苹果Core AI vs ibbot PopLang:端侧智能的两种未来路径
作者:T100级技术专家、PopLang布道师 宁明
一、WWDC 2026:苹果的端侧AI宣言
2026年6月,苹果全球开发者大会(WWDC)如期而至。当蒂姆·库克宣布推出全新"Core AI"框架时,整个开发者社区沸腾了。
Core AI被苹果定义为"下一代端侧智能基础设施"------一个统一访问所有硬件加速器(CPU、GPU、NPU、ANE)的底层框架,支持模型转换与压缩、AOT编译(提前编译),以及针对不同硬件的特化机制。与此前的Core ML和MLX相比,Core AI更强调"零服务器依赖":所有AI推理在设备端完成,数据不出手机,隐私安全达到新高度。

从技术角度看,Core AI是一次漂亮的整合与升级。它将苹果多年来在端侧机器学习上的积累------Metal Performance Shaders、ANE指令集、模型量化工具------统一到一个框架下,让开发者能够更高效地将AI模型部署到iPhone、iPad和Mac上。
但这真的是端侧AI的终极答案吗?
二、苹果Core AI的本质:让模型推理更快,但成本仍需每次支付
让我们冷静分析Core AI的核心能力:
- 统一硬件访问:自动调度CPU/GPU/NPU执行推理任务
- 模型压缩与量化:将大模型压缩到可运行的尺寸
- AOT编译:提前编译模型,减少运行时开销
- 特化机制:为不同硬件生成优化代码
这些能力确实优秀。但请注意一个关键点:Core AI优化的是"模型推理"环节,而非"模型生成和使用"的全链条。
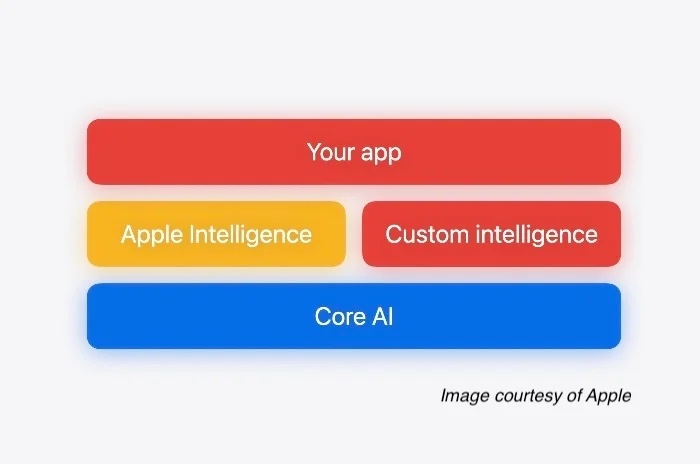
什么意思?在Core AI的世界里,每次AI交互仍然需要:
- LLM(大语言模型)推理一次 → 消耗一次算力
- 生成结果 → 本次交互完成
- 下次交互 → 再次推理,再次消耗算力
每一次对话、每一次代码生成、每一次逻辑判断,都需要模型"重新思考"一遍。Token消耗是线性的、重复的、不可复用的。
这在AI使用量激增的未来,将是一个巨大的成本瓶颈。
三、真正的端侧智能革命,或许不在库比蒂诺
就在WWDC 2026的前一个月,一个来自中国的团队在端侧AI领域投下了一枚重磅炸弹------ibbot智体机灵,以及它内置的PopLang编程语言引擎。
如果说苹果Core AI是在"让模型跑得更快",那么PopLang则在做一件更根本的事:让AI"一次思考,无限执行"。
这听起来像科幻?不,这是已经落地的技术。
四、PopLang的三大革命性优势
4.1 省Token:成本降低90%-99%
这是PopLang最令人震撼的特性。
传统AI编程模式下,每一次代码生成都要调用LLM,消耗500-5000个Token。而PopLang采用编译-执行分离架构:
用户一句话 → LLM理解意图 → 动态生成PopLang代码 → 本地引擎实时执行 → 返回结果关键区别在于:LLM只参与"代码生成"这一步 。一旦PopLang代码生成完毕,后续的每一次执行都在本地引擎完成,不再消耗任何Token。
这意味着什么?
