RAG概念
RAG,全称检索增强生成,是一个将信息检索和大语言模型结合起来的AI架构
在原生的LLM中,训练数据是有日期限制的,并没有包含新实时数据,而且它的数据完全来源于公开数据,自己本地是数据,私有数据,并没有拿来被大模型训练。而RAG系统就是让在大模型回答我们问题之前先去,我们提供的私有数据库或外部动态知识库检索相关信息,然后组织最终给我们。保证了信息的实时性和专用性。
如下图示:
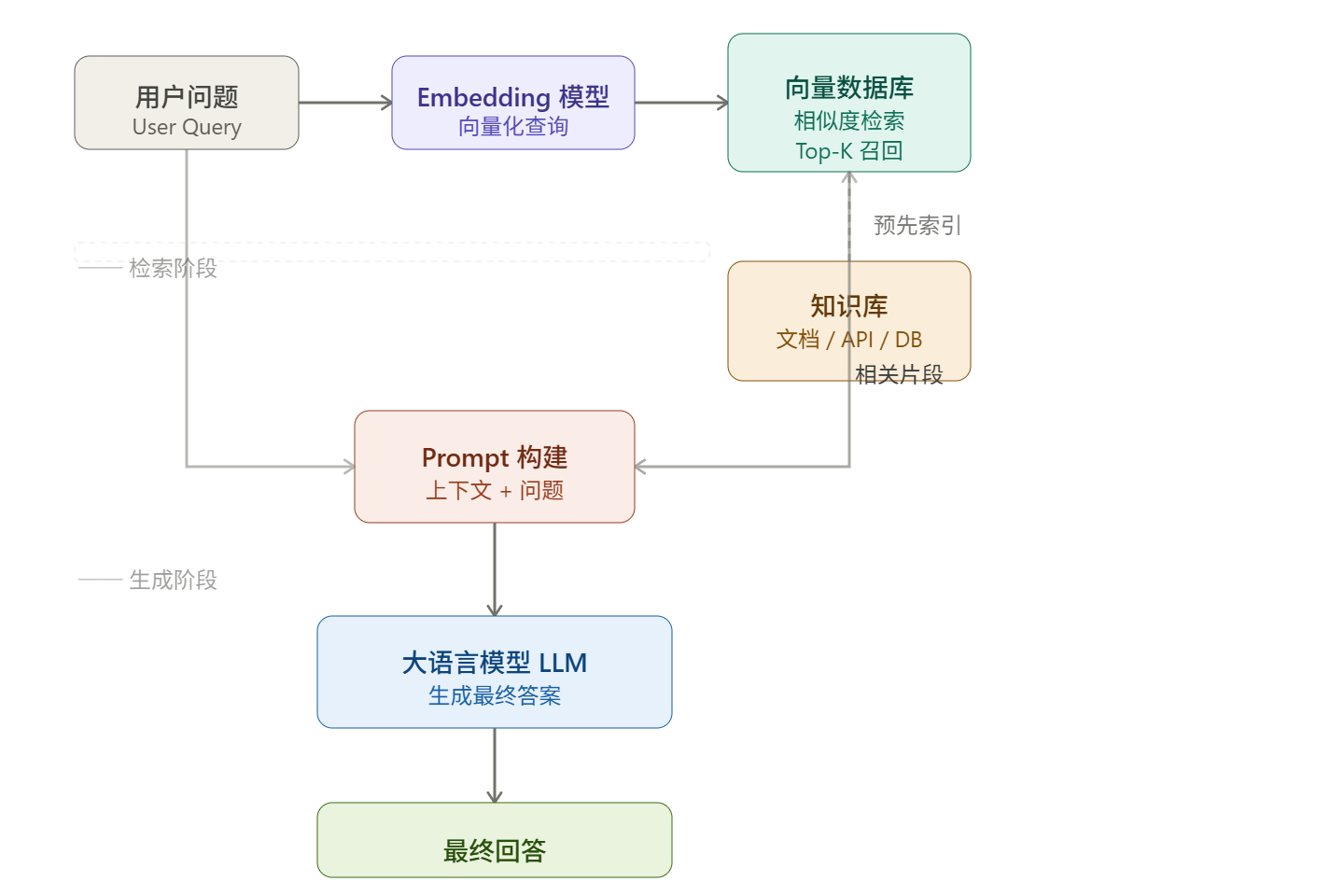
RAG的两个核心阶段:
- 检索:获取用户输入,然后转化成向量到知识库进行语义相似度搜索。(嵌入模型完成)
- 生成:把在搜索到的信息给LLM,最终组织成自然语言输出给用户(大语言模型完成)
可以划分为两个模块:离线数据处理和在线检索过程。离线数据处理本质是构建知识库。如下:
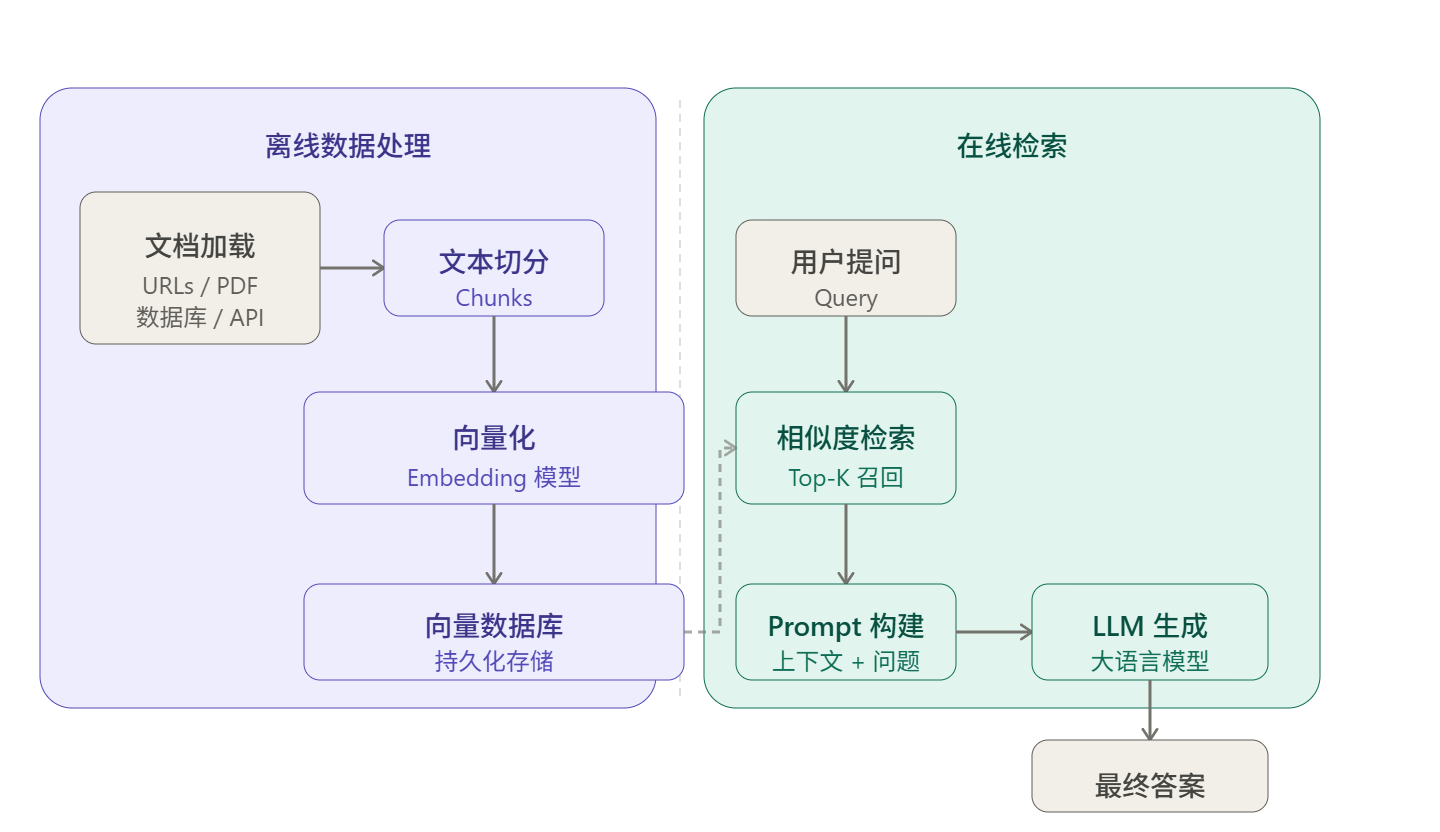
离线数据处理有分为文档加载器,文本分割器,向量存储。离线数据加载到系统(LangChain)无论什么数据都叫做文档。有的文档很大有的小,主题多。文本分割器可以把文档拆分成多个小文档。按功能模块拆分,包括代码等等各种都能拆分。
组件
Document
一个文件载入后会被分成多个块,这个块是用Document结构来维护的
如下:
Document(
#内容
#元数据字典
#元数据属性,包含,文档源,与其他文档以及其他属性信息
)对于单个Document文档,它一般表示较大文档里的某个块或某一页
手动定义Document
python
documents = [
Document(
# 内容
page_content="公司密码是sadgasfg",
# 元数据字典,元数据属性可以包含:文档源,与其他文档的关系以及其他属性信息
metadata={"source": "pets-doc"},
),
Document(
page_content="AI最大的价值是提升信息整理、代码理解和测试设计效率,但最终的判断和验证还是需要测试人员完成",
metadata={"source": "pets-doc"},
),
]把本地文档加载到内存里需要用到文档加载器。
在LangChain包里的文档加载器有很多种,比如PDF的文档加载器,Markdown格式的文档加载器等,接下来以这两个为例进行使用演示:
PDF文档加载:
python
# 创建并配置加载器
loader = PyPDFLoader(file_path="./电商平台测试报告.pdf")
