概念 - 传统训练缩放、TTCS
Test-Time Compute Scaling 推理时计算缩放 / 测试阶段算力扩展,业内简称:TTS
模型权重完全固定、不重新训练、不微调,仅在推理 / 测试阶段主动增加算力消耗,换取更高推理准确率
算力投入越多,任务效果越好,存在可量化的缩放定律(缩放定律)
传统 Pre-training Scaling(预训练缩放)
提升效果靠堆训练算力:
加大模型参数量、扩充训练数据、延长训练步数;成本极高,模型一旦训练完成,推理时只能单次前向,无法再提升能力
Test-Time Compute Scaling(TTCS)
训练完全结束,模型权重不变;
只在用户提问推理时额外消耗算力,让模型 "多思考、多试错、多验证",显著提升数学、代码、逻辑推理能力
(OpenAI o1、DeepSeek R1、Gemini Deep Think 底层核心技术)
Pre-training Scaling vs Test-time Scaling(预训练缩放 vs 推理时算力缩放)
participants pɑːˈtɪsɪpənt
n. 参加者,参与者
adj. 参与的
quo 拉丁语,原形 quod,本义:状态、情形、现状。日常英语几乎不会单独用,只固定出现在短语 status quo 里,现状/现传统/当前既定模式
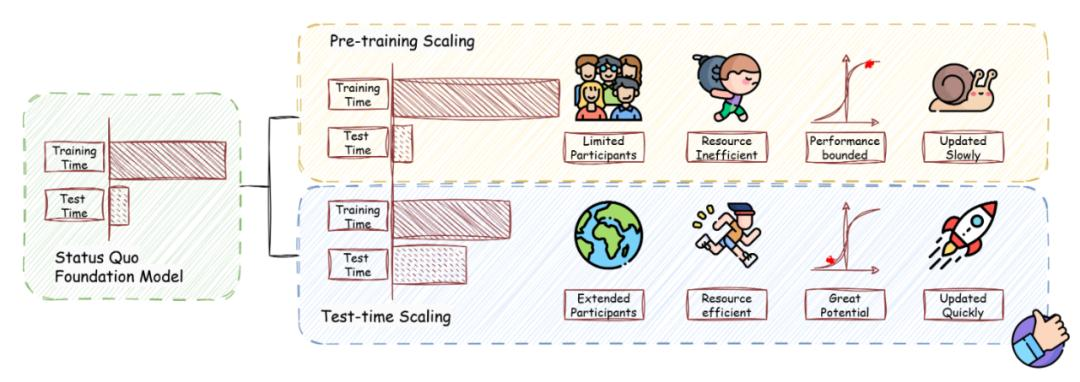
最左侧:Status Quo Foundation Model(传统基座模型现状)
把算力切分成两块:大块 Training Time(预训练耗时)、小块 Test Time(推理 / 测试耗时)
传统方案只在「预训练阶段」堆算力;而图里分成两条技术路线做对比:
- 上方黄色框:Pre-training Scaling 预训练缩放
- 下方蓝色框:Test-time Scaling 推理时计算缩放(TTCS)
Pre-training Scaling 传统预训练扩容方案
算力分配
Training Time:占用绝大部分算力(长条填充)
Test Time:推理阶段只分配极少算力(窄条)
5 个短板
Limited Participants(人群头像)
提升效果只能靠实验室 / 企业自己花钱堆卡做预训练,普通用户、下游使用者无法参与优化模型,参与主体受限。
Resource Inefficient(负重小人)
资源效率极低:预训练烧海量算力、数据、资金,成本巨大,性价比差。
Performance bounded(性能曲线红点在上)
性能天花板被锁死:模型训练完成后,推理阶段算力固定,效果上限无法突破,曲线很快收敛。
Updated Slowly(蜗牛)
迭代更新极慢:重新预训练大模型动辄几周 / 数月,迭代周期漫长。
Test-time Scaling 推理时算力扩容(TTCS)
算力分配
Training Time:预训练算力保持不变(和传统方案一样长)
