百度开源 Unlimited OCR:一次推理转录几十页文档,KV 缓存恒定不增长!
百度新作,用 Reference Sliding Window Attention 替换全部解码器注意力层,32K 长度一次跑完多页文档。
目录
- [1. 项目简介------它是什么?](#1. 项目简介——它是什么?)
- [2. 它能做什么?------三大核心能力](#2. 它能做什么?——三大核心能力)
- [3. 为什么现有 OCR 不够好?------痛点分析](#3. 为什么现有 OCR 不够好?——痛点分析)
- [4. 核心原理------R-SWA 机制详解](#4. 核心原理——R-SWA 机制详解)
- [5. 快速上手------三种推理方式](#5. 快速上手——三种推理方式)
- [6. 适用场景与优缺点](#6. 适用场景与优缺点)
- [7. 总结](#7. 总结)
1. 项目简介------它是什么?
Unlimited OCR 是百度近期开源的端到端 OCR 模型,定位一句话概括:让 OCR 模型像人一样,长时间抄写不掉速。
它的核心目标是在一次前向推理中,把几十页的文档完整转录为文本------不是"一页一页分别 OCR",而是一口气跑完,效率从头到尾恒定。
项目以 DeepSeek-OCR 为基线,在此基础上做了关键改进:将解码器中所有注意力层替换为自研的 Reference Sliding Window Attention(R-SWA),使得 KV 缓存在整个解码过程中保持恒定大小,不再随输出长度线性增长。
🔗 项目地址:https://github.com/baidu/Unlimited-OCR
🔗 论文地址:https://arxiv.org/abs/2606.23050
🔗 Hugging Face 模型:https://huggingface.co/baidu/Unlimited-OCR
🔗 ModelScope 模型:https://modelscope.cn/models/PaddlePaddle/Unlimited-OCR
📜 License:CC BY 4.0
2. 它能做什么?------三大核心能力
| 能力 | 说明 | 配置模式 |
|---|---|---|
| 🖼️ 单图文档解析 | 一张图片(合同、发票、手写笔记等)一次推理输出完整文本 | gundam(切片模式,高精度)或 base(整图模式) |
| 📑 多页文档解析 | 多张页面图片一次性送入,联合解析输出连贯文本 | 仅 base 模式 |
| 📄 PDF 文档解析 | 自动将 PDF 转为图片,再进行多页联合解析 | 仅 base 模式 |
两种图像配置模式的区别:
| 参数 | gundam 模式 |
base 模式 |
|---|---|---|
base_size |
1024 | 1024 |
image_size |
640 | 1024 |
crop_mode |
✅ 开启(切片处理高分辨率图) | 关闭(整图输入) |
| 适用场景 | 单张高清图片 | 多页 / PDF 联合解析 |
3. 为什么现有 OCR 不够好?------痛点分析
近年来端到端 OCR 模型(如 DeepSeek-OCR)让 OCR 再次火了起来。核心思路是用大语言模型(LLM)做解码器,借助语言模型的先验分布来提升识别精度------效果确实好,但代价也很明显:
❌ 传统 LLM 解码器的三大痛点
- KV 缓存线性增长:每生成一个 token 就多一份 KV 缓存,输出越长,显存占用越大
- 推理速度逐渐变慢:KV 缓存膨胀导致注意力计算量持续增长,长序列解码越来越慢
- 无法一次跑完长文档:受显存限制,单次推理往往只能处理 1-2 页
🧠 人类的类比
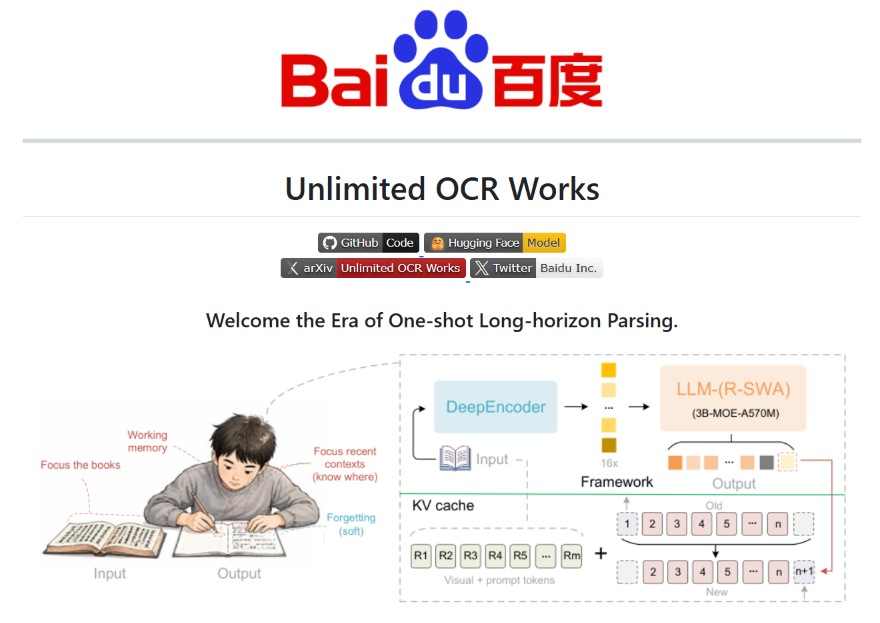
论文提出了一个非常形象的类比:人类在长时间抄写任务中不会效率下降。你抄写第 1 行和抄写第 100 行的速度是一样的------因为人类有「工作记忆」机制,不需要记住之前所有内容,只需要参考最近的内容就够了。
Unlimited OCR 就是要让模型也拥有这种「工作记忆」能力。
4. 核心原理------R-SWA 机制详解
🔑 关键创新:Reference Sliding Window Attention(R-SWA)
R-SWA 是 Unlimited OCR 的核心创新,它替换了解码器中所有注意力层(不是部分替换,是全部替换!),核心思想:
传统注意力:每个 token 要关注之前所有 token → KV 缓存线性增长
R-SWA: 每个 token 只关注固定窗口内的 token → KV 缓存恒定📐 工作机制
R-SWA 的工作方式可以类比人类的「抄写工作记忆」:
- 滑动窗口 :解码时只保留最近
