深入理解 MySQL 索引底层数据结构与算法
-
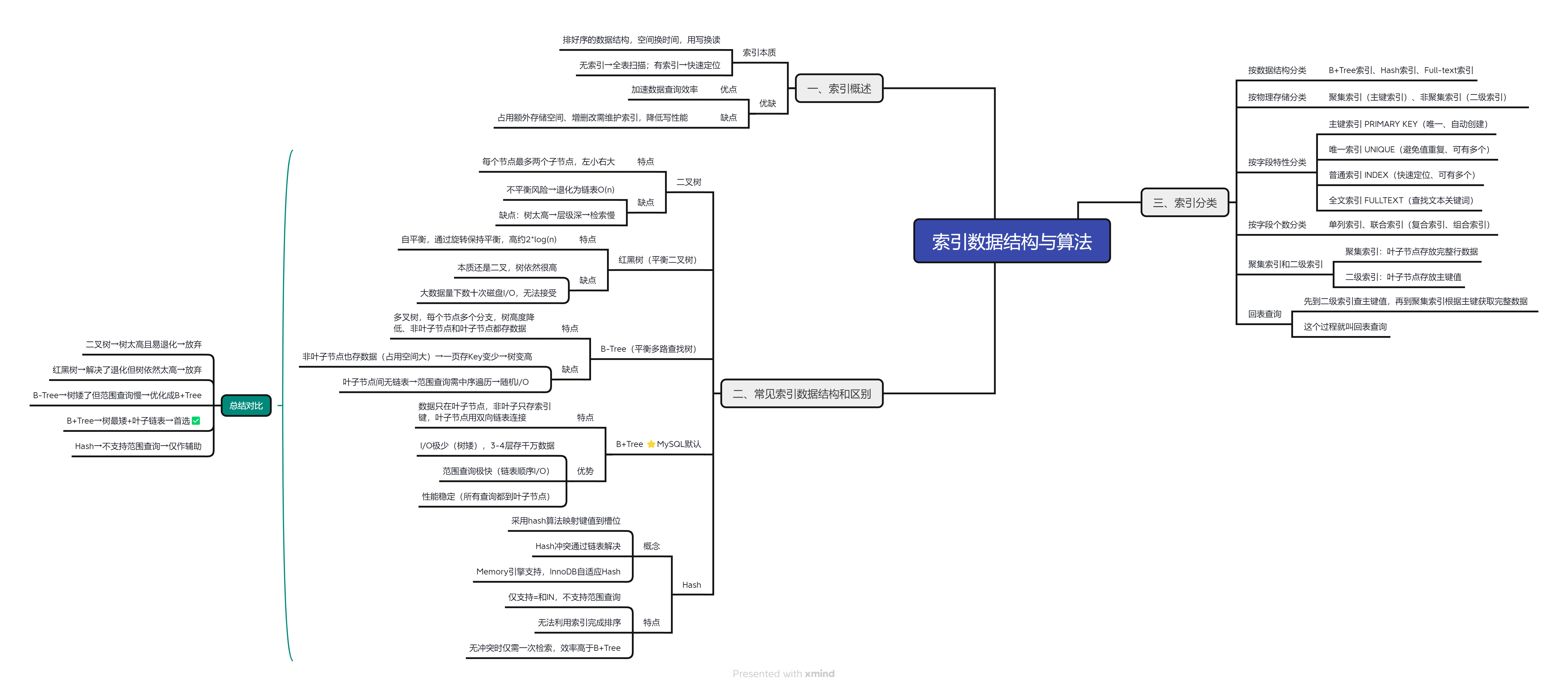
- ✅索引概述
- ✅常见索引数据结构和区别
- ✅Mysql索引分类
- ✅索引跳跃扫描
-
- ☑️1.联合索引案例脚本
- [☑️2.最左前缀与索引跳跃扫描(Index Skip Scan)](#☑️2.最左前缀与索引跳跃扫描(Index Skip Scan))
- ☑️3.索引跳跃扫描原理
- ☑️4.限制条件
- ☑️5.总结
- ✅常见面试题
-
- [1. 什么是索引?索引的优缺点是什么?](#1. 什么是索引?索引的优缺点是什么?)
- [2. 索引常用的数据结构有哪些?为什么 MySQL 最终选择了 B+Tree?](#2. 索引常用的数据结构有哪些?为什么 MySQL 最终选择了 B+Tree?)
- [3. 千万级数据表,B+Tree 索引为什么只需要 3 次 I/O 就能查到数据?](#3. 千万级数据表,B+Tree 索引为什么只需要 3 次 I/O 就能查到数据?)
- [4. 聚集索引、非聚集索引(二级索引)、稀疏索引分别是什么?](#4. 聚集索引、非聚集索引(二级索引)、稀疏索引分别是什么?)
- [5. 为什么 DBA 总推荐使用整型自增主键?](#5. 为什么 DBA 总推荐使用整型自增主键?)
- [6. 为什么不建议使用过长的字段做主键?](#6. 为什么不建议使用过长的字段做主键?)
- [7. InnoDB 二级索引的叶子节点为什么存主键值,而不是磁盘地址?](#7. InnoDB 二级索引的叶子节点为什么存主键值,而不是磁盘地址?)
- [8. 什么是回表查询?如何避免回表?](#8. 什么是回表查询?如何避免回表?)
- [9. 联合索引的底层存储结构是怎样的?和单列索引有什么不同?](#9. 联合索引的底层存储结构是怎样的?和单列索引有什么不同?)
- [10. 什么是最左前缀原则?为什么会有这个原则?](#10. 什么是最左前缀原则?为什么会有这个原则?)
- [11. 联合索引 `(a, b, c)`,以下查询哪些能用索引?](#11. 联合索引
(a, b, c),以下查询哪些能用索引?) - [12. 联合索引设计时,字段顺序怎么选?](#12. 联合索引设计时,字段顺序怎么选?)
- [13. MySQL 8.0 的索引跳跃扫描(Index Skip Scan)是什么?](#13. MySQL 8.0 的索引跳跃扫描(Index Skip Scan)是什么?)
- [14. 索引跳跃扫描的执行原理和效率因素是什么?](#14. 索引跳跃扫描的执行原理和效率因素是什么?)
- [15. 索引跳跃扫描有哪些限制条件?](#15. 索引跳跃扫描有哪些限制条件?)
- [16. 有了 Index Skip Scan,还需要遵守最左前缀吗?](#16. 有了 Index Skip Scan,还需要遵守最左前缀吗?)
- [17. EXPLAIN 中如何判断使用了 Index Skip Scan?](#17. EXPLAIN 中如何判断使用了 Index Skip Scan?)
- [18. 索引分类有哪些维度?InnoDB、MyISAM、Memory 分别支持哪些索引类型?](#18. 索引分类有哪些维度?InnoDB、MyISAM、Memory 分别支持哪些索引类型?)
- [18. 索引分类有哪些维度?InnoDB、MyISAM、Memory 分别支持哪些索引类型?](#18. 索引分类有哪些维度?InnoDB、MyISAM、Memory 分别支持哪些索引类型?)
