本文面向 AI 战略分析师 / 算法工程师场景 /AI Agent 工程师
结合 Hermes Agent 四层记忆、自进化闭环、Skill 自动生成、RL 轨迹学习
靶向改造:本体论根因分析系统(LLM + MCP + AtlasGraph + 六阶段自动化工作流)
文章目录
-
- [一、Hermes Agent 可迁移的核心机制总览](#一、Hermes Agent 可迁移的核心机制总览)
- 二、经典流程改造一:记忆系统嵌入六阶段工作流
-
- [2.1 原有六阶段工作流](#2.1 原有六阶段工作流)
- [2.2 Hermes 四层记忆系统映射](#2.2 Hermes 四层记忆系统映射)
- [2.3 记忆注入时机设计](#2.3 记忆注入时机设计)
- [2.4 关键实现:冻结快照模式](#2.4 关键实现:冻结快照模式)
- 三、经典流程改造二:自更新系统(自进化闭环)
-
- [3.1 Hermes 五阶段闭环映射到运维场景](#3.1 Hermes 五阶段闭环映射到运维场景)
- [3.2 Skill 自动生成触发条件设计](#3.2 Skill 自动生成触发条件设计)
- [3.3 Patch 增量更新机制](#3.3 Patch 增量更新机制)
- [四、经典流程改造三:RL 轨迹学习与数据飞轮](#四、经典流程改造三:RL 轨迹学习与数据飞轮)
-
- [4.1 Hermes 数据飞轮机制](#4.1 Hermes 数据飞轮机制)
- [4.2 运维场景改造:排障决策轨迹优化](#4.2 运维场景改造:排障决策轨迹优化)
- [4.3 轨迹导出实现](#4.3 轨迹导出实现)
- 五、经典流程改造四:上下文压缩引擎
-
- [5.1 Hermes ContextCompressor 设计](#5.1 Hermes ContextCompressor 设计)
- [5.2 运维场景适配](#5.2 运维场景适配)
- [六、经典流程改造五:子 Agent 委托机制](#六、经典流程改造五:子 Agent 委托机制)
-
- [6.1 Hermes 子 Agent 设计](#6.1 Hermes 子 Agent 设计)
- [6.2 运维多 Agent 编排](#6.2 运维多 Agent 编排)
- 七、整体架构改造全景图
- 八、实施路线图建议
- 九、关键设计决策总结
一、Hermes Agent 可迁移的核心机制总览
Hermes Agent 由 Nous Research 在 2026 年 2 月发布(MIT 协议),核心理念是"越用越强的自进化 Agent"。经过对其架构的深度调研,以下 六大机制 可以直接迁移到运维根因分析系统:
| 序号 | Hermes 机制 | 运维系统映射 | 改造价值 |
|---|---|---|---|
| 1 | 四层记忆系统 | 运维经验知识库 | 故障处理经验不丢失,跨会话复用 |
| 2 | 自进化闭环(5阶段) | 故障自愈流程 | 同类故障自动识别 + 方案自动优化 |
| 3 | Skill 自动生成 + Patch 修复 | 根因分析 Skill 库 | 复杂排障流程自动沉淀为可复用技能 |
| 4 | FTS5 全文检索 + LLM 摘要 | 历史故障语义检索 | 按故障特征快速匹配历史案例 |
| 5 | RL 轨迹学习 + 数据飞轮 | 排障决策轨迹优化 | 积累训练数据,微调专属运维模型 |
| 6 | 上下文压缩引擎 | 长链路排障上下文管理 | 多跳图查 + 多轮对话不爆 token |
二、经典流程改造一:记忆系统嵌入六阶段工作流
2.1 原有六阶段工作流
阶段1:意图识别 → 阶段2:规则匹配 → 阶段3:多跳图查
→ 阶段4:连通性检测 → 阶段5:指标采集 → 阶段6:报告输出2.2 Hermes 四层记忆系统映射
Hermes 的四层记忆本质上是 人类认知的三记忆模型(程序性/情景/语义记忆)的工程实现。改造后的运维记忆系统如下:
┌─────────────────────────────────────────────────────┐
│ 运维记忆系统架构 │
├─────────────────────────────────────────────────────┤
│ L1 常驻提示记忆 (MEMORY.md + USER.md) │
│ ├─ 系统拓扑快照(服务依赖图、关键配置) │
│ ├─ 运维 SOP 摘要(黄金流程、紧急预案) │
│ ├─ 用户偏好(告警阈值、报告格式、通知渠道) │
│ └─ 字符限制:3575 字符,强制筛选真正重要的信息 │
├─────────────────────────────────────────────────────┤