# 读取文档
docs = loader.load()
# 打印页数
print(f"文档页数:{len(docs)}")
# 打印前200字符
print(f"第一个文档内容: {docs[0].page_content[:200]}")PDF加载中通常一个页占一个子块。即一个Document结构。
Markdown文档加载:
python
md_loader = UnstructuredMarkdownLoader("./电商平台测试报告.md")
docs = md_loader.load()Markdown文档加载中默认只会加载成一个整个子块,因为它并没有页的概念,即len(docs)结果为1,不过可以在创建加载器时进行配置,如下:
python
md_loader = UnstructuredMarkdownLoader(
"./电商平台测试报告.md"
,mode="elements" #通常是按照大纲进行分块
# 默认为model = "single" )这个过程将文档加载入内存中,并且拆成Document列表。这不是文本拆分器的行为,后面文本拆分器可能还会拆分。
获取文档中所有类型:
print(set(document.metadata["category"] for document in data))
图片加载怎么解决?使用UnstructuredImageLoader 可以加载图片,如果是pdf格式文件中有图片需要加载则使用UnstructuredPDFLoader,传参时添加strategy="hi_res",即hi_res模式。
对于LangChain来说,能加载的⽂档类型远不⽌这些,它还能加载⽹⻚、⼀些云提供商⽂件、社交媒体平台⽂档等,更多⽂档加载器⻅这⾥
文本分割器
加载器拆分有问题,比如按页拆分,把一个内容切断了。更希望相近的内容被分为一个文档,在将来生成向量是,也只用生成一份向量。文本分割器可以将内容拆分的更细,把相关性高的放在一起。方便管理和查询时更加准确。
文档加载时所做的拆分只是为了读文件、打标签、统一格式,而后面文档分割器还要进行重新拆分,之前的文档拆分成什么样无关影响对。而加载器的拆分粒度决定了 metadata 的精细程度,对溯源信息有影响。
文本分割器怎么解决这个问题?可以按照我们制定的规则拆分文档,所使用的接口为CharacterTextSplitter:有下面几种规则:
按长度+语义拆分
比如按前200字符拆分。缺点是会将完整句子拆成两断。怎么解决?越过长度限制,通过语义把完整内容拆出来。所以长度就成了辅助条件。
