

A. 监督学习 :依赖带标注的样本数据 做训练,没有通过奖励机制迭代优化行为的设计,不符合题意。
B. 无监督学习 :是从无标注数据里挖掘内在规律,不存在奖励引导策略优化的环节。
C. 强化学习 :核心机制就是智能体(Agent)和环境交互,依靠奖励 / 惩罚机制 不断迭代优化行为策略,AlphaGo 正是用强化学习结合蒙特卡洛树搜索完成训练的,符合题目描述。
D. 迁移学习:是把旧任务学到的知识迁移到新任务来提升训练效率,不是依靠奖励机制优化行为的核心框架。

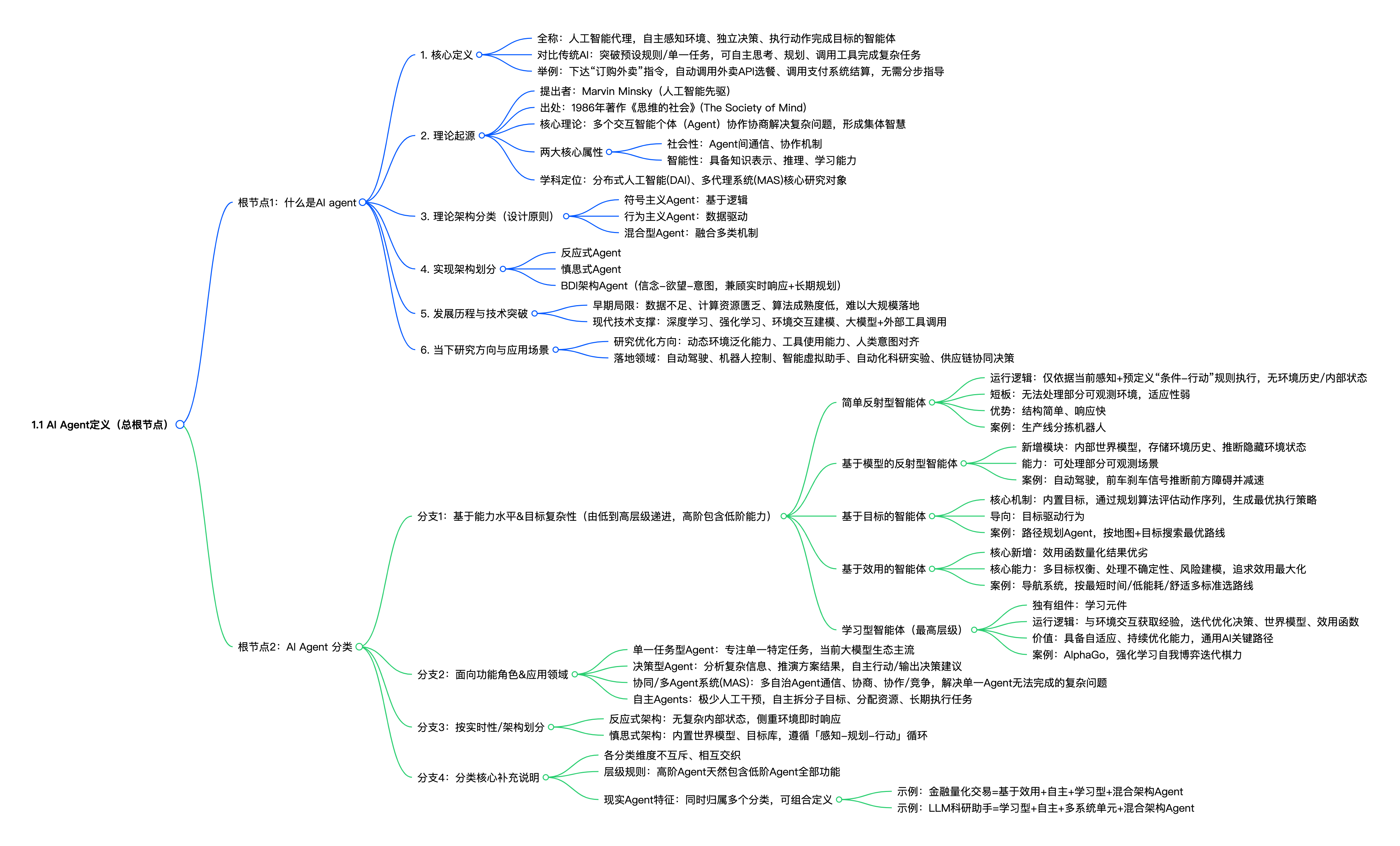
简单反射型智能体(A 选项)仅依靠当前感知和预设规则行动,没有内部状态与环境历史存储能力,无法处理部分可观测环境。
基于模型的反射型智能体(B 选项)内置了内部世界模型,可以保存过往的环境历史信息,以此推断环境中无法直接观测的隐藏状态,具备处理部分可观测场景的能力,和题目描述完全匹配。
基于目标的智能体(C 选项)是在模型反射的基础上增加了目标规划能力,核心特点是围绕目标做动作序列规划,不是以维护环境历史、解决部分可观测问题为核心特征。
基于效用的智能体(D 选项)在目标型的基础上引入效用函数做多目标权衡优化,侧重点是量化方案优劣、处理决策不确定性。
五层智能体是逐层叠加、功能包含的递进关系:高层智能体完整继承下层全部能力,再新增独有模块