一句话总结
把训练数据做细,构造大规模、高质量、跨领域的长程轨迹样本数据,Agents-A1 利用多领域 OPD 让 35B MoE 模型达到与顶级万亿参数模型相当的水平
- 论文标题:Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
- 论文地址 :https://arxiv.org/abs/2606.30616
- 作者背景:上海人工智能实验室(Shanghai Artificial Intelligence Laboratory)
- 代码地址 :https://github.com/InternScience/Agents-A1
- 模型地址 :https://huggingface.co/InternScience/Agents-A1
一、动机
构建能自主规划、调用工具、长时间连续工作的智能体,是当前大模型落地的核心方向。这类长程任务(long-horizon task)的难点在于:任务跨度越长,早期错误越容易逐步积累,模型需要根据新信息做持续修正
现有的做法大致分两条路线:
- 堆参数:用万亿级参数将各种推理模式、工具使用行为和领域知识内化到模型中。这条路有效,但复现门槛极高------你必须有对等的模型规模、数据和算力,小团队几乎无法复刻。
- 扩视野(horizon):不放大模型本身,而是收集更详细的中间信息,例如把 agent 的知识获取、动作执行、观察解读、验证判断都转化为训练信号
Agents-A1 走的是第二条路。它的核心主张是:想让 agent 在长程任务上变强,与其拼参数规模,不如把过程训练做厚做扎实
"从过程中学" 本身并不新鲜,多数 agent 模型都会收集推理步骤和工具调用轨迹来做训练,但常规过程数据要么太短、要么缺乏逐步验证、要么只能靠人工标注无法规模化
Agents-A1 的核心贡献是,跑通了一套大规模、高质量(平均数万 token,每步带有真实执行结果和对错验证结果)数据生成与模型训练的流程。这种数据互联网上爬不到,纯靠人标也负担不起
二、实现方案
2.1 知识-动作图谱
