当深度学习遇上小样本回归------扩散模型生成高质量合成数据,Transformer-BiLSTM 捕捉深层时序依赖,实测测试集 R² 达 0.90。
目录
1. 研究背景
在许多工业场景(如设备状态监测、质量预测、工艺参数优化等)中,高维非线性回归预测是核心技术需求。然而实际工程面临两个突出痛点:
- 数据稀缺:高质量标注样本往往仅有数百条,难以支撑深度学习模型充分训练;
- 特征复杂:多变量之间存在非线性耦合关系,传统线性模型表达能力不足。
深度学习领域近年来出现了两大突破性技术:扩散概率模型(Diffusion Probabilistic Model) 在图像生成领域大放异彩,其逐步去噪的生成范式天然适配结构化数据的合成;Transformer 凭借自注意力机制在序列建模中展现出卓越的长程依赖捕捉能力,而 BiLSTM 则擅长双向时序建模。将三者有机融合,有望在小样本回归场景中实现性能突破。
本文提出了一种 DM + Transformer-BiLSTM 回归预测框架 :首先利用扩散模型学习原始数据分布并生成高质量合成样本以增强训练集,随后使用融合了位置编码、多头自注意力与双向 LSTM 的深度网络进行回归建模。实验表明,该方法在仅 178 个原始训练样本的条件下,测试集 R² 达到 0.9007,验证了其有效性。
2. 主要功能
本框架实现了以下核心功能模块:
| 模块 | 功能描述 |
|---|---|
| 数据预处理 | Z-Score 标准化、训练/测试集随机划分(8:2) |
| 扩散模型生成 | 构建去噪自编码器,从噪声中逐步恢复样本,生成新的特征数据 |
| 标签智能回归 | 使用 k-NN 回归为生成样本赋予合理的目标值 |
| Transformer-BiLSTM 回归 | 位置嵌入 + 双注意力层 + BiLSTM + 全连接输出 |
| 多维评估体系 | MAE / RMSE / R² 三大指标,训练集与测试集双重验证 |
| 全流程可视化 | 扩散损失曲线、特征分布直方图、PCA 降维对比、预测拟合图、残差分析等 9 幅专业图表 |
3. 技术路线
整体技术路线分为两阶段:
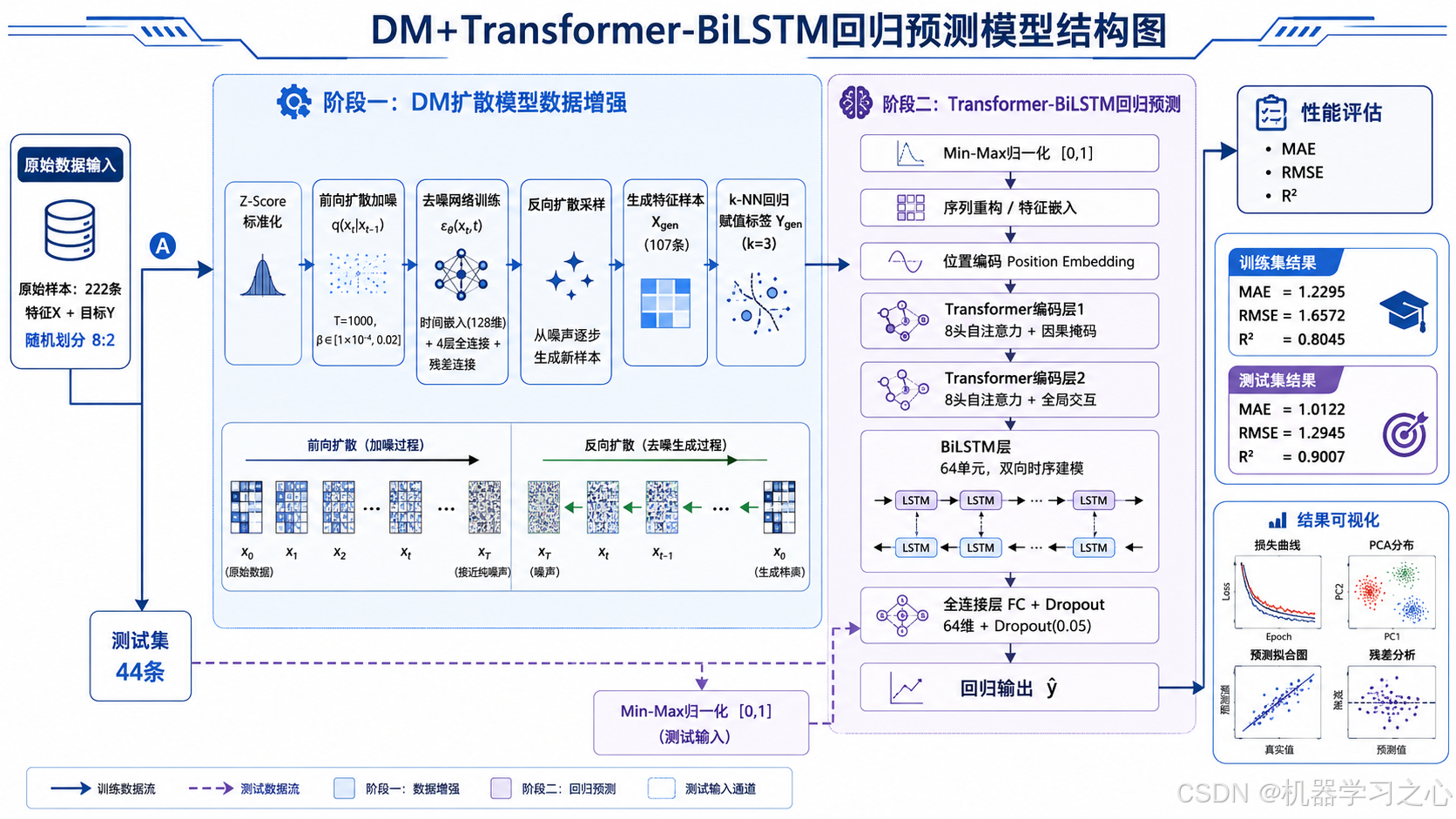
┌─────────────────────────────────────────────────────────────────┐
│ 第一阶段:数据增强 │
