计算机组成原理期末考试重点
第一章
1.1 计算机系统简介
1.1.2 计算机系统的层次结构
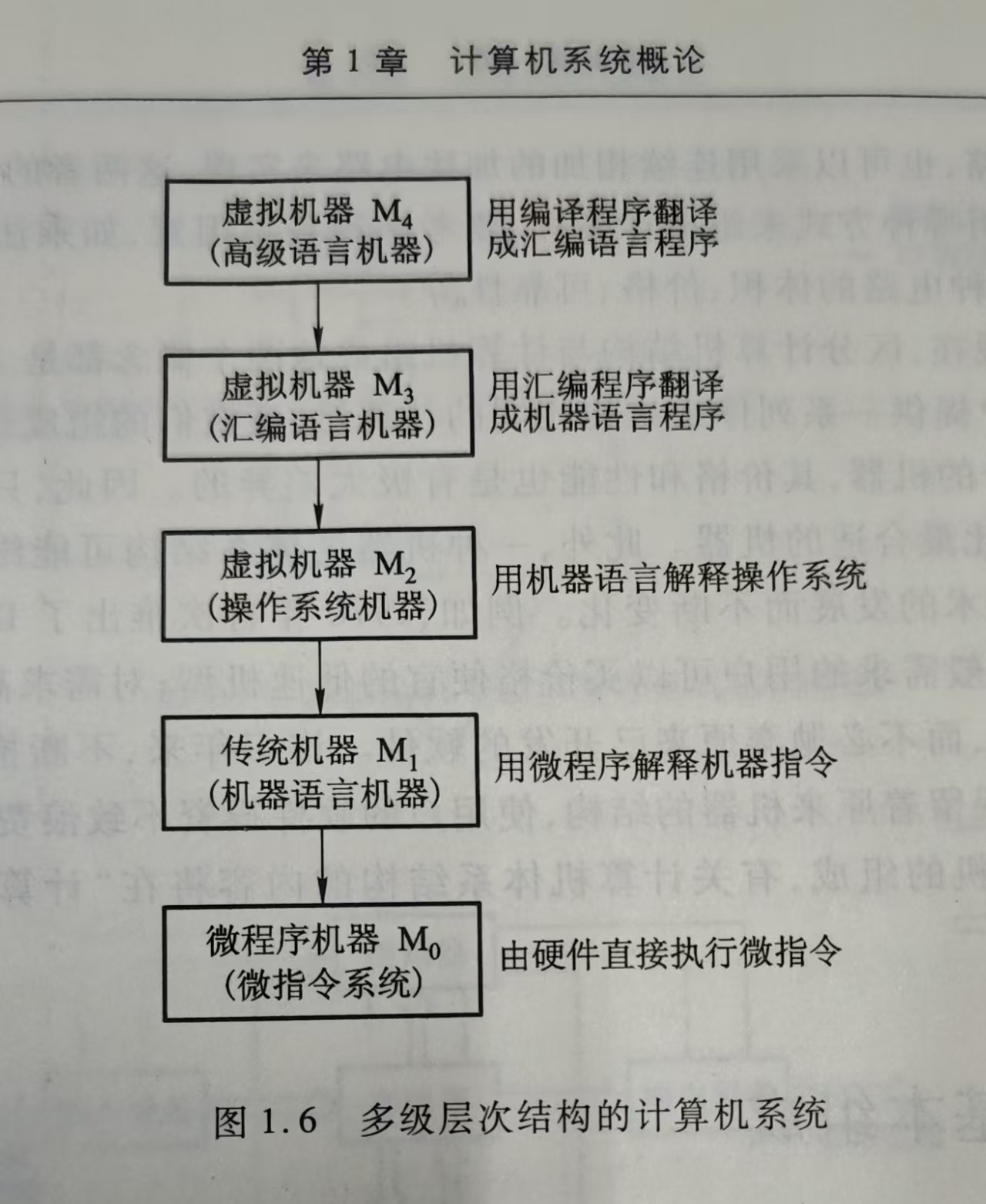
- 高级语言层
- 汇编语言层
- 操作系统层
- 机器语言层
- 微指令系统层
1.1.3 计算机系统的体系结构

计算机的体系结构 是指 那些能被程序员所见到的计算机系统的属性,即概念性的结构与功能特性,包含:指令集、数据类型、存储器寻址技术、I/O结构。
1.2 计算机的基本组成
1.2.1 冯诺依曼计算机的特点(两个框图🌟)
特点:
- 指令与数据都用二进制表示;
- 存储程序:指令和数据一同存放在存储器中;
- 计算机由五大部件组成:运算器、控制器、存储器、输入设备、输出设备;
- 指令顺序存放,PC自动给出下一条指令地址;
- 指令由操作码+地址码构成。

两个框图:
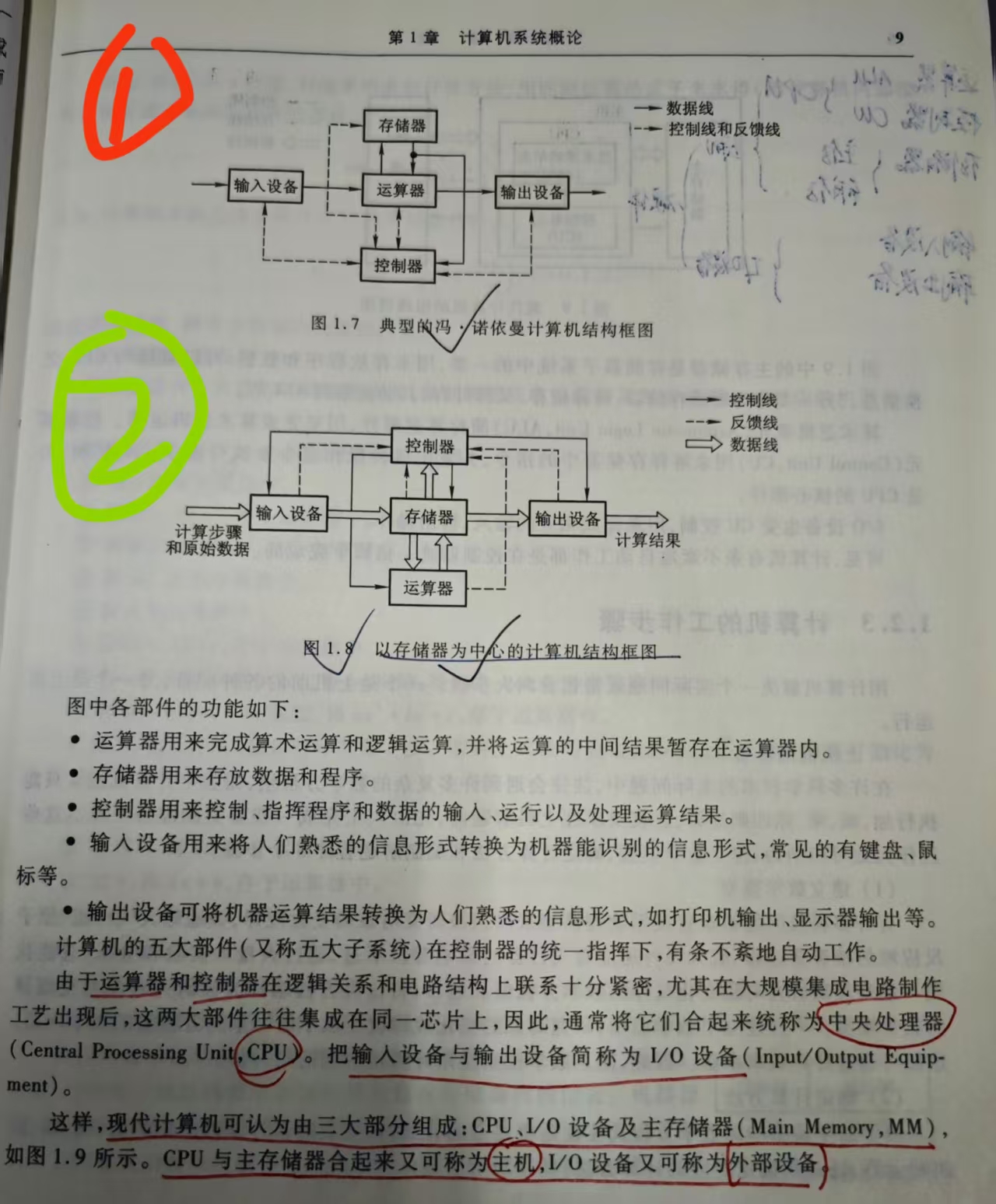
- CPU = 运算器 + 控制器
- 主机 = CPU + 主存储器
- I/O设备(外部设备)= 输入设备 + 输出设备
题 1:对比图 1.7 与图 1.8 两种冯诺依曼体系结构,简述二者区别
- 图 1.7 是早期冯・诺依曼计算机结构,以运算器为中心。输入 / 输出设备与主存之间的数据传送都必须经过运算器,数据通路效率低。
- 图 1.8 是现代计算机结构,以存储器为中心。I/O 设备可以直接和主存交换信息,数据不需要经过运算器,支持 DMA 高速传输,系统效率更高。
- 两种结构都保留了冯诺依曼五大硬件部件:运算器、控制器、存储器、输入设备、输出设备。
题 2:简述计算机五大部件各自的功能
- 运算器:完成算术运算和逻辑运算,暂存运算中间结果;
- 存储器:存放程序与数据;
- 控制器:指挥控制程序运行、数据输入输出;
- 输入设备:把外部信息转换成机器可识别的二进制信息;
- 输出设备:将运算结果转换为人能识别的信息。
题 3:画图(给了,应该不会这么变态吧)
画出图 1.7:典型冯・诺依曼计算机(以运算器为中心)结构框图,并标注数据线、控制线。
画出图 1.8:以存储器为中心的计算机结构框图,标注数据流走向。
第三章
3.2 总线的分类(重点🐦🔥)
按数据传送方式分:并行传输总线、串行传输总线
按连接位置分类:
- 片内总线:芯片内部(CPU内部寄存器、ALU之间)
- 系统总线 :连接CPU、主存、I/O接口,分为三类:
- 地址总线(单向,CPU→主存/I/O)
- 数据总线(双向)
- 控制总线(单向+双向)
- 通信总线:计算机之间、主机与外设之间(USB、以太网)
3.3 总线特征及性能指标(了解)
总线特征:
- 机械特性:规定插头引脚物理规格;
- 电气特性:规定信号电平高低;
- 功能特性:定义每一根信号线的用途;
- 时间特性:规定信号的时序与先后顺序。
总线性能指标:总线宽度、总线带宽、时钟频率、信号线数量、总线复用方式、同步 / 异步定时、总线负载。
3.4 总线结构(了解)
- 单总线结构:结构简单,同一时刻只能一对设备传输,速度慢。
- 双总线结构:CPU总线+主存总线,性能更高。
- 三总线结构:CPU总线、主存总线、I/O总线,多设备并行工作。
3.5 总线控制(重中重🐦🔥)
3.5.1 总线判优控制(会考一种方法🌟)
- 链式查询(优先级固定)
总线请求BR→总线忙BS→总线授权BG串行传递。
- 优点:线路少,成本低