为了自动、大规模生产 "超长 + 步骤可验证" 的轨迹,Agents-A1 构建了一套知识-动作图谱(Knowledge-Action Graph, KAG)。与普通知识图谱存储实体与关系不同,KAG 记录的是 "一道题是怎么一步步做出来、每步又怎么验对的"
形式上,KAG 是一个四元组 G=(C, A, O, V)
| 元素 | 含义 | 举例 |
|---|---|---|
| C(语料) | 领域知识、证据、约束 | wiki 页面、竞赛说明书、科学问题 |
| A(动作空间) | 可执行的操作 | 搜索查询、代码编辑、工具调用 |
| O(观察空间) | 动作的返回 | 检索结果、执行日志、提交分数 |
| V(验证集) | 正确性检查 | 答案匹配、证据链核验、格式校验 |
一个动作可被记为 (s_t, a_t, o_t, v_t) ,其中 s_t 表示当前状态(已掌握的证据加上前几步的观察)。成功和失败的轨迹都被保留到图谱 ------ 失败轨迹尤其有价值,能从中学到教训,实现逐步的功劳归因
初始图谱不可能覆盖所有场景,Agents-A1 用一个三方博弈游戏来自动扩展:出题者(proposer)从图中采样出约束任务;解题者(solver)用搜索和工具去解;裁判(verifier)验答案、验证据链、检查有无走捷径。通过校验的轨迹写回图中,不通过的被打回重练。图谱就这样越滚越大、越滚越难
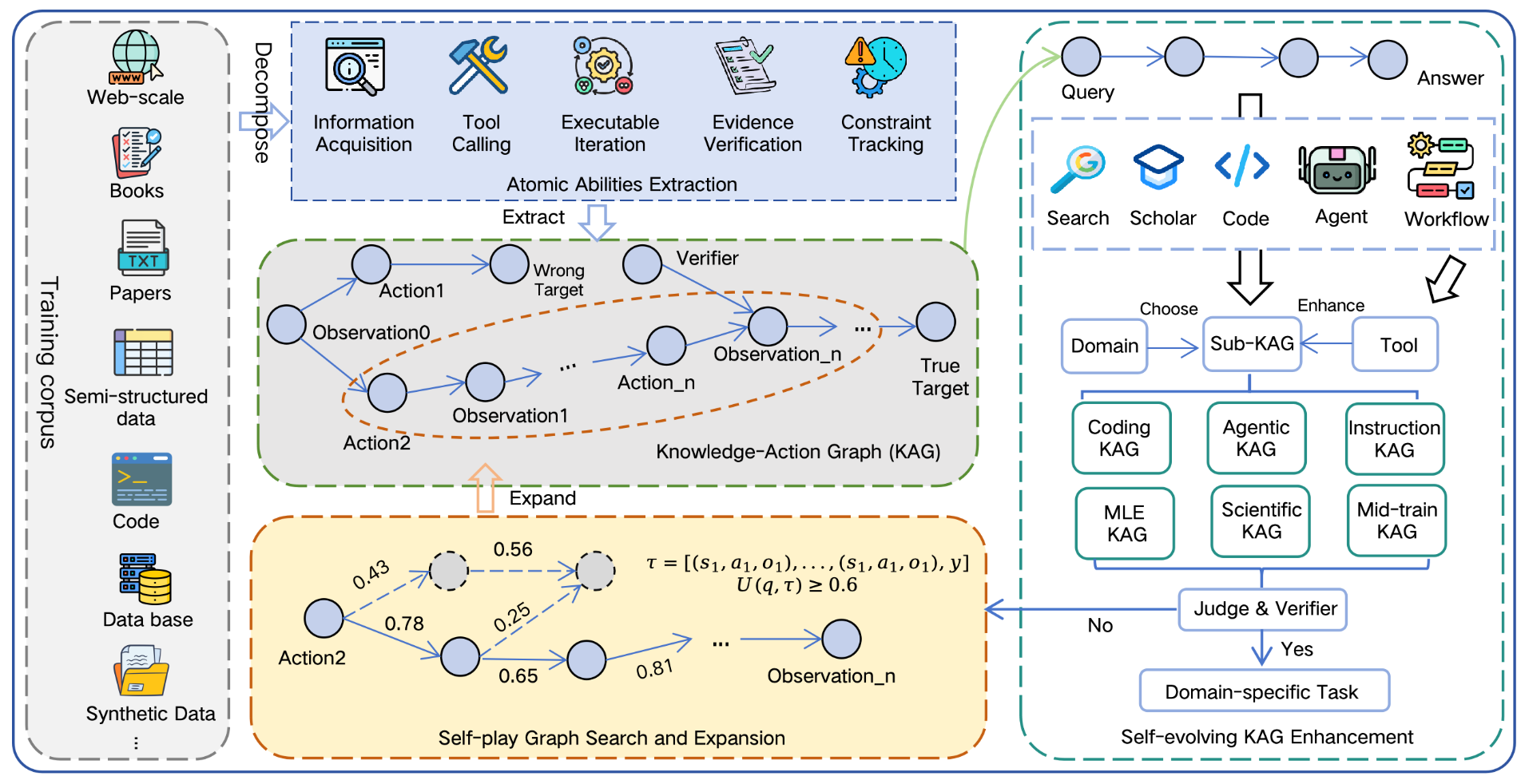
最终产出覆盖六大领域(长程搜索、MLE 工程、科学推理、指令遵循、工具调用、通用智能体)的训练轨迹约 10 万条,平均长度 45K token
2.2 三阶段训练
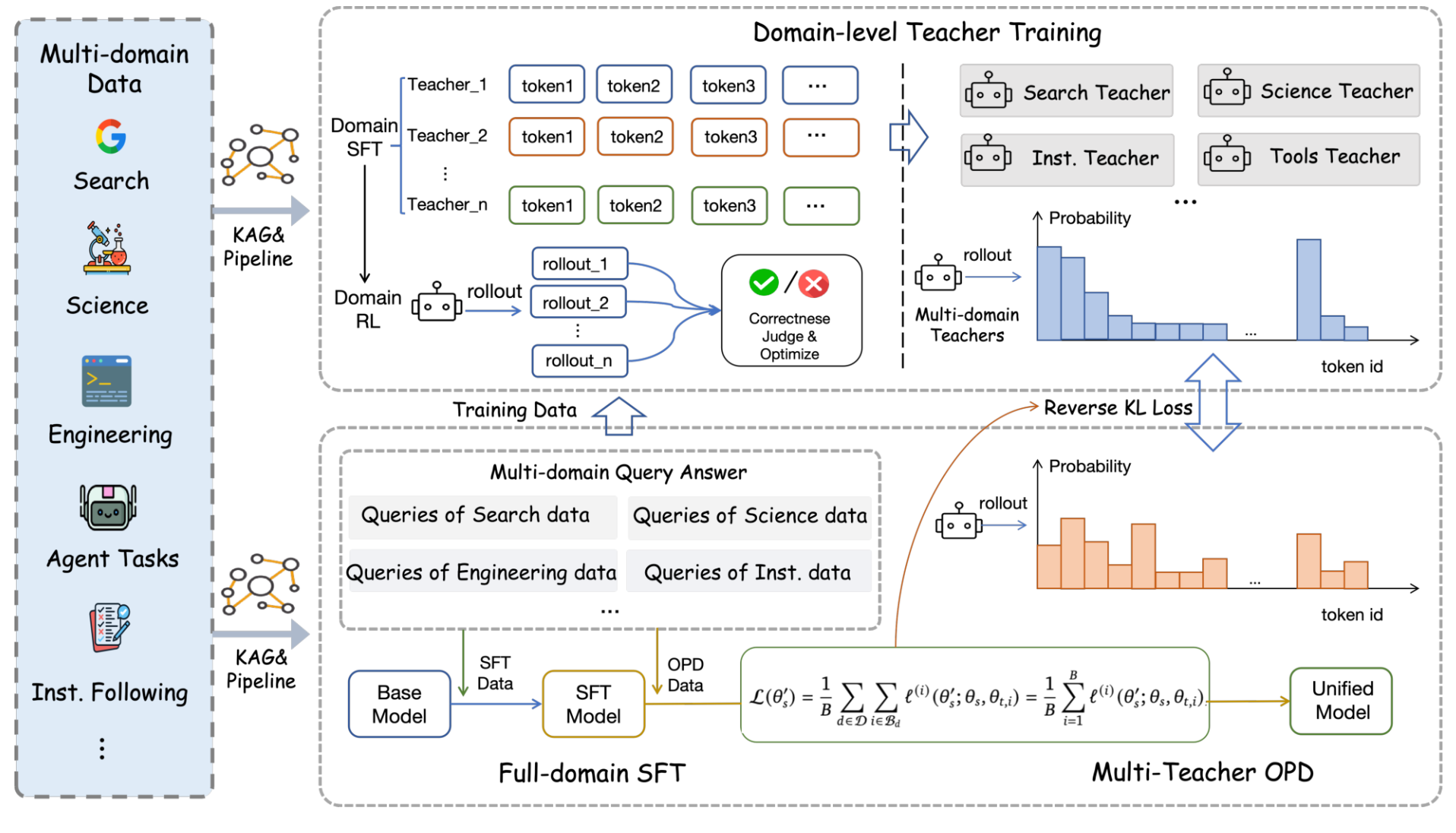
- 全域监督微调
基座模型选用 Qwen3.5-35B-A3B,用上述 10 万条跨领域轨迹做标准 SFT。训练后的模型在搜索、科研等任务上提升显著,但指令遵循和通用智能体任务却变差了。原因是不同领域存在推理模式冲突:长程搜索是 "多轮 × 短思考 × 频繁调用工具" 的快节奏,长指令遵循是 "单轮 × 长思考 × 一次输出" 的慢节奏,全域 SFT 无法平衡两种截然不同的节奏模式
- 领域教师训练
为解决上述冲突,Agents-A1 为每个领域单独训练一个专科教师模型:
| 教师 | 训练方式 | 提升效果 |
|---|---|---|
| 搜索教师 | SFT + GRPO RL | GAIA 59.8 → 95.1 |
| 科学教师 | 两阶段 SFT(推理 → 工具增强) | FS-R 2.5 → 54.3 |
| 指令教师 | 两阶段 GRPO RL(约束 → 长上下文) | IFBench 70.2 → 82.0 |
| 工具教师 | SFT + RL(64 样本硬集 + 数据复用) | τ²-Bench 32.5 → 82.5 |
每位教师只需在自己的领域做到极致,不用关心跨域兼容问题
- 多教师 OPD 与显著词表对齐
最后一步是把所有教师的能力统一蒸馏进一个学生模型
与传统蒸馏(老师给标准答案,学生模仿)不同,在线策略蒸馏(On-Policy Distillation)让学生自己生成回答,然后由对应领域的教师针对学生写的内容逐 token 打分纠正
为避免全词表比对的高成本,论文提出了显著词表对齐(Salient Vocabulary Alignment, SVA)。在每个 token 位置,只取教师分布中概率最高的 top-k 个候选词,在这个紧凑子集上做截断反向 KL 散度对齐
为防止跨域信号冲突(如前文提到的推理模式相反),蒸馏时做了两手准备:
- 硬路由:每道题只由对应领域的教师来教,不混合多位教师的信号
- 领域归一化聚合:先在每个领域内平均 loss,再跨域平均。这样数据量大的领域不会抢走全部梯度话语权
三、实验结果
3.1 35B vs 万亿参数
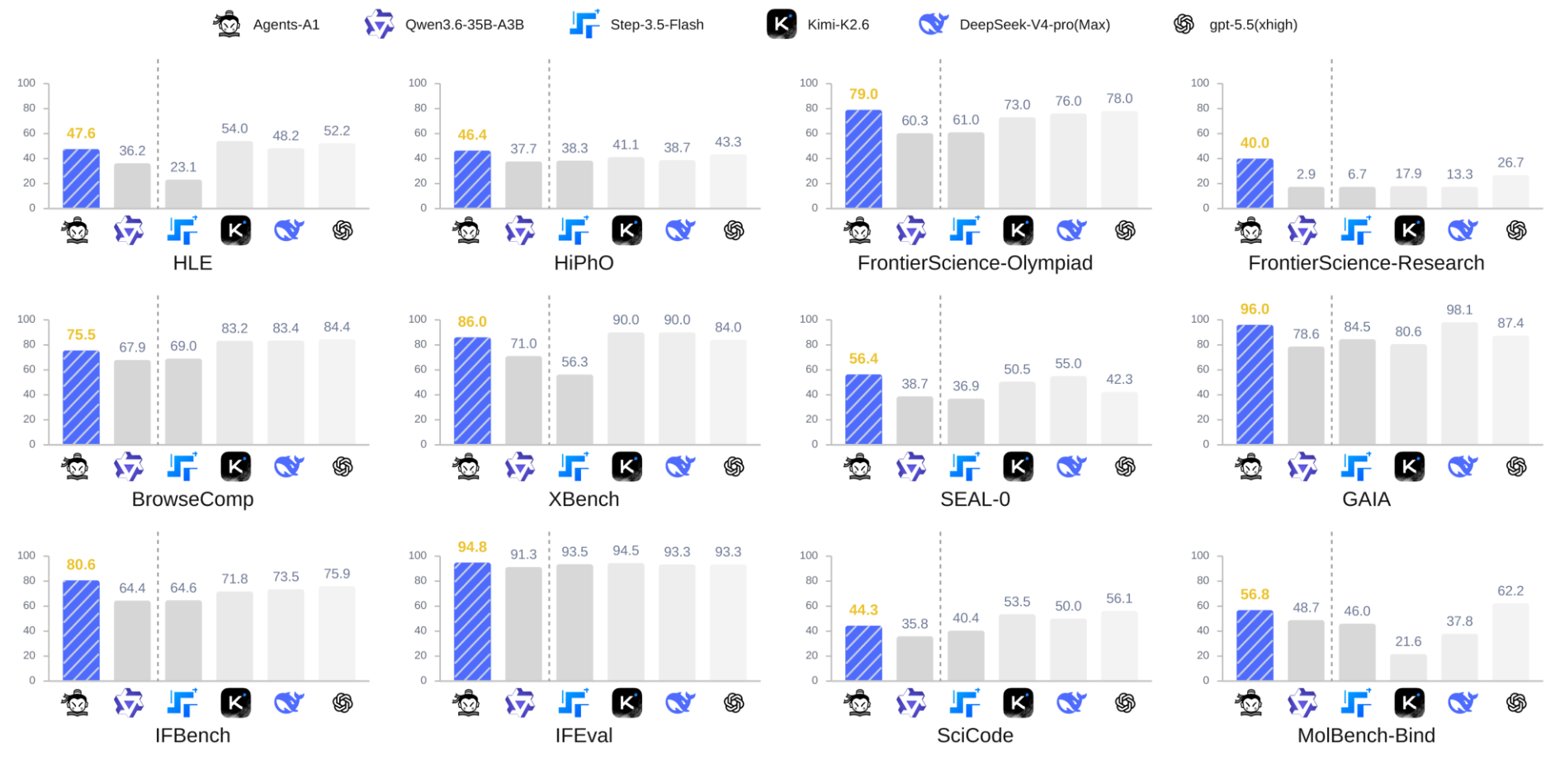
在长程搜索、MLE 工程、科学推理、指令遵循、工具调用、通用智能体 6 个领域的 16 个基准上测试,除了对比 Qwen3.6-35B-A3B、NexN2-mini 这些同级别选手以外,还与 Kimi-K2.6、DeepSeek-V4-Pro、GPT 5.5 这些万亿参数规模模型同台竞技
注:HiPhO、FS-O、FS-R 三项基准上对比模型没开工具,而 Agents-A1 是带工具(search / visit / code / scholar)跑的
