NondBREM: Nondeterministic Offline Reinforcement Learning for Large-Scale Order Dispatching【2024】
摘要
网约车服务中最核心的任务之一是订单派发,即向空闲司机分配未服务的订单。近年来,得益于强化学习(RL)的发展,订单派发技术取得了显著的进步,强化学习已被证明能有效解决这类如订单派发般的序列决策问题。然而,大多数现有的强化学习方法需要智能体通过与线上环境进行实时交互来学习最优策略,由于高昂的成本或安全隐患,这在现实世界的部署中往往具有挑战性甚至是不切实际的。例如,由于供需在时空上的不平衡,在策略学习期间,基于在线强化学习的订单派发可能会严重影响网约车平台的收入和乘客体验。
因此,在这项工作中,我们开发了一个名为 NondBREM 的大规模订单派发离线深度强化学习框架,该框架仅从累积的日志数据中学习策略,从而避免了与环境进行高昂且不安全的交互。在 NondBREM 中,我们开发了一个非确定性批量约束 Q 学习(NondBCQ)模块,用于减少算法的外推误差;同时利用一个集成了多值网络与多头网络的随机集成混合(REM)模块,以提高模型的泛化能力和鲁棒性。在真实世界大规模网约车数据集上的广泛实验表明了我们设计的优越性。
引言
由于高出行需求和移动互联网的快速发展,网约车服务(如 Uber、Lyft 和滴滴)在过去十年中迎来了显著增长。在网约车服务中,最核心的任务之一就是实时订单派发,它直接影响到乘客的体验、司机的收入、平台的利润以及整体的交通效率。因此,在本文中,我们专注于面向大规模网约车服务的实时订单派发问题。
鉴于订单派发的重要性,它吸引了工业界和学术界的广泛关注,研究人员已经开展了大量工作来解决这一问题。特别是随着近年来深度学习和计算能力的提升,深度强化学习(DRL)在解决诸如网约车订单派发等序列决策问题上展现出了巨大的潜力。例如,有研究提出了一种独立的基于 DRL 的派发策略,该策略配备了多种新颖的机制,以确保高效且鲁棒的在线(on-policy)学习与推理,同时能够适应全量规模的部署;还有研究设计了价值函数和分层 DRL,将订单派发和车辆重新调度(relocation)问题联合起来进行统一解决。此外,也有学者开发了独立的 Q 学习方法来解决多个智能体之间的通信和交互问题,从而平衡车辆分布与订单分布;以及提出新型的多智能体 DRL 框架,帮助司机获得更好的订单并做出重新定位的决策。
然而,尽管这些 DRL 方法在订单派发问题上表现出了巨大的优势,但它们需要智能体与环境进行交互以收集海量数据来进行模型训练。这给将这些算法投入实际应用带来了巨大的挑战,因为在线与环境交互可能会导致严重的负面后果,包括降低司机的收入、损害乘客的乘车体验,以及增加运营成本并引发危险行为。为了解决这些问题,离线深度强化学习(Offline DRL)作为一种极具前景的技术应运而生。与传统的在线或离线策略(off-policy)DRL 相比,离线 DRL 通过历史日志数据集来训练智能体,不需要智能体与环境进行交互,从而避免了学习过程中的不良后果。研究人员一直尝试在不同领域开发离线深度强化学习(Offline DRL)算法,包括推荐系统(Swaminathan 等,2017;Xiao & Wang,2021;Deffayet 等,2023)、医疗健康(Fatemi 等,2022;Tang 等,2022)以及自动驾驶(Shi 等,2021;Fang 等,2022),并取得了令人满意的性能。开发离线 DRL 的一个核心挑战在于如何获取大规模的历史日志真实世界数据。幸运的是,得益于移动设备和通信技术的发展,出于商业和安全目的,包含订单数据和车辆 GPS 数据在内的大规模网约车数据被记录了下来,同时"数据造福社会"(Data for Social Good)倡议也使得这些数据可用于学术研究。这些数据为我们开发用于网约车订单派发的高效离线 DRL 算法提供了一个良好的契机。
然而,即便拥有海量的日志数据,针对网约车订单派发问题开发高效的离线深度强化学习(Offline DRL)仍然面临着以下三大核心挑战:
- 外推误差(Extrapolation Error): 这是由于当前策略(Policy)所访问的数据分布,与历史日志数据集(Logged data)的数据分布之间存在不一致性所导致的。
- 动态非确定性动作空间(Dynamic Nondeterministic Action Space): 在网约车订单派发场景中,每一次可能的"司机-车辆"匹配都被视为一个动作。因此,无论是连续控制算法(如基于 BCQ 和 DDPG 的算法),还是现有的具有固定输出单元的离线 DRL 算法(如 Discrete BCQ),都无法直接应用于订单派发问题。
- 实时性保证(Real-time Guarantee): 在面对大规模智能体(车辆)和庞大动作量(订单池)的实际场景下,我们需要在极短的有限时间内生成决策,以满足乘客的即时出行需求。
为了应对上述三个挑战,在这项工作中,我们开发了一个名为 NondBREM 的大规模订单派发非确定性离线强化学习框架。该框架仅从累积的日志数据中学习策略,从而避免了与环境进行高昂且不安全的交互。在 NondBREM 中,我们首先基于真实的日志数据构建了一个用于离线训练的数据集。随后,我们开发了一个非确定性批量约束 Q 学习(NondBCQ)模块,通过考虑动态非确定性的动作空间,来解决算法的外推误差问题。在此基础上,我们进一步利用了一个集成了多值网络与多头网络的随机集成混合(REM)模块(Agarwal, Schuurmans, and Norouzi 2020),以提高模型的泛化能力和鲁棒性。我们工作的主要贡献可以概括为以下几点:
-