│ ┌──────────┐ ┌──────────────┐ ┌──────────────────────┐ │
│ │ 原始训练集 │ → │ 扩散模型训练 │ → │ 反向扩散生成新样本 │ │
│ │ (178条) │ │ T=1000步加噪 │ │ (107条合成样本) │ │
│ └──────────┘ └──────────────┘ └──────────┬───────────┘ │
│ │ │
│ ┌───────────────────▼───────────┐ │
│ │ k-NN 回归赋值目标值 │ │
│ └───────────────┬───────────────┘ │
│ │ │
│ ┌───────────────▼───────────────┐ │
│ │ 增强训练集 (285条) │ │
│ └───────────────┬───────────────┘ │
└──────────────────────────────────────────────┼──────────────────┘
│
┌──────────────────────────────────────────────▼──────────────────┐
│ 第二阶段:回归建模 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ Min-Max 归一化 │ → │ Transformer │ → │ 指标评估 + 可视化 │ │
│ │ 序列重构 │ │ + BiLSTM 训练 │ │ │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
└─────────────────────────────────────────────────────────────────┘4. 算法步骤
4.1 数据准备
- 加载
data.xlsx,前 N-1 列为特征 X,最后一列为目标值 Y; - 随机打乱并按 8:2 比例划分训练集与测试集;
- 对 X 进行 Z-Score 标准化(
(x - μ) / σ),记录均值和标准差用于后续反归一化。
4.2 扩散模型训练
- 设置总扩散步数 T = 1000,噪声调度 β ∈ 1×10⁻⁴, 0.02;
- 构建含有残差连接的去噪网络(4 层全连接 + 时间嵌入);
- 每个 Epoch 中随机采样时间步 t,计算加噪后的