│ L2 会话归档记忆 (SQLite + FTS5 全文索引) │
│ ├─ 每次排障的完整对话/工具调用轨迹 │
│ ├─ FTS5 全文检索:按故障现象/服务名/时间范围快速定位 │
│ ├─ LLM 摘要压缩:长链路排障过程压缩为结构化摘要 │
│ └─ 写竞争处理:随机抖动重试(15次,20-150ms) │
├─────────────────────────────────────────────────────┤
│ L3 技能记忆 (OPS_SKILL.md 排障技能库) │
│ ├─ 按故障类型组织:CPU飙升/内存泄漏/磁盘满/网络丢包/DB慢查询│
│ ├─ 每份 SKILL 含:触发条件、排障步骤、工具调用序列、回滚方案 │
│ ├─ 自修复机制:Patch 增量更新,不破坏已有有效逻辑 │
│ └─ 两级缓存加速读取(LRU 内存 + 磁盘快照) │
├─────────────────────────────────────────────────────┤
│ L4 用户画像记忆 (Operator Profile) │
│ ├─ 值班工程师偏好(惯用诊断命令、偏好的可视化方式) │
│ ├─ 团队协作模式(升级路径、审批流程) │
│ └─ 方言式建模(Honcho 风格):从行为推断,而非显式配置 │
└─────────────────────────────────────────────────────┘2.3 记忆注入时机设计
将记忆系统嵌入到六阶段工作流的每个关键节点:
| 阶段 | 记忆注入内容 | 来源层 | 作用 |
|---|---|---|---|
| 意图识别 | 历史相似故障的意图分类 + 用户偏好 | L2 + L4 | 提升意图分类准确率 |
| 规则匹配 | 已沉淀的排障 Skill + SOP 摘要 | L3 + L1 | 快速匹配已知故障模式 |
| 多跳图查 | 系统拓扑快照 + 最近变更记录 | L1 + L2 | 缩小图查询范围 |
| 连通性检测 | 历史连通性问题模式 | L2 | 优先检测高频故障点 |
| 指标采集 | 用户偏好的指标维度 + 阈值 | L4 + L1 | 采集更有针对性的指标 |
| 报告输出 | 历史报告模板 + 格式偏好 | L2 + L4 | 生成符合团队习惯的报告 |
2.4 关键实现:冻结快照模式
借鉴 Hermes 的核心创新------冻结快照模式:
python
class OpsMemoryManager:
"""
运维记忆管理器:读路径和写路径完全解耦
- 会话开始时拍摄记忆快照,注入 System Prompt
- 整个会话期间 System Prompt 不变(保持 KV Cache 有效性)
- 排障过程中写入的记忆仅更新磁盘,下次会话才可见
"""
def session_start(self, session_id: str):
# 1. 拍摄四层记忆快照
snapshot = {
"topology": self.load_topology_snapshot(), # L1
"recent_incidents": self.fts5_search( # L2
"similar_incident",
limit=5
),
"relevant_skills": self.match_skills( # L3
context=self.current_context
),
"operator_profile": self.load_profile() # L4
}
# 2. 冻结快照,注入 System Prompt
self.frozen_snapshot = snapshot
return self._build_system_prompt(snapshot)
def record_experience(self, incident: dict):
"""排障结束后写入磁盘,不影响当前会话"""
# 写 L2:归档完整排障轨迹
self.session_db.insert(incident)
# 写 L3:如果流程可复用,触发 Skill 生成
if self._is_reusable(incident):
self.skill_generator.create_or_patch(incident)
# 写 L1:如果发现新的系统事实
if incident.get("new_fact"):
self._update_memory_md(incident["new_fact"])三、经典流程改造二:自更新系统(自进化闭环)
3.1 Hermes 五阶段闭环映射到运维场景
Hermes 的自进化闭环包含 感知→规划→执行→反思→沉淀 五个阶段。改造为运维系统的 故障自愈闭环:
┌──────────────────────────────────────────────────────────┐
│ 运维自进化闭环 (OPS Evolution Loop) │
├──────────────────────────────────────────────────────────┤
│ │
│ ① 感知 (Perceive) │
│ ├─ 接收告警 / 用户提交故障单 │
│ ├─ 提取故障特征向量(服务名、错误码、时间窗口、影响范围) │
│ └─ FTS5 检索历史相似故障 → 注入 L2 记忆 │
│ ↓ │
│ ② 规划 (Plan) │
│ ├─ 匹配 L3 排障 Skill(命中率 > 阈值则直接执行) │
│ ├─ 未命中则 LLM 生成排障计划(多跳图查路径 + 指标采集列表) │
│ └─ 计划审批(P0/P1 故障需人工确认,P2/P3 自动执行) │
│ ↓ │
│ ③ 执行 (Execute) │
│ ├─ 阶段3-5 自动化执行(图查→连通性→指标采集) │
│ ├─ 并行工具执行(借鉴 Hermes _PARALLEL_SAFE_TOOLS 分类) │
│ └─ 迭代预算控制(默认 90 次迭代上限,防止死循环) │
│ ↓ │
│ ④ 反思 (Reflect) │
│ ├─ 根因是否定位成功?(置信度评分) │
│ ├─ 修复方案是否有效?(回滚率监测) │
│ ├─ 排障效率评估(MTTR / 工具调用次数 / token 消耗) │
│ └─ 生成反思摘要 → 存入 L2 会话归档 │
│ ↓ │
│ ⑤ 沉淀 (Sediment) │
│ ├─ 触发条件:工具调用次数 > 5 且 根因定位成功 │
│ ├─ 自动生成 OPS_SKILL.md(含触发条件+排障步骤+回滚方案) │
│ ├─ 已有 Skill 的 Patch 更新(增量修复,不全量覆写) │
│ └─ 更新 L1 MEMORY.md(如发现新的系统事实/依赖关系) │
│ │
└──────────────────────────────────────────────────────────┘3.2 Skill 自动生成触发条件设计
Hermes 用"工具调用次数"作为触发 Skill 创建的代理指标。运维场景改造为复合触发条件:
python
class OpsSkillGenerator:
"""
运维排障技能自动生成器
借鉴 Hermes 的 "变异+选择+保留" 进化机制
"""
SKILL_CREATION_THRESHOLDS = {
"min_tool_calls": 5, # 最少 5 次工具调用
"min_duration_minutes": 3, # 排障至少持续 3 分钟
"min_confidence": 0.7, # 根因置信度 >= 70%
"max_mttr_reduction": 0.3, # 相比首次排障 MTTR 降低 30%+
}
def should_create_skill(self, incident: dict) -> bool:
"""判断是否应该从本次排障中沉淀 Skill"""
# 简单问答不触发(Hermes 设计哲学)
if incident["tool_calls"] < self.SKILL_CREATION_THRESHOLDS["min_tool_calls"]:
return False
# 根因必须定位成功
if incident["root_cause_confidence"] < self.SKILL_CREATION_THRESHOLDS["min_confidence"]:
return False
# 检查是否已有同类 Skill
existing = self.find_similar_skill(incident["fault_signature"])
if existing:
# 已有 Skill → Patch 更新(增量,不全量覆写)
self._patch_skill(existing, incident)
return False
else:
# 新故障模式 → 创建新 Skill
return True
def generate_skill_md(self, incident: dict) -> str:
"""生成 OPS_SKILL.md 文件"""
return f"""# OPS_SKILL: {incident['fault_type']}
## 触发条件
- 服务: {incident['service_name']}
- 告警特征: {incident['alert_signature']}
- 时间窗口: {incident['time_window']}
