HDFS 安装
HDFS 是后面很多组件的底座。YARN、MapReduce2、Tez、Hive、HBase、Spark、Hue 都会不同程度依赖它,所以我会把 HDFS 放在 Knox 之后、YARN 之前安装。
当前集群已经开启了 Kerberos,也已经接入了 Ranger 和 Knox。安装 HDFS 时会多一个动作:向导需要提交一次 KDC 管理员凭据,用来为 HDFS 生成和分发 Kerberos Principal。这个步骤不要跳过,否则组件包可能装完了,但服务启动和 Service Check 会卡住。
本次主机规划如下:
| 主机 | HDFS 角色 |
|---|---|
hadoop1.test.com |
NAMENODE、DATANODE、HDFS_CLIENT |
hadoop2.test.com |
SECONDARY_NAMENODE、DATANODE、HDFS_CLIENT |
hadoop3.test.com |
DATANODE、HDFS_CLIENT |
::: tip
这里继续使用 FQDN 主机名,不要在 HDFS、Kerberos、Knox 之间混用 IP、短主机名和完整域名。后面接 WebHDFS、Hive、Hue、Knox 拓扑时,统一主机名能少掉很多莫名其妙的认证问题。
:::
1. 选择 HDFS 服务
进入 服务与组件 ,点击 新增服务 。在服务列表中找到 HDFS,勾选它。

这一步只选择 HDFS。页面会显示 已选服务 1,说明本次向导只处理 HDFS,不会把 YARN、MapReduce2、Hive 等后续组件一并装进去。
HDFS 的依赖里已经有 ZooKeeper 和 Kerberos 环境,前面的准备文章已经完成,所以这里可以直接下一步。
2. 分配 Master 角色
Master 分配页里有两个 HDFS Master 角色:
| 组件 | 分配主机 |
|---|---|
NAMENODE |
hadoop1.test.com |