✅索引概述
索引是一种数据结构,他将数据提前按照一定的规则进行排序和组织,能够帮助快速定位到数据,加快数据库表中数据的查找和访问速度。
类似书籍的目录、文件夹、标签、房号...都可以帮助我们快速定位,都可以视为索引。
索引的本质:排好序的、专门用来加速查找的数据结构,本质是用空间换时间、用写换读。
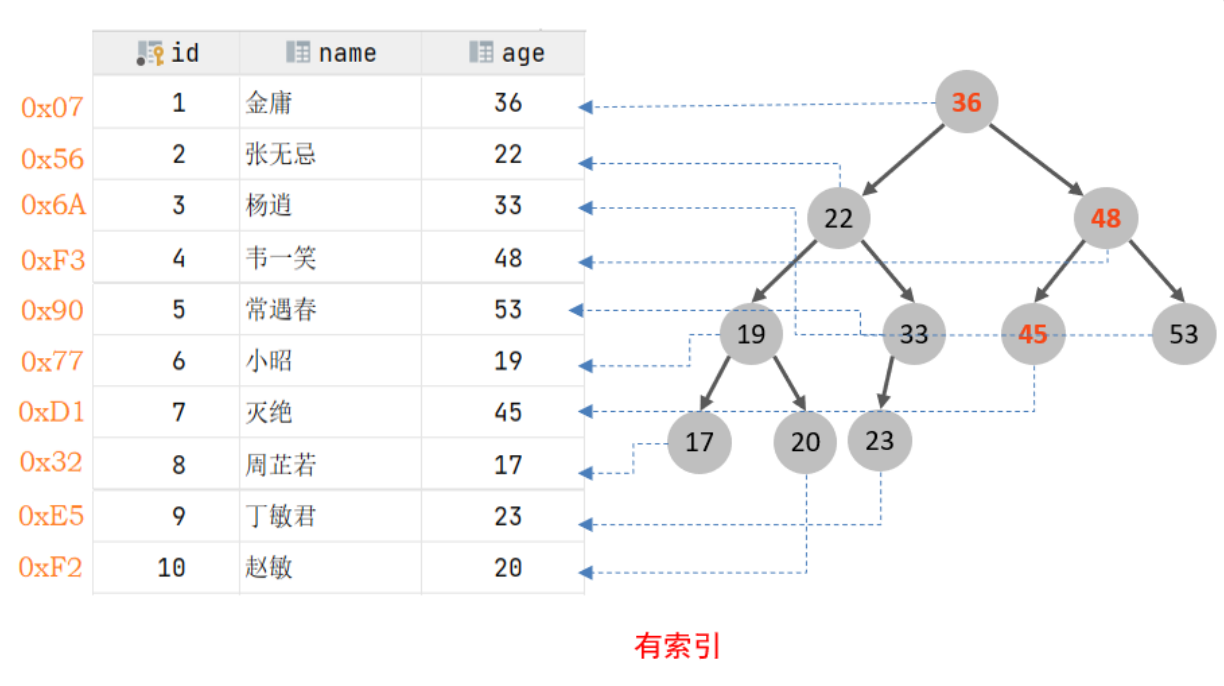
比如查询语句:select * from user where age = 45;
- 在无索引情况下,就需要从第一行开始扫描,一直扫描到最后一行,我们称之为全表扫描,性能很低。
- 如果针对这张表对age字段建立索引(假设就是二叉树索引结构),只需要扫描三次就可以找到数据了,极大的提高的查询的效率。
优点:
- 大幅减少需要扫描的数据量,加快查询。
- 利用有序性,避免额外排序/临时表。
- 唯一索引保证数据唯一性。
- 加速 JOIN、ORDER BY、GROUP BY 等操作。tencent.com+1
缺点:
- 占用额外存储空间。
- 增删改时需要维护索引,降低写性能。
- 索引设计不当(过多、不合理)会导致优化器选错执行计划,反而更慢。
一句话总结:
索引 = 有序数据结构 + 空间换时间 + 读快写慢 + 必须根据查询模式设计。
✅常见索引数据结构和区别
索引数据结构包括:
- 二叉树
- 红黑树
- Hash 表
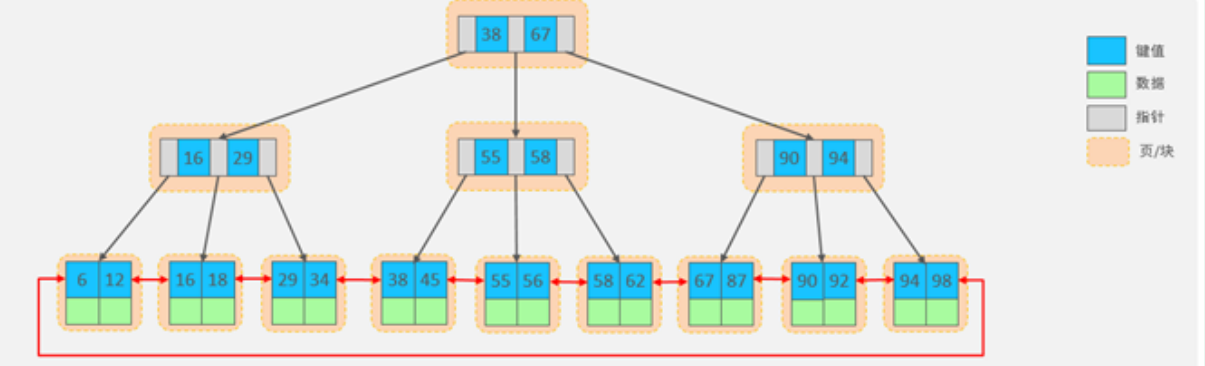
- B-Tree
- B+Tree 结构(B-Tree 变种)
区别:树的高度影响获取数据的性能(每一个树节点都是一次磁盘I/O)
☑️二叉树
**特点:**每个节点最多有两个子节,大在右,小在左 ,数据随机性情况下树杈越明显。
缺点:
- 不平衡风险:顺序插入时,会形成一个链表,查询性能大大降低。
- 树太高:大数据量情况下,层级较深,检索速度慢。