根据字符长度进行拆分
指定字符拆分长度,可以配置可重叠部分的大小,使用参数chunk_overlap,可以让相邻的块有小部分重叠保证语义完整。
chunk_overlap:块之间可重叠大小,举一个不恰当的例子🤔如下文字中,"有时候它给出的接口参数"就是重叠部分,它即被分给了前面一块也分给了后面一块。
同时可以让两个换行符进行拆分。(所以要注意md的编写)

配置示例:
如下:
python
text_splitter = CharacterTextSplitter(
separator="\n\n", # 分割符
chunk_size=400, # 块大小
chunk_overlap=50, # 块重叠大小
length_function=len, # 测量字符长度的函数
is_separator_regex=False, # 是否正则表达式描写分隔符
)设置长度计算方法:
length_funtion=len
分割符是否是正则表达式描写:is_separator_regex=False
基于token数拆分
python
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # cl100k_base 是tiktoken 分词器中的一种编码方式
chunk_size=400, # 块token大小(参考标准,为了保证段落/句子完整,会超
chunk_overlap=50, # 块重叠大小
)强制长度拆分
递归文本分割器:
python
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # cl100k_base 是tiktoken 分词器中的一种编码方式
separator=["\n\n","\n","。"] # 分割符
chunk_size=400, # 块token大小(参考标准,为了保证段落/句子完整,会超出此设定的大小)
chunk_overlap=0, # 块重叠大小
)递归分割(通常用多分割符):先切整个文本,找到有分割符(优先级找)进行分割,还大于400,再在400内找分隔符分割。
特殊文档结构拆分
比如代码,html等等,有单独的拆分方式,比如按函数名。
创建文档遵守分割器规则。
python
# 字符串文档
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
def hello_python():
print("Hello, Python!")
