从 ROS2 机器人开发者视角体验 NVIDIA Alpamayo:Vision-Language-Action 在自动驾驶中的一次实践
关键词: NVIDIA、Alpamayo、ROS2、VLA、Vision-Language-Action、自动驾驶、机器人、具身智能、CUDA、AI
前言
最近一段时间,Vision-Language-Action(VLA)模型逐渐成为具身智能领域的热门方向。从最初的大语言模型(LLM),到视觉语言模型(VLM),再到如今能够直接输出机器人动作的 VLA,大模型的发展已经开始从"理解世界"逐渐走向"执行任务"。
作为一名主要学习 ROS2、机器人视觉以及导航开发 的开发者,我也一直在关注这些新技术在机器人领域的应用。前段时间 NVIDIA 开源了 Alpamayo 1,这是一个面向自动驾驶场景的 VLA 模型,最大的特点就是把**视觉理解(Vision)+ 推理(Reasoning)+ 动作预测(Action Prediction)整合到同一个框架中。
虽然它主要面向自动驾驶,但在阅读官方资料后,我发现其中很多设计思想同样值得机器人开发者借鉴。因此,这次结合自己的学习方向,对 Alpamayo 做了一次完整体验,并记录整个过程。
一、Alpamayo 到底是什么?
官方对 Alpamayo 的介绍可以概括为一句话:
Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving
简单理解,就是:
让自动驾驶模型不仅知道"怎么开",还知道"为什么这样开"。
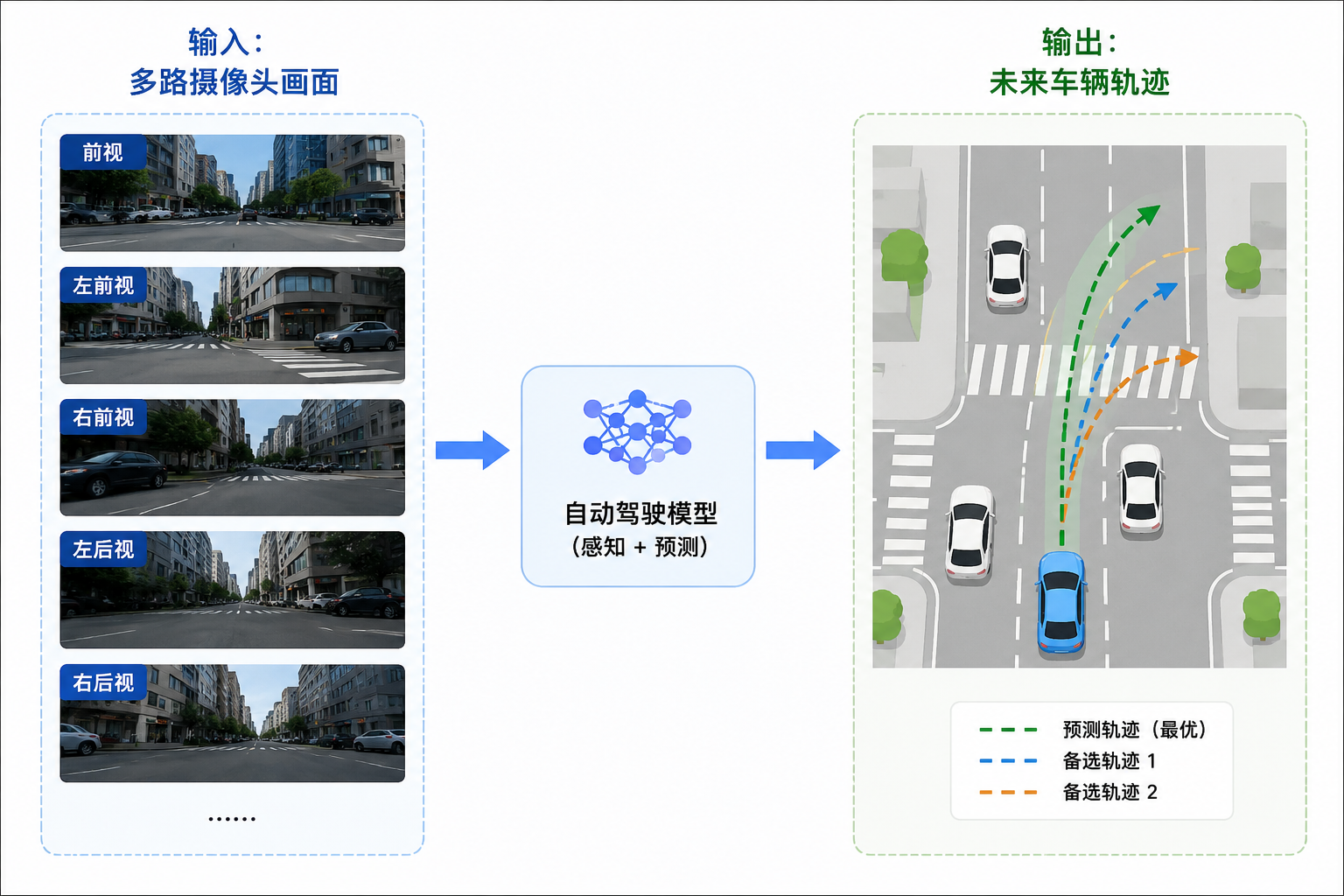
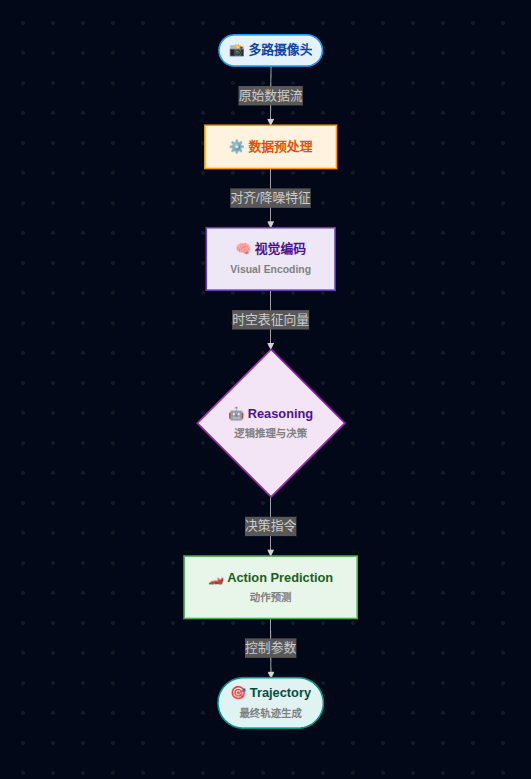
传统自动驾驶模型更多关注轨迹预测,如图所示,传统自动驾驶模型通常采用"多路摄像头输入 → 环境感知 → 轨迹预测"的处理流程。车辆首先通过多个摄像头采集周围环境信息,包括道路结构、交通参与者、交通标识以及障碍物等内容,再利用神经网络完成场景理解,最终输出未来一段时间内的车辆行驶轨迹。为了提高模型的鲁棒性,预测结果通常不仅包含一条最优轨迹,还会生成多条候选轨迹,用于应对不同交通场景或突发情况。这种方式能够较好地解决车辆"应该往哪里开"的问题,也是当前端到端自动驾驶模型中较为常见的设计思路。
而 Alpamayo 在此基础上增加了推理能力:
如图所示,自动驾驶AI的决策链路清晰可见:系统首先感知 到前方车辆亮起红色尾灯,随即启动多模态分析引擎探究原因;通过计算机视觉与热成像融合,系统精准判断 出前方横穿马路的行人;基于这一关键信息,决策模块立即发出"DECELERATE"指令,控制车速平稳下降以决定减速 ;最终,规划模块在路面上投射出蓝绿色的预测路径,输出未来轨迹,指引车辆安全绕过风险区域,完美展示了一次从感知到执行的端到端智能决策闭环。
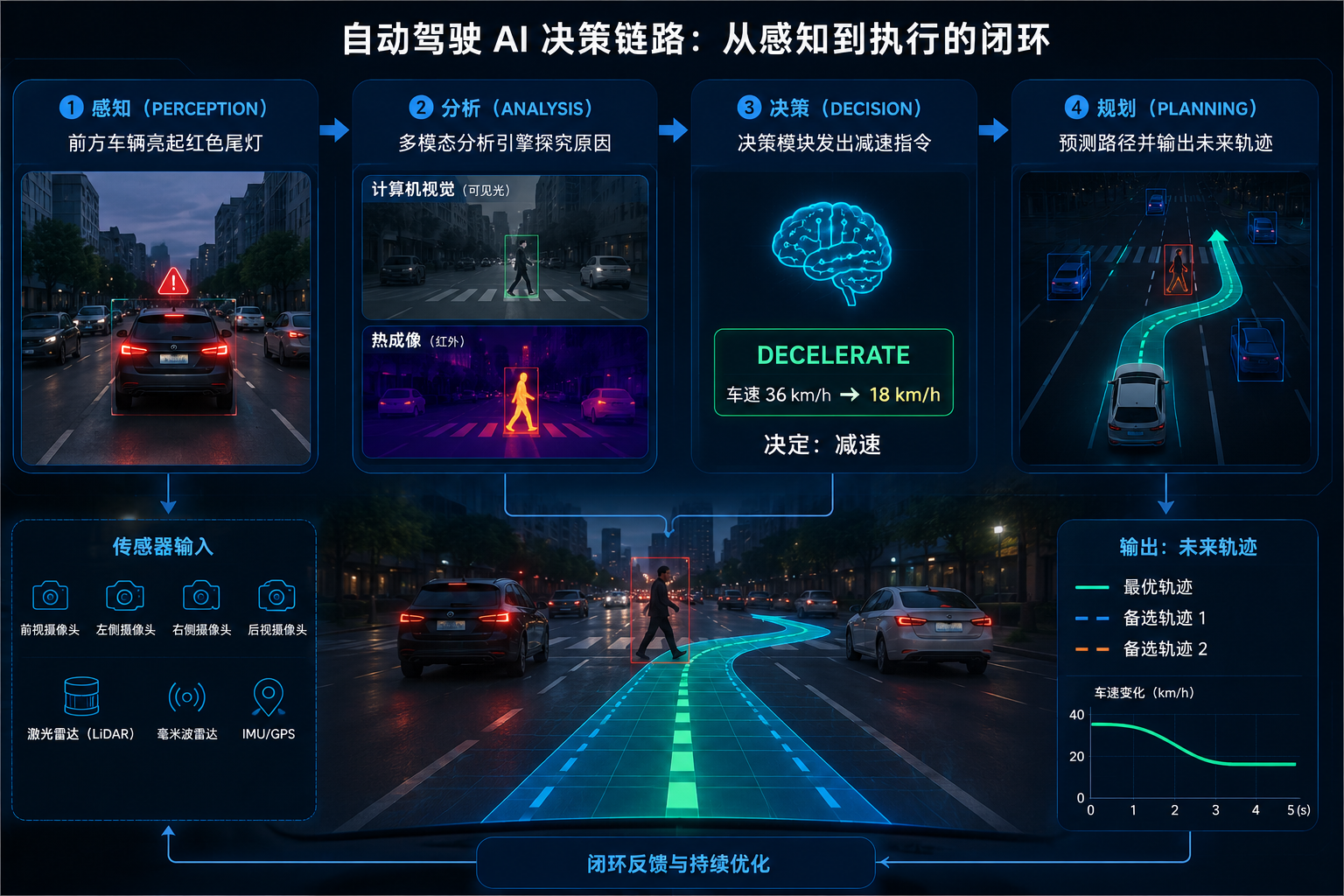
也就是说,模型不仅输出结果,还会给出一条推理链(Chain of Causation),增强了模型的可解释性。
从机器人开发的角度来看,这种设计理念其实与当前具身智能的发展方向非常一致。
英文文档看起来不太方便,我让翻译了一版,下面是他的能力
|---------------------------|------|
| 功能 | 是否支持 |
| 因果推理(Chain of Causation) | ✅ |
| Vision-Language-Action 架构 | ✅ |
| 轨迹预测 | ✅ |
| SFT 微调模型 | ✅ |
| SFT 微调代码 | ✅ |
| RL 后训练代码 | ✅ |