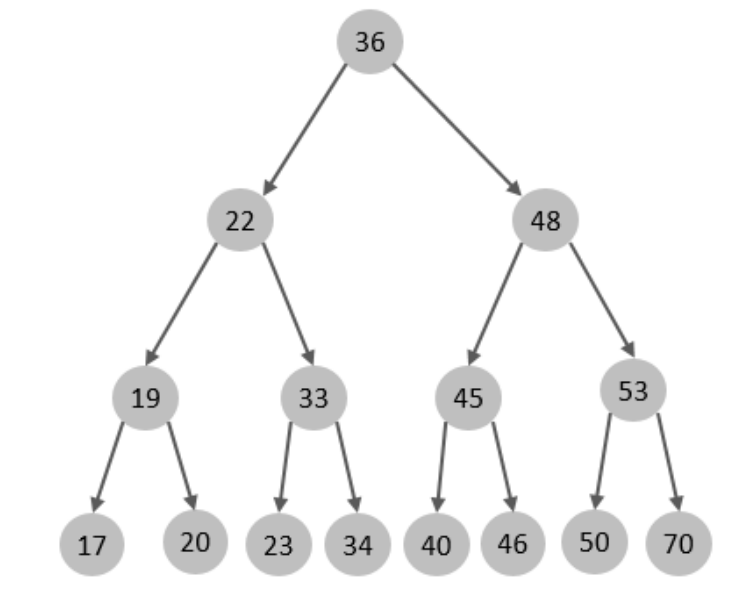
如果数据是按顺序依次进入,则树的高度则会很高 (形成一个链表结构) , 此时元素的查找效率就等于链表查询O(n), 数据检索效率将极为低下。

☑️红黑树(平衡二叉树)
特点 :自平衡二叉树,通过旋转保持平衡,高度约 2 * log(n)。
缺点:
- 本质还是二叉:虽然平衡了,但树的高度依然很大。
- I/O 效率低:假设数据量 1000 万,红黑树高度可能几十层,意味着几十次磁盘 I/O,无法接受。
红黑树是一颗自平衡二叉树,那这样即使是顺序插入数据,最终形成的数据结构也是一颗平衡的二叉树,结构如下:
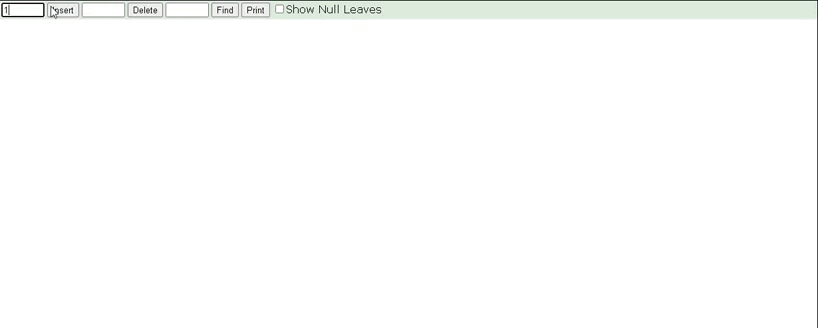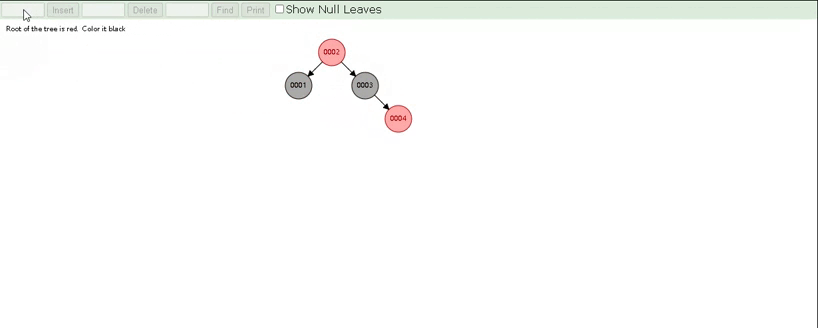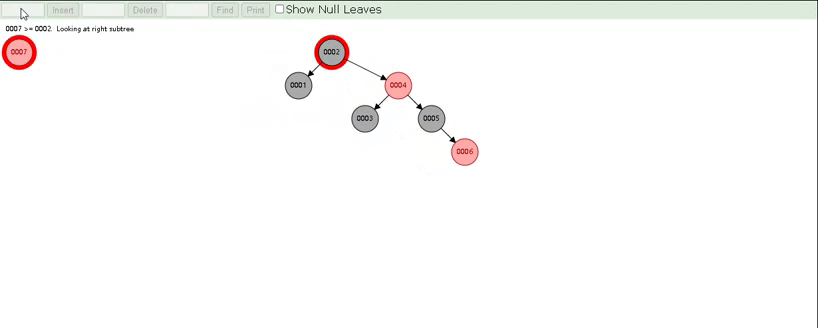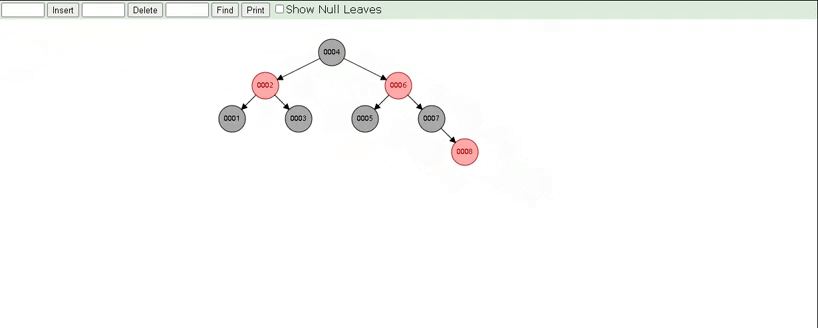
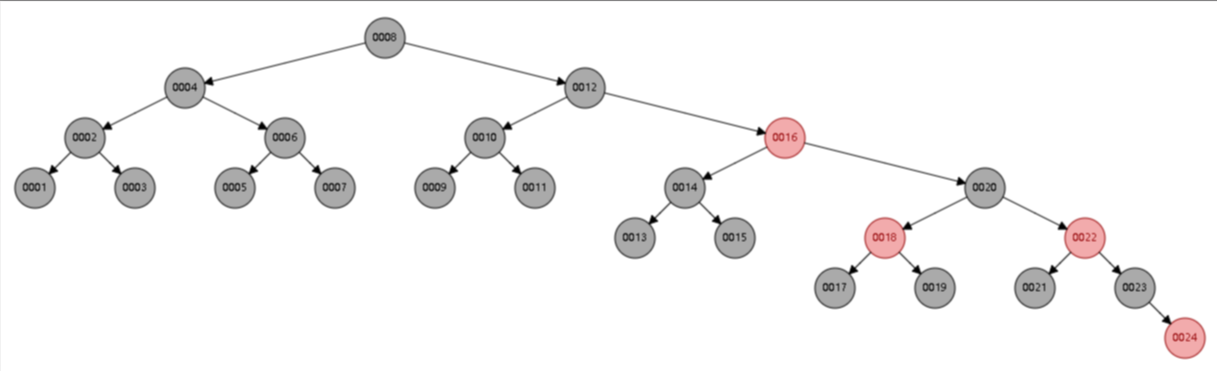
所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,那么什么是B+Tree?在详解B+Tree之前,先来介绍一个B-Tree。
☑️B-Tree
B-Tree(B树),又叫平衡多路查找树,是一颗多叉树,每个节点可以有多个分支,即多叉,所以相比较于前面的那些二叉树数据结构又将整体的树高度降低了。
以一颗最大度数(max-degree)为4(4阶)的b-tree为例,那这个B树每个节点最多存储3个key,4个指针:
特点 :多路搜索树,非叶子节点和叶子节点都存数据。
缺点:
- 树相对较高:非叶子节点存了数据(占用空间大),导致一页能存的 Key 变少,树变高,I/O 变多。
- 范围查询性能差:节点之间没有链表指针,做范围扫描需要中序遍历,在节点间反复跳跃(随机 I/O)。
