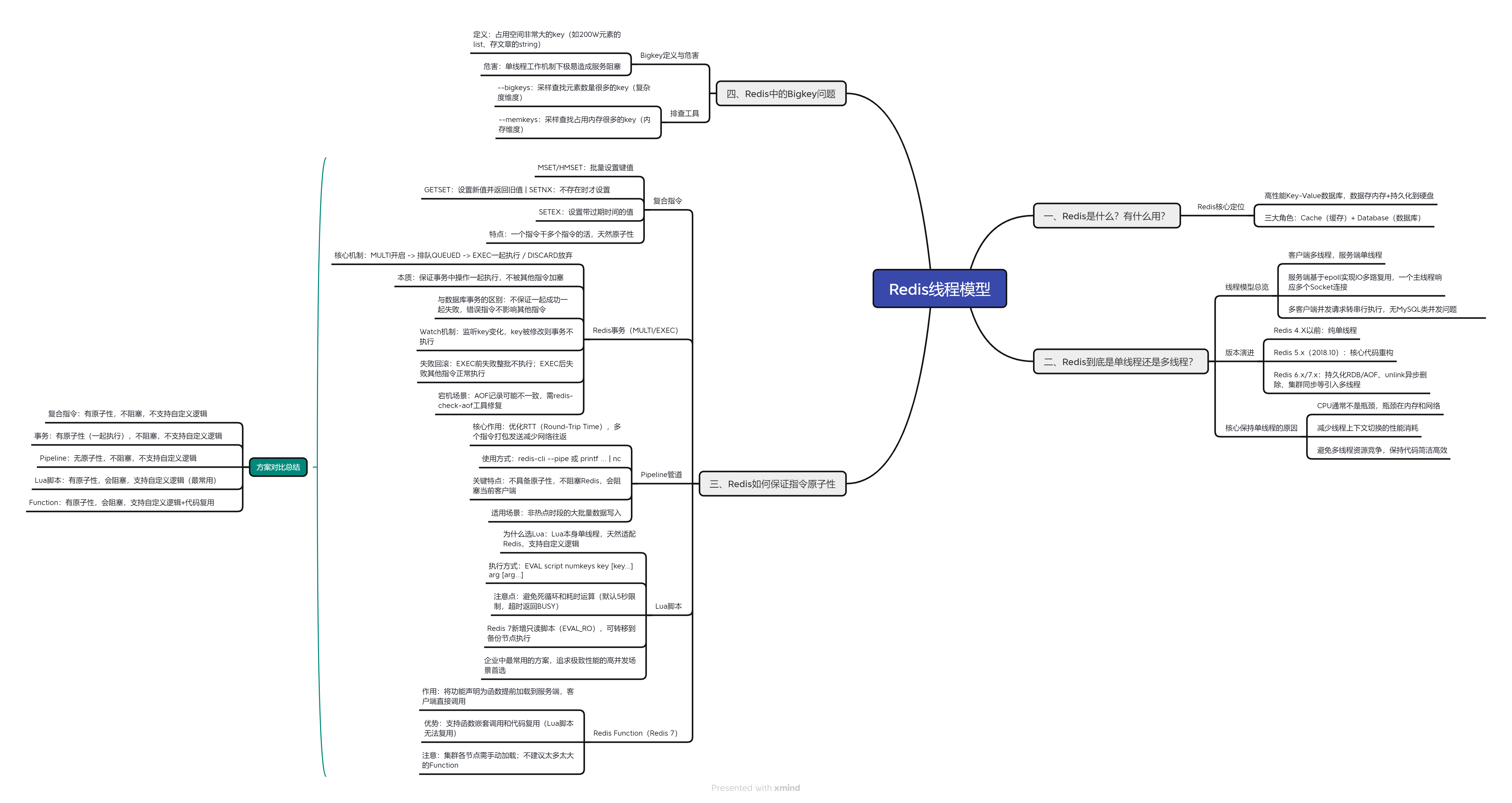
深入理解Redis线程模型
-
- [📋 知识体系总览](#📋 知识体系总览)
- 一、Redis是什么?有什么用?
-
- [✅1. Redis是什么?](#✅1. Redis是什么?)
- [✅2. 2024年的Redis是什么样的?](#✅2. 2024年的Redis是什么样的?)
- 二、Redis到底是单线程还是多线程?
- 三、Redis如何保证指令原子性
-
- [✅1. 复合指令](#✅1. 复合指令)
- [✅2. Redis事务](#✅2. Redis事务)
- [✅3. Pipeline](#✅3. Pipeline)
- [✅4. lua脚本](#✅4. lua脚本)
-
- [1、什么是 lua?为什么 Redis 支持 lua?](#1、什么是 lua?为什么 Redis 支持 lua?)
- [2、Redis 中如何执行 lua?](#2、Redis 中如何执行 lua?)
