CEPH分布式存储应用实践------分布式存储简介与CEPH分布式存储![]() https://blog.csdn.net/xiaochenXIHUA/article/details/162394922
https://blog.csdn.net/xiaochenXIHUA/article/details/162394922
一、Ceph其他组件与概念
1.1、Pool
Pool是存储对象的逻辑分区(或者叫存储池)它规定了数据冗余的类型和对应的副本分布策略,默认存储3份副本;支持两种类型:【副本(replicated)】和 【纠删码( Erasure Code)】。
| 存储池的两种类型 | 说明 |
|---|---|
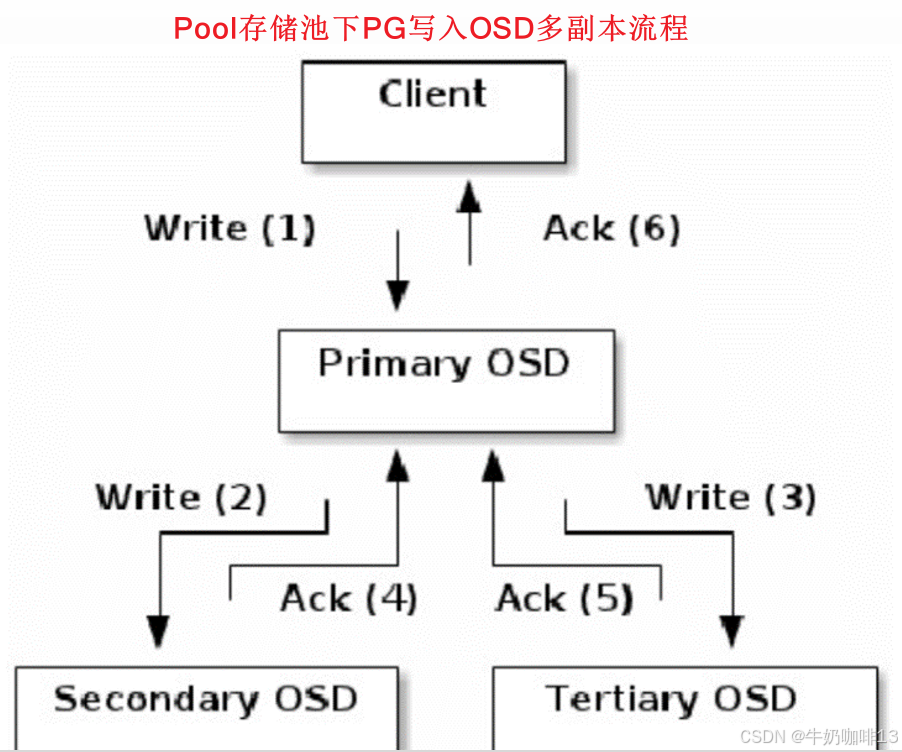
| Replicated pool(默认) | 副本池,默认的存储池类型,把每个存入的对象(Object)存储为多个副本,其中分为主副本和从副本,从副本相当于备份副本,从而确保在部分 OSD 丢失的情况下数据不丢失。 这种类型的 pool 需要更多的裸存储空间,但是它支持所有的 pool 操作。 如果客户端在上传对象的时候不指定副本数,默认为3个副本。在开始存数据之前会计算出该对象存储的主副本与从副本的位置,首先会将数据存入到主副本,然后主副本再将数据分别同步到从副本。主副本与从副本同步完毕后会通知主副本,这时候主副本再响应客户端,并表示数据上传成功。所以如果客户端收到存储成功的请求后,说明数据已经完成了所有副本的存储。 |
| Erasure-coded pool | 纠删码池,此类型会将数据存储为K+M(其中K是数据块数量,每个对象存储到Ceph集群的时候会分成多个数据块分开进行存储。而M为最多容忍可坏的数据块数量,类似于磁盘阵列RAID5,在最大化利用空间的同时,还能保证数据丢失可恢复性,相比副本池更节约磁盘的空间)。 