我们开发了一个用于实时、大规模订单派发的非确定性离线深度强化学习(DRL)框架,称为 NondBREM。它仅从历史日志数据中学习策略,并通过限制动作集来提升性能,能够非常容易地集成到现有的订单派发系统中。
-
在 NondBREM 中,我们设计了一个非确定性 BCQ 模块,该模块不仅能有效降低外推误差,还能完美应对动态非确定性的动作空间。同时,我们还引入了 REM 模块 来增强模型的泛化性与鲁棒性。
-
在包含 50,000 多辆车和 2,000 万个订单的真实世界大规模网约车数据集上进行了广泛的实验。结果表明,在在线和离线场景下,我们的非确定性离线 DRL 算法 NondBREM 表现均优于传统的 DRL 方法,使订单响应率提升了 3.76%。
问题陈述(Problem Statement)
形式上,我们将订单派发问题建模为一个马尔可夫博弈(Markov Game, MG)(Littman 1994)。该博弈由一个五元组 G = ( N , S , A , R , P , γ ) G = (N, S, A, R, P, \gamma) G=(N,S,A,R,P,γ) 定义,其中 S S S 是状态集; A A A 是动作集; R R R 是回报(奖励)函数; P P P 是状态转移概率函数; γ \gamma γ 是折扣因子,而 N N N 代表智能体的数量。每个要素的详细描述如下:
- N N N(智能体数量) : 我们将当前时间段内可被派发的车辆(即没有乘客的空闲车辆)视为智能体, N N N 即为可用车辆的数量。我们将城市划分为一组网格(Grids),位于同一个网格内的车辆共享相同的状态和动作集,即它们是同质的(Homogeneous)。
- 状态 s t ∈ S s_t \in S st∈S : s t s_t st 表示在时间段 t t t 的全局状态。 s t i s_t^i sti 表示智能体 i i i 在时间段 t t t 的状态。形式上,它被表示为一个四元组: s t i = ( l , n v , n o , t ) s_t^i = (l, n_v, n_o, t) sti=(l,nv,no,t),其中 l l l 是智能体 i i i 所在网格的编号, n v n_v nv 表示当前网格内可用车辆的数量, n o n_o no 表示当前网格中排队等待的订单数量, t t t 表示当前的时间段。
- 动作 A t ∈ A A_t \in A At∈A : 在本问题中,我们将可用司机与订单的所有可能匹配视为动作集。对于每个智能体 i i i, A t i A_t^i Ati 表示智能体 i i i 在时间段 t t t 的动作。一个动作可以表示为一个五元组 ( s , e , g , d , p ) (s, e, g, d, p) (s,e,g,d,p),它由订单的起点网格编号、终点网格编号、订单生成的时间段、预计行程耗时以及订单价格组成。
- 状态转移 : 我们假设状态转移是确定性的,即在送单过程中不存在订单取消或变更的情况。经过 T T T 个时间步长后,智能体到达订单的目的地,其状态将被更新,同时收到相应的回报。
- 回报(Reward) : 回报决定了优化的目标。我们使用订单价格的 0.1 0.1 0.1 倍作为回报。这种线性变换有利于神经网络的收敛。这在以往的研究和我们的实验中都被证明是行之有效的。
对于每个在时间段 t t t 的智能体 i i i, A t i ∈ A A_t^i \in A Ati∈A 和 r t i r_t^i rti 分别表示其动作集和回报函数。状态转移发生在每次决策(即动作执行)之后。智能体在时间 t t t 的状态 s t i s_t^i sti 将在时间 t + 1 t+1 t+1 转移为 s t + 1 i s_{t+1}^i st+1i,并且智能体会从环境中获得回报。
基于上述定义,每个智能体的主要目标是学习如何最大化从 t t t 到 T T T 的累积回报 G t : T G_{t:T} Gt:T:
max G t : T = max ∑ t = 0 T γ t r t i , 其中 a t i ∼ π θ ( s t i ) ( 1 ) \max G_{t:T} = \max \sum_{t=0}^{T} \gamma^t r_t^i, \quad \text{其中 } a_t^i \sim \pi_\theta(s_t^i) \quad (1) maxGt:T=maxt=0∑Tγtrti,其中 ati∼πθ(sti)(1)
其中,由参数 θ \theta θ 参数化的 π θ ( ⋅ ) \pi_\theta(\cdot) πθ(⋅) 表示针对时间 t t t 状态的策略。
方法
NondBREM 框架概述
在这项工作中,我们提出了一种名为 NondBREM 的非确定性离线强化学习框架。NondBREM 的整体框架如图 1 所示。NondBREM 主要由两个核心组件构成:
- 非确定性批量约束 Q 学习(NondBCQ)模块:该模块利用相似度来约束动态且非确定性的动作空间,旨在减少算法的推断误差(外推误差)并降低复杂度。
- 随机集合混合(REM)模块:该模块将多个价值网络与多头网络相结合,旨在提高模型的泛化能力与鲁棒性。
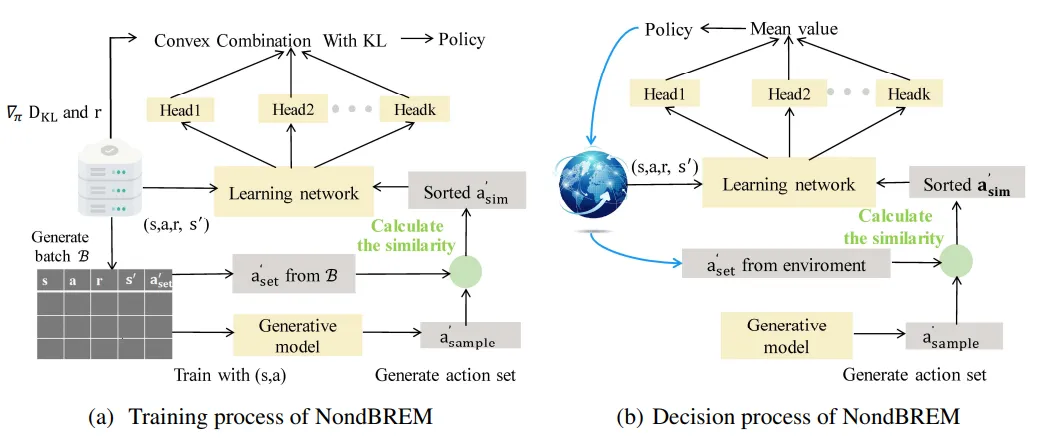
图 1:(a) 描述了 NondBREM 的训练过程。其 Q 值神经网络分为两个部分,即底层共享的学习网络和顶层的多头(multi-head)网络。图中绿色圆圈处包含三个步骤:计算两个集合的相似度矩阵、从相似度矩阵中获取相似度向量、根据相似度进行排序并截取 a s i m ′ a'{sim} asim′ 以获得集合 a s i m ′ a'{sim} asim′。(b) 描述了该模型的推理(推断)过程,即利用训练好的网络与模拟环境进行交互。