- [3、使用 lua 注意点](#3、使用 lua 注意点)
- [✅5. Redis Function](#✅5. Redis Function)
-
- [1、什么是 Function](#1、什么是 Function)
- [2、Function 案例](#2、Function 案例)
- [3、Function 注意点](#3、Function 注意点)
- [✅6. Redis指令原子性总结](#✅6. Redis指令原子性总结)
- [📊 指令原子性方案对比](#📊 指令原子性方案对比)
- 四、Redis中的Bigkey问题
- 五、Redis线程模型总结
- [📋 全文总结](#📋 全文总结)
-
- [✅1. Redis 线程模型核心:客户端多线程,服务端单线程](#✅1. Redis 线程模型核心:客户端多线程,服务端单线程)
- [✅2. 保证指令原子性的五种方式](#✅2. 保证指令原子性的五种方式)
- [✅3. Bigkey 问题](#✅3. Bigkey 问题)
- [✅4. 关键版本变化](#✅4. 关键版本变化)
📋 知识体系总览
深入理解Redis线程模型
├── 一、Redis是什么?有什么用?
│ ├── ✅1. Redis是什么?
│ └── ✅2. 2024年的Redis是什么样的?
├── 二、Redis到底是单线程还是多线程?
├── 三、Redis如何保证指令原子性
│ ├── ✅1. 复合指令
│ ├── ✅2. Redis事务
│ ├── ✅3. Pipeline
│ ├── ✅4. lua脚本
│ ├── ✅5. Redis Function
│ └── ✅6. Redis指令原子性总结
├── 四、Redis中的Bigkey问题
└── 五、Redis线程模型总结📝 核心: Redis整体线程模型为「客户端多线程,服务端单线程」。核心读写操作由单线程串行执行,不存在MySQL那样的并发问题。但严格来说,Redis后端的线程模型与版本有关------Redis4.X以前纯单线程,5.x/6.x/7.x逐步引入多线程处理耗时操作。
一、Redis是什么?有什么用?
✅1. Redis是什么?
Redis 全称 REmote DIctionary Server (远程字典服务),是一个完全开源的、高性能的 Key-Value 数据库。官网地址:https://redis.io/
📝 核心总结:
- 数据结构复杂: Redis 相比于传统的 K-V 型数据库,能够支撑更复杂的数据类型,已经远远超出了缓存的范围,可以实现很多复杂的业务场景。
- 数据保存在内存,但是持久化到硬盘: 数据全部保存在内存,读写性能极高;同时持久化到硬盘,数据安全可靠,完全可以当做一个数据库来用。
官方对 Redis 的作用定位为三个方面:Cache(缓存)、Database(数据库)、Vector Search(向量搜索)。

✅2. 2024年的Redis是什么样的?
在 2023 年之前,Redis 是一个纯粹的开源数据库。但从最近两年开始,Redis 正在从一个缓存产品变成一整套生态服务。
- Redis Cloud: 基于 AWS、Azure 等公有云,提供完整的企业服务,并提供了 Redis Enterprise 企业级收费产品。
- Redis Insight: Redis 官方推出的图形化客户端,以往需要第三方客户端,现在不需要了,并且可以在 Redis Cloud 上直接使用。


在功能层面,目前已经形成了 Redis OSS 和 Redis Stack 两套服务体系:
- Redis OSS: 以前常用的开源服务体系。
- Redis Stack: 基于 Redis OSS 打造的一套更完整的技术栈,基于 Redis Cloud 提供服务,在 Redis OSS 功能的基础上,提供了很多高级的扩展功能。
二、Redis到底是单线程还是多线程?
这是 Redis 面试过程中最喜欢问的问题,几乎伴随着 Redis 的整个发展过程。
📝 面试要点: 首先整体来说,Redis 的线程模型可以简单解释为:客户端多线程,服务端单线程。
Redis 为了能够与更多的客户端进行连接,使用多线程来维护与客户端的 Socket 连接。在 redis.conf 中有一个参数 maxclients 维护了最大的客户端连接数:
bash
# Redis is mostly single threaded, however there are certain threaded
# operations such as UNLINK, slow I/O accesses and other things that are
# performed on side threads.
#
# Now it is also possible to handle Redis clients socket reads and writes
# in different I/O threads. Since especially writing is so slow, normally
# Redis users use pipelining in order to speed up the Redis performances per
# core, and spawn multiple instances in order to scale more. Using I/O
# threads it is possible to easily speedup two times Redis without resorting
# to pipelining nor sharding of the instance.
#
# By default threading is disabled, we suggest enabling it only in machines
# that have at least 4 or more cores, leaving at least one spare core.
# Using more than 8 threads is unlikely to help much. We also recommend using
# threaded I/O only if you actually have performance problems, with Redis
# instances being able to use a quite big percentage of CPU time, otherwise
# there is no point in using this feature.
#
# So for instance if you have a four cores boxes, try to use 2 or 3 I/O
# threads, if you have a 8 cores, try to use 6 threads. In order to
# enable I/O threads use the following configuration directive:
#
# io-threads 4
# Set the max number of connected clients at the same time. By default
# this limit is set to 10000 clients, however if the Redis server is not
# able to configure the process file limit to allow for the specified limit
# the max number of allowed clients is set to the current file limit
# minus 32 (as Redis reserves a few file descriptors for internal uses).
#
# Once the limit is reached Redis will close all the new connections sending
# an error 'max number of clients reached'.
#
# IMPORTANT: When Redis Cluster is used, the max number of connections is also
# shared with the cluster bus: every node in the cluster will use two
# connections, one incoming and another outgoing. It is important to size the
# limit accordingly in case of very large clusters.
#
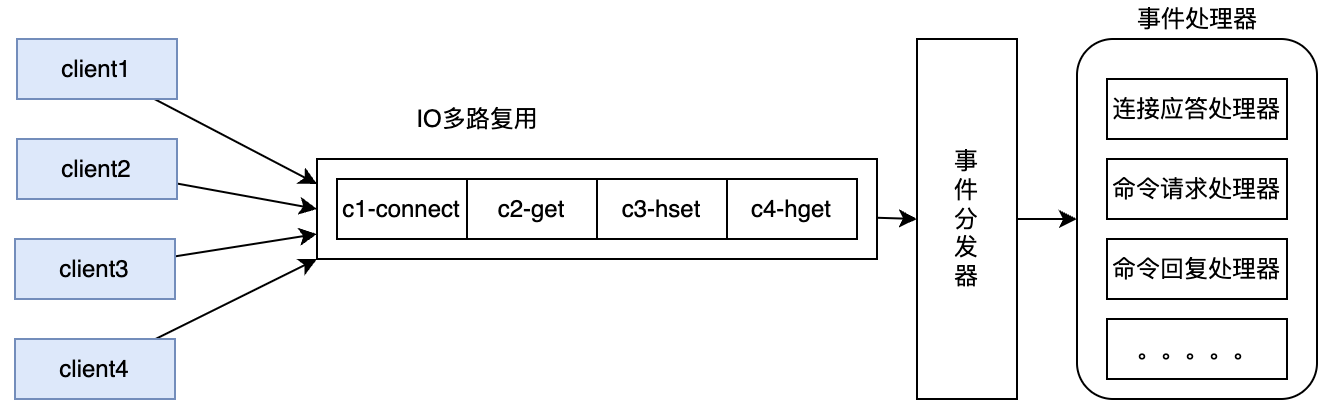
# maxclients 10000📝 关键理解: 在服务端,Redis 响应网络 IO 和键值对读写的请求,是由一个单独的主线程完成的。Redis 基于 epoll 实现了 IO 多路复用,这就可以用一个主线程同时响应多个客户端 Socket 连接的请求。
在这种线程模型下,Redis 将客户端多个并发的请求转成了串行的执行方式。因此:
- 完全不用考虑诸如 MySQL 的脏读、幻读、不可重复读之类的并发问题。
- 这种串行化的线程模型 + 基于内存工作的极高性能,让 Redis 成为很多并发问题的解决工具。
📝 版本演进:
- Redis 4.X 以前: 纯单线程。
- 2018年10月 Redis 5.x: 进行一次大的核心代码重构。
- Redis 6.x / 7.x: 开始用全新的多线程机制来提升后台工作。持久化 RDB/AOF 文件、unlink 异步删除、集群数据同步等耗时操作都由额外线程执行。例如
FLUSHALL已经提供了异步方式。
📝 为什么核心保持单线程?
- 对于现代 Redis,CPU 通常不是性能瓶颈,瓶颈大部分是内存和网络,所以核心改为多线程的要求并不急切。
- 单线程为主的工作机制可以减少线程上下文切换的性能消耗。
- 如果核心改为多线程并发执行,必然带来资源竞争,反而会极大增加 Redis 的业务复杂性,影响执行效率。

三、Redis如何保证指令原子性
对于核心的读写键值操作,Redis 是单线程处理的。如果多个客户端同时进行读写请求,Redis 只会排队串行。也就是说,针对单个客户端,Redis 并没有类似 MySQL 的事务那样保证同一个客户端的操作原子性。
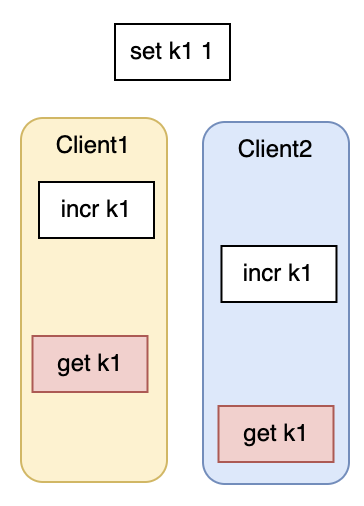
如何控制 Redis 指令的原子性呢?这在不同业务场景下,Redis 提供了不同的思路。
✅1. 复合指令
Redis 内部提供了很多复合指令,它们是一个指令,但明显干着多个指令的活:
| 复合指令 | 说明 |
|---|---|
MSET / HMSET |
批量设置键值 |
GETSET |
设置新值并返回旧值 |
SETNX |
不存在时才设置 |
SETEX |
设置带过期时间的值 |
这些复合指令都能很好地保持原子性。
✅2. Redis事务
像 MySQL 一样,Redis 也提供了事务机制。
bash
127.0.0.1:6379> help @transactions
DISCARD (null) -- 放弃事务
summary: Discards a transaction.
