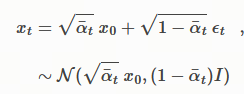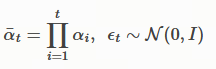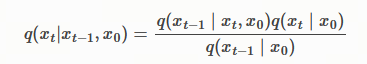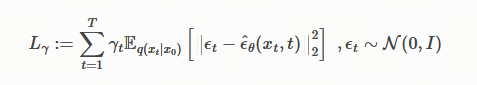核心的思想是,构建一个马尔科夫链式结构,逐步的向x0 上添加高斯随机噪声,并最终令其演变成一个纯高斯数据(标准正态分布), 把这个过程称为加噪过程,或者前向过程。 它的逆向过程就是逐步降噪的过程, 主要估计出逆向过程中每一步的降噪转换核 p ( x t − 1 ∣ p t ) p(x_{t-1}|p_{t}) p(xt−1∣pt) , 就可以从一个标准正态分布的高斯噪声数据 x T x_T xT , 逐步的降噪生成一张图片数据。
假设我们拥有一组来自数据分布 q ( x 0 ) q(x_0) q(x0) 的样本,我们的目标是学习一个模型分布 p θ ( x 0 ) p_\theta(x_0) pθ(x0),使其能够逼近 q ( x 0 ) q(x_0) q(x0) 并且易于从中采样。
去噪扩散概率模型(DDPMs)属于潜变量模型,其形式为 p θ ( x 0 ) = ∫ p θ ( x 0 : T ) d x 1 : T p_\theta(x_0) = \int p_\theta(x_{0:T}) dx_{1:T} pθ(x0)=∫pθ(x0:T)dx1:T,其中联合分布定义为 p θ ( x 0 : T ) : = p θ ( x T ) ∏ t = 1 T p θ ( t ) ( x t − 1 ∣ x t ) p_\theta(x_{0:T}) := p_\theta(x_T) \prod_{t=1}^{T} p^{(t)}\theta(x{t-1}|x_t) pθ(x0:T):=pθ(xT)t=1∏Tpθ(t)(xt−1∣xt)。这里, x 1 , ... , x T x_1, \dots, x_T x1,...,xT 是与 x 0 x_0 x0 处于相同样本空间 X \mathcal{X} X 中的潜变量。
想象你有一张清晰的照片(这是真实数据 x 0 x_0 x0),以及一张完全充满静电噪声的图片(这是噪声 x T x_T xT)。
在扩散模型中,我们假设从清晰照片到噪声图片的过程,并不是直接一步完成的,而是经过了 T T T 个中间步骤。
x 0 x_0 x0:原始数据(例如:一张清晰的猫的照片)。
x T x_T xT:纯噪声(高斯噪声)。
x 1 , ... , x T − 1 x_1, \dots, x_{T-1} x1,...,xT−1:这些就是潜变量(Latent Variables) 。它们处于 x 0 x_0 x0 和 x T x_T xT 之间,代表了数据从"清晰"逐渐变得"模糊"再到"完全噪声"的中间状态。
"联合分布定义为 p θ ( x 0 : T ) : = p θ ( x T ) ∏ t = 1 T p θ ( t ) ( x t − 1 ∣ x t ) p_\theta(x_{0:T}) := p_\theta(x_T) \prod_{t=1}^T p_\theta^{(t)}(x_{t-1} | x_t) pθ(x0:T):=pθ(xT)∏t=1Tpθ(t)(xt−1∣xt)"
这里的公式描述的是反向生成过程的数学表达。
p θ ( x T ) p_\theta(x_T) pθ(xT):起始状态,即采样一个纯高斯噪声。
∏ t = 1 T p θ ( t ) ( x t − 1 ∣ x t ) \prod_{t=1}^T p_\theta^{(t)}(x_{t-1} | x_t) ∏t=1Tpθ(t)(xt−1∣xt):这意味着我们从 t = T t=T t=T 开始,利用模型(参数为 θ \theta θ)预测如何从 x t x_t xt 变成 x t − 1 x_{t-1} xt−1,一直重复到 t = 1 t=1 t=1。
联合概率的链式法则(Chain Rule of Probability),马尔可夫链(Markov Chain)的联合概率分布。在扩散模型(Diffusion Models)的逆向过程中,从 x T x_{T} xT开始,每一步的变换只依赖于当前状态。
连乘部分,本质上是在计算在给定初始起点 x T x_{T} xT的情况下,整条生成路径 ( x 0 : T − 1 ) (x_{0:T-1}) (x0:T−1)出现的联合概率
简单来说,这个公式描述了**"从噪声生成图像"**这一完整路径的概率。
积分的作用:
" p θ ( x 0 ) = ∫ p θ ( x 0 : T ) d x 1 : T p_\theta(x_0) = \int p_\theta(x_{0:T}) dx_{1:T} pθ(x0)=∫pθ(x0:T)dx1:T"
因为我们要计算最终生成数据 x 0 x_0 x0 的概率,但我们不知道中间的具体路径 x 1 ... x T x_1 \dots x_T x1...xT 是什么,所以数学上需要对所有可能的中间路径进行积分(求和) 。这表示无论中间过程怎么走,只要最终能回到 x 0 x_0 x0,都算作有效生成。
max θ E q ( x 0 ) log p θ ( x 0 ) ≤ max θ E q ( x 0 , x 1 , ... , x T ) log p θ ( x 0 : T ) − log q ( x 1 : T ∣ x 0 ) ( 2 ) \max_\theta \mathbb{E}{q(x_0)}\\log p_\\theta(x_0) \leq \max\theta \mathbb{E}_{q(x_0, x_1, \dots, x_T)} \\log p_\\theta(x_{0:T}) - \\log q(x_{1:T}\|x_0) \quad (2) θmaxEq(x0)logpθ(x0)≤θmaxEq(x0,x1,...,xT)logpθ(x0:T)−logq(x1:T∣x0)(2)
其中 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0) 是作用于潜变量的某种推断分布。
