一、排序的概念及运用
排序的基本概念
排序是指将一组数据按照特定的顺序重新排列的过程,是计算机科学中最基础也是最重要的算法之一。排序的主要目的是为了提高数据检索的效率,使数据更易于处理和分析。
基本术语
- 稳定排序:如果两个相等的元素在排序前后的相对位置保持不变,则该排序算法是稳定的(如插入排序、冒泡排序、归并排序)
- 不稳定排序:不保证相等元素的相对位置(如快速排序、堆排序、选择排序)
- 内部排序:所有数据都能一次性装入内存进行排序
- 外部排序:数据量太大,需要借助外部存储器进行排序
常见排序指标
- 时间复杂度:衡量算法执行时间随数据规模增长的变化程度
- 空间复杂度:衡量算法执行过程中需要的额外存储空间
- 原地排序:指不需要额外空间或仅需要常数级额外空间的排序算法
二、常见排序算法的实现
1.插入排序
基本思想:
插入排序的核心思想是将数组分为已排序区间0, end和未排序区间。算法通过不断将未排序区间的首个元素(tmp = end+1位置)插入到已排序区间的适当位置来完成排序。具体步骤如下:
- 从end位置开始向前比较,若当前元素大于tmp元素,则将该元素后移一位
- end递减,继续比较,直到找到合适位置或end<0
- 将tmp元素插入到end+1位置
- 重复上述过程,直到所有元素都完成排序
动图演示:
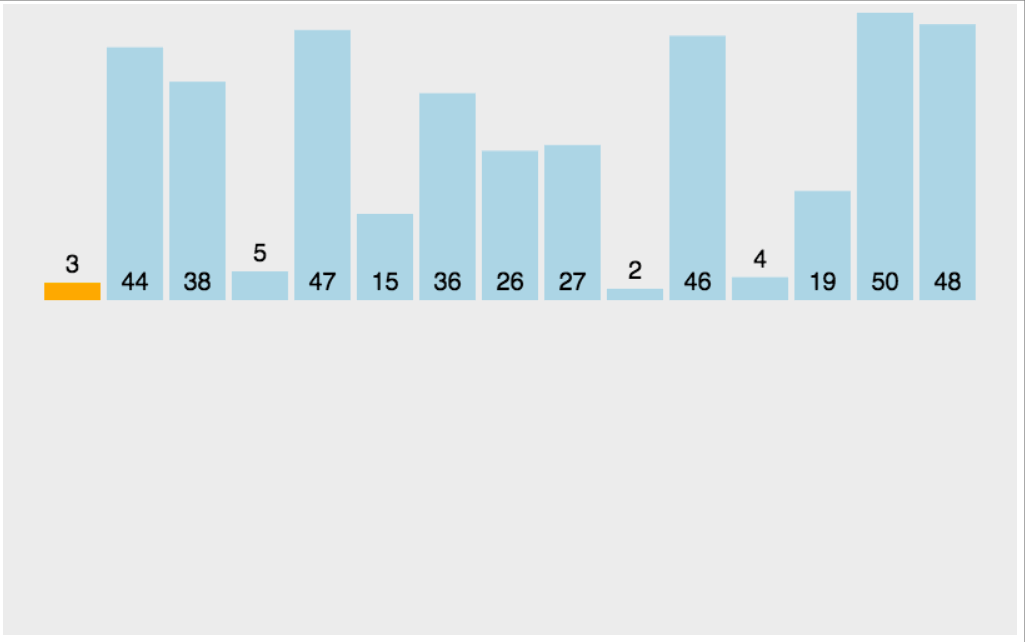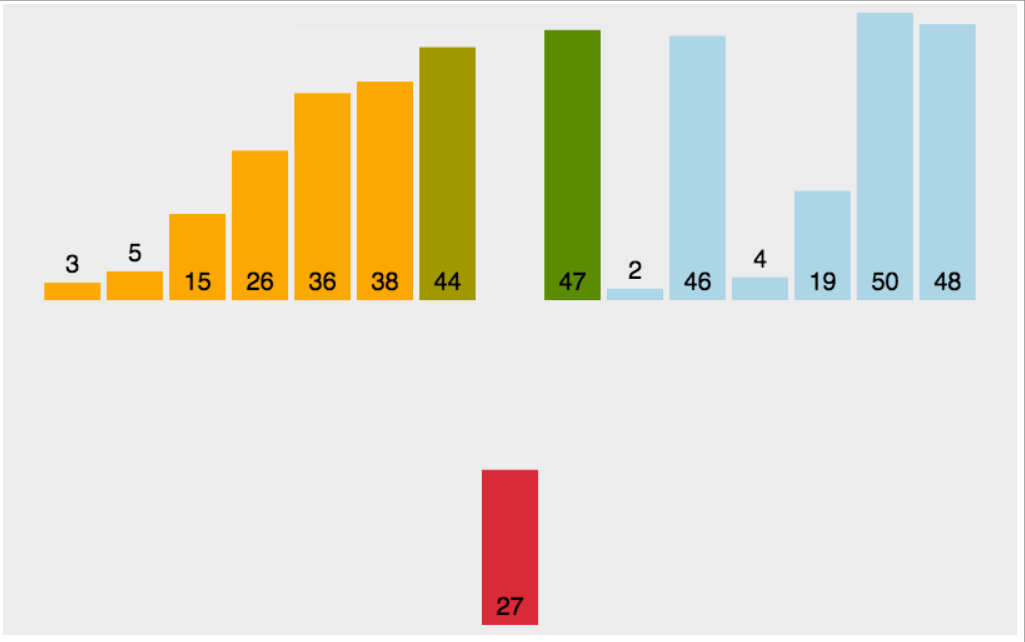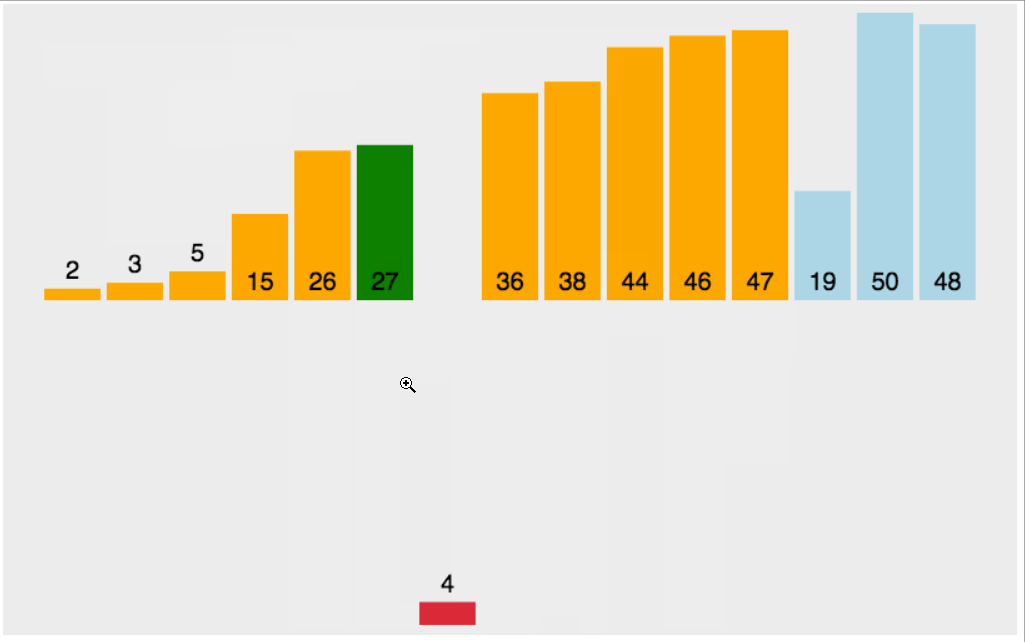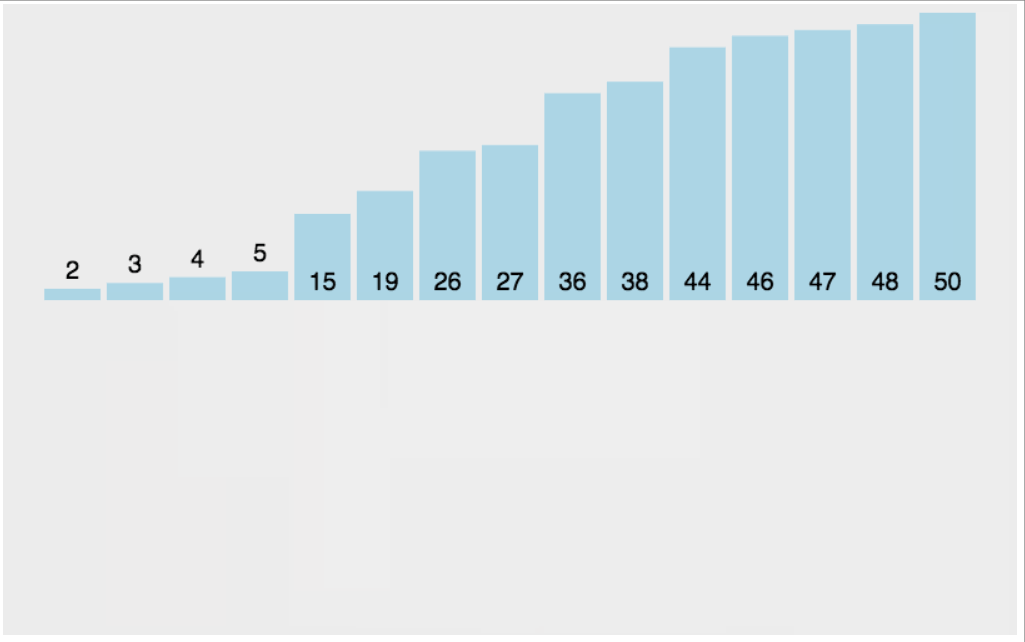
实现代码:
cpp
//插入排序
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
if (tmp > a[end])
{
break;
}
}
a[end+1] = tmp;
}
}效率分析:
时间复杂度:最坏:在完全逆序时,每次插入需比较并移动所有已排序元素,复杂度为O(n^2)。
最好:序列已经有序时只需比较n-1次。
空间复杂度:插入排序的空间复杂度为O(1)
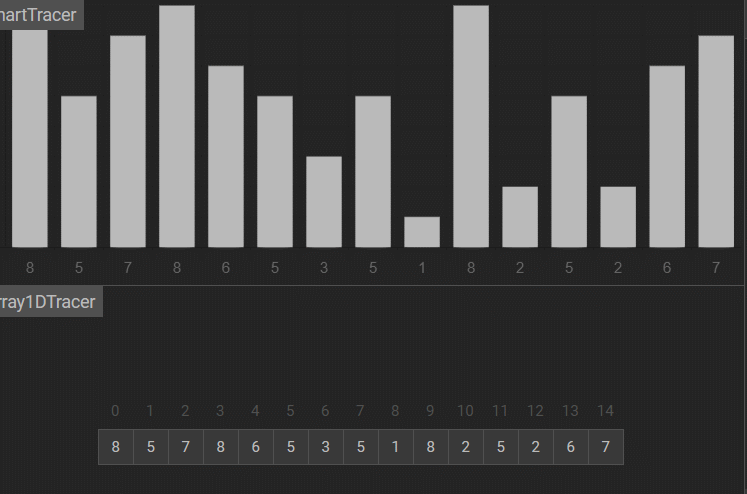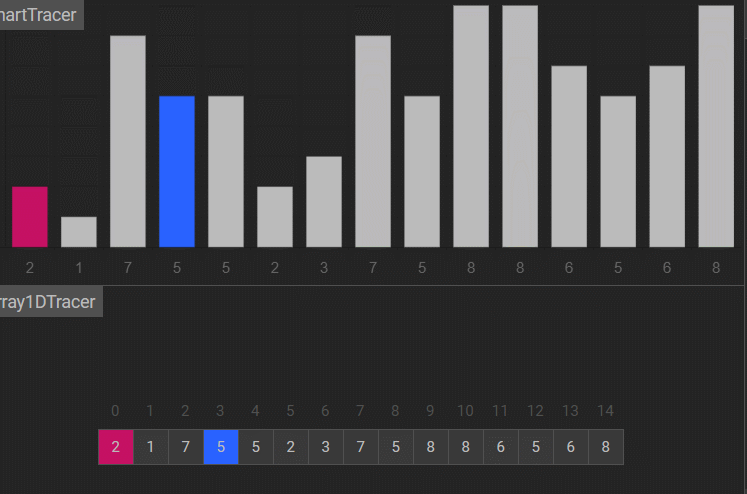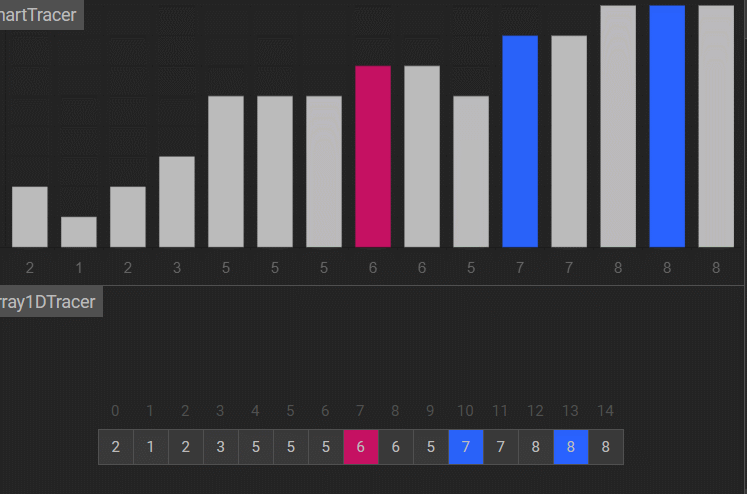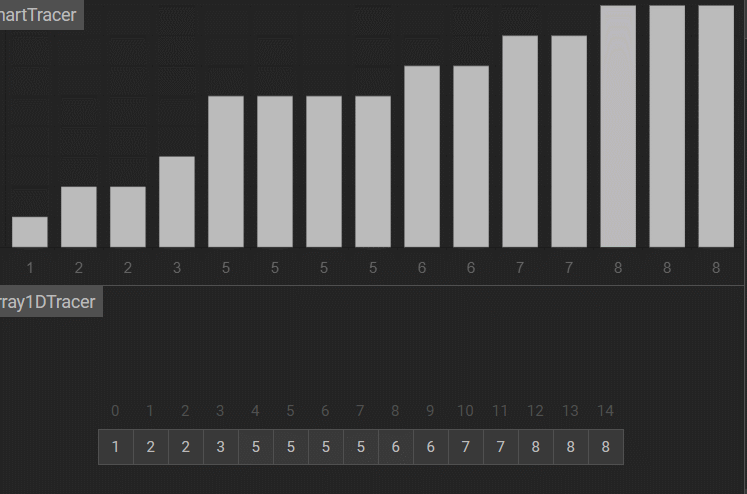
2.希尔排序
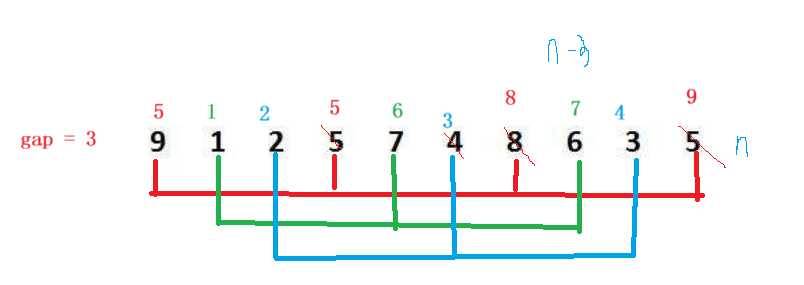
**基本思想:**希尔排序是对插入排序的优化,将其分为gap组,分别对每组进行预排序,gap逐渐减小,直到gap=1,再进行插入排序,预排序的目的是让数组变得更有序。具体步骤如下:
- 确定一个初始间隔gap,将数组分为gap组。