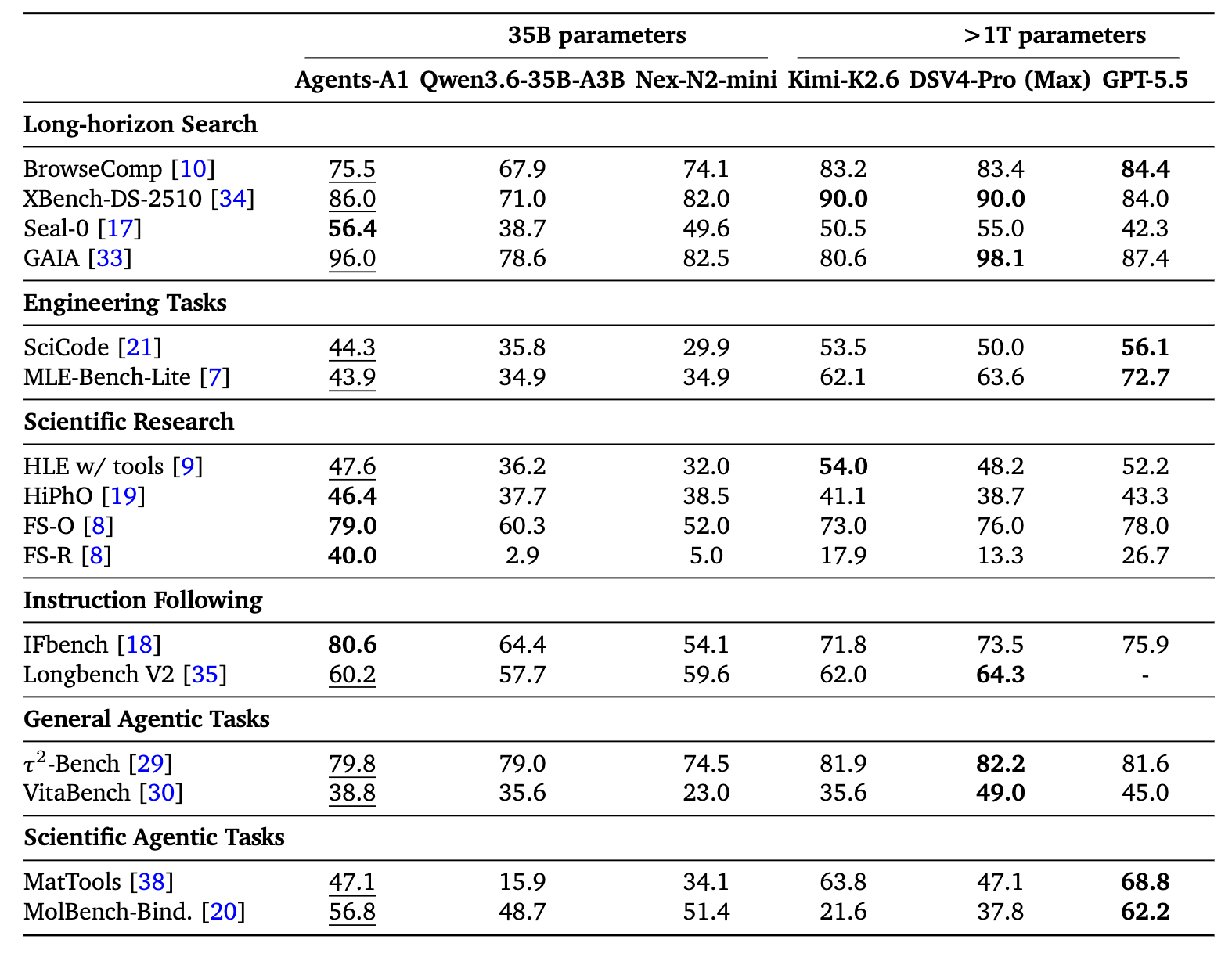
Agents-A1 在 5 个基准上取得全场最佳,超越所有万亿参数模型,3 个 基准上与万亿模型保持竞争力
3.2 长程实战案例
- 鲸鱼叫声识别:
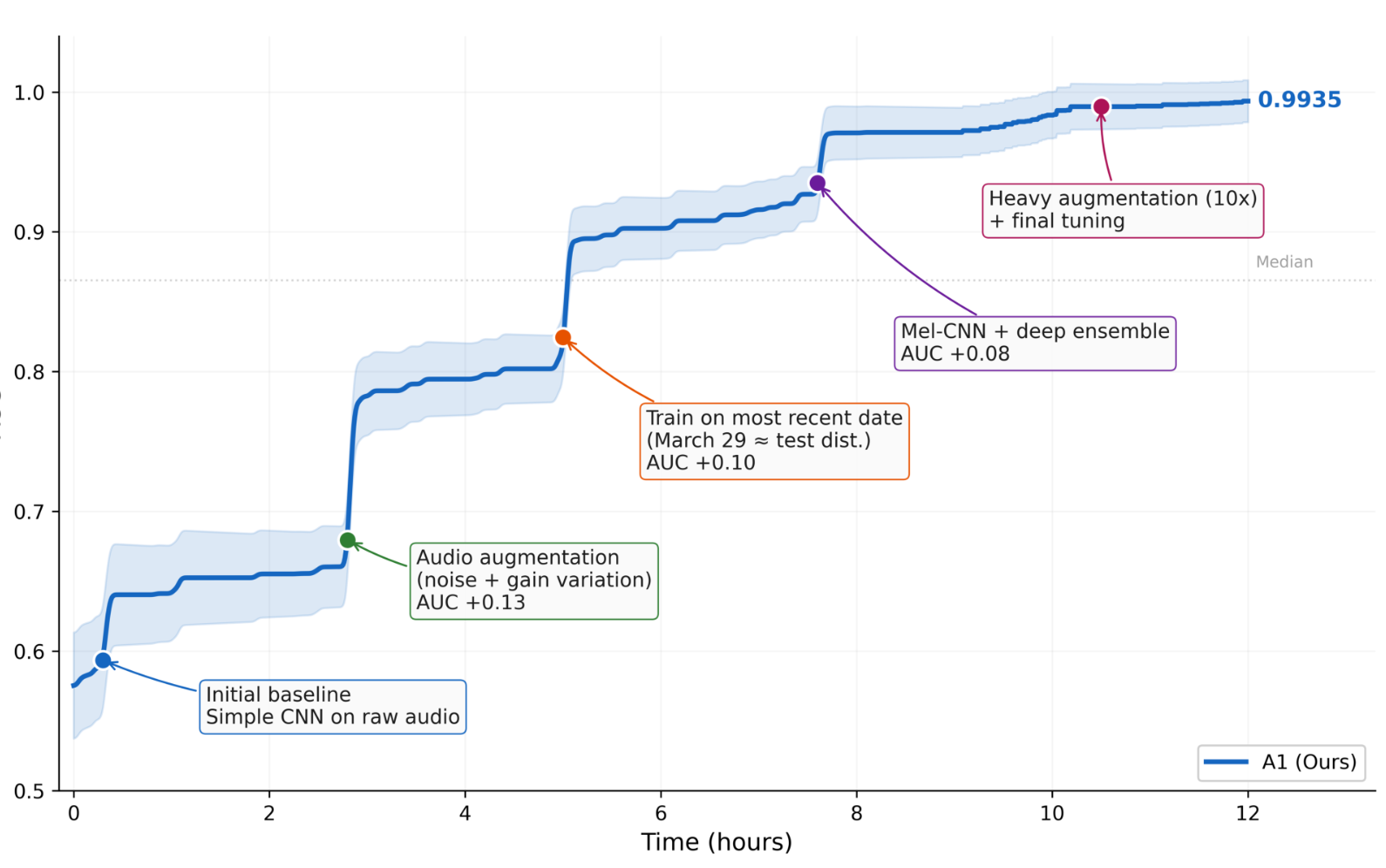
在 MLE-Bench 的 ICML 2013 Whale Challenge 上,Agents-A1 被给定数据集后全自动运行 12 小时,0 人工干预。它从 naive CNN 基线开始,自主进行时域分析、音频增强、Mel-spectrogram CNN 集成、大规模增强等一系列改进,最终将验证集 AUC 从 0.58 提升至 0.9935,达到金牌水平
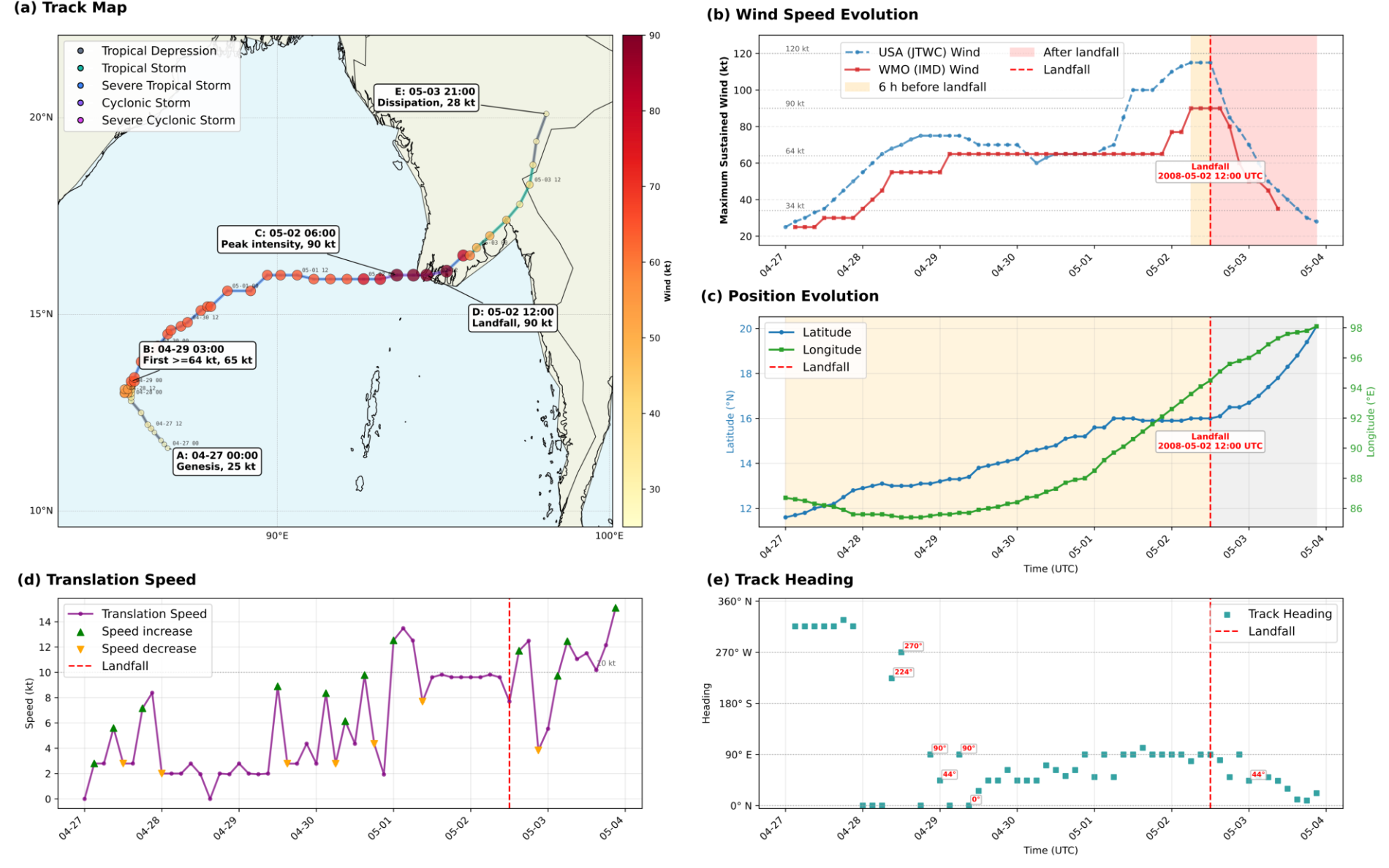
- 热带气旋分析闭环
给定真实最佳路径数据(IBTrACS),Agents-A1 自主完成数据获取 → 清洗 → 指标计算 → 可视化 → 报告撰写的完整研究闭环,输出包括路径图、风速演变、移速和航向变化等诊断图