因为副本池很浪费存储空间,如果Ceph集群总容量为100T,如果使用副本池,那么实际可用空间按3个副本算,那么只有30T出头。 而使用纠删码池就可以更大化的利用空间,但纠删码池更浪费计算资源(如:存储一个100M的资源,若使用副本池,按3副本计算实际上要使用300M的空间。而使用纠删码池,如果将100M资源分为25块,如果将M指定为2,那么总共只需要108M空间即可,计算公式为100+100/25*2)。 注意:如果存储RBD镜像,那么不支持纠删码池。关于此类型存储池使用不多,不做过多介绍。 |
1.2、PG与PG temp
PG(全称:Placement Group,又叫归置组),可以将PG看做一个逻辑容器,这个容器包含多个对象,同时这个逻辑对象映射多个OSD上。如果没有PG,在成千上万个OSD上管理和跟踪数百万计的对象的复制和传播是相当困难的。没有PG这一层,管理海量的对象所消耗的计算资源也是不可想象的。
PG的作用:PG相当于一个虚拟组件,出于集群伸缩,性能方面的考虑(Ceph将每个存储池分为多个PG,如果存储池为副本池类型,并会给该存储池每个PG分配一个主OSD和多个从OSD,当数据量大的时候,PG将均衡的分布在集群中的每个OSD上面)【OSD(object storage device)是负责存储文件的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。**主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等;**在Ceph集群中所有的文件都会以对象的形式存储到OSD中。OSD与OSD之间是可以相互通信的】。