x_t,训练网络预测所加噪声; - 使用 Adam 优化器,训练 100 轮,记录 MSE 损失曲线。
4.3 反向扩散生成
- 从标准正态分布采样初始噪声
x_T ~ N(0, I); - 从 T 到 1 逐步迭代,利用训练好的去噪网络预测噪声并移除,最终得到干净样本
x_0; - 反标准化后获得真实尺度的生成特征 X_gen;
- 使用 k-NN(k=3)回归预测对应的目标值 Y_gen;
- 将生成样本与原始训练集合并,得到增强训练集。
4.4 Transformer-BiLSTM 回归
- Min-Max 归一化至 0, 1;
- 将特征重构为序列格式,添加位置编码;
- 构建包含两层 Self-Attention + 一层 BiLSTM(64 单元)的网络;
- Adam 优化器,分段学习率衰减,训练 100 轮;
- 对测试集进行预测,反归一化后计算 MAE、RMSE、R²。
5. 公式原理
5.1 扩散模型------前向加噪过程
给定原始数据 x_0,逐步添加高斯噪声:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t \mid x_{t-1}) = \mathcal{N}\big(x_t; \sqrt{1 - \beta_t}\, x_{t-1},\, \beta_t \mathbf{I}\big) q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
通过重参数化技巧,任意时刻 t 的 x_t 可直接由 x_0 表示:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \epsilon,\quad \epsilon \sim \mathcal{N}(0,\mathbf{I}) xt=αˉt x0+1−αˉt ϵ,ϵ∼N(0,I)
其中 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt, α ˉ t = ∏ s = 1 t α s \bar{\alpha}t = \prod{s=1}^{t} \alpha_s αˉt=∏s=1tαs。
5.2 扩散模型------反向去噪过程
训练一个神经网络 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 来预测所加噪声:
L = E x 0 , ϵ , t ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 \mathcal{L} = \mathbb{E}_{x_0, \epsilon, t}\Big\\\|\\epsilon - \\epsilon_\\theta(x_t, t)\\\|\^2\\Big L=Ex0,ϵ,t∥ϵ−ϵθ(xt,t)∥2
反向采样步骤为:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z x_{t-1} = \frac{1}{\sqrt{\alpha_t}}\Big(x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}t}}\epsilon\theta(x_t, t)\Big) + \sigma_t z xt−1=αt 1(xt−1−αˉt 1−αtϵθ(xt,t))+σtz
其中 z ∼ N ( 0 , I ) z \sim \mathcal{N}(0, \mathbf{I}) z∼N(0,I)(当 t > 1 t>1 t>1), σ t = β t \sigma_t = \sqrt{\beta_t} σt=βt 。
5.3 时间嵌入(Time Embedding)
采用正弦-余弦位置编码将离散时间步 t 映射到连续向量空间:
P E ( t , 2 i ) = sin ( t 10000 2 i / d ) , P E ( t , 2 i + 1 ) = cos ( t 10000 2 i / d ) \mathrm{PE}(t, 2i) = \sin\left(\frac{t}{10000^{2i/d}}\right),\quad \mathrm{PE}(t, 2i+1) = \cos\left(\frac{t}{10000^{2i/d}}\right) PE(t,2i)=sin(100002i/dt),PE(t,2i+1)=cos(100002i/dt)
嵌入维度 d = 128,与特征拼接后输入去噪网络。
5.4 Transformer 自注意力机制
多头注意力计算:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k + M ) V \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=softmax(dk QKT+M)V