Test Time:大幅扩充推理阶段算力(填充条变宽,核心区别)
Extended Participants(地球)
参与主体无限扩大:所有终端用户推理时都能参与 "算力扩容",每个人提问时都可以额外分配算力做思考、采样、搜索,不再局限于训练方。
Resource efficient(轻装快跑小人)
资源利用高效:不用重复重训模型,只在推理时按需消耗算力,不用一次性投入巨额预训练成本。
Great Potential(性能曲线红点在下)
性能潜力巨大:推理算力越高,效果持续上涨,没有预训练带来的固定性能天花板;算力投入和效果正相关。
Updated Quickly(火箭)
迭代速度极快:不需要重新训练模型权重,只修改推理解码逻辑(CoT、多采样、自校验、MCTS 等),上线、调优、迭代速度飞快。
算力增量全部发生在用户发提问、模型生成答案的瞬间,不在训练机房。
对比
这里的TTCS是云端扩容
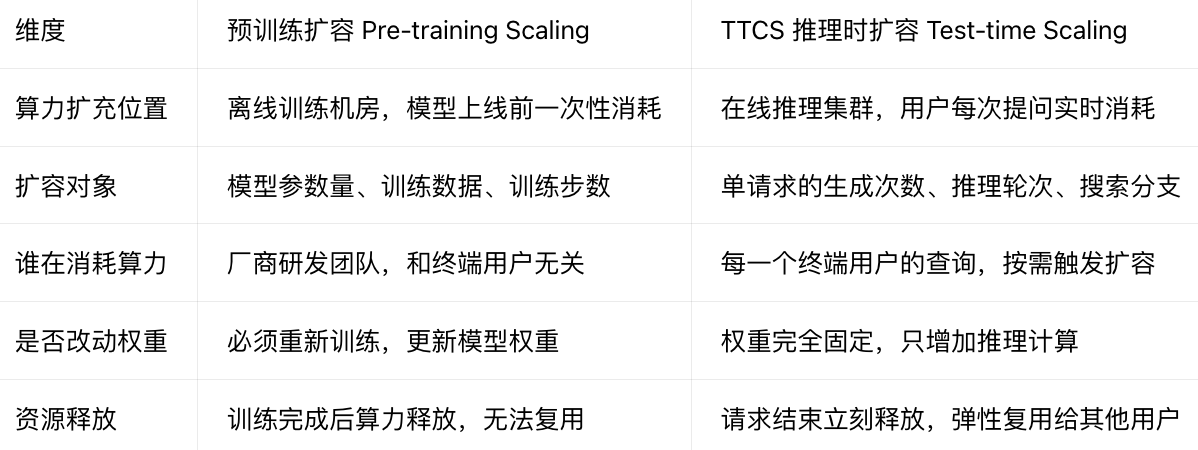
小结
传统思路(Pre-training Scaling):把所有资源砸在模型训练阶段,推理阶段几乎不分配算力,成本高/迭代慢/性能有上限、只有大厂能参与优化
TTCS 新思路(Test-time Scaling):训练算力不变,大幅增加推理时算力,让终端推理成为提升模型能力的核心环节
TTCS 是更优路线:资源利用率更高、所有人都能参与提升模型、效果上限更高、迭代更新速度远快于重新预训练
贴合行业实例
OpenAI o1、DeepSeek R1、Gemini Advanced 都是典型 TTCS 落地:
模型权重固定,推理时加长思维链、多路径采样、树搜索,靠推理算力换取更强逻辑能力,不用重新预训练大模型
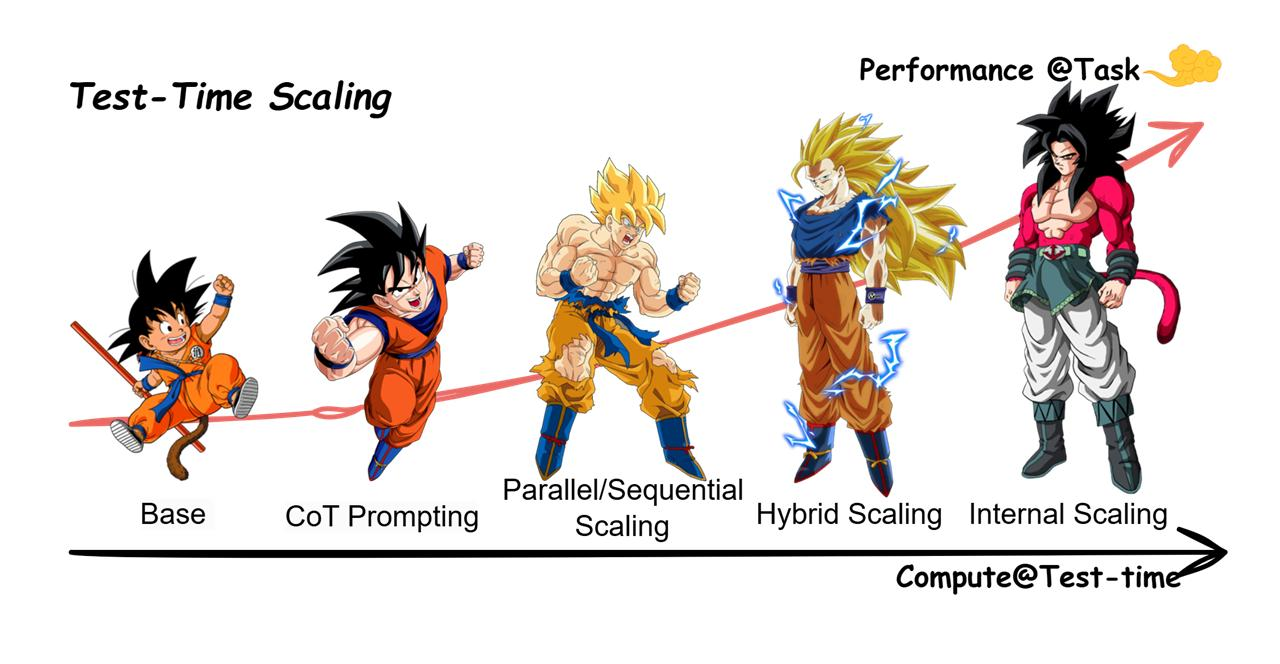
四大主流实现方式(怎么 "增加推理算力")
上下文缩放(Internal Scaling)
延长 CoT 思维链,生成更长推理步骤,让模型分步推导;算力消耗随思考 token 线性上涨。
并行采样缩放(Batch Scaling / Best-of-N)
一次 prompt 并行生成 N 条答案,用打分器 / 模型自校验选出最优解;N 越大算力越高、正确率越高。
迭代精调缩放(Turn Scaling / Self-refine)
模型写完答案后,多次自查、修正、重写,多轮迭代优化输出。
搜索类缩放(MCTS / Beam Search)
对解题路径做树搜索,遍历多条推理分支,选出最优路径,算力消耗最大、提升最明显。
行业共识
同等算力下,TTCS 效果优于单纯堆大模型:小模型搭配充足推理算力,性能可超过参数大十几倍的原生模型
存在缩放收益递减:算力加到一定阈值后,准确率提升微乎其微,甚至出现 "过度思考(overthinking)" 反而答错
任务强相关:数学、竞赛代码、多跳逻辑收益极大;闲聊、简单分类几乎无提升