| RL 后训练模型 | ❌ |
| 导航输入(Route) | ❌ |
| Meta Action | ❌ |
| 通用视觉问答(VQA) | ❌ |
二、官方体验与项目资源
官方目前提供了较为完整的资料,包括:
-
GitHub 项目
-
HuggingFace 模型权重
-
arXiv 论文
-
推理 Notebook
-
微调(SFT)脚本
-
强化学习(RL)训练脚本
其中最让我关注的是 README 中列出的整体架构,包括:
-
Vision-Language-Action
-
Chain of Causation(CoC)
-
Trajectory Prediction
-
Diffusion Model
整个项目已经不仅仅是一个简单的轨迹预测网络,而是完整覆盖了自动驾驶推理流程。

三、本地部署体验
为了更深入了解整个项目,我还是决定按照官方文档尝试部署。
官方推荐使用 Python 3.12,并使用 uv 创建虚拟环境:
uv venv ar1_venv
source ar1_venv/bin/activate
uv sync --active整个安装流程比较顺利,但在安装依赖时遇到了第一个问题。
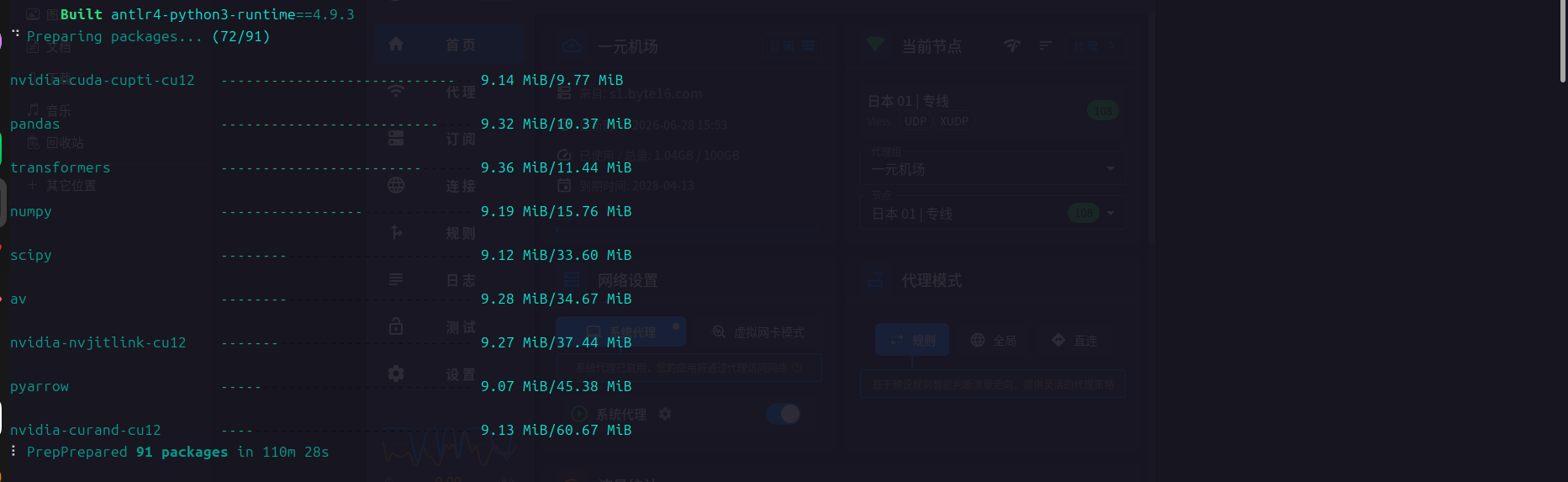
Flash Attention 编译失败
执行 uv sync --active 后,安装过程停留在 Flash Attention:
ModuleNotFoundError: No module named 'wheel'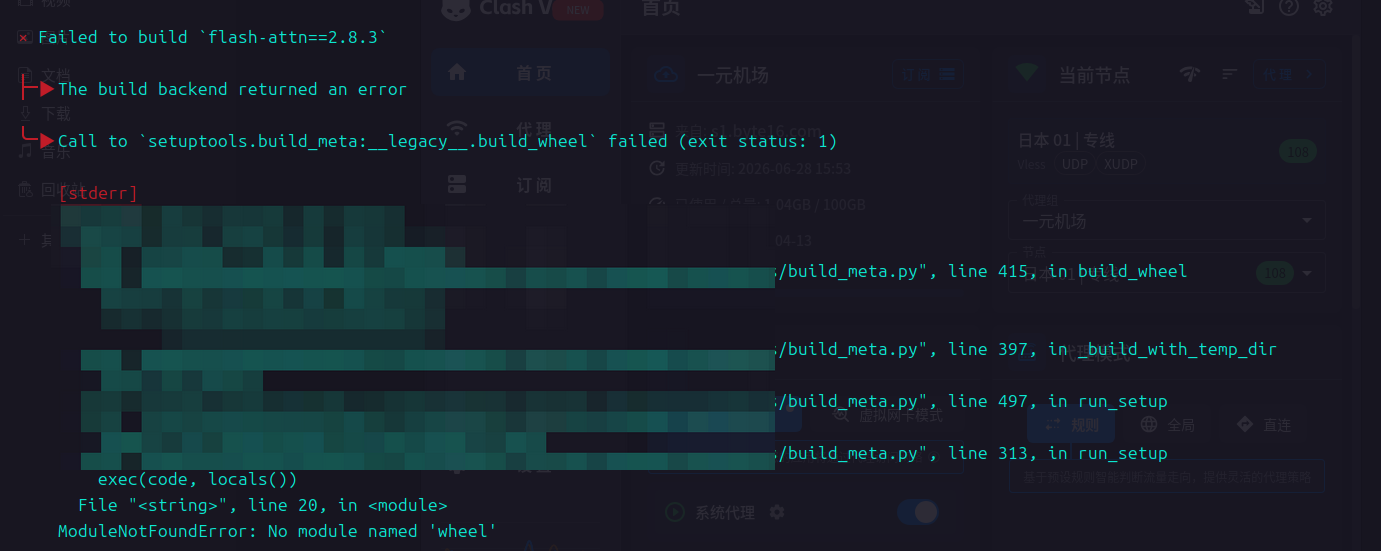
刚开始我以为是 CUDA 环境的问题,后来排查发现实际上是 Flash Attention 在构建过程中缺少 wheel 依赖。
安装 wheel 后继续排查,又发现了新的问题。

CUDA 环境检查
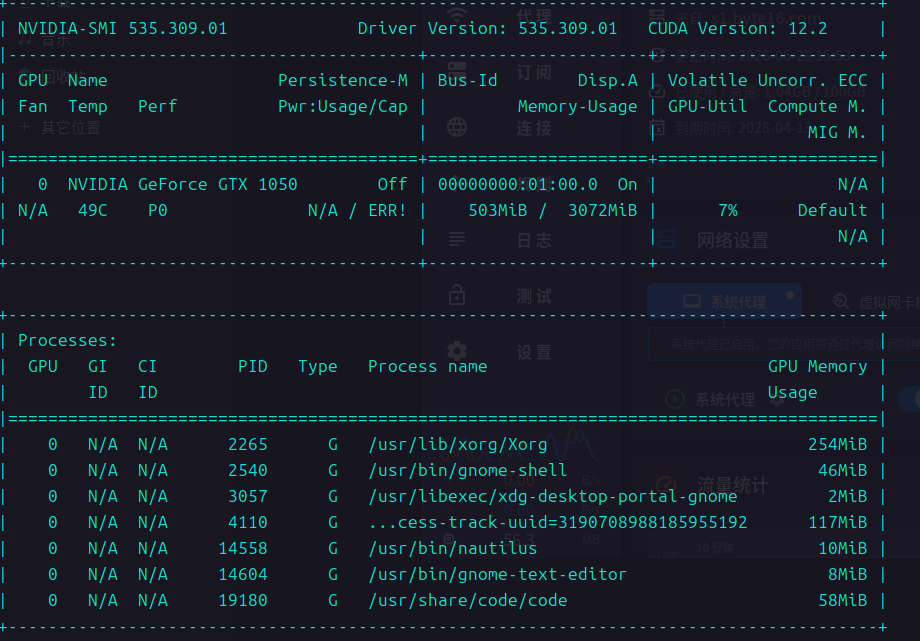
继续检查环境:
nvidia-smi显示本机 GPU 为:
NVIDIA GTX1050
3GB 显存继续检查:
python -c "import torch;print(torch.__version__)"结果发现:
2.12.0+cpu也就是说当前安装的是 CPU 版本 PyTorch。
此外,本机并未安装 CUDA Toolkit,因此:
nvcc -V提示命令不存在。