NondBCQ(非确定性批量约束 Q 学习)
由于存在推断误差(外推误差),传统的 on/off-policy 强化学习(RL)方法(如 DQN 和 DDPG)很难适应真实世界的数据,因此近期的许多工作都聚焦于数据驱动的深度强化学习(DRL),即离线强化学习(offline DRL)。最流行的离线强化学习方法之一是批量约束 Q 学习(BCQ),它通过生成与离线数据集中相似的状态和动作,来减少真实数据集与策略所访问的生成数据之间的分布偏移。
然而,在我们的场景设定中,车辆与订单的每一次可能匹配都被视为一个动作,因此动作集并不是固定的,并且我们只能选择由环境提供的订单,这使得 BCQ 并不适用于我们的场景。针对这种动态且非确定性的动作空间问题,本文提出了一种 NondBCQ 方法。
具体而言:
- 我们首先移除了标准 BCQ 网络中的扰动网络(disturbance network)。
- 随后,我们计算了生成的动作集与来自真实离线数据集的动作集之间的余弦相似度矩阵。
- 最后,我们根据相似度对真实数据集中的动作进行排序。
通过这种方式,便可以获得一个与数据集中动作相似的动作集。在此之后,我们利用获取到的动作集来计算目标 Q 值。
由于我们的设定中存在多个智能体(agents),如果每个智能体都与环境进行交互,环境将会变得不稳定。因此,我们优化了智能体的联合策略,并尽可能最大化车辆分布与订单分布之间的匹配率,从而带来了能够轻松应对动态智能体且计算开销更低的优势。
算法 1 展示了 NondBCQ 的流程,具体细节如下:
我们首先获取 B B B 个转换元组 ( s , a , r , s ′ , a s e t ′ ) (s, a, r, s', a'{set}) (s,a,r,s′,aset′),其中 ( s , a ) (s, a) (s,a) 是当前时段的状态-动作对,而 ( s ′ , a s e t ′ ) (s', a'{set}) (s′,aset′) 是下一时段的状态-动作对。 s ′ s' s′ 被用于通过一个变分自编码器(VAE)网络生成一个与 a s e t ′ a'{set} aset′ 具有相同长度 n n n 的动作集 a s a m p l e ′ a'{sample} asample′,该 VAE 网络是在真实数据集中的所有 ( s , a ) (s, a) (s,a) 对上训练得到的。
接着,以余弦相似度作为度量标准,计算大小为 n × n n \times n n×n 的 a s e t ′ a'{set} aset′ 与 a s a m p l e ′ a'{sample} asample′ 之间的相似度矩阵 M M M。需要注意的是, a s e t ′ a'{set} aset′ 和 a s a m p l e ′ a'{sample} asample′ 都是动作集,前者是来自离线数据的动作集,而后者是由 VAE 网络生成的动作集。这里的相似度被用来缩小实际决策中的动作分布与离线数据集中的动作分布之间的差距,从而减少推断误差(外推误差)。
我们根据一个动作与 a s a m p l e ′ a'{sample} asample′ 中所有动作之间的最大相似度,对 a s e t ′ a'{set} aset′ 中的动作进行排序,并保留一部分相似度较大的动作作为新的动作集 a s i m ′ a'_{sim} asim′。具体而言,计算相似度和构建新集合的具体操作过程如下:
-
我们定义并计算一个相似度矩阵 M M M,其中 M i , j Mi, j Mi,j 表示 a s e t ′ a'{set} aset′ 中的第 i i i 个元素与 a s a m p l e ′ a'{sample} asample′ 中的第 j j j 个元素之间的余弦相似度。
-
在计算出相应的相似度矩阵后,我们将相似度矩阵中每一行的最大值放入相似度向量 m m m 中,其中 m k mk mk 代表 a s e t ′ a'{set} aset′ 的第 k k k 个元素与 a s a m p l e ′ a'{sample} asample′ 中所有元素之间的最大相似度。
-
随后,我们根据相似度向量 m m m 对 a s e t ′ a'{set} aset′ 进行降序排序,并将其裁剪至长度 β × n \beta \times n β×n,以获得动作集 a s i m ′ a'{sim} asim′。 a s i m ′ a'_{sim} asim′ 即对应新的动作集。在后续的目标 Q 值计算中,将从此集合中选择具有最大值的动作。
结合 KL 散度(KL divergence)优化,算法 1 中的优化目标如下:
L θ = ∑ i ( Q ^ θ ( s , a ) − Q θ i ( s , a ) ) 2 + η D K L \mathcal{L}{\theta} = \sum{i}(\hat{Q}{\theta}(s,a) - Q{\theta_i}(s, a))^2 + \eta D_{KL} Lθ=i∑(Q^θ(s,a)−Qθi(s,a))2+ηDKL Q ^ θ ( s , a ) = r + γ max a i ∼ a s i m ′ λ min j = 1 , 2 Q θ j ′ ( s ′ , a i ) + ( 1 − λ ) max j = 1 , 2 Q θ j ′ ( s ′ , a i ) ( 2 ) \hat{Q}{\theta}(s,a) = r + \gamma \max{a_i \sim a'_{sim}} \left \\lambda \\min_{j=1,2} Q_{\\theta'_j}(s', a_i) + (1 - \\lambda) \\max_{j=1,2} Q_{\\theta'_j}(s', a_i) \\right \quad (2) Q^θ(s,a)=r+γai∼asim′maxλj=1,2minQθj′(s′,ai)+(1−λ)j=1,2maxQθj′(s′,ai)(2)