- 缺点:优先级固定,离CPU近的设备优先级最高,故障会阻塞后续设备
- 计数器定时查询
设备地址由计数器给出,优先级可以灵活改变。
- 优点:优先级次序可以改变
- 缺点:增加了控制线,线路更加复杂
- 独立请求方式
每个设备独立的请求线与授权线,优先级可编程控制,硬件线路最多。
- 优点:响应速度快,优先次序控制灵活
- 缺点:控制线数量多,总线控制更复杂
3.5.2 总线通信控制(了解即可)
总线周期分为四个阶段:申请分配阶段、寻址阶段、传数阶段、结束阶段
通信的四种方式:同步通信(统一时钟,速度快)、异步通信(无统一时钟信号)、半同步信号、分离式通信
第四章
4.1 概述
4.1.1 存储器的分类(RAM、ROM🌟)

几种常用存储器的好坏(🌟)
-
SRAM(静态RAM)
优点:读写速度快,不需要刷新
缺点:集成度低,成本高
用途:高速缓存Cache
-
DRAM(动态RAM)
优点:集成度高,容量大,价格便宜
缺点:需要定期刷新,速度比SRAM慢
用途:计算机主存(内存条)
-
ROM系列(非易失,断电数据不丢失)
- MROM:出厂固化,无法修改,成本极低
- PROM:仅能一次性写入
- EPROM:紫外线整片擦除
- EEPROM:电信号按字节擦写
共同缺点:写入速度慢,无法频繁改写
-
Flash闪存
优点:断电数据保留,体积小
缺点:只能整块擦除,不能修改单个字节
用途:U盘、固态硬盘
-
辅存(外存)
- 磁盘:容量大,支持随机访问;机械结构,速度慢
- 磁带:存储容量极大,价格最低;仅支持顺序读取,用于数据备份
- 光盘:数据保存持久;读写速度慢

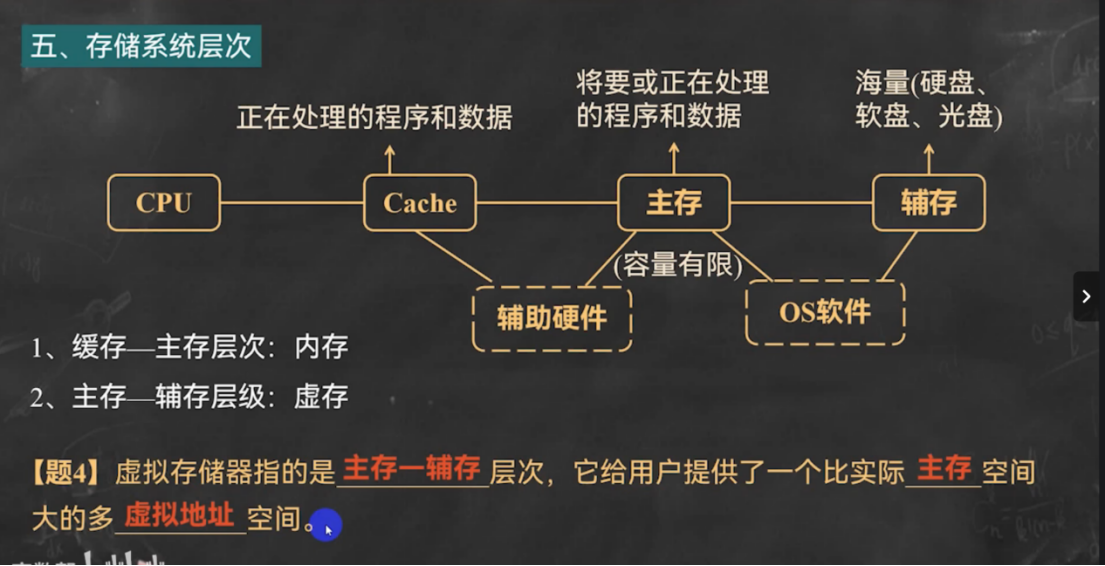
4.1.2 存储器的层次结构(意义+作用🌟)
- **两层结构:**内存 + 外存
- **三层结构:**Cache + 主存 + 辅存
-
目的:解决 速度、容量、价格 三者之间的矛盾
-
各层作用:
- Cache:使主存存取速度与CPU运算速度相匹配
- 主存:存放运行中的程序和数据
- 辅存(磁盘):提供海量存储空间
4.2 主存储器
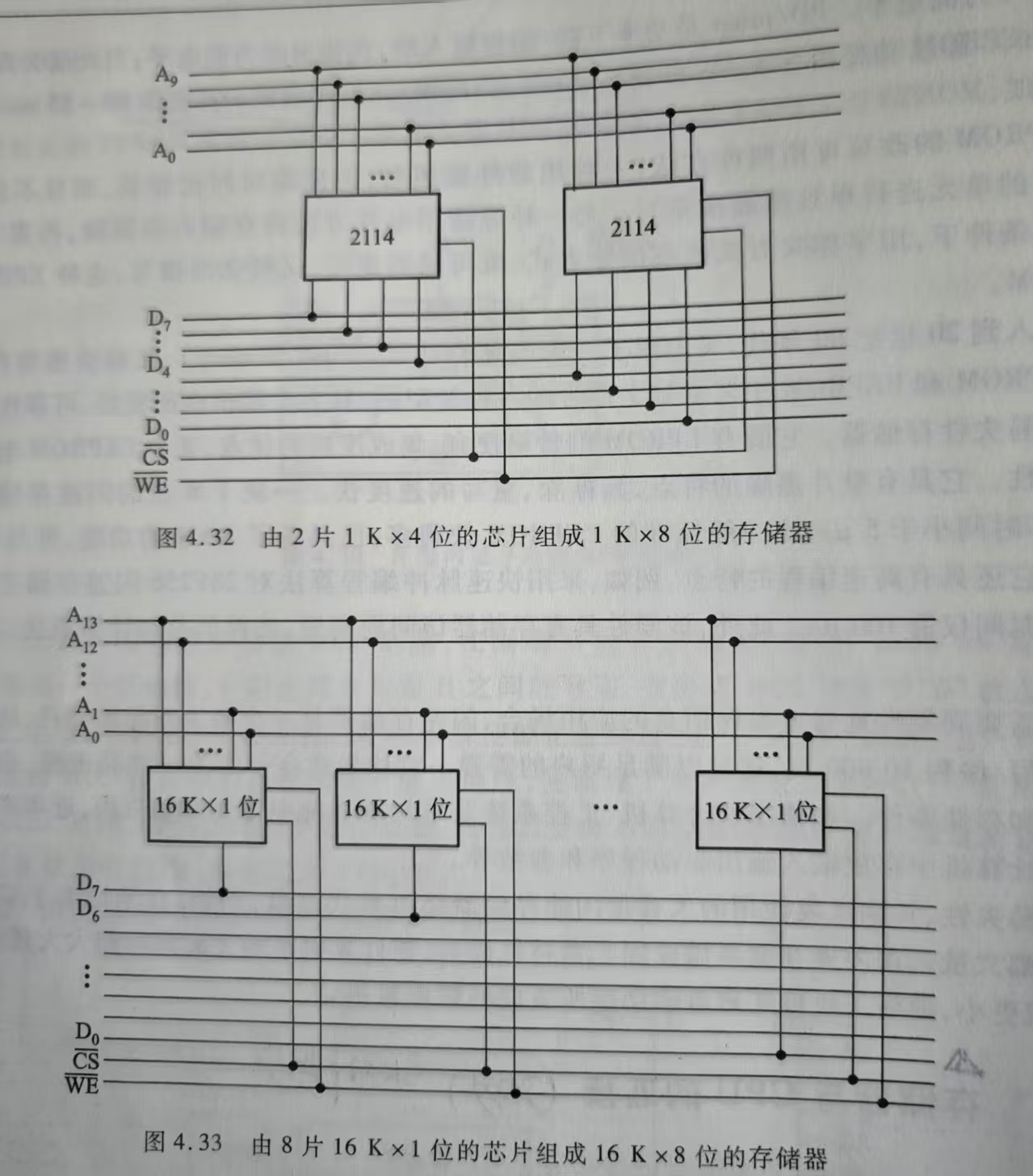
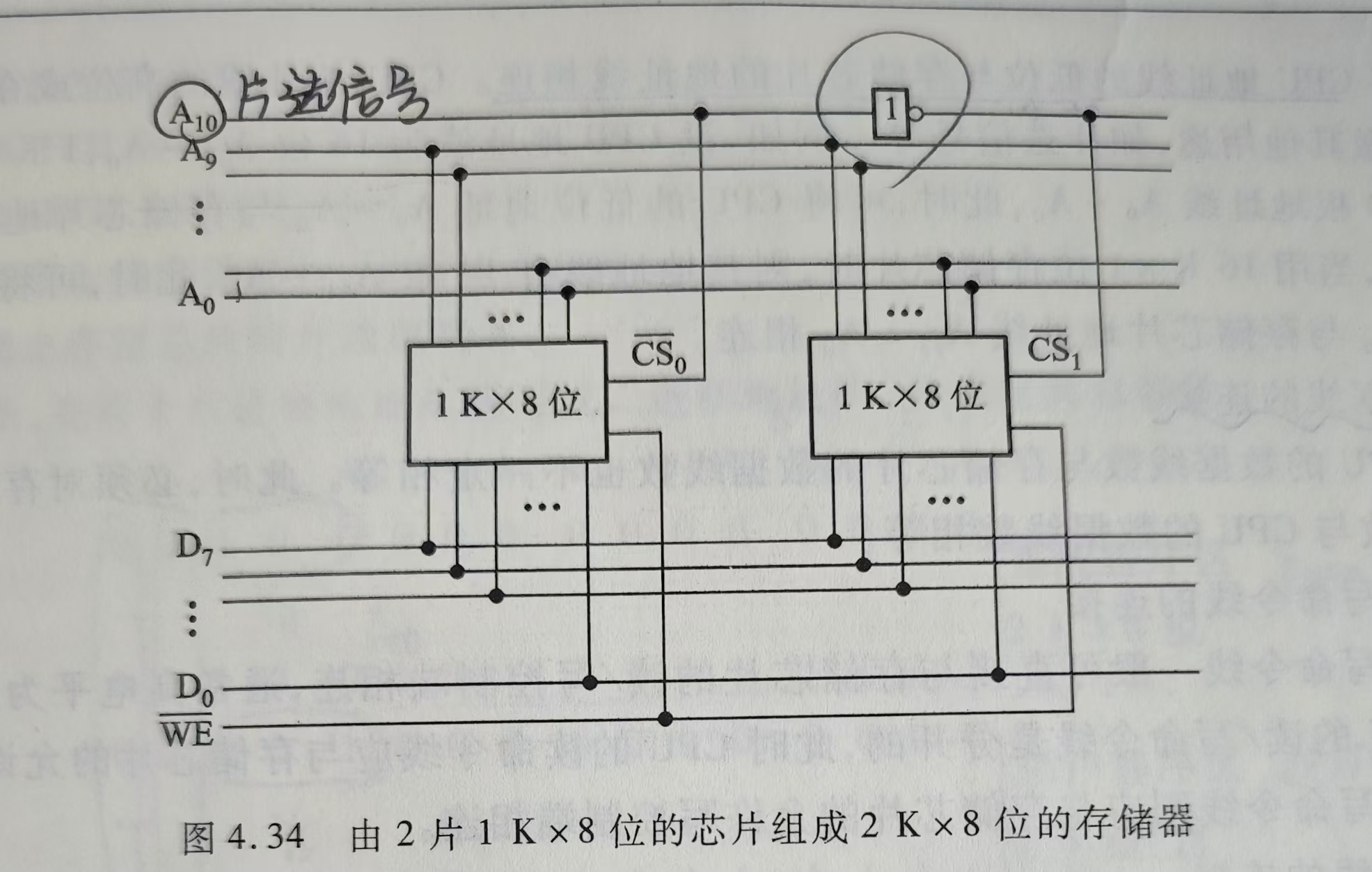
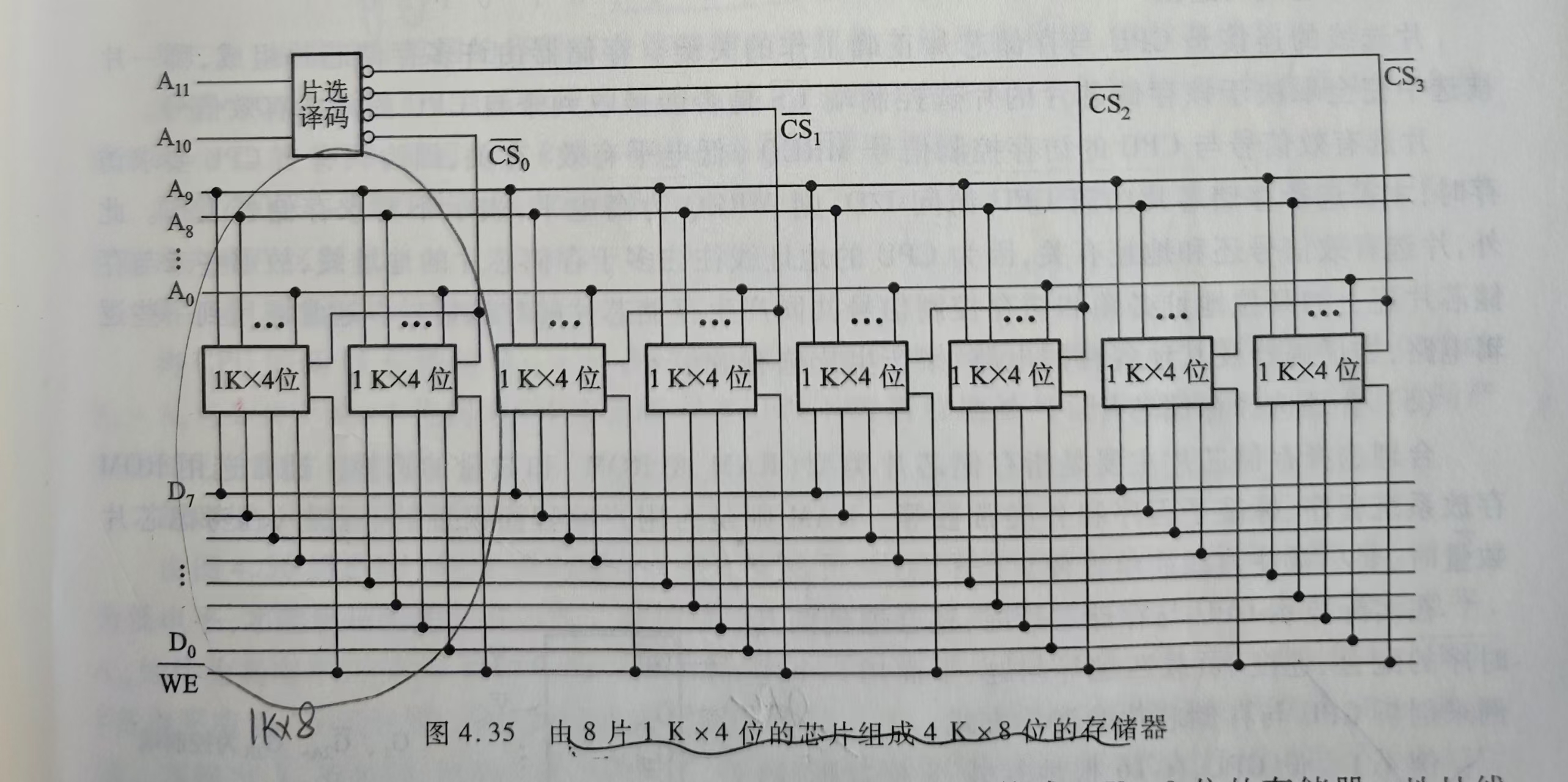
4.2.5 存储器与CPU的连接(有20分的大题-->会计算+画图🐦🔥)
三种扩展方式:
-
位扩展
-
字扩展
-
字、位扩展(先位扩展,再字扩展、)
-
例题4.1 、4.2
-
作业
4.2.6 存储器的校验(海明码🌟)
- 基本不等式: 2 r ≥ n + k + 1 2^r \ge n+k+1 2r≥n+k+1
n n n=信息位, k k k=校验位。
2.编码规则
①校验位放在第 2 0 , 2 1 , 2 2 ... 2^0,2^1,2^2... 20,21,22... 位置(1,2,4,8...号位);
②分组异或计算每一位校验值;
③出错后得到伴随式,伴随式十进制数值=出错位编号;
④该位取反即可纠错。
- 课本例题
4.3 高速缓冲存储器
4.3.2 Cache-主存地址映射
- 参考例题4.8 - 4.11 (不是老师说的)
第五章
5.1.2 输入输出系统的组成
输入输出系统由I/O 硬件 和I/O 软件两部分组成:
- 硬件包含外部 I/O 设备、I/O 接口、系统总线;
