Redis7 核心数据结构
-
- [📋 知识体系总览](#📋 知识体系总览)
- [Redis7 数据结构全景](#Redis7 数据结构全景)
-
- [✅ Redis7 有哪些数据结构](#✅ Redis7 有哪些数据结构)
- [✅ 永远的神:help 命令](#✅ 永远的神:help 命令)
- 一、核心数据结构
-
- [✅1. String 字符串](#✅1. String 字符串)
- [✅2. Hash 哈希](#✅2. Hash 哈希)
-
- [Hash 常用操作](#Hash 常用操作)
- [String vs Hash 存储对象对比](#String vs Hash 存储对象对比)
- [Hash 应用场景](#Hash 应用场景)
- [Hash 结构优缺点](#Hash 结构优缺点)
- [✅3. List 列表](#✅3. List 列表)
-
- [List 常用操作](#List 常用操作)
- [List 应用场景](#List 应用场景)
- [List 注意事项](#List 注意事项)
- [✅4. Set 集合](#✅4. Set 集合)
-
- [Set 常用操作](#Set 常用操作)
- [Set 运算操作](#Set 运算操作)
- [Set 应用场景](#Set 应用场景)
- [✅5. ZSet 有序集合](#✅5. ZSet 有序集合)
-
- [ZSet 常用操作](#ZSet 常用操作)
- [ZSet 集合运算](#ZSet 集合运算)
- [ZSet 应用场景:排行榜](#ZSet 应用场景:排行榜)
- 二、扩展数据结构
-
- [✅6. Bitmap 位图](#✅6. Bitmap 位图)
-
- [Bitmap 常用操作](#Bitmap 常用操作)
- [Bitmap 应用场景:每日签到](#Bitmap 应用场景:每日签到)
- [✅7. HyperLogLog](#✅7. HyperLogLog)
-
- [HyperLogLog 常用操作](#HyperLogLog 常用操作)
- 使用示例
- [✅8. Geo 地理位置](#✅8. Geo 地理位置)
-
- [Geo 常用操作](#Geo 常用操作)
- [Geo 应用场景:附近商家推荐](#Geo 应用场景:附近商家推荐)
- 三、高级数据结构
-
- [✅9. Stream 消息流](#✅9. Stream 消息流)
-
- [Stream 常用操作](#Stream 常用操作)
- [Stream 消费者组操作](#Stream 消费者组操作)
- [四、SpringBoot 集成 Redis](#四、SpringBoot 集成 Redis)
-
- [✅10. Maven 依赖与配置](#✅10. Maven 依赖与配置)
- [✅11. RestTemplate 快速上手](#✅11. RestTemplate 快速上手)
- [✅12. RedisTemplate 解决中文乱码](#✅12. RedisTemplate 解决中文乱码)
- [📋 全文总结](#📋 全文总结)
-
- [✅1. 数据结构总览对比](#✅1. 数据结构总览对比)
- [✅2. 面试高频考点](#✅2. 面试高频考点)
- [✅3. 数据结构选择决策树](#✅3. 数据结构选择决策树)
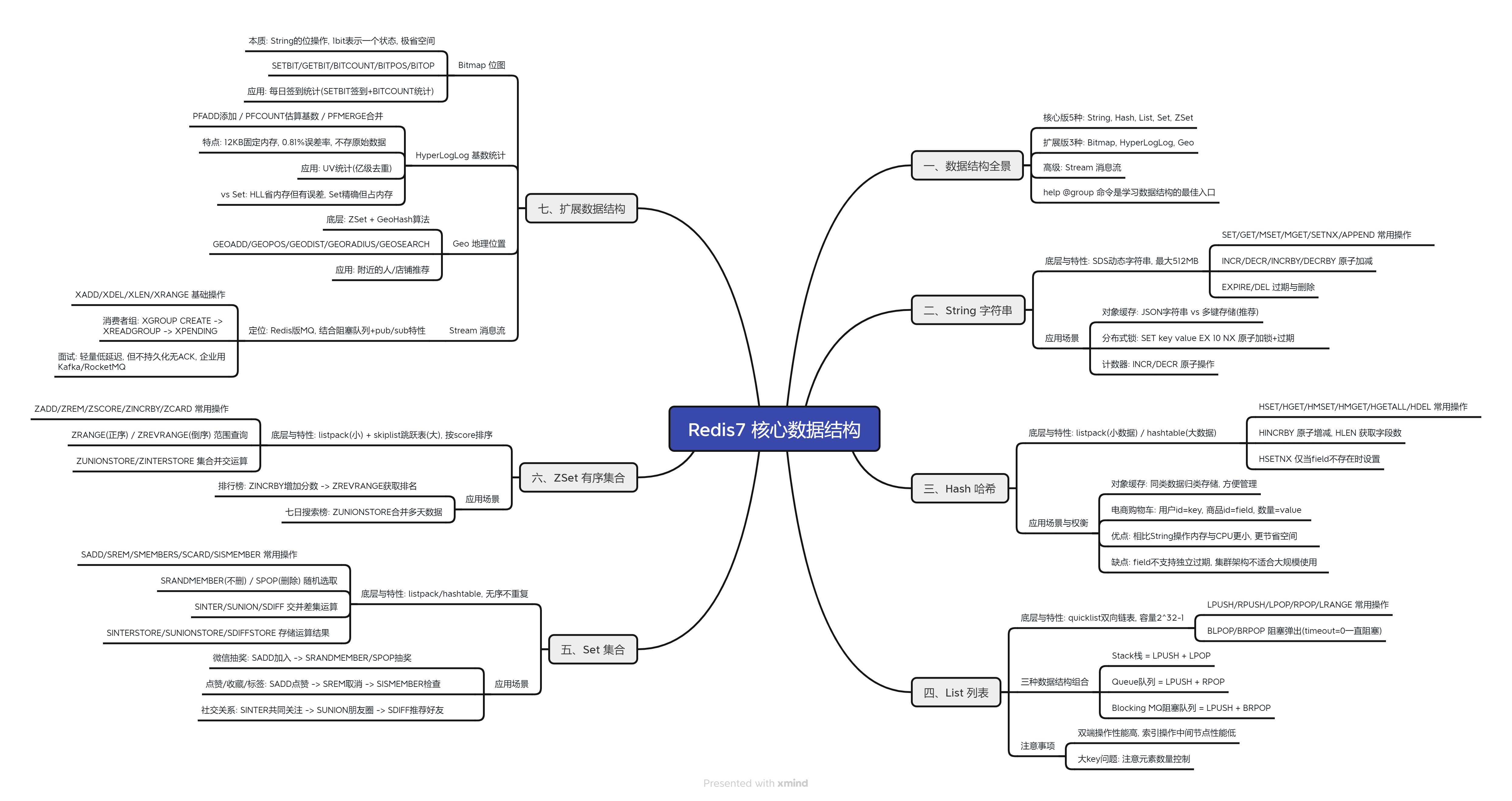
📋 知识体系总览
Redis7 核心数据结构
├── 数据结构全景
│ ├── ✅ 核心版 vs 扩展版
│ └── ✅ help 命令
├── 一、核心数据结构
│ ├── ✅1. String 字符串
│ ├── ✅2. Hash 哈希
│ ├── ✅3. List 列表
│ ├── ✅4. Set 集合
│ └── ✅5. ZSet 有序集合
├── 二、扩展数据结构
│ ├── ✅6. Bitmap 位图
│ ├── ✅7. HyperLogLog
│ └── ✅8. Geo 地理位置
├── 三、高级数据结构
│ └── ✅9. Stream 消息流
└── 四、SpringBoot 集成 Redis
├── ✅10. Maven 依赖与配置
├── ✅11. RestTemplate 快速上手
└── ✅12. RedisTemplate 中文乱码解决Redis7 数据结构全景
✅ Redis7 有哪些数据结构
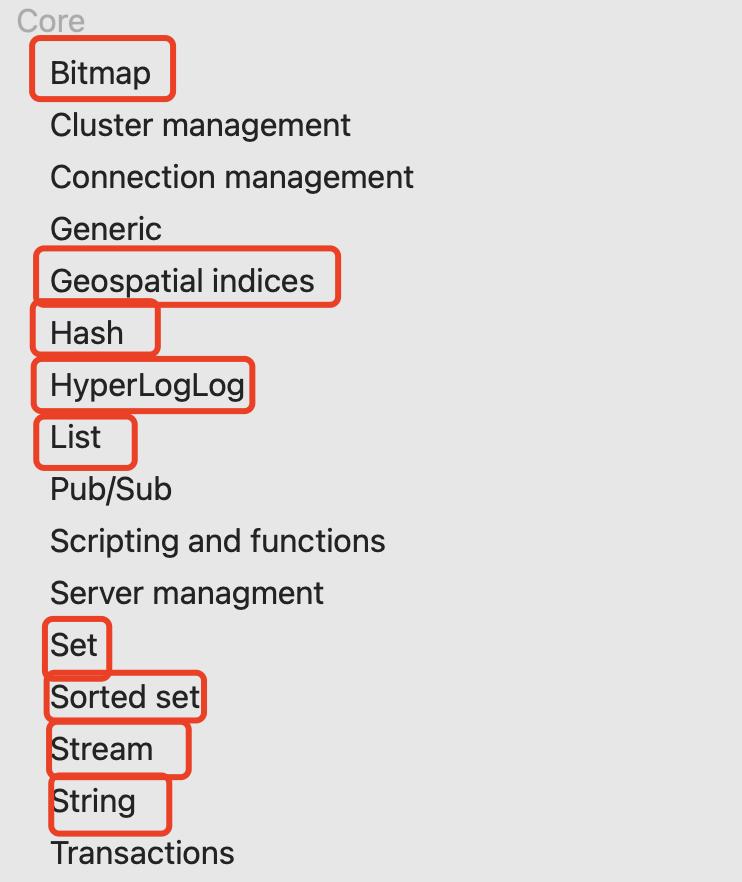
Redis7 的数据结构分为核心版 和扩展版两大类别:
✅ 永远的神:help 命令
在 Redis 中,help 命令是学习数据结构的最佳入口,通过 help @<group> 可以查看任意数据结构的完整命令列表。