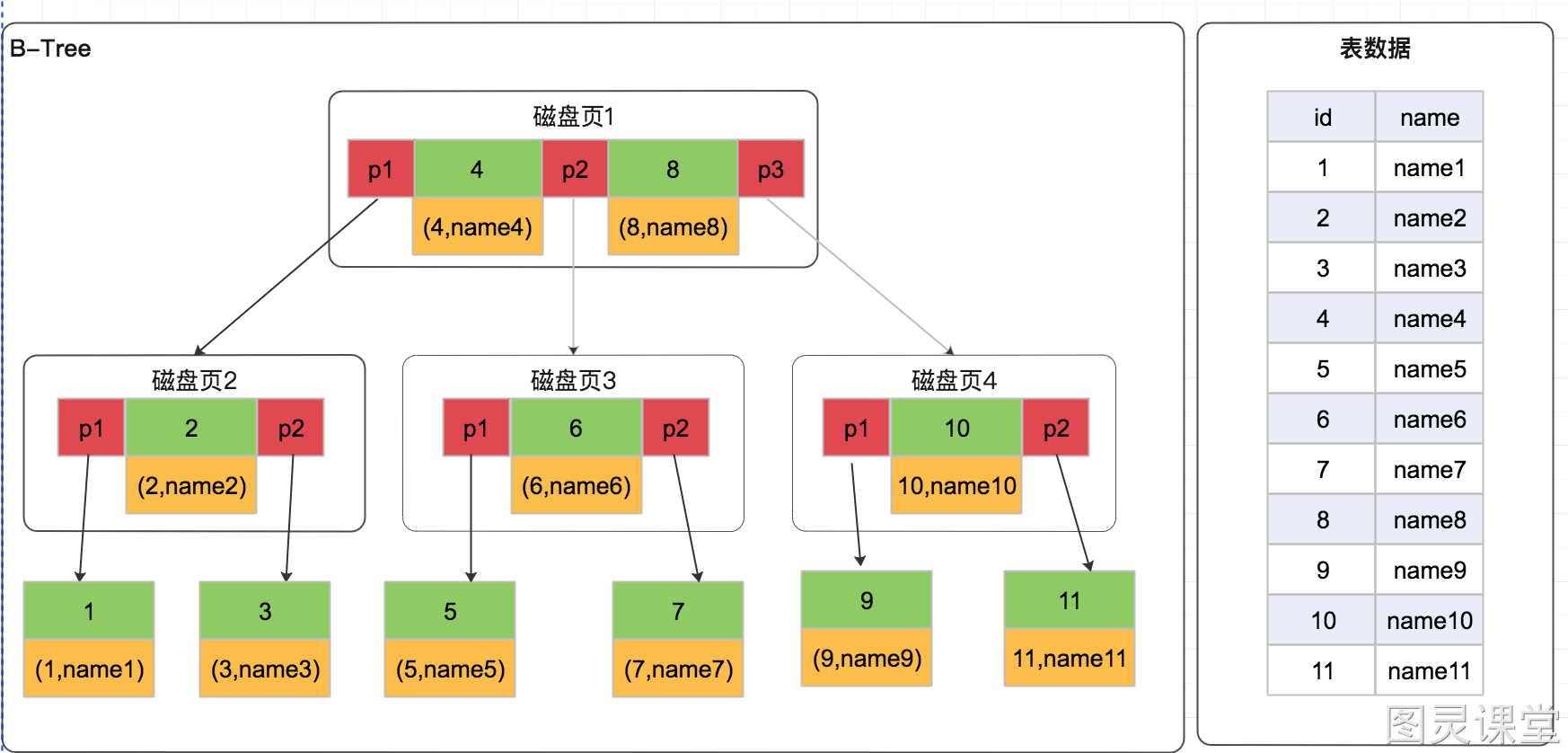
知识小贴士: 树的度数指的是一个节点的子节点个数。比如3阶的B树,每一个节点最多存储2个key,对应3个指针,每个节点可以有3个分支,一旦节点存储的key数量到达2,就会裂变,中间元素向上分裂。
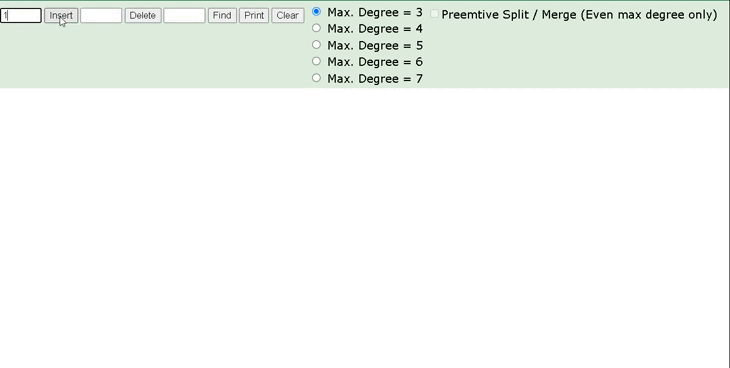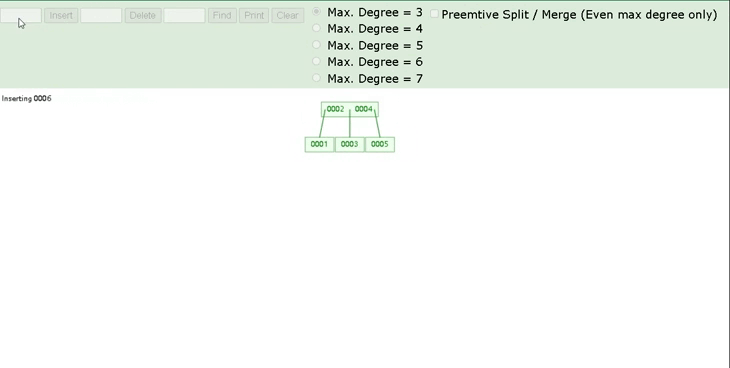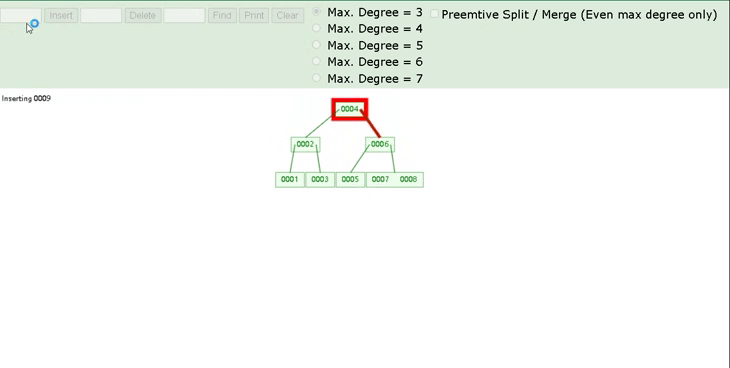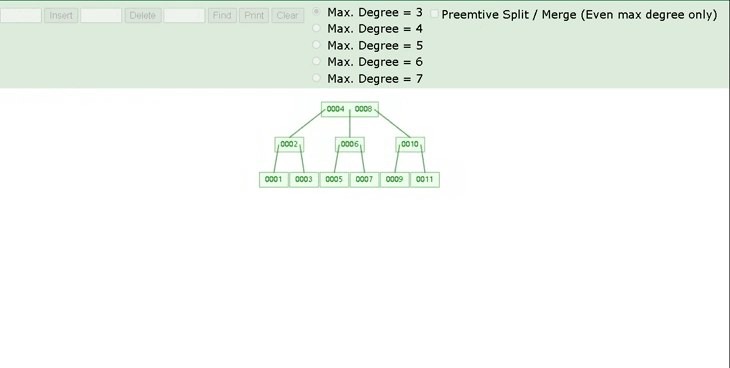
我们可以通过一个数据结构可视化的网站来简单演示一下。 https://www.cs.usfca.edu/\~galles/visualization/BTree.html插入一组数据: 1 2 3 5 6 7 。然后观察一些数据插入过程中,节点的变化情况。
☑️B+Tree
B+Tree是B-Tree的变种,是 MySQL InnoDB 存储引擎默认的索引数据结构。
特点:
- 数据下沉:数据只在叶子节点,非叶子节点只存索引键。
- 叶子串联:所有叶子节点用双向链表连接。
我们以一颗最大度数(max-degree)为3(3阶)的b+tree为例,来看一下其结构示意图:
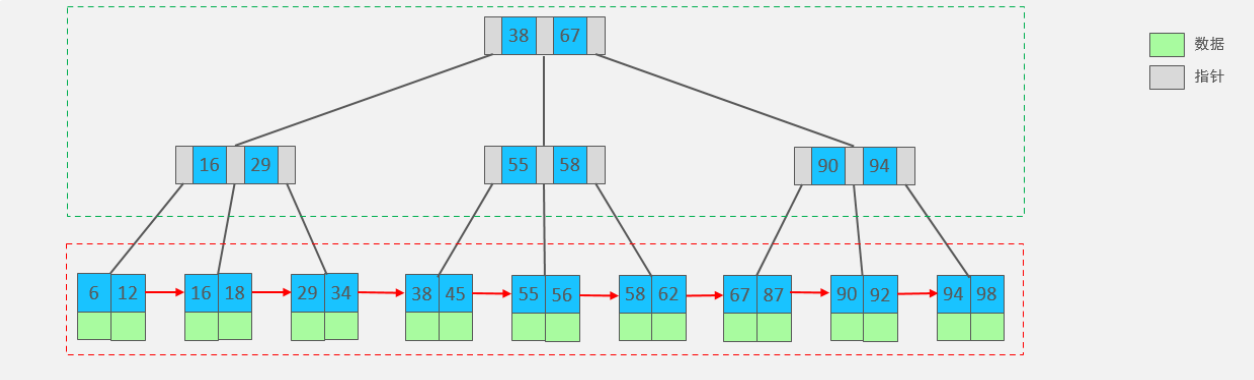
我们可以看到,两部分:
-
绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
-
红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据
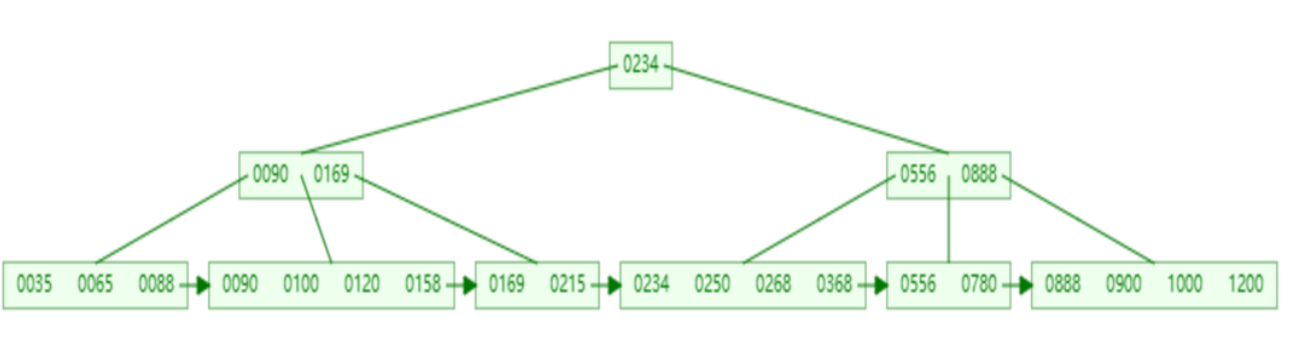
数据结构可视化的网站演示: https://www.cs.usfca.edu/\~galles/visualization/BPlusTree.html