W个 token 的 KV 缓存(类似人类只看最近几行) - 参考锚点:窗口之外不丢弃,而是保留若干关键锚点的 KV 作为「参考」(类似人类偶尔回头看开头或标题)
- 恒定缓存:窗口大小 + 锚点数量固定 → KV 缓存总量恒定,不随输出长度增长
这意味着:
- 显存恒定:无论输出 1000 还是 32000 个 token,KV 缓存占用相同
- 速度恒定:注意力计算量不随序列增长而增加
- 质量保持:参考锚点机制确保模型不会丢失对全局上下文的感知
🏗️ 整体架构
输入图像
↓
DeepSeek-OCR 编码器(高压缩率)
↓
视觉 token 序列
↓
Unlimited-OCR 解码器(全部注意力层替换为 R-SWA)
↓
32K 长度内的完整文本输出结合 DeepSeek-OCR 编码器的高压缩率(将整页图像压缩为少量 token)+ R-SWA 的恒定 KV 缓存,模型可以在标准 32K 最大长度下,一次推理转录几十页文档。
🔬 更深远的意义
论文特别强调:R-SWA 不只是 OCR 专用------它是一种通用的「解析注意力机制」,同样适用于:
- 🎙️ ASR(语音识别):长时间语音转录
- 🌐 翻译:长文档翻译
- 📝 任何需要长序列输出的生成任务
5. 快速上手------三种推理方式
Unlimited OCR 提供了三种推理方案,适配不同的部署场景:
方式一:Transformers(最简单,适合单机调试)
环境要求:Python 3.12.3 + CUDA 12.9
bash
pip install torch==2.10.0 torchvision==0.25.0 transformers==4.57.1
pip install Pillow==12.1.1 pymupdf==1.27.2.2 einops==0.8.2单图推理示例:
python
from transformers import AutoModel, AutoTokenizer
model_name = 'baidu/Unlimited-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
use_safetensors=True,
torch_dtype=torch.bfloat16,
)
model = model.eval().cuda()
# 单图 --- gundam 模式(切片,高精度)
model.infer(
tokenizer,
prompt='<image>document parsing.',
image_file='your_image.jpg',
output_path='output/',
base_size=1024, image_size=640, crop_mode=True,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=128,
save_results=True,
)多页 / PDF 推理示例:
python
import tempfile, fitz # PyMuPDF
# PDF → 图片转换
def pdf_to_images(pdf_path, dpi=300):
doc = fitz.open(pdf_path)
tmp_dir = tempfile.mkdtemp(prefix='pdf_ocr_')
mat = fitz.Matrix(dpi / 72, dpi / 72)
paths = []
for i, page in enumerate(doc):
out = os.path.join(tmp_dir, f'page_{i+1:04d}.png')
page.get_pixmap(matrix=mat).save(out)
paths.append(out)
doc.close()
return paths
# 多页联合解析(仅 base 模式)
model.infer_multi(
tokenizer,
prompt='<image>Multi page parsing.',
image_files=pdf_to_images('your_doc.pdf', dpi=300),
output_path='output/',
image_size=1024,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=1024,
save_results=True,
)方式二:vLLM(生产级,高性能推理)
官方提供了专用 Docker 镜像:
bash
# 默认版(CUDA 13.0)
docker pull vllm/vllm-openai:unlimited-ocr
# Hopper GPU 版(CUDA 12.9)
docker pull vllm/vllm-openai:unlimited-ocr-cu129部署指南详见:https://recipes.vllm.ai/baidu/Unlimited-OCR