📝 面试要点: 面试官常问"Redis有哪些数据结构?",标准回答是:5 种核心数据结构(String、Hash、List、Set、ZSet)+ 4 种扩展数据结构(Bitmap、HyperLogLog、Geo、Stream)。Bitmap 本质是 String 的位操作,Geo 基于 ZSet 实现。
一、核心数据结构
✅1. String 字符串
📝 关键理解: String 是 Redis 中最基础的数据类型,其 value 根据字符串格式不同分为 3 类:string(普通字符串)、int(整数类型)、float(浮点类型),其中 int 和 float 可以做自增自减操作。底层是动态字符串(SDS)。最大容量 512MB。
字符串常用操作
| 命令 | 说明 |
|---|---|
SET key value |
存入字符串键值对(key 不存在则新增,存在则修改) |
GET key |
获取一个字符串键值 |
MSET key value [key value ...] |
批量存储字符串键值对 |
MGET key [key ...] |
批量获取字符串键值 |
SETNX key value |
存入一个不存在的字符串键值对 |
SETEX key seconds value |
存入字符串键值对并指定有效期(秒) |
DEL key [key ...] |
删除一个键 |
EXPIRE key seconds |
设置一个键的过期时间(秒) |
APPEND key value |
向字符串末尾追加内容 |
使用示例:
bash
127.0.0.1:6379> set name Rose # key 不存在则新增
OK
127.0.0.1:6379> get name
"Rose"
127.0.0.1:6379> set name Jack # key 已存在则修改
OK
127.0.0.1:6379> get name
"Jack"
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> MGET name k1 k2 k3
1) "Jack"
2) "v1"
3) "v2"
4) "v3"原子加减操作
| 命令 | 说明 |
|---|---|
INCR key |
将 key 中储存的数字值加 1 |
DECR key |
将 key 中储存的数字值减 1 |
INCRBY key increment |
将 key 所储存的值加上 increment(负数则减) |
DECRBY key decrement |
将 key 所储存的值减去 decrement |
使用示例:
bash
127.0.0.1:6379> set age 10
OK
127.0.0.1:6379> incr age # 自增1
(integer) 11
127.0.0.1:6379> incrby age 2 # 自增2
(integer) 13
127.0.0.1:6379> incrby age -1 # 加负数 = 减
(integer) 12
127.0.0.1:6379> decr age # 自减1
(integer) 11Key 的层级结构
Redis 没有类似 MySQL 的 Table 概念,如何区分不同类型的 key 呢?可以通过给 key 添加前缀,用 : 分隔多个单词,形成层级结构:
多级 key 格式:项目名:业务名:类型:id例如:
- user 相关:
test:user:1 - product 相关:
test:product:1
如果 Value 是一个 Java 对象,可以将对象序列化为 JSON 字符串后存储:
test:user:1 → {"id":1, "name": "Jack", "age": 21}
test:product:1 → {"id":1, "name": "小米11", "price": 4999}在可视化界面中,Redis 会以层级结构来展示,更加直观方便管理。
String 常见应用场景
① 单值缓存:
bash
SET key value
GET key② 对象缓存:
bash
-- 方式一:JSON 字符串(简单,但不能单独操作字段)
SET user:1 '{"name":"roy","balance":1888}'
-- 方式二:多键存储(推荐,便于单独操作每个属性)
MSET user:1:name roy user:1:balance 1888
MGET user:1:name user:1:balance③ 分布式锁:
bash
SETNX product:10001 true # 返回1=获取锁成功,返回0=失败