SECONDARY_NAMENODE |
hadoop2.test.com |
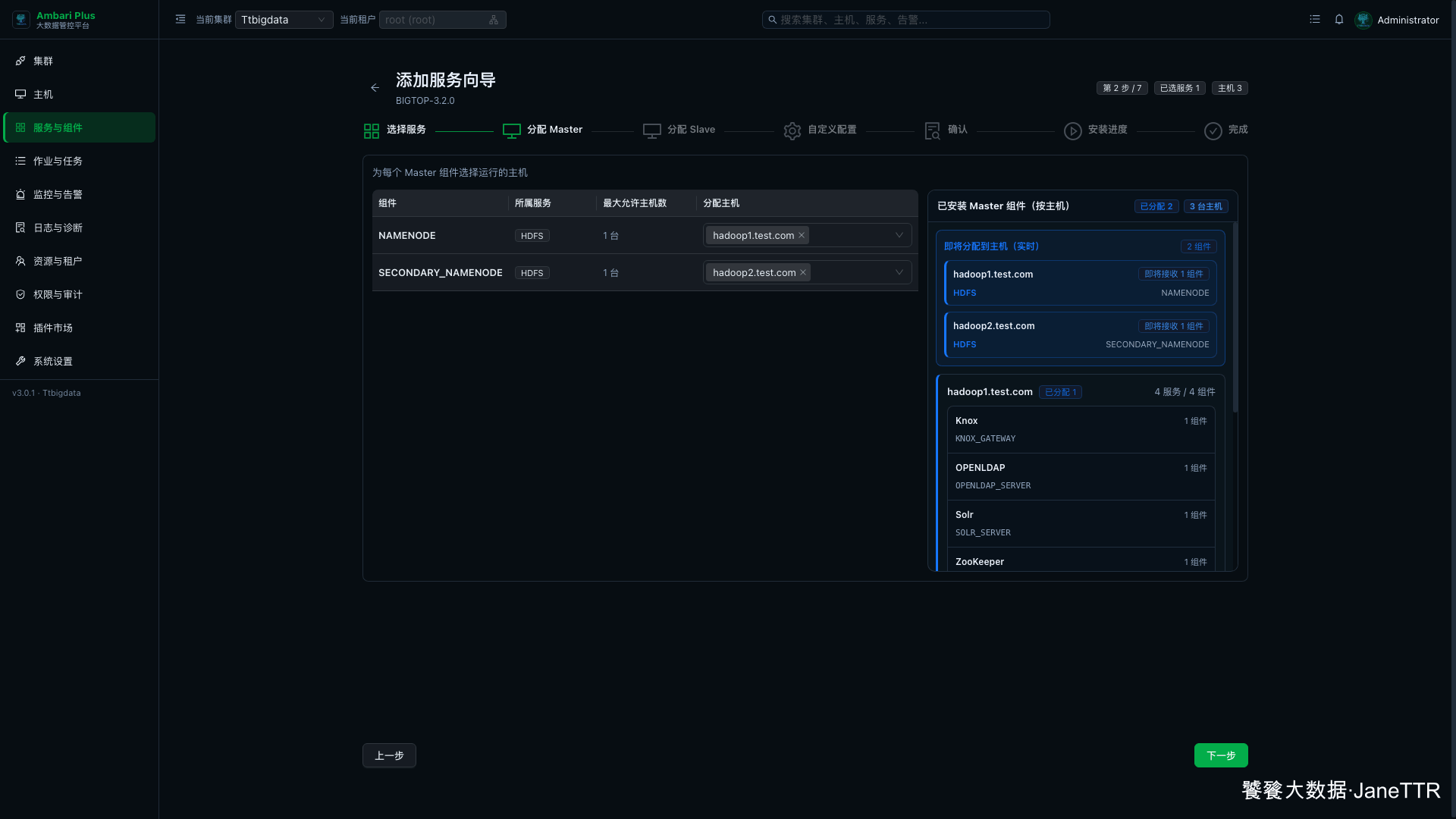
我这里保留默认分配。hadoop1.test.com 是平台入口和主要管理节点,把 NAMENODE 放在这里,后面看 HDFS 状态、接 Hive、接 Hue 时都比较直观。SECONDARY_NAMENODE 放到 hadoop2.test.com,可以把 checkpoint 角色和 NameNode 分开。
::: warning
SecondaryNameNode 不是 NameNode 的热备。它主要做 checkpoint,不等于 HDFS HA。生产环境要做 NameNode HA,需要单独规划 JournalNode、ZKFC 和两个 NameNode。
:::
3. 分配 DataNode 和 HDFS Client
Slave 与 Client 分配页里,HDFS 有两个要看的角色:
| 角色 | 本次分配 |
|---|---|
DATANODE |
hadoop1.test.com、hadoop2.test.com、hadoop3.test.com |
HDFS_CLIENT |
hadoop1.test.com、hadoop2.test.com、hadoop3.test.com |
演示环境三台机器都作为 DataNode,这样 HDFS 能看到 3 个存储节点。HDFS_CLIENT 也三台都装,后续在任意节点上执行 hdfs dfs 命令会方便一些。
如果是生产环境,DataNode 是否部署到管理节点,要结合磁盘、内存、角色隔离和运维规范决定;教程环境为了完整演示,三台都保留。
4. 补齐代理用户配置
进入自定义配置页后,页面会提示有 1 个必填配置项尚未填写。点击 待填写,只看缺失项。
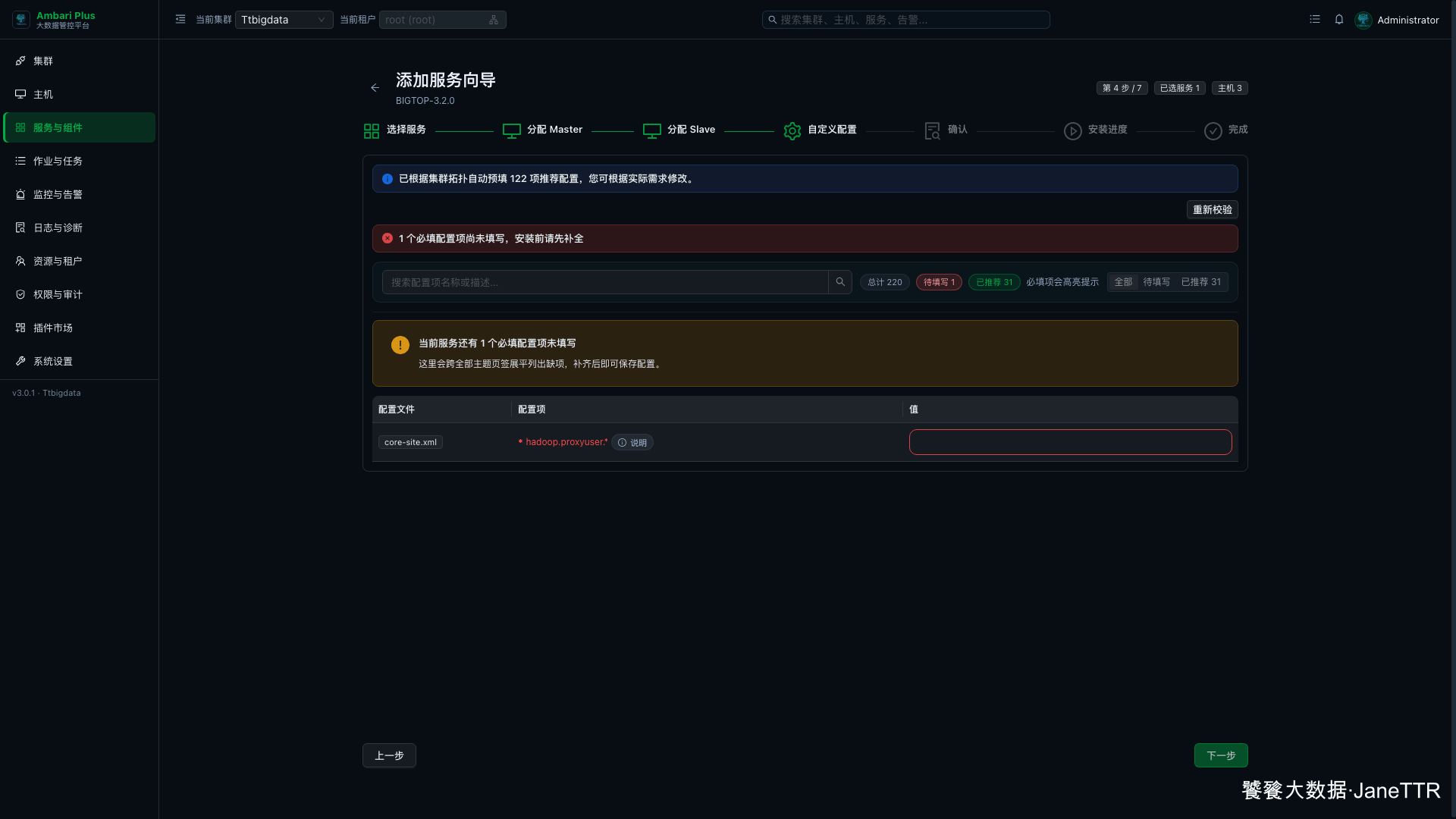