- 分组插入排序,对每组进行插入排序,经过这轮排序,虽然整体不一定有序,但元素已经朝着最终位置移动了一定距离。
- 缩小间隔:将gap缩小,重复分组和排序过程。
- 最终排序:当gap=1时,算法退化为标准的插入排序。由于前面多轮的预排序已经使数组变得基本有序,此时的插入排序效率会非常高。
注意:gap越大,大的数可以越快跳到后面,小的数可以越快跳到前面,越不接近有序。gap越小,跳的越慢,越接近有序。
动图演示:
cpp
//希尔排序
void ShellSort(int* a, int n)
{
//gap逐渐减小,最后为1
//gap不为1时是预排序
//gap为1时是直接插入排序
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)//内层循环排序每组数据,i<n-gap保证tmp不越界
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}效率分析:
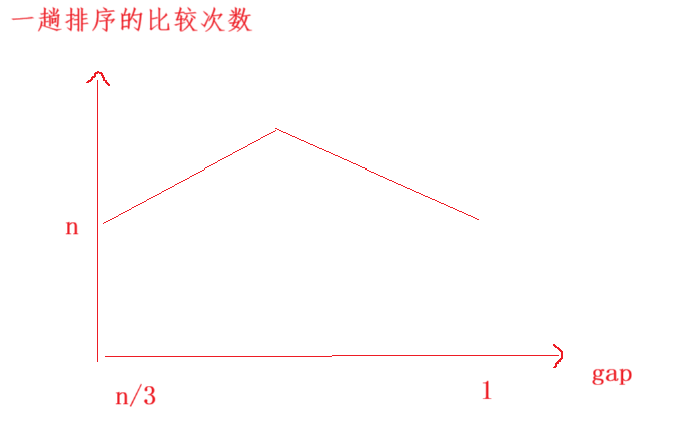
**时间复杂度:**希尔排序的时间复杂度不固定,它难以计算,具体由增量序列决定,我们可以将它时间复杂度记作O(n^1.3)。
希尔排序时间复杂度难以计算的原因:while循环的次数可以算出,为logN量级,但是对内层循环的消耗很难计算,当gap=1时,数据已经十分接近有序,可以看作消耗为n.