- 软件包含用户应用程序、设备独立管理程序、设备驱动程序、中断服务程序。
5.1.3 I/O设备与主机的联系方式
分为两大维度:编址方式 、联络信号(通信控制)
一、按I/O地址编址方式(必考)
-
统一编址(存储器映射方式)
-
规则:把I/O接口寄存器当成主存单元,共用一套地址空间,I/O地址占用主存地址范围。
-
访问指令:只用访存指令(LOAD/STORE)读写外设,无专门I/O指令。
-
优缺点
✅ 指令丰富,可直接对外设做算术、逻辑运算;
❌ 占用一部分主存地址,主存可用空间变少。
-
独立编址(I/O单独编址)
-
规则:主存、I/O有两套完全独立的地址空间,互不占用。
-
访问指令:必须使用专用I/O指令:
IN(输入)、OUT(输出)。 -
优缺点
✅ 不占用主存地址,主存空间完整;
❌ 只有专门I/O指令才能访问外设,操作功能有限。
按时序联络控制方式(设备与主机怎么互相通知)
-
立即应答(无条件传送)
外设始终就绪,主机直接收发数据,不需要握手信号。
适用:LED、开关这类简单设备。
-
异步握手(查询方式,程序直接控制)
主机主动轮询外设状态寄存器,判断设备是否就绪,就绪再传输。
适用:低速外设,CPU利用率低。
-
中断联络(中断方式)
外设准备好数据后,主动发中断请求 通知CPU;CPU暂停当前任务处理I/O,完成后返回原程序。
适用:中低速外设,提升CPU利用率。
-
DMA联络(直接存储器访问)
外设与主存直接交换数据,DMA控制器接管总线,传输期间无需CPU干预;传输完成后发中断告知CPU。
适用:磁盘、固态硬盘等高速块设备。
简答背诵版
I/O设备与主机联系方式分为两类:
- 地址编址方式:统一编址、独立编址;
- 数据传输联络方式:立即应答、程序查询、程序中断、DMA。
选择填空高频考点(AI)
- 有IN/OUT指令 → 独立编址
- 用LOAD/STORE访问外设 → 统一编址
- 外设主动通知CPU的联络方式:中断方式
- 高速外设批量传输用:DMA方式
5.1.4 I/O设备与主机信息传送的控制方式
简答标准答题模板(考试默写)
主机与I/O设备信息传送共有四种控制方式:
- 程序查询方式:CPU循环轮询设备状态,CPU利用率低,硬件简单;
- 程序中断方式:设备就绪主动申请中断,CPU与外设并行,适合中低速设备;
- DMA方式:外设和主存直接批量传输,仅传输完成发中断,适合高速存储设备;
- 通道方式:专用通道硬件统一管理多台外设,多用于大型计算机。
选择填空高频考点
- CPU利用率最低:程序查询方式
- 高速硬盘大批量数据传输用:DMA方式
- 设备主动打断CPU工作:程序中断方式
- 有独立I/O处理器、多设备并发:通道方式
5.4 I/O接口(了解,填空/选择)
一、I/O接口的作用(高频选择)
- 寻址设备:区分系统中多个不同外设;
- 速度匹配/数据缓冲:主机速度快、外设慢,接口寄存器缓存数据;
- 电平、信号转换:主机与外设电气标准不同,接口做转换;
- 传送控制信号:传递读/写、就绪、中断请求等联络信号;
- 数据格式转换:串并行数据互相转换(如串口外设)。
二、接口内部三类寄存器(填空必考)
- 数据缓冲寄存器(DBR):存放主机和外设交换的数据;
- 状态寄存器(SR):存放设备工作状态(忙/就绪/出错标志);
- 控制寄存器(CR):存放CPU发给设备的控制命令。
三、接口分类(选择题)
- 按数据传送方式
- 并行接口:多位数据同时传输(打印机)
