一文讲清 RAG 效果如何衡量:从检索指标到生成可信度的企业级评估体系
摘要
RAG(Retrieval-Augmented Generation)已经成为企业构建大模型应用的标准架构,但"能用"不等于"好用","回答流畅"也不代表"结果正确"。
在真实生产环境中,RAG 的效果评估远比模型本身更复杂,它涉及检索质量、上下文相关性、生成忠实度以及端到端一致性等多个维度。
本文从企业级实践出发,系统讲解如何衡量 RAG 的效果,构建一套可量化、可监控、可迭代的评估体系,并结合架构设计、指标体系、工程实现与面试高频问题,帮助你真正理解 RAG 的"好坏标准"。
前言
在一次企业知识库项目上线后,我们遇到一个非常典型的问题:
- 离线测试效果很好
- demo 准确率超过 85%
- 但线上用户反馈"答案不稳定"
进一步拆解后发现:
- 有些问题检索错了文档
- 有些问题召回正确但排序错误
- 有些问题上下文正确但模型"编造补充"
- 有些问题甚至完全依赖模型参数知识回答
这让我意识到一个关键事实:
RAG 的效果不是一个指标,而是一条完整链路的综合结果。
因此,如果只看"回答是否正确",在工程上是远远不够的。
本文适合:
- Java / 后端工程师转 AI 应用开发
- 做企业知识库 / 智能客服系统的研发人员
- 面试 RAG / LLM / AI 架构岗位
- 想理解工业级 RAG 评估体系的人
技术背景
Retrieval-Augmented Generation 的核心思想是:
用"检索系统 + 大模型"替代"纯参数记忆模型"。
它的优势在于:
- 可更新知识
- 可接入私有数据
- 减少模型幻觉
- 降低微调成本
但在企业落地后暴露出一个核心问题:
传统软件只需要判断"对/错",但 RAG 需要判断"是否可信"。
因此,RAG 评估变成一个多维系统工程。
核心概念:RAG 的效果到底在衡量什么?
很多人误以为 RAG 效果 = 答案正确率。
但在工程上,这个定义是严重不足的。
RAG 的效果至少包含四个层级:
1. 检索效果(Retrieval Effectiveness)
衡量:
有没有找到"该找到的内容"
关键问题:
- 是否召回正确文档
- 是否遗漏关键 chunk
- 是否引入噪声文档
2. 上下文质量(Context Quality)
衡量:
给 LLM 的信息是否"干净且相关"
关键问题:
- chunk 是否语义完整
- 是否存在信息污染
- 是否冗余导致注意力稀释
3. 生成可信度(Generation Faithfulness)
衡量:
模型是否"只基于上下文回答"
关键问题:
- 是否产生幻觉
- 是否引用不存在信息
- 是否扩展推理过度
4. 端到端正确性(End-to-End Correctness)
衡量:
最终答案是否正确(无论过程是否正确)
一个真实案例
用户问题:
公司A融资情况
系统返回:
- chunk1:公司介绍
- chunk2:错误融资数据
- chunk3:新闻摘要
模型输出:
融资金额 2 亿
问题:
- 检索错(chunk2污染)
- 生成错(依赖错误证据)
- 端到端错误
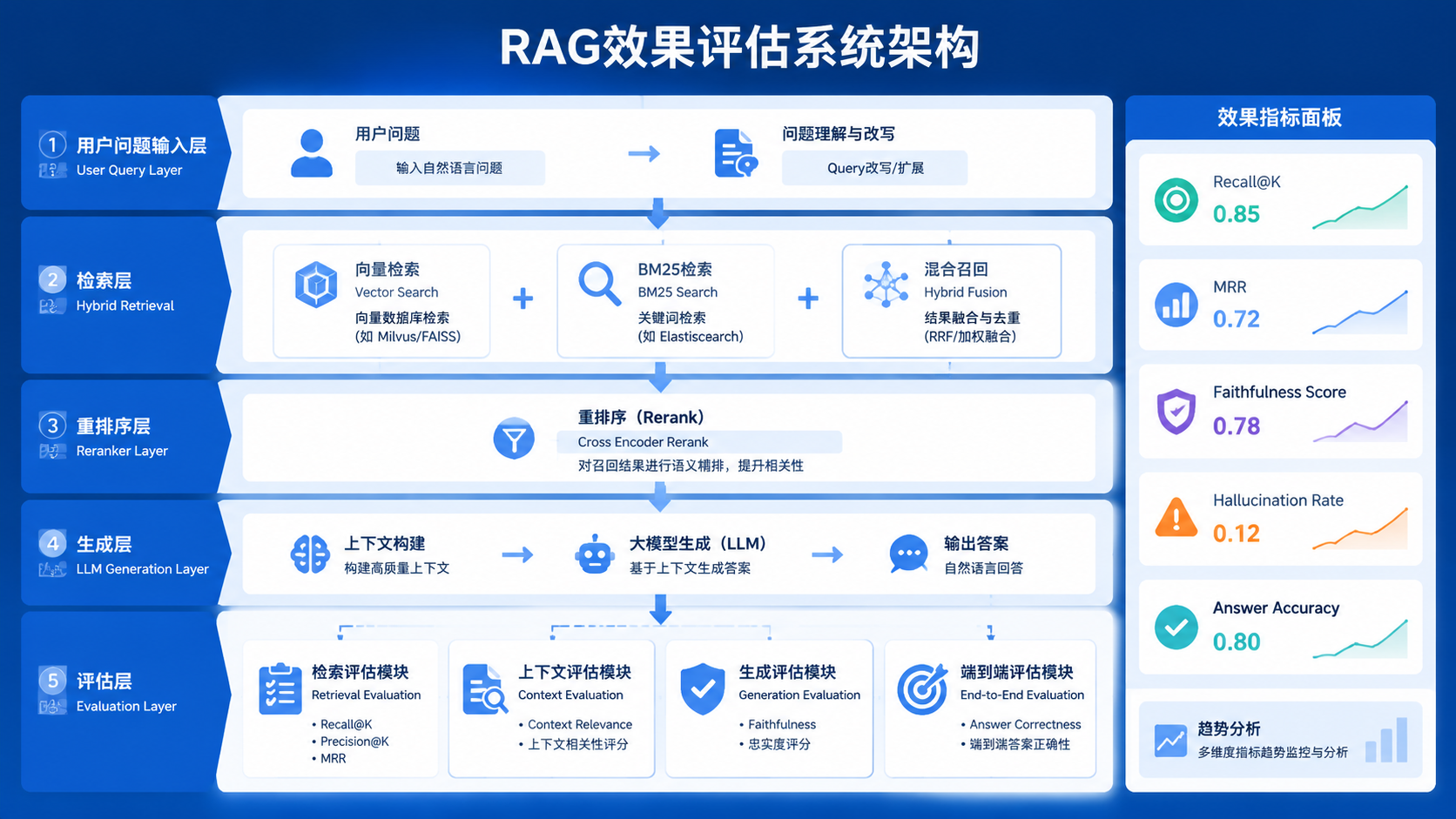
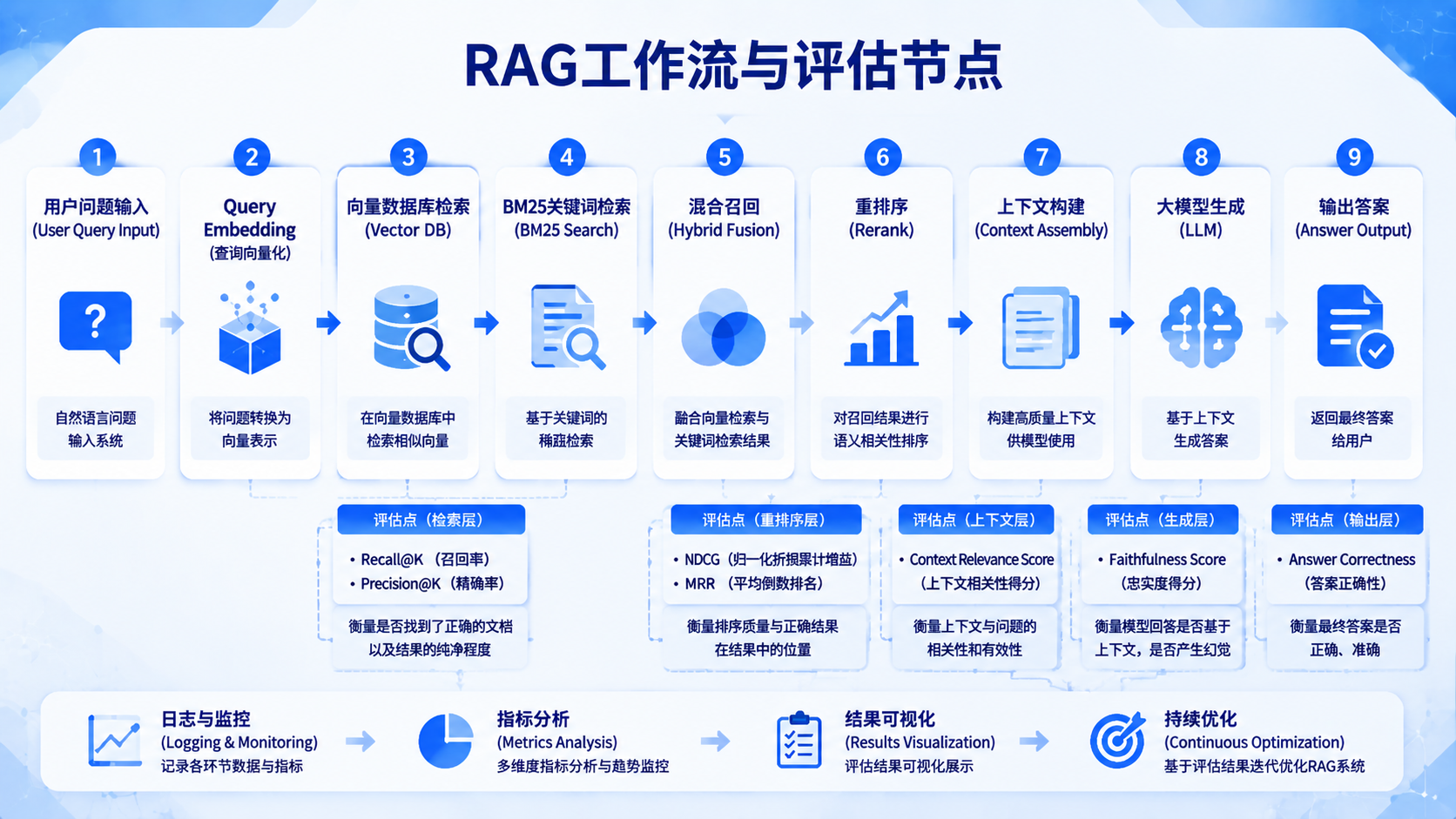
RAG 效果评估整体架构
RAG 工作流程与评估点分布
核心指标体系:如何量化 RAG 的效果
RAG 的评估必须拆解,否则无法优化。
一、检索层指标(Retrieval Metrics)
1. Recall@K
衡量:
正确答案是否被召回,解决找到没
公式:
正确文档是否出现在 Top-K
适用场景:
- 知识库问答
- FAQ 系统
2. Precision@K精确度
衡量:
返回结果的"纯净度"
问题:
- 是否混入无关 chunk
3. MRR(Mean Reciprocal Rank)平均倒数排名
衡量:
正确答案排名是否靠前,多快找到的
企业经验
在实际项目中:
- Recall 不够 → 增加 hybrid search
- Precision 不够 → 加 rerank
- MRR 不够 → 优化 chunk
二、上下文质量评估(Context Evaluation)
这一层经常被忽略,但影响极大。
关键指标:
- Context Relevance Score 上下文相关性得分
- Context Redundancy Rate 上下文冗余率
- Context Noise Ratio 上下文噪声值
常见问题
- chunk 太长 → 信息稀释
- chunk 太短 → 语义断裂
- embedding 不准 → 语义错位