希尔排序时间复杂度的变化规律
**空间复杂度:**希尔排序的空间复杂度为O(1)
3.快速排序
基本思想:
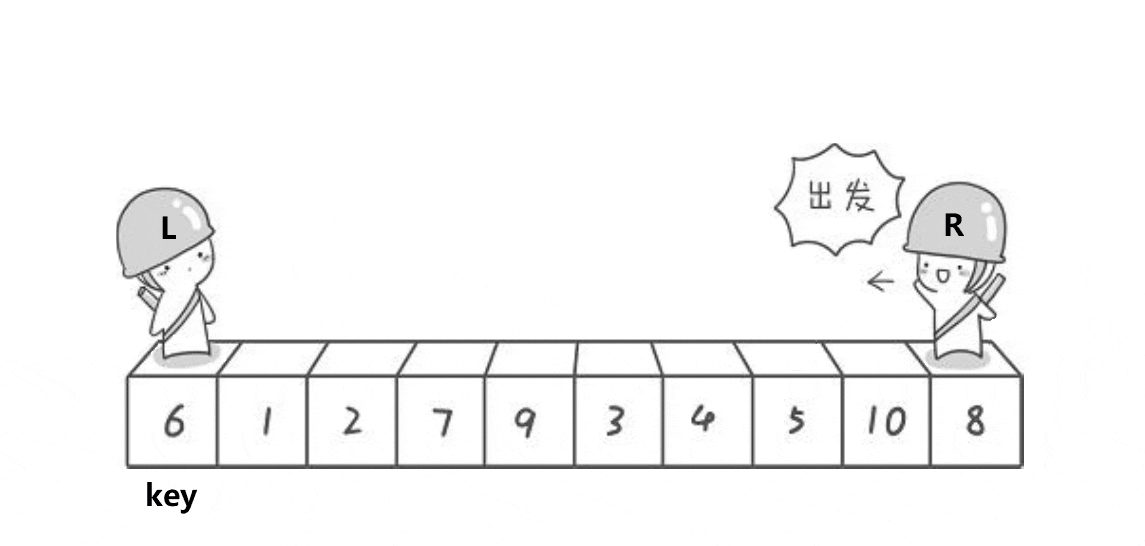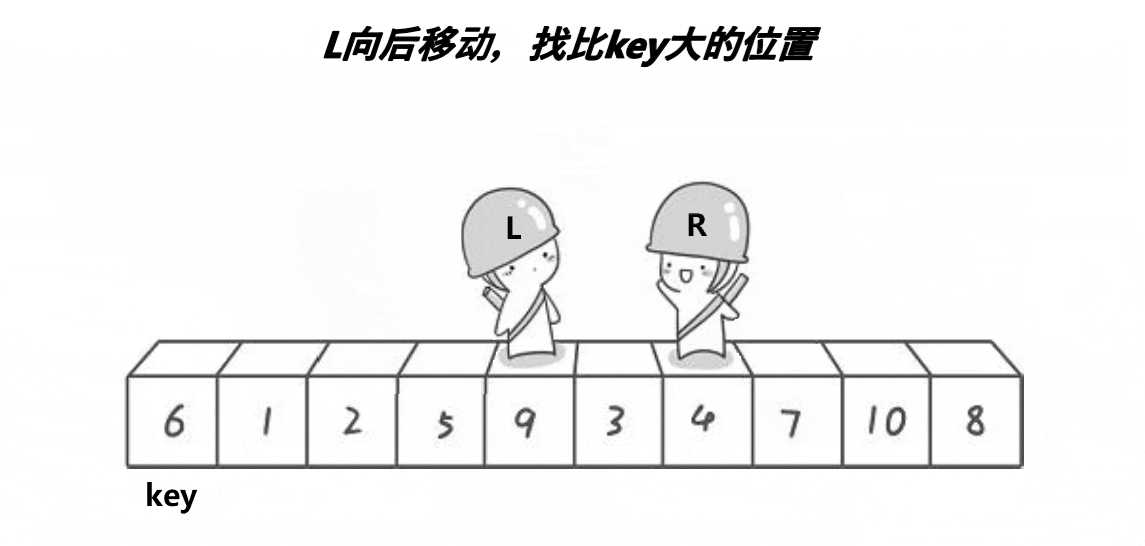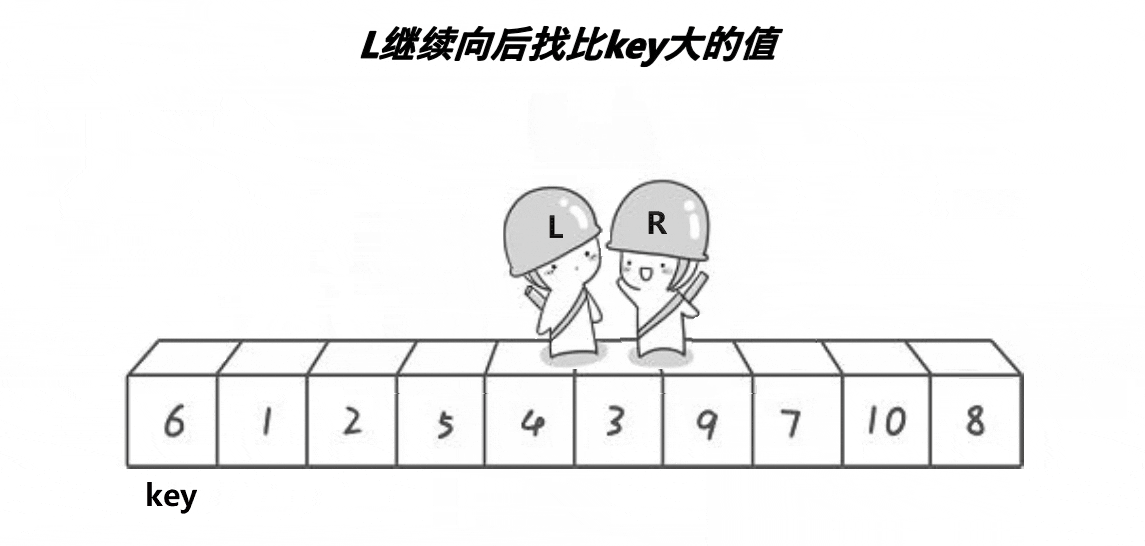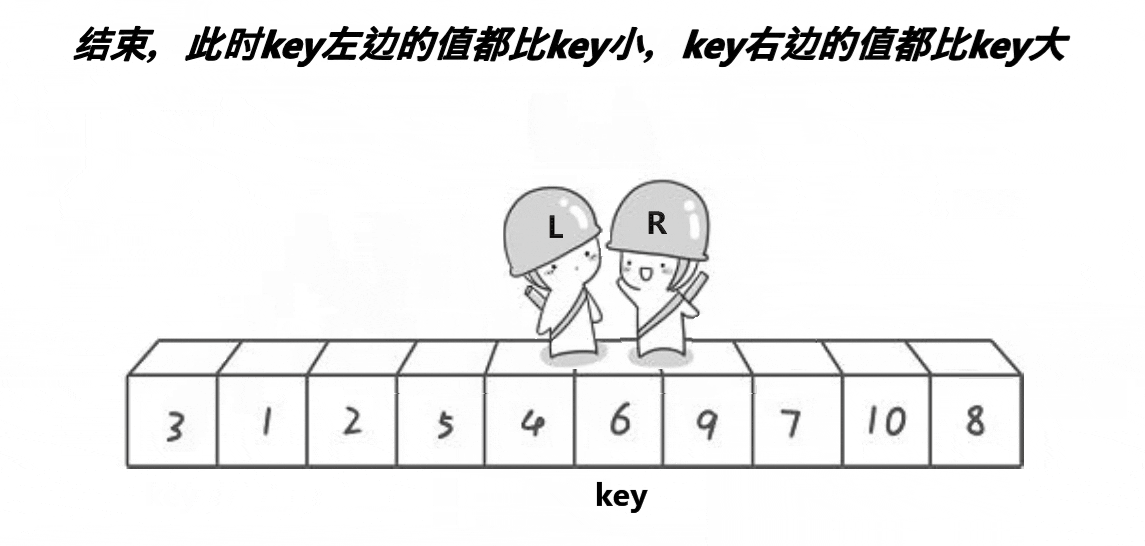
- 用两个变量begin和end分别标记每个区间的最左边和最右边,设置keyi=left,让end从最右边开始依次找比keyi位置小的数,找到了就停下;让begin从最左边开始找比keyi位置大的数,找到了就停下,交换begin位置和end位置的数,循环的条件为begin<end。
- 当最终begin与end相遇时,则交换keyi位置和begin位置的数。
- 对数组递归排序,直到需要排序的数组区间只有一个数或者空的时候,数组排序完成。
注意:这里每次排序完成的任务是确定keyi元素的位置,以及区分左右区间。比keyi位置元素小的都在keyi的左边,比keyi位置元素大的都在keyi的右边。
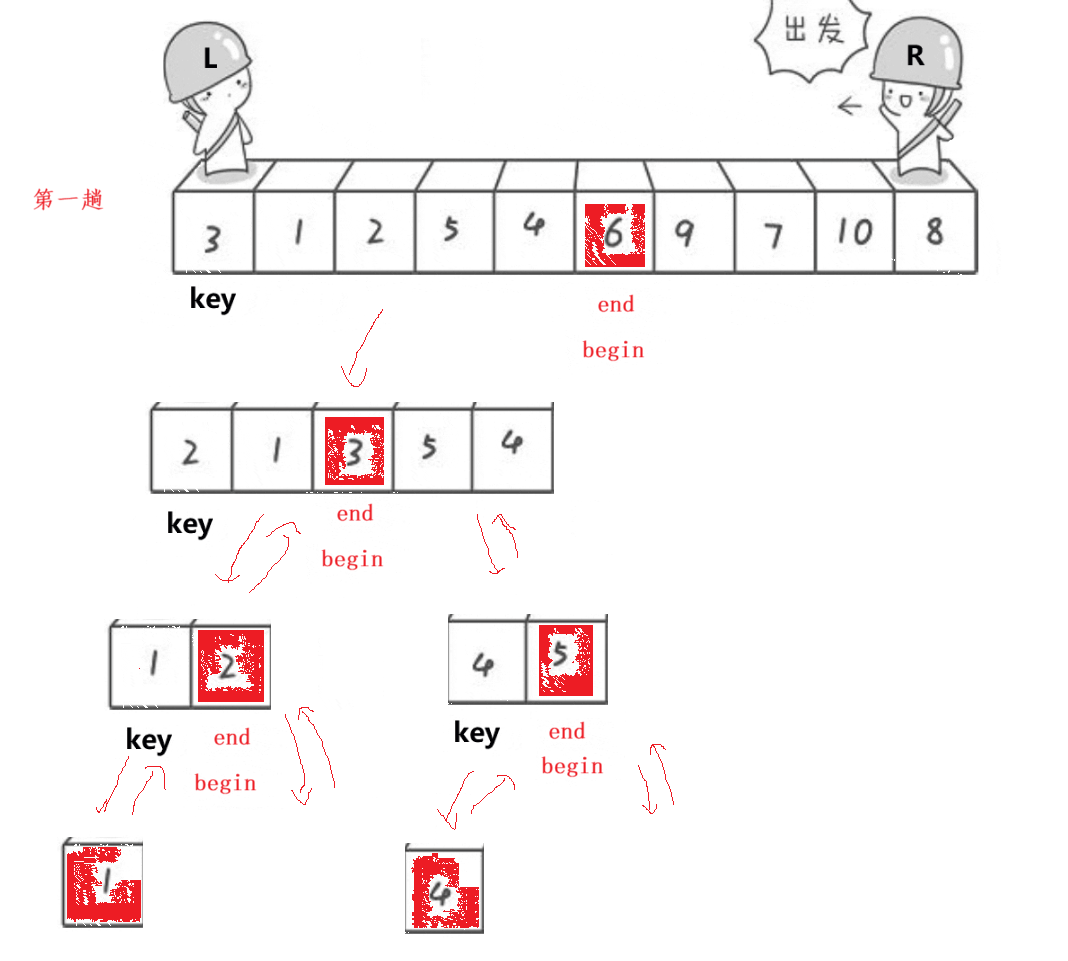
动图演示:
实现代码:
cpp
//快速排序
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = left;
int begin = left;
int end = right;
while (begin < end)
{
while (begin < end && a[end] >= a[keyi])//右边找小
{
--end;
}
while (begin < end && a[begin] <= a[keyi])//左边找大
{