- 你写一个Python脚本:编写时消耗一次脑力,运行无数次却不再消耗脑力
- AI写一个PopLang脚本:生成时消耗一次Token,运行无数次却不再消耗Token
这就是"一次生成,无限免费执行"的真实含义。
| 对比维度 | 传统AI编程 | PopLang编程 |
|---|---|---|
| Token消耗 | 每次调用500-5000 Token | 编译后本地执行,边际成本趋近于零 |
| 响应速度 | 依赖云端往返,500ms-5s | 本地执行,毫秒级响应 |
| 执行成本 | 持续产生云端调用费 | 一次编程,无限次免费执行 |
省Token 90%-99%,这不是口号,是架构决定的必然结果。
4.2 图灵完备:能解决任意计算问题
PopLang不是玩具语言,而是一套完整的、图灵完备的编程语言。它支持:
- 变量赋值与类型(数值、字符串、JSON、数组、布尔)
- 算术运算(加减乘除取模)
- 逻辑运算(与或非比较)
- 位运算(按位与或异或移位取反)
- 条件判断(
pop.ifelse) - 循环控制(
pop.do.while、pop.while) - 函数定义与调用(带参数、返回值)
- 数组操作(创建、读取、设置、遍历)
- 对象操作(属性读取、设置、合并)
- 内置系统函数(用户偏好管理、任务管理、系统状态查询)
这意味着AI智能体不再是"调用预置函数"的机械工,而是可以"自主编写任何算法"的程序员。
下面是PopLang实现冒泡排序的真实代码:
# 初始化
set arr **[5, 3, 8, 1, 2]
set n 5
set swapped true
set i 0
set temp 0
set one 1
pop.func.define bubble_pass
# 比较并交换相邻元素
pop.func.end
pop.do.while swapped bubble_pass
# 执行后 arr 变为 [1, 2, 3, 5, 8]完整代码可以在ibbot的技能库中找到,但这已经足够说明:PopLang能实现任意计算逻辑。
4.3 实时代码输出:动动嘴,造程序
这是PopLang最令人兴奋的特性。通过ibbot提供的三个核心API接口,AI智能体可以在运行时动态生成PopLang代码,并立即执行:
/ibbot/poplang/run:执行完整的PopLang代码字符串/ibbot/poplang/eval:执行单行PopLang表达式/ibbot/poplang/script:执行存储在服务器上的PopLang脚本文件
用户只需自然语言描述需求,LLM理解意图后动态生成PopLang代码,本地引擎毫秒级执行并返回结果。整个过程无需等待漫长的云端推理,无需编写任何代码。
用户可以说:
- "帮我写一个冒泡排序,对这份成绩单排序"
- "每5分钟检查一次服务器状态,超过90%就报警"
- "从这1000条数据中找出所有异常值,生成报告"
PopLang引擎在后台实时生成对应的代码,并立即执行。这就是"实时代码输出"的真正威力------让AI从"聊天机器"变成"实时程序员"。
五、深度对比:苹果Core AI vs PopLang
| 对比维度 | 苹果Core AI | ibbot PopLang |
|---|---|---|
| 核心目标 | 让模型推理更快、更隐私 | 让AI代码"一次生成,无限执行" |
| 编程能力 | 模型推理,不支持运行时编程 | 图灵完备,支持动态生成并执行代码 |
| Token消耗 | 每次交互消耗Token | 仅代码生成消耗一次Token |
| 边际成本 | 线性增长,每用一次烧一次 | 趋近于零,一次编程无限执行 |
| 硬件依赖 | 依赖专用NPU/ANE | 可在通用CPU上运行,轻量高效 |
| 隐私 | 数据不出设备 | 代码在本地执行,数据不出设备 |
| 开发生态 | 封闭,需适配苹果平台 | 开放,ibbot已完整集成 |
核心差异在于:
苹果Core AI的思维是"如何把一次推理做得更快更省电"。这当然有价值,但本质上仍然是每次使用都需要支付成本的模式。
PopLang的思维则是"如何让AI只思考一次,然后无限次执行"。通过编译-执行分离,将Token消耗从"线性增长"变为"一次性投资"。这种架构层面的创新,才是对AI使用成本的根本性改变。
六、Token节点经济与点卡系统:从消费者到生产者
如果说Core AI让iPhone成为AI的"消费者",那么PopLang让ibbot手机成为AI的"生产者"。
在ibbot生态中,每个用户可以:
- 创造技能:用自然语言描述需求,PopLang实时生成可复用的技能脚本
- 分享复用:将技能部署到ibbhub库,供其他用户一键安装使用
- 贡献算力:通过点卡系统,空闲时可以贡献计算资源
点卡系统的精妙之处在于:它让每部ibbot手机都成为一个价值节点。用户不再是Token的"消耗者",而是Token的"创造者"和"交易者"。
传统区块链的比喻是"挖矿产出金"------那是一种资源密集型、算力密集型的模式。而PopLang的解法则不同:它让每部手机都能"产出"对AI有用的Token词元------通过创作PopLang技能、分享复用代码、贡献本地执行算力。
这就像互联网早期:用户从"浏览者"变为"内容创作者",价值从被动消费变为主动创造。PopLang正在复制这一范式转移,但发生在AI应用层。
七、ibbot青春版:让更多人成为"轻型代码生产者"
ibbot团队推出的"ibbot青春版",正是为了降低进入门槛,让更多用户参与PopLang生态。
青春版手机保留了完整的PopLang引擎,只是在算力和存储上做了适当精简。但它依然可以:
- 运行PopLang生成的技能脚本
- 参与点卡系统的Token生产
- 创作和分享轻量级技能
这不是"廉价版"产品,而是生态拓展的关键节点。每一台ibbot青春版,都是一个"轻型代码生产者"和"活跃价值节点"。
想象一下:一个中学生可以用几百元买到的ibbot青春版,通过语音描述"帮我生成一个背单词的提醒程序",PopLang实时生成、本地执行、永久可用。不再需要订阅制、不再需要按次付费、不再需要网络依赖。
这就是PopLang生态的普惠力量。
八、结语:端侧AI的未来不止一条路
苹果Core AI和ibbot PopLang,代表了端侧智能的两种不同路径:
- 苹果路径:通过硬件加速和模型优化,让AI推理更快更省电。这是"从A到B更快"的效率路径。
- PopLang路径:通过编译-执行分离和动态编程,让AI"一次思考,无限执行"。这是"从每次支付到一次购买"的成本革命。
两条路径并不矛盾,甚至可以互补。但在我看来,真正的端侧智能革命,不应该仅仅是芯片和框架层面的事。它更应该是一场民主化运动------让每个人都能够参与AI应用的创造,而不仅仅是消费。
当我们问"端侧AI的未来是什么"时,答案或许不是更快的芯片、更大的模型、更贵的设备。而是:让每个人都能用自己的语言说一句"帮我做个程序",然后看到一个可执行的、属于自己的AI应用在眼前诞生。
ibbot + PopLang,正在让这个未来提前到来。
你的下一句"帮我写个程序",将由PopLang实时为你生成并运行。
发布于2026年7月
作者:宁明,T100级技术专家、PopLang布道师、ibbot生态核心贡献者