三、生成层评估(Generation Evaluation)
这是 RAG 最关键的一层。
1. Faithfulness(忠实度)
衡量:
回答是否可以被 context 支撑
2. Hallucination Rate(幻觉率)
衡量:
模型是否编造信息
3. Answer Relevancy(答案相关性)
衡量:
模型回复是不是想要的
评估方法:
- 句子拆解(claim extraction)
- 逐条对齐 context
- LLM-as-judge 一个RAG端到端的评估架构的核心思路,意思是用LLM来当裁判,自动打分
四、端到端评估(End-to-End)
最终衡量:
用户看到的答案是否正确
用户可以对答案进行点踩
企业级 RAG 评估系统设计
在生产环境中,通常采用如下架构:
评估系统架构
- 离线评估系统(Batch Evaluation)
- 在线评估系统(Online Monitoring)
- A/B Test 平台
- 人工标注系统
数据结构设计
json
{
"query": "公司A融资情况",
"retrieved_docs": ["chunk1", "chunk2"],
"generated_answer": "2亿",
"ground_truth": "1亿",
"metrics": {
"recall": 0.82,
"precision": 0.75,
"faithfulness": 0.6,
"correctness": 0.5
}
}向量数据库实践
在企业系统中常用 Milvus:
- 存储 embedding
- 支持 ANN 检索
- 支持 hybrid index
企业实践:真实 RAG 系统如何评估效果
在一个企业知识库项目中,我们采用如下策略:
业务背景
- 医疗行业知识库
- 10 万+文档
- 日查询量 50 万+
技术选型
- LangChain4j
- Milvus 向量库
- Elasticsearch BM25
- Cross Encoder rerank
评估策略
离线评估
- 构建 1000 条标准问题集
- 标注 ground truth
- 定期跑评估任务
在线评估
- 用户反馈(点赞/点踩)
- 点击行为
- follow-up query
关键问题
问题1:线上效果比离线差
原因:
- 数据分布偏移