"""
# 分割器(python代码)
splitter = PythonCodeTextSplitter(
chunk_size=50,
chunk_overlap=0,
)
# 按上面所配置的规则进行分割,返回document结构
python_docs = splitter.create_documents([PYTHON_CODE])
# 打印分割结果
for document in python_docs:
print("*" * 30)
print(document)嵌入模型转换向量
什么是向量?
向量本质就是用一串数字描写某个事物的特征,比如描述一个人:
[身高, 体重, 年龄] = [175, 70, 22]这就是一个三维向量
在RAG里的向量,也就是文本向量(也叫 Embedding)是把一段文字变成一串浮点数:
"今天天气真好" → [0.12, -0.87, 0.34, 0.56, ..., 0.09] # 通常 768 或 1536 维
"今天阳光明媚" → [0.11, -0.85, 0.36, 0.54, ..., 0.10] # 和上面很接近
"我喜欢吃披萨" → [0.93, 0.21, -0.67, 0.02, ..., 0.88] # 差距很大在数学几何中的向量表示:
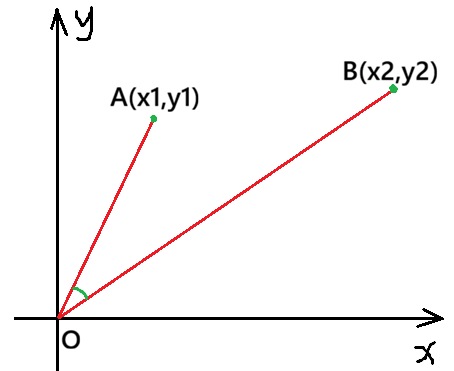
设两点 A ( x 1 , y 1 ) \text{A}(x_1, y_1) A(x1,y1) 和 B ( x 2 , y 2 ) \text{B}(x_2, y_2) B(x2,y2),从 A \text{A} A 点位置向量写作:
O A ⃗ = ( x 1 , y 1 ) \vec{OA} = (x_1, y_1) OA =(x1,y1)
三维空间同理:
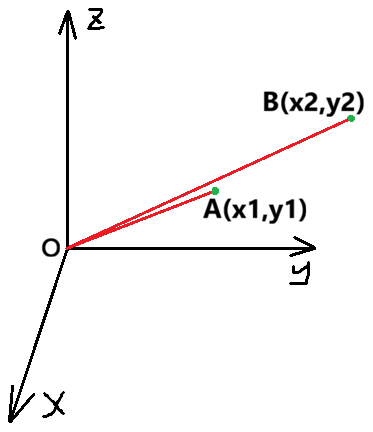
O A ⃗ = ( x 1 , y 1 , z 1 ) \vec{OA} = (x_1, y_1, z_1) OA =(x1,y1,z1)
假设这两个点所表示的就是两文本,则两个点到原点连线的夹角越小则两个文本语义相似度就越高,比如可以用 A B ⃗ \vec{AB} AB 的值来衡量。而连线的长度(模长)则可以表示文本的长度。
所以用来表示文本的向量维度越高,那么文本相似度匹配精确度就越高。
什么是嵌入模型?
