一、RAG原理
RAG(Retrieval-Augmented Generation,检索增强生成) :用户提问时,先将问题向量化,从 向量知识库 中检索与问题语义最相关的文档片段,再把 检索结果和用户问题 一起拼成 Prompt,交给 LLM 生成答案。
这样可以 降低幻觉、提升时效性,并支持 企业私有知识 的问答场景。
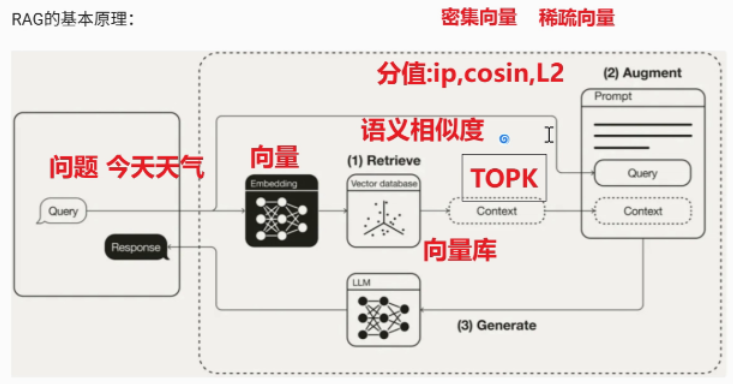
1.1 整体流程(对应图中 Query → Response)
RAG 的本质可以概括为三步:检索(Retrieve)→ 增强(Augment)→ 生成(Generate)。
第一步:Retrieve 检索阶段:Query Embedding (问题向量化) 用户查询的问题先经过词嵌入转成向量 → Vector Database Retrieve (向量库检索) 在向量库(如 Milvus)中,用 Query 向量与 文档向量 做语义相似度检索,从知识库中找到与用户问题 语义最相关 的 TopK 文档片段作为 Context;
第二步:Augment 增强阶段:将原始 Query 与检索到的 Context 按 Prompt 模板拼接,作为 LLM的输入;
第三步:Generate 生成阶段:LLM 基于增强后的 Prompt 生成最终 Response。
bash
用户 Query
↓
Embedding(向量化)
↓
(1) Retrieve --- 向量库检索 TopK Context
↓
(2) Augment --- Query + Context 组装 Prompt
↓
(3) Generate --- LLM 生成 Response
↓
返回用户1.2 详解
1.2.1 Retrieve --- 检索阶段
目标 : 从知识库中找到与用户问题 语义最相关 的 TopK 文档片段。
流程 :
1. Query 向量化(Embedding)
用户查询的问题Query 先经过 Embedding 词嵌入转成向量;向量分为两类:
稀疏向量(Sparse Vector) :如 BM25 风格,关键词匹配能力强;
稠密向量(Dense Vector) :如 BGE、OpenAI Embedding,语义理解能力强;
实际项目中常做 混合检索(Hybrid Search ),兼顾语义理解与关键词精确匹配。
2. 向量库检索(Vector Database Retrieve)
在向量库(如 Milvus)中,用 Query 向量与文档向量做相似度计算,取出 TopK 最相关片段作为 Context;
3. 相似度度量: 常见三种:
Cosine(余弦相似度) :最常用,衡量向量方向是否一致;
IP(Inner Product,内积 ):向量已归一化时与 Cosine 等价;
L2(欧氏距离) :衡量向量空间距离,越小越相似;
生产环境 Cosine + TopK 最常见;Milvus 等向量库会内置 ANN 索引(HNSW、IVF 等)加速检索;
1.2.2 Augment --- 增强阶段
目标 : 把检索到的外部知识 注入 到 LLM 的输入中;
做法 :将原始 Query 与检索到的 Context 按 Prompt 模板拼接,例如:
这一步叫 Prompt Augmentation(提示增强) :LLM 不再"裸答",而是 基于给定 Context 作答;
python
你是一个专业的助手,请根据以下参考内容回答问题。如果参考内容中没有答案,请明确说明。
【参考内容】
{Context_1}
{Context_2}
...
【用户问题】
{Query}1.2.3 Generate --- 生成阶段
目标 : LLM 基于增强后的 Prompt 生成最终 Response 。
LLM 会:理解用户意图;结合 Context 中的事实;组织自然语言输出。