一、写在前面:为什么需要"交互模型"?
过去我们熟悉的多模态助手,大多是这样的工作方式:
text
用户提出问题
模型读取图片或视频片段
模型给出回答
等待下一轮提问这种方式适合做图片问答、视频总结、内容识别,但它并不适合真实世界里的连续场景。
真实场景不会等待用户提问。锅快溢出来了,孩子靠近危险区域了,比赛关键瞬间出现了,手机页面已经跳到下一步了,字幕已经切换到下一句了。等用户再开口问 AI,很多关键时机已经过去。
JoyAI-VL-Interaction 的核心价值就在这里:它不只是回答问题,而是持续观看视觉流,自己判断什么时候应该说话,什么时候应该保持安静,什么时候应该把复杂任务交给后台模型或智能体处理。
二、项目资源入口
| 资源 | 地址 |
|---|---|
| 技术报告 | 技术报告 |
| 代码仓库 | 代码仓库 |
| 模型页面 | 模型页面 |
| 数据集页面 | 数据集页面 |
| 项目主页 | 项目主页 |
三、一句话理解 JoyAI-VL-Interaction
可以把它理解成:
text
一个能够持续观看视频流、判断交互时机、主动响应、支持长程记忆和后台智能体委托的实时视觉语言交互模型。它解决的问题不是"这张图里有什么",而是:
text
当前时刻发生了什么?
这件事要不要提醒用户?
现在说话会不会打扰?
这个任务是不是应该交给后台模型?
前几分钟看到的内容还能不能记住?四、四个核心特性
| 特性 | 解释 |
|---|---|
| 实时在场 | 模型持续观看视频流,而不是等待用户每次提问 |
| 视觉触发主动响应 | 画面出现关键事件时,模型可以主动开口 |
| 时间感知 | 能够按秒级节奏进行提醒、计数、等待和停止 |
| 智能体委托 | 遇到复杂任务时,把任务交给后台模型、工具或 API,同时自己继续观看 |
五、九大能力总览
| 序号 | 能力 | 典型场景 |
|---|---|---|
| 01 | 实时翻译 | 视频字幕、采访字幕、课堂字幕 |
| 02 | 监控与预警 | 摔倒检测、黄牌提醒、安全监控 |
| 03 | App 引导 | 手机操作、购物流程、二手交易平台讲解 |
| 04 | 直播解说 | 宠物直播、旅行视频、比赛解说 |
| 05 | 实时计数 | 飞镖、健身动作、生产线计数 |
| 06 | 时间感知 | 20 秒提醒、每 3 秒播报、定时停止 |
| 07 | 长程视觉记忆 | 回忆几分钟前出现过的物品或数量 |
| 08 | 视觉驱动交互 | 根据画面变化主动聊天、问答和回应 |
| 09 | 智能体委托 | 生成图表、复刻 App UI、数学推导 |
六、完整视频资源引入
下面按页面原始顺序列出所有视频资源。发布到 CSDN 时,如果平台不允许内嵌外链视频,可以保留链接;如果发布为 HTML5 页面,可以直接使用后文 HTML 版中的 <video> 标签。
01. 项目介绍视频
- 分类:首页介绍
- 说明:用于快速了解 JoyAI-VL-Interaction 的整体定位、实时交互方式和演示入口。
- 视频地址 :项目介绍视频
02. 药店就诊动画翻译:JoyAI-VL-Interaction
- 分类:实时翻译