- 串行接口:一位一位依次传输(鼠标、USB)
- 按控制方式
- 中断接口:可向CPU发中断请求
- DMA接口:配合DMA控制器高速批量传输
四、常考判断/填空短句
- CPU不能直接和外设相连,必须通过I/O接口;
- 接口中存放设备忙/就绪信号的是状态寄存器;
- 解决主机与外设速度不匹配依靠接口的数据缓冲功能;
- 串行接口传输1位数据,并行接口同时传输多位数据。
配套选择题示例
- 下列不属于I/O接口功能的是()
A. 数据缓冲 B. 电平转换 C. 执行算术运算 D. 设备寻址
答案:C - 记录外设是否就绪的寄存器是()
A. 数据寄存器 B. 状态寄存器 C. 控制寄存器
答案:B
5.5 程序中断方式(了解,填空/选择)
一、核心基础考点
- 中断触发时机:每条指令执行完毕、进入取指周期前,CPU才会检测中断请求。
- 核心优点:CPU与外设并行工作,相比轮询查询,大幅提升CPU利用率。
- 适用设备:键盘、打印机等中低速I/O设备。
二、中断完整流程(填空常考顺序)
中断请求 → 中断判优 → 中断响应 → 保存断点 → 关中断 → 转入中断服务程序 → 开中断 → 中断返回
- 中断请求:外设就绪,向CPU发中断信号;
- 中断判优:多个设备同时请求时,按优先级选择先处理谁;
- 中断响应:CPU暂停当前程序,保存PC(断点地址);
- 中断服务:执行对应I/O读写操作;
- 中断返回:恢复断点,回到原来程序继续执行。
三、关键名词填空
- 断点:被打断的指令地址(存放在PC),中断结束后回到此处;
- 中断向量:存放中断服务程序入口地址,快速跳转;
- 中断屏蔽字:可以临时屏蔽低优先级中断,动态改变设备优先级;
- 关中断:响应中断时关闭中断,防止打断断点保存操作。
四、高频选择题考点
- CPU什么时候响应中断?
A. 指令执行中途 B. 一条指令执行完成后 C. 时钟任意时刻
答案:B - 中断方式相比程序查询最大优势?
A. 硬件简单 B. CPU和外设并行,效率高 C. 传输速度更快
答案:B - 保存被打断程序地址的寄存器是?
A. IR B. PC C. MAR
答案:B
五、判断小考点
- 外设主动发起请求才会触发中断(√)
- 中断传输适合硬盘大批量高速数据(×,高速批量用DMA)
- 中断服务结束后,CPU回到被打断的程序继续运行(√)
5.6 DMA方式(了解,填空/选择)
一、核心定义
DMA:直接存储器访问,外设和主存之间直接批量传输数据,不需要CPU逐字中转。
二、核心特点(高频选择题)
- 传输数据块时,总线由DMA控制器接管,不占用CPU运算;
- 仅传输开始、整块数据传输结束时,和CPU交互一次中断;
- 适合高速块设备:硬盘、固态硬盘、光驱;
- 对比中断:中断一次只传1个字节/字,DMA一次性传大批数据。
三、DMA控制器内部三大寄存器(填空必考)
- 主存地址寄存器MAR:存放要读写的内存起始地址
- 字数计数器WC:记录剩余待传输数据个数,每传一个自动减1,减到0代表传输完成
- 设备地址寄存器/控制寄存器:存放外设地址、读写控制信号
四、DMA工作流程
- CPU初始化DMA三个寄存器,启动外设;
- DMA接管总线,外设↔主存直接交换数据;
- 每传输一个数据,MAR+1、WC-1;
- WC=0,DMA发中断通知CPU传输结束。
五、常考选择/判断
- 硬盘大批量数据传输优先采用()
A.程序查询 B.中断 C.DMA
答案:C - DMA传输过程中,数据经过CPU吗?
