文章目录
-
- 一、项目背景:预约时段为什么会超卖?
- 二、最朴素的问题:多个请求同时读到剩余名额
- [三、第一层防护:Redis SET NX 去重,防止重复提交](#三、第一层防护:Redis SET NX 去重,防止重复提交)
- [四、第二层防护:Redis SET NX EX 实现分布式锁](#四、第二层防护:Redis SET NX EX 实现分布式锁)
- [五、TTL 的作用:防止死锁,但也带来锁过期风险](#五、TTL 的作用:防止死锁,但也带来锁过期风险)
- [六、正确释放锁:为什么必须校验 owner?](#六、正确释放锁:为什么必须校验 owner?)
- [七、幂等 key 和 lock key 的区别](#七、幂等 key 和 lock key 的区别)
- [八、第三层防护:MySQL 号源检查作为最终兜底](#八、第三层防护:MySQL 号源检查作为最终兜底)
- 九、数据库兜底的三种常见方式
-
- [1. 条件更新](#1. 条件更新)
- [2. 唯一索引](#2. 唯一索引)
- [3. 事务](#3. 事务)
- 十、完整流程
- 总结
在我的「医云问」项目里,预约挂号是技术含量比较高的模块之一,也是面试和答辩中很容易被追问的地方。
这个模块表面上看只是"患者选择时段并提交预约",但真正的难点在于:
在高并发场景下,如何既防止同一个用户重复预约,又防止同一个时段的号源被超卖?
比如某个医生下午 3 点只有 1 个剩余号源,但同时来了 10 个预约请求。如果系统处理不当,就可能出现 10 个人都预约成功的情况,这就是典型的"超卖问题"。
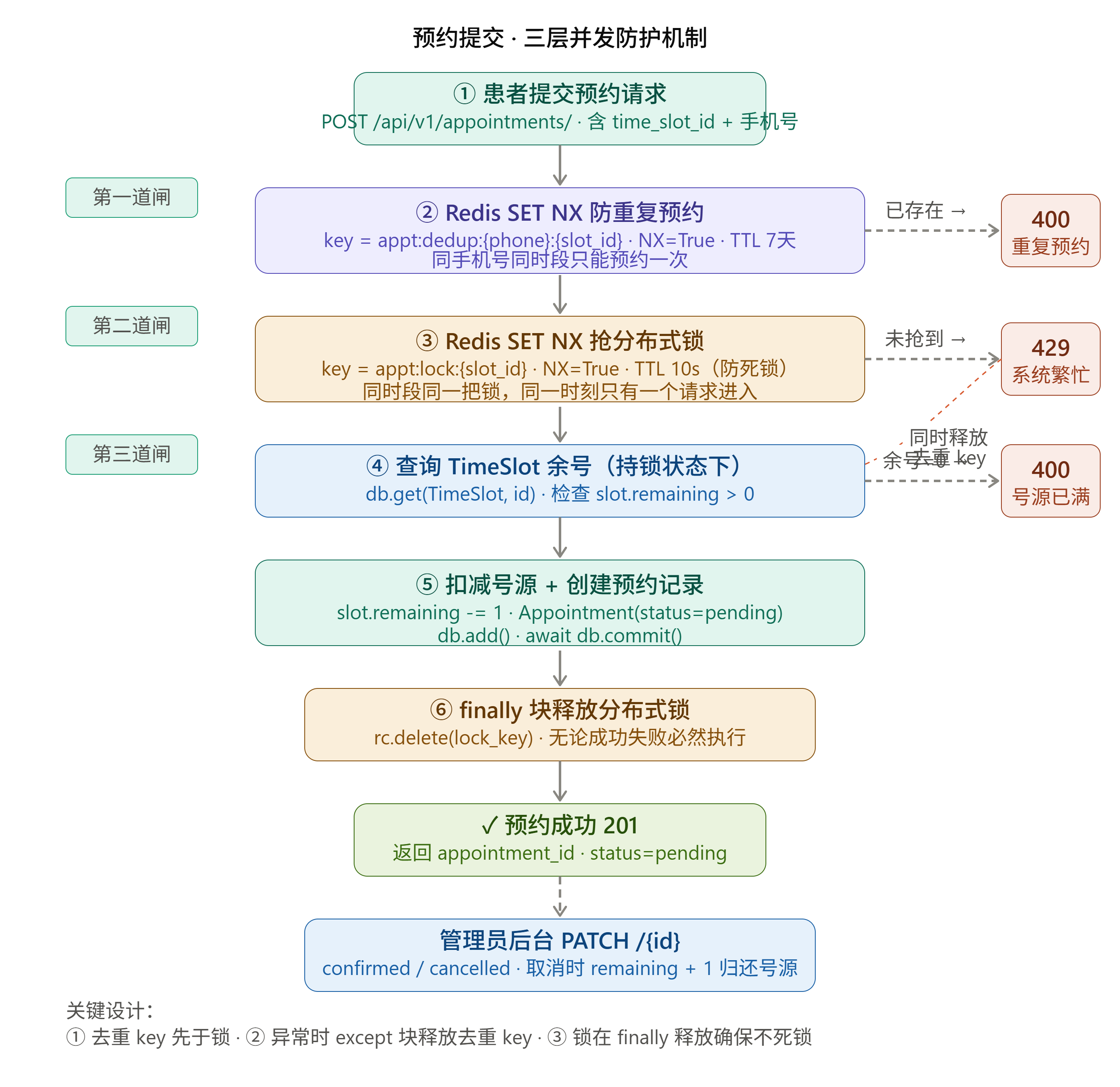
一、项目背景:预约时段为什么会超卖?