since: 2.0.0
EXEC (null) -- 执行事务
summary: Executes all commands in a transaction.
since: 1.2.0
MULTI (null) -- 开启事务
summary: Starts a transaction.
since: 1.2.0
UNWATCH (null) -- 去掉监听
summary: Forgets about watched keys of a transaction.
since: 2.2.0
WATCH key [key ...] -- 监听某一个key的变化,key有变化后,就执行当前事务
summary: Monitors changes to keys to determine the execution of a transaction.
since: 2.2.0使用方式也很典型,开启事务后,接入一系列操作,然后根据执行情况选择执行事务还是回滚事务:
bash
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set k2 2
QUEUED
127.0.0.1:6379(TX)> incr k2
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> EXEC --执行事务
1) OK
2) (integer) 3
3) "3"
127.0.0.1:6379> DISCARD -- 放弃事务📝 关键区分:Redis 事务 ≠ 数据库事务! 看下面的例子:
bash
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set k2 2
QUEUED
127.0.0.1:6379(TX)> incr k2
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> lpop k2
QUEUED
127.0.0.1:6379(TX)> incr k2
QUEUED
127.0.0.1:6379 (TX)> get k2
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) (integer) 3
3) "3"
4) (error) WRONGTYPE Operation against a key holding the wrong kind of value
5) (integer) 4