经过查阅官方文档后确认,Alpamayo 官方建议使用 24GB 以上显存,例如 RTX3090、RTX4090、A100、H100 等显卡,而我当前使用的 GTX1050(3GB)显然无法满足推理需求。
不过最近正在采购一台高性能工作站,等到了过后再试试。
因此,本次部署最终停留在源码阅读阶段,没有继续进行完整模型推理。
四、阅读源码后的几点理解
虽然没有完成模型推理,但我重点阅读了项目源码。
项目整体目录如下:
src/
├── action_space
├── common
├── diffusion
├── geometry
├── models
├── config.py
├── helper.py
├── test_inference.py整个工程结构非常清晰。


我重点阅读了 test_inference.py。
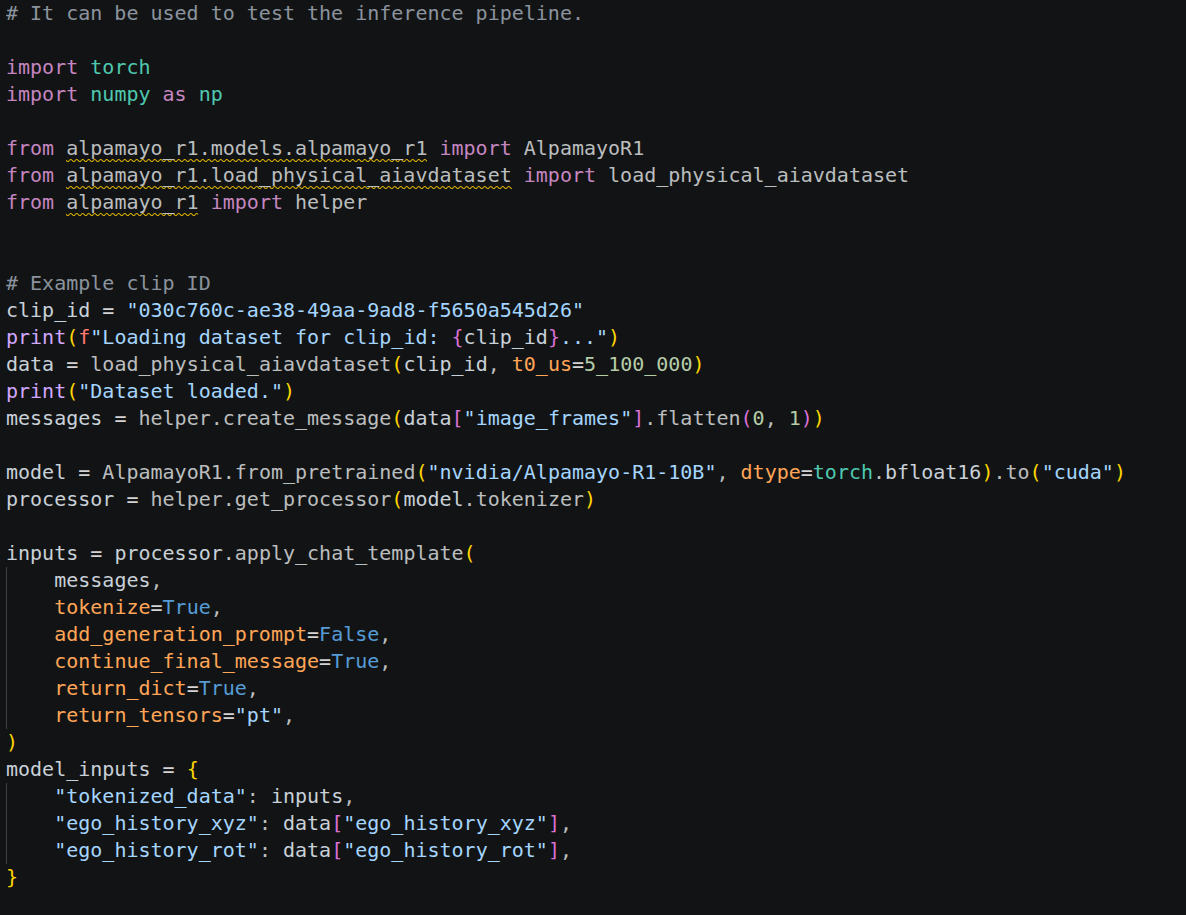
整个推理流程大致如下:
这种设计与传统机器人程序有着明显区别。
以前我们开发 ROS2 机器人时,往往采用的是模块化方式:
每一个模块之间都是人为设计接口。
而 VLA 更像是:
整个流程由同一个模型完成。
这也是未来机器人发展的重要方向。
五、如果放到机器人场景,会是什么样?