- 说明:随着视频字幕变化持续翻译,体现连续视觉流下的实时响应。
- 视频地址 :药店就诊动画翻译:JoyAI-VL-Interaction
03. 药店就诊动画翻译:豆包对比
- 分类:实时翻译
- 说明:对比传统视频通话助手在字幕变化过程中的响应延迟和连续性。
- 视频地址 :药店就诊动画翻译:豆包对比
04. 药店就诊动画翻译:Gemini 对比
- 分类:实时翻译
- 说明:对比一次性问答式视频助手在实时翻译任务中的局限。
- 视频地址 :药店就诊动画翻译:Gemini 对比
05. 街头采访翻译:JoyAI-VL-Interaction
- 分类:实时翻译
- 说明:持续识别新字幕并翻译,强调不是单帧问答。
- 视频地址 :街头采访翻译:JoyAI-VL-Interaction
06. 街头采访翻译:豆包对比
- 分类:实时翻译
- 说明:对比其只关注提问时刻画面的情况。
- 视频地址 :街头采访翻译:豆包对比
07. 街头采访翻译:Gemini 对比
- 分类:实时翻译
- 说明:对比其无法持续跟随后续字幕变化的情况。
- 视频地址 :街头采访翻译:Gemini 对比
08. 黄牌事件预警:JoyAI-VL-Interaction
- 分类:监控预警
- 说明:事件发生时快速发出提醒,体现视觉触发的主动性。
- 视频地址 :黄牌事件预警:JoyAI-VL-Interaction
09. 黄牌事件预警:豆包对比
- 分类:监控预警
- 说明:对比响应滞后的情况。
- 视频地址 :黄牌事件预警:豆包对比
10. 黄牌事件预警:Gemini 对比
- 分类:监控预警
- 说明:对比没有持续关注后续视觉事件的情况。
- 视频地址 :黄牌事件预警:Gemini 对比
11. 摔倒检测预警:JoyAI-VL-Interaction
- 分类:监控预警
- 说明:在摔倒发生时立即提醒,适合安全监控场景。
- 视频地址 :摔倒检测预警:JoyAI-VL-Interaction
12. 摔倒检测预警:豆包对比
- 分类:监控预警
- 说明:对比安全事件响应延迟。
- 视频地址 :摔倒检测预警:豆包对比
13. 摔倒检测预警:Gemini 对比
- 分类:监控预警
- 说明:对比回看式视频问答和实时告警的差异。
- 视频地址 :摔倒检测预警:Gemini 对比
14. 购物 App 引导:JoyAI-VL-Interaction
- 分类:App 引导
- 说明:跟随手机屏幕变化持续引导用户。
- 视频地址 :购物 App 引导:JoyAI-VL-Interaction
15. 购物 App 引导:豆包对比
- 分类:App 引导
- 说明:对比无法持续主动引导的情况。
- 视频地址 :购物 App 引导:豆包对比
16. 购物 App 引导:Gemini 对比
- 分类:App 引导
- 说明:对比一次性回答无法覆盖动态操作流程的问题。
- 视频地址 :购物 App 引导:Gemini 对比
17. 转转 App 实时讲解:JoyAI-VL-Interaction
- 分类:App 引导
- 说明:按用户节奏跟随不断变化的手机页面进行解释。
- 视频地址 :转转 App 实时讲解:JoyAI-VL-Interaction