算法 1:NondBCQ
输入 :批次(Dataset) B B B,时间步长 T T T,目标网络更新率 τ \tau τ,小批量数据大小(mini-batch size) B B B,最大候选订单与车辆数量的比例 β \beta β,最小权重系数 λ \lambda λ, D K L D_{KL} DKL 系数 η \eta η。
初始化 :使用随机参数 θ 1 , θ 2 , ω \theta_1, \theta_2, \omega θ1,θ2,ω 初始化 Q 网络 Q θ 1 Q_{\theta_1} Qθ1、 Q θ 2 Q_{\theta_2} Qθ2 以及变分自编码器(VAE) G ω = ( E ω 1 , D ω 2 ) G_\omega = (E_{\omega_1}, D_{\omega_2}) Gω=(Eω1,Dω2);初始化目标网络 Q θ 1 ′ , Q θ 2 ′ Q_{\theta'1}, Q{\theta'_2} Qθ1′,Qθ2′,令 θ 1 ′ ← θ 1 , θ 2 ′ ← θ 2 \theta'_1 \leftarrow \theta_1, \theta'_2 \leftarrow \theta_2 θ1′←θ1,θ2′←θ2。参数: θ 1 , θ 2 , ω 1 , ω 2 \theta_1, \theta_2, \omega_1, \omega_2 θ1,θ2,ω1,ω2。
1: for t = 1 t = 1 t=1 to T T T do
2: \quad 从批次 B B B 中采样一个小批量(mini-batch)包含 B B B 个转换元组的集合 ( s , a , r , s ′ , a s e t ′ ) (s, a, r, s', a'_{set}) (s,a,r,s′,aset′)
3: \quad 计算 μ , σ = E ω 1 ( s , a ) \mu, \sigma = E_{\omega_1}(s, a) μ,σ=Eω1(s,a),生成动作 a ~ = D ω 2 ( s , z ) \tilde{a} = D_{\omega_2}(s, z) a~=Dω2(s,z),其中隐变量 z ∼ N ( μ , σ ) z \sim \mathcal{N}(\mu, \sigma) z∼N(μ,σ)
4: \quad 更新 VAE 参数: ω ← arg min ω ∑ ( a − a ~ ) 2 + D K L ( N ( μ , σ ) ∣ ∣ N ( 0 , 1 ) ) \omega \leftarrow \arg\min_\omega \sum (a - \tilde{a})^2 + D_{KL}(\mathcal{N}(\mu, \sigma) \mid\mid \mathcal{N}(0, 1)) ω←argminω∑(a−a~)2+DKL(N(μ,σ)∣∣N(0,1))
5: \quad 从状态 s ′ s' s′ 中获取 a s e t ′ a'_{set} aset′ 的长度 n n n 以及当前区域内的可用车辆数量 n ′ n' n′
6: \quad 从 VAE 中采样 n n n 个动作: { a i ∼ G ω ( s ′ ) } i = 1 n \{a_i \sim G_\omega (s')\}{i=1}^n {ai∼Gω(s′)}i=1n,作为样本集 a s a m p l e ′ a'{sample} asample′
7: \quad 计算 a s a m p l e ′ a'{sample} asample′ 与 a s e t ′ a'{set} aset′ 之间的相似度矩阵 M i , j M_{i,j} Mi,j
8: \quad 提取每行最大值存入向量: m k = max ( M i = 1 , 2 , ... n , j = k ) mk = \max(Mi = 1, 2, \\dots n, j = k) mk=max(Mi=1,2,...n,j=k)
9: \quad 根据向量 m m m 对 a s e t ′ a'{set} aset′ 进行降序排序,并将动作集的大小截断至 β × n \beta \times n β×n,从而获得新集合 a s i m ′ a'{sim} asim′
10: \quad 计算优化目标损失函数 L θ \mathcal{L}_{\theta} Lθ
11: \quad 更新 Q 网络参数: θ i ← arg min L θ \theta_i \leftarrow \arg\min \mathcal{L}_{\theta} θi←argminLθ
12: \quad 更新目标网络: θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ \theta'_i \leftarrow \tau\theta_i + (1 - \tau)\theta'_i θi′←τθi+(1−τ)θi′
13: end for
D K L D_{KL} DKL 优化项用于优化派单后订单分布与车辆分布之间的距离。这采用了一种非显式的通信方式,使多辆车的移动更加协同。
D K L D_{KL} DKL 对参数 θ i \theta_i θi 的梯度是利用链式法则推导出来的:
∇ θ i D K L = ∇ π D K L ⋅ ∇ θ i π \nabla_{\theta_i}D_{KL} = \nabla_{\pi}D_{KL} \cdot \nabla_{\theta_i}\pi ∇θiDKL=∇πDKL⋅∇θiπ = n t j ∑ i = 1 N p t + 1 i 1 N v e h i c l e − 1 n t + 1 i ⋅ ∇ θ i π ( 3 ) = n_{t}^{j}\sum_{i=1}^{N}p_{t+1}^{i}\left\\frac{1}{N_{vehicle}} - \\frac{1}{n_{t+1}\^{i}}\\right \cdot \nabla_{\theta_i}\pi \quad (3) =ntji=1∑Npt+1iNvehicle1−nt+1i1⋅∇θiπ(3)
π \pi π 对 θ i \theta_i θi 的梯度为:
∇ Q i ( s , a ) π ( a ∣ s ) ⋅ ∇ θ i Q i ( s , a ) ( 4 ) \nabla_{Q_i(s,a)}\pi(a | s) \cdot \nabla_{\theta_i}Q_i(s, a) \quad (4) ∇Qi(s,a)π(a∣s)⋅∇θiQi(s,a)(4)
最终, L θ \mathcal{L}_{\theta} Lθ 对 θ i \theta_i θi 的梯度计算如下:
∇ θ i L θ = ∇ θ i ∑ i ( Q ^ θ ( s , a ) − Q θ i ( s , a ) ) 2 + η ∇ θ i D K L ( 5 ) \nabla_{\theta_i}\mathcal{L}{\theta} = \nabla{\theta_i}\sum_{i}(\hat{Q}{\theta}(s,a) - Q{\theta_i}(s, a))^2 + \eta\nabla_{\theta_i}D_{KL} \quad (5) ∇θiLθ=∇θii∑(Q^θ(s,a)−Qθi(s,a))2+η∇θiDKL(5)
在目标 Q 值的计算中,本文沿用了 BCQ 的做法。具体而言,使用两个 Q 值的凸组合作为目标 Q 值。 λ \lambda λ 具有两个作用:第一,给较小的 Q 值赋予更大的权重,从而避免 Q 值神经网络的过估计问题;第二,可以控制未来时间步的不确定性。在这里,我们使用均方误差(MSE)作为损失函数。 η \eta η 用于控制 D K L D_{KL} DKL 的范围。
表 1 阐明了用于计算 KL 优化项梯度的变量。 τ \tau τ 是网络更新的幅度(步长), β \beta β 用于控制最终动作集 a s i m ′ a'{sim} asim′ 的大小,满足 n ′ / n ≤ β ≤ 1 n'/n \le \beta \le 1 n′/n≤β≤1。其中, n n n 是 a s e t ′ a'{set} aset′ 的长度(表示等待中订单的数量),而 n ′ n' n′ 指的是当前状态下可派单的车辆数量。这意味着最终动作集 a s i m ′ a'_{sim} asim′ 的长度介于 n ′ n' n′ 和 n n n 之间。当 β \beta β 趋近于 1 时,动作集往往会变得不受控制。当 β \beta β 趋近于 n ′ / n n'/n n′/n 时,我们的方法会通过相似度而不是 Q 值来选择动作。
- N N N:网格的数量
- n t + 1 i n_{t+1}^{i} nt+1i:在时间 t + 1 t+1 t+1 时,网格 i i i 中的空闲车辆数量
- n t j n_{t}^{j} ntj:在时间 t t t 时,网格 j j j 中的空闲车辆数量
- p t + 1 i p_{t+1}^{i} pt+1i:在时间 t + 1 t+1 t+1 时,网格 i i i 中的订单比例(率)
表1:重要符号
Q 学习通过状态-动作输入来学习动作价值函数 Q ( s , a ) Q(s, a) Q(s,a)。 Q ( s , a ) Q(s, a) Q(s,a) 计算累积回报的期望,公式如下:
Q ( s , a ) = E π G t : T ∣ s t i = s , a t i = a ( 6 ) Q(s, a) = \mathbb{E}_{\pi}G_{t:T} \\mid s_{t}\^{i}=s, a_{t}\^{i}=a \quad (6) Q(s,a)=EπGt:T∣sti=s,ati=a(6)
随后基于 Q 函数做出决策。Q 函数网络的贝尔曼方程(Bellman equation)可以写作:
Q ( s t i , a t i ) = α Q ( s t i , a t i ) + ( 1 − α ) r t i + γ ⋅ E a t + 1 i ∼ π ( s t + 1 i ) \[ Q ( s t + 1 i , a t + 1 i ) ] ( 7 ) Q(s_{t}^{i}, a_{t}^{i}) = \alpha Q(s_{t}^{i}, a_{t}^{i}) + (1 - \alpha)\leftr_{t}\^{i} + \\gamma \\cdot \\mathbb{E}_{a_{t+1}\^{i} \\sim \\pi(s_{t+1}\^{i})}\[Q(s_{t+1}\^{i}, a_{t+1}\^{i})\right] \quad (7) Q(sti,ati)=αQ(sti,ati)+(1−α)rti+γ⋅Eat+1i∼π(st+1i)\[Q(st+1i,at+1i)](7)
通过离线训练获得策略后,在推理部署(即决策)阶段,我们根据 Q 值对动作进行排序,并选择对应前 n n n 个最大 Q 值的订单作为动作。公式如下:
π ( s , n ) = a ∈ A ( s ) ∣ Q ( s , a ) ≥ Q ( s , a n + 1 ) ( 8 ) \pi(s, n) = a \in \mathcal{A}(s) \mid Q(s, a) \ge Q(s, a_{n+1}) \quad (8) π(s,n)=a∈A(s)∣Q(s,a)≥Q(s,an+1)(8)