PG temp :一个PG组里有三个组员(OSD),三个组员第一个是组长,组长负责对外提供服务,组员负责备份,一旦组长挂掉后,相当于公司中一个部门的项目经理辞职了,公司会招聘一个新的项目经理,但新的项目经理刚来的时候还什么都不知道(即新加进来的osd是没有任何组内数据的),此时公司会让某个组员先临时接替一下组长的职务、对外提供服务,一旦新来的组长了解了业务(即新加进来的osd已经同步好数据了),那么就可以让新组长出山了。
1.3、PGP
PGP(Placement Groups of Placement)是为了实现定位而设置的PG,是存储池PG中OSD分布组合个数,它的值应该和PG的总数(即pg_num)保持一致。对于Ceph的一个pool而言,如果增加pg_num,还应该调整pgp_num为同样的值。这样集群才可以开始再平衡。
1.4、Object
Object(存储对象)是最底层的存储单元,包含元数据和原始数据。
1.5、Pool、PG、 Object、OSD之间的关系
| LVM逻辑卷对应Ceph | Pool、PG、Object、OSD之间的关系类比LVM逻辑卷 |
|---|---|
| pv------>osd | 把一系列的盘都做好标记,由LVM管理起来 |
| vg------>pool | 是把一系列的pv给归类到一起,相当于一块大磁盘 |
| lv------>image | 相当于从vg这个"大磁盘"中分出的一个"分区" |
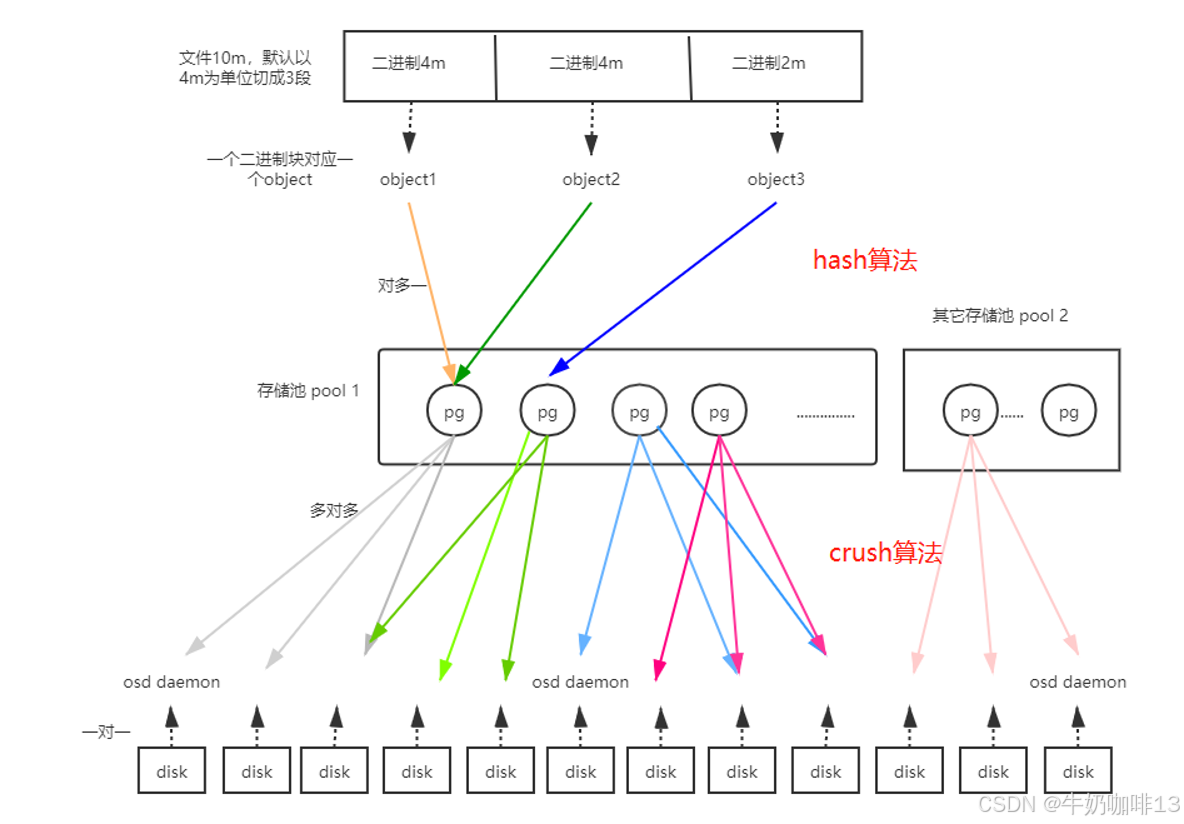
如上图所示:
- Object与PG是多对一关系;
- PG与OSD daemon是多对多关系;
- OSD daemon与Disk是一对一关系;
- Pool是PG对象的逻辑集合,pool中的副本数若设置为3,则一个pg中包含3个osd(即同一个PG接收到的所有object将在这3个osd上被复制)。
- 一个OSD上的PG则可达到数百个。PG数量的设置牵扯到数据分布的均匀性问题。PG 和 OSD 之间的映射关系由 CRUSH 决定,而它做决定的依据是 CRUSH 规则(rules)。