预约接口大致如下:
http
POST /api/v1/appointments/前端会传入:
json
{
"time_slot_id": 1001,
"patient_name": "张三",
"patient_phone": "13800000000",
"organization_id": 1
}其中核心字段是:
- time_slot_id:预约的时间段
- patient_phone:患者手机号,用于判断是否重复预约
- organization_id:机构 ID,但这个值不能完全信任前端,后端需要结合业务权限重新校验
假设数据库中的某个时段记录如下:
python
time_slot_id = 1001
remaining = 1如果没有并发控制,两个请求可能同时执行:
html
请求 A:读取 remaining = 1
请求 B:读取 remaining = 1然后它们都认为还有号,于是都执行扣减:
text
请求 A:remaining - 1,创建预约
请求 B:remaining - 1,创建预约最终结果就是:
text
明明只剩 1 个号,却成功预约了 2 个人问题的根源不是"判断逻辑写错了",而是:
读库存、判断库存、扣减库存这几个步骤不是原子操作。
这就是并发场景下最常见的坑:代码在单线程下看起来完全正确,但多个请求同时进来时,就开始"集体表演穿模"。
二、最朴素的问题:多个请求同时读到剩余名额
如果代码逻辑是这样:
python
slot = await db.get(TimeSlot, body.time_slot_id)
if not slot:
raise HTTPException(status_code=404, detail="时间段不存在")
if datetime.datetime.combine(slot.date, slot.start_time) <= datetime.datetime.now():
raise HTTPException(status_code=400, detail="该时间段已过期,不可预约")
if slot.remaining <= 0:
raise HTTPException(status_code=400, detail="该时间段号源已满")
slot.remaining -= 1
appointment = Appointment(
organization_id=body.organization_id,
department_id=slot.department_id,
time_slot_id=slot.id,
patient_name=body.patient_name,
patient_phone=body.patient_phone,
status="pending",
)
db.add(appointment)
await db.commit()在单个请求下没有问题。
但在高并发下,问题出在这一句:
python
if slot.remaining <= 0:多个请求可能在同一时间读到相同的 remaining 值。
也就是说,它们看到的都是"旧世界":
text
请求 A:我看到 remaining = 1,可以预约
请求 B:我也看到 remaining = 1,也可以预约这时候就需要引入并发控制,让同一个时段的预约请求排队执行。
三、第一层防护:Redis SET NX 去重,防止重复提交
我的第一层防护不是分布式锁,而是幂等去重。
因为在真实业务中,用户可能会:
- 连续点击两次提交按钮
- 网络卡顿后重复提交
- 浏览器重试请求
- 前端页面误触发多次请求
所以需要先防止"同一个用户重复预约同一个时段"。
我使用的 Redis key 是:
python
dedup_key = f"appt:dedup:{body.patient_phone}:{body.time_slot_id}"例如:
text
appt:dedup:13800000000:1001
python
is_new = await rc.set(dedup_key, "1", nx=True, ex=604800)对应的 Redis 命令逻辑是:
redis
SET appt:dedup:13800000000:1001 1 NX EX 604800这里的含义是:
SET:设置一个 keyNX:只有 key 不存在时才设置成功EX 604800:设置 7 天过期时间
如果设置成功,说明这是该手机号第一次预约这个时段。
如果设置失败,说明这个用户已经预约过了,直接返回:
http
400 Bad Request业务提示:
text
您已预约该时间段,请勿重复预约这里有一个很重要的细节:
去重 key 要先于分布式锁设置。