++begin;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[keyi], &a[begin]);
keyi = begin;
QuickSort(a, left, keyi-1);
QuickSort(a, keyi + 1, right);
}问题分析:
**1.**当给出的序列是有序的,快速排序的效率会如何,该如何改进?
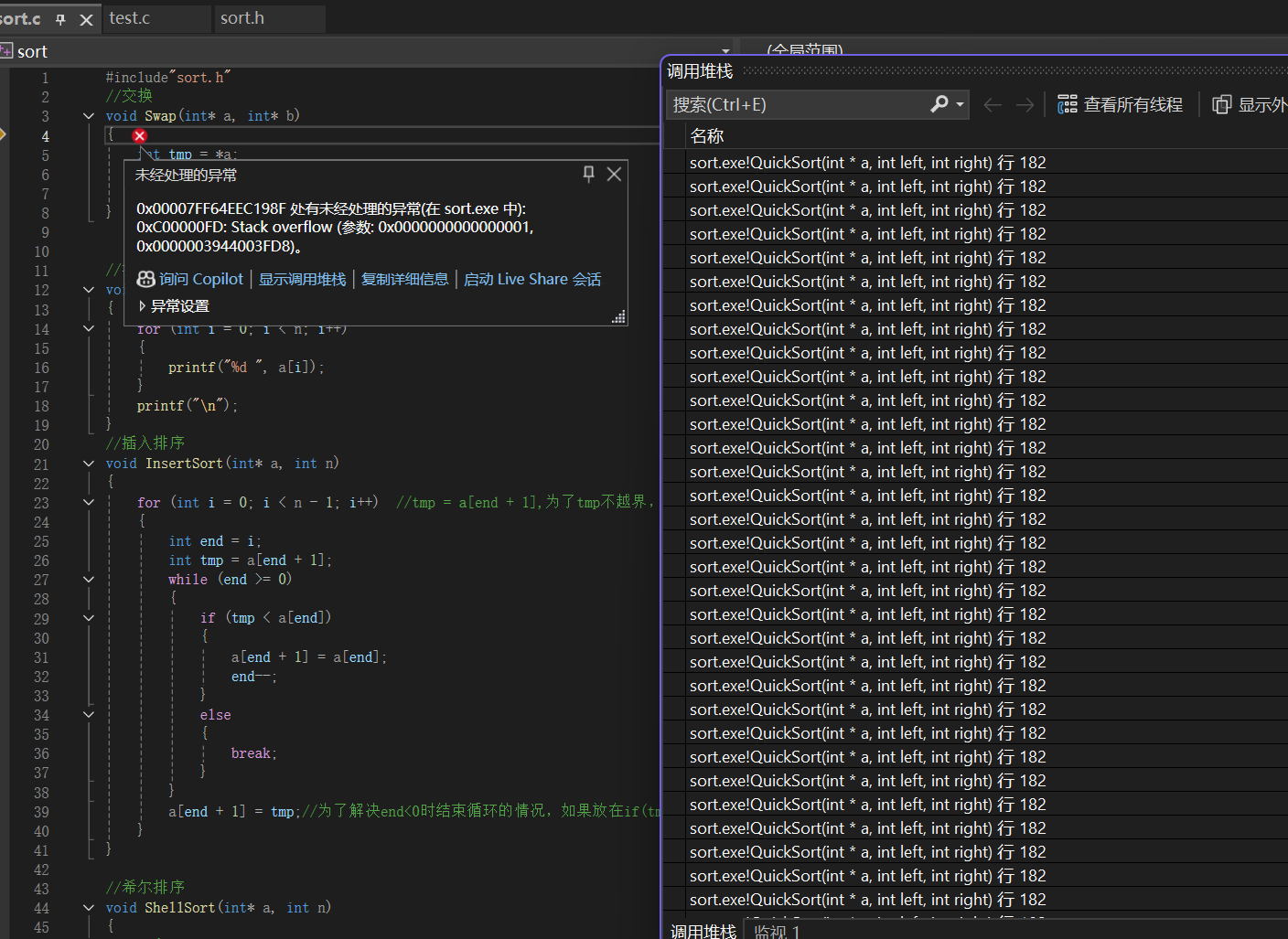
通常情况下,快速排序的平均递归深度是 O(log N)。但是,如果快速排序选定的基准值(keyi)每次都是数组中的最大值或最小值遇到已经有序 或逆序的数据时,快速排序会退化成最坏情况,递归深度达到 O(N)。
每个函数栈帧大概占用几十到上百字节,100000 次递归相乘,所需的空间远远超过了操作系统默认给程序分配的栈内存大小(Windows 下通常是 1MB 或 2MB),因此程序直接崩溃并报出 Stack overflow。
**改进方法:**三数取中,小区间插入
三数取中:基本可以避免keyi去到最大值或最小值的情况,从而降低递归深度。
cpp
int GetMidIndex(int* a, int left, int right) //三数取中
{
int mid = (right + left) / 2;
if (a[left] < a[right])
{
if (a[mid] < a[left])
{
return left;
}
else if (a[mid] > a[right])
{
return right;
}
else
{
return mid;
}
}
else
{
if (a[mid] < a[right])
{
return right;
}
else if (a[mid] > a[left])
{
return left;
}
else