## 排障步骤
{self._format_steps(incident['troubleshooting_steps'])}
## 工具调用序列
{self._format_tool_calls(incident['tool_calls'])}
## 回滚方案
{incident.get('rollback_plan', 'N/A')}
## 元数据
- 创建时间: {incident['timestamp']}
- 平均 MTTR: {incident['mttr']}
- 成功率: {incident['success_rate']}
- 版本: v1.0
"""3.3 Patch 增量更新机制
Hermes 的 Skill 修复采用 Patch 方式而非全量覆写,这是其架构的一个精巧设计。运维场景实现:
python
class OpsSkillPatcher:
"""
Skill 增量更新器
借鉴 Hermes 的 Patch 机制:只修改有问题的部分,不破坏已有有效逻辑
"""
def patch_skill(self, skill_path: str, incident: dict):
"""
Patch 策略:
1. 排障步骤中某一步被验证无效 → 替换该步骤
2. 新增了更优的工具调用方式 → 追加为 Alternative 方案
3. 回滚方案更新 → 替换回滚部分
4. 元数据更新 → 更新成功率和 MTTR
"""
current_skill = self.read_skill(skill_path)
patches = []
# 检测无效步骤
for step in incident["failed_steps"]:
if step in current_skill:
patches.append({
"type": "replace_step",
"old": step,
"new": incident["effective_alternative"]
})
# 检测更优方案
if incident.get("better_approach"):
patches.append({
"type": "append_alternative",
"content": incident["better_approach"]
})
# 执行增量更新(不覆写整个文件)
for patch in patches:
self._apply_patch(skill_path, patch)
# 更新版本号和元数据
self._update_metadata(skill_path, incident)四、经典流程改造三:RL 轨迹学习与数据飞轮
4.1 Hermes 数据飞轮机制
Hermes 将每次任务执行的完整轨迹记录为 ShareGPT 格式,导出后配合 Atropos 框架进行 RL 训练。这是 Hermes 架构中 最容易被忽视但最有长期价值 的能力。
4.2 运维场景改造:排障决策轨迹优化
┌────────────────────────────────────────────────────────┐
│ 运维数据飞轮 (Ops Data Flywheel) │
├────────────────────────────────────────────────────────┤
│ │
│ 排障执行 │
│ ├─ 记录完整轨迹(意图→规则→图查→检测→采集→报告) │
│ ├─ 轨迹格式:ShareGPT 兼容的 JSONL │
│ └─ 标注:根因正确性 / MTTR / 人工反馈 │
│ ↓ │
│ 轨迹筛选 │
│ ├─ 过滤低质量轨迹(置信度 < 0.7 / 人工标记错误) │
│ ├─ 去重相似轨迹 │
│ └─ 压缩到指定 token 预算(借鉴 --max-tokens 参数) │
│ ↓ │
│ 训练数据生成 │
│ ├─ ShareGPT 格式导出 │
│ ├─ 正例:成功定位根因的轨迹 │
│ └─ 负例:定位失败但有价值的探索路径 │
│ ↓ │
│ RL 微调(Atropos 集成) │
│ ├─ TrajectoryTrainer 训练 │
│ ├─ 11 种工具调用解析器 │
│ └─ 输出:运维专属微调模型 │
│ ↓ │
│ 模型能力提升 │
│ ├─ 根因定位准确率 ↑ │
│ ├─ 平均工具调用次数 ↓ │
│ ├─ MTTR ↓ │
│ └─ 降低对通用商业模型的依赖 │
│ ↓ │
│ ↻ 回到排障执行(正向循环) │
│ │
└────────────────────────────────────────────────────────┘4.3 轨迹导出实现
python
class OpsTrajectoryExporter:
"""
运维排障轨迹导出器