缺失项在 core-site.xml,配置名是 hadoop.proxyuser.*。这里填写:
| 配置项 | 示例值 |
|---|---|
hadoop.proxyuser.* |
* |
这个配置和后面的 Hive、Hue、Knox 代理访问有关。教程环境写 *,可以减少后面组件接入时的代理用户报错;生产环境建议按具体服务用户收紧,例如只给 hive、knox、hue 等代理用户开放指定主机和组。
5. 确认安装清单
配置补齐后进入确认页。这里不要直接点开始安装,我会先对照三项:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | HDFS |
| Master 分配 | NAMENODE -> hadoop1.test.com,SECONDARY_NAMENODE -> hadoop2.test.com |
| Slave / Client 分配 | DATANODE 和 HDFS_CLIENT 都在三台主机 |
| 配置校验 | 必填项已填写 |
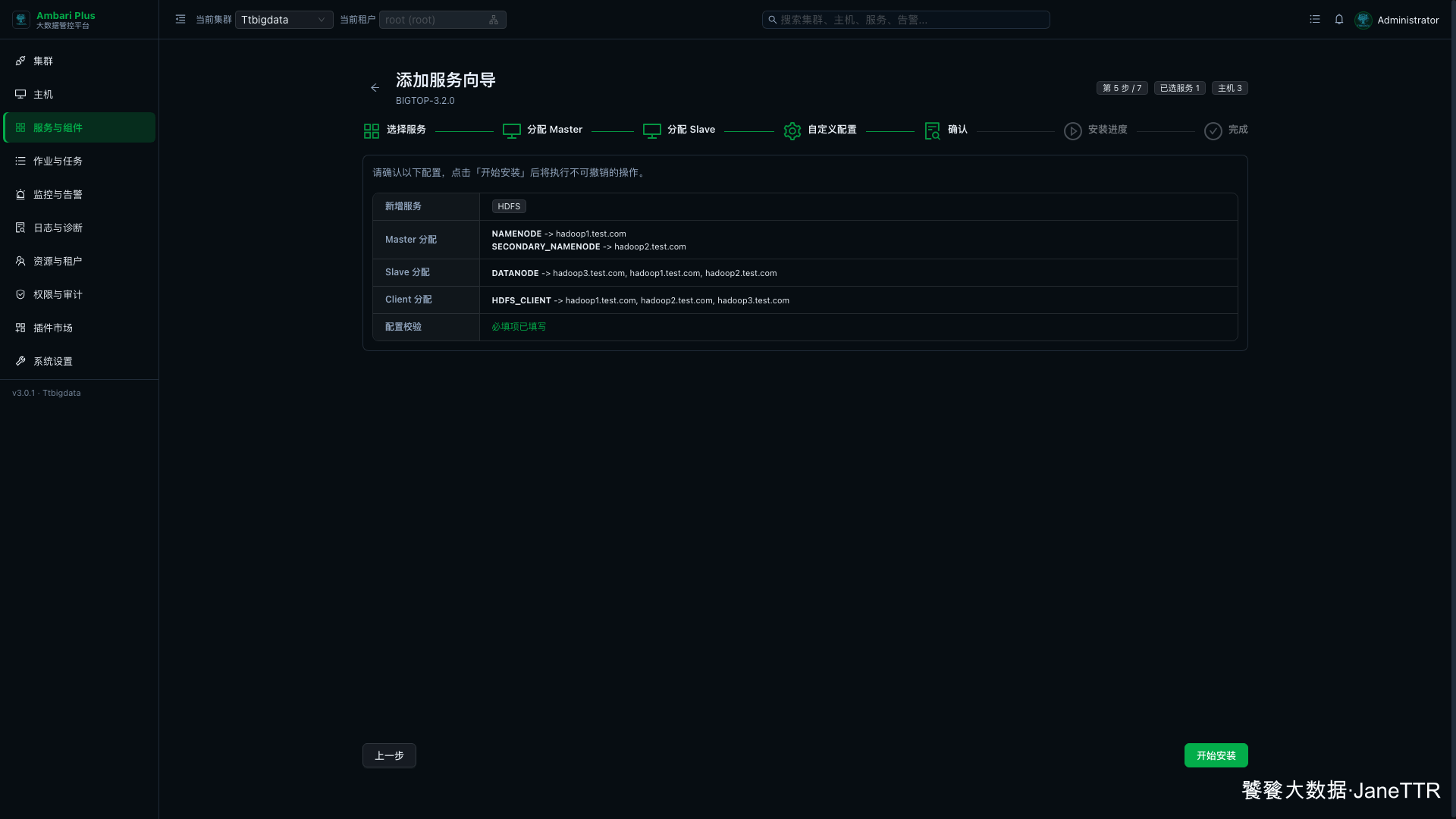
确认无误后点击 开始安装。
6. 提交 KDC 管理员凭据
因为集群已经启用了 Kerberos,HDFS 安装过程中会弹出 KDC 管理员凭据。这里使用前面 Kerberos 文章里创建的管理员:
| 配置项 | 示例值 |
|---|---|
| 管理员 Principal | admin/admin@TEST.COM |
| 管理员密码 | 填写实际 KDC 管理员密码 |
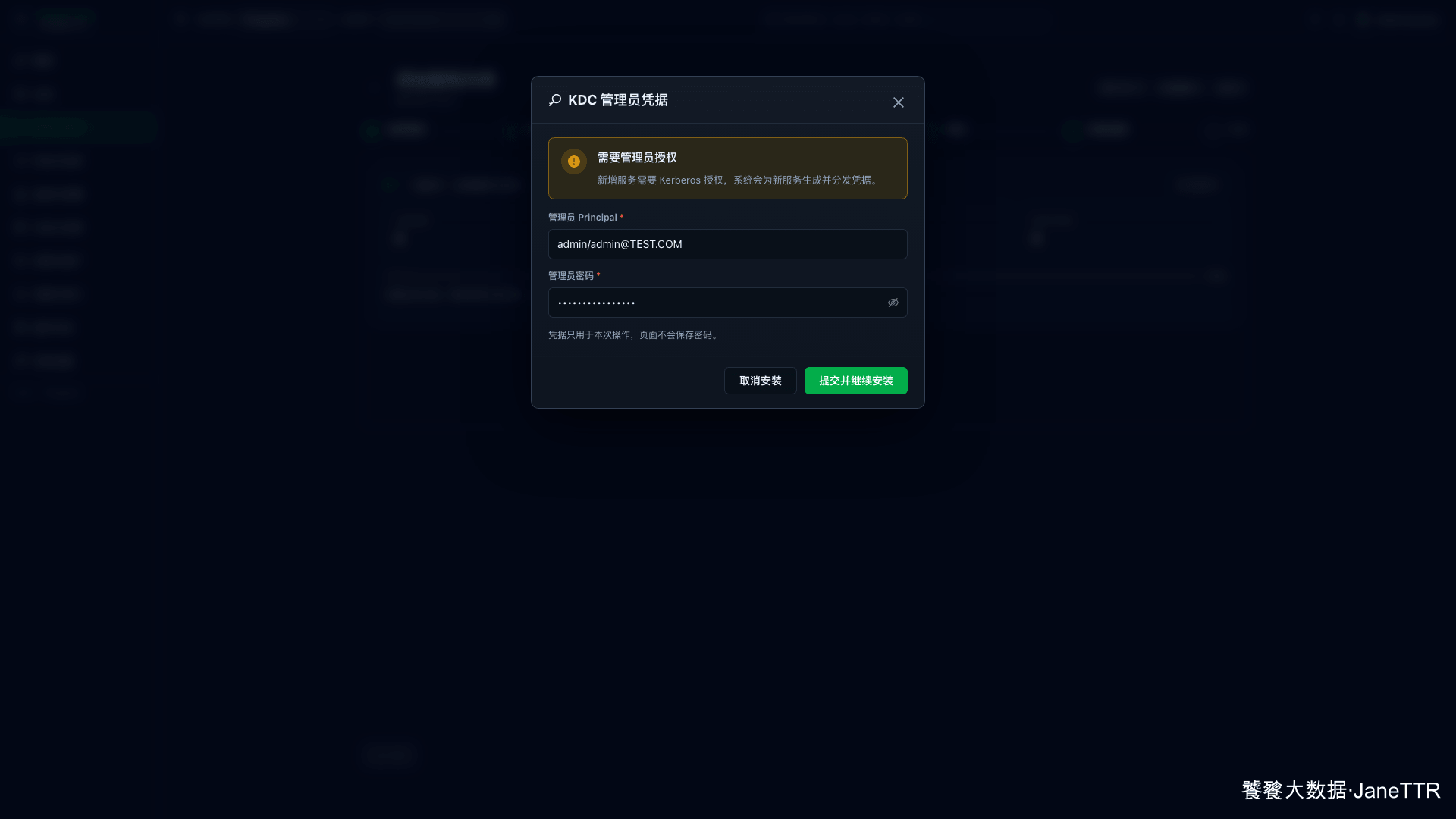
填写后点击 提交并继续安装。这个凭据只用于本次创建 HDFS Principal 和下发 keytab,页面不会保存管理员密码。
7. 等待安装与 Service Check
提交凭据后,向导会进入安装进度页。这里不要只看包安装是否完成,还要看后面的启动和 HDFS_SERVICE_CHECK。