插入一组数据: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88 120 268 250 。然后观察一些数据插入过程中,节点的变化情况。
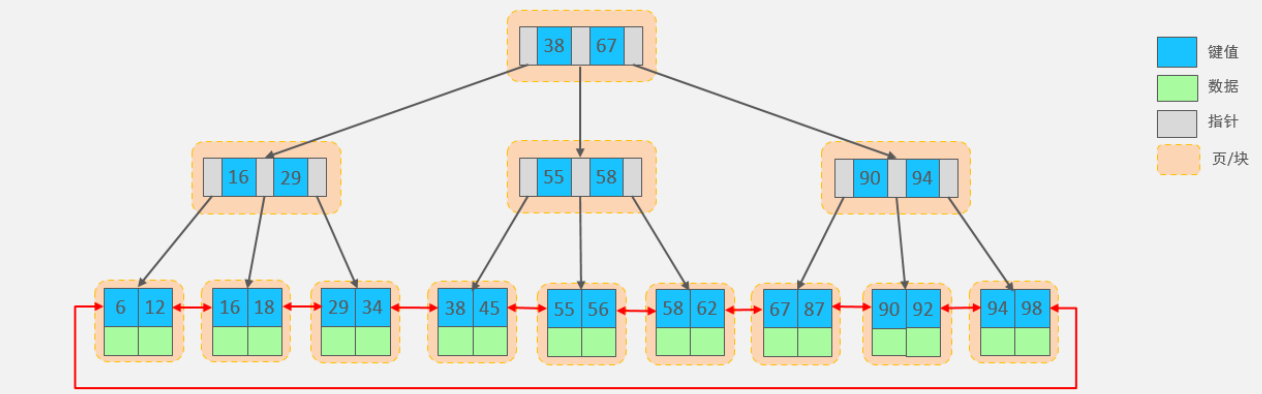
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。
MySQL 选择原因(核心):
- I/O 极少(树矮):
- 非叶子节点不存数据,一页(16KB)能存更多 Key。
- 树高度通常 3-4 层即可存千万级数据,仅需 3-4 次 I/O。
- 范围查询极快:
- 叶子节点形成有序链表,范围扫描只需遍历链表(顺序 I/O),不需要在树中反复跳转。
- 性能稳定:所有查询都要走到叶子节点,耗时波动小。
☑️Hash
在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能,hash索引是InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
-
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
-
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
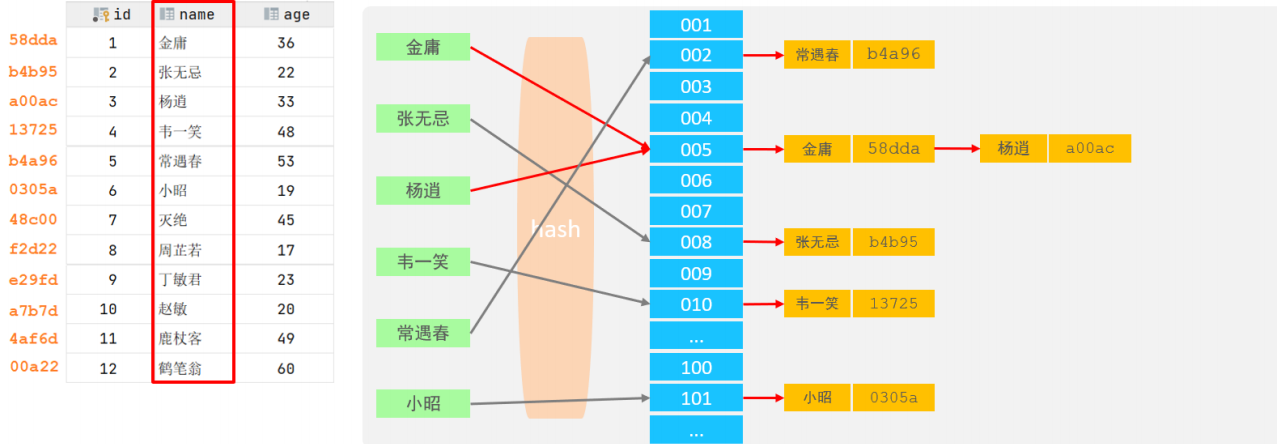
特点:
-
Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,...)
-
无法利用索引完成排序操作
-
查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
思考题:为什么InnoDB存储引擎选择使用B+tree索引结构?