借鉴 Hermes export --format sharegpt 机制
"""
def export_trajectories(
self,
start_date: str,
end_date: str,
min_confidence: float = 0.7,
max_tokens: int = 4096
) -> list[dict]:
"""
导出 ShareGPT 格式的训练数据
"""
trajectories = []
# 从 L2 会话归档中提取
sessions = self.session_db.query(
start_date=start_date,
end_date=end_date,
min_confidence=min_confidence
)
for session in sessions:
trajectory = {
"id": session.id,
"conversations": [
{
"from": "human",
"value": self._format_incident(session.incident)
},
{
"from": "gpt",
"value": self._format_trajectory(
session.steps,
max_tokens=max_tokens
)
}
],
"metadata": {
"fault_type": session.fault_type,
"mttr": session.mttr,
"confidence": session.confidence,
"tool_calls": session.tool_call_count
}
}
trajectories.append(trajectory)
return trajectories
def _format_trajectory(self, steps: list, max_tokens: int) -> str:
"""
轨迹压缩:借鉴 Hermes ContextCompressor 的分段压缩策略
- 保护头部(意图识别 + 规则匹配)
- 保护尾部(报告输出)
- 中间部分按重要性评分选择性保留
"""
if self._estimate_tokens(steps) <= max_tokens:
return self._serialize(steps)
# 分段压缩
head = steps[:2] # 意图识别 + 规则匹配(保护)
tail = steps[-1:] # 报告输出(保护)
middle = steps[2:-1] # 图查 + 检测 + 采集(可压缩)
# 用辅助模型生成中间部分的结构化摘要
middle_summary = self._summarize_middle(middle, max_tokens)
return self._serialize(head) + middle_summary + self._serialize(tail)五、经典流程改造四:上下文压缩引擎
5.1 Hermes ContextCompressor 设计
Hermes 的上下文压缩引擎采用可插拔架构,核心策略:
| 参数 | Hermes 默认值 | 运维场景建议 |
|---|---|---|
threshold_percent |
0.75 | 0.70(运维链路更长,更早触发) |
protect_first_n |
3 | 3(System Prompt + 告警 + 初始意图) |
protect_last_n |
6 | 4(最近排障步骤 + 当前工具输出) |
| 中间部分处理 | 辅助模型生成摘要 | 辅助模型 + 图查询结果的结构化压缩 |
5.2 运维场景适配
python
class OpsContextCompressor:
"""
运维上下文压缩器
解决多跳图查 + 指标采集导致的长上下文问题
"""
def __init__(self, threshold_percent=0.70):
self.threshold = threshold_percent
self.protect_head = 3 # System Prompt + 告警信息 + 意图识别结果
self.protect_tail = 4 # 最近 4 步操作
def should_compress(self, context_window: int, max_tokens: int) -> bool:
"""判断是否需要触发压缩"""
return (context_window / max_tokens) > self.threshold
def compress(self, messages: list) -> list:
"""
压缩策略:
1. 保护头部(意图 + 规则匹配结果)