虽然 Alpamayo 面向自动驾驶,但我觉得它的设计思想完全可以迁移到机器人领域。
例如家庭服务机器人。
传统机器人:
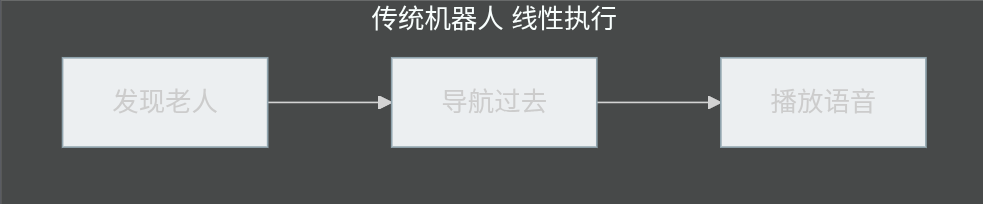
而加入推理能力后:

再比如商超机器人。
过去更多依赖固定逻辑:
如果加入 VLA:
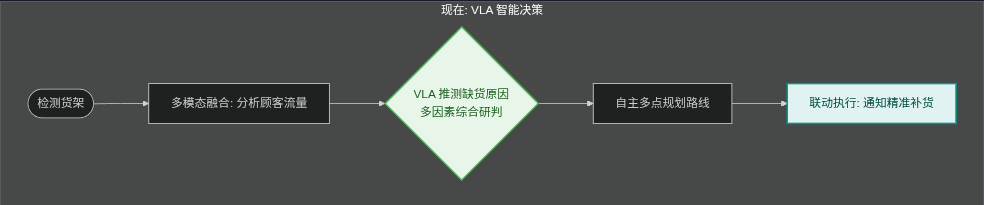
可以发现,真正改变的不是机器人"能不能完成任务",而是它开始具备一定程度的"决策能力"。
这也是我认为 Alpamayo 最值得学习的地方。
六、几点体验感受
整个体验下来,我最大的感受有三点。
第一,官方文档非常完善。
无论是 README、论文,还是 HuggingFace 模型卡,都提供了比较详细的说明,对于开发者非常友好。(英文不太好,自己搞了一个中文版本)
第二,硬件门槛确实较高。
目前官方推荐至少 24GB 显存,对于普通开发者来说,本地部署仍然存在一定门槛。如果只是学习源码,CPU 环境已经能够帮助理解整体架构;如果希望实际运行模型,则更适合使用高显存显卡或云端 GPU。
第三,VLA 的思路值得机器人领域关注。
相比传统"感知 + 决策 + 控制"的流水线架构,VLA 更强调统一建模,让模型直接学习从视觉到动作的映射关系,同时保留一定的推理过程。这种能力对于家庭机器人、巡检机器人、仓储物流机器人等场景都有一定参考价值。
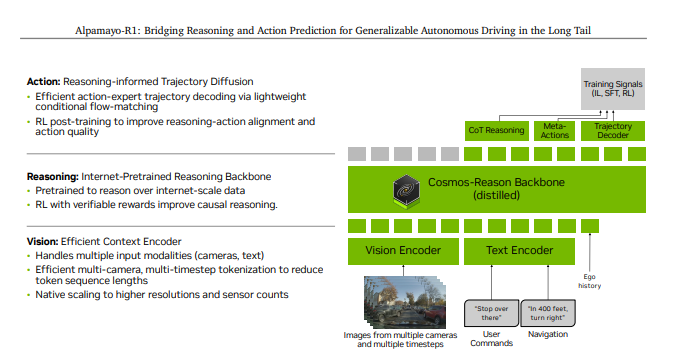
图片引自论文内容:https://research.nvidia.com/labs/avg/publication/wang.luo.etal.arxiv2025/
总结
虽然受限于本地硬件(GTX1050,3GB 显存),最终没有完成 Alpamayo 的完整推理体验,但通过阅读官方文档、部署项目、分析源码以及结合自身 ROS2 开发经验,我对 Vision-Language-Action 模型有了更加直观的认识。
对于机器人开发者而言,Alpamayo 带来的启发并不仅仅是一个自动驾驶模型,更是一种新的系统设计思路:将视觉理解、推理能力和动作生成整合到统一框架中,让机器人具备更强的环境理解和自主决策能力。
未来,我也希望继续结合 ROS2、机器人导航以及具身智能方向,对类似 VLA 架构进行进一步学习和实践。相信随着模型能力和硬件性能的不断提升,这类技术也会逐渐从自动驾驶走向更广泛的机器人应用场景。
参考资料
-
NVIDIA Alpamayo GitHub 项目
-
Alpamayo HuggingFace Model Card
-
Alpamayo 官方论文(arXiv)
-
NVIDIA Physical AI 相关资料