-- 执行业务操作
DEL product:10001 # 执行完业务释放锁
-- 推荐写法(原子操作:加锁 + 设置过期时间,防止死锁)
SET product:10001 true EX 10 NX✅2. Hash 哈希
📝 关键理解: Hash 类型,也叫散列,其 value 是一个无序字典,类似于 Java 中的
HashMap结构。适合存储对象,将一个对象的多个属性存储在一个 key 下,可以针对单个 field 做 CRUD。底层使用 listpack(小数据量)或 hashtable(大数据量)。
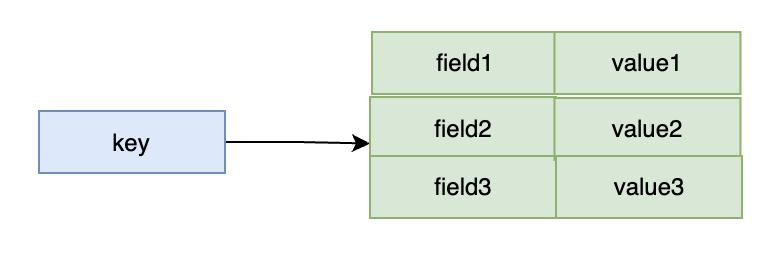
Hash 常用操作
| 命令 | 说明 |
|---|---|
HSET key field value |
存储一个哈希表 key 的键值(field 不存在则新增,存在则修改) |
HGET key field |
获取哈希表 key 对应的 field 键值 |
HSETNX key field value |
存储一个不存在的哈希表 key 的键值 |
HMSET key field value [field value ...] |
在一个哈希表 key 中存储多个键值对 |
HMGET key field [field ...] |
批量获取哈希表 key 中多个 field 键值 |
HGETALL key |
返回哈希表 key 中所有的 field 和 value |
HKEYS key |
获取一个 hash 类型的 key 中的所有 field |
HVALS key |
获取一个 hash 类型的 key 中的所有 value |
HDEL key field [field ...] |
删除哈希表 key 中的 field 键值 |
HLEN key |
返回哈希表 key 中 field 的数量 |
HINCRBY key field increment |
为哈希表 key 中 field 键的值加上增量 increment |
使用示例:
bash
127.0.0.1:6379> HSET heima:user:3 name Lucy # field 不存在则新增
(integer) 1
127.0.0.1:6379> HSET heima:user:3 age 21
(integer) 1
127.0.0.1:6379> HSET heima:user:3 age 17 # field 存在则修改
(integer) 0
127.0.0.1:6379> HGET heima:user:3 name
"Lucy"
127.0.0.1:6379> HGET heima:user:3 age
"17"
127.0.0.1:6379> HMSET heima:user:4 name LiLei age 20 sex man
OK
127.0.0.1:6379> HMGET heima:user:4 name age sex
1) "LiLei"
2) "20"
3) "man"
127.0.0.1:6379> HGETALL heima:user:4
1) "name"
2) "LiLei"
3) "age"
4) "20"
5) "sex"
6) "man"
127.0.0.1:6379> HKEYS heima:user:4
1) "name"
2) "age"
3) "sex"
127.0.0.1:6379> HINCRBY heima:user:4 age 2 # age 自增2
(integer) 22String vs Hash 存储对象对比
| 方式 | 写法 | 优点 | 缺点 |
|---|---|---|---|
| String(JSON) | SET user:1 '{"name":"Jack","age":21}' |
简单直接 | 修改单个字段需反序列化整个 JSON |
| String(多键) | MSET user:1:name Jack user:1:age 21 |
可单独操作每个属性 | key 数量多,管理不便 |
| Hash | HSET user:1 name Jack age 21 |
归类整合、节省空间、可单独操作 field | field 不支持独立设置过期时间 |
Hash 应用场景
① 对象缓存:
bash
HSET user:1 name roy balance 1888
HMGET user:1 name balance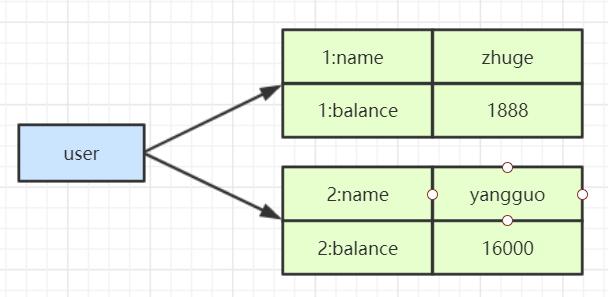
② 电商购物车:
- 以用户 id 为 key
- 商品 id 为 field
