今天第六次导师面。
简历完全被问穿,而且八股都不会。道心快碎了,但是又有种知耻而后勇的感觉。
梯度消失与梯度爆炸
一、先说一句人话(面试先定调)
梯度消失 :反向传播时,梯度逐层越传越小 ,靠近输入层的参数几乎不更新,模型学不动。
梯度爆炸 :反向传播时,梯度逐层越传越大,参数更新剧烈,模型直接崩掉。
本质 :两者都是深层神经网络在反向传播时,梯度连乘效应导致的不稳定问题。
二、用一个简单的链式例子说明
假设网络只有 3 层,损失函数对第 1 层参数的梯度为:
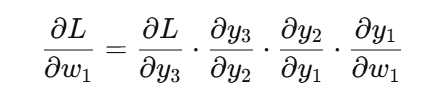
-
如果每一项(如激活函数的导数)都 < 1 ,连乘后梯度指数级衰减 → 梯度消失
-
如果每一项都 > 1 ,连乘后梯度指数级增长 → 梯度爆炸
核心原因 :深度网络的反向传播本质上是一个连乘结构,乘得太多,结果要么趋近 0,要么趋近无穷。
三、梯度消失(Vanishing Gradient)
常见原因
| 原因 | 说明 |
|---|---|
| 激活函数选择不当 | Sigmoid / Tanh 在两端导数趋近于 0,饱和区直接杀死梯度 |
| 网络太深 | 连乘效应导致梯度逐层衰减 |
| 初始化不当 | 权重初始值太小,信号逐层萎缩 |
典型表现
-
靠近输入层的参数几乎不变
-
网络收敛极慢,甚至不收敛
-
深层网络反而不如浅层网络效果好
例子
Sigmoid 函数在 x=2 时导数 ≈ 0.1,x=4 时导数 ≈ 0.01。 100 层连乘:0.1^100 ≈ 10^(-100),梯度直接“消失”到接近于 0。
四、梯度爆炸(Exploding Gradient)
常见原因
| 原因 | 说明 |
|---|---|
| 权重初始化太大 | 初始值过大,连乘后指数级增长 |
| 网络太深 | 连乘效应同样会导致指数放大 |
| RNN 长期依赖 | 同一权重矩阵反复连乘,容易爆炸 |
典型表现
-
损失值变成 NaN(Not a Number)
-
参数更新步长巨大,模型发散
-
训练过程震荡剧烈,无法收敛
例子
如果每层梯度都放大 1.5 倍,50 层后:1.5^50 ≈ 6.3e8,梯度直接“爆炸”。五、常见解决方案(面试高频追问"怎么解决")
| 解决手段 | 针对消失 | 针对爆炸 | 说明 |
|---|---|---|---|
| 使用 ReLU / LeakyReLU | ✅ | ❌ | 正区间梯度恒为 1,避免饱和 |
| 使用残差连接(ResNet) | ✅ | ❌ | 让梯度有一条"近路"直通浅层 |
| 使用 Batch Normalization | ✅ | ✅ | 保持每层输入分布稳定,避免梯度极端 |
| 梯度裁剪(Gradient Clipping) | ❌ | ✅ | 限制梯度最大值,防止指数放大 |
| 恰当的权重初始化 | ✅ | ✅ | Xavier / He 初始化匹配网络规模 |
| 减少网络层数 | ✅ | ✅ | 最直接但牺牲表达能力 |
六、对比总结表
| 对比维度 | 梯度消失 | 梯度爆炸 |
|---|---|---|
| 梯度变化方向 | 逐层变小,趋近 0 | 逐层变大,趋近无穷 |
| 对参数更新的影响 | 浅层参数几乎不变 | 所有参数更新剧烈,模型发散 |
| 主要成因 | 激活函数饱和、连乘 < 1 | 权重初始化过大、连乘 > 1 |
| 典型表现 | 训练极慢、不收敛 | 损失值 NaN、训练震荡 |
| 核心解决方案 | ReLU、残差连接、BatchNorm | 梯度裁剪、适当初始化 |
七、面试回答模板(直接背)
"梯度消失和梯度爆炸是深层神经网络在反向传播时,由于梯度连乘效应导致的两种极端情况。
梯度消失指的是反向传播时梯度逐层缩小,靠近输入层的参数几乎不更新,模型学不动。主要原因包括激活函数(如 Sigmoid)在饱和区导数趋近于 0,以及网络太深导致连乘效应。常用解决方案是使用 ReLU 激活函数、残差连接(ResNet)或 Batch Normalization。
梯度爆炸指的是梯度逐层放大,导致参数更新剧烈,模型发散,损失值可能出现 NaN。主要原因包括权重初始化过大或 RNN 中的长期依赖。常用解决方案是梯度裁剪(Gradient Clipping)和适当的权重初始化(如 He 初始化)。
两者的本质相同:都是反向传播中连乘效应导致的梯度不稳定,只是变化方向相反。"
正向传播(Forward Propagation):数据往前走
方向:输入层 → 隐藏层 → 输出层
做的事情:输入数据经过每一层的权重和激活函数,逐层计算,最后输出一个预测结果。
例子:你输入一张猫的图片,网络经过一系列计算,最后输出"90% 是猫"。这个过程就是正向传播。
得到什么 :得到一个预测值 ,和一个损失值(预测值和真实标签之间的差距)。
正向传播的核心目的:知道模型这次猜得有多离谱。
反向传播(Backpropagation):误差往回走
方向:输出层 → 隐藏层 → 输入层
做的事情 :从损失函数出发,沿着网络结构从后往前,逐层计算损失对每个参数的偏导数(梯度)。
为什么必须从后往前?
因为链式法则决定了:后一层的梯度可以先算出来,前面层的梯度依赖后面层的梯度。
数学上:
∂L/∂W₁ = ∂L/∂y₃ · ∂y₃/∂y₂ · ∂y₂/∂y₁ · ∂y₁/∂W₁必须先算 ∂L/∂y₃(最后一层),才能往前往后推 ∂L/∂W₁。方向天然就是从后往前。
得到什么 :每一层每个参数的梯度值(即"参数应该往哪个方向调、调多少")。
反向传播的核心目的:告诉每一层参数应该怎么改,才能让损失变小。
图论


主要是概念

割集的概念和二部图的概念,这还真没那么好看懂。理解了这个定义后惊为天人。

关联矩阵是点和边,n*m;邻接矩阵是点和点,n*n,邻接矩阵的性质A^k表示长度为k的路总数。

欧拉回路=一笔画,欧拉路不要求回到起点。核心是边。
哈密顿图核心是点。
欧拉图:一张图中,你想"不重复地走完每条路"。
哈密顿图:一张图中,你想"不重复地逛完每个景点"。
以下例子代表是欧拉图但不是哈密顿图;是哈密顿图但不是欧拉图。
A ------ B
| | ← 左边一个环
D ------ C
|
| ← 桥(公共顶点 C)
|
E ------ F
| | ← 右边一个环
H ------ G
A ------ C| |\
| | E
| |/
B ------ D

一把鼻涕一把泪,明天加练prim和floyd算法。这两对于我总是搞不清。

这个3、4的证明有点看不太懂了,主要是这个模型不好抽象......先算了吧。