答案:不经过,外设直接访问主存 - DMA计数器归零时会向CPU发送()
答案:中断请求 - 中断适合低速单字节传输,DMA适合高速批量传输(√)
- DMA全程不需要CPU参与任何操作(×)
改正:初始化、传输完成中断需要CPU参与,仅数据搬运阶段不用CPU。
六、简答一句话(选择题干)
DMA优点:大批量高速数据传输,CPU开销极小,提升高速外设I/O效率。
第七章
指令扩展码技术(🐦🔥)
7.2 操作数类型和操作类型
7.3 寻址方式(会考一种🌟)
约定:指令格式 OP 形式地址A;EA=有效地址(操作数真实内存地址)
- 立即寻址
规则
地址码A直接就是操作数,不用访问内存取数。
例题
指令:ADD #6
- OP:ADD(加法)
- #代表立即寻址,A=6
- 操作:把数值6和累加器内容相加
- 访存:只取指令,无额外访存
- 直接寻址
规则
形式地址A = 操作数内存地址,EA=A。
例题
指令:ADD 0007H
- A=0007H,EA=0007H
- 操作:去内存0007H单元取出数据,和累加器相加
- 额外访存:1次
- 寄存器寻址
规则
A是寄存器编号,操作数存放在CPU寄存器内,不访问内存。
例题
指令:ADD R2
- A=R2(2号通用寄存器)
- 操作:取出R2里存放的数字参与加法
- 额外访存:0次,速度极快
- 寄存器间接寻址
规则
A是寄存器编号,寄存器里存的是操作数内存地址;EA=®。
例题
指令:ADD (R1)
- A=R1,假设R1中存放地址0100H
- EA = (R1) = 0100H
- 操作:去内存0100H取数相加
- 额外访存:1次
- 存储器间接寻址(内存间接)
规则
A是内存地址,该单元存的仍是地址;要读两次内存才拿到操作数,EA=(A)。
例题
指令:ADD (0005H)
- 第一次访存:去0005H单元,读出内容=0200H(这是真正地址)
- EA=0200H
- 第二次访存:去0200H取操作数相加
- 额外访存:2次(考试高频坑点)
- 变址寻址
规则
EA = 变址寄存器IX + 形式地址A;专门用来遍历数组。
例题
指令:ADD A,IX
设A=0002H,变址寄存器IX=0005H
EA = 0002H + 0005H = 0007H
操作:访问内存0007H取数;循环时IX自动+1,依次读取数组连续元素
- 相对寻址(跳转专用)
规则
EA = PC(当前指令地址) + 偏移量A,用于分支、循环跳转。
例题
指令:JMP +4
当前PC=1000H,偏移A=4
EA = 1000H + 4 = 1004H
操作:跳转到内存1004H处执行下一条指令
7.5 RISC技术
7.5.3 RISC 和 CISC 的比较(必考🐦🔥)
一、基础定义
- CISC:复杂指令集计算机(Intel x86电脑CPU)
- RISC:精简指令集计算机(ARM手机、苹果M系列、RISC-V)
二、逐条对比考点(填空选择)
CISC(复杂指令集)
- 指令数量多,几百条,功能复杂
- 指令长度不固定,寻址方式繁多
- 有大量复杂指令,一条指令可完成多步操作
- 控制单元:微程序控制
- 寄存器数量少
- 编译简单,单条指令功能强,对编译器要求低
- 执行速度慢,指令执行周期不统一
- 代表:Intel/AMD x86处理器、8086
RISC(精简指令集)
- 指令数量少,几十条,只保留常用简单指令
- 指令长度固定,寻址方式少
- 只有简单基础指令,复杂操作靠多条指令组合
- 控制单元:硬布线逻辑控制,速度快
- 通用寄存器数量非常多
- 编译复杂,需要编译器拆分复杂运算
- 所有指令单周期执行,流水线效率高
- 功耗低、成本低,适合移动设备
- 代表:ARM、RISC-V、苹果M1/M2/M3
三、对比表格(考试直接默写)
| 对比项 | CISC复杂指令集 | RISC精简指令集 |
|---|---|---|
| 指令条数 | 多(200+) | 少(几十条) |
| 指令长度 | 长短不一 | 全部固定长度 |
| 寻址方式 | 种类多 | 极少 |
| 控制器 | 微程序控制 | 硬布线控制,更快 |
| 通用寄存器 | 数量少 | 数量极多 |
| 指令功能 | 单指令功能复杂 | 只做简单操作,复杂任务靠组合 |
| 指令执行周期 | 长短不同 | 大多单周期执行,流水线友好 |
| 编译器难度 | 简单 | 复杂,依赖编译器优化 |
| 功耗 | 功耗高 | 低功耗,移动端首选 |
| 典型芯片 | x86(Intel/AMD) | ARM、RISC-V、苹果M系列 |
四、高频选择题考点
- 手机、平板CPU采用:RISC
- 台式机Intel CPU属于:CISC
- 控制器采用硬布线、速度更快的是:RISC
- 指令长度不固定、指令繁多:CISC
- RISC寄存器更多,减少访存,提升速度(√)
- CISC流水线更容易设计(×,RISC更适合流水线)
五、简答标准答案
- CISC拥有大量复杂指令,指令长度可变,微程序控制,寄存器少,适合PC;
- RISC精简常用指令,定长指令、硬布线控制、寄存器多,流水线效率高、功耗低,广泛用于移动终端、嵌入式设备。
第八章
8.1 CPU的结构
8.1.2 CPU结构框图
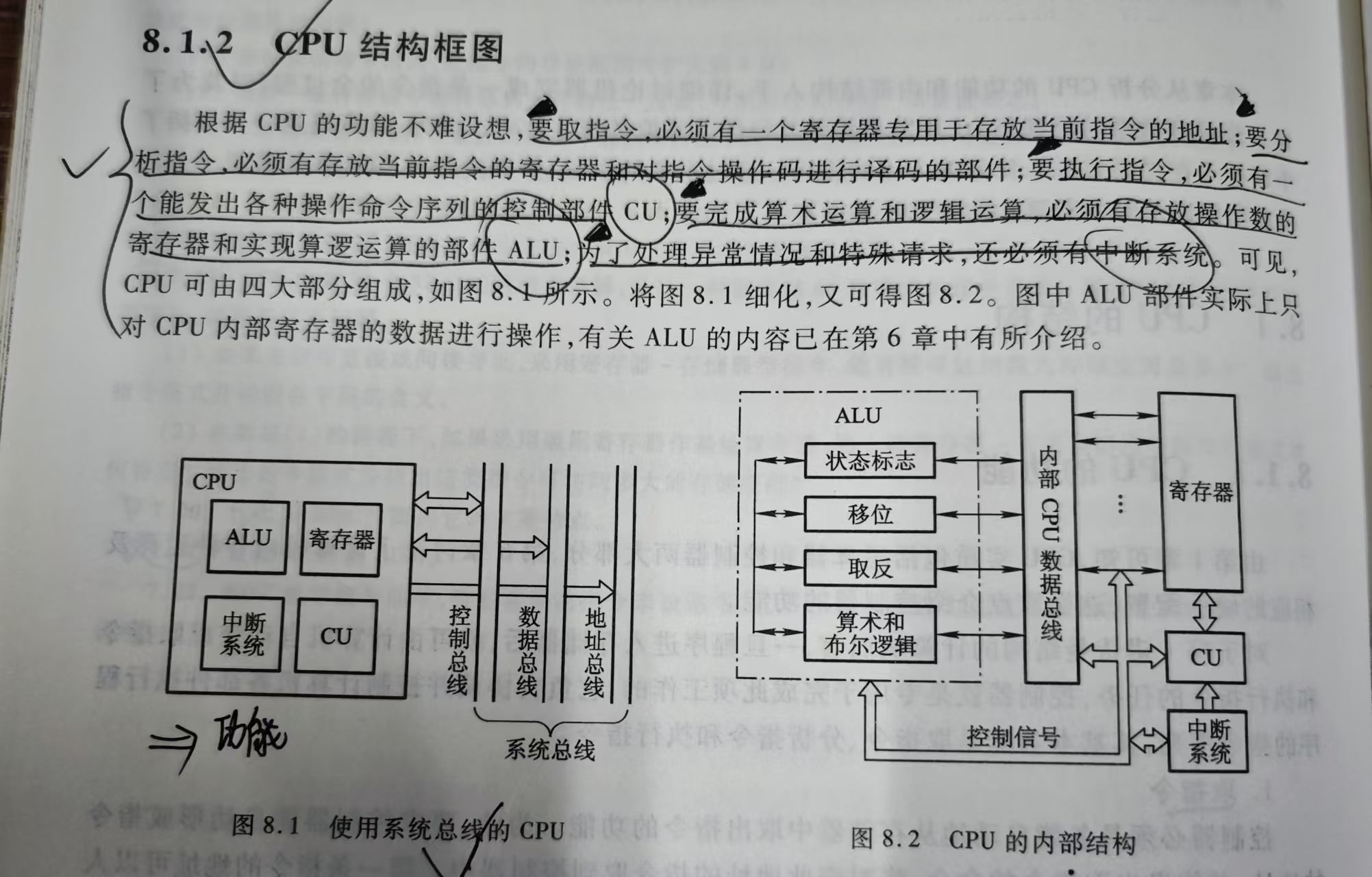
一、CPU整体两大模块
- 运算器(ALU相关,负责计算)
- 控制器(CU相关,负责发控制信号、取指令)
二、运算器组成部件
- 算术逻辑单元 ALU:完成加减乘除、与或非等运算
- 通用寄存器组 GR:存放运算数据,RISC芯片数量多
- 累加器 ACC:暂存ALU输入/运算结果
- 程序状态字 PSW(标志寄存器):保存运算标志(进位、溢出、正负、零标志)
- 移位寄存器:实现数据左移、右移操作
三、控制器组成部件
- 程序计数器 PC:存下一条指令内存地址,自动自增
- 指令寄存器 IR:存放当前正在执行的指令
- 指令译码器 ID:解析IR中的操作码,识别指令功能
- 控制单元 CU:根据译码结果,产生全部硬件控制信号
- 地址寄存器 MAR:存放访问主存的地址
- 数据寄存器 MDR:存放CPU与主存交互的数据
五、各部件极简功能填空考点
- PC:存下一条指令地址
- IR:存放当前指令
- MAR:存放内存地址
- MDR:CPU与主存之间数据缓冲
- ALU:完成算术、逻辑运算
- CU:产生整机控制信号
- PSW:存放运算状态标志
8.2 指令周期
指令周期(计组填空选择简答速记)
-
定义
指令周期 :CPU取出并执行一条完整指令的全部时间。
细分三层时间单位(从小到大):
-
时钟周期(节拍):CPU最小基本时间单位
-
机器周期:完成一次内存访问(取指/存取数),一个机器周期包含若干时钟周期
-
指令周期:由若干个机器周期组成
-
填空高频考点
-
所有指令公共阶段:取指周期
-
最小时间单位:时钟周期
-
完成一次访存的时间:机器周期
-
间接寻址指令指令周期最长,因为多一次访存
-
取指周期操作对全部指令完全相同
-
简答模板
指令周期是执行一条指令所需全部时间,由若干机器周期构成。每条指令都包含取指周期,用于从内存读取指令;再根据寻址方式不同,拥有不同数量的执行周期,寻址访存次数越多,指令周期越长。
8.3 指令流水(作用、几级流水?🌟)
指令流水线(计组填空/选择简答)
一、流水线作用
- 并行执行多条指令,把取指、译码、执行等步骤重叠进行,大幅提升CPU吞吐率(单位时间完成更多指令);
- 缩短多条指令总执行时间,提高CPU运行效率;
- 若没有流水,指令串行执行,必须等上一条完全结束才执行下一条,速度慢。
二、经典五级指令流水线(考试最常考,RISC标准五级)
每条指令拆分成5个阶段,同时多条指令错开并行:
- IF 取指:从主存取出指令,送入IR
- ID 译码/取寄存器:解析操作码,读出所需寄存器操作数
- EX 执行:ALU完成算术/逻辑运算、计算有效地址
- MEM 访存:读写主存(load/store指令用到)