- 商品数量为 value
bash
-- 添加商品
HSET cart:1001 10088 1
-- 增加数量
HINCRBY cart:1001 10088 1
-- 商品总数
HLEN cart:1001
-- 删除商品
HDEL cart:1001 10088
-- 获取购物车所有商品
HGETALL cart:1001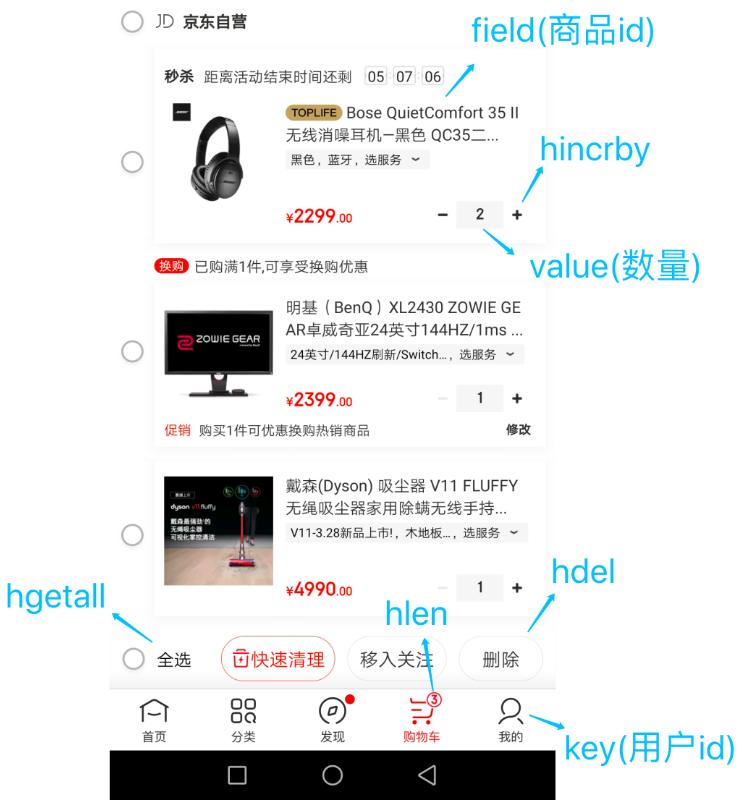
Hash 结构优缺点
| 优点 | 缺点 |
|---|---|
| 同类数据归类整合储存,方便数据管理 | 过期功能不能使用在 field 上,只能用在 key 上 |
| 相比 string 操作消耗内存与 CPU 更小 | Redis 集群架构下不适合大规模使用 |
| 相比 string 储存更节省空间 | --- |
✅3. List 列表
📝 关键理解: List 与 Java 中的
LinkedList类似,底层是一个双向链表。支持正向和反向检索。特征:有序、元素可重复、插入删除快、查询速度一般。一个 list 的容量是 2^32-1 个元素(约 40 多亿)。使用时要注意大 key 问题。
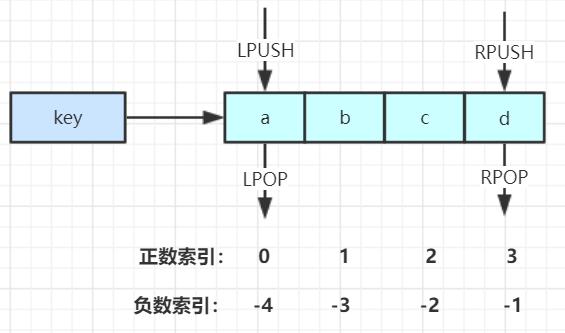
List 常用操作
| 命令 | 说明 |
|---|---|
LPUSH key value [value ...] |
将一个或多个值插入到 key 列表的表头(最左边) |
RPUSH key value [value ...] |
将一个或多个值插入到 key 列表的表尾(最右边) |
LPOP key |
移除并返回 key 列表的头元素,列表为空则返回 nil |
RPOP key |
移除并返回 key 列表的尾元素,列表为空则返回 nil |
LRANGE key start stop |
返回列表 key 中指定区间内的元素(-1 表示到末尾) |
BLPOP key [key ...] timeout |
从表头弹出元素,若无元素则阻塞等待 timeout 秒(timeout=0 一直阻塞) |
BRPOP key [key ...] timeout |
从表尾弹出元素,若无元素则阻塞等待 timeout 秒(timeout=0 一直阻塞) |
使用示例:
bash
127.0.0.1:6379> LPUSH users 1 2 3 # 左进:3 2 1
(integer) 3
127.0.0.1:6379> RPUSH users 4 5 6 # 右进:3 2 1 4 5 6
(integer) 6
127.0.0.1:6379> LPOP users # 左出:弹出3
"3"
127.0.0.1:6379> RPOP users # 右出:弹出6
"6"
127.0.0.1:6379> LRANGE users 0 -1 # 查看所有元素
1) "2"
2) "1"
3) "4"
4) "5"List 应用场景
常用数据结构组合:
Stack(栈) = LPUSH + LPOP
Queue(队列) = LPUSH + RPOP
Blocking MQ(阻塞队列) = LPUSH + BRPOP
常见业务场景:
- 视频列表、签到列表
- 排队机
- 简化版的 MQ(消息队列)
List 注意事项

- 一个 list 的容量是 2^32-1 个元素,大概 40 多亿。但在应用时,要注意大 key 问题。
- list 的底层是一个双向链表,对双端的操作性能很高。但是通过索引下标直接操作某一个中间节点的性能就会比较低。
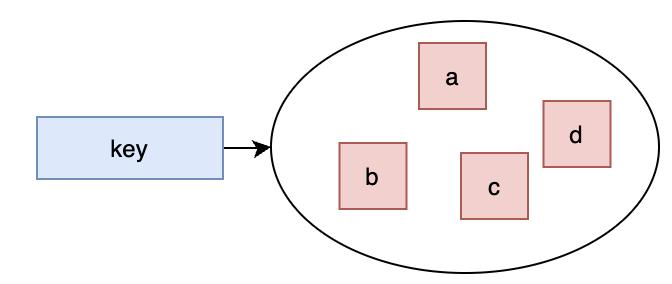
✅4. Set 集合
📝 关键理解: Set 是无序不重复集合,底层使用 listpack(小数据量)或 hashtable。支持交并差集运算,适合做标签、点赞、抽奖等场景。
Set 常用操作
| 命令 | 说明 |
|---|---|
SADD key member [member ...] |
往集合 key 中存入元素,元素存在则忽略,key 不存在则新建 |
SREM key member [member ...] |
从集合 key 中删除元素 |
SMEMBERS key |
获取集合 key 中所有元素 |
SCARD key |
获取集合 key 的元素个数 |
SISMEMBER key member |
判断 member 元素是否存在于集合 key 中 |
SRANDMEMBER key [count] |
从集合 key 中选出 count 个元素,元素不从 key 中删除 |
SPOP key [count] |
从集合 key 中选出 count 个元素,元素从 key 中删除 |