工程权衡:算力↑ → 准确率↑、延迟↑、吞吐量↓;生产环境需要自适应 TTCS,简单问题少分配算力,难题多分配算力
TTCS = Test-Time Compute Scaling(完整全称)
TTS = Test-Time Scaling(通用简称)
Inference-time scaling:同义,工程侧更常用
举例
同样 7B 开源模型:
普通推理:单次生成答案,GSM8K 数学正确率 62%
TTCS 开启(Best-of-16 + 长 CoT):多路径采样 + 长思考,算力翻 16 倍,正确率冲到 80%+
全程不重新训练模型,仅修改推理解码逻辑
附录
MCTS 含义
Monte Carlo Tree Search,蒙特卡洛树搜索
定义
一种启发式树搜索算法,结合随机采样(蒙特卡洛模拟)+ 树分支推演,用来在海量可选路径里找到最优决策;是大模型 Test-Time Scaling(推理时缩放)的核心技术之一
四大标准执行步骤(循环迭代)
Selection 选择
从根节点出发,按 UCB 公式挑选最有潜力的子节点,走到未完全探索的叶子
Expansion 扩展
给当前叶子新增一条 / 多条未尝试的分支(对应模型下一步可能输出的 token、推理步骤)
Simulation 模拟(蒙特卡洛随机推演)
从新节点快速随机走完一整条完整推理路径,得到这条分支的最终得分(比如数学题是否答对、逻辑是否通顺)
Backpropagation 反向传播
把模拟得到的分数回传给这条路径上所有祖先节点,更新每个分支的平均收益、访问次数,后续选择时优先高分路径
循环重复以上 4 步,算力投入越多,搜索越充分,答案越精准
和大模型 TTCS 的关系
传统单条 CoT、Best-of-N 只是简单并行采样;MCTS 是结构化深度搜索:
- 普通推理:只生成 1 条思考链,算力极低,容易局部错误
- MCTS 推理:把每一步推理拆成树分支,遍历多条解题路径、淘汰错误分支、择优,属于典型Test-Time Compute Scaling,靠推理算力换取更强逻辑、数学、代码能力
直观例子(数学解题)
题目:(12+8)×5
根节点:题目
扩展分支 1:先算 12+8=20;分支 2:先算 8×5=40(错误路径)
模拟推演:分支 1 算出最终 100(高分),分支 2 算出 52(低分)
反向更新权重,后续优先走 "先算括号" 的正确分支
迭代多次后,模型会稳定输出最优解题步骤。
经典落地场景
博弈 AI:AlphaGo、AlphaZero 核心算法(围棋、象棋);
大模型深度推理:o1、DeepSeek-R1、Qwen-R1 等推理模型,用于数学竞赛、代码、多跳逻辑;
机器人规划、调度决策。
优点
不用暴力穷举所有路径,随机采样大幅降低计算量;
天然适配大模型分步推理,解决长链条逻辑错误;
算力投入越多,搜索效果单调提升,完美契合 Test-Time Scaling 缩放定律。
缺点
推理延迟、显存消耗显著上升;
简单问答场景收益极低,只适合复杂推理任务。