",为什么 Redis 7.0 要大费周章拆成多个文件?
|------------|---------------------------------------------|------------------------------------------------------------|
| 对比维度 | 旧版混合(4.0~6.x) | Redis 7.0 MP-AOF |
| 物理文件 | 单文件 (一个 .aof文件里嵌着 RDB 头和 AOF 尾) | 多文件 (独立的 BASE.rdb/ BASE.aof + INCR.aof) |
| 重写机制 | 子进程生成新 .aof临时文件,完成后原子替换旧文件(期间有数据拷贝) | 子进程生成新 BASE文件,主进程追加新 INCR 文件 ,最后更新清单文件(Manifest) |
| 增量数据存储 | 重写期间新增数据先写 aof_rewrite_buf,最后塞进新文件的尾部 | 重写期间新增数据直接写入新的 INCR 文件,无需拷贝给子进程 |
| 内存开销 | 高(需要额外的重写缓冲区,双倍内存) | 低(无需重写缓冲区,主进程写 INCR,子进程写 BASE) |
一句话总结你的问题
Redis 7.0 的多 AOF 文件设计,本质上是把原来"挤在一个文件里的 RDB 和 AOF 数据"拆成了"独立存放的 BASE 文件和 INCR 文件"。
它在数据恢复策略 上依然是 RDB(快速加载全量)+ AOF(回放增量),但在文件管理和重写算法上进行了彻底重构,解决了旧版单文件重写时的内存瓶颈和额外 I/O 开销。
所以,你可以这样回答面试官:
"Redis 7.0 的 MP-AOF 保留了 RDB 快照作为 BASE 文件来加速恢复,同时用独立的 INCR 文件记录增量,是在混合持久化思想上的物理存储升级,而非推翻重来。"