方式三:SGLang(支持批量并发推理)
适合需要批量处理大量图片或 PDF 的场景:
安装:
bash
uv venv --python 3.12
source .venv/bin/activate
uv pip install wheel/sglang-0.0.0.dev11416+g92e8bb79e-py3-none-any.whl
uv pip install kernels==0.11.7
uv pip install pymupdf==1.27.2.2启动服务:
bash
python -m sglang.launch_server \
--model baidu/Unlimited-OCR \
--served-model-name Unlimited-OCR \
--attention-backend fa3 \
--page-size 1 \
--mem-fraction-static 0.8 \
--context-length 32768 \
--enable-custom-logit-processor \
--disable-overlap-schedule \
--skip-server-warmup \
--host 0.0.0.0 \
--port 10000批量推理(自动启动 SGLang 服务,并发请求):
bash
# 图片目录批量处理
python infer.py \
--image_dir ./examples/images \
--output_dir ./outputs \
--concurrency 8 \
--image_mode gundam
# PDF 文档批量处理
python infer.py \
--pdf ./examples/document.pdf \
--output_dir ./outputs \
--concurrency 8 \
--image_mode gundam6. 适用场景与优缺点
✅ 最佳适用场景
| 场景 | 说明 |
|---|---|
| 📚 长文档数字化 | 合同、论文、书籍等几十页文档一次性转录 |
| 📋 表单/发票批量处理 | 企业级文档自动化 |
| 🔍 档案检索预处理 | 先 OCR 转文本,再做语义检索 |
| 🎙️ 长语音转录 | R-SWA 同样适用于 ASR 场景 |
| 🌐 长文本翻译 | R-SWA 的恒定缓存对翻译也有优势 |
⚖️ 优缺点对比
| 优点 | 缺点 |
|---|---|
| 🟢 KV 缓存恒定,长序列推理不掉速 | 🔴 需要较强 GPU(推荐 bfloat16 + CUDA 12.9+) |
| 🟢 32K 长度一次跑完多页文档 | 🔴 模型权重较大,部署门槛高于轻量 OCR |
| 🟢 gundam 模式切片处理,高分辨率图也精准 | 🔴 多页/PDF 只支持 base 模式,精度略低于 gundam |
| 🟢 三种推理方案覆盖调试到生产 | 🔴 SGLang 需要安装特定 wheel,环境配置稍复杂 |
| 🟢 R-SWA 是通用机制,适用 ASR/翻译等 | 🔴 项目刚开源(2026.06),生态和文档还在早期 |
| 🟢 百度出品 + 有论文支撑,质量可信 | 🔴 No-repeat ngram 参数需手动调优(size=35, window=128/1024) |
7. 总结
Unlimited OCR 解决的是端到端 OCR 模型的一个根本性问题:长序列推理时 KV 缓存膨胀导致的效率下降。它用 R-SWA(Reference Sliding Window Attention)替换全部解码器注意力层,让 KV 缓存恒定不变,实现了「像人一样长时间抄写不掉速」的效果。
结合 DeepSeek-OCR 编码器的高压缩率,模型在标准 32K 长度下一次推理就能转录几十页文档。而且 R-SWA 不限于 OCR------它本质上是一种通用的长序列解析注意力机制,对 ASR、翻译等任务同样有价值。
三种推理方案(Transformers / vLLM / SGLang)从单机调试到生产部署全覆盖,百度还提供了 Hugging Face Spaces 在线 demo,你可以先去体验再决定是否本地部署。
推荐指数:⭐⭐⭐⭐⭐ (5/5)
百度在 DeepSeek-OCR 基础上做出了真正的架构级创新,R-SWA 的恒定 KV 缓存设计对整个长序列生成领域都有启发意义。开源权重 + 论文 + 三种推理方案,诚意十足。
原文链接 :https://github.com/baidu/Unlimited-OCR
论文链接 :https://arxiv.org/abs/2606.23050
License:CC BY 4.0
标签:#百度 #UnlimitedOCR #OCR #深度学习 #R-SWA #KV缓存 #长序列推理 #开源项目
分类:原创文章