2. 保护尾部(最近排障步骤)
3. 中间部分:
- AtlasGraph 查询结果 → 只保留关键路径 + 异常节点
- 指标采集结果 → 只保留异常指标 + 基线对比
- 工具调用输出 → 裁剪冗余字段
4. 用辅助模型生成结构化摘要
"""
head = messages[:self.protect_head]
tail = messages[-self.protect_tail:]
middle = messages[self.protect_head:-self.protect_tail]
if not middle:
return messages
# 图查询结果压缩
compressed_middle = []
for msg in middle:
if msg["role"] == "tool" and "graph_result" in msg:
# 只保留关键路径上的节点和异常节点
msg["content"] = self._compress_graph_result(msg["content"])
elif msg["role"] == "tool" and "metrics" in msg:
# 只保留异常指标和基线
msg["content"] = self._compress_metrics(msg["content"])
compressed_middle.append(msg)
# 生成中间部分的结构化摘要
summary = self._generate_summary(compressed_middle)
return head + [summary] + tail
def _compress_graph_result(self, graph_output: dict) -> dict:
"""压缩 AtlasGraph 查询结果"""
return {
"critical_path": graph_output.get("critical_path", []),
"anomaly_nodes": graph_output.get("anomaly_nodes", []),
"summary": f"图查询涉及 {len(graph_output.get('nodes', []))} 个节点,"
f"关键路径 {len(graph_output.get('critical_path', []))} 跳,"
f"发现 {len(graph_output.get('anomaly_nodes', []))} 个异常节点"
}
def _compress_metrics(self, metrics_output: dict) -> dict:
"""压缩指标采集结果"""
anomalies = [m for m in metrics_output.get("metrics", []) if m.get("is_anomaly")]
return {
"anomaly_metrics": anomalies,
"baseline": metrics_output.get("baseline", {}),
"summary": f"采集 {len(metrics_output.get('metrics', []))} 个指标,"
f"发现 {len(anomalies)} 个异常"
}六、经典流程改造五:子 Agent 委托机制
6.1 Hermes 子 Agent 设计
| 维度 | Hermes 设计 | 运维场景映射 |
|---|---|---|
| 无父历史 | 子 Agent 看不到父对话 | 子 Agent 只接收具体排障指令 |
| 独立终端 | 独立执行环境 | 独立 MCP 连接 + 监控数据源 |
| 工具限制 | DELEGATE_BLOCKED_TOOLS | 禁止递归委托、禁止修改生产配置 |
| 最大深度 | 1(默认) | 2(P0 故障允许更深探索) |
| 最大并发 | 3 | 5(多服务并行排查) |
6.2 运维多 Agent 编排
┌──────────────────┐
│ Master Ops Agent │ ← 运维主控 Agent
│ (意图识别+调度) │
└──────┬───────────┘
┌───────────────┼───────────────┐
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ DB 排查 Agent│ │网络排查 Agent│ │应用排查 Agent│
│ (慢查询/锁/ │ │ (丢包/延迟/ │ │ (CPU/内存/ │
│ 连接池) │ │ DNS/带宽) │ │ GC/线程) │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