- WB 写回:把运算结果写回通用寄存器
五级流水示意图(文字)
第1周期:指令1 IF
第2周期:指令1 ID,指令2 IF
第3周期:指令1 EX,指令2 ID,指令3 IF
第4周期:指令1 MEM,指令2 EX,指令3 ID,指令4 IF
第5周期:指令1 WB,指令2 MEM,指令3 EX,指令4 ID,指令5 IF
三、其他常见流水级数(了解选择题)
- 四级流水:IF、ID、EX、WB(省去单独访存阶段)
- 三级流水:取指、译码、执行(老式简单CPU)
- 现代高端CPU:十几级、二十多级超深流水线(Intel酷睿)
四、流水线三大冒险(选择填空)
流水会出错阻塞,称为冒险:
- 结构冒险:硬件资源冲突(同一周期同时访问存储器)
- 数据冒险:前后指令存在数据依赖,后一条要等前一条计算结果
- 控制冒险:跳转、分支指令改变PC,流水线清空重填
五、高频考点
- RISC标准流水线:五级(IF-ID-EX-MEM-WB)
- 流水线核心目的:重叠执行指令,提高吞吐率
- 一条指令执行时间没变,多条指令整体速度变快
- 跳转指令会造成流水线停顿/冲刷,降低流水效率
第九章
9.1 微操作命令的分析
- P375 存取周期、间址周期、中断周期的具体操作流程完全记忆🌟
一、基础概念
- 微操作:CPU最基本、不可再分的硬件动作(寄存器传送、ALU运算、读写内存、+1等)。
- 微操作命令:CU发出控制信号,驱动硬件完成对应微操作。
- 一条指令周期 = 若干机器周期;每个机器周期由一组固定微操作完成。
二、四大机器周期完整微操作命令(背诵核心)
(一)取指周期(所有指令共用)
任务:从主存取出指令送入IR,PC自增指向下一条指令
微操作命令:
- P C → M A R PC \to MAR PC→MAR:程序计数器内容送地址寄存器
- 1 → R 1 \to R 1→R:发内存读控制信号
- M ( M A R ) → M D R M(MAR) \to MDR M(MAR)→MDR:主存对应地址指令读到数据寄存器
- M D R → I R MDR \to IR MDR→IR:指令送入指令寄存器
- O P ( I R ) → I D OP(IR) \to ID OP(IR)→ID:指令操作码送译码器译码
- P C + 1 → P C PC+1 \to PC PC+1→PC:PC自增,准备下一条指令
(二)间址周期(间接寻址指令才有)
任务:取出有效地址EA
微操作命令:
- A D ( I R ) → M A R AD(IR) \to MAR AD(IR)→MAR:指令形式地址送MAR
- 1 → R 1 \to R 1→R:读内存
- M ( M A R ) → M D R M(MAR) \to MDR M(MAR)→MDR:取出存储单元内的有效地址
- M D R → A D ( I R ) MDR \to AD(IR) MDR→AD(IR):有效地址放回指令地址字段
(三)❌️❌️❌️执行周期(按不同寻址举例题,配微操作)
例题1:加法指令 ADD X(直接寻址, A C C + M ( X ) → A C C ACC+M(X) \to ACC ACC+M(X)→ACC)
微操作:
- A D ( I R ) → M A R AD(IR) \to MAR AD(IR)→MAR; 1 → R 1\to R 1→R
- M ( M A R ) → M D R M(MAR) \to MDR M(MAR)→MDR
- M D R → X MDR \to X MDR→X; A C C → A L U ACC \to ALU ACC→ALU
- A L U ( + ) → A C C ALU(+) \to ACC ALU(+)→ACC (两数相加写回累加器)
例题2:存数指令 STO X(把ACC存入主存X单元)
微操作:
- A D ( I R ) → M A R AD(IR)\to MAR AD(IR)→MAR
- A C C → M D R ACC \to MDR ACC→MDR
- 1 → W 1\to W 1→W:发内存写信号
- M D R → M ( M A R ) MDR \to M(MAR) MDR→M(MAR)
例题3:无条件跳转 JMP Y(相对/直接修改PC)
微操作:
- A D ( I R ) → P C AD(IR) \to PC AD(IR)→PC:有效地址送入PC,实现跳转
例题4:寄存器间接 ADD (R1)
- R 1 → M A R R1 \to MAR R1→MAR; 1 → R 1\to R 1→R
- M ( M A R ) → M D R M(MAR)\to MDR M(MAR)→MDR
- M D R → A L U MDR \to ALU MDR→ALU, A C C + A L U → A C C ACC+ALU \to ACC ACC+ALU→ACC
(四)中断周期(中断发生时,保存断点)
任务:把断点PC存入栈,切换中断服务程序入口
微操作:
- S P → M A R SP \to MAR SP→MAR; 1 → W 1\to W 1→W
- P C → M D R PC \to MDR PC→MDR
- M D R → M ( M A R ) MDR \to M(MAR) MDR→M(MAR):断点PC压栈保存
- S P − 1 → S P SP-1 \to SP SP−1→SP:栈指针调整
- 中断向量地址 → P C \to PC →PC:转入中断服务程序
三、考试简答题模板
- 取指周期微操作:送PC地址、读内存取指令、送入IR、PC自增;
- 间址周期微操作:取形式地址访存,读出有效地址;
- 执行周期随指令功能不同,完成取操作数、运算、存结果或修改PC;
- 中断周期微操作:保存断点到堆栈,更新PC为中断入口地址。
四、选择填空高频考点
- 所有指令必须执行取指周期微操作;
- 1 → R 1\to R 1→R 代表读主存, 1 → W 1\to W 1→W 代表写主存;
- P C + 1 → P C PC+1\to PC PC+1→PC 属于取指周期微操作;
- 跳转指令核心微操作:地址送入PC,改变程序执行顺序。
- 10条指令中的ADD和乘法 🍂
9.2 控制单元的功能
9.2.2 控制信号举例
- P382 例题9.1、9.2 🌟🌟🌟
9.2.3 多级时序系统 (选择/填空)
一、三级时序单位(从小到大必考排序)
- 时钟周期(节拍脉冲/T)
CPU最小时序单位,由晶振产生;所有寄存器传送、微操作都在节拍内完成。 - 机器周期(CPU周期)
完成一次完整访存操作(取指/取数/存数),包含若干时钟周期。
一台机器固定划分:取指周期、间址周期、执行周期、中断周期。 - 指令周期
取出并执行一条完整指令,由1个或多个机器周期组成。
填空必背排序
时钟周期 < 机器周期 < 指令周期
二、三者关系
- 1个机器周期 = 若干个时钟周期(节拍)
- 1个指令周期 = 若干个机器周期
- 所有微操作命令,都由节拍信号定时送出
三、多级时序系统作用
控制器CU依靠三级时序信号,按顺序、分时发出微操作控制信号,保证硬件动作有序执行,不会冲突。
四、两种时序控制方式(选择题高频)
- 同步控制(统一时序)
所有机器周期时钟周期数量固定,统一节拍,电路简单;效率偏低。 - 异步控制(可变机器周期)
不同指令机器周期长度不一样,快慢设备自动匹配,效率高,电路复杂。 - 现代CPU多用:同步+异步混合控制
五、高频选择/填空考点
- CPU最小时间单位:时钟周期(节拍)
- 完成一次主存读写的时间:机器周期
- 执行一条完整指令的总时间:指令周期
- 指令周期由若干机器周期 组成;机器周期由若干时钟周期组成。
- 取指周期属于机器周期,所有指令都包含该机器周期。
- 同步时序:全部机器周期节拍数相同;异步时序:不同指令机器周期长短可变。
六、典型选择题
- 下列时序单位最小的是()
A.指令周期 B.机器周期 C.时钟周期
答案:C - 一条间接寻址加法指令,指令周期包含几个机器周期?