6) "4"lpop 指令是针对 list 的操作,针对 string 类型的 k2 操作报错了。但是:
- 错误的指令没有让整个事务回滚
- 后面的指令没有受到影响
📝 核心: Redis 的事务并不是 像数据库事务那样保证一起成功或一起失败。Redis 的事务作用,仅仅是保证事务中的原子操作是一起执行,而不会在执行过程中被其他指令加塞。
📝 关键理解: 开启事务后,所有操作的返回结果都是QUEUED,表示这些操作只是排好了队,等到EXEC后一起执行。
更多说明参考官网:https://redis.io/docs/latest/develop/interact/transactions/
Redis事务总结
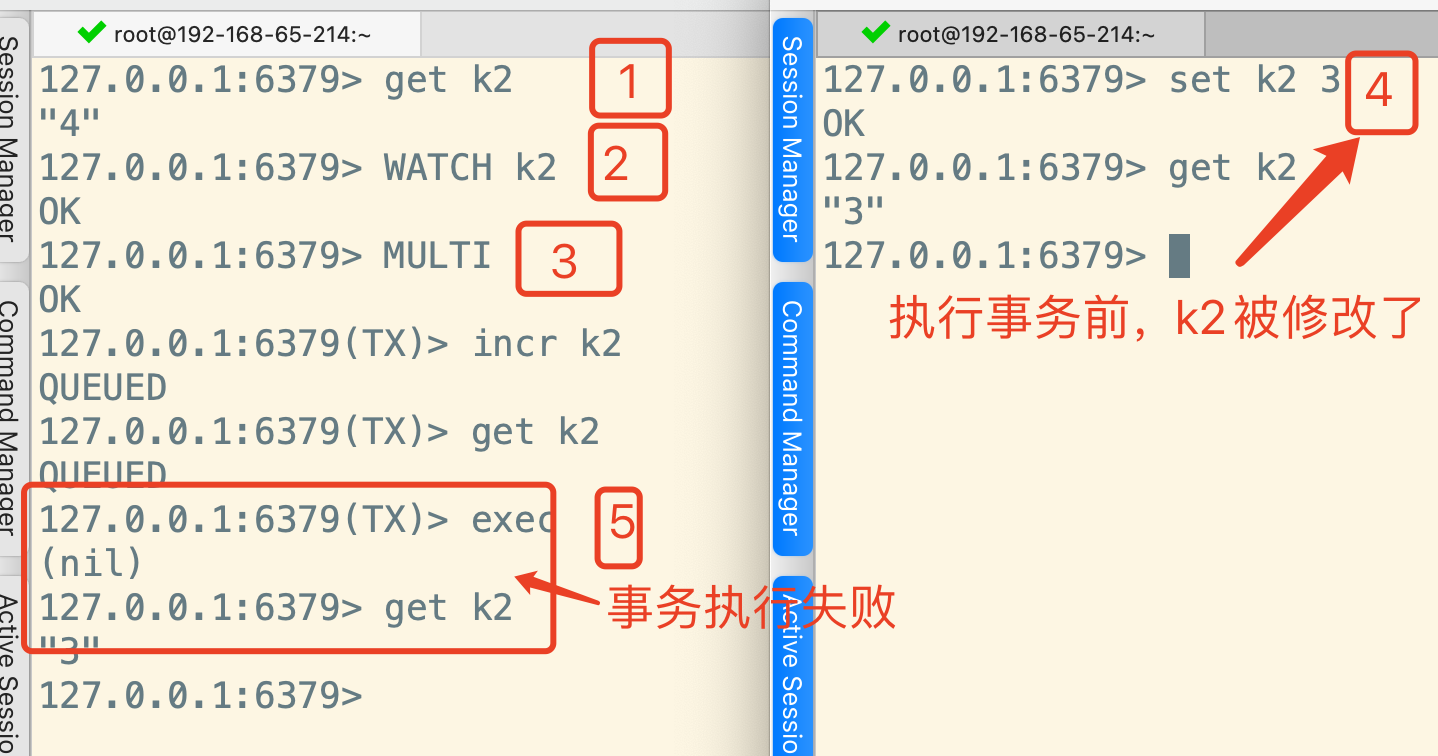
1、Redis 事务可以通过 Watch 机制 进一步保证在某个事务执行前,某一个 key 不被修改。
📝 注意:
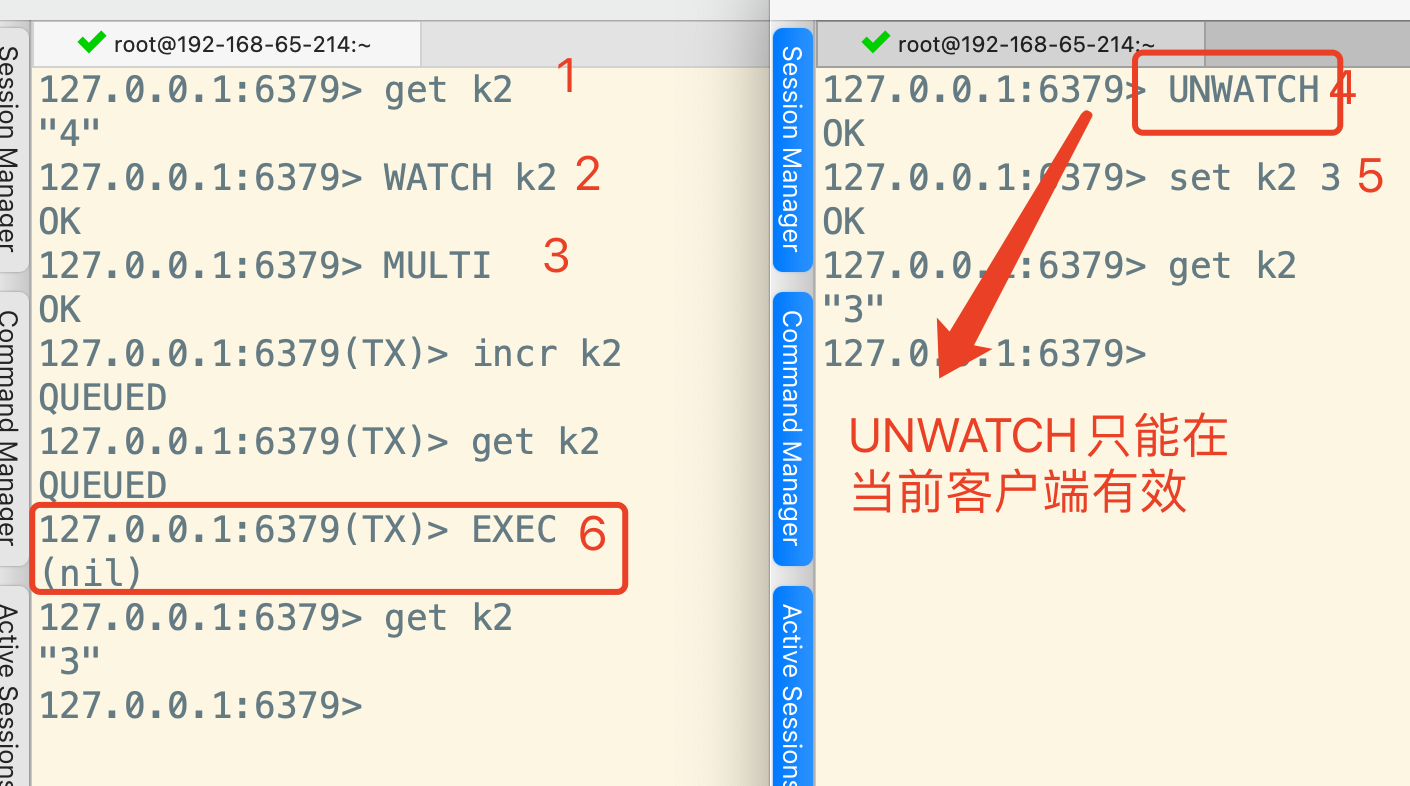
UNWATCH取消监听,只在当前客户端有效。比如下图,只有在左侧客户端步骤3之前执行UNWATCH才能让事务执行成功。在右侧客户端执行UNWATCH是不生效的。
2、Redis 事务失败如何回滚
Redis 中的事务回滚,不是回滚数据,而是回滚操作:
- 如果事务在 EXEC 执行前失败(比如事务中的指令敲错了,或者指令的参数不对),那么整个事务的操作都不会执行。
- 如果事务在 EXEC 执行之后失败(比如指令操作的 key 类型不对),那么事务中的其他操作都会正常执行,不受影响。
3、事务执行过程中出现失败了怎么办
- 只要客户端执行了
EXEC指令,那么就算之后客户端的连接断开了,事务就会一直进行下去。 - 事务有可能造成数据不一致。当
EXEC指令执行后,Redis 会先将事务中的所有操作都记录到 AOF 文件中,然后再执行具体的操作。如果保存了 AOF 记录后,事务的操作在执行过程中服务出现了非正常宕机(服务崩溃,或被kill -9),就会造成 AOF 中记录的操作与数据不符合。Redis 发现这种情况后,下次启动时会报错无法正常启动。这时需要使用redis-check-aof工具修复 AOF 文件,将不完整的事务操作记录移除掉,这样下次服务就可以正常启动了。
4、事务机制优缺点,什么时候用事务(开放性问题,无标准答案)
✅3. Pipeline
1、什么是管道
使用 redis-cli --help 查看客户端指令中两个不太起眼的参数:
bash
--pipe Transfer raw Redis protocol from stdin to server.