相对于二叉树,层级更少,搜索效率高;
对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
相对Hash索引,B+tree支持范围匹配及排序操作;
☑️总结
- 二叉树 -> 树太高,且易退化 -> 放弃。
- 红黑树 -> 解决了退化,但树依然太高 -> 放弃。
- B-Tree -> 树变矮了,但范围查询慢,非叶存数据浪费空间 -> 在基础上优化成B+树。
- B+Tree -> 树最矮(省 I/O),叶子节点成双向链表(范围查询快),完美适配磁盘数据库 -> 首选。
- Hash 表 -> 不支持范围查询 -> 仅作辅助。
✅Mysql索引分类
在MySQL中索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。常见的索引分类如下:
- 按数据结构分类:B+tree索引、Hash索引、Full-text索引。
- 按物理存储分类:聚集索引、非聚集索引。
- 按字段特性分类:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(INDEX)、全文索引(FULLTEXT)。
- 按字段个数分类:单列索引、联合索引(也叫复合索引、组合索引)。
不同的存储引擎对于索引结构的支持情况。
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| Full-text(全文索引) | 5.6版本之后支持 | 支持 | 不支持 |
在MySQL数据库,关于主键索引、唯一索引、常规索引(联合索引)、全文索引。
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建, 只能 有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
☑️聚集索引和非聚集索引(二级索引)
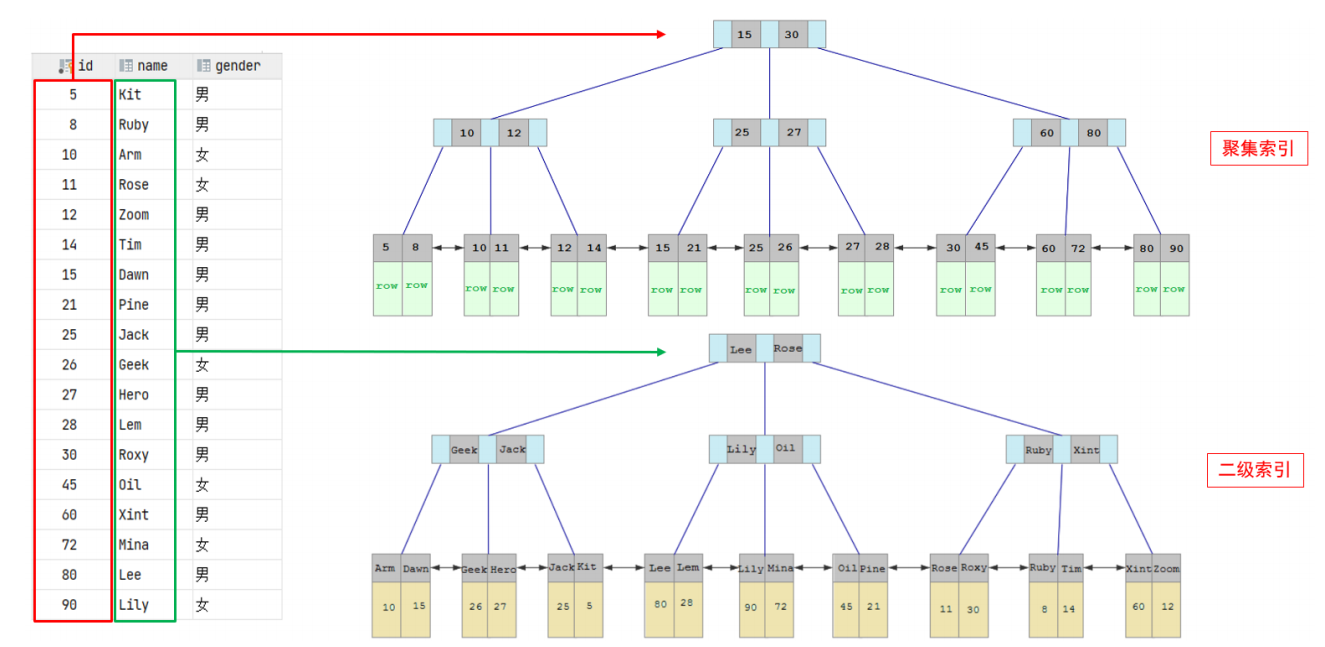
- 聚集索引的叶子节点下挂的是这一行的数据 。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
接下来,我们来分析一下,当我们执行如下的SQL语句时,具体的查找过程是什么样子的。
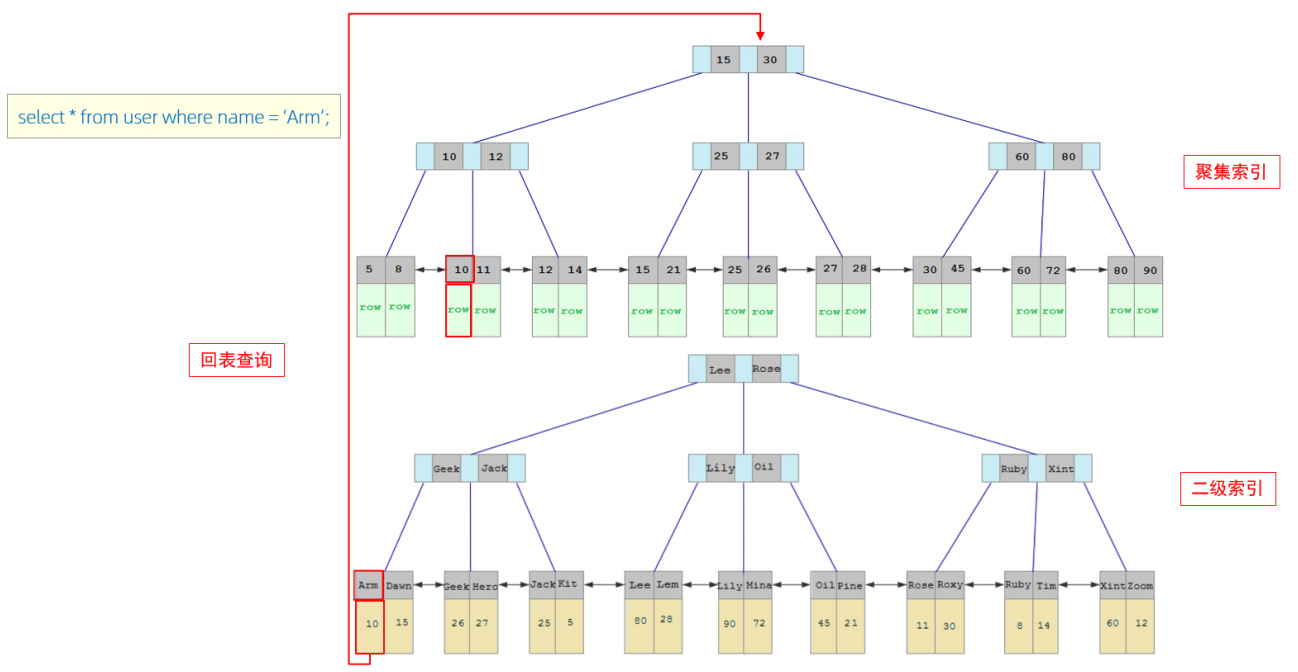
具体过程如下:
-
由于是根据name字段进行查询,所以先根据name='Arm'到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
-
由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。
-
最终拿到这一行的数据,直接返回即可。
☑️回表
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
思考题:
InnoDB主键索引的B+tree高度为多高呢?
假设:
一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB的指针占用6个字节的空间,主键即使为bigint,占用字节数为8。
高度为2:
n * 8 + (n + 1) * 6 = 16*1024 , 算出n约为 1170
1171* 16 = 18736
也就是说,如果树的高度为2,则可以存储 18000 多条记录。
高度为3:
- 1171 * 1171 * 16 = 21939856
也就是说,如果树的高度为3,则可以存储 2200w 左右的记录。
✅索引跳跃扫描
☑️1.联合索引案例脚本
建表语句
sql
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='员工记录表';插入数据
sql
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());查询分析
sql
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';☑️2.最左前缀与索引跳跃扫描(Index Skip Scan)
核心变化:
MySQL 一定是遵循最左前缀匹配的------这句话在 MySQL 8.0 以前是正确的,但在 MySQL 8.0 中不一定成立。
MySQL 8.0.13 引入了 索引跳跃扫描(Index Skip Scan) 优化。
官网参考:
☑️3.索引跳跃扫描原理
示例准备
sql
CREATE TABLE t1 (f1 INT NOT NULL, f2 INT NOT NULL, PRIMARY KEY(f1, f2));
INSERT INTO t1 VALUES
(1,1), (1,2), (1,3), (1,4), (1,5),
(2,1), (2,2), (2,3), (2,4), (2,5);
-- 扩大数据量
INSERT INTO t1 SELECT f1, f2 + 5 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 10 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 20 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 40 FROM t1;
ANALYZE TABLE t1;
EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40;工作原理
虽然 SQL 没有遵循最左前缀原则(只用了 f2 作为查询条件),但经过 MySQL 8.0 的优化后,会通过索引跳跃扫描的方式用到索引。
执行过程(由优化器自动完成):
- 获取
f1字段第一个唯一值 ,即f1 = 1 - 构造
f1 = 1 AND f2 > 40,进行范围查询 - 获取
f1字段第二个唯一值 ,即f1 = 2 - 构造
f1 = 2 AND f2 > 40,进行范围查询
等价于执行:
sql
SELECT f1, f2 FROM t1 WHERE f1 = 1 AND f2 > 40
UNION
SELECT f1, f2 FROM t1 WHERE f1 = 2 AND f2 > 40;适用场景
- 当联合索引的前导列(
f1)区分度低、取值少时,跳跃扫描效果较好 - 反之,如果
f1值非常多,跳跃扫描的查询效率会变慢
注意:不能依赖这个优化。建立联合索引时,仍然优先把区分度高、查询频繁的字段放到最左边。
☑️4.限制条件
索引跳跃扫描的使用存在以下限制:
- 只能单表查询,不能多表 JOIN
- 查询中不能使用 GROUP BY 或 DISTINCT 语句
- 查询的字段必须是索引中的列(即覆盖索引场景)
组合索引形式要求
([A_1, ..., A_k,] B_1, ..., B_m, C [, D_1, ..., D_n])- A、D 可以为空
- B、C 不能为空(即前导列和跳跃列必须存在)
☑️5.总结
| 要点 | 说明 |
|---|---|
| 传统规则 | MySQL 遵循最左前缀匹配(MySQL 8.0 之前) |
| 新特性 | MySQL 8.0.13+ 支持 Index Skip Scan |
| 原理 | 优化器自动枚举前导列各唯一值,用 UNION 方式分别查询 |
| 适用条件 | 单表、无 GROUP BY/DISTINCT、查询字段全在索引中 |
| 最佳实践 | 仍然优先把区分度高的字段放在联合索引最左边 |
✅常见面试题
1. 什么是索引?索引的优缺点是什么?