答:取指周期+间址周期+执行周期,共3个机器周期。
第十章
10.1 组合逻辑设计
10.1.2 微操作的节拍安排(怎么、为什么?🐦🔥)
一、基础前提
- 机器周期由多个**时钟节拍(时钟周期T)**组成,每个节拍发一组微操作控制信号;
- 一个节拍内可以并行完成不冲突的微操作;
- 有先后依赖的微操作,必须分到不同节拍。
二、安排规则(怎么安排?4条核心)
规则1:存在数据依赖 → 分不同节拍
例: P C → M A R PC \to MAR PC→MAR 之后才能读内存,不能放同一拍
- T1: P C → M A R PC \to MAR PC→MAR
- T2: 1 → R , M ( M A R ) → M D R 1\to R,\ M(MAR)\to MDR 1→R, M(MAR)→MDR
原因:MAR还没收到地址,发读信号无效,必须等传送完成。
规则2:无冲突、互不依赖 → 同一节拍并行执行
例: M D R → I R MDR\to IR MDR→IR 和 P C + 1 → P C PC+1\to PC PC+1→PC 互不干扰,可以同一拍同时做。
规则3:访存动作需要完整一拍
1 → R 1\to R 1→R / 1 → W 1\to W 1→W 读写内存必须单独占一个节拍,存储器读写需要时间,不能和传送挤同一拍。
规则4:ALU运算、结果回送分两拍
1拍送两个操作数进ALU,下一拍输出结果写回寄存器。
三、举完整例子:取指周期节拍安排(标准4节拍)
设取指机器周期分为 T1、T2、T3、T4
- T1: P C → M A R PC \to MAR PC→MAR
为什么先做?要把指令地址送给地址寄存器,是访存前置步骤,必须最先。 - T2: 1 → R , M ( M A R ) → M D R 1\to R,\ M(MAR)\to MDR 1→R, M(MAR)→MDR
为什么放T2?MAR地址稳定后才能发读信号,内存读出数据到MDR,访存需要一整拍。 - T3: M D R → I R MDR \to IR MDR→IR
为什么放T3?MDR拿到指令数据后,才能送到指令寄存器IR保存。 - T4: O P ( I R ) → C U , P C + 1 → P C OP(IR)\to CU,\ PC+1\to PC OP(IR)→CU, PC+1→PC
为什么放T4:- IR稳定后才能送操作码译码;
- PC自增和译码无资源冲突,并行放在同一节拍,节省时间。
四、例题:直接寻址ADD X 执行周期节拍
T1: A D ( I R ) → M A R AD(IR) \to MAR AD(IR)→MAR
T2: 1 → R , M ( M A R ) → M D R 1\to R,\ M(MAR)\to MDR 1→R, M(MAR)→MDR
T3: M D R → A L U , A C C → A L U MDR\to ALU,\ ACC\to ALU MDR→ALU, ACC→ALU
T4: + , A L U → A C C +\ ,\ ALU\to ACC + , ALU→ACC
- T1先送地址;T2访存取数;T3送两个操作数进运算单元;T4执行加法并写回结果。
- 不能颠倒:前面没拿到操作数,ALU无法运算。
五、简答标准答案(怎么安排+为什么)
-
怎么安排节拍
① 有先后数据依赖的微操作分配到不同节拍;
② 无资源冲突、互不依赖的微操作放在同一节拍并行执行;
③ 主存读写信号 1 → R / W 1\to R/W 1→R/W单独占用一个节拍;
④ ALU输入、运算、结果写回分多节拍。
-
为什么这样安排
① 硬件数据传送需要时间,依赖操作错拍执行,保证数据稳定正确;
② 无关操作并行,减少总节拍数,提高CPU速度;
③ 存储器读写速度慢,单独一拍保证读写完成;
④ 严格时序防止寄存器输入输出门同时打开造成数据混乱。
六、选择填空考点
- 有数据先后关系的微操作不能放在同一节拍;
- 同一节拍可并行执行无资源冲突的微操作;
- 读/写内存信号必须单独占一个节拍;
- P C → M A R PC\to MAR PC→MAR 一定在发读信号 1 → R 1\to R 1→R之前的节拍。
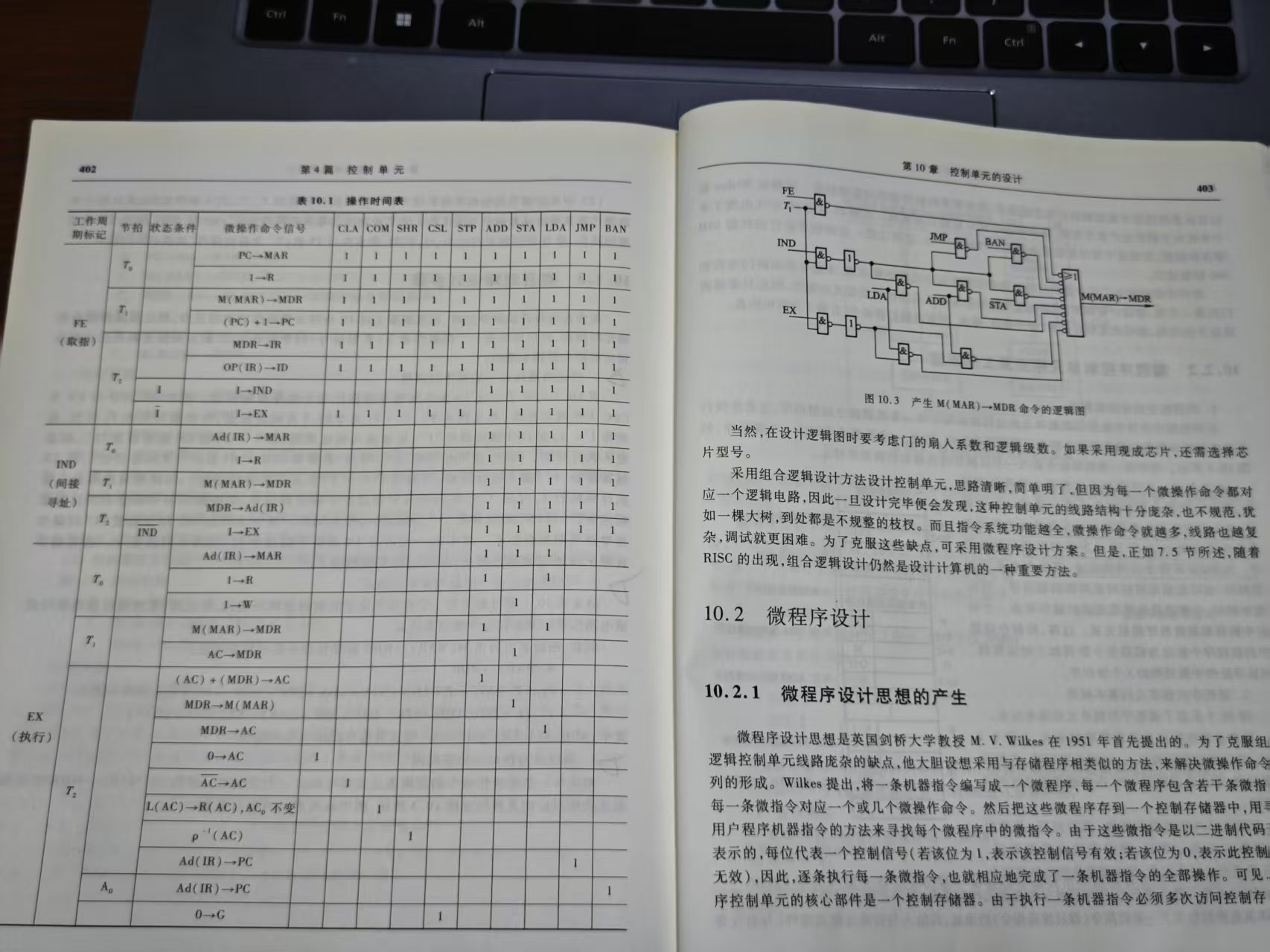
10.1.3 组合逻辑设计步骤 (由图写步骤🌟)

10.2 微程序设计
10.2.2 微程序控制单元框图及工作原理

一、微程序控制单元(CU)框图文字版(可直接画图默写)
核心组成部件
- 控制存储器 CM
存放全部微程序(每条机器指令对应一段微程序),只读ROM。 - 微地址寄存器 μAR
存下一条微指令在CM中的地址,相当于微程序级PC。 - 微指令寄存器 μIR
从CM读出的当前微指令暂存于此,分为两部分:- 微操作控制字段:输出所有硬件控制信号;
- 顺序控制字段:决定下一条微地址(μAR来源)。
- 地址转移逻辑(微地址形成电路)
根据:当前微指令顺序字段、机器指令操作码OP、标志位PSW,生成新微地址送入μAR。 - 微命令译码器
对μIR的微操作字段译码,产生微操作控制信号(如 P C → M A R 、 1 → R PC\to MAR、1\to R PC→MAR、1→R等)。
框图数据流结构
机器指令OP(IR) ────┐
标志PSW ├──→ 地址转移逻辑 → μAR(微地址寄存器)
μIR顺序字段 ────┘
↓
控制存储器CM ←──── μAR
↓(读出微指令)
μIR 微指令寄存器
├─微操作字段 → 微命令译码器 → 整机硬件微操作控制信号