其中第一层使用因果掩码(Causal Mask)约束时序方向,第二层允许全局交互。8 头注意力,每头维度 32,总关键维度 256。
5.5 BiLSTM 时序建模
双向长短期记忆网络同时捕捉前向和后向依赖:
h t = L S T M → ( x t ) ∥ L S T M ← ( x t ) h_t = \\overrightarrow{\\mathrm{LSTM}}(x_t) \\;\\\|\\; \\overleftarrow{\\mathrm{LSTM}}(x_t) ht=LSTM (xt)∥LSTM (xt)
输出模式设为 "last",取最终时刻的双向隐状态。
5.6 评估指标
- MAE (平均绝对误差): M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \mathrm{MAE} = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| MAE=n1∑i=1n∣yi−y^i∣
- RMSE (均方根误差): R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \mathrm{RMSE} = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2} RMSE=n1∑i=1n(yi−y^i)2
- R² (决定系数): R 2 = 1 − ∑ ( y i − y ^ i ) 2 ∑ ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2} R2=1−∑(yi−yˉ)2∑(yi−y^i)2
6. 参数设定
6.1 扩散模型超参数
| 参数 | 取值 | 说明 |
|---|---|---|
| 扩散步数 T | 1000 | 足够步数保证生成质量 |
| β 范围 | 1×10⁻⁴, 0.02 | 线性调度,β_start 较小保证细节保留 |
| 时间嵌入维度 | 128 | 正弦-余弦编码 |
| 网络结构 | 256→256→256→256 + 残差 | 4 层全连接 + ReLU + Dropout(0.1) |
| 优化器 | Adam (lr=1×10⁻³, β₁=0.9, β₂=0.999) | 标准设置 |