答:
索引 是一种排好序的数据结构 ,本质是空间换时间、用写换读。它帮助 MySQL 高效获取数据,就像书的目录一样。
优点:
- 大幅减少扫描数据量,加快查询速度
- 利用有序性避免额外排序和临时表
- 唯一索引保证数据唯一性
- 加速 JOIN、ORDER BY、GROUP BY 操作
缺点:
- 占用额外磁盘空间
- INSERT / UPDATE / DELETE 需要同时维护索引,降低写性能
- 索引过多会导致优化器选错执行计划
不应该建索引的情况:
- 表数据量很小(< 几千行,全表扫描更快)
- 频繁更新的字段(维护开销大)
- 区分度极低的字段(如性别,只有男/女)
- WHERE 条件中几乎不用的字段
- 查询中总是需要返回大部分数据的场景(如 > 90% 行)
一句话总结:索引 = 有序数据结构 + 空间换时间 + 读快写慢 + 必须根据查询模式设计。
2. 索引常用的数据结构有哪些?为什么 MySQL 最终选择了 B+Tree?
答:
常用索引数据结构:二叉树 → 红黑树 → B-Tree → B+Tree → Hash。这是一个逐步淘汰的过程:
| 数据结构 | 问题 | 结论 |
|---|---|---|
| 二叉树 | 顺序插入退化为链表,O(n);树高度不可控 | 放弃 |
| 红黑树(平衡二叉树) | 解决了退化,但本质还是二叉,1000 万数据树高约 23~24 层 = 24 次磁盘 I/O | 放弃 |
| B-Tree(多路平衡查找树) | 树变矮了,但非叶子节点也存 data → 一页能存的 key 变少 → 树仍然偏高;节点间无链表 → 范围查询需中序遍历(随机 I/O) | 优化为 B+Tree |
| B+Tree | 数据只存叶子节点,非叶子节点只存索引(冗余),一页能存更多 key → 树最矮;叶子节点用双向链表连接 → 范围查询顺序 I/O | 首选 |
| Hash | 等值查询 O(1),但不支持范围查询和排序 | 仅 Memory 引擎支持,InnoDB 自适应 Hash 作为辅助 |
核心结论 :B+Tree 做到了树最矮、范围最快、性能最稳定,完美适配磁盘数据库的场景。
3. 千万级数据表,B+Tree 索引为什么只需要 3 次 I/O 就能查到数据?
答:
关键原因:MySQL 每次 I/O 读取一页(默认 16KB),B+Tree 非叶子节点不存 data,一页能塞进大量索引条目,导致树高度极低。
计算过程:
假设:一行数据 1K,主键 bigint(8B),指针(6B),页大小 16K
- 非叶子节点:每页可存 16384 ÷ 14 ≈ 1170 个(key + 指针)
- 叶子节点:每页可存 16384 ÷ 1024 ≈ 16 条数据行| B+Tree 高度 | 可存数据量 | 计算公式 |
|---|---|---|
| 2 | ≈ 1.8 万条 | 1170 × 16 |
| 3 | ≈ 2200 万条 | 1170 × 1170 × 16 |
| 4 | ≈ 256 亿条 | 1170³ × 16 |
千万级数据的表,B+Tree 高度通常只有 3 层 ,根节点常驻内存,实际只需 2~3 次磁盘 I/O。
对比红黑树:1000 万数据红黑树要 23~24 次 I/O,B+Tree 只要 3 次------差距近 10 倍。
4. 聚集索引、非聚集索引(二级索引)、稀疏索引分别是什么?
答:
聚集索引(Clustered Index)
- 数据即索引 :叶子节点存放完整的数据行
- 一个表只能有一个(数据只能按一种顺序存放)
- InnoDB 中,主键索引就是聚集索引;无主键则选唯一非空索引;都没有则自动生成隐藏 row_id
非聚集索引 / 二级索引(Secondary Index)
- 叶子节点存放主键值,而非完整数据
- 查完二级索引后需要回表到聚集索引取完整数据
- 一个表可以有多个
稀疏索引(Sparse Index)
- 不是为每条记录建索引,而是每隔一定间隔建一个索引条目
- B+Tree 的非叶子节点本身就是稀疏索引:只指向下一层节点范围,不直接指向数据
| 类型 | 叶子节点内容 | 数量限制 |
|---|---|---|
| 聚集索引 | 完整行数据 | 一个表一个 |
| 非聚集索引(二级索引) | 主键值 | 可多个 |
| 稀疏索引 | 页/范围指针 | --- |
5. 为什么 DBA 总推荐使用整型自增主键?
答:
核心就四个字:性能 + 空间。
① 自增 → 减少页分裂
- 自增主键:INSERT 追加到末尾,写入效率最高
- UUID:随机插入,页面满了就**页分裂(page split)**→ 数据移动、产生碎片、写入变慢
② 整型 → 比较快、占空间小
int4 字节 vs UUID 36 字节,空间差 9 倍- 整型比较速度远超字符串比较
- 主键越小 → 二级索引也越小 → B+Tree 能存更多条目
③ 不建主键会怎样?
- InnoDB 会按优先级:主键 → 第一个唯一非空索引 → 自动生成 6 字节隐藏列
row_id - 隐藏 row_id 不可见、不可用、不可控,所以必须自己建主键
6. 为什么不建议使用过长的字段做主键?
答:
因为二级索引叶子节点存储的是主键值:
聚集索引叶子节点:主键 + 完整行数据
二级索引叶子节点:二级索引字段 + 主键值- 主键越长 → 所有二级索引都跟着变大 → 占用更多磁盘
- 主键越长 → 每页存的索引条目越少 → 树高度越高 → I/O 更多
- int(4B) vs UUID(36B)→ 二级索引空间差 9 倍
最佳实践 :业务需要 UUID 做唯一标识时,用自增整型做主键,UUID 做业务唯一键。
7. InnoDB 二级索引的叶子节点为什么存主键值,而不是磁盘地址?
答:
① 一致性
- 存磁盘地址 → 页分裂/数据迁移后所有索引地址都要更新 → 写放大严重
- 存主键值 → 数据随便移动,只要主键不变,二级索引不受影响
② 节省存储空间
- 每个二级索引都存完整数据 = 数据冗余 N 份 → 磁盘爆炸
- 存主键值,数据只在聚集索引存一份
③ 对比 MyISAM
- MyISAM 存磁盘地址(物理指针)→ 直接寻址快,但数据移动后地址失效
- InnoDB 用主键做"逻辑指针"→ 牺牲一点回表开销,换了极高的一致性
8. 什么是回表查询?如何避免回表?
答:
回表:先用二级索引查到主键值,再拿主键回到聚集索引查完整数据。
SELECT * FROM employees WHERE name = 'LiLei';
① name 二级索引找到 'LiLei' → 拿到主键值 id = 1
② 拿 id = 1 到聚集索引 → 获取完整行数据
③ 返回结果
①→② 就是"回表"。避免回表 → 覆盖索引:查询字段全部在同一个索引中。
sql
-- 会回表
SELECT * FROM employees WHERE name = 'LiLei';
-- 不回表(name, age, position 全在 idx_name_age_position 中)
SELECT name, age, position FROM employees WHERE name = 'LiLei';EXPLAIN 中
Extra列显示Using index表示走了覆盖索引。这也是为什么不建议写SELECT *。
9. 联合索引的底层存储结构是怎样的?和单列索引有什么不同?