Set 运算操作
| 命令 | 说明 |
|---|---|
SINTER key [key ...] |
交集运算 |
SINTERSTORE destination key [key ..] |
将交集结果存入新集合 destination 中 |
SUNION key [key ..] |
并集运算 |
SUNIONSTORE destination key [key ...] |
将并集结果存入新集合 destination 中 |
SDIFF key [key ...] |
差集运算 |
SDIFFSTORE destination key [key ...] |
将差集结果存入新集合 destination 中 |
Set 应用场景
① 微信抽奖小程序:
bash
-- 点击参与抽奖加入集合
SADD key {userID}
-- 查看参与抽奖所有用户
SMEMBERS key
-- 抽取 count 名中奖者
SRANDMEMBER key [count] -- 不删除元素,可重复中奖
SPOP key [count] -- 删除元素,不可重复中奖
② 微信/微博点赞、收藏、标签:
bash
-- 点赞
SADD like:{消息ID} {用户ID}
-- 取消点赞
SREM like:{消息ID} {用户ID}
-- 检查用户是否点过赞
SISMEMBER like:{消息ID} {用户ID}
-- 获取点赞的用户列表
SMEMBERS like:{消息ID}
-- 获取点赞用户数
SCARD like:{消息ID}
③ 集合运算实现社交关系:
bash
SINTER set1 set2 → 共同关注的人
SUNION set1 set2 → 朋友圈所有人
SDIFF set1 set2 → 可能认识的人(推荐好友)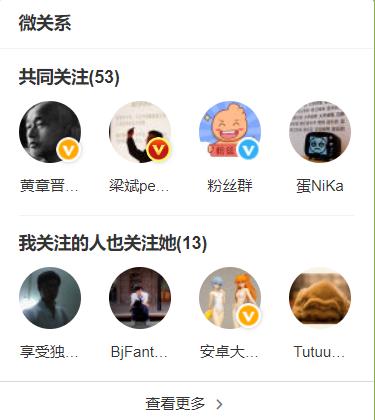
④ 社交好友关系实战练习:
需求:
- 张三的好友有:李四、王五、赵六
- 李四的好友有:王五、麻子、二狗
bash
127.0.0.1:6379> SADD zs lisi wangwu zhaoliu
(integer) 3
127.0.0.1:6379> SADD ls wangwu mazi ergou
(integer) 3
-- 计算张三好友有几人
127.0.0.1:6379> SCARD zs
(integer) 3
-- 计算张三和李四的共同好友
127.0.0.1:6379> SINTER zs ls
1) "wangwu"
-- 查询哪些人是张三好友却不是李四好友
127.0.0.1:6379> SDIFF zs ls
1) "zhaoliu"
2) "lisi"
-- 查询张三和李四的全部好友
127.0.0.1:6379> SUNION zs ls
1) "wangwu"
2) "zhaoliu"
3) "lisi"
4) "mazi"
5) "ergou"
-- 判断李四是否是张三的好友
127.0.0.1:6379> SISMEMBER zs lisi
(integer) 1 # 返回1:是好友
-- 将李四从张三的好友列表中移除
127.0.0.1:6379> SREM zs lisi
(integer) 1✅5. ZSet 有序集合
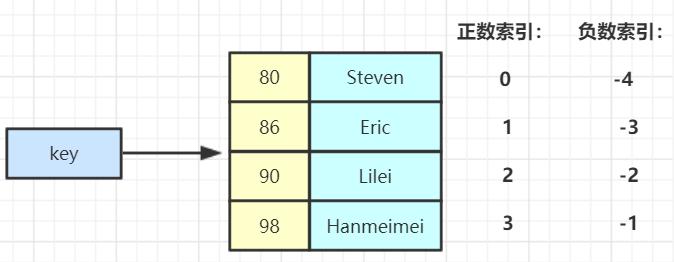
📝 关键理解: ZSet 与 Java 中的
TreeSet类似,每个元素关联一个 score 用于排序。底层使用 listpack(小数据量)+ skiplist(跳跃表)+ hashtable。可排序、元素不重复、查询速度快。适合排行榜场景。
ZSet 常用操作
| 命令 | 说明 |
|---|---|
ZADD key score member [[score member]...] |
往有序集合 key 中加入带分值元素(已存在则更新 score) |
ZREM key member [member ...] |
从有序集合 key 中删除元素 |
ZSCORE key member |
返回有序集合 key 中元素 member 的分值 |
ZRANK key member |
获取指定元素的排名(从 0 开始,按分数从小到大) |
ZREVRANK key member |
获取指定元素的排名(从 0 开始,按分数从大到小) |
ZCARD key |
返回有序集合 key 中元素个数 |
ZCOUNT key min max |
统计有序集合中分数在给定范围内的元素个数 |
ZINCRBY key increment member |