嵌入模型是用来把文本文档转化为向量的。计算机天⽣擅⻓处理数字,但不理解⽂字、图⽚的含义。嵌⼊(Embedding)的核⼼思想就是将⼈类世界的符号(如单词、句⼦、产品、用户、图⽚)转换为计算机能够理解的数值形式(即向量,本质上是⼀个数字列表),并且要求这种转换能够保留原始符号的语义和关系。我们可以把它想象成⼀个翻译过程,把⼈类语⾔"翻译"成计算机的"数学语⾔"。
示例:
将文档转化为向量
python
# 定义嵌入模型,日常学习测试推荐使用开源模型qwen3-embedding
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 内存向量存储
vector_store = InMemoryVectorStore(embedding=embeddings)
# 获取文档列表 (single 模式,只生成一个大文档)
loader = UnstructuredMarkdownLoader("./电商平台测试报告.md")
# Document 列表
data = loader.load()
# 定义分词器(tiktoken)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # cl100k_base 是tiktoken 分词器中的一种编码方式
chunk_size=400, # 块token大小(参考标准,为了保证段落/句子完整,会超出此设定的大小)
chunk_overlap=50, # 块重叠大小
)
# 文档列表
docs = text_splitter.split_documents(data)
# 存储文档到内存向量存储中
# add_documents: 将要存储的文档列表进行编排索引。
ids = vector_store.add_documents(docs)
print(f"共有{len(docs)}个文档,编排了{len(ids)}个索引")
print(f"前三个文档的索引:{ids[:3]}")
# 根据索引获取文档
doc_2 = vector_store.get_by_ids(ids[:2])
print(doc_2)
#
# 删除文档
vector_store.delete(ids=ids[:2])
doc_3 = vector_store.get_by_ids(ids[:3])
print(doc_3)
# 检索
# similarity_search: 根据余弦相似度来捕捉语义的
search_docs = vector_store.similarity_search(query="项目介绍", k=2)
for doc in search_docs:
print("*" * 30)
print(doc)在RAG检索中,输入的问题的向量转化方法可能和文档库的向量转化方法不一样。对于不同的供应商,针对这两种场景会做不同的优化策略,甚至于同一种供应商,也会其分开处理,从而获得更好的搜索结果。
向量存储
为了将向量持久化存储,需要把向量存入向量数据库。可以使⽤Redis来存储向量。⼤多数开发者都熟悉Redis,因为它速度快、拥有庞⼤的客户端库⽣态系统,并且多年来已被众多⼤型企业采⽤。
实际上是拆分的文档存储到向量库中。所以怎么做到?必须绑定一个嵌入模型。
向量数据库作用(能力):管理和检索数据。
原理
MySQL底层使用了Innodb将数据存储到磁盘上,除了存储数据还存储了索引(比如B+树)高效且精确查找数据。向量数据库也需要索引,而不是暴力搜索,常用的一种搜索方式就是ANN搜索。也就是近似最邻近搜索。
比如一个图书馆。每本书都有自己的特征,比如已经有《战争与和平-上》要查《战争与和平-下》,目标是近似不是精确。
怎么找?如果书的是散乱的放在地上,只能暴力了。(优点100%准确,缺点效率巨低,维度灾难)。像这种不用考虑精确度的数据,只需要近似最邻近,用精度换去速度。
ANN工作原理:
空间分割、哈希、近邻图(HNSW算法,分层导航小世界)这个是主流的。是图状结构
比如旅游场景:要去与上海特征(不是距离)相近的城市。
- 分层:第一层只标注国家,只需要知道国家与国家之间相似度。只有国家关系。(入口点)
- 第二层:在中国构造一张图,在去找一个最匹配的省图。(不能保证100%准确的,可能上一层就错开预期的结果了)
核心机制
向量相似度计算优化,高度优化的库来做向量计算,有CPU的SIMD和GPU并行计算能力。
还有管理功能:
- CRUD:增删改查
- 元数据过滤
- 可扩展与持久性
- 集成方便
内存存储
LangChain提供的内存存储能力。
示例:
python
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 创建内存向量存储(需要绑定嵌入模型,向量转换由其完成)
vector_store = InMemoryVectorStore(embedding=embeddings)
# 绑定之后后面就和上文一样做正常的向量转化管理操作就行......Redis向量存储
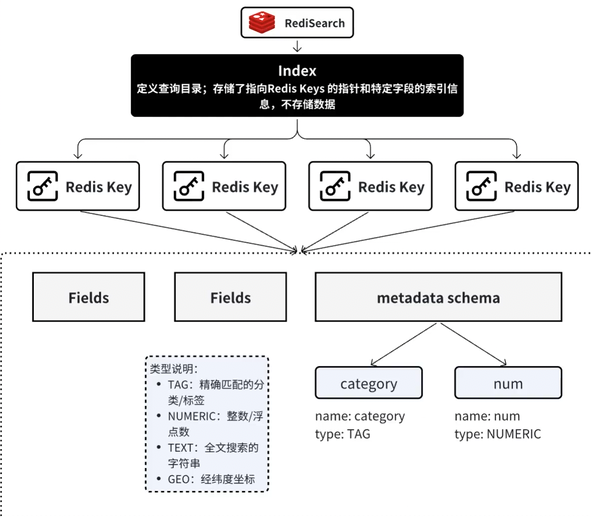
RediSearch是Redis官⽅提供的⼀款⾼性能【搜索】与【全⽂索引】引擎模块。Index(索引)是RediSearch模块⾥的概念,⽤于定义⼀个查询⽬录。Index是⼀个独⽴的数据结构,它本⾝不存储数据,⽽是存储了指向其他Redis Keys的指针,和这些Keys中特定字段的索引信息。
Redis服务搭建
容器启动:
bash
docker run -d -p 6379:6379 -it redis:latest初始化:
python