▼ ▼ ▼
各自独立的 MCP 连接 + 监控数据源 + L2/L3 记忆
python
class OpsAgentOrchestrator:
"""
运维多 Agent 编排器
借鉴 Hermes 子 Agent 委托机制
"""
MAX_DEPTH = 2
MAX_CONCURRENT = 5
DELEGATE_BLOCKED_TOOLS = [
"modify_production_config", # 禁止修改生产配置
"restart_service", # 禁止重启服务
"delegate_agent", # 禁止递归委托
]
def dispatch_sub_agents(self, fault_signature: dict) -> list:
"""
根据故障特征分派子 Agent
"""
sub_agents = []
if fault_signature.get("db_related"):
sub_agents.append({
"agent_type": "db_diagnosis",
"prompt": self._build_db_prompt(fault_signature),
"blocked_tools": self.DELEGATE_BLOCKED_TOOLS,
"memory_layers": ["L2_db_incidents", "L3_db_skills"]
})
if fault_signature.get("network_related"):
sub_agents.append({
"agent_type": "network_diagnosis",
"prompt": self._build_network_prompt(fault_signature),
"blocked_tools": self.DELEGATE_BLOCKED_TOOLS,
"memory_layers": ["L2_network_incidents", "L3_network_skills"]
})
if fault_signature.get("app_related"):
sub_agents.append({
"agent_type": "app_diagnosis",
"prompt": self._build_app_prompt(fault_signature),
"blocked_tools": self.DELEGATE_BLOCKED_TOOLS,
"memory_layers": ["L2_app_incidents", "L3_app_skills"]
})
# 并行执行(ThreadPoolExecutor,借鉴 Hermes 设计)
results = self._parallel_execute(sub_agents)
# 汇总子 Agent 结果
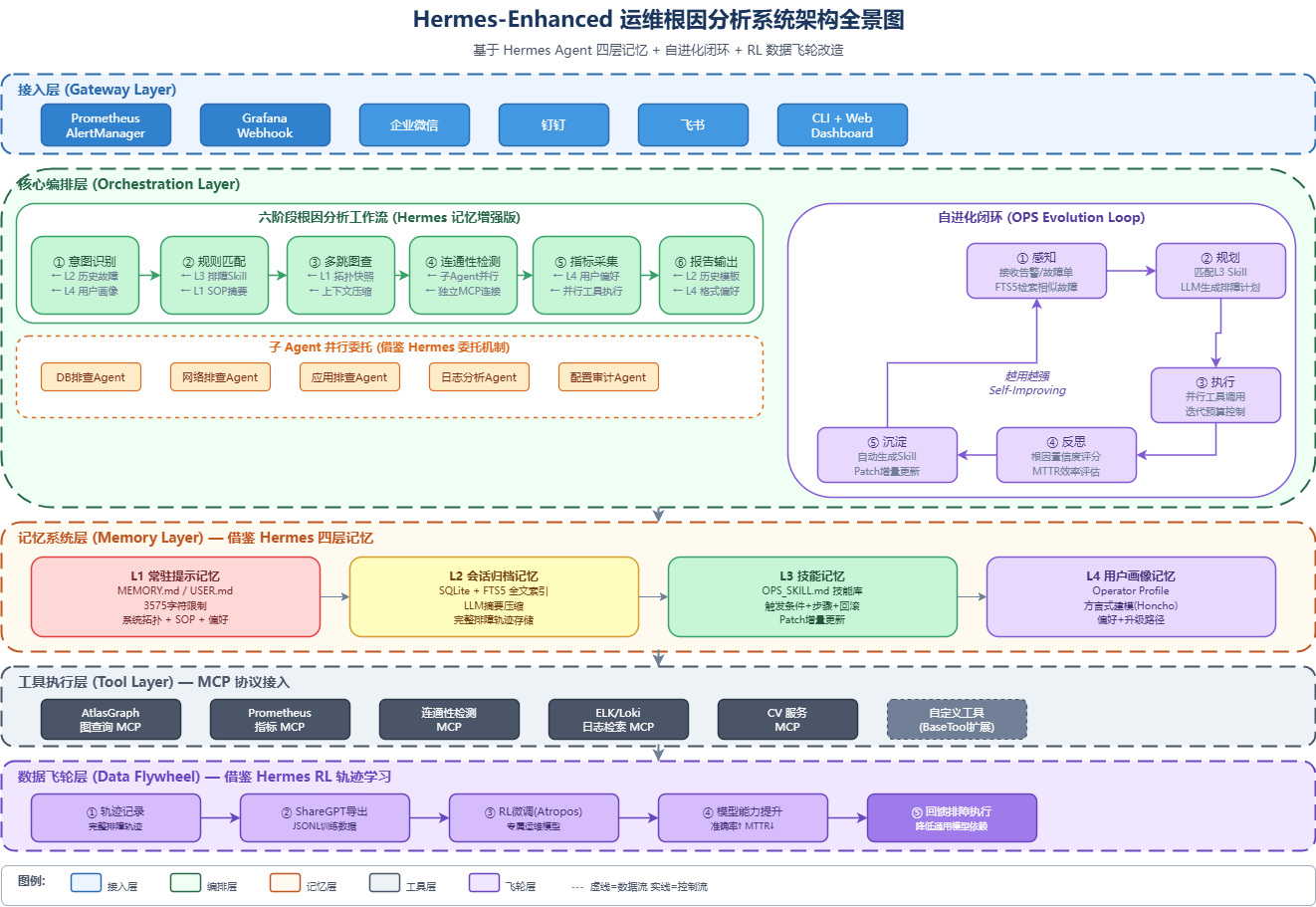
return self._merge_results(results)七、整体架构改造全景图
┌─────────────────────────────────────────────────────────────────────┐
│ 改造后的运维根因分析系统架构 │
│ (Hermes-Enhanced OPS Architecture) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 接入层 (Gateway Layer) │ │
│ │ ├─ 告警平台 Webhook (Prometheus/Grafana/Zabbix) │ │
│ │ ├─ 企业微信 / 钉钉 / 飞书 消息接入 │ │
│ │ └─ CLI + Web Dashboard │ │
│ └──────────────────────────┬──────────────────────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 核心编排层 (Orchestration Layer) │ │
│ │ ┌─────────────────────────────────────────────────────┐ │ │
│ │ │ 六阶段工作流 (Hermes 增强版) │ │ │
│ │ │ ① 意图识别 ← L2 历史故障 + L4 用户画像 │ │ │
│ │ │ ② 规则匹配 ← L3 排障 Skill 库 + L1 SOP 摘要 │ │ │
│ │ │ ③ 多跳图查 ← L1 拓扑快照 + 上下文压缩引擎 │ │ │