答:
联合索引底层还是 B+Tree,区别在于排序规则:先按第一个字段排序,相同时按第二个排序,依此类推。
联合索引 (name, age, position):
├── HanMeimei-23-dev → 主键值
├── LiLei-22-manager → 主键值
└── Lucy-23-dev → 主键值核心区别:
| 维度 | 单列索引 | 联合索引 |
|---|---|---|
| 排序 | 单字段 | 多字段按顺序排序 |
| 最左前缀 | 不需要 | 必须遵守 |
| 覆盖索引 | 单字段 | 多字段联合覆盖,更灵活 |
| 存储 | 多个索引 = 多棵 B+Tree | 一个索引 = 一棵 B+Tree |
联合索引优势 :(a,b,c) 可同时充当 (a) 和 (a,b) 的索引,维护成本低,更容易做覆盖索引。
10. 什么是最左前缀原则?为什么会有这个原则?
答:
最左前缀原则 = 使用联合索引时,查询条件必须从最左列开始连续匹配,不能跳过中间列。
根本原因------由底层 B+Tree 的排序规则决定:
联合索引 (a, b, c) 先按 a 排 → a 相同按 b 排 → b 相同按 c 排。所以 b 只在 a 相同的情况下有序,单独查 b 无法利用索引。
例子 (联合索引 idx_name_age_position):
| 查询 | 能用索引? | 原因 |
|---|---|---|
WHERE name = 'LiLei' |
能 | 从最左列开始 |
WHERE name = 'LiLei' AND age = 22 |
能 | 连续两列匹配 |
WHERE name = 'LiLei' AND position = 'dev' |
部分(仅 name) | 跳过了 age,position 无法用 |
WHERE age = 22 |
不能 | 没从最左列开始 |
口诀:
带头大哥不能死 → 最左列必须出现
中间兄弟不能断 → 不能跳过中间列
范围之后全失效 → 范围查询后的列无法用索引11. 联合索引 (a, b, c),以下查询哪些能用索引?
| 查询条件 | 能用索引 | 用到哪几列 | 说明 |
|---|---|---|---|
WHERE a = 1 |
能 | a | 从最左开始 |
WHERE a = 1 AND b = 2 |
能 | a, b | 连续匹配 |
WHERE a = 1 AND b = 2 AND c = 3 |
能 | a, b, c | 全匹配 |
WHERE a = 1 AND c = 3 |
部分能 | a | 跳过了 b |
WHERE b = 2 |
5.7 不能 / 8.0 可能能 | --- / 取决于 a 区分度 | 8.0 可能触发 Skip Scan |
WHERE b = 2 AND c = 3 |
5.7 不能 / 8.0 可能能 | --- / 取决于 a 区分度 | 同上 |
WHERE a > 1 AND b = 2 |
部分能 | a | 范围后 b 失效 |
WHERE a = 1 ORDER BY b |
能 | a, b | 有序,排序也用上了 |
WHERE a = 1 ORDER BY c |
能过滤 | a(过滤) | 排序不能用(跳 b) |
12. 联合索引设计时,字段顺序怎么选?
答:
等值在前,范围在后;高频在前,低频在后;区分度高的往前靠。
- 区分度高的放最左 → 区分度 =
COUNT(DISTINCT col) / COUNT(*),越接近 1 越好,最快缩小范围 - 等值查询字段在前,范围查询字段在后 → 范围后的列无法用索引
- 查询频率高的放左边 → 大部分查询都能用上
- ORDER BY / GROUP BY 字段尽量包含 → 利用有序性避免 filesort
13. MySQL 8.0 的索引跳跃扫描(Index Skip Scan)是什么?
答:
MySQL 8.0.13 引入的优化。当联合索引**前导列区分度很低(取值很少)**时,即使查询跳过了前导列,优化器也能自动枚举前导列的每个 distinct 值,分别补全条件再 UNION,从而利用索引。
例如 PRIMARY KEY(f1, f2),f1 只有 1 和 2:
sql
-- 用户写的 SQL
SELECT f1, f2 FROM t1 WHERE f2 > 40;
-- 优化器等价于执行
SELECT f1, f2 FROM t1 WHERE f1 = 1 AND f2 > 40
UNION
SELECT f1, f2 FROM t1 WHERE f1 = 2 AND f2 > 40;14. 索引跳跃扫描的执行原理和效率因素是什么?
答:
核心思想:把"跳过前导列"的查询拆成多个"带上完整前缀"的查询,再 UNION。
执行步骤:
- 获取前导列第一个 distinct 值 → 如
f1 = 1 - 补全条件执行 →
f1 = 1 AND f2 > 40 - 获取下一个 distinct 值 →
f1 = 2 - 补全条件执行 →
f1 = 2 AND f2 > 40 - 重复直到所有 distinct 值遍历完,UNION 返回
效率关键:前导列 distinct 值数量。取值越少(如性别 2 个值)→ 效果越好;取值越多(如时间戳百万级)→ 效率越差。
15. 索引跳跃扫描有哪些限制条件?
答:
- 只能单表查询,不支持多表 JOIN
- 不能使用 GROUP BY 或 DISTINCT 语句
- 查询字段必须全是索引中的列(覆盖索引场景)
- 组合索引形式要求
([A_1, ..., A_k,] B_1, ..., B_m, C [, D_1, ..., D_n]),B 和 C 不能为空
16. 有了 Index Skip Scan,还需要遵守最左前缀吗?
答:
必须遵守,Index Skip Scan 只是兜底优化,不能替代正确的索引设计。
原因:
- Skip Scan 是兜底,不是首选 → 只在无法满足最左前缀时才尝试,且不一定生效
- 性能差距巨大 → 前导列区分度高时(如用户 ID),枚举数万个 distinct 值,退化为 N 次查询再 UNION,效率极差
- 不跨版本兼容 → MySQL 5.7 及之前版本没有这个优化
结论:设计索引时,仍然优先把区分度高、查询频繁的字段放最左边。
17. EXPLAIN 中如何判断使用了 Index Skip Scan?
答:
sql
EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40;type列为rangeExtra列出现Using index for skip scan
两个条件同时满足,就说明触发了索引跳跃扫描。
18. 索引分类有哪些维度?InnoDB、MyISAM、Memory 分别支持哪些索引类型?
答:
四个分类维度:
| 维度 | 分类 |
|---|---|
| 数据结构 | B+Tree 索引、Hash 索引、Full-text 索引 |
| 物理存储 | 聚集索引、非聚集索引(二级索引) |
| 字段特性 | 主键索引 PRIMARY、唯一索引 UNIQUE、普通索引 INDEX、全文索引 FULLTEXT |
| 字段个数 | 单列索引、联合索引(复合索引) |
存储引擎支持对比:
| 索引类型 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree | 支持 | 支持 | 支持 |
| Hash | 不支持(但有自适应 Hash) | 不支持 | 支持 |
| Full-text | 5.6 版本之后支持 | 支持 | 不支持 |
18. 索引分类有哪些维度?InnoDB、MyISAM、Memory 分别支持哪些索引类型?
答:
四个分类维度:
| 维度 | 分类 |
|---|---|
| 数据结构 | B+Tree 索引、Hash 索引、Full-text 索引 |
| 物理存储 | 聚集索引、非聚集索引(二级索引) |
| 字段特性 | 主键索引 PRIMARY、唯一索引 UNIQUE、普通索引 INDEX、全文索引 FULLTEXT |
| 字段个数 | 单列索引、联合索引(复合索引) |
存储引擎支持对比:
| 索引类型 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree | 支持 | 支持 | 支持 |
| Hash | 不支持(但有自适应 Hash) | 不支持 | 支持 |
| Full-text | 5.6 版本之后支持 | 支持 | 不支持 |