因为重复提交是用户维度的问题,而分布式锁是时段维度的问题。先做去重,可以尽早拦截明显无效的请求,减少后面锁竞争和数据库压力。
四、第二层防护:Redis SET NX EX 实现分布式锁
解决完"同一用户重复提交"后,还要解决"多个用户同时抢同一个时段"的问题。
这时就需要分布式锁。
我使用的 lock key 是:
python
lock_key = f"appt:lock:{body.time_slot_id}"例如:
text
appt:lock:1001对应 Redis 命令:
redis
SET appt:lock:1001 request_id NX EX 10含义是:
NX:只有锁不存在时才能加锁成功EX 10:锁 10 秒后自动过期request_id:锁的持有者标识,也可以理解为 owner
这样一来,同一个时段在同一时刻只能有一个请求进入核心扣减逻辑。
如果没有抢到锁,说明当前已有其他请求正在处理这个时段,接口返回:
http
429 Too Many Requests业务提示:
text
系统繁忙,请稍后重试同时要释放刚才设置的去重 key:
text
appt:dedup:{phone}:{slot_id}否则用户这次虽然没有预约成功,但去重 key 已经存在,后续就无法重新提交了。
这一点非常关键:
分布式锁获取失败时,要释放本次创建的幂等 key,让用户具备重试机会。
五、TTL 的作用:防止死锁,但也带来锁过期风险
分布式锁为什么一定要加 TTL?
假设加锁成功后,服务突然崩溃:
text
请求 A 加锁成功
请求 A 服务宕机
finally 没有机会执行
锁一直留在 Redis如果锁没有过期时间,那么这个时段就会被永久锁住,后面的用户永远无法预约。
这就是死锁。
所以需要:
redis
EX 10让锁最多存在 10 秒。
但是 TTL 也不是万能药,它会带来另一个风险:
text
请求 A 加锁成功,TTL = 10s
请求 A 执行业务超过 10s,锁自动过期
请求 B 加锁成功,进入业务逻辑
请求 A 执行完毕,删除锁这时请求 A 可能会误删请求 B 的锁。
所以锁不能只存一个固定值,比如:
redis
SET appt:lock:1001 1 NX EX 10更推荐存一个唯一 owner:
redis
SET appt:lock:1001 request_uuid NX EX 10例如:
text
appt:lock:1001 = "req-abc-123"这样释放锁时,就能判断:
text
只有锁的 value 仍然等于我自己的 request_id,我才能删除它六、正确释放锁:为什么必须校验 owner?
错误释放方式是:
python
redis.delete(lock_key)这段代码看起来很自然,但在分布式锁里是不安全的。
原因是:锁可能已经过期,并且被别的请求重新获取。
更安全的释放逻辑应该是:
text
先判断 lock_key 的 value 是否等于自己的 request_id
如果相等,才删除
如果不相等,说明锁已经不是自己的了,不能删这一步最好用 Lua 脚本保证原子性:
lua
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end因为"先 get 再 delete"如果分成两条命令,中间仍然可能发生并发切换。
所以正确释放锁的核心原则是:
谁加的锁,谁才能释放。不能看到锁就删。
这就像图书馆占座,不能因为桌上有本书,你就默认那是你的书然后拿走。
七、幂等 key 和 lock key 的区别
这个项目里同时用了两个 Redis key:
text
appt:dedup:{phone}:{slot_id}
appt:lock:{slot_id}它们看起来都用了 SET NX EX,但职责完全不同。
| Key 类型 | 示例 | 解决的问题 | 作用范围 | 过期时间 |
|---|---|---|---|---|
| 幂等去重 key | appt:dedup:{phone}:{slot_id} |
防止同一用户重复预约 | 用户 + 时段 | 7 天 |
| 分布式锁 key | appt:lock:{slot_id} |
防止多人并发抢同一号源 | 时段 | 10 秒 |
幂等 key 关注的是:
text
这个用户是不是已经预约过这个时段?lock key 关注的是:
text
此刻有没有其他请求正在处理这个时段?所以它们不能混用。
如果只用幂等 key,无法阻止多个不同用户同时抢同一个时段。
如果只用 lock key,无法阻止同一个用户在不同时间重复提交。
这也是我把它设计成"两层 Redis 防护"的原因。
八、第三层防护:MySQL 号源检查作为最终兜底
