1 引言
分布式系统早已渗透到现代软件基础设施的每一个角落------从金融交易数据库到社交网络的 feed 推送,从对象存储到实时流计算。然而,构建一个可靠的分布式系统远比单机系统复杂得多。核心挑战在于:多个节点通过网络协作,却面临着网络延迟、消息丢失、节点宕机乃至时钟偏差等一系列不确定性。在这样的环境下,如何保证数据的一致性?如何在部分节点故障时仍然提供服务?如何将海量数据合理地分布到成千上万台机器上,既均匀又便于扩容?
这些问题看似独立,实则相互交织。业界经过数十年的探索,沉淀出了几种经典算法,分别从不同维度给出了答案。
Paxos 和 Raft 属于"共识算法"家族,它们解决的是同一个根本问题:如何让一群节点对一个值(或一系列值)达成一致。Paxos 是理论上的里程碑,以优雅的数学证明定义了安全边界,却因晦涩难懂而被戏称为"分布式系统的希腊神话";Raft 则在 Paxos 的基础上进行了彻底的工程化重构,通过强领导者和日志连续性等设计,让共识变得可理解、可实现,成为 etcd、TiKV 等众多系统的基石。
而 CRUSH 解决的问题截然不同:如何在没有中心元数据服务器的情况下,将数据对象快速、均匀地映射到具体的存储设备上。它诞生于 Ceph 分布式存储系统,利用哈希和层次化故障域控制数据放置,使得扩容时数据迁移量极小,且完全避免了单点瓶颈。
这三者并非互相排斥,反而常常协同工作:Paxos/Raft 确保元数据或日志的一致性和可靠性,CRUSH 则负责数据的具体存放位置。理解它们的原理和设计哲学,不仅能帮助你更好地使用 TiDB、Ceph、etcd 等系统,更能让你在面对分布式系统的各种疑难杂症时,拥有从底层推理的能力。
本文将从问题出发,依次剖析 Paxos、Raft 和 CRUSH 的核心思想、工作机制以及各自的优劣,并最终将它们串联成一幅完整的分布式系统设计图谱。无论你是刚入门的开发者还是寻求系统性梳理的架构师,相信都能从中获得启发。
2 Paxos:共识的"理论基石"
2.1 问题定义:非拜占庭环境下的值选定
Paxos解决的场景是:在一个若干节点组成的异步网络中,允许节点宕机、消息丢失或延迟,但不考虑恶意节点(非拜占庭)。目标是让所有的非故障节点最终对某个提案(proposal)的值达成一致,且满足三个安全属性:
- 有效性(Validity):只有被提出的值才有可能被选中。
- 唯一性(Uniqueness):最终只能有一个值被选中。
- 可学习性(Learnability):一旦一个值被选中,所有节点都能获知这个值。
Paxos 将参与节点分为三类角色:提议者(Proposer)、接受者(Acceptor)和学习者(Learner)。一个节点可以同时担任多种角色。提议者负责发起提案,接受者负责投票和持久化已接受的值,学习者负责获取最终选定的值。
- Client:系统外部角色,请求发起者
- Proposer:接收client请求,向集群提出提议(Proposer)。并在冲突发送时,起到冲突调节的作用
- Acceptor(Vector):提议投票和接收者,只有在形成法定人数(一般为多数派时)提议才会最终被接受
- Learner:接收提议者,backup,备份,对集群一致性没什么影响。
2.2 核心流程:Basic Paxos
Basic Paxos 是最基础的版本,它通过两阶段协议(Prepare 和 Accept)来保证一致性。整个协议围绕一个全局唯一的、单调递增的提案编号(ballot number)展开。
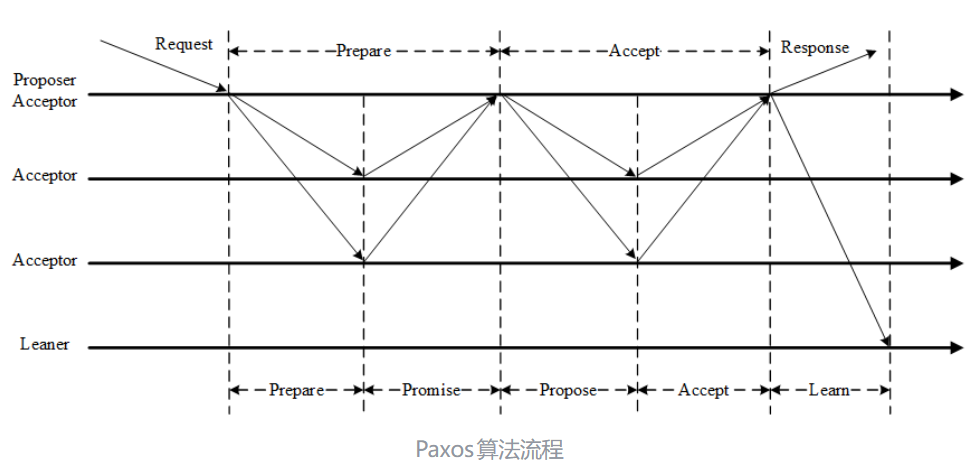
第一阶段:Prepare
- Proposer生成全局唯一且递增的Proposal ID (可使用时间戳加Server ID),向所有Acceptors发送Prepare请求,这里无需携带提案内容,只携带Proposal ID即可。
- 接受者收到Prepare(n)后,如果n大于它之前见过的任何提案编号,则做出"两个承诺,一个应答"(Promise):
两个承诺:
- 不再接受Proposal ID小于等于(注意:这里是<= )当前请求的Prepare请求。
- 不再接受Proposal ID小于(注意:这里是< )当前请求的Propose请求。
一个应答:
- 不违背以前作出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
第二阶段:Accept
- 提议者收集来自多数派(超过一半)接受者的
Promise回复。如果这些回复中包含任何已接受的值,提议者必须从中挑选编号最大的那个值作为本次提案的值;否则它可以自由选择自己的值。 - 提议者向所有接受者发送
Accept(n, value)请求,其中 n是第一阶段使用的编号,value是选定的值。 - 接受者收到
Accept(n, value)后,只要它还没有响应过编号更大的Prepare请求,就接受这个提案,将该值持久化,并通知所有学习者。
一旦多数派接受者接受了同一个值,该值就被视为已选定。学习者可以通过监听接受者的响应或通过独立的 Learn 阶段来获知最终结果。
2.3 关键难点:活锁与 Multi-Paxos
2.3.1 活锁问题
Basic Paxos 存在一个经典问题:两个提议者交替提高编号,导致对方始终无法完成 Accept 阶段。例如:
- 提议者 A 发出
Prepare(1),得到多数派承诺。 - 提议者 B 发出
Prepare(2),由于编号更大,多数派承诺给 B,同时拒绝 A 后续的Accept(1)。 - A 发现失败,再次发出
Prepare(3),又打断 B 的Accept(2)。 - 如此循环,永远无法选定一个值。
解决方法通常有两种:引入随机退避(类似于以太网碰撞检测),或者通过选出一个唯一的领导者(Leader)来避免冲突。后者正是 Multi-Paxos 的思路。
2.3.2 Muti-Paxos优化
在实际系统中,我们需要连续地就一系列值(如日志条目)达成共识,而不是单个值。Basic Paxos 每次都需要两轮 RTT,效率极低。Multi-Paxos 做了两项关键优化:
- 固定 Leader:在集群中选出一个长期稳定的提议者(Leader),其他提议者不再主动发起提案,而是将请求转发给 Leader。这样大部分情况下只需执行 Accept 阶段,Prepare 阶段只在 Leader 变更时才需要执行一次。
- 日志复制:Leader 为每个日志条目分配连续的序号,并使用相同的提案编号(或递增的编号)批量提交。接受者只需按序接受即可。
Multi-Paxos 本质上是一个"单次 Paxos + 日志流"的组合,它保证了日志的全局有序性和一致性。Google 的 Chubby 锁服务就是基于 Multi-Paxos 实现的。Muti-Paxos就是raft的前身。Raft 的作者 Diego Ongaro 在博士论文里直言不讳:Raft 的设计目标就是"一个能被理解和实现的 Multi-Paxos"
2.4 优缺点分析
优点:
- 理论完备性:Paxos 的安全性(Safety)和活性(Liveness)在异步网络模型下有严格的形式化证明,是分布式共识的理论标杆。
- 容错性强:只要多数派节点存活,系统就能继续运行;节点可以任意加入或离开(需配合成员变更协议)。
- 不依赖时钟:完全基于消息传递和编号,不假设任何同步时钟,适用于真正的异步网络。
缺点:
- 理解门槛极高:Lamport 最初的论文《The Part-Time Parliament》用古希腊议会隐喻,加上复杂的数学符号,使得大多数工程师难以直接掌握。后来他写的《Paxos Made Simple》虽然简化了语言,但仍需要仔细推敲。
- 工程实现困难:Basic Paxos 的活锁、Multi-Paxos 的 Leader 选举与日志空洞处理、成员变更等细节在论文中并未完整给出,导致每个实现都有不同的变体,且容易出错。
- 性能瓶颈:即使经过 Multi-Paxos 优化,每次写入仍需要至少一次 RTT(Leader 到多数派),且 Leader 成为单点瓶颈。相比之下,Raft 通过更清晰的日志结构降低了实现复杂度,但性能模型类似。