- query 更复杂
- chunk coverage 不足
问题2:召回率高但答案错
原因:
- rerank 不准
- context contamination
问题3:答案看似正确但不可追溯
原因:
- hallucination
- context ignored
性能优化与效果提升策略
RAG 的优化本质是"提高可用信息密度"。
1. Chunk 优化
- semantic chunk
- sliding window
- overlap chunk
效果:
- ↑ recall
- ↑ context quality
2. Hybrid Search
- vector + BM25
效果:
- ↑ recall
- ↑ robustness
3. Rerank 模型
- cross encoder
效果:
- ↑ precision
- ↑ MRR
4. Prompt 约束
- 强制引用 context
- 禁止自由发挥
效果:
- ↓ hallucination
5. Cache 优化
- embedding cache
- prompt cache
效果:
- ↓ latency
- 不影响正确性
常见踩坑总结
1. 只看答案不看证据
错误认知:
对 = 模型对
实际:
- 可能是"猜对"
2. 没有 ground truth
导致:
- 无法衡量 correctness
3. 忽略 rerank
导致:
- topK 全是噪声
4. chunk 不合理
- 太大:噪声多
- 太小:语义断裂
5. 只做 embedding 检索
缺失:
- keyword recall
- precision control
面试高频问题
1. 如何评估 RAG 效果?
考察:
- 是否理解多指标体系
2. 为什么需要 recall + faithfulness 双指标?
考察:
- 检索 vs 生成分离思想
3. 如何降低 hallucination?
回答方向:
- prompt 约束
- context 增强
- rerank
4. 为什么 embedding 不能保证正确?
考察:
- 向量语义局限
总结
RAG 的效果评估,本质上不是一个指标问题,而是一个系统工程问题。同时关注:
- 检索是否准确
- 上下文是否干净
- 生成是否忠实
- 结果是否可追溯