--pipe-timeout <n> In --pipe mode, abort with error if after sending all data.
no reply is received within <n> seconds.
Default timeout: 30. Use 0 to wait forever.2、使用案例
在 Linux 上编辑一个文件 command.txt,包含一系列指令:
bash
set count 1
incr count
incr count
incr count然后在客户端执行 redis-cli 时,直接执行这个文件中的指令:
bash
[root@192-168-65-214 ~]# cat command.txt | redis-cli -a 123qweasd --pipe
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 4
[root@192-168-65-214 ~]# redis-cli -a 123qweasd
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> get count
"4"3、有什么用
📝 结论: 如果你有大批量的数据需要快速写入到 Redis 中,pipeline 方式可以一定程度提高执行效率。
参考官网:https://redis.io/docs/latest/develop/use/pipelining/
核心作用:优化 RTT(Round-Trip Time)
RTT 是什么? 当客户端执行一个指令,数据包需要通过网络从 Client 传到 Server,然后再从 Server 返回到 Client。这个中间的时间消耗,就称为 RTT(Rount Trip Time)。
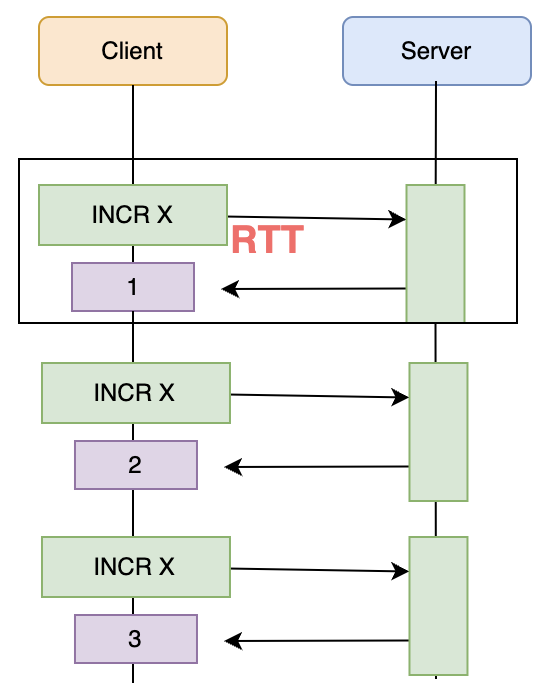
可以看到,如果客户端的指令非常频繁,RTT 消耗就会非常可观。Redis 提供了 pipeline 机制,将客户端的多个指令打包一起往服务端推送。
📝 关键理解: pipeline 就是客户端和服务端之间的一层优化。将多个指令打包一起发送,减少网络往返。客户端把多个命令一次性发送,服务端统一处理返回。
官网案例:
bash
[root@192-168-65-214 ~]# printf "AUTH 123qweasd\r\nPING\r\nPING\r\nPING\r\n" | nc localhost 6379
+OK
+PONG
+PONG
+PONG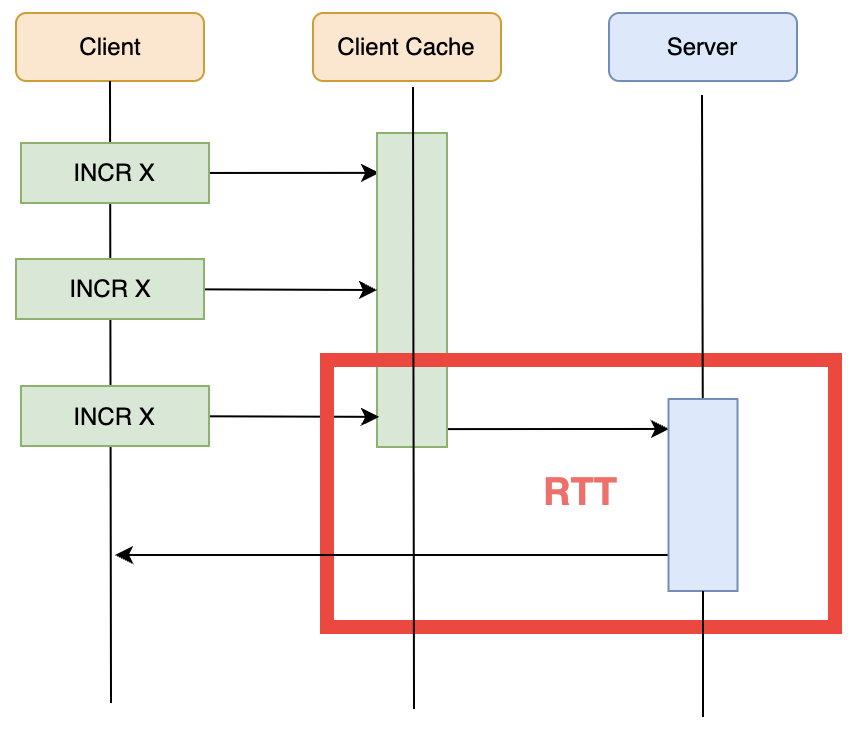
4、pipeline 注意点
📝 关键区分:
| 对比项 | 复合指令 | 事务 | Pipeline |
|---|---|---|---|
| 原子性 | 有 | 有(一起执行) | 不具备原子性 |
| 是否阻塞其他命令 | 会 | 会 | 不会 |
- Pipeline 不具备原子性,只是将多条命令打包发送,最终还是可能会被其他客户端的指令加塞(虽然概率通常比较小)。
- Pipeline 中通常不建议进行复杂的数据操作。
- Pipeline 的执行需要客户端和服务端同时完成,执行过程中会阻塞当前客户端。
- Pipeline 中不建议拼装过多的指令:指令过多会使客户端阻塞时间太长,同时服务端需要回复这个很繁忙的客户端,占用很多内存。
📝 应用场景: Pipeline 机制适合做一些在非热点时段进行的数据调整任务。
✅4. lua脚本