为有序集合 key 中元素 member 的分值加上 increment |
ZRANGE key start stop [WITHSCORES] |
正序获取有序集合 key 从 start 下标到 stop 下标的元素 |
ZREVRANGE key start stop [WITHSCORES] |
倒序获取有序集合 key 从 start 下标到 stop 下标的元素 |
ZRANGEBYSCORE key min max [WITHSCORES] |
按 score 排序后,获取指定 score 范围内的元素 |
📝 注意: 所有排名默认都是升序,如果要降序则在命令的 Z 后面加 REV。例如:
ZRANK(升序排名)→ZREVRANK(降序排名);ZRANGE(升序获取)→ZREVRANGE(降序获取)。
ZSet 集合运算
| 命令 | 说明 |
|---|---|
ZUNIONSTORE destkey numkeys key [key ...] |
并集计算 |
ZINTERSTORE destkey numkeys key [key ...] |
交集计算 |
ZDIFFSTORE destkey numkeys key [key ...] |
差集计算 |
ZSet 应用场景:排行榜
bash
-- 1)用户点击新闻,增加热度
ZINCRBY hotNews:20190819 1 守护香港
-- 2)展示当日排行前十(按热度倒序)
ZREVRANGE hotNews:20190819 0 9 WITHSCORES
-- 3)七日搜索榜单计算(合并7天的数据)
ZUNIONSTORE hotNews:20190813-20190819 7 \
hotNews:20190813 hotNews:20190814 ... hotNews:20190819
-- 4)展示七日排行前十
ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES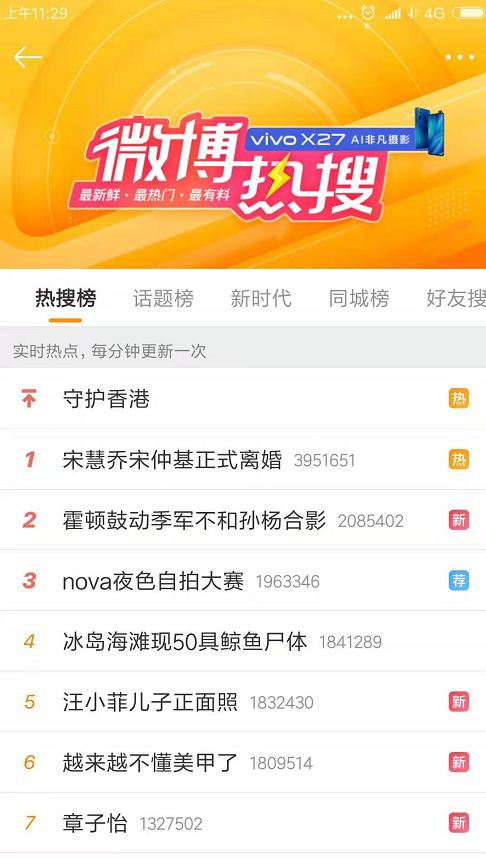
二、扩展数据结构
✅6. Bitmap 位图
📝 关键理解: Bitmap 本质是 String 的位操作,用一个 bit 位来表示某个元素对应的值或状态。最大优势是节省空间,适合只有两个状态的数据统计。

Bitmap 常用操作
| 命令 | 说明 |
|---|---|
SETBIT key offset value |
将一个二进制数组的 offset 位置设置成 value(0 或 1) |
GETBIT key offset |
返回一个二进制数组的 offset 位置的值 |
| `BITCOUNT key [start end [BYTE | BIT]]` |
| `BITPOS key bit [start [end [BYTE | BIT]]]` |
| `BITOP AND | OR |
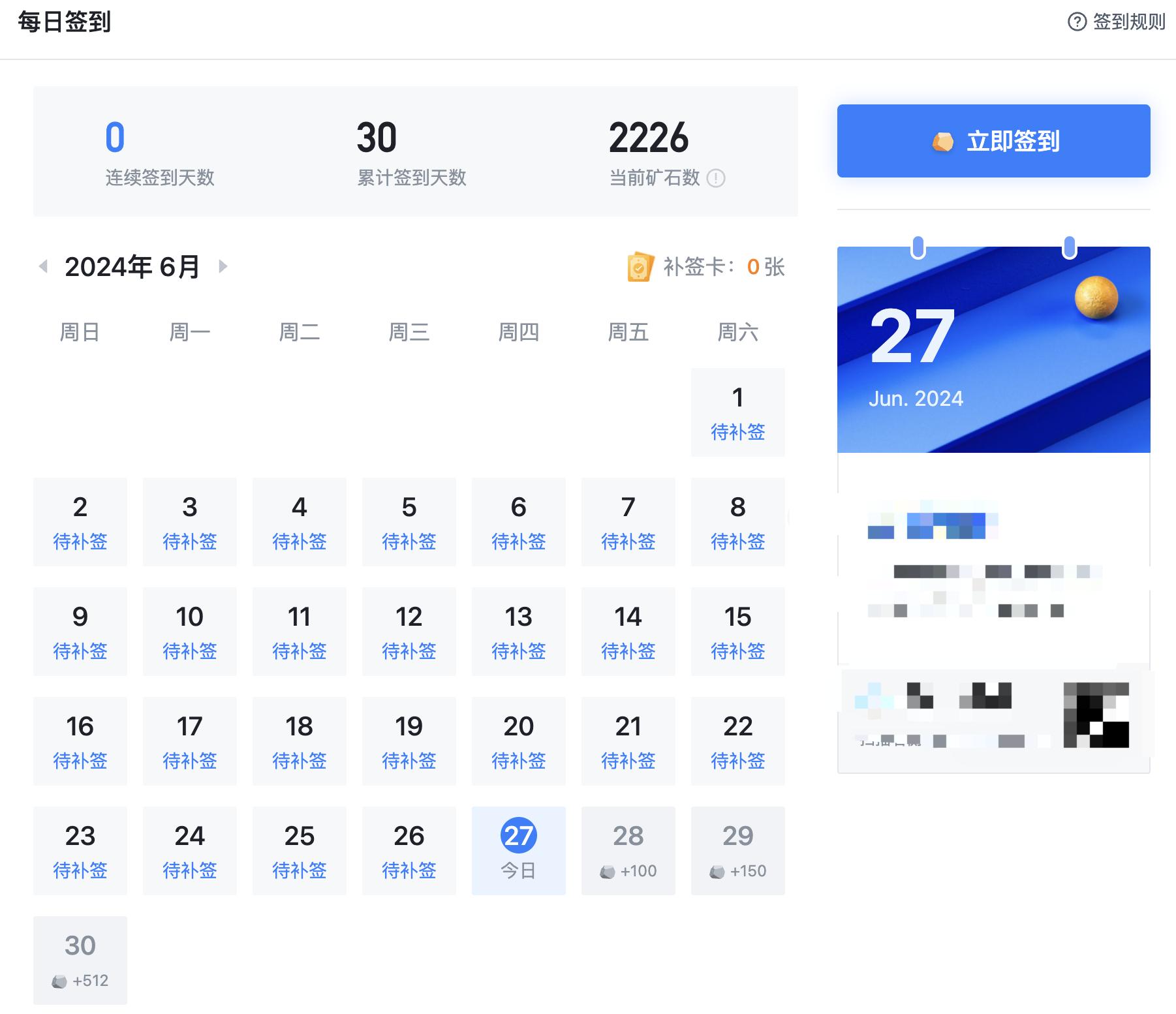
Bitmap 应用场景:每日签到
bash
-- 1号用户第100天完成了签到
SETBIT dailycheck:1 100 1
-- 统计1号用户的签到次数
BITCOUNT dailycheck:1
-- 统计1号用户第一天签到的时间
BITPOS dailycheck:1 1优点:快速、高效、节省空间。
✅7. HyperLogLog
📝 关键理解: HyperLogLog 用于统计一个集合中不重复的元素个数(基数统计)。它不保存具体数据,占用空间极小(12KB),但有约 0.81% 的误差率。典型应用场景:统计网站的 UV。
HyperLogLog 常用操作
| 命令 | 说明 |
|---|---|
PFADD key element [element ...] |
添加元素到 HyperLogLog |
PFCOUNT key [key ...] |
返回 HyperLogLog 的基数估算值 |
PFMERGE destkey sourcekey [sourcekey ...] |
将多个 HyperLogLog 合并为一个 |
使用示例
bash
-- 添加用户访问记录
PFADD visitlog 192.168.65.111 192.168.65.112 192.168.65.111
-- 统计不同的独立访客(UV)
PFCOUNT visitlog📝 面试要点: HyperLogLog 和 Set 都可以做去重统计,但 HyperLogLog 不存储原始数据,内存占用仅 12KB,适合超大数据量的去重统计(如亿级 UV)。Set 精确但占内存,适合小数据量精确去重。
✅8. Geo 地理位置