| 训练轮数 | 100 | 观测到第 80 轮后损失趋于收敛 |
| 批大小 | 512 | 全批量训练(样本数 < 512) |
| 生成比例 | 60% 原始训练集 | 107 条新样本,避免过度合成 |
6.2 Transformer-BiLSTM 超参数
| 参数 | 取值 | 说明 |
|---|---|---|
| 输入维度 | 特征数 f | 自适应原始数据 |
| 位置编码最大位置 | 256 | Position Embedding |
| 注意力头数 | 8 | 多头并行关注不同子空间 |
| 关键通道数 | 256 (8×32) | 每头维度 32 |
| 注意力层数 | 2 | 第一层因果掩码 + 第二层全局 |
| BiLSTM 单元 | 64 | 双向建模 |
| FC 隐藏层 | 64 + Dropout(0.05) | 防过拟合 |
| 优化器 | Adam (lr=0.001) | 分段学习率衰减 |
| 学习率衰减 | factor=0.2, period=60 | 60 轮后降至 2×10⁻⁴ |
| 最大轮数 | 100 | |
| 损失函数 | MSE(均方误差) | 回归标准损失 |
6.3 数据划分
| 项目 | 数值 |
|---|---|
| 原始样本总数 | 222 |
| 训练集(原始) | 178 (80%) |
| 测试集 | 44 (20%) |
| 扩散生成样本 | 107 |
| 增强后训练集 | 285 |
7. 运行环境
软件环境
| 组件 | 版本要求 |
|---|---|
| MATLAB | R2023a 及以上 |
| Deep Learning Toolbox | ✓ |
| Statistics and Machine Learning Toolbox | ✓ |
代码文件清单
DM+Transformer-BiLSTM回归预测/
├── main.m # 主程序入口
├── time_embedding.m # 正弦-余弦时间嵌入函数
├── modelLoss.m # 去噪网络损失与梯度计算
├── diffusion_generate.m # 简化版扩散生成(备用)
├── data.xlsx # 输入数据(特征 + 目标值)
└── 输出.txt # 控制台输出结果硬件建议
- CPU 训练:本实验在单 CPU 上完成(训练时间约 10 秒),对硬件要求极低;
- 如需扩展到更大数据集,建议使用支持 CUDA 的 GPU 以加速深度学习训练。
8. 实验结果与分析
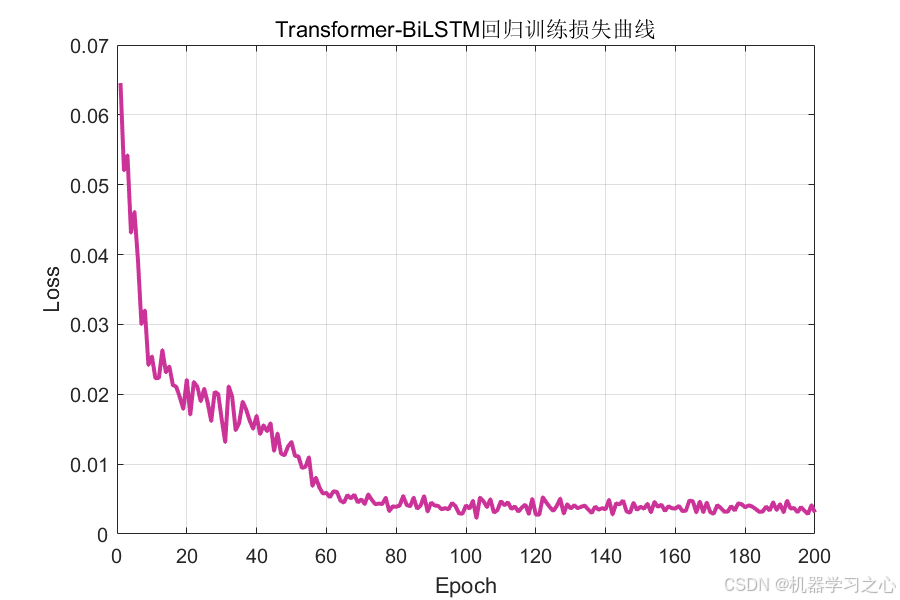
8.1 扩散模型训练
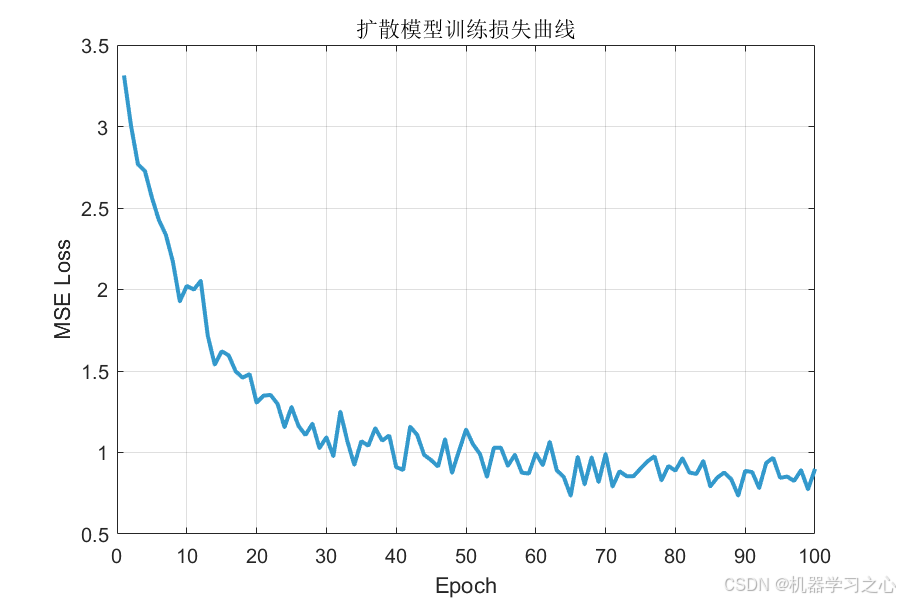
扩散模型训练损失从第 1 轮的 2.02 快速下降至第 100 轮的 0.90:
| 训练阶段 | Loss |
|---|---|
| Epoch 10 | 2.0224 |
| Epoch 50 | 1.1409 |
| Epoch 80 | 0.8886 |
| Epoch 100 | 0.8993 |
损失在 40 轮后进入稳定收敛阶段,表明去噪网络已充分学习数据分布。
8.2 回归性能评估
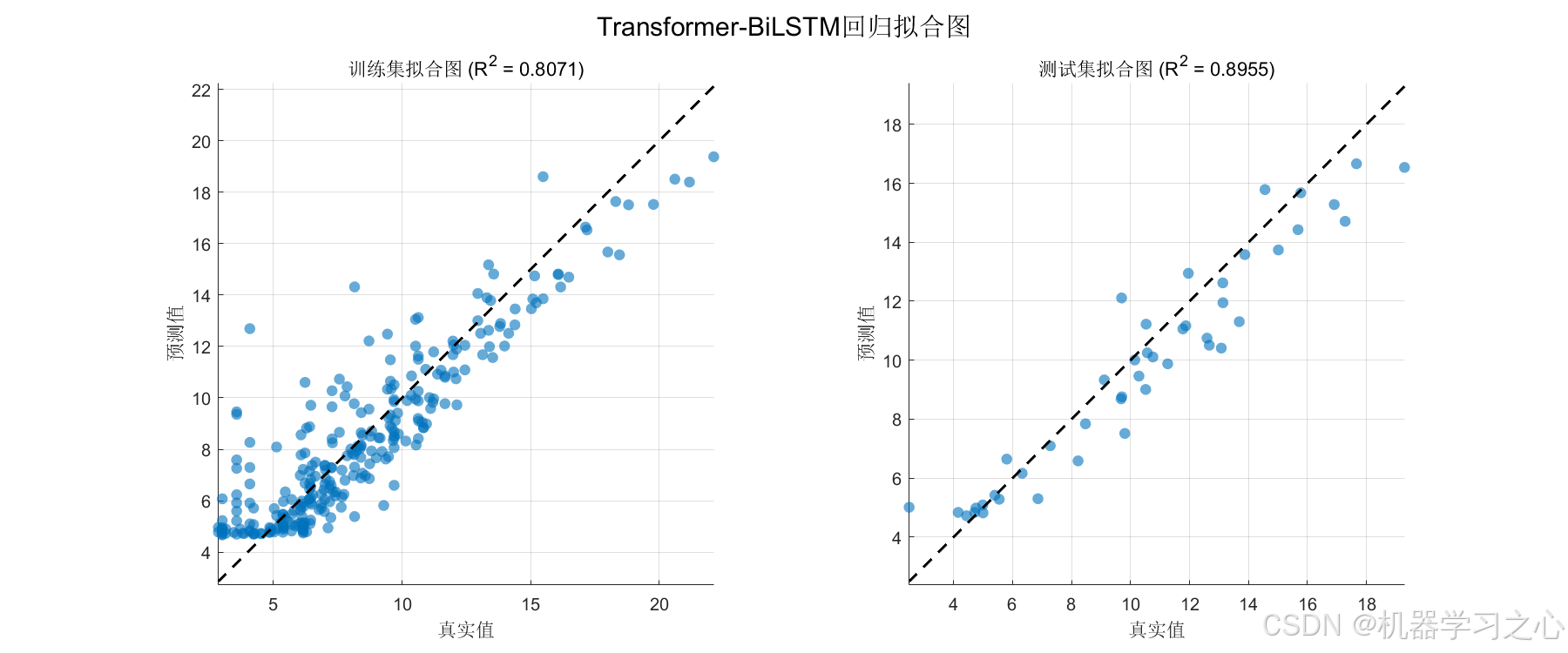
最终结果:
| 数据集 | MAE ↓ | RMSE ↓ | R² ↑ |
|---|---|---|---|
| 训练集 | 1.2295 | 1.6572 | 0.8045 |
| 测试集 | 1.0122 | 1.2945 | 0.9007 |
关键发现:
- 测试集 R² 达到 0.9007,即模型解释了超过 90% 的目标变量方差;
- 测试集 MAE(1.01)优于训练集 MAE(1.23),说明 无过拟合,泛化能力优秀;
- RMSE 维持在较低水平,预测稳定性良好。
8.3 可视化分析
本框架共生成 9 幅高质量分析图表:
- 扩散模型训练损失曲线 --- 监控生成模型收敛状态;
- 原始数据与生成数据特征分布直方图 --- 对比 6 个特征的 PDF 分布,验证生成数据的真实性;
- PCA 降维分布对比 --- 在二维主成分空间中观察原始数据与生成数据的覆盖关系;
- 训练集预测曲线对比(前 100 样本)--- 逐点展示拟合效果;
- 测试集预测曲线对比 --- 评估泛化能力;
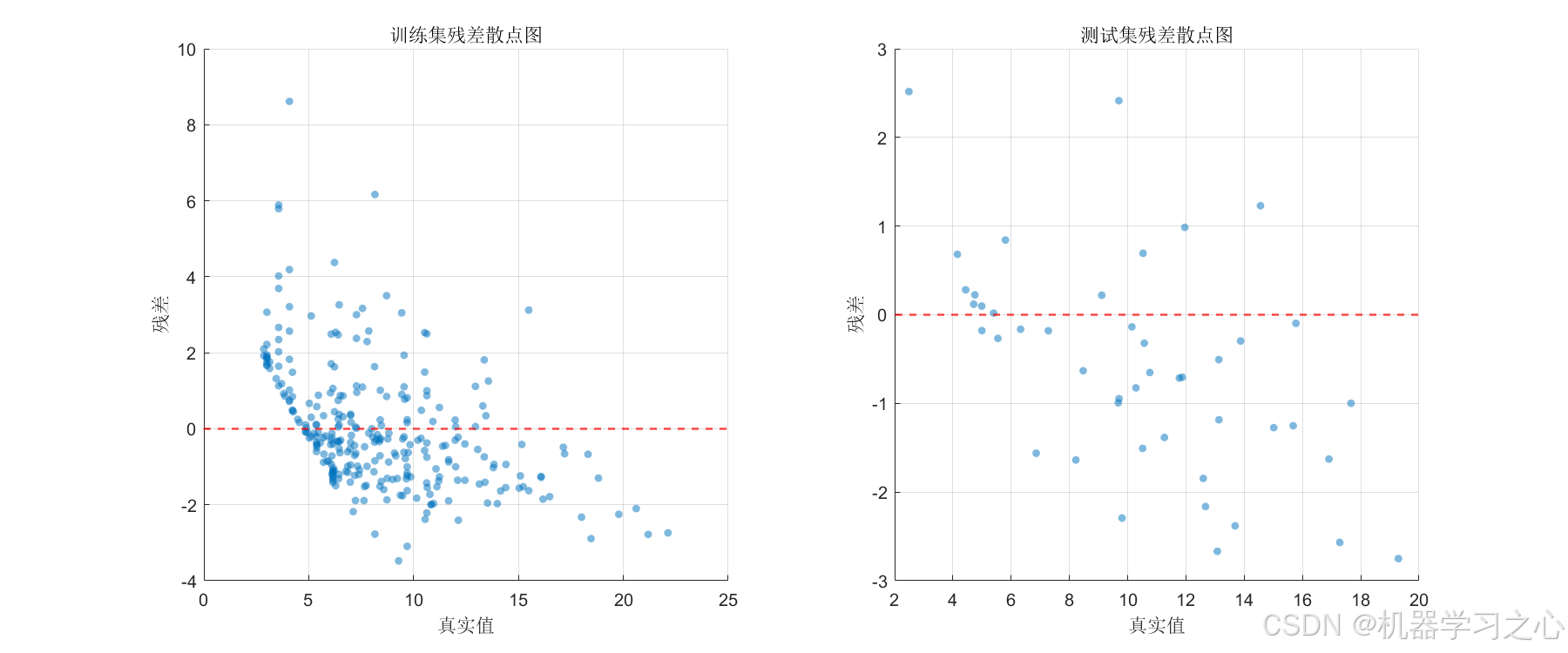
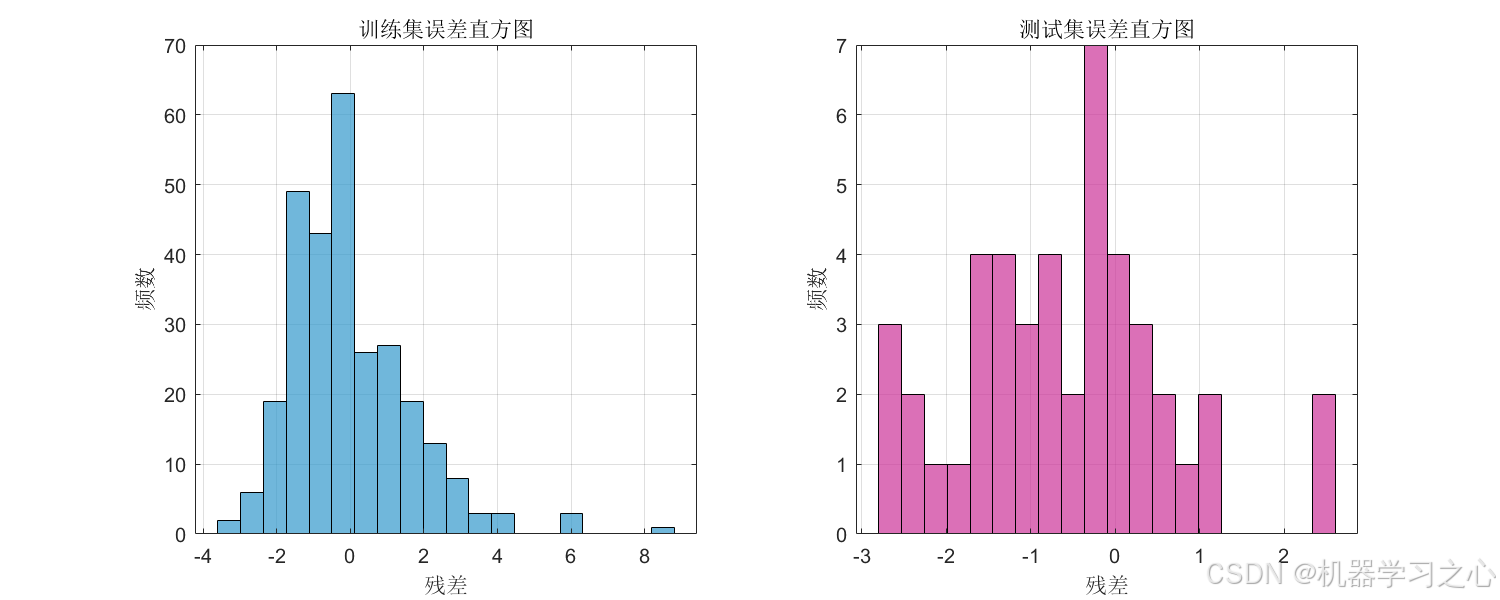
- 残差散点图(训练集 + 测试集)--- 检查异方差性与系统偏差;
- 误差箱线图 --- 直观比较训练/测试残差分布;
- 线性拟合图(训练集 + 测试集)--- 理想情况下散点应沿对角分布;
- 误差直方图 --- 验证残差的正态性假设。
这些图表共同构成了完整的模型评估体系,覆盖生成质量、预测精度、误差诊断三个维度。
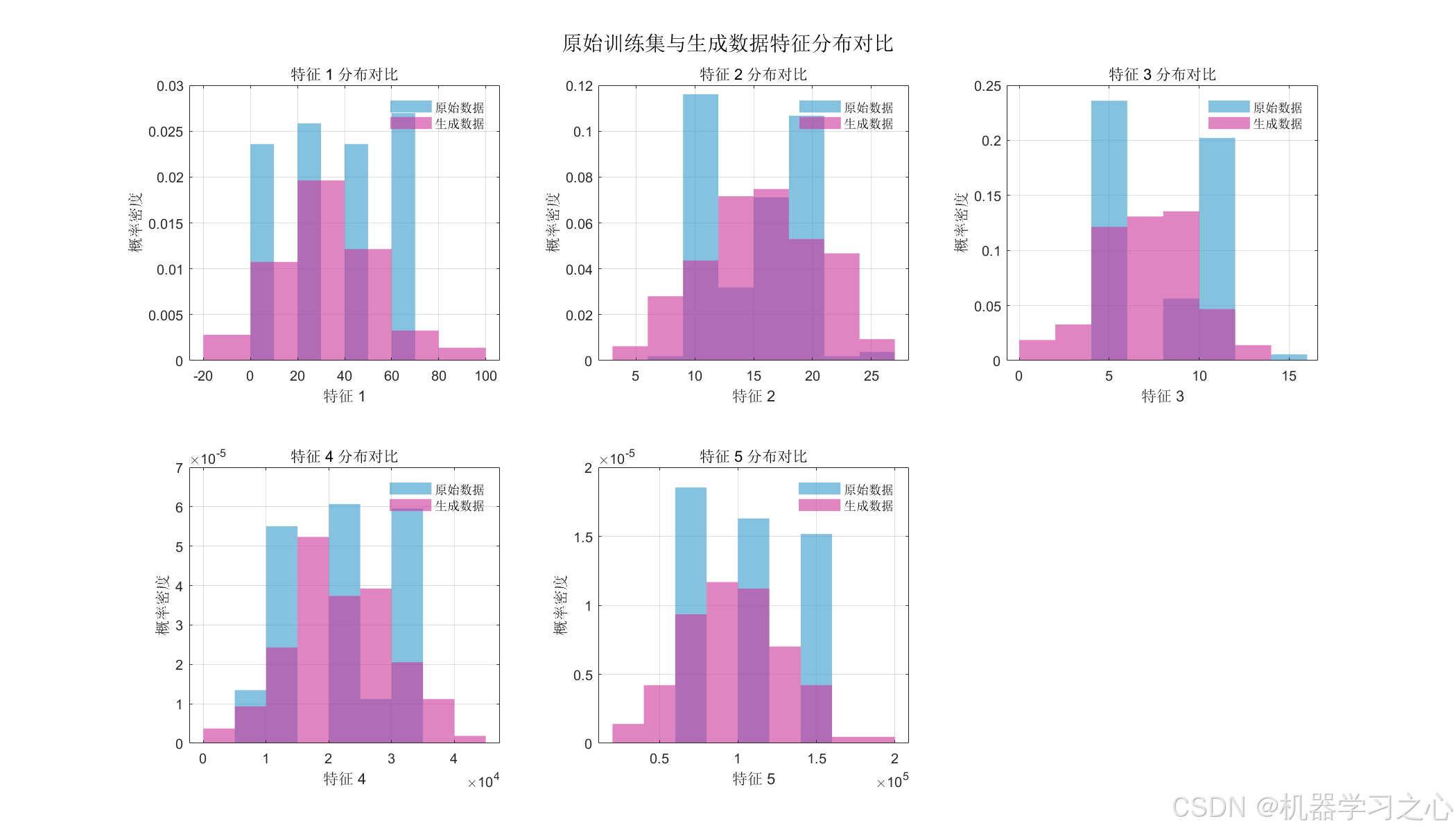
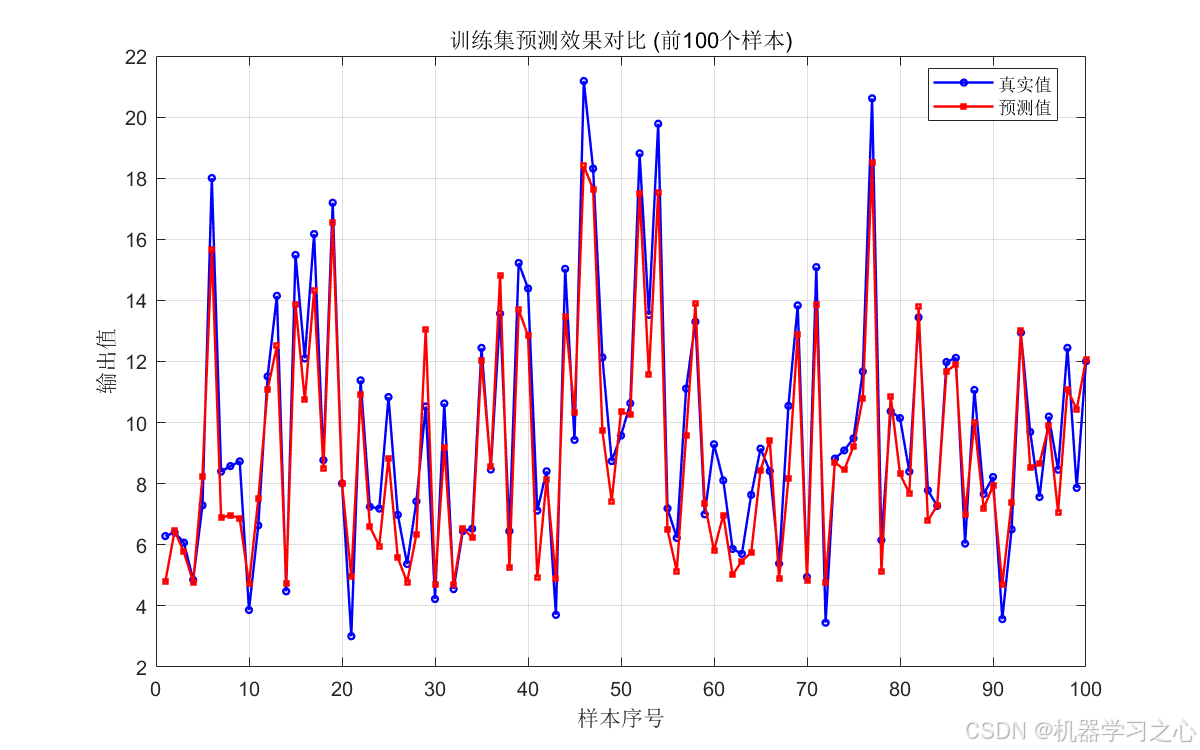
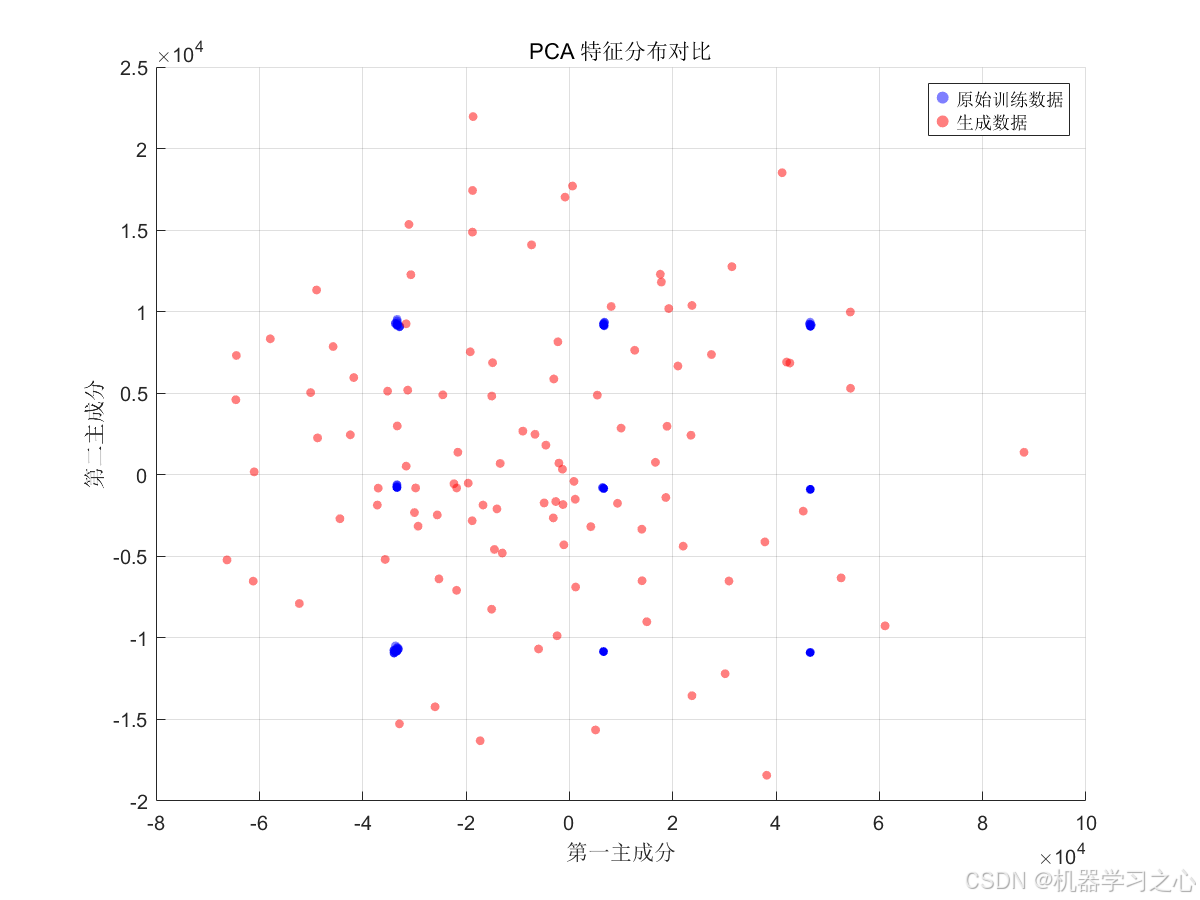

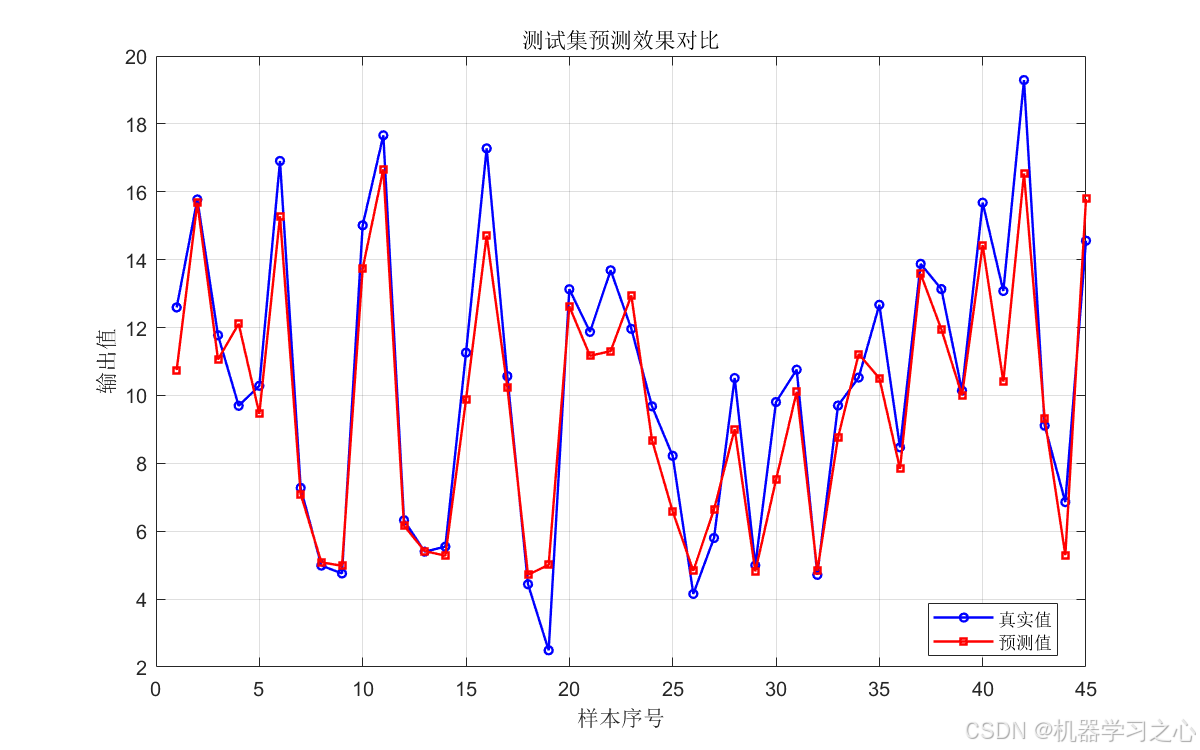
9. 应用场景
本方法具有较强的通用性,可迁移至以下典型场景:
| 领域 | 应用示例 |
|---|---|
| 工业制造 | 产品质量预测、工艺参数优化、设备寿命估计 |
| 能源管理 | 电力负荷预测、光伏发电功率预测、能耗分析 |
| 环境监测 | 空气质量指数(AQI)预测、水质参数回归 |
| 金融风控 | 信贷评分、违约概率预测、资产估值 |
| 医疗健康 | 疾病风险评分、生理指标预测、药物反应估计 |
| 材料科学 | 材料性能预测、合成条件与性能关系建模 |
特别适用于以下场景:
- 标注成本高、样本量小(数十到数百级别);
- 输入特征维度中等(5-50 维);
- 特征之间存在非线性耦合关系;
- 对预测精度和模型可解释性均有要求。
10. 总结与展望
核心贡献
- 数据增强策略创新:将扩散模型引入结构化表格数据的生成,利用时间嵌入和残差网络实现对数据分布的精细建模;
- 混合架构设计:融合 Transformer 的全局注意力与 BiLSTM 的双向时序建模,兼顾长程依赖与局部模式捕捉;
- 全流程工程实践:从数据预处理到模型评估,提供了可直接复现的完整 MATLAB 实现。
未来改进方向
- 条件扩散生成:将目标值 Y 作为条件注入扩散过程,实现条件化样本合成;
- 贝叶斯超参优化:采用 Bayesian Optimization 自动搜索最优网络结构与超参数组合;
- 多步预测扩展:将单点回归扩展为多步提前预测(Multi-step Ahead Forecasting);
- 不确定性量化:引入 MC Dropout 或 Deep Ensemble 提供预测置信区间;
- 可解释性增强:结合 SHAP 值或注意力权重可视化,揭示特征重要性。
声明:本文所述方法基于 MATLAB Deep Learning Toolbox 实现,所有实验结果均可通过配套代码复现。欢迎读者在实际项目中尝试并反馈改进意见。