│ │ │ ④ 连通性检测 ← 子 Agent 并行委托 │ │ │
│ │ │ ⑤ 指标采集 ← L4 用户偏好 + 并行工具执行 │ │ │
│ │ │ ⑥ 报告输出 ← L2 历史报告模板 │ │ │
│ │ └─────────────────────────────────────────────────────┘ │ │
│ │ ┌─────────────────────────────────────────────────────┐ │ │
│ │ │ 自进化闭环 (Evolution Loop) │ │ │
│ │ │ 感知 → 规划 → 执行 → 反思 → 沉淀 │ │ │
│ │ │ 每次排障完成后自动触发 Skill 生成/Patch 更新 │ │ │
│ │ └─────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────┬──────────────────────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 记忆系统层 (Memory Layer) │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ L1 常驻 │ │ L2 会话 │ │ L3 技能 │ │ L4 画像 │ │ │
│ │ │ MEMORY.md │ │ SQLite │ │ SKILL.md │ │ Profile │ │ │
│ │ │ USER.md │ │ + FTS5 │ │ 技能库 │ │ 用户模型 │ │ │
│ │ │ 3575字符 │ │ + LLM摘要│ │ Patch更新 │ │ 方言建模 │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │ │
│ └──────────────────────────┬──────────────────────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 工具执行层 (Tool Layer) │ │
│ │ ├─ AtlasGraph 图查询 MCP │ │
│ │ ├─ Prometheus/Grafana 指标 MCP │ │
│ │ ├─ 连通性检测 MCP (ping/telnet/traceroute) │ │
│ │ ├─ 日志检索 MCP (ELK/Loki) │ │
│ │ └─ CV 服务 MCP (截图/图表识别) │ │
│ └──────────────────────────┬──────────────────────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 数据飞轮层 (Data Flywheel) │ │
│ │ ├─ 轨迹记录 → ShareGPT 格式导出 │ │
│ │ ├─ RL 微调 (Atropos) → 运维专属模型 │ │
│ │ └─ 模型能力提升 → 降低通用模型依赖 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────┘八、实施路线图建议
| 阶段 | 周期 | 改造内容 | 优先级 |
|---|---|---|---|
| Phase 1 | 2周 | L2 会话归档(SQLite + FTS5)+ L3 基础 Skill 库搭建 | P0 |
| Phase 2 | 2周 | 自进化闭环(感知→沉淀)核心流程 + Skill 自动生成 | P0 |
| Phase 3 | 1周 | 上下文压缩引擎接入六阶段工作流 | P1 |
| Phase 4 | 2周 | 子 Agent 并行委托 + L1/L4 记忆完善 | P1 |
| Phase 5 | 3周 | RL 轨迹导出 + 数据飞轮搭建 + 模型微调实验 | P2 |
九、关键设计决策总结
| 决策 | Hermes 原设计 | 运维场景调整 | 理由 |
|---|---|---|---|
| 记忆注入方式 | 冻结快照模式 | 保留 | 保持 KV Cache 有效性,降低推理成本 |
| Skill 触发条件 | 工具调用次数 | 复合条件(工具次数 + 置信度 + MTTR) | 运维场景需要更精准的触发 |
| 上下文压缩阈值 | 75% | 70% | 运维链路更长,更早触发 |
| 子 Agent 并发 | 3 | 5 | 微服务架构需要更多并行排查 |
| 记忆字符限制 | 3575 | 5000 | 运维拓扑信息量更大 |
| 模型要求 | 64K 上下文 | 128K(推荐) | 多跳图查 + 长链路排障需要更大窗口 |