2.5 小结
整体流程:
- Client 发请求给 Proposer → Proposer 生成全局递增编号
n,发 Prepare(n) 给所有 Acceptor(第一轮 RPC,只带 n 不带 value) - Acceptor 若
n大于等于自己见过的最大编号,就承诺不再接受 < n 的提案,并把**自己已接受的最大编号 value(如有)**回给 Proposer - Proposer 收齐多数派 Promise 后,若有回包带旧 value 则选
accepted_n最大的那个,否则用 Client 给的 value,发 Accept(n, value) 第二轮 RPC - 多数派 Acceptor 接受后该值选定
- Learner 从 Acceptor 学到选定值,返回给 Client。
Paxos 是分布式共识领域的"牛顿定律"------它定义了正确性的边界,但直接用于工程却过于繁琐。它的价值不在于让你直接实现它,而在于提供了一套严谨的思维框架:提案编号、多数派、两阶段提交、承诺与接受。后来的 Raft 正是站在 Paxos 的肩膀上,通过简化角色和流程,让共识算法变得可理解、可实现。理解 Paxos,就等于理解了所有非拜占庭共识算法的 DNA。
3 Raft:工程化的共识算法
对于raft算法的内容也可以参看我的这篇博客:raft共识算法-CSDN博客
3.1 设计目标:从"正确"到"可理解"
Paxos 在理论上完美,但在实践中却让无数工程师折戟。Lamport 本人也曾感叹:"Paxos 的实现比理解更难。"Raft 的设计者总结了 Paxos 的主要痛点:
- 角色模糊:Paxos 中的 Proposer、Acceptor、Learner 可以重叠,导致状态机混乱。
- 日志空洞:Multi-Paxos 允许日志索引出现空洞,需要额外机制处理。
- Leader 选举不明确:Paxos 没有内建的 Leader 选举协议,工程上需要自行补充。
- 成员变更复杂:Paxos 原论文未讨论如何安全地添加或移除节点。
Raft 针对这些问题,提出了三项核心设计原则:
- 强领导者(Strong Leader):所有日志复制必须经过 Leader,简化了冲突解决。
- 领导者选举(Leader Election):使用随机超时和任期(term)机制,使选举过程清晰可控。
- 成员变更(Membership Change):引入联合共识(Joint Consensus)两阶段方法,保证变更期间的安全性。
一个关于raft一致性的算法浓缩性总结(不包括成员变换和日志压缩 ):
| 特性 | 解释 |
|---|---|
| 选举安全特性 | 对于一个给定的任期号,最多只会有一个领导人被选举出来(5.2 节) |
| 领导人只附加原则 | 领导人绝对不会删除或者覆盖自己的日志,只会增加(5.3 节) |
| 日志匹配原则 | 如果两个日志在某一相同索引位置日志条目的任期号相同,那么我们就认为这两个日志从头到该索引位置之间的内容完全一致(5.3 节) |
| 领导人完全特性 | 如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中(5.4 节) |
| 状态机安全特性 | 如果某一服务器已将给定索引位置的日志条目应用至其状态机中,则其他任何服务器在该索引位置不会应用不同的日志条目(5.4.3 节) |

3.2 角色与任期
Raft算法的角色:
| 角色 | 职责 |
|---|---|
| Leader | 处理所有客户端请求、管理日志复制、发送心跳维持权威 |
| Follower | 被动响应 Leader 和 Candidate 的请求,不主动发起任何操作 |
| Candidate | 用于选举 Leader 的临时角色,由 Follower 超时后转换而来 |
任期(Term)是 Raft 中的逻辑时钟,是一个单调递增的整数。每个任期最多只有一个 Leader。任期的作用有两个:
- 作为时间分界,区分不同 Leader 的领导时期;
- 作为日志条目的标记,防止旧 Leader 的日志干扰新 Leader 的决定。
3.3 Leader Election
Leader 选举是 Raft 最直观的创新之一。过程如下:
- 启动选举:Follower 在"选举超时"(通常 150~300ms 随机)内未收到 Leader 的心跳,则转换为 Candidate,并将自己的任期加 1。
- 发起投票 :Candidate 向所有节点发送
RequestVote RPC,附带自己的任期号和最后一条日志的索引与任期。 - 投票规则:每个节点在每个任期内只能投一票,且只能投给日志至少与自己一样新的 Candidate(比较最后一条日志的任期和索引)。
- 胜出条件:Candidate 获得超过半数节点的投票,则成为新 Leader。随后立即向所有节点发送心跳,确立权威。
随机超时的巧妙之处在于:多个 Candidate 同时发起选举的概率很低,即使发生,也会很快因为超时时间不同而收敛,避免了 Paxos 中的活锁问题。
3.4 Log Replication
一旦 Leader 当选,客户端的所有写入请求都必须经过它。流程如下:
- 追加日志:Leader 将客户端请求包装成日志条目(包含命令、任期号、索引),追加到自己的日志中。
- 并行复制 :Leader 向所有 Follower 发送
AppendEntries RPC,包含待复制的日志条目以及前一条日志的索引和任期(用于一致性检查)。 - 一致性检查 :Follower 收到
AppendEntries后,检查自己日志中对应索引位置的条目是否与 Leader 指定的前一条匹配。如果不匹配,则拒绝并返回自己的最后一条日志索引;Leader 会后退并重试,直到找到一致的匹配点。这一机制保证了日志的连续性和一致性。 - 提交条件 :当 Leader 确认某条日志已经被多数节点 成功复制后,将该条日志标记为"已提交"(commitIndex 更新),并在后续的心跳中将 commitIndex 广播给所有 Follower。Follower 据此将日志应用到状态机。
Raft 的日志复制具有两个重要性质:
- 日志匹配性质:如果两个节点在相同索引位置有相同任期的日志,那么这两个节点的日志在该索引之前完全相同。
- Leader 完整性:一旦某条日志被提交,所有未来的 Leader 都将包含该日志。
3.5 Safety 保证
Raft 的安全性是整个协议的"保险丝",主要体现在两个方面:
- 选举限制(Election Restriction) :Candidate 必须拥有至少与多数节点一样新的日志才有资格当选。具体来说,投票者在投票时会比较 Candidate 的最后一条日志:先比较任期,任期大的更新;任期相同则比较索引,索引大的更新。这一限制确保了新 Leader 一定包含了所有已提交的日志,从而避免了 Paxos 中"新 Leader 需要回放补全"的问题。
- 提交规则(Commitment Rule) :Leader 不能直接提交之前任期的日志,即使它们已经被复制到多数节点。原因在于:如果旧任期的日志尚未提交,新 Leader 可能会覆盖它。正确的做法是:只有当前任期的一条日志被复制到多数节点后,Leader 才能提交该日志,并顺带提交所有之前任期的日志 。这一规则堵住了 Multi-Paxos 中一个著名的安全漏洞(Chubby 曾因此遇到过问题)。
3.6 与 Paxos 的对比
| 维度 | Multi-Paxos(工程版) | Raft |
|---|---|---|
| 角色划分 | Proposer/Acceptor/Learner 可重叠 | Leader/Follower/Candidate 严格区分 |
| Leader 选举 | 隐含在 Prepare 阶段,无独立协议 | 独立、明确的选举过程 |
| 日志结构 | 允许空洞,需额外处理 | 连续无空洞,一致性检查强制填充 |
| 成员变更 | 无标准方案 | Joint Consensus 两阶段协议 |
| 实现难度 | 高(易遗漏细节) | 低(协议内建所有机制) |
| 安全性证明 | 分散在多篇论文中 | 集中、清晰,论文中给出完整证明 |
3.7 实际应用
Raft 已成为现代分布式系统的首选共识引擎:
- etcd:CoreOS 开发的分布式键值存储,Kubernetes 的核心组件,使用 Raft 保证集群状态一致性。
- TiKV:TiDB 的分布式 KV 层,使用 Raft 进行数据复制和故障恢复。
- Consul:HashiCorp 的服务发现与配置管理工具,底层使用 Raft。
- MongoDB:从 3.2 版本开始,副本集协议基于 Raft 重新设计。
- Apache Kafka:KRaft 模式(去除 ZooKeeper)使用 Raft 进行元数据管理。
4 CRUSH:可控的、可扩展的数据分布算法
如果说 Paxos 和 Raft 解决的是"多个节点对一个值达成一致",那么 CRUSH 解决的是另一个完全不同的问题------在没有任何中心元数据服务器的情况下,如何把一个对象确定性地映射到具体存储设备上,同时满足故障域隔离、权重均衡和最小化扩容迁移。它是 Sage Weil 在 2004 年那篇同名论文里提出的,也是 Ceph 之所以能"去中心化"的核心发动机。
需要先厘清一个容易混的点:CRUSH 不解决共识 。Ceph 集群里 Monitor 节点之间用 Paxos 保证 OSDMap(集群拓扑)的一致性,而 CRUSH 则利用这份 OSDMap做数据放置计算 ------ 前者管"元数据一致",后者管"数据放哪",两者互补。
4.1 解决什么问题
大部分存储系统将数据写入到后端存储设备之后,数据很少会在设备之间再次移动。这就存在一个潜在问题:即使一个数据分布已经趋于完美均衡的系统,随着时间的推移,新的空闲设备不断加人,老的故障设备不断退出,数据也会重新变得不均衡,这种情况在大型分布式存储系统中尤为常见。
一种可行的解决方案是将数据以足够小的粒度打散,然后完全随机地分布在所有存储设备之间,这样,从概率上而言,如果系统运行的时间足够长,所有设备的空间利用率将会趋于均衡。当新设备加人后,数据会随机地从不同的老设备迁移过来;同样,当老设备因为故障退出后,其原有数据会随机迁出至其他正常设备。这样整个系统将一直处于动态平衡过程之中,从而能够适应任何类型的负载和拓扑结构变化。进一步的,因为任何数据(可以是文件、块设备等)都被打散成为多个碎片然后写人不同的底层存储设备,从而使得在大型分布式存储系统中获得尽可能高的I/O并发和汇聚带宽成为可能。
一般而言,使用哈希函数可以达到上述目的,但是实际应用中还需要解决两个问题:一是如果系统中存储设备数量发生变化,如何最小化数据迁移量从而使得系统尽快恢复平衡;二是在大型(PB级及以上)分布式存储系统中,数据一般包含多个备份,如何合理分布这些备份从而尽可能地使得数据具有较高的可靠性。因此,需要对普通哈希函数加以扩展,使之能够解决上述问题, Ceph 称为 CRUSH (Controlled Replication Under Scalable Hashing)
传统的分布式存储做数据定位,一般有两条老路:
- 查表法:中心节点维护对象 -> 设备的映射表。问题是中心节点成为瓶颈,且表本身需要同步和容灾
- 一致性hash:对象hash到环上,环上找设备。均匀性OK,但故障域感知弱(没法保证三副本在不同的机架)、权重调整时扰动大、扩容迁移量不算最优
CRUSH算法的设计目标就是在这几条上同时突破
- 去中心化:客户端拿OSDMap+CRUSH Rule本地算,不需要问任何人
- 故障域感知:副本强制打散到不同的host/rack/datacenter
- 权重感知:大容量盘多存,小容量盘少存,异构混部
- 扩容迁移量最小:增删OSD时只迁该OSD相关的PG,理论比例1/W(W为总权重)
4.2 两个中间层
CRUSH的定位不是"对象直接哈希到盘",而是两层映射
第一层:Objetc -> PG(Placement Group)
PG_ID = Hash(Object_ID) % pg_num
PG 是"归置组",逻辑上的数据分片单位。一个 PG 包含一批对象,所有对象同进同出一个 PG。pg_num是存储池级别配置的,扩容时可以调大(PG split)。
第二层:PG -> OSD
这就是 CRUSH 算法的本体:
输入
- PG_ID
- 集群拓扑(OSDMap)
- 放置规则
输出
- 一个 OSD 列表(副本数由 Rule 定,三副本就出 3 个)。
相同 PG_ID + 相同 OSDMap + 相同 Rule → 输出永远相同,所以客户端可以本地算,不需要查中心。
**为什么中间要垫一层 PG?**如果对象直接映射到 OSD,每个对象都要在 OSDMap 上跑一次 CRUSH,元数据(每个对象的映射结果)虽可算但恢复时粒度太细;PG 把"几百个对象"捆成一捆管理,恢复、peering、元数据开销都降一个量级。这是 Ceph 工程上的关键设计
4.3 Cluster Map:层次化故障域

OSDMap 在 CRUSH 眼里是一棵带权决策树,叶子是 OSD,中间节点叫 Bucket(host / rack / row / datacenter / root)
root default
├── rack rack1
│ ├── host node1
│ │ ├── osd.1 (weight 1.0)
│ │ └── osd.2 (weight 1.0)
│ └── host node2
│ ├── osd.3 (weight 1.0)
│ └── osd.4 (weight 1.0)
└── rack rack2
├── host node3
│ ├── osd.5 (weight 1.0)
│ └── osd.6 (weight 1.0)
└── host node4
├── osd.7 (weight 1.0)
└── osd.8 (weight 1.0)每个 OSD 有权重(正比于容量,4TB 盘 weight≈4,8TB 盘 weight≈8),每个 Bucket 的权重是其子节点权重之和。CRUSH 按权重比例分配数据量,所以大盘自然多扛。
4.4 Placement Rule:放置策略引擎
光有树不够,还得告诉 CRUSH"副本怎么选"。Rule 是伪代码风格的步骤序列:
rule replicated_rule {
ruleset 0
type replicated
min_size 1
max_size 10
step take default # 从 root default 开始
step chooseleaf firstn 0 type rack # 先选不同 rack
step chooseleaf firstn 0 type host # 再在每个 rack 下选不同 host 的 OSD
step emit
}chooseleaf firstn 0 type host的意思是:选 N 个 OSD,且每个 OSD 落在不同 host 上(N=0 表示"按池的副本数来")。CRUSH 会递归地在树里往下钻------先在 rack 层挑出 3 个不同 rack,再在每个 rack 下挑 host,最后落到 OSD。这样"三副本不同机架"这种运维约束直接写进 Rule,不用应用层操心。
4.5 Straw2:CRUSH的抽签引擎
Rule 定了"去哪层选",但具体"从一堆 OSD 里挑谁"靠的是 Straw2 算法------目前 Ceph 的默认 Bucket 算法。
名字来自 "draw straws"(抽稻草比长短)。每个候选 OSD 独立抽一根"签",签最长者胜出
几个关键性质:
- 独立抽签:每个OSD的draw只跟自己的额item.id、weight和输入有关,不依赖其他OSD的相对排序。这是Straw2相比老版的Straw最大的改进 ------ 老版Straw改一个OSD的权重可能让其他OSD之间的相对签长变换,导致无关的PG也迁移;Straw2修掉了这个坑
- 权重正比:draw ∝ weight,所以 8TB 盘(weight≈8)赢的概率是 4TB 盘(weight≈4)的 2 倍,异构混部自然均衡。
- 多副本:副本序号
r不同,同一 PG 在多副本场景下会在同一 bucket 里抽多次(每次排除已选),保证副本打散。
4.6 扩容/故障时的迁移量:CRUSH 的杀手锏
这是 CRUSH 相比一致性哈希最值得吹的一点。
- 加一个 OSD :Straw2 独立抽签 → 只有"抽到新 OSD 赢"的那些 PG 才会迁过来,其他 PG 完全不动 。理论迁移量占集群比例 ≈
1 / W。 - 删/故障一个 OSD :该 OSD 上的 PG 重新抽签(其余 OSD 的抽签过程不受影响,原来赢的还是赢),迁到剩下活着的 OSD 上。同样比例
1 / W。 - 调权重:Straw2 保证只迁与该 OSD 相关的 PG,不触发无关 OSD 间的"互相挤"。
对比一致性哈希:加一个节点理论上也要迁 1/N的数据,但一致性哈希没法做故障域约束("三副本不同 rack"你得额外写逻辑),也没法做权重异构(虚拟节点能模拟但粗糙)。CRUSH 把这三件事一次性解决。
4.7 与 Paxos / Raft 的关系
正如上面所说,CRUSH算法不解决共识问题,但是在ceph中它们是搭档
- Monitor 集群 用 Paxos(较新版本也可用更轻的量级协议)维护
OSDMap的一致性------这是"共识"那档的事 - OSD 节点之间用 Primary-Backup + PG log 做副本复制(Ceph 没用 Raft,是自己的一套)
- CRUSH 利用
OSDMap算 PG→OSD 的放置,完全本地计算,无网络开销
所以一个完整 Ceph 写请求的路径是:Client → 算 CRUSH 找到 Primary OSD → Primary 写副本 → 多数 OSD ack → 返回。这里面"算位置"是 CRUSH(无RPC),"保一致"是 PG log + 监控(有 RPC),分工清楚。
4.8 小结
CRUSH 的聪明之处在于把"数据放置"这个本来要查表/要中心路由的事,变成了一个纯函数 :f(pgid, osdmap, rule) → [osd_list]。靠层次化 Cluster Map 表达故障域,靠 Straw2 独立抽签做到权重均衡+迁移最优,靠 Rule 把运维约束(不同 rack / 不同 DC)编进算法。它不解决一致性,但让"一致性协议管元数据 + CRUSH 管数据"这套架构成为可能------这也是为什么 Ceph 能做到千节点级无中心路由还能自愈。
5 三种算法的对比总结
| 维度 | Paxos | Raft | CRUSH |
|---|---|---|---|
| 解决的问题 | 共识(值选定) | 共识(日志复制) | 数据分布(放置) |
| 核心机制 | 两阶段提交 + 编号 | Leader + 心跳 + 日志复制 | 哈希 + 权重 + 故障域 |
| 是否依赖 Leader | 可选(Multi-Paxos 需要) | 强制 | 不需要 |
| 理解难度 | 极高 | 中等 | 中等 |
| 工程落地 | 少(Google Chubby, ZK 用 ZAB) | 多(etcd, TiKV, Consul) | Ceph 独有 |
| 动态变化 | 需单独处理 reconfiguration | Joint Consensus | 权重调整即自动重分布 |
| 性能瓶颈 | 消息数量 | Leader 单点(可通过批处理缓解) | 纯计算,无网络开销 |
- Paxos 和 Raft 都属于"复制状态机"范式,保证副本之间操作顺序一致。
- CRUSH 则属于"去中心化数据路由",不涉及副本间的一致性问题(副本一致性由其他协议如 Raft 或 Primary-Backup 保证)。
- 三者组合起来构成完整存储系统:Paxos/Raft 管元数据和日志,CRUSH 管数据放置。