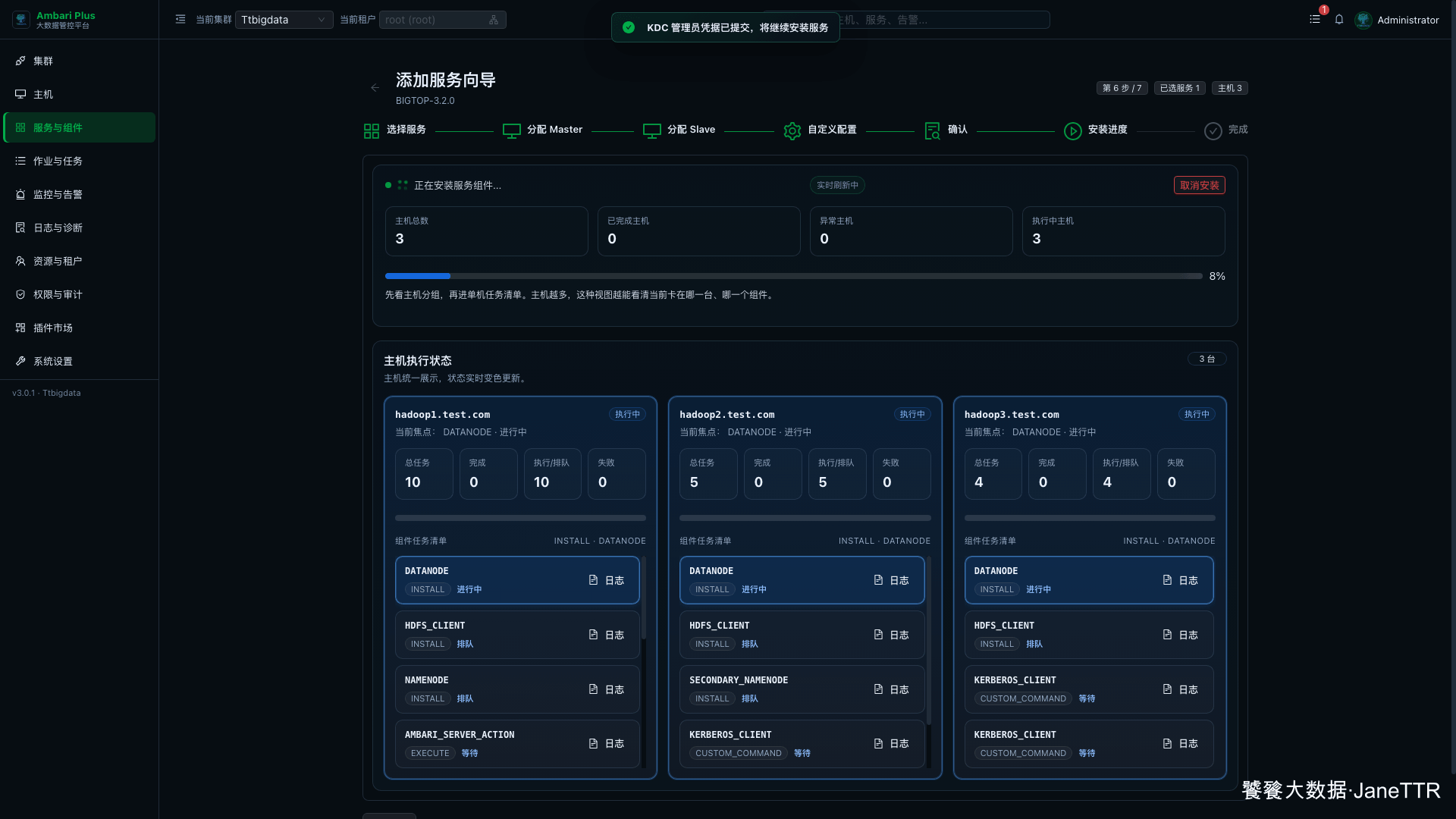
这个阶段我重点看:
| 检查项 | 期望结果 |
|---|---|
DATANODE |
三台主机都启动成功 |
NAMENODE |
hadoop1.test.com 启动成功 |
SECONDARY_NAMENODE |
hadoop2.test.com 启动成功 |
HDFS_SERVICE_CHECK |
最终执行成功 |
| 失败任务 | 0 |
如果卡在启动阶段,优先点开失败主机的日志看 Kerberos、目录权限、端口占用和磁盘目录问题。HDFS 的启动链路比较长,DataNode 成功不代表整套服务已经可用,Service Check 通过才算这一轮安装收口。
8. 完成安装向导
服务启动和检查完成后,向导进入最后一步,页面会显示 HDFS 安装完成。
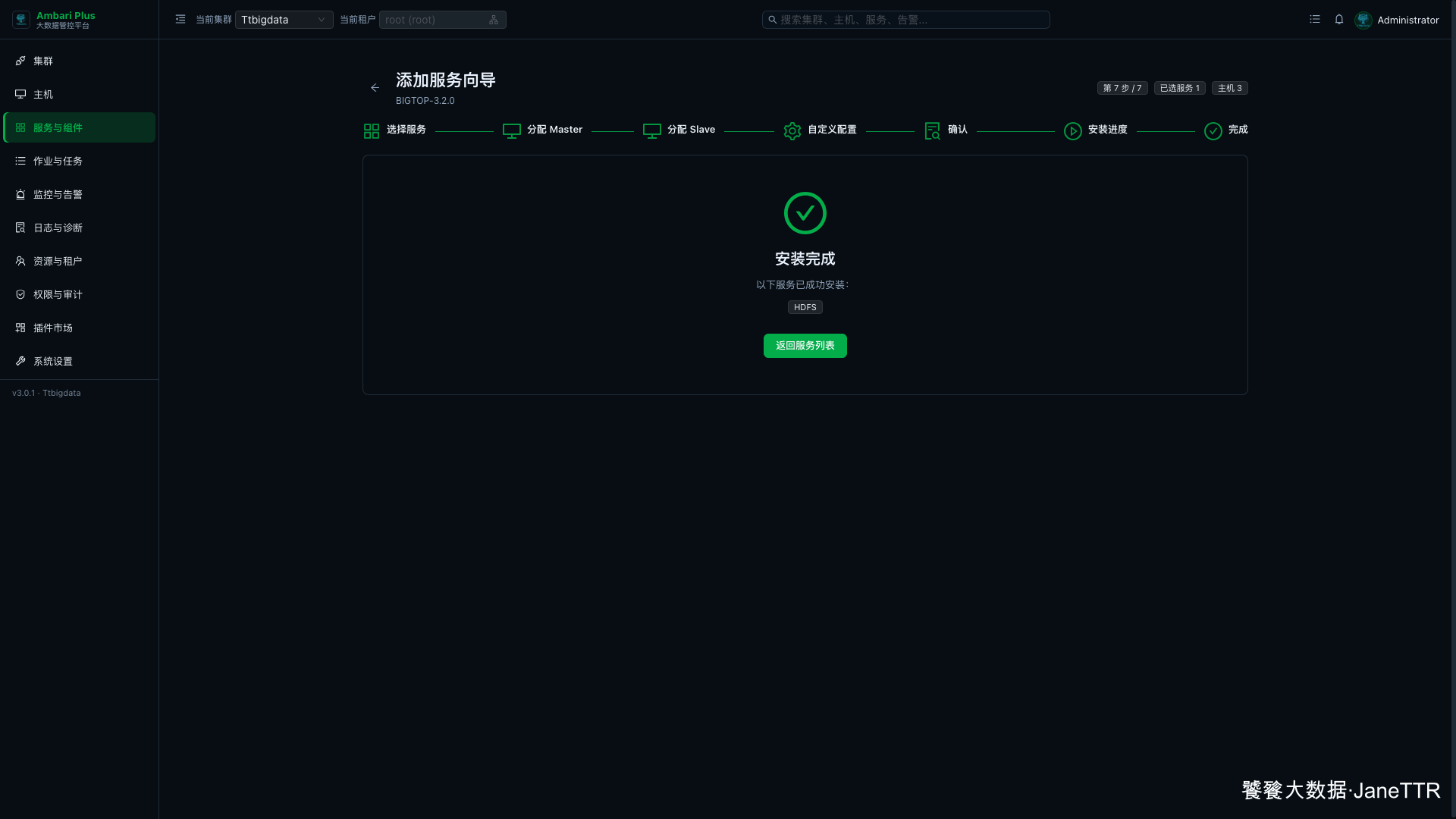