- 对象的副本数目,也就是被拷贝的次数,是在创建 Pool 时指定的。该份数决定了每个PG会在几个OSD上保存对象。如果一个拷贝型Pool的size(拷贝份数)为 2,它会包含指定数目的PG,每个PG使用两个 OSD,其中,第一个为主OSD (primary),其它的为从 OSD(secondary)。不同的 PG 可能会共享一个 OSD。
- PG 是Ceph集群做清理(scrubbing)的基本单位,也就是说数据清理是一个一个PG来做的。
1.6、PG数目的确定
创建 pool 时需要确定其 PG 的数目,在 pool 被创建后也可以调整该数字,但是增加池中的PG数是影响ceph集群的重大事件之一,生成环境中应该避免这么做,因为pool中pg的数目会影响到数据的均匀分布性。
每个 OSD 上的PG数目不宜过大,否则,会降低数据的持久性,可以肯定的一点是osd数越多,存储池中包含的pg的数目也应对应增加,这样每个osd上的pg数才会尽量均匀、不会过大。那如何确定一个Pool中有多少 PG?Ceph不会自己计算,而是给出了一些参考原则,让Ceph用户自己计算:
| 单OSD的PG副本数推荐阈值 |
|---|
| 单Pool基准PG数 = (集群OSD总数 × 100) / pool_size * pool_size:副本池 = 副本数(size=3 则填 3);纠删码池 = K+M 之和(如 4+2=6); * 计算结果向上取最近 2 的幂(64/128/256/512/1024/2048/4096/8192/...),CRUSH 哈希效率最优Ceph; |