其中, a i a_i ai 是状态 s s s 下对应前 n n n 个最大 Q 值的动作。 n n n 是当前区域内的空闲车辆数量。该公式为当前区域内的所有车辆选择订单。
随机集合混合(REM)
为了提高算法的泛化性能,我们利用随机集合混合(Random Ensemble Mixture, REM),通过凸组合(convex combination)将多个 Q 值估计结合起来,从而得到最终的 Q 值。
在训练阶段,REM(随机集合混合)共享底层网络,并利用多个上层多头(header)网络的输出值来计算加权损失函数。该加权损失函数被用于训练多头网络和底层网络。多头网络可以有效避免 Q 值估计偏差的问题,并增强策略网络的鲁棒性与泛化能力。
在推理(推断)阶段,联合决策是在策略约束下做出的。这可以使策略所访问的数据分布与记录的离线数据集相似,从而缓解分布外(out-of-distribution, OOD)查询的问题。同时,REM 算法还能增强我们模型的泛化能力。最终 NondBREM 的伪代码如算法 2 所示。
NondBREM 中的优化目标 L θ \mathcal{L}_{\theta} Lθ 如下:
L θ = E s , a , r , s ′ , a s e t ′ ∼ B E α ∼ P Δ \[ ℓ λ ( δ θ α ) ] + η D K L ( 9 ) \mathcal{L}{\theta} = \mathbb{E}{s,a,r,s',a'{set} \sim \mathcal{B}} \left \\mathbb{E}_{\\alpha \\sim P_{\\Delta}} \\left\[ \\ell_{\\lambda} (\\delta_{\\theta}\^{\\alpha}) \\right \right] + \eta D{KL} \quad (9) Lθ=Es,a,r,s′,aset′∼BEα∼PΔ\[ℓλ(δθα)]+ηDKL(9) δ θ α ( s , a , r , s ′ , a s e t ′ ) = ∑ k α k Q θ k ( s , a ) − r − γ max a ′ ∼ a s i m ′ ∑ k α k Q θ ′ k ( s ′ , a ′ ) ( 10 ) \delta_{\theta}^{\alpha}(s, a, r, s', a'{set}) = \sum{k} \alpha_k Q_{\theta}^k(s, a) - r - \gamma \max_{a' \sim a'{sim}} \sum{k} \alpha_k Q_{\theta'}^k(s', a') \quad (10) δθα(s,a,r,s′,aset′)=k∑αkQθk(s,a)−r−γa′∼asim′maxk∑αkQθ′k(s′,a′)(10)
其中 ℓ λ \ell_{\lambda} ℓλ 是由下式给出的 Huber 损失:
ℓ λ ( u ) = { 1 2 u 2 , if ∣ u ∣ ≤ λ λ ( ∣ u ∣ − 1 2 λ ) , otherwise ( 11 ) \ell_{\lambda}(u) = \begin{cases} \frac{1}{2}u^2, & \text{if } |u| \le \lambda \\ \lambda \left(|u| - \frac{1}{2}\lambda\right), & \text{otherwise} \end{cases} \quad (11) ℓλ(u)={21u2,λ(∣u∣−21λ),if ∣u∣≤λotherwise(11)
P Δ P_{\Delta} PΔ 表示标准 ( K − 1 ) (K-1) (K−1) 单形(simplex) Δ ( K − 1 ) = { α ∈ R K : α 1 + α 2 + ⋯ + α K = 1 ; α k ≥ 0 ; k = 1 , ... K } \Delta^{(K-1)} = \{\alpha \in \mathbb{R}^K : \alpha_1+\alpha_2+\dots+\alpha_K = 1; \alpha_k \ge 0; k = 1, \dots K\} Δ(K−1)={α∈RK:α1+α2+⋯+αK=1;αk≥0;k=1,...K} 上的概率分布。 D K L D_{KL} DKL 的梯度计算与 NondBCQ 类似。 η \eta η 是用于控制 D K L D_{KL} DKL 范围的超参数。
NondBREM 通过在 ( K − 1 ) (K-1) (K−1) 单形上混合概率,来训练一组 Q 函数逼近器,并将多个 Q 值的凸组合作为最终的 Q 值估计量。我们利用 α k \alpha_k αk 对多个上层网络的损失进行加权,从而获得用于训练多头网络的最终损失。
在动作选择阶段,使用 K K K 个 Q 网络的平均值作为最终的 Q 值:
Q ( s , a ) = ∑ k Q θ k ( s , a ) / K ( 12 ) Q(s, a) = \sum_{k} Q_{\theta}^k(s, a)/K \quad (12) Q(s,a)=k∑Qθk(s,a)/K(12)
实验数据
我们使用来自某大型城市、跨越八周 lunar 的真实网约车数据来评估我们的算法。共使用了两类数据,包括车辆 GPS 数据以及来自 5 万多辆车的 2000 多万条订单数据。该数据集的时间跨度为 2021 年 9 月至 2021 年 11 月。
- 车辆 GPS 数据:GPS 数据是通过每辆网约车上的车载设备收集的。每条 GPS 记录都包含描述车辆实时状态的字段,包括车辆 ID、时间戳以及经纬度。