18. 转转 App 实时讲解:豆包对比
- 分类:App 引导
- 说明:对比只回应一次、无法持续跟随的情况。
- 视频地址 :转转 App 实时讲解:豆包对比
19. 转转 App 实时讲解:Gemini 对比
- 分类:App 引导
- 说明:对比初始识别强但持续交互不足的情况。
- 视频地址 :转转 App 实时讲解:Gemini 对比
20. 宠物直播解说:JoyAI-VL-Interaction
- 分类:直播解说
- 说明:随着画面中宠物变化持续给出有依据的解说。
- 视频地址 :宠物直播解说:JoyAI-VL-Interaction
21. 宠物直播解说:豆包对比
- 分类:直播解说
- 说明:对比只描述少数片段、容易漏掉真实画面的情况。
- 视频地址 :宠物直播解说:豆包对比
22. 宠物直播解说:Gemini 对比
- 分类:直播解说
- 说明:对比只给出一次回应而没有持续解说。
- 视频地址 :宠物直播解说:Gemini 对比
23. 旅行场景解说:JoyAI-VL-Interaction
- 分类:直播解说
- 说明:保持用户要求的解说节奏,并持续扎根于画面内容。
- 视频地址 :旅行场景解说:JoyAI-VL-Interaction
24. 旅行场景解说:豆包对比
- 分类:直播解说
- 说明:对比无法按要求持续重复解说。
- 视频地址 :旅行场景解说:豆包对比
25. 旅行场景解说:Gemini 对比
- 分类:直播解说
- 说明:对比解说风格与任务要求不匹配的情况。
- 视频地址 :旅行场景解说:Gemini 对比
26. 飞镖投掷计数:JoyAI-VL-Interaction
- 分类:实时计数
- 说明:抓住重复事件出现的时机并进行计数。
- 视频地址 :飞镖投掷计数:JoyAI-VL-Interaction
27. 飞镖投掷计数:豆包对比
- 分类:实时计数
- 说明:对比只回复少数几次且延迟较高。
- 视频地址 :飞镖投掷计数:豆包对比
28. 飞镖投掷计数:Gemini 对比
- 分类:实时计数
- 说明:对比没有完成连续计数任务。
- 视频地址 :飞镖投掷计数:Gemini 对比
29. 波比跳计数:JoyAI-VL-Interaction
- 分类:实时计数
- 说明:跟踪重复运动动作并在正确时刻更新计数。
- 视频地址 :波比跳计数:JoyAI-VL-Interaction
30. 波比跳计数:豆包对比
- 分类:实时计数
- 说明:对比只回应一次、缺少连续计数。
- 视频地址 :波比跳计数:豆包对比
31. 波比跳计数:Gemini 对比
- 分类:实时计数
- 说明:对比无法可靠完成实时计数。
- 视频地址 :波比跳计数:Gemini 对比
32. 烹饪场景定时提醒:JoyAI-VL-Interaction
- 分类:时间感知
- 说明:在接近目标时间点提醒,体现模型对时间流逝的判断。
- 视频地址 :烹饪场景定时提醒:JoyAI-VL-Interaction
33. 烹饪场景定时提醒:豆包对比
- 分类:时间感知
- 说明:对比没有按目标时间提醒。
- 视频地址 :烹饪场景定时提醒:豆包对比
34. 烹饪场景定时提醒:Gemini 对比