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客⼾端
redis_url = "redis://192.168.100.238:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
#Redis 存储初始化
vector_store = RedisVectorStore(embeddings, config=config)后面的存储和管理操作和上文内存存储相同。
Pincecone向量存储
Pinecone是为机器学习应⽤量⾝打造的⽣产级向量数据库服务,适⽤于⾼维向量数据的⾼效存储、索
引与查询。
初始化:
python
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
# 建⽴索引
pc = Pinecone()
index_name = "qa"
if not pc.has_index(index_name):
pc.create_index(
name=index_name, # 索引名称
dimension=3072, # 尺⼨,表⽰向量维度,需要和嵌⼊模型维度⼀致
metric="cosine", # 度量⽅式,cosine 表⽰余弦相似度
spec=ServerlessSpec(
cloud="aws", # 亚⻢逊云
region="us-east-1" # 区域
),
)
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 获取索引
index = pc.Index(index_name)
# 定义 Pinecone 向量存储
vector_store = PineconeVectorStore(embedding=embeddings, index=index)RAG系统实现
构建链完成RAG能力
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_redis import RedisConfig, RedisVectorStore
# 构建链:完成RAG能力
# 定义组件,构建链
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 聊天模型
model = ChatOpenAI(model="gpt-4o-mini")
# 1. 先从知识库中检索
# Redis 配置
config = RedisConfig(
index_name="qa", # 定义索引名
redis_url="redis://192.168.100.238:6379",
metadata_schema=[
{"name": "category", "type": "tag"}, # 添加索引字段:分类
{"name": "num", "type": "numeric"}, # 添加索引字段:编号
]
)
# Redis 向量库
vector_store = RedisVectorStore(
embeddings=embeddings,
config=config,
)
# 检索器
retriever = vector_store.as_retriever()
# 2. 将检索结果+查询语句 构建为提示词(提示词模板)
# 提示词模板
prompt = ChatPromptTemplate.from_messages(
[
(
"human",
"""你是负责回答问题的助手。使用一下检索到的上下文片段来回答问题。如果你不知道答案,就说不知道答案。最多回复三句话的结果,回答要简明扼要
Question:{question}
Context:{context}
Answer:"""
)
]
)
# 将检索出来的文档转换成文本传递给提示词模板
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 3. 将消息发送给 LLM(实例化消息,交由链完成)
# 定义链,执行时需要 question
# 检索器 + format_docs, question (同时传递)
# prompt
# model
# 输出解析器
chain = (
# 检索器 + format_docs 分支1
# question 分支2: RunnablePassthrough() 在链中透传输入数据,保持原始问题不变,直接传递给后续步骤
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser() # 输出解析器
)
# 执行流:
# 输入问题:"项目介绍"
# 并行执行两个分支,提高效率
# 输出结果:
# {
# "context":"xxxx"
# "question":"项目介绍"
# }
# 4. 打印字符串结果 (流式)
while True:
# 获取用户输入
question = input("\n请输入您的问题(输入'退出'或'quit'结束程序): ").strip()
# 检查是否退出
if question.lower() in ["退出", "quit"]:
print("程序已结束,再见!")
break
# 检查输入是否为空
if not question:
print("问题不能为空,请重新输入。")
continue
# 执行链,流式输出
print("回答: ", end="", flush=True)
for chunk in chain.stream(question):
print(chunk, end="", flush=True)
print() # 换行