📝 为什么需要 Lua? 事务和 Pipeline 对于指令原子性问题都有水土不服的地方,并且它们都只是对 Redis 现有指令进行拼凑,无法添加更多自定义的复杂逻辑。企业中用到更多的是 lua 脚本,同时也是 Redis 7 版本着重调整的功能。
1、什么是 lua?为什么 Redis 支持 lua?
Lua 是一种小巧的脚本语言,拥有很多高级语言的特性(参数类型、作用域、函数等)。语法非常简单,熟悉 Java 后基本上可以零门槛上手。
lua 参考网站:https://wiki.luatos.com/(可直接在线调试,但注意 Redis 7.x 支持的是 lua 5.1 版本,网站是 5.3 版本)

📝 核心: Lua 语言最大的特点是线程模型是单线程 的,这使其天生就非常适合 Redis、Nginx 等单线程模型的中间件。所以,在 Redis 中执行一段 lua 脚本,天然就是原子性的。
2、Redis 中如何执行 lua?
Lua API 参考官网:https://redis.io/docs/latest/develop/interact/programmability/lua-api/
Redis 对 lua 开始了:
bash
127.0.0.1:6379> help eval
EVAL script numkeys [key [key ...]] [arg [arg ...]]
summary: Executes a server-side Lua script.
since: 2.6.0
group: scripting📝 参数说明:
script:一段 Lua 脚本程序,运行在 Redis 服务器上下文中,不必(也不应该)定义为一个 Lua 函数。numkeys:键名参数的个数。key [key ...]:从 EVAL 的第三个参数开始算起,表示在脚本中用到的那些 Redis 键,在 Lua 中通过全局变量KEYS数组以 1 为基址访问(KEYS[1]、KEYS[2])。arg [arg ...]:附加参数,在 Lua 中通过全局变量ARGV数组访问(ARGV[1]、ARGV[2])。
示例:
bash
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"在 lua 脚本中使用 redis.call 函数来调用 Redis 的命令:
bash
127.0.0.1:6379> set stock_1 1
OK
-- 调整1号商品的库存。如果库存小于10,就设置为10
127.0.0.1:6379> eval "local initcount = redis.call('get', KEYS[1]) local a = tonumber(initcount) local b = tonumber(ARGV[1]) if a >= b then redis.call('set', KEYS[1], a) return 1 end redis.call('set', KEYS[1], b) return 0 " 1 "stock_1" 10
(integer) 0
127.0.0.1:6379> get stock_1
"10"📝 注意: 注意其中 keys 和 args 是如何传参的。
3、使用 lua 注意点
1》不要在 Lua 脚本中出现死循环和耗时的运算,否则 Redis 会阻塞。
Redis 中有一个配置参数来控制 Lua 脚本的最长执行时间,默认 5 秒钟 。当 lua 脚本执行时间超过了这个时长,Redis 会对其他操作返回一个 BUSY 错误:
bash
################ NON-DETERMINISTIC LONG BLOCKING COMMANDS #####################
# Maximum time in milliseconds for EVAL scripts, functions and in some cases
# modules' commands before Redis can start processing or rejecting other clients.
#
# If the maximum execution time is reached Redis will start to reply to most
# commands with a BUSY error.
#
# In this state Redis will only allow a handful of commands to be executed.
# For instance, SCRIPT KILL, FUNCTION KILL, SHUTDOWN NOSAVE and possibly some
# module specific 'allow-busy' commands.
#
# SCRIPT KILL and FUNCTION KILL will only be able to stop a script that did not
# yet call any write commands, so SHUTDOWN NOSAVE may be the only way to stop
# the server in the case a write command was already issued by the script when
# the user doesn't want to wait for the natural termination of the script.
#
# The default is 5 seconds. It is possible to set it to 0 or a negative value
# to disable this mechanism (uninterrupted execution). Note that in the past
# this config had a different name, which is now an alias, so both of these do
# the same:
# lua-time-limit 5000
# busy-reply-threshold 5000📝 管道 vs Lua: 管道 pipeline 不会阻塞 Redis,而 lua 脚本会阻塞。
2》尽量使用只读脚本
只读脚本是 Redis 7 中新增的一种脚本执行方法,表示那些不修改 Redis 数据集的只读脚本。需要在脚本上加上一个只读的标志,并通过指令 EVAL_RO 触发。在只读脚本中不允许执行任何修改数据集的操作,并且可以随时使用 SCRIPT_KILL 指令停止。
📝 好处: 一方面可以限制某些用户的操作;另一方面,这些只读脚本通常都可以转移到备份节点执行,从而减轻 Redis 的压力。
3》热点脚本可以缓存到服务端
✅5. Redis Function
1、什么是 Function
如果你觉得开发 lua 脚本有困难,Redis 7 之后提供了另一种方法------Redis Function。
Redis Function 允许将一些功能声明成一个统一的函数,提前加载到 Redis 服务端(可以由熟悉 Redis 的管理员加载)。客户端可以直接调用这些函数,而不需要再去开发函数的具体实现。
📝 核心优势: Function 中可以嵌套调用其他 Function,更有利于代码复用。相比之下,lua 脚本就无法进行复用。
2、Function 案例
在服务器上新增一个 mylib.lua 文件,定义函数:
lua
#!lua name=mylib
local function my_hset(keys, args)
local hash = keys[1]
local time = redis.call('TIME')[1]
return redis.call('HSET', hash, '_last_modified_', time, unpack(args))
end
redis.register_function('my_hset', my_hset)📝 注意: 脚本第一行
#!lua name=mylib是指定函数的命名空间,不是注释,不能少!
使用 Redis 客户端,将函数加载到 Redis 中:
bash
[root@192-168-65-214 myredis]# cat mylib.lua | redis-cli -a 123qweasd -x FUNCTION LOAD REPLACE
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
"mylib"其他客户端可以直接调用这个函数,函数的调用以及传参方式跟 lua 脚本一样:
bash
127.0.0.1:6379> FUNCTION LIST
1) 1) "library_name"
2) "mylib"
3) "engine"
4) "LUA"
5) "functions"
6) 1) 1) "name"
2) "my_hset"
3) "description"
4) (nil)
5) "flags"
6) (empty array)
127.0.0.1:6379> FCALL my_hset 1 myhash myfield "some value" another_field "another value"
(integer) 3
127.0.0.1:6379> HGETALL myhash
1) "_last_modified_"
2) "1717748001"
3) "myfield"
4) "some value"
5) "another_field"
6) "another value"3、Function 注意点
- Function 同样可以进行只读调用。
- 如果在集群中使用 Function,目前版本需要在各个节点都手动加载一次。 Redis 不会在集群中进行 Function 同步。
- Function 是要在服务端缓存的,所以不建议使用太多太大的 Function。
- Function 和 Script 一样,也有一系列的管理指令 ,使用指令
help @scripting自行了解。
✅6. Redis指令原子性总结
以上介绍的各种机制,其实都是 Redis 改变指令执行顺序的方式。
📝 面试要点: 在这几种工具中,Lua 脚本通常是项目中使用最多的方式。在很多追求极致性能的高并发场景,Lua 脚本都会担任很重要的角色。但其他方式也需要有了解,这样面临真实业务场景才有更多方案可以选择。
📊 指令原子性方案对比
| 方案 | 原子性 | 是否阻塞 | 自定义逻辑 | 适用场景 |
|---|---|---|---|---|
| 复合指令 | 有 | 不会 | 不支持 | 简单的组合操作 |
| 事务(MULTI/EXEC) | 有(一起执行) | 不会 | 不支持 | 需要批量串行执行 |
| Pipeline | 无 | 不阻塞 | 不支持 | 大批量数据写入(非热点时段) |
| Lua 脚本 | 有 | 会阻塞 | 支持 | 复杂业务逻辑(最常用) |
| Redis Function | 有 | 会阻塞 | 支持 | Lua 脚本的升级版,支持复用 |
四