- 分类:时间感知
- 说明:对比提醒时间偏差较大的情况。
- 视频地址 :烹饪场景定时提醒:Gemini 对比
35. 灶台清洁计时:JoyAI-VL-Interaction
- 分类:时间感知
- 说明:按要求间隔计数,并能在收到指令时停止。
- 视频地址 :灶台清洁计时:JoyAI-VL-Interaction
36. 灶台清洁计时:豆包对比
- 分类:时间感知
- 说明:对比无法可靠保持重复时间节奏。
- 视频地址 :灶台清洁计时:豆包对比
37. 灶台清洁计时:Gemini 对比
- 分类:时间感知
- 说明:对比短暂回应后停止交互。
- 视频地址 :灶台清洁计时:Gemini 对比
38. 肉丸数量回忆:JoyAI-VL-Interaction
- 分类:长程视觉记忆
- 说明:从几分钟前的视觉上下文中正确回答细节。
- 视频地址 :肉丸数量回忆:JoyAI-VL-Interaction
39. 肉丸数量回忆:豆包对比
- 分类:长程视觉记忆
- 说明:对比给出错误数量的情况。
- 视频地址 :肉丸数量回忆:豆包对比
40. 场景感知闲聊与 GDP 图表委托
- 分类:视觉驱动交互
- 说明:实时调用后台模型生成图表,同时继续处理人物出现和多轮问答。
- 视频地址 :场景感知闲聊与 GDP 图表委托
41. 手机端实时闲聊
- 分类:视觉驱动交互
- 说明:在移动端画面变化中保持自然聊天和视觉 grounding。
- 视频地址 :手机端实时闲聊
42. 手机 App 委托
- 分类:Agent 委托
- 说明:后台模型复刻手机 App UI,交互模型继续完成计数等实时任务。
- 视频地址 :手机 App 委托
43. 微分中值定理委托
- 分类:Agent 委托
- 说明:后台模型推导数学证明,交互模型继续负责实时多轮问答。
- 视频地址 :微分中值定理委托
44. 穿搭指导
- 分类:更多能力
- 说明:根据摄像头中的衣着画面给出搭配建议。
- 视频地址 :穿搭指导
45. 找橙汁与细节回忆
- 分类:更多能力
- 说明:回忆数分钟前出现过的商品或视觉细节。
- 视频地址 :找橙汁与细节回忆
46. 赛车实时解说
- 分类:更多能力
- 说明:对高速变化场景进行实时赛事解说。
- 视频地址 :赛车实时解说
47. 主动响应演示
- 分类:更多能力
- 说明:根据视觉事件主动开口,而不是等待用户再次提问。
- 视频地址 :主动响应演示
48. 做饭指导
- 分类:更多能力
- 说明:在厨房场景中根据画面进行免手持指导。
- 视频地址 :做饭指导
49. 虚拟陪伴
- 分类:更多能力
- 说明:以更自然、更有情绪温度的方式进行视觉陪伴。
- 视频地址 :虚拟陪伴
50. 购物过程分钟级视觉回忆
- 分类:更多能力
- 说明:在内容密集的购物浏览过程中保留视觉细节。
- 视频地址 :购物过程分钟级视觉回忆
51. 视觉诗歌创作
- 分类:更多能力
- 说明:根据当前画面进行创意文本生成,并能按需停止。
- 视频地址 :视觉诗歌创作
52. 找牛奶提醒
- 分类:更多能力
- 说明:在目标商品出现时及时触发提醒。
- 视频地址 :找牛奶提醒
七、完整图片资源引入