└─顺序控制字段 → 地址转移逻辑二、工作原理(完整流程,分4步)
步骤1:取机器指令(公共微程序段:取指微程序)
- μAR存放取指微程序入口微地址;
- 从CM读出取指微指令送入μIR;
- 译码输出取指周期全部微操作: P C → M A R 、 1 → R 、 M D R → I R 、 P C + 1 → P C PC\to MAR、1\to R、MDR\to IR、PC+1\to PC PC→MAR、1→R、MDR→IR、PC+1→PC;
- 取指完成后,IR中得到机器指令,操作码OP送入地址转移逻辑。
步骤2:根据机器OP跳转对应微程序
地址转移逻辑接收OP,生成该机器指令专属微程序入口地址,送入μAR。
例:ADD指令 → 加法微程序入口;JMP → 跳转微程序入口。
步骤3:逐条执行该指令的微程序
循环:
- μAR给出地址,CM读出微指令→μIR;
- 微操作字段译码,发出各类控制信号,完成寄存器传送、访存、ALU运算;
- 顺序控制字段配合地址转移逻辑,计算下一条微地址更新μAR;
- 重复直到该机器指令全部微指令执行完毕。
步骤4:微程序结束,回到取指微程序入口
一条机器指令执行完成后,地址转移逻辑自动将取指微程序入口地址送入μAR,重新取下一条机器指令,循环往复。
三、关键概念填空考点
- 存放微程序的硬件:控制存储器CM(ROM)
- 存放当前微指令:μIR 微指令寄存器
- 存下一条微指令地址:μAR 微地址寄存器
- 机器指令OP用来:生成对应微程序入口地址
- 微指令两大部分:微操作控制字段、顺序控制字段
- 微程序:一条机器指令对应一段微程序;一段微程序由多条微指令组成;一条微指令产生一组微命令。
四、简答标准答题模板
-
微程序控制单元框图组成
由控制存储器CM、微地址寄存器μAR、微指令寄存器μIR、地址转移逻辑、微命令译码器五部分构成。CM存储所有微程序;μAR提供微地址读取微指令;μIR存放当前微指令;译码器输出微操作信号;地址转移逻辑负责微程序跳转。
-
工作原理
-
初始化μAR为取指微程序入口;
-
从CM读出微指令到μIR,译码输出微操作,完成取机器指令;
-
指令操作码送入地址转移逻辑,生成当前机器指令对应的微程序入口,更新μAR;
-
循环读取、执行该段微程序内所有微指令,完成指令功能;
-
指令执行完毕,μAR重置为取指微程序地址,重复上述流程。
五、对比选择题考点
- 微程序控制:用软件(微程序)产生控制信号,硬件简单,易修改,CISC主流;
- 硬布线控制:纯硬件组合逻辑生成控制信号,速度快,RISC主流。
10.2.6 静态微程序设计和动态微程序设计 🌟
10.2.7 毫微程序设计 🌟


一、静态微程序设计
- 控制存储器介质:ROM(只读存储器)
- 核心特点
微程序在CPU出厂前一次性烧录固化,运行过程只能读、不能修改/重写。 - 优点:硬件简单、速度快、成本低、可靠性高。
- 缺点:完全无灵活性,不能新增指令、不能优化微代码。
- 适用:传统CISC处理器、普通微型计算机。
二、动态微程序设计
- 控制存储器介质:RAM / EPROM / EEPROM(可读写)
- 核心特点
开机可从外设加载微程序;运行期间能修改、替换、重写微程序。同一套硬件可切换不同指令集(如切换RISC/CISC仿真)。 - 优点:灵活性极强,支持自定义指令、调试优化微程序。
- 缺点:硬件复杂,需配套加载电路,速度略慢、成本更高。
- 适用:教学CPU、可重构处理器、大型仿真主机。
三、毫微程序设计(三级控制结构,两层微程序)
核心概念
把控制信号分为两层:
- 微指令层:面向机器指令,完成取指、寻址、数据通路传送;
- 毫微指令层 :底层硬件级,直接生成最基础的微操作控制信号。
配套两级存储:
- 微程序存微控制存储器μCM;
- 毫微程序存毫微控制存储器nCM。
工作流程
机器指令 → 微程序(微指令)→ 调用毫微程序 → 输出硬件控制信号
多条功能相近的微指令可共享同一段毫微程序,大幅减少存储容量。
优缺点
✅ 毫微指令复用率高,大幅缩减控制存储器总容量;规整、易设计。
❌ 两级查表,多一次访存,速度变慢;硬件结构复杂。
四、三者对比表格
| 对比维度 | 静态微程序 | 动态微程序 | 毫微程序设计 |
|---|---|---|---|
| 存储介质 | ROM只读 | RAM/EPROM可读写 | 两级ROM:μCM + nCM |
| 能否修改微程序 | 不可修改固化 | 运行可加载改写 | 微程序可静态/动态,底层毫微程序一般固化 |
| 层次结构 | 单层微程序 | 单层微程序 | 双层:微程序+毫微程序 |
| 微指令复用 | 无复用机制 | 无复用机制 | 毫微指令全局共享,节省存储空间 |
| 速度 | 最快 | 中等 | 最慢(两次查表) |
| 灵活性 | 最低 | 最高 | 中等 |
| 典型用途 | 普通PC、老式CISC | 教学、可重构CPU、仿真机 | 大型机高性能系统 |
五、简答背诵模板
- 静态微程序:CM用ROM,微程序出厂固化只读,结构简单速度快,无法修改。
- 动态微程序:CM采用可读写存储器,运行可加载、替换微程序,灵活度高,但硬件复杂。
- 毫微程序设计采用两级存储架构,分为微程序层与毫微程序层,多条微指令共享毫微操作,节省控制存储器空间;但两级读取会降低执行速度。
六、填空/选择高频考点
- 出厂固化、不可改写:静态微程序
- 运行可更换指令集、改写微代码:动态微程序
- 两层存储、共享底层控制信号:毫微程序设计
- 毫微程序最大优势:减少控制存储器容量
- 速度最慢的是毫微程序设计,最快是静态微程序。