- 车辆订单数据:网约车平台会收集每个订单的信息。用于派单的特征包括订单生成时间、出发地经纬度、目的地经纬度、订单价格、订单结束时间、车辆 ID 等。
数据集构建 :我们利用这些数据生成了一个五元组数据集 ( s , a , r , s ′ , a s e t ′ ) (s, a, r, s', a'_{set}) (s,a,r,s′,aset′) 来训练价值函数。在我们的设定中,五元组数据可以分为四个部分:状态、动作、回报和智能体数量。状态和动作中主要包含三类元素:位置索引、时间段、车辆数量和订单数量。在 GPS 数据中,我们拥有每辆车的经纬度,因此很容易获取位置索引。我们将一天划分为 144 个时段,每个时段长 10 分钟。对于回报,我们很容易通过订单价格来生成。最后,GPS 数据包含了丰富的时间和位置信息,这使我们能够获取车辆的初始空闲时间和非工作时间,从而动态地控制车辆数量。总而言之,我们拥有足够的信息来生成训练离线强化学习算法所需的数据。
值得注意的是,由于我们的模拟器采用采样方法来获取订单,因此订单数据同时用于策略训练和性能评估阶段。为了准确评估模型的性能,我们对数据进行了固定划分。我们使用前 6 周的数据来训练模型,并将最后 2 周的数据加载到模拟器中进行性能评估。
基线方法与实验设置
本节中的实验证明了 NondBREM 能够克服离线派单任务中的推断误差(外推误差),并取得优异的性能。我们评估了多个算法的性能以进行对比,并简要描述了每个算法以及实验的细节。本文采用了几种最先进的(state-of-the-art)算法作为基线方法(baselines),包括:
- IL(独立学习) (Van Hasselt, Guez, and Silver 2016):每个智能体都使用相同的双重深度 Q 网络(Double DQN)进行派单,不考虑智能体之间的相互交互。
- 表格价值函数(TVal) (Xu et al. 2018):状态评估仅考虑两个变量,即时间和位置。其价值是通过在离散的表格空间中进行动态规划获取的,并利用历史数据来更新表格。
- 基于 KL 散度的方法(KL-Based) (Zhou et al. 2019):在独立派单的基础上,引入了 KL 散度优化项,以缩小可用车辆与等待中订单分布之间的距离。这是一种离策(off-policy)方法。
- PolarB (Yansheng Wang and Tong 2020):一种基于价值的方法,曾在 KDD Cup 2020 强化学习(RL)赛道的派单任务中获得第一名。
需要注意的是,KL-Based 和 PolarB 均在在线(online)和离线(offline)两种情况下进行了训练,并且本文报告了这两种设置下的性能。我们使用 "KL-Based offline" 和 "PolarB offline" 来表示离线训练。而 IL 方法仅用作在线场景下训练的基线。
我们利用两个广泛采用的指标来评估所提出的方法,包括单日司机总收入(也称为派单得分,dispatch score)以及相比于基线方法的单日订单响应率(ORR)提升率。具体而言,若一个订单的价格记为 r a r_a ra,则派单得分定义为:
d i s p a t c h _ s c o r e = ∑ a ∈ A r a (13) dispatch\score= \sum{a \in \mathcal{A}} r_a \tag{13} dispatch_score=a∈A∑ra(13)
其中 A \mathcal{A} A 为单日内被接受的订单集合。方法 M M M 的 ORR 提升率 O R R I R M ORRIR_M ORRIRM 公式化为:
O R R I R M = ( O R R M − O R R I L ) / O R R I L (14) ORRIR_M = (ORR_M - ORR_{IL}) / ORR_{IL} \tag{14} ORRIRM=(ORRM−ORRIL)/ORRIL(14)
微调后的超参数设置如下: γ = 0.95 \gamma = 0.95 γ=0.95、 τ = 1 \tau = 1 τ=1、 λ = 0.75 \lambda = 0.75 λ=0.75、 β = min ( max ( n ′ / n , 0.9 ) , 1 ) \beta = \min(\max(n'/n, 0.9), 1) β=min(max(n′/n,0.9),1)。 β \beta β 是在一个范围内进行选择的,我们稍后将分析不同 β \beta β 值对性能的影响。我们的实验使用 Python 语言基于 TensorFlow 1.15 实现,并在配备 Intel® Xeon® E5-2620 v4 @ 2.10GHz CPU 和单张 16GB Nvidia Tesla V100 GPU 的环境中执行。
结果与分析
从表 2 中可以看出,尽管传统的强化学习方法在在线(online)场景中具有可接受的性能表现,但它们在离线(offline)场景中的表现却无法超越 IL 在在线场景中的表现。我们的 NondBREM 采用离线数据训练,其性能超越了在在线和离线状态下训练的传统强化学习算法。我们报告了为期两周的平均派单得分和 ORRIR(订单响应率提升率)。
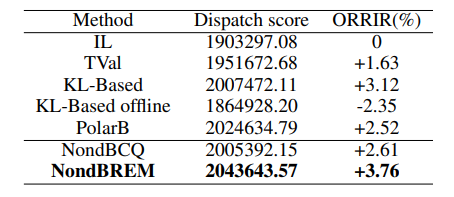
表2:不同算法下的性能。NondBCQ和NondBREM是我们提出的算法。
同时,在图 2 中,我们报告了五种主要方法在离线训练和在线决策过程中的误差。决策阶段的误差仅用于评估,并不会更新 Q 函数。为了统一结果,我们报告了均方误差(MSE)。可以看出,这五种算法在实际决策阶段的误差均大于离线训练中的误差。这种误差是由训练数据分布与策略访问数据分布的不一致(即分布偏移)所导致的。我们提出的两种方法(注:指 NondBCQ 和 NondBREM)在这两种情况下的误差差值是最小的,这验证了我们的方法能够减少推断误差(外推误差)并学习到最优的派单策略。