{
return mid;
}
}
}小区间插入:当划分的数组子区间很小的时候,比如小于10,可以使用插入排序,提高效率的同时减小递归深度。
cpp
if (right - left +1 < 10)
{
InsertSort(a + left, right - left + 1);
}2.怎么确定begin与end相遇时,相遇位置的值一定比keyi位置的值小?
我们每次都让右边先开始走,分析left和right相遇的情况
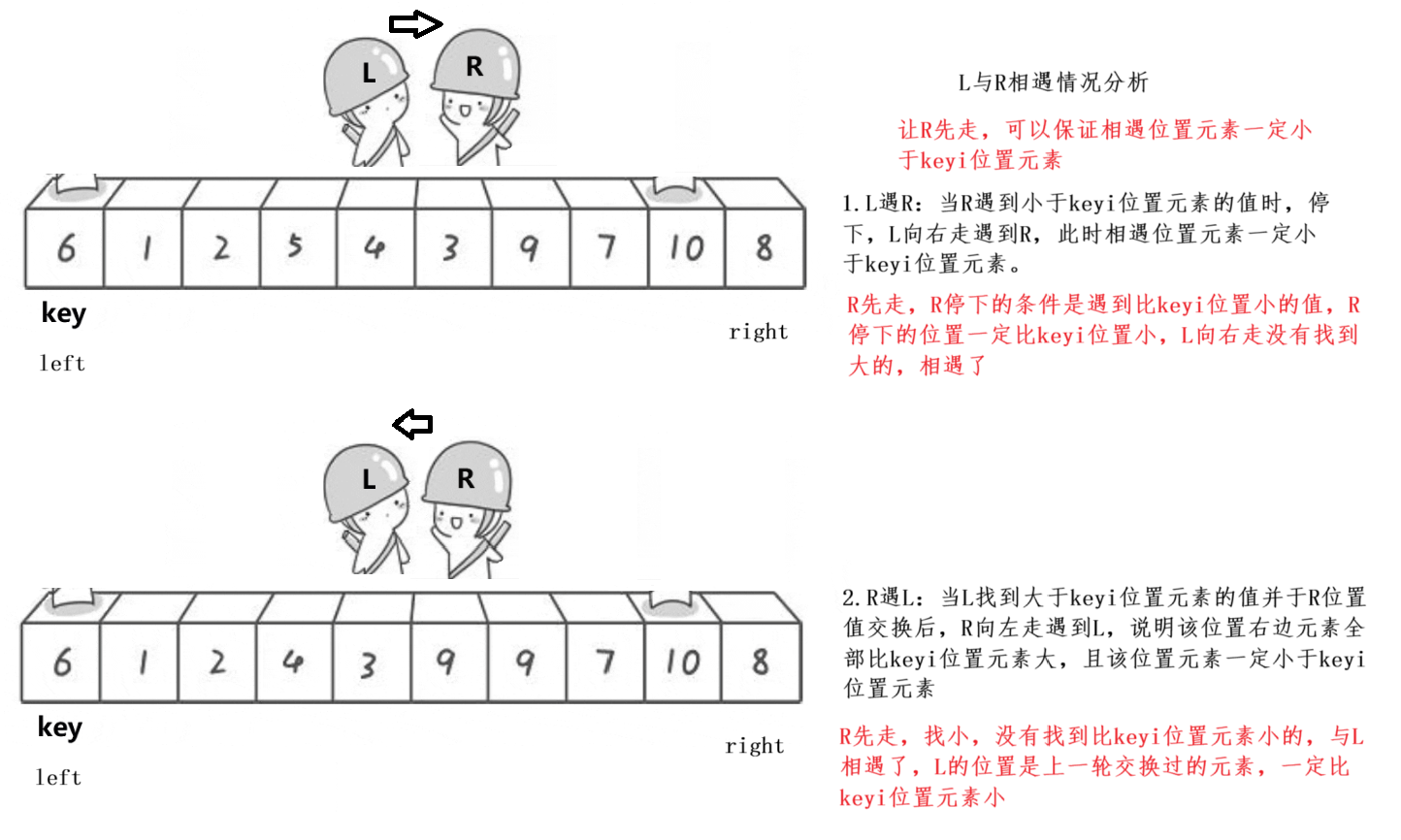
快速排序的优化:
前后指针法
核心思路:使用双指针 prev 和 cur,其中 cur = prev + 1。当 cur 指向的元素小于基准值 key 时,两个指针同步后移;若 cur 指向的元素大于 key,则 prev 保持不动,cur 继续向前寻找较小的元素。找到后,将 prev 后移一位并与 cur 交换元素。当 cur 越界时,最终交换 key 与 prev 位置的元素。该方法的本质是通过 prev 指针将小于 key 的元素归到左侧,大于 key 的元素归到右侧。
动图演示: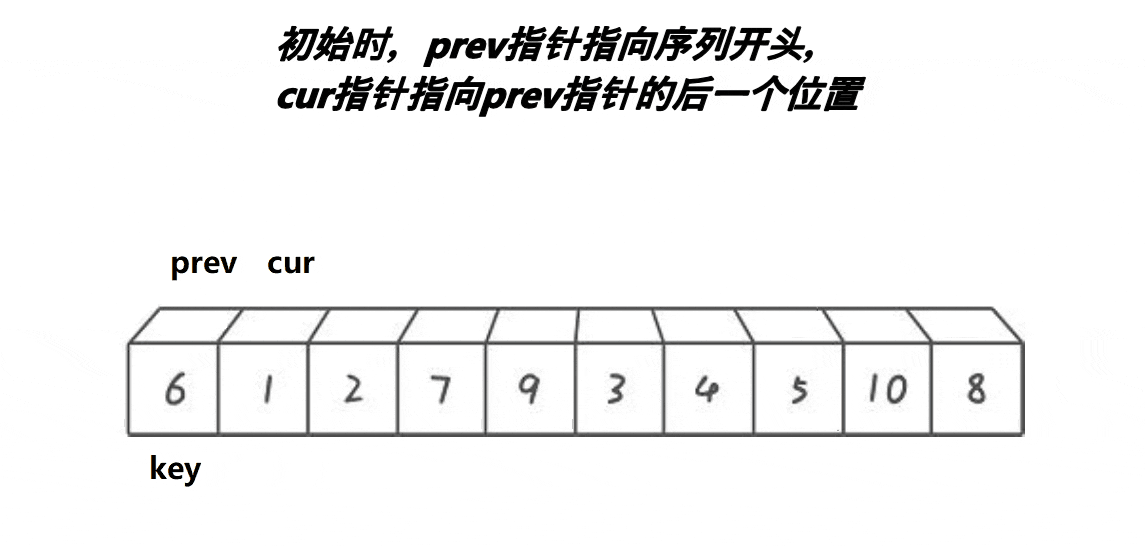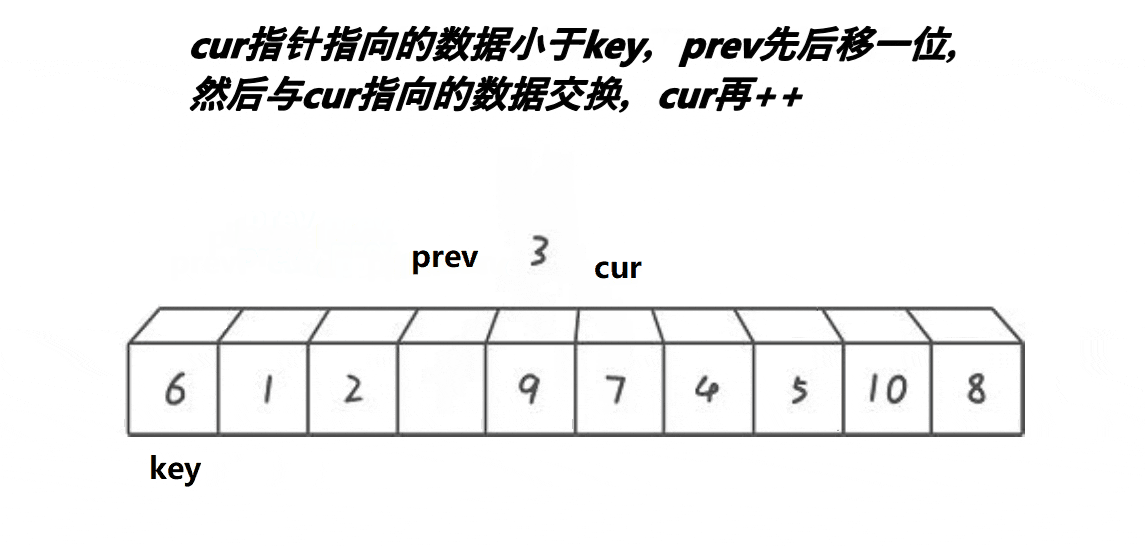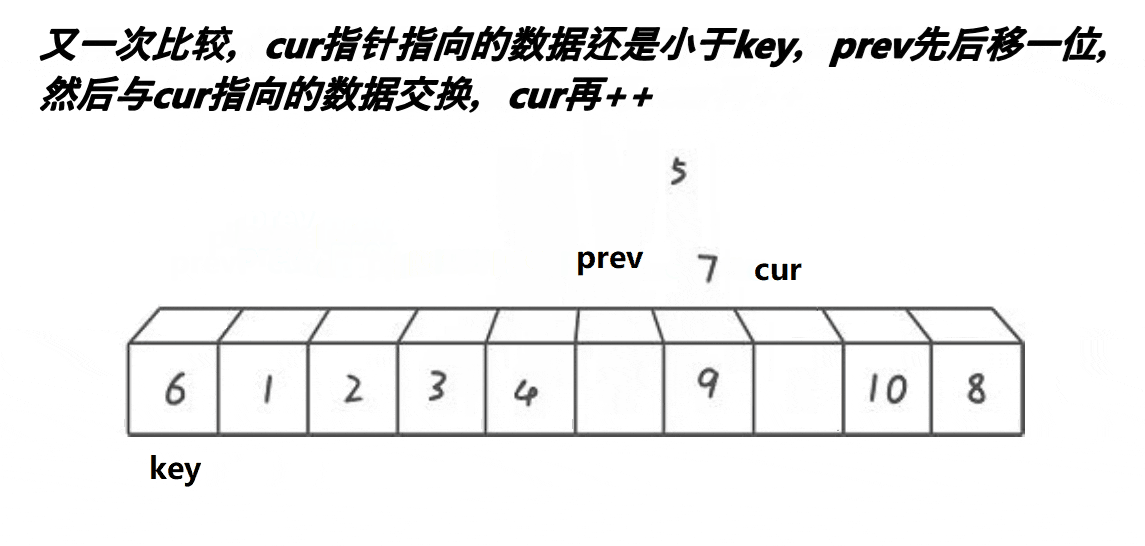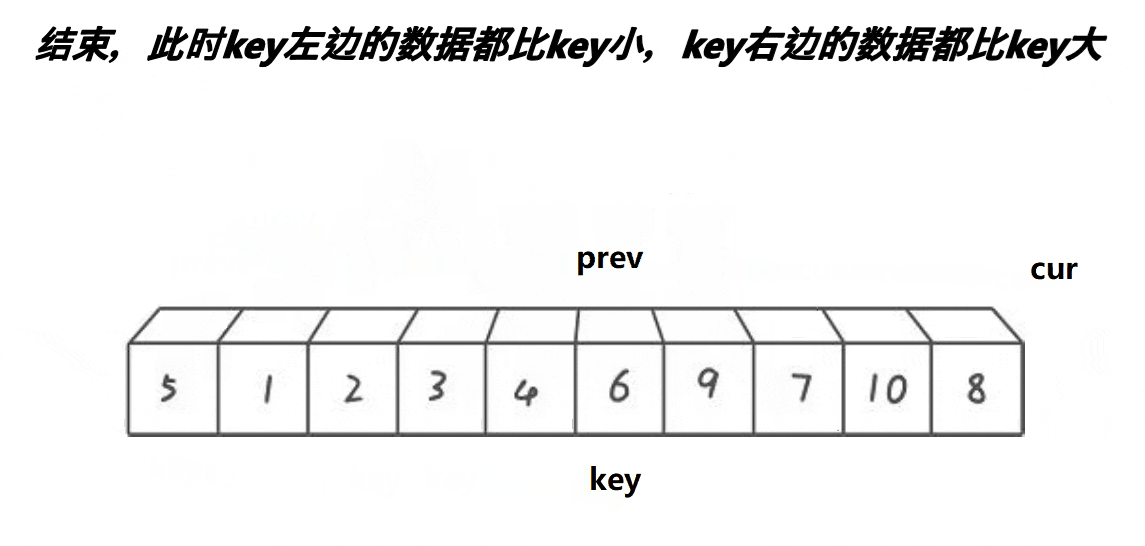
代码实现:
cpp
//快慢指针法
int PartSort2(int* a, int left, int right)
{
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && cur != prev++)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[keyi], &a[prev]);