| 单Pool建议PG = (单OSD目标PG副本数 × OSD总数 × 该池数据占比) / pool_size 1. 单 OSD 目标 PG 副本:集群不扩容选 100;未来扩容一倍选 200; 2. % Data:该池存储数据占集群总数据比例(多 RGW / 多业务池必须分摊); * 少于 5 个 OSD daemon, 建议将pool中的pg数设为 128; * 5 到 10 个 OSD daemon,建议将pool中的pg数设为 512; * 10 到 50 个 OSD daemon,建议将pool中的pg数设为 4096; |
PG 设置正反影响: 1. PG 过少:数据分布不均、热点 OSD、IO 并发差、故障恢复粒度大; 2. PG 过多:OSD 内存 / CPU 暴涨、Peering/Recovery 速度大幅下降、集群卡顿、触发mon_max_pg_per_osd告警; |
1.7、RBD、CephFS、Crush
RBD (全称RADOS block device)是Ceph对外提供的块设备服务;
CephFS (全称Ceph File System)是Ceph对外提供的分布式文件存储服务;
CRUSH 是Ceph底层使用的数据分布算法,让数据分配到预期的地方,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则(如:跨机房、机架感知等)同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点。
二、Ceph的资源划分与存储过程
2.1、Ceph的资源划分与存储过程原理
Ceph采用crush算法,在大规模集群下,实现数据的快速、准确存放,同时能够在硬件故障或扩展硬件设备时,做到尽可能小的数据迁移,其原理如下:
| Ceph的资源划分与存储过程原理 |
|---|
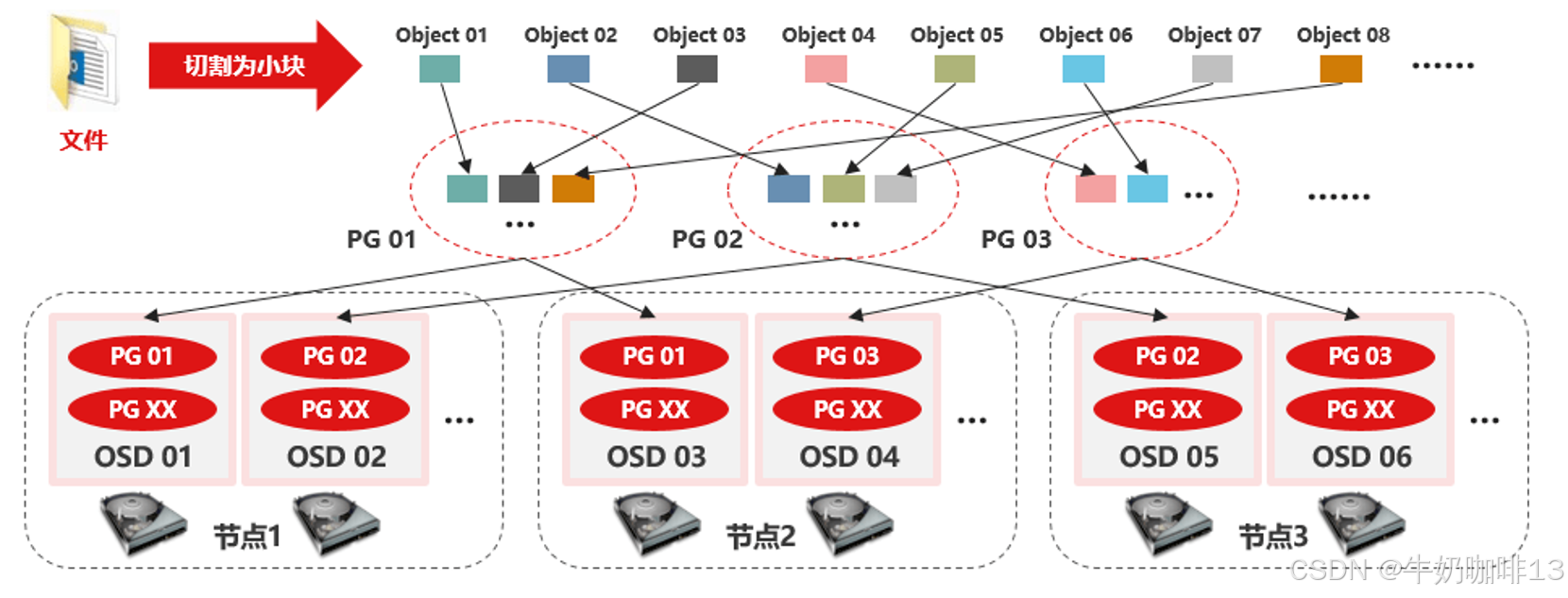
| 《1》当用户要将数据存储到Ceph集群时,数据先被分割成多个object,(每个object一个object id,大小可设置,默认是4MB),object是Ceph存储的最小存储单元。 |