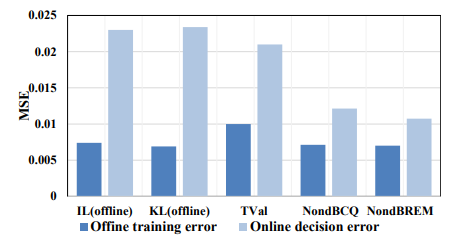
图2:离线训练和在线决策过程中不同算法的均方误差(MSE)。
消融实验
β \beta β 的影响 。在 NondBCQ 和 NondBREM 中,超参数 β \beta β 用于控制动作集的大小,且满足 n ′ / n ≤ β ≤ 1 n'/n \le \beta \le 1 n′/n≤β≤1。当 β = 1 \beta = 1 β=1 时,动作集的大小与环境给出的订单数量相同。根据我们的统计, n ′ / n n'/n n′/n 的范围从 0.6 到大于 1 不等,因此我们测试了五个不同的 β \beta β 值,以评估不同 β \beta β 值对算法性能的影响,包括:
- β 1 = min ( max ( n ′ / n , 0.8 ) , 1 ) \beta_1 = \min(\max(n'/n, 0.8), 1) β1=min(max(n′/n,0.8),1)
- β 2 = min ( max ( n ′ / n , 0.85 ) , 1 ) \beta_2 = \min(\max(n'/n, 0.85), 1) β2=min(max(n′/n,0.85),1)
- β 3 = min ( max ( n ′ / n , 0.9 ) , 1 ) \beta_3 = \min(\max(n'/n, 0.9), 1) β3=min(max(n′/n,0.9),1)
- β 4 = min ( max ( n ′ / n , 0.95 ) , 1 ) \beta_4 = \min(\max(n'/n, 0.95), 1) β4=min(max(n′/n,0.95),1)
- β 5 = 1 \beta_5 = 1 β5=1
我们使用不同的 β \beta β 值来训练 NondBREM,并报告了它们的损失(losses)和归一化累积回报。从图 3 中可以看出,当 β = β 3 \beta = \beta_3 β=β3 时,累积回报值最大。然而,当 β = β 1 \beta = \beta_1 β=β1 时,损失值最小。当 β \beta β 较小时,动作集也较小。尽管在这种情况下相应的损失较小,但动作过于受限,从而导致性能较差。而当 β = 1 \beta = 1 β=1 时,较大的损失会导致较大的误差,同样导致性能较差。当 β \beta β 设置合理时,我们的算法可以大大减少推断误差(外推误差),并获得更好的外推性能。
动作约束模块的有效性 。我们研究了 NondBREM 中动作约束模块的有效性。我们主要通过改变变分自编码器(VAE)生成网络的约束程度,来评估该模块的重要性。在图 3 中我们可以看到,当 β \beta β 等于 1 时,意味着我们对动作集没有任何限制,因此该算法会退化为传统的强化学习方法。实验表明,在这种情况下,算法的测试误差会变大,而累积回报会变小。当选择较小的 β \beta β 时,测试误差会变小,且累积回报会增加。这表明我们的动作约束模块能够有效减少 NondBREM 的推断误差(外推误差),使其更适合进行离线训练。
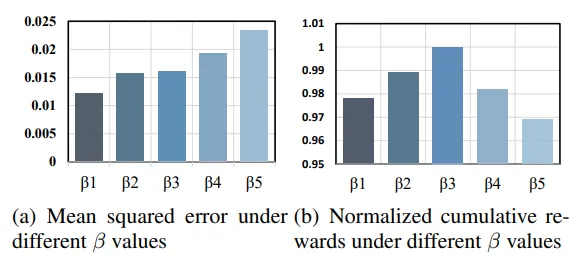
图3:不同β值下在线决策过程中NondBREM的损失值和归一化收益。
数据集大小的影响:我们分析了不同数据规模对离线算法的影响。我们分别使用总数据的 25% 和 50% 对不同的离线算法进行了实验。我们提取了相应数量的转换元组(transitions)用于训练。我们在表 3 中报告了为期两周的平均派单得分。
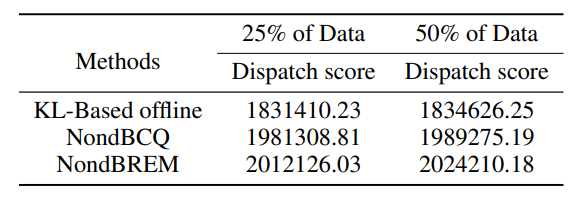
表3:不同数据量下的性能对比
如表 3 所示,当有更多数据可用时,传统算法和离线算法都能取得更好的效果。在不同数据规模的实验中,我们算法的性能均优于传统的强化学习算法。此外,如图 4 所示,更大的数据集促进了算法的收敛。因此,在离线场景下,在更大的数据集上进行训练可以带来更好的策略,并加快算法的收敛速度。
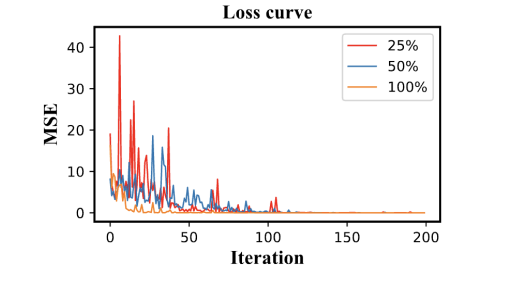
图4:不同数据集大小下NondBREM的收敛情况。每次迭代对应500个训练步骤,报告了200次迭代的学习曲线。
推理时间:对于大规模订单派单任务而言,模型的推理时间至关重要。因此,我们在表 4 中将我们模型的推理时间消耗与基线方法进行了对比。在包含 5 万多辆车(智能体)的实验中,虽然由于引入了 VAE 网络,我们模型的推理时间(1.1435 秒)相比于现有方法更长,但对于大规模实时订单派单而言,这一时间仍然足够短。
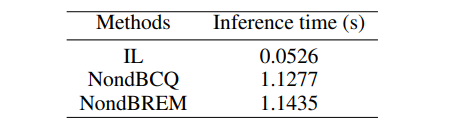
表4:一个 episode 内的平均调度时间
结论
在本文中,我们针对大规模订单派单问题设计了一种名为 NondBREM 的非确定性离线强化学习方法。NondBREM 仅通过积累的日志数据来学习策略,从而避免了与复杂的现实世界环境进行高成本且不安全的交互。在 NondBREM 中,开发了一个非确定性批量约束 Q 学习模块(即 NondBCQ),该模块利用相似度来约束动态非确定性动作空间,以减少算法的推断误差(外推误差);同时,利用一个整合了多个价值网络与多头网络的 REM 模块来提高模型的泛化能力和鲁棒性。在规模宏大的真实网约车数据集上进行的大量实验表明,我们的设计具有优越性,与最先进的(SOTA)基线方法相比,订单响应率(ORR)提升了 3.76%。