📝 关键理解: Geo 基于 ZSet 实现,用于存储地理位置信息(经纬度),支持距离计算、附近搜索等。底层使用 GeoHash 算法将二维坐标编码为一个字符串。
Geo 常用操作
| 命令 | 说明 |
|---|---|
| `GEOADD key [NX | XX] [CH] longitude latitude member [...]` |
GEOPOS key [member [member ...]] |
返回地址的经纬度 |
| `GEODIST key member1 member2 [M | KM |
| `GEORADIUS key longitude latitude radius M | KM |
| `GEOSEARCH key FROMMEMBER member | FROMLONLAT longitude latitude BYRADIUS radius ...` |
Geo 应用场景:附近商家推荐
获取经纬度坐标:https://api.map.baidu.com/lbsapi/getpoint/index.html
bash
-- 添加商家地址
GEOADD changsha 113.017489 28.200454 火车站 \
112.96903 28.201195 橘子洲 \
113.017031 28.199706 赛格广场 \
113.017004 28.197677 国储
-- 查询两个地点之间的距离
GEODIST changsha 火车站 橘子洲 M
-- 查找火车站附近 2KM 内的景点
GEORADIUSBYMEMBER changsha 火车站 2 KM WITHdist WITHcoord COUNT 4 WITHhash
三、高级数据结构
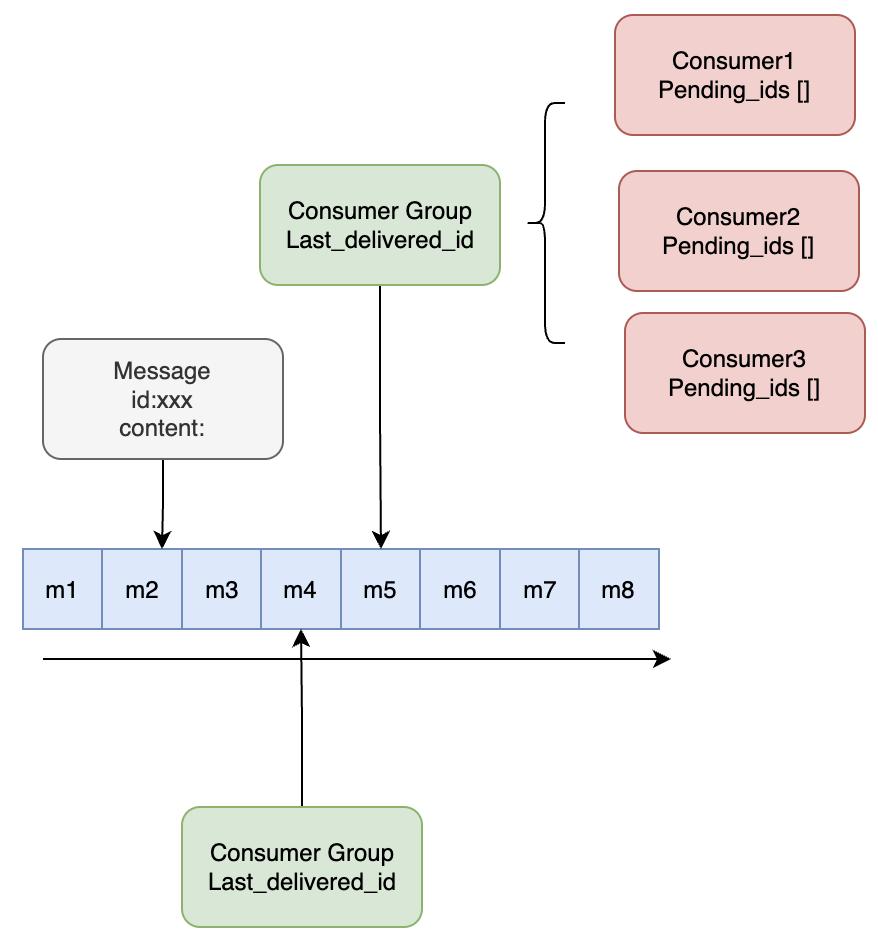
✅9. Stream 消息流
📝 关键理解: Stream 是 Redis 版的 MQ(消息队列),结合了阻塞队列 + pub/sub 的特性。优点是轻量级、低延迟,但企业应用中较少直接使用 Redis Stream,更多选择专业的 MQ 如 Kafka、RocketMQ 等。了解即可。
Stream 常用操作
| 命令 | 说明 |
|---|---|
| `XADD key [NOMKSTREAM] [MAXLEN | MINID ...] * |
XDEL key id [id ...] |
删除队列中的一条消息 |
XLEN key |
获取队列的长度 |
XRANGE key start end [COUNT count] |
查询队列中的消息 |
Stream 消费者组操作
bash
-- 创建队列,并添加消息(*表示让系统自动生成ID)
XADD mystream * name loulan name roy name admin
-- 查看队列消息(- 队列开始,+ 队列结尾)
XRANGE mystream - +
-- 创建消费者组(0 从队列头部开始消费,$ 从队列尾部开始消费)
XGROUP CREATE mystream groupA 0
-- 消费消息(> 表示从第一条未被消费过的消息消费)
XREADGROUP GROUP groupA consumer1 COUNT 2 STREAMS mystream >
-- 查看消费者组的消费进度
XPENDING mystream groupA四、SpringBoot 集成 Redis
✅10. Maven 依赖与配置
Maven 依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>核心配置(application.yml):
yaml
spring:
data:
redis:
host: 192.168.65.214
port: 6379
password: 123qweasd
# ... 更多配置✅11. RestTemplate 快速上手
记住一个对象:
java
@Resource
private RedisTemplate<String, Object> redisTemplate;按组操作:
java
redisTemplate.opsForValue().xxx // String 类型
redisTemplate.opsForSet().xxx // Set 类型
redisTemplate.opsForHash().xxx // Hash 类型
redisTemplate.opsForList().xxx // List 类型
redisTemplate.opsForZset().xxx // ZSet 类型
redisTemplate.opsForGeo().xxx // Geo 类型