最大化变分下界(ELBO)
"模型参数 θ \theta θ 通过最大化变分下界来拟合数据分布... max θ E q ( x 0 ) log p θ ( x 0 ) ≤ max θ E log p θ ( x 0 : T ) − log q ( x 1 : T ∣ x 0 ) \max_\theta \mathbb{E}{q(x_0)}\\log p_\\theta(x_0) \le \max\theta \mathbb{E}\\log p_\\theta(x_{0:T}) - \\log q(x_{1:T}\|x_0) maxθEq(x0)logpθ(x0)≤maxθElogpθ(x0:T)−logq(x1:T∣x0)"
log p θ ( x 0 : T ) \log p_\theta(x_{0:T}) logpθ(x0:T):这是模型生成的联合概率。
− log q ( x 1 : T ∣ x 0 ) -\log q(x_{1:T}|x_0) −logq(x1:T∣x0):这是一个"惩罚项"或"参考项"。 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0) 被称为**推断分布(Inference Distribution)**或近似后验分布。
在前向扩散过程中,我们其实已经知道如何从 x 0 x_0 x0 变成 x T x_T xT(这是确定的加噪过程)。因此,我们可以构造一个已知的分布 q q q 来近似模型在反向过程中应该遵循的潜变量分布。
与典型的潜变量模型(如VAE变分自编码器,Rezende 等人,2014)不同,DDPMs 使用固定的(而非可训练的)推断过程 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0),且潜变量具有较高的维度。例如,Ho 等人(2020)考虑了以下由递减序列 α 1 : T ∈ ( 0 , 1 ] T \alpha_{1:T} \in (0, 1]^T α1:T∈(0,1]T 参数化的马尔可夫链,其转移过程具有高斯性质:
q ( x 1 : T ∣ x 0 ) : = ∏ t = 1 T q ( x t ∣ x t − 1 ) , 其中 q ( x t ∣ x t − 1 ) : = N ( α t α t − 1 x t − 1 , ( 1 − α t α t − 1 ) I ) ( 3 ) q(x_{1:T}|x_0) := \prod_{t=1}^{T} q(x_t|x_{t-1}), \quad \text{其中 } q(x_t|x_{t-1}) := \mathcal{N}\left( \sqrt{\frac{\alpha_t}{\alpha_{t-1}}} x_{t-1}, \left(1 - \frac{\alpha_t}{\alpha_{t-1}}\right)I \right) \quad (3) q(x1:T∣x0):=t=1∏Tq(xt∣xt−1),其中 q(xt∣xt−1):=N(αt−1αt xt−1,(1−αt−1αt)I)(3)
q ( x 1 : T ∣ x 0 ) : = ∏ t = 1 T q ( x t ∣ x t − 1 ) , q(x_{1:T}|x_0) := \prod_{t=1}^{T} q(x_t|x_{t-1}), \quad q(x1:T∣x0):=t=1∏Tq(xt∣xt−1),
前向扩散过程的转换核 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)是一个条件高斯分布, 它的概率密度为
q ( x t ∣ x t − 1 ) : = N ( α t α t − 1 x t − 1 , ( 1 − α t α t − 1 ) I ) ( 3 ) q(x_t|x_{t-1}) := \mathcal{N}\left( \sqrt{\frac{\alpha_t}{\alpha_{t-1}}} x_{t-1}, \left(1 - \frac{\alpha_t}{\alpha_{t-1}}\right)I \right) \quad (3) q(xt∣xt−1):=N(αt−1αt xt−1,(1−αt−1αt)I)(3)
有了这个转换(加噪)核,就可以逐步的把一张有意义的图像数据 x0 转换为一个纯高斯噪声数据 x T x_T xT 。
这里协方差矩阵的对角线元素被确保为正。由于采样过程从 x 0 x_0 x0 自回归地演进到 x T x_T xT,这一过程被称为前向过程 。我们称潜变量模型 p θ ( x 0 : T ) p_\theta(x_{0:T}) pθ(x0:T) 为生成过程 ,因为它从 x T x_T xT 采样至 x 0 x_0 x0,旨在近似难以处理的逆过程 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt)。直观地说,前向过程逐步向观测值 x 0 x_0 x0 添加噪声,而生成过程则逐步去除噪声观测值中的噪声(见图1左侧)。
然而这个加噪计算过程需要一步一步计算,计算效率比较差, 这时可以利用条件高斯分布的一个计算技巧,直接从 x0 一步计算得到任意时刻的xt , 这个过程可以表示为条件概率分布 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0) :
前向过程的一个特殊性质在于:
q ( x t ∣ x 0 ) : = ∫ q ( x 1 : t ∣ x 0 ) d x 1 : ( t − 1 ) ∼ N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) ; q(x_t|x_0) := \int q(x_{1:t}|x_0) dx_{1:(t-1)} \sim \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1-\bar{\alpha}_t)I); q(xt∣x0):=∫q(x1:t∣x0)dx1:(t−1)∼N(xt;αˉt x0,(1−αˉt)I);
(注:原文中公式(4)的系数可能指累乘后的系数,通常记为 α ˉ t \bar{\alpha}_t αˉt,此处保留原文逻辑结构)
q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)的直接算数计算等式为线性组合。我们可以将 x t x_t xt 表示为 x 0 x_0 x0 和噪声变量 ϵ \epsilon ϵ 的线性组合:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ , 其中 ϵ ∼ N ( 0 , I ) . ( 4 ) x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon, \quad \text{其中 } \epsilon \sim \mathcal{N}(0, I). \quad (4) xt=αˉt x0+1−αˉt ϵ,其中 ϵ∼N(0,I).(4)
当我们将 α ˉ T \bar{\alpha}T αˉT 设置得足够接近 0 时,对于任意 x 0 x_0 x0, q ( x T ∣ x 0 ) q(x_T|x_0) q(xT∣x0) 都会收敛到标准高斯分布,因此自然地设定先验分布为 p θ ( x T ) : = N ( 0 , I ) p\theta(x_T) := \mathcal{N}(0, I) pθ(xT):=N(0,I)。如果所有的条件分布都被建模为均值函数可训练且方差固定的高斯分布,公式 (2) 中的目标函数可以简化为¹:
L γ ( ϵ θ ) : = ∑ t = 1 T γ t E x 0 ∼ q ( x 0 ) , ϵ t ∼ N ( 0 , I ) ∥ ϵ θ ( t ) ( α ˉ t x 0 + 1 − α ˉ t ϵ t ) − ϵ t ∥ 2 2 ( 5 ) L_\gamma(\epsilon_\theta) := \sum_{t=1}^{T} \gamma_t \mathbb{E}_{x_0 \sim q(x_0), \epsilon_t \sim \mathcal{N}(0,I)} \left \\\|\\epsilon\^{(t)}_\\theta (\\sqrt{\\bar{\\alpha}_t}x_0 + \\sqrt{1-\\bar{\\alpha}_t}\\epsilon_t) - \\epsilon_t\\\|_2\^2 \\right \quad (5) Lγ(ϵθ):=t=1∑TγtEx0∼q(x0),ϵt∼N(0,I)∥ϵθ(t)(αˉt x0+1−αˉt ϵt)−ϵt∥22(5)
其中 ϵ θ : = { ϵ θ ( t ) } t = 1 T \epsilon_\theta := \{\epsilon^{(t)}\theta\}{t=1}^T ϵθ:={ϵθ(t)}t=1T 是一组包含 T T T 个函数的集合,每个 ϵ θ ( t ) : X → X \epsilon^{(t)}\theta : \mathcal{X} \to \mathcal{X} ϵθ(t):X→X(由 t t t 索引)都是一个具有可训练参数 θ ( t ) \theta^{(t)} θ(t) 的函数,而 γ : = γ 1 , ... , γ T \gamma := \\gamma_1, \\dots, \\gamma_T γ:=γ1,...,γT 是目标函数中正系数向量,其值取决于 α 1 : T \alpha{1:T} α1:T。在 Ho 等人(2020)中,优化的是 γ = 1 \gamma = 1 γ=1 时的目标函数,以最大化训练模型的生成性能;这也与基于得分匹配(Hyvärinen, 2005;Vincent, 2011)的噪声条件得分网络(Song & Ermon, 2019)所使用的目标函数相同。
从训练好的模型中采样 x 0 x_0 x0 的步骤如下:首先从先验分布 p θ ( x T ) p_\theta(x_T) pθ(xT) 中采样 x T x_T xT,然后迭代地从生成过程中采样 x t − 1 x_{t-1} xt−1。
逆向过程:
加噪过程的逆过程称为降噪过程,降噪过程是对联合概率 p ( x 0 : T ) p(x_{0:T}) p(x0:T)按照反向过程进行链式分解:
x 0 x_0 x0:原始数据(例如:一张清晰的猫的照片)。
x T x_T xT:纯噪声(高斯噪声)。
x 1 , ... , x T − 1 x_1, \dots, x_{T-1} x1,...,xT−1:这些就是潜变量(Latent Variables) 。它们处于 x 0 x_0 x0 和 x T x_T xT 之间,代表了数据从"清晰"逐渐变得"模糊"再到"完全噪声"的中间状态。
"联合分布定义为
p θ ( x 0 : T ) : = p θ ( x T ) ∏ t = 1 T p θ ( t ) ( x t − 1 ∣ x t ) p_\theta(x_{0:T}) := p_\theta(x_T) \prod_{t=1}^T p_\theta^{(t)}(x_{t-1} | x_t) pθ(x0:T):=pθ(xT)t=1∏Tpθ(t)(xt−1∣xt)
他表示在 xt 的基础上去掉一部分高斯噪声得到 x t − 1 x_{t-1} xt−1,所以称为降噪过程。
其中 p ( x T ) p(x_T) p(xT) 的概率密度是知道的,它是一个标准高斯分布 N ( 0 , I ) N(0,I) N(0,I)
我们的关键就是估计出 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt) 的一个近似表示。
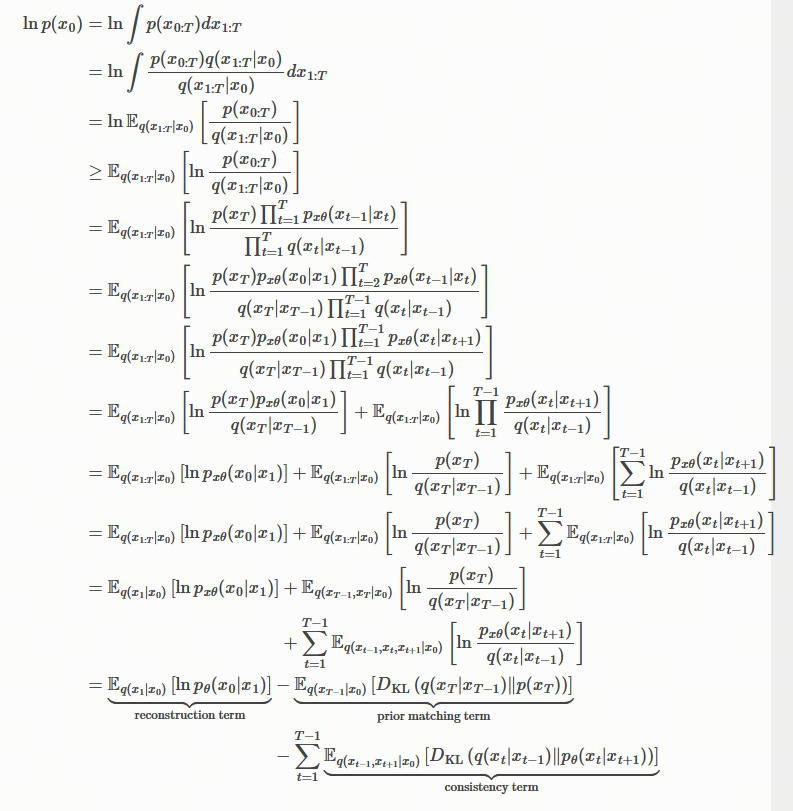
然而 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt)是难以计算的, 即使根据贝叶斯定理得出 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt) 的表达式, 它的分母部分(归一化项)是含有积分的,这个积分是没有解析解的,是非常难以计算的。 因此,我们想到用一个模型(神经网络)取拟合学习条件概率分布 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt) ,然后利用学习好的模型,充当 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt) ,这样就有了逆向过程的完整链式结构,也就可以通过逆向过程,从一个随机高斯噪声 逐步生成一张真实的图片 。
我们的目标是让模型学会生成数据,根据最大似然估计理论,我们需要极大化观测数据的对数似然ln(p(x0)) ,然而整个网络中随机变量有个 T 个,可是只有 x0 有观测样本。
整个网络的联合概率分布是 p ( x 0 : T ) p(x_{0:T}) p(x0:T),我们只有x0 的观测数据(样本) ,没有x1:T 的观测样本,因此我们极大化的是边缘分布 p(x0)
联合概率p(x_{0:T}) 进行边缘化进而得到 x0 的边缘概率 p(x0), 如下式所示,
l n p ( x 0 ) = l n ∫ p ( x 0 : T ) d x 1 : T ln p(x_0) = ln \int{p(x_{0:T})dx_{1:T}} lnp(x0)=ln∫p(x0:T)dx1:T
在机器学习和概率图模型中,当我们有一组潜变量 (Latent Variables,这里是 x 1 : T x_{1:T} x1:T)和观测变量 (Observed Variables,这里是 x 0 x_0 x0)时,观测数据的似然(Likelihood)定义为所有潜变量的联合概率之和(积分) 。
p ( x 0 ) = ∫ p ( x 0 , x 1 , . . . , x T ) d x 1 . . . d x T = ∫ p ( x 0 : T ) d x 1 : T p(x_0) = \int p(x_0, x_1, ..., x_T) dx_1 ... dx_T = \int p(x_{0:T}) dx_{1:T} p(x0)=∫p(x0,x1,...,xT)dx1...dxT=∫p(x0:T)dx1:T
这行公式在数学定义上是完全正确的。 它表示:
"数据 x 0 x_0 x0 出现的概率,等于所有可能的中间噪声状态 x 1 : T x_{1:T} x1:T 与 x 0 x_0 x0 同时出现的联合概率之和。"
这是一个多元积分,我举个多元积分例子:
∫ p ( x 0 , x 1 ) d x 1 \int p(x_0, x_1) dx_1 ∫p(x0,x1)dx1 :这是一个标量 (一个具体的数字)。它表示 x 0 x_0 x0 的边缘概率密度。
∫ ∫ p ( x 0 , x 1 ) d x 0 d x 1 \int \int p(x_0, x_1) dx_0 dx_1 ∫∫p(x0,x1)dx0dx1 :这也是一个标量 (一个具体的数字),而且它通常等于 1 。它表示整个联合分布的总概率质量。
情况 A: ∫ p ( x 0 , x 1 ) d x 1 \int p(x_0, x_1) dx_1 ∫p(x0,x1)dx1
积分变量 : x 1 x_1 x1。
自由变量 : x 0 x_0 x0 保持不变。
结果 :一个关于 x 0 x_0 x0 的函数,记为 p ( x 0 ) p(x_0) p(x0)。
物理意义 :边缘概率密度(Marginal PDF) 。
它告诉我们:不管 x 1 x_1 x1 是什么状态,观测到 x 0 x_0 x0 的概率密度是多少。
在扩散模型中,这就是我们要极大化的目标函数 ln p ( x 0 ) \ln p(x_0) lnp(x0) 的核心部分。
情况 B: ∬ p ( x 0 , x 1 ) d x 0 d x 1 \iint p(x_0, x_1) dx_0 dx_1 ∬p(x0,x1)dx0dx1
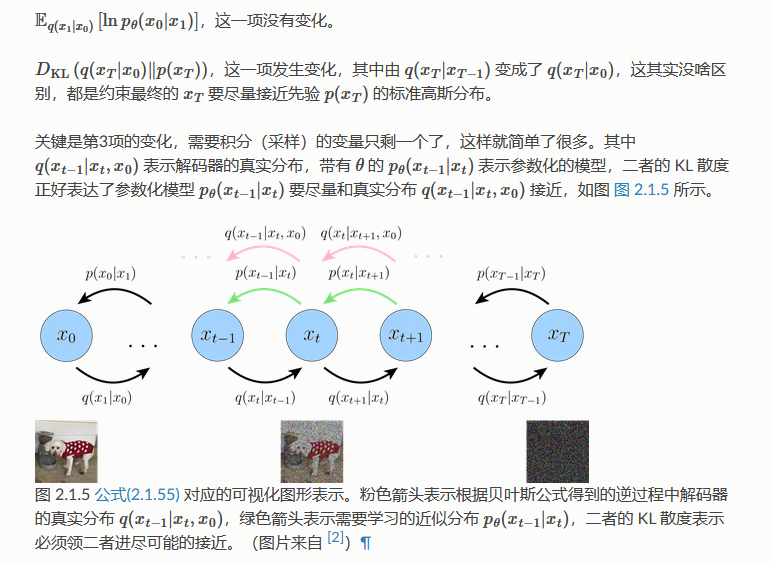
第二项不包含任意可学习参数,因此可以忽略掉。 另外两项都是一个期望项,解决方法和 VAE 一样,可以通过采样法(MCMC)近似求解期望。 然而,第三项存在一个小问题,它的期望是关于两个变量的 x t − 1 , x t + 1 xt-1,xt+1 xt−1,xt+1 , 用采样法(MCMC)同时对两个随机变量进行采样,会导致更大的方差,这会使得优化过程不稳定,不容易收敛 2。 因此直接优化 公式(2.1.52) 并不是最佳的选择,我们继续看能不能改进一下。
根据条件独立性
我再重新推导 ELBO 函数,推导过程如下:
对比一下 公式 发生了一些变化,
代入各项之后,最后的目标函数是一个简单的均方误差,这里记作 L L L , 其中 γ t \gamma_t γt表示一些常数项,它不影响极大化的结果。
前向过程的长度 T T T 是 DDPMs 中的一个重要超参数。从变分推断的角度来看,较大的 T T T 值可以使逆过程更接近高斯分布(Sohl-Dickstein 等人,2015),从而使由高斯条件分布建模的生成过程成为良好的近似;这解释了为何要选择较大的 T T T 值,例如 Ho 等人(2020)中使用的 T = 1000 T=1000 T=1000。然而,由于获取样本 x 0 x_0 x0 必须依次执行所有 T T T 次迭代,而不能并行处理,因此从 DDPMs 中采样的速度远慢于其他深度生成模型。这使得它们在计算资源有限且对延迟敏感的任务中变得不切实际。
(以上属于是回顾DDPM)
3 非马尔可夫前向过程(Non-Markovian Forward Processes)
作者观察到DDPM 的Loss 主要依赖边缘概率密度分布 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0),但是并不直接依赖联合概率 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0),似乎可以采用非 markov 去改变generative 过程。如图1
作者指出,DDPM 的损失函数(Objective Function,记为 L γ L_\gamma Lγ)实际上只依赖于数据在每一步的边缘分布 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0),而并不直接依赖于整个联合分布 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0)。
这里的正向过程不再具有马尔可夫性,因为每个 x t x_t xt 可能同时依赖于 x t − 1 x_{t-1} xt−1 和 x 0 x_0 x0。 σ \sigma σ 的大小控制了正向过程的随机性程度;当 σ → 0 \sigma \to 0 σ→0 时,我们进入一种极端情形:只要已知某个时刻 t t t 的 x 0 x_0 x0 和 x t x_t xt,那么 x t − 1 x_{t-1} xt−1 就被确定且固定不变。
3.2 生成过程与统一的变分推断目标
接下来,我们定义一个可训练的生成过程 p θ ( x 0 : T ) p_\theta(x_{0:T}) pθ(x0:T),其中每个 p θ ( t ) ( x t − 1 ∣ x t ) p_\theta^{(t)}(x_{t-1}|x_t) pθ(t)(xt−1∣xt) 都利用了对 q σ ( x t − 1 ∣ x t , x 0 ) q_\sigma(x_{t-1}|x_t, x_0) qσ(xt−1∣xt,x0) 的知识。直观地说,给定一个带噪声的观测值 x t x_t xt,我们首先对相应的 x 0 x_0 x0 做出预测,然后利用已定义的逆条件分布 q σ ( x t − 1 ∣ x t , x 0 ) q_\sigma(x_{t-1}|x_t, x_0) qσ(xt−1∣xt,x0) 从中采样得到 x t − 1 x_{t-1} xt−1。
对于某些 x 0 ∼ q ( x 0 ) x_0 \sim q(x_0) x0∼q(x0) 和 ϵ t ∼ N ( 0 , I ) \epsilon_t \sim \mathcal{N}(0, I) ϵt∼N(0,I),可以通过公式 (4) 获得 x t x_t xt。模型 ϵ θ ( t ) ( x t ) \epsilon_\theta^{(t)}(x_t) ϵθ(t)(xt) 随后试图从 x t x_t xt 预测 ϵ t \epsilon_t ϵt,且无需知道 x 0 x_0 x0。通过重写公式 (4),我们可以预测去噪后的观测值,即在给定 x t x_t xt 的情况下对 x 0 x_0 x0 的预测:
f θ ( t ) ( x t ) : = ( x t − 1 − α t ⋅ ϵ θ ( t ) ( x t ) ) / α t . ( 9 ) f_\theta^{(t)}(x_t) := (x_t - \sqrt{1 - \alpha_t} \cdot \epsilon_\theta^{(t)}(x_t)) / \sqrt{\alpha_t}. \quad (9) fθ(t)(xt):=(xt−1−αt ⋅ϵθ(t)(xt))/αt .(9)
接着,我们可以定义生成过程,其固定先验为 p θ ( x T ) = N ( 0 , I ) p_\theta(x_T) = \mathcal{N}(0, I) pθ(xT)=N(0,I),且
p θ ( t ) ( x t − 1 ∣ x t ) = { N ( f θ ( 1 ) ( x 1 ) , σ 1 2 I ) 如果 t = 1 q σ ( x t − 1 ∣ x t , f θ ( t ) ( x t ) ) 否则 , ( 10 ) p_\theta^{(t)}(x_{t-1}|x_t) = \begin{cases} \mathcal{N}(f_\theta^{(1)}(x_1), \sigma_1^2 I) & \text{如果 } t = 1 \\ q_\sigma(x_{t-1}|x_t, f_\theta^{(t)}(x_t)) & \text{否则} \end{cases}, \quad (10) pθ(t)(xt−1∣xt)={N(fθ(1)(x1),σ12I)qσ(xt−1∣xt,fθ(t)(xt))如果 t=1否则,(10)
其中 q σ ( x t − 1 ∣ x t , f θ ( t ) ( x t ) ) q_\sigma(x_{t-1}|x_t, f_\theta^{(t)}(x_t)) qσ(xt−1∣xt,fθ(t)(xt)) 的定义如公式 (7) 所示,只是将 x 0 x_0 x0 替换为 f θ ( t ) ( x t ) f_\theta^{(t)}(x_t) fθ(t)(xt)。对于 t = 1 t=1 t=1 的情况,我们添加了一些高斯噪声(协方差为 σ 1 2 I \sigma_1^2 I σ12I),以确保生成过程处处有支撑(supported everywhere)。
J σ ( ϵ θ ) : = E x 0 : T ∼ q σ ( x 0 : T ) log q σ ( x 1 : T ∣ x 0 ) − log p θ ( x 0 : T ) ( 11 ) J_\sigma(\epsilon_\theta) := \mathbb{E}{x{0:T} \sim q_\sigma(x_{0:T})} \\log q_\\sigma(x_{1:T}\|x_0) - \\log p_\\theta(x_{0:T}) \quad (11) Jσ(ϵθ):=Ex0:T∼qσ(x0:T)logqσ(x1:T∣x0)−logpθ(x0:T)(11)
= E x 0 : T ∼ q σ ( x 0 : T ) log q σ ( x T ∣ x 0 ) + ∑ t = 2 T log q σ ( x t − 1 ∣ x t , x 0 ) − ∑ t = 1 T log p θ ( t ) ( x t − 1 ∣ x t ) − log p θ ( x T ) = \mathbb{E}{x{0:T} \sim q_\sigma(x_{0:T})} \left \\log q_\\sigma(x_T\|x_0) + \\sum_{t=2}\^T \\log q_\\sigma(x_{t-1}\|x_t, x_0) - \\sum_{t=1}\^T \\log p_\\theta\^{(t)}(x_{t-1}\|x_t) - \\log p_\\theta(x_T) \\right =Ex0:T∼qσ(x0:T)logqσ(xT∣x0)+t=2∑Tlogqσ(xt−1∣xt,x0)−t=1∑Tlogpθ(t)(xt−1∣xt)−logpθ(xT)
其中, q σ ( x 1 : T ∣ x 0 ) q_\sigma(x_{1:T}|x_0) qσ(x1:T∣x0) 按照公式 (6) 进行因式分解, p θ ( x 0 : T ) p_\theta(x_{0:T}) pθ(x0:T) 按照公式 (1) 进行因式分解。
定理 1。 对于所有 σ > 0 \sigma > 0 σ>0,存在 γ ∈ R > 0 T \gamma \in \mathbb{R}^T_{>0} γ∈R>0T 和 C ∈ R C \in \mathbb{R} C∈R,使得 J σ = L γ + C J_\sigma = L_\gamma + C Jσ=Lγ+C。
变分目标函数 L γ L_\gamma Lγ 的特殊之处在于,如果模型 ϵ θ ( t ) \epsilon_\theta^{(t)} ϵθ(t) 的参数在不同的 t t t 之间不共享,那么 ϵ θ \epsilon_\theta ϵθ 的最优解将不依赖于权重 γ \gamma γ(因为通过对求和中的每一项分别最大化,即可达到全局最优)。 L γ L_\gamma Lγ 的这一性质具有两个含义。一方面,这证明了在 DDPM 中使用 L 1 L_1 L1 作为变分下界的代理目标函数是合理的;另一方面,由于根据定理 1, J σ J_\sigma Jσ 等价于某个 L γ L_\gamma Lγ,因此 J σ J_\sigma Jσ 的最优解与 L 1 L_1 L1 的最优解相同。因此,如果模型 ϵ θ \epsilon_\theta ϵθ 中的参数在 t t t 之间不共享,那么 Ho 等人 (2020) 使用的 L 1 L_1 L1 目标函数也可以作为变分目标函数 J σ J_\sigma Jσ 的代理目标函数。
我们在推理阶段 (生成阶段)不需要 x 0 x_0 x0(因为它是未知的噪声),但我们需要利用在训练阶段学到的知识。
模型 ϵ θ ( x t ) \epsilon_\theta(x_t) ϵθ(xt) 从 x t x_t xt 预测噪声 ϵ t \epsilon_t ϵt。
根据公式 (9),我们可以从这个预测噪声中重构出 x 0 x_0 x0 的估计值:
f θ ( t ) ( x t ) : = ( x t − 1 − α t ⋅ ϵ θ ( t ) ( x t ) ) / α t f^{(t)}\theta(x_t) := (x_t - \sqrt{1-\alpha_t} \cdot \epsilon^{(t)}\theta(x_t)) / \sqrt{\alpha_t} fθ(t)(xt):=(xt−1−αt ⋅ϵθ(t)(xt))/αt
这相当于问神经网络:"基于当前的噪声图片 x t x_t xt,你觉得原始的干净图片 x 0 x_0 x0 长什么样?"
然后,生成步骤 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt) 使用这个预测的 f θ ( t ) ( x t ) f^{(t)}_\theta(x_t) fθ(t)(xt) 来代替真正的 x 0 x_0 x0,代入到之前定义的非马尔可夫逆向分布中采样。
定理 1 (Theorem 1) 的重大意义:
对于所有的 σ > 0 \sigma > 0 σ>0,存在权重 γ \gamma γ 和常数 C C C,使得 J σ = L γ + C J_\sigma = L_\gamma + C Jσ=Lγ+C。
以 L1 为目标,我们不仅学习了索尔-迪克斯坦等人(Sohl-Dickstein et al., 2015)和霍等人(Ho et al., 2020)所考虑的马尔可夫推理过程的生成过程,还学习了由参数 σ 参数化的许多非马尔可夫前向过程的生成过程。因此,我们可以本质上将预训练的 DDPM 模型作为新目标问题的解,并通过调整 σ 来寻找一种更能满足我们需求的、生成样本更优的生成过程。
4.1 去噪扩散隐式模型
根据公式 (10) 中的 p θ ( x 1 : T ) p_\theta(x_{1:T}) pθ(x1:T),可以从样本 x t x_t xt 生成样本 x t − 1 x_{t-1} xt−1,具体方式如下:
x t − 1 = α t − 1 ( x t − 1 − α t ϵ θ ( t ) ( x t ) α t ) ⏟ "预测的 x 0 " + 1 − α t − 1 − σ t 2 ⋅ ϵ θ ( t ) ( x t ) ⏟ "指向 x t 的方向" + σ t ϵ t ⏟ 随机噪声 ( 12 ) x_{t-1} = \underbrace{\sqrt{\alpha_{t-1}} \left( \frac{x_t - \sqrt{1-\alpha_t}\epsilon_\theta^{(t)}(x_t)}{\sqrt{\alpha_t}} \right)}{\text{"预测的 } x_0 \text{"}} + \underbrace{\sqrt{1-\alpha{t-1} - \sigma_t^2} \cdot \epsilon_\theta^{(t)}(x_t)}{\text{"指向 } x_t \text{ 的方向"}} + \underbrace{\sigma_t \epsilon_t}{\text{随机噪声}} \quad (12) xt−1="预测的 x0" αt−1 (αt xt−1−αt ϵθ(t)(xt))+"指向 xt 的方向" 1−αt−1−σt2 ⋅ϵθ(t)(xt)+随机噪声 σtϵt(12)
其中 ϵ t ∼ N ( 0 , I ) \epsilon_t \sim \mathcal{N}(0, I) ϵt∼N(0,I) 是与 x t x_t xt 独立的标准高斯噪声,我们定义 α 0 : = 1 \alpha_0 := 1 α0:=1。 σ \sigma σ 的不同取值对应于不同的生成过程,但它们均使用相同的模型 ϵ θ \epsilon_\theta ϵθ,因此无需重新训练模型。当对所有 t t t 满足 σ t = ( 1 − α t − 1 ) / ( 1 − α t ) 1 − α t / α t − 1 \sigma_t = \sqrt{(1-\alpha_{t-1})/(1-\alpha_t)} \sqrt{1-\alpha_t/\alpha_{t-1}} σt=(1−αt−1)/(1−αt) 1−αt/αt−1 时,前向过程变为马尔可夫过程,生成过程即转化为 DDPM。
我们注意到另一种特殊情况,即对所有 t t t(注5) σ t = 0 \sigma_t = 0 σt=0;此时前向过程在给定 x t − 1 x_{t-1} xt−1 和 x 0 x_0 x0 的条件下是确定性的( t = 1 t=1 t=1 除外);在生成过程中,随机噪声 ϵ t \epsilon_t ϵt 前面的系数变为零。由此得到的模型成为一种隐式概率模型(Mohamed & Lakshminarayanan, 2016),其中样本通过固定程序(从 x T x_T xT 到 x 0 x_0 x0)从潜在变量生成。我们将此模型命名为去噪扩散隐式模型(DDIM,发音为 /diːdiːɛm/),因为它是使用 DDPM 目标函数训练的隐式概率模型(尽管前向过程不再具有扩散性质)。
4.2 加速的生成过程
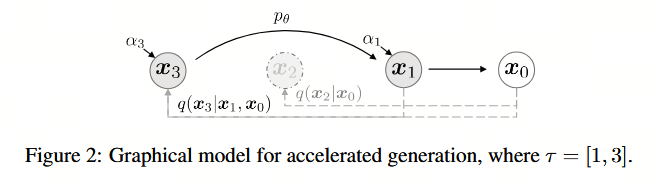
在前面的章节中,生成过程被视为逆向过程的近似;由于前向过程包含 T T T 个步骤,生成过程也被迫采样 T T T 个步骤。然而,只要 q σ ( x t ∣ x 0 ) q_\sigma(x_t|x_0) qσ(xt∣x0) 保持固定,去噪目标 L 1 L_1 L1 就不依赖于特定的前向程序。因此,我们可以考虑长度小于 T T T 的前向过程,从而在不训练不同模型的情况下加速相应的生成过程。
让我们考虑前向过程并非定义在所有潜在变量 x 1 : T x_{1:T} x1:T 上,而是定义在一个子集 { x τ 1 , ... , x τ S } \{x_{\tau_1}, \dots, x_{\tau_S}\} {xτ1,...,xτS} 上,其中 τ \tau τ 是序列 1 , ... , T 1, \\dots, T1,...,T 中长度为 S S S 的递增子序列。具体而言,我们定义在 x τ 1 , ... , x τ S x_{\tau_1}, \dots, x_{\tau_S} xτ1,...,xτS 上的顺序前向过程,使得 q ( x τ i ∣ x 0 ) = N ( α τ i x 0 , ( 1 − α τ i ) I ) q(x_{\tau_i}|x_0) = \mathcal{N}(\sqrt{\alpha_{\tau_i}}x_0, (1-\alpha_{\tau_i})I) q(xτi∣x0)=N(ατi x0,(1−ατi)I) 与"边际分布"相匹配(见图2所示)。生成过程现在根据逆向序列 reverse ( τ ) \text{reverse}(\tau) reverse(τ) 对潜在变量进行采样,我们将其称为(采样)轨迹。当采样轨迹的长度远小于 T T T 时,由于采样过程的迭代性质,我们可以显著提高计算效率。
原则上,这意味着我们可以训练一个具有任意数量前向步骤的模型,但在生成过程中仅从其中的某些步骤进行采样。因此,经过训练的模型可以考虑比 Ho et al. (2020) 中考虑的步骤多得多,甚至是一个连续时间变量 t t t(Chen et al., 2020)。我们将这方面的实证研究留待未来的工作。
4.3 与神经常微分方程(Neural ODEs)的相关性
此外,我们可以根据公式 (12) 重写 DDIM 的迭代过程,其与求解常微分方程(ODEs)的欧拉积分(Euler integration)之间的相似性变得更加明显:
x t − Δ t α t − Δ t = x t α t + ( 1 − α t − Δ t α t − Δ t − 1 − α t α t ) ϵ θ ( x t ) ( 13 ) \frac{x_{t-\Delta t}}{\sqrt{\alpha_{t-\Delta t}}} = \frac{x_t}{\sqrt{\alpha_t}} + \left( \sqrt{\frac{1-\alpha_{t-\Delta t}}{\alpha_{t-\Delta t}}} - \sqrt{\frac{1-\alpha_t}{\alpha_t}} \right) \epsilon_\theta(x_t) \quad (13) αt−Δt xt−Δt=αt xt+(αt−Δt1−αt−Δt −αt1−αt )ϵθ(xt)(13)
为了推导相应的常微分方程,我们可以将 ( 1 − α / α ) (\sqrt{1-\alpha}/\sqrt{\alpha}) (1−α /α ) 重新参数化为 σ \sigma σ,将 ( x / α ) (x/\sqrt{\alpha}) (x/α ) 重新参数化为 x ˉ \bar{x} xˉ。在连续情况下, σ \sigma σ 和 x x x 是时间 t t t 的函数,其中 σ : R ≥ 0 → R ≥ 0 \sigma : \mathbb{R}{\ge 0} \to \mathbb{R}{\ge 0} σ:R≥0→R≥0 是连续且单调递增的,并满足 σ ( 0 ) = 0 \sigma(0) = 0 σ(0)=0。公式 (13) 可以被视为以下常微分方程的欧拉方法:
d x ˉ ( t ) d σ ( t ) = ϵ θ ( x ˉ ( t ) σ 2 + 1 ) , ( 14 ) \frac{d\bar{x}(t)}{d\sigma(t)} = \epsilon_\theta \left( \frac{\bar{x}(t)}{\sqrt{\sigma^2 + 1}} \right), \quad (14) dσ(t)dxˉ(t)=ϵθ(σ2+1 xˉ(t)),(14)
其中初始条件为 x ( T ) ∼ N ( 0 , σ ( T ) ) x(T) \sim \mathcal{N}(0, \sigma(T)) x(T)∼N(0,σ(T)),且 σ ( T ) \sigma(T) σ(T) 非常大(对应于 α ≈ 0 \alpha \approx 0 α≈0 的情况)。这表明,通过足够的离散化步骤,我们也可以逆转生成过程(从 t = 0 t=0 t=0 到 T T T),这会将 x 0 x_0 x0 编码为 x T x_T xT,并模拟公式 (14) 中常微分方程的反向过程。这意味着与 DDPM 不同,我们可以使用 DDIM 来获取观测数据的编码(以 x T x_T xT 的形式),这对于需要模型潜在表示的其他下游应用可能很有用。
在另一项同时发表的工作(Song et al., 2020)中,作者提出了一种"概率流常微分方程"(probability flow ODE),旨在基于得分函数恢复随机微分方程(SDE)的边缘密度,从中可以获得类似的采样调度策略。在此,我们指出,我们的常微分方程等价于他们工作的一个特例(对应于 DDPM 的连续时间模拟)。
命题 1 :公式 (14) 中的常微分方程,在使用最优模型 ϵ θ \epsilon_\theta ϵθ 时,等价于 Song et al. (2020) 中对应于"方差爆炸"(Variance-Exploding)SDE 的概率流常微分方程。
我们将证明包含在附录 B 中。虽然这些常微分方程是等价的,但采样过程并非如此,因为针对概率流常微分方程的欧拉方法会产生以下更新:
x t − Δ t α t − Δ t = x t α t + 1 2 ( 1 − α t − Δ t α t − Δ t − 1 − α t α t ) ⋅ α t 1 − α t ⋅ ϵ θ ( x t ) ( 15 ) \frac{x_{t-\Delta t}}{\sqrt{\alpha_{t-\Delta t}}} = \frac{x_t}{\sqrt{\alpha_t}} + \frac{1}{2} \left( \sqrt{\frac{1-\alpha_{t-\Delta t}}{\alpha_{t-\Delta t}}} - \sqrt{\frac{1-\alpha_t}{\alpha_t}} \right) \cdot \sqrt{\frac{\alpha_t}{1-\alpha_t}} \cdot \epsilon_\theta(x_t) \quad (15) αt−Δt xt−Δt=αt xt+21(αt−Δt1−αt−Δt −αt1−αt )⋅1−αtαt ⋅ϵθ(xt)(15)
当 α t \alpha_t αt 和 α t − Δ t \alpha_{t-\Delta t} αt−Δt 足够接近时,上式等价于我们的更新公式。然而,在采样步数较少时,这些选择会产生差异;我们针对 d σ ( t ) d\sigma(t) dσ(t)(其对"时间" t t t 的缩放依赖较小)进行欧拉步进,而 Song et al. (2020) 则是针对 d t dt dt 进行欧拉步进。
你可以把 DDIM 理解为在用欧拉法(Euler Method)去逼近求解一个特定的 概率流常微分方程(Probability Flow ODE): 5, 6
x t − 1 = α t − 1 x ^ 0 ( x t ) + 1 − α t − 1 ⋅ ϵ θ ( x t ) x_{t-1} = \sqrt{\alpha_{t-1}} \hat{x}0(x_t) + \sqrt{1 - \alpha{t-1}} \cdot \epsilon_\theta(x_t) xt−1=αt−1 x^0(xt)+1−αt−1 ⋅ϵθ(xt)
在这个公式里:
每一项都是确定的数值计算,没有任何类似 N ( 0 , I ) \mathcal{N}(0, \mathbf{I}) N(0,I) 的随机采样项。
L = E t , x 0 , ϵ ∥ ϵ ⏟ 真实噪声 − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ ⏟ x t , t ) ⏟ 模型预测的噪声 ∥ 2 \mathcal{L} = \mathbb{E}_{t, x_0, \epsilon} \\\| \\underbrace{\\epsilon}_{\\text{真实噪声}} - \\underbrace{\\epsilon_\\theta(\\underbrace{\\sqrt{\\bar{\\alpha}_t}x_0 + \\sqrt{1-\\bar{\\alpha}_t}\\epsilon}_{x_t}, t)}_{\\text{模型预测的噪声}} \\\|\^2 L=Et,x0,ϵ∥真实噪声 ϵ−模型预测的噪声 ϵθ(xt αˉt x0+1−αˉt ϵ,t)∥2
α ˉ t x 0 + 1 − α ˉ t ϵ \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon αˉt x0+1−αˉt ϵ ------ 输入 x t x_t xt
这是**重参数化技巧(Reparameterization Trick)**的体现。
在扩散模型中,从 x 0 x_0 x0 到 x t x_t xt 的转移分布是 q ( x t ∣ x 0 ) = N ( α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_t|x_0) = \mathcal{N}(\sqrt{\bar{\alpha}_t}x_0, (1-\bar{\alpha}_t)I) q(xt∣x0)=N(αˉt x0,(1−αˉt)I)。
如果我们直接采样 x t x_t xt,我们需要从正态分布里采样,这会导致梯度无法回传(因为采样过程不可导)。
为了能让梯度从 Loss 传回模型,我们直接把 x t x_t xt 表示 为 x 0 x_0 x0 和 ϵ \epsilon ϵ 的线性组合:
α ˉ t x 0 \sqrt{\bar{\alpha}_t}x_0 αˉt x0:保留下来的信号部分。
1 − α ˉ t ϵ \sqrt{1-\bar{\alpha}_t}\epsilon 1−αˉt ϵ:添加进去的噪声部分。
这样, x t x_t xt 就变成了一个确定性计算(只要有 x 0 x_0 x0 和 ϵ \epsilon ϵ 就能算出来),从而允许反向传播。