01. 总览图
项目页面中的概览图,用于展示 JoyAI-VL-Interaction 的整体工作方式。

02. 系统架构图
项目页面中的系统架构图,用于说明模型、编码、记忆、语音和 Agent 的关系。
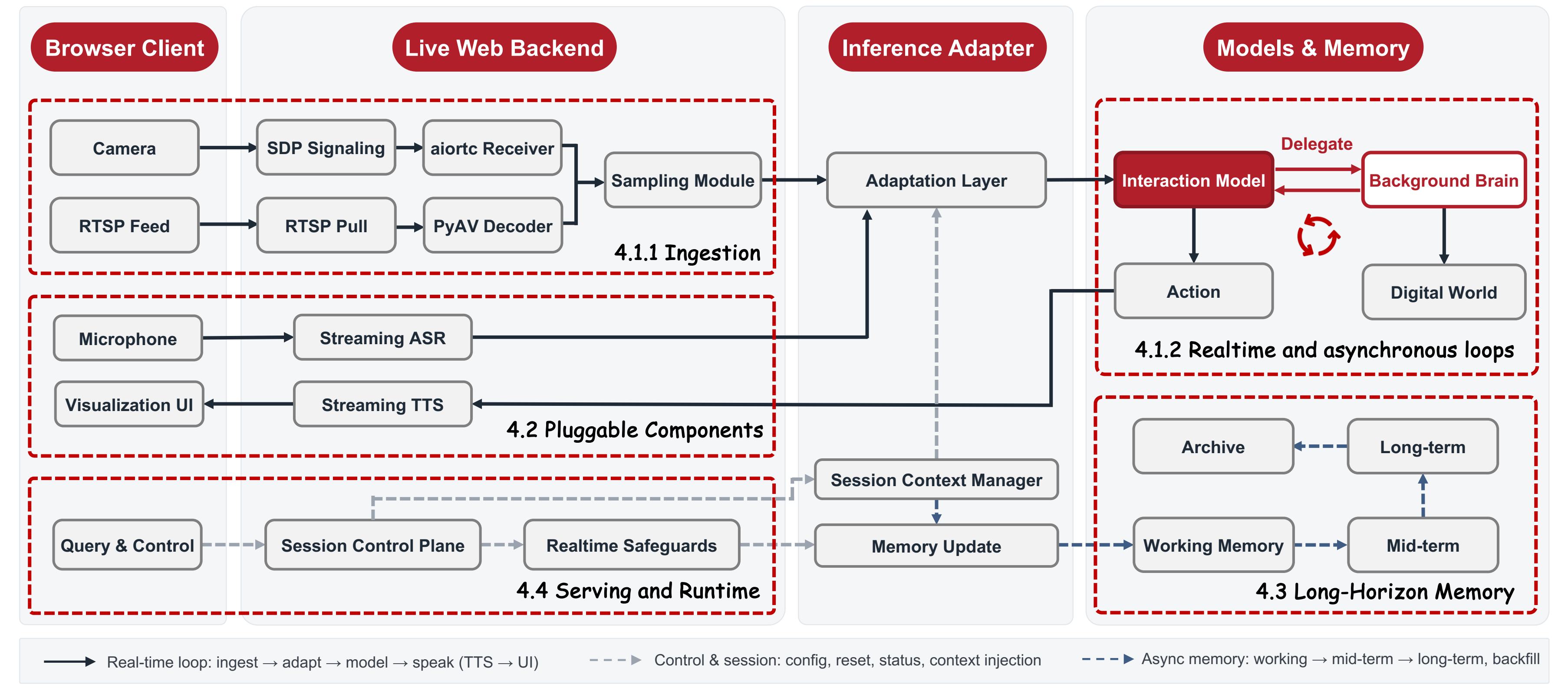
八、系统方法解析
JoyAI-VL-Interaction 的核心不是把语音、视觉和工具简单拼在一起,而是让模型在连续视频流中学习一个关键决策:
text
说话 / 保持安静 / 委托后台系统中包含几个关键组件:
| 组件 | 作用 |
|---|---|
| 视觉语言交互模型 | 负责理解当前画面并判断交互时机 |
| 预测式视频编码 | 降低长视频流中的 token 消耗 |
| 语音输入输出 | 通过流式语音识别和语音合成完成自然交互 |
| 长程记忆 | 保存跨分钟甚至跨小时的有用视觉信息 |
| 智能体桥接 | 把复杂任务交给后台模型、工具或业务 API |
| 可视化界面 | 展示模型响应、视频画面、事件提醒和交互状态 |
九、评测结果解读
页面中给出了 58 个真实视觉交互案例的人工成对评测。评测重点不是单纯看答案是否正确,而是同时关注两个维度:
text
回答内容是否合适
响应时机是否正确整体结果如下:
| 对比对象 | JoyAI-VL-Interaction 胜率 | 平局 | 对方胜率 |
|---|---|---|---|
| 豆包 | 77.6% | 17.2% | 5.2% |
| Gemini | 87.9% | 10.3% | 1.7% |
最明显的优势集中在:
- 监控与预警
- 实时翻译
- 实时计数
- 直播解说
- 视觉事件触发响应
这些任务的共同点是:时机比单次回答更重要。
十、为什么它适合企业落地?
如果把 JoyAI-VL-Interaction 放到企业系统里,它可以形成下面这种架构:
text
摄像头 / 直播流 / 手机屏幕
↓
推流与抽帧服务
↓
JoyAI-VL-Interaction 实时交互模型
↓
语音播报 / 页面提醒 / 告警推送
↓
长期记忆库 / 业务 API / 后台智能体适合的落地方向包括:
| 场景 | 用法 |
|---|---|
| 安防监控 | 摔倒、危险区域、异常行为提醒 |
| 直播助手 | 自动解说、弹幕生成、事件提醒 |
| 智能导购 | 跟随商品浏览过程进行推荐和解释 |
| App 教学 | 根据手机屏幕变化实时指导 |
| 老人儿童陪护 | 视觉事件主动提醒 |
| 工业巡检 | 异常画面检测和实时告警 |
| 运动训练 | 动作识别、计数、节奏提醒 |
| 教育讲解 | 看课件、看板书、跟随演示过程讲解 |
十一、总结
JoyAI-VL-Interaction 带来的启发是:多模态模型正在从"看一张图回答一个问题",走向"持续存在于真实世界中并在关键时刻帮助用户"。
它真正强调的是:
text
不是用户问了什么,而是当前时刻是否需要 AI 开口。这会影响未来很多 AI 产品的交互方式。未来的智能助手不一定总是聊天框,也可能是一个持续在场的视觉伙伴:它看得见、记得住、懂时机、能提醒,也能把复杂任务交给后台智能体。