这里可以点击 返回服务列表。我一般会先回到服务总览看一次,确认 HDFS 已经被归到基础存储分类里,并且核心角色显示运行中。
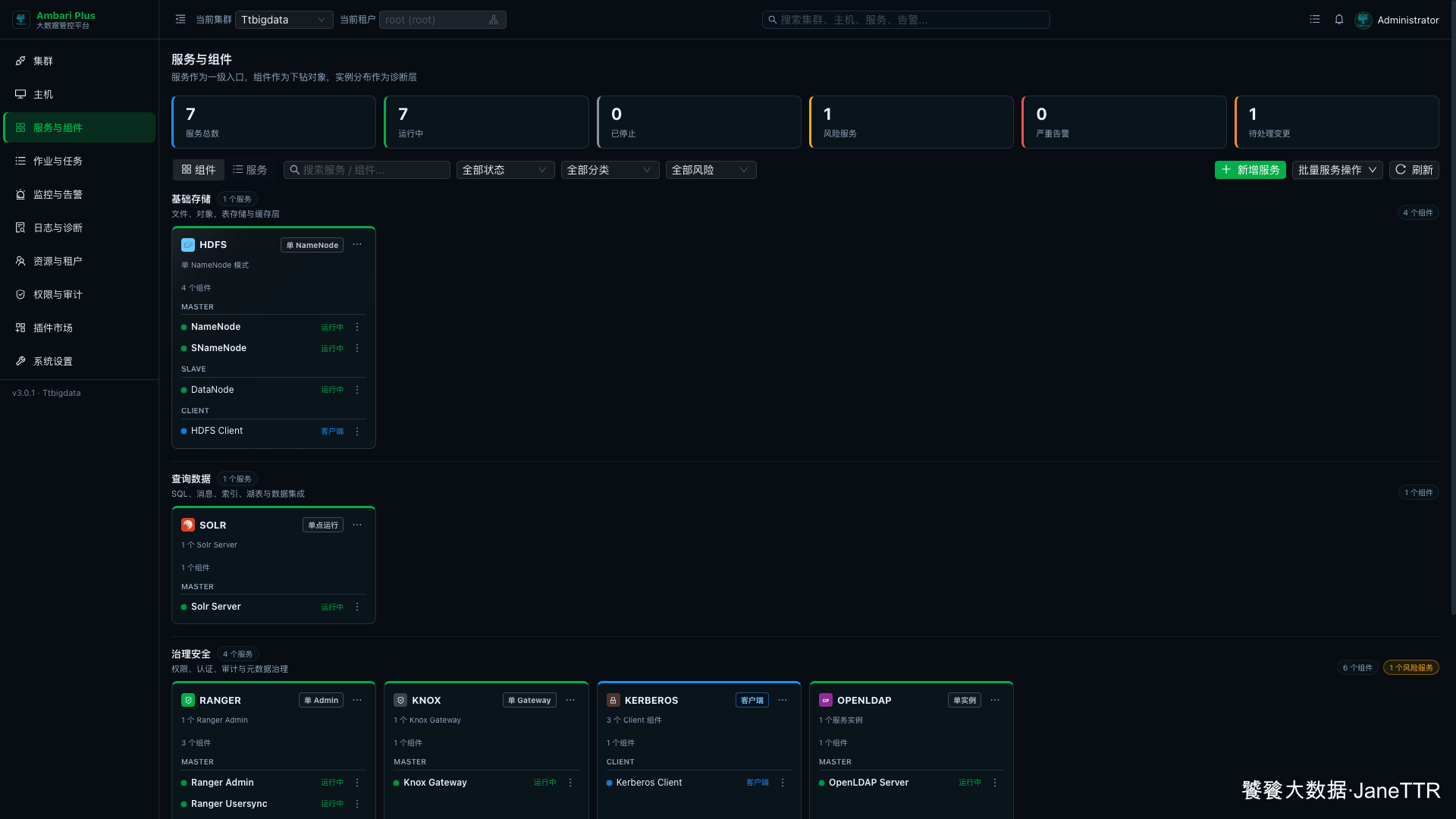
9. 回到 HDFS 服务页确认状态
最后进入 HDFS 服务详情页,状态应显示为 运行中。
这个页面我会看几项:
| 检查项 | 期望结果 |
|---|---|
| 服务状态 | HDFS 运行中 |
| 核心实例 | NameNode、SNameNode、DataNode 显示运行中 |
| 待刷新配置 | 0 |
| 失败请求 | 0 |
HDFS Client 是客户端组件,状态通常是已安装,不会像 DataNode 那样作为守护进程显示运行中。只要服务状态是运行中、核心实例正常、失败请求为 0,这一篇就可以收口。
HDFS 装好以后,下一步继续安装 YARN。YARN 会把资源调度层补上,后面的 MapReduce2、Tez、Hive、Spark 才有比较完整的运行基础。