redisTemplate.opsForHyperLogLog().xxx // HyperLogLog 类型
redisTemplate.opsForStream().xxx // Stream 类型
redisTemplate.opsForValue().setBit() // Bitmap 类型(基于 String)📝 注意: Bitmap 没有单独的操作类型(opsForBit),而是通过
opsForValue().setBit()来操作,因为 Bitmap 本质上是基于 String 的位操作。
✅12. RedisTemplate 解决中文乱码
java
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
// GenericJackson2JsonRedisSerializer jsonSerializer = new GenericJackson2JsonRedisSerializer();
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
GenericToStringSerializer<String> genericToStringSerializer = new GenericToStringSerializer<>(String.class);
// 指定 key 和 value 的序列化方式
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setValueSerializer(genericToStringSerializer);
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setHashValueSerializer(stringRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}📋 全文总结
✅1. 数据结构总览对比
| 数据结构 | 底层实现 | 特点 | 典型场景 |
|---|---|---|---|
| String | SDS(动态字符串) | 基础类型,最大 512MB | 缓存、分布式锁、计数器 |
| Hash | listpack / hashtable | 适合存储对象 | 对象缓存、购物车 |
| List | quicklist(双向链表) | 有序、可重复 | 栈、队列、阻塞队列 |
| Set | listpack / hashtable | 无序、去重 | 标签、点赞、抽奖、集合运算 |
| ZSet | listpack + skiplist | 有序、去重、按分数排序 | 排行榜 |
| Bitmap | String 位操作 | 极省空间(1bit/位) | 签到、活跃统计 |
| HyperLogLog | 概率统计算法 | 12KB 固定内存,0.81% 误差 | UV 统计、大基数去重 |
| Geo | ZSet + GeoHash | 地理位置计算 | 附近的人/店铺 |
| Stream | Rax(基数树) | 消息队列 | 轻量级 MQ |
✅2. 面试高频考点
- String 实现分布式锁:
SET key value EX 10 NX原子操作,注意锁超时和锁释放的安全性 - Hash vs String 存对象: Hash 更节省空间,可以针对单个 field 操作,但 field 不支持独立过期
- List 实现的三种结构: Stack = LPUSH+LPOP,Queue = LPUSH+RPOP,Blocking MQ = LPUSH+BRPOP
- Set 实现社交关系: SINTER(共同关注)、SUNION(朋友圈)、SDIFF(推荐好友)
- ZSet 实现排行榜:
ZINCRBY增加分数,ZREVRANGE倒序获取排名 - HyperLogLog vs Set 做去重: HyperLogLog 省内存但有误差,Set 精确但占内存
- Redis Stream vs 专业 MQ: Stream 轻量级、低延迟,但不能持久化、没有 ACK 机制,企业级选 Kafka/RocketMQ
✅3. 数据结构选择决策树
需要排序?
├── 是 → 用 ZSet
└── 否 → 需要去重?
├── 是 → 统计基数?
│ ├── 是 → HyperLogLog(大基数估算)
│ └── 否 → Set / ZSet
└── 否 → 存对象?
├── 是 → Hash(可单字段操作)
└── 否 → 有队列特性?
├── 是 → List / Stream
└── 否 → String