return prev;
}快速排序的非递归实现
当处理大规模数据时,递归实现的快速排序可能因递归层数过深导致栈溢出 (Stack Overflow)。为解决这一问题,可以利用显式栈数据结构模拟递归调用过程,实现非递归版本的快速排序。
-
栈的作用 :
用栈(后进先出)存储待处理的数组区间(即每次划分的左右边界
[left, right])。每次从栈顶取出一个区间进行划分,并将新生成的子区间压入栈中,直到栈为空。 -
步骤分解:
- 初始化 :将整个数组的起始和结束下标
[left,right]压入栈。 - 循环处理 :
- 弹出栈顶区间
[begin,end]。 - 对该区间执行单趟排序(Partition),得到基准值的位置 keyi。
- 若左子区间
[begin,keyi-1]长度大于1,将其压入栈;同理处理右子区间[keyi+1,end]。
- 弹出栈顶区间
- 终止条件:栈为空时,排序完成。
- 初始化 :将整个数组的起始和结束下标
过程图解: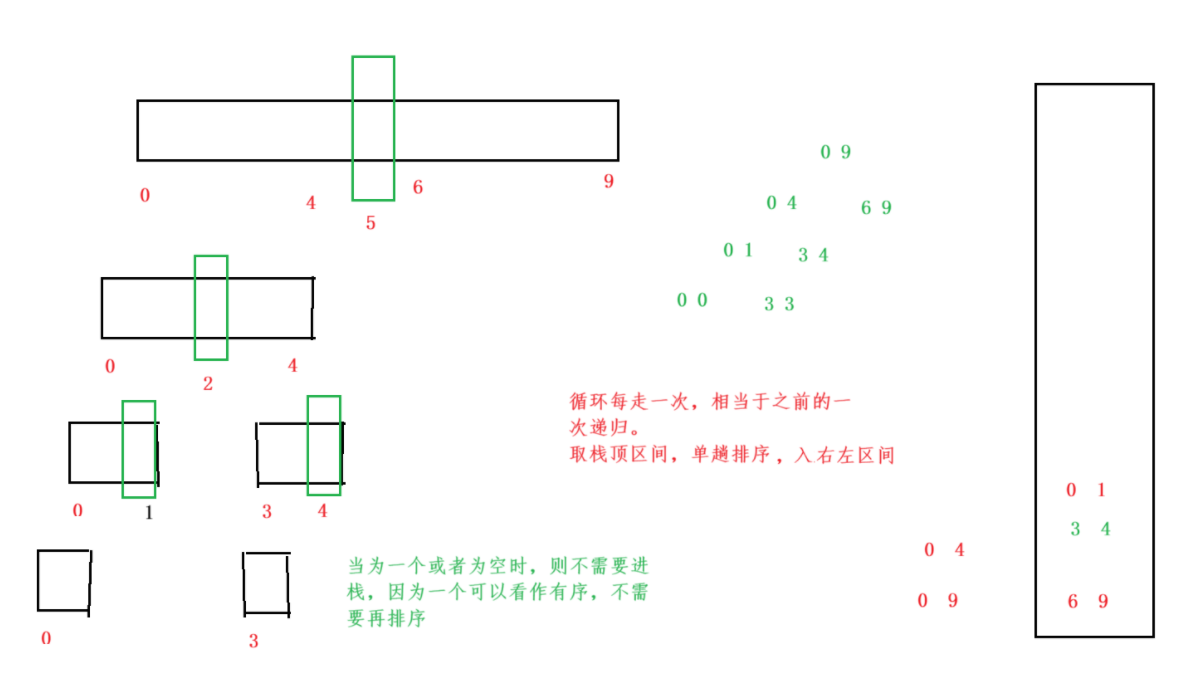
代码实现:
cpp
//非递归
#include"Stack.h"
void QuickSortNre(int* a, int left, int right)
{
ST st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
while (!STEmpty(&st))
{
int begin = STTOP(&st);
STPop(&st);
int end = STTOP(&st);
STPop(&st);
int keyi = PartSort2(a, begin, end);
if (keyi + 1 < end)
{
STPush(&st, end);
STPush(&st, keyi+1);
}
if (begin < keyi - 1)
{
STPush(&st, keyi - 1);
STPush(&st, begin);
}
}
STDestroy(&st);
}4.归并排序
基本思路: 采用分治法:将一个大数组递归地划分为左右两个子区间,直到每个子区间至多只有一个元素(天然有序),然后将两个有序子区间合并成一个大的有序区间,借助一个与原数组等长的辅助数组暂存合并结果,最后回拷到原数组对应位置。
动图演示:
代码实现:
cpp
//归并排序
void _MergeSort(int* a, int* m, int begin, int end)
{
if (begin >= end)
{
return;
}
//如果左右区间都有序,就可以归并了
int mid = (begin + end) / 2;
_MergeSort(a, m, begin, mid);
_MergeSort(a, m, mid + 1, end);
//归并
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
m[i++] = a[begin1++];
}
else
{
m[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
m[i++] = a[begin1++];
}
while (begin2 <= end2)
{
m[i++] = a[begin2++];
}
memcpy(a + begin, m + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail!");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}