Redis 锁能大幅降低并发冲突,但最终的数据一致性一定要落在数据库上。
因为 Redis 是外部组件,可能出现:
- Redis 锁过期
- 服务执行时间过长
- 网络抖动
- 代码异常
- 多服务实例竞争
所以数据库层必须有兜底能力。
在我的项目中,持有锁后会再次查询号源:
python
slot = db.get(TimeSlot, slot_id)
if slot.remaining <= 0:
raise Exception("号源已满")如果还有剩余号源,则执行:
python
slot.remaining -= 1
appointment = Appointment(
time_slot_id=slot_id,
patient_name=patient_name,
patient_phone=patient_phone,
status="pending"
)
db.add(appointment)
db.commit()预约创建后,初始状态是:
text
pending管理员后续可以在后台确认或取消:
text
confirmed / cancelled如果管理员取消预约,则归还号源:
python
slot.remaining += 1这里也要限制状态流转:
text
只有 pending 状态的预约可以确认或取消这样可以避免重复取消、重复归还号源等问题。
九、数据库兜底的三种常见方式
如果要把这个模块讲得更深入,可以从数据库角度补充三种兜底方案。
1. 条件更新
最推荐的扣减方式是使用条件更新:
sql
UPDATE time_slot
SET remaining = remaining - 1
WHERE id = ? AND remaining > 0;然后判断影响行数。
如果影响行数是 1,说明扣减成功。
如果影响行数是 0,说明号源已经不足。
这种写法的好处是:
检查 remaining > 0 和扣减 remaining - 1 在数据库内部一次完成。
这比先查再改更安全。
2. 唯一索引
为了防止同一个用户重复预约同一个时段,可以在数据库层增加唯一索引:
sql
UNIQUE KEY uk_phone_slot (patient_phone, time_slot_id)这样即使 Redis 去重失效,数据库也能兜住最后一道防线。
Redis 是前置拦截,数据库唯一索引是最终裁判。
3. 事务
创建预约和扣减号源应该放在同一个事务中。
否则可能出现:
text
号源扣减成功
预约记录创建失败或者:
text
预约记录创建成功
号源扣减失败这两种都会导致数据不一致。
所以核心逻辑应该具备事务边界:
text
开始事务
扣减号源
创建预约
提交事务只要中间任何一步失败,就整体回滚。
十、完整流程
整个预约流程可以分成三层防护:
| 层次 | 防护目标 | 失败返回码 | 失败后是否释放去重 key |
|---|---|---|---|
| Redis SET NX 去重 | 防止同一用户重复提交 | 400 重复预约 | 不需要 |
| Redis 分布式锁 | 防止多用户并发抢同一时段 | 429 系统繁忙 | 需要 |
| MySQL 号源检查 | 保证最终数据一致性 | 400 号源已满 | 需要 |
完整链路如下:
text
患者提交预约请求
↓
Redis SET NX 创建幂等 key
↓
Redis SET NX 抢分布式锁
↓
查询 TimeSlot 剩余号源
↓
扣减 remaining
↓
创建 Appointment,状态为 pending
↓
提交事务
↓
finally 释放分布式锁
↓
返回预约成功异常场景处理也很关键:
| 场景 | 处理方式 |
|---|---|
| 用户重复预约 | 直接返回 400,不释放 dedup key |
| 没抢到分布式锁 | 返回 429,释放本次 dedup key |
| 号源已满 | 返回 400,释放本次 dedup key |
| 业务执行异常 | 回滚事务,释放 dedup key,finally 释放 lock key |
| 服务宕机 | Redis 锁依靠 TTL 自动过期 |
总结
预约超卖问题本质上是并发读写导致的数据一致性问题。
在这个项目中,我采用了三层并发防护:
- Redis SET NX 去重,防止同一用户重复预约。
- Redis 分布式锁,防止多个用户同时抢占同一个时段。
- MySQL 条件更新、唯一索引和事务,保证最终数据一致性。
这套设计的重点不是单纯使用 Redis,而是明确每一层的职责边界:
text
幂等 key 管用户重复提交
lock key 管并发资源竞争
数据库管最终正确性真正可靠的系统,往往不是靠某一个"神仙组件"解决所有问题,而是通过多层防护,预防好每一个可能失败的场景。