| 《2》由于object的数量很多,为了有效减少了Object到OSD的索引表、降低元数据的复杂度,使得写入和读取更加灵活,引入了pg(Placement Group ):PG(归置组)用来管理object,每个object通过Hash,映射到某个pg中,一个pg可以包含多个object。 |
| 《3》Pg再通过CRUSH计算,映射到osd中。如果是三副本的,则每个pg都会映射到三个osd,保证了数据的冗余。 |
2.2、Ceph的数据写入流程
| Ceph的数据写入流程 |
|---|
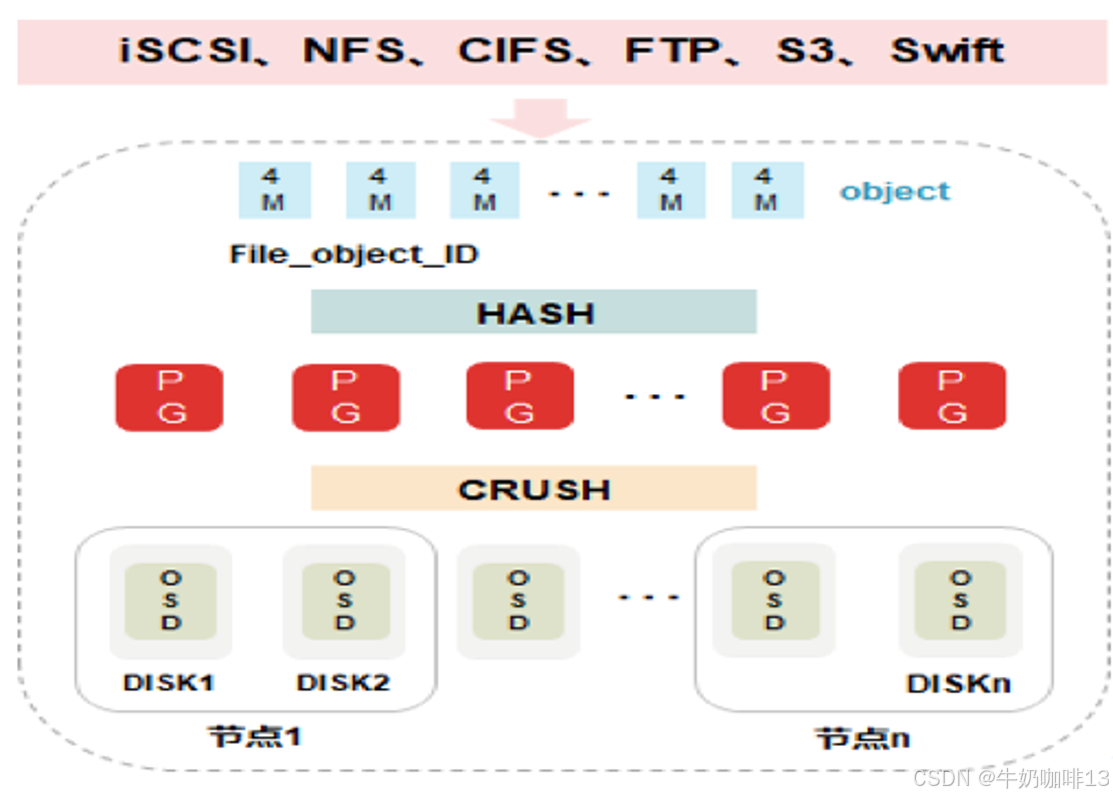
| 《1》数据通过负载均衡获得节点动态IP地址; |
| 《2》通过块、文件、对象协议将文件传输到节点上; |
| 《3》数据被分割成4M对象并取得对象ID; |
| 《4》对象ID通过HASH算法被分配到不同的PG; |
| 《5》不同的PG通过CRUSH算法被分配到不同的OSD。 |
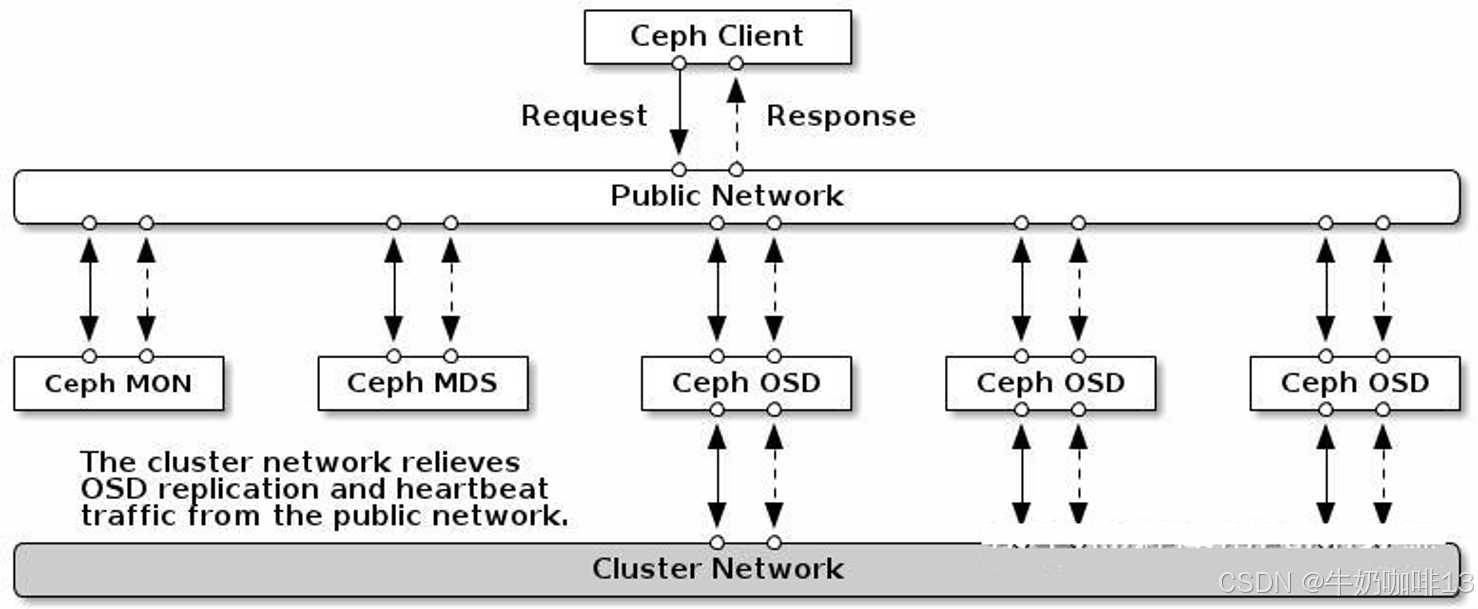
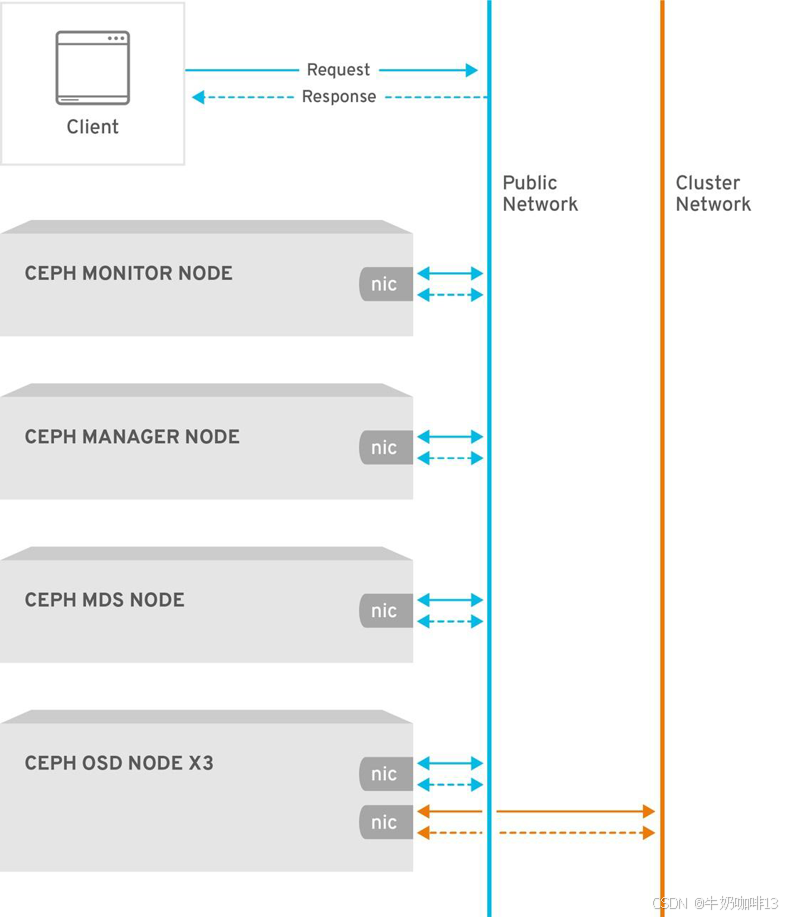
2.3、Ceph的网络
可以在 Ceph 配置文件的 global 部分配置两个网络:
- public network = {public-network/netmask}
- cluster network = {cluster-network/netmask}
public network是连接客户端通信的网络【网络带宽没有严格要求,一般千兆就够了】。cluster network是连接 Ceph 各存储节点集群内通信的网络【涉及各种数据的大量传输,需要很高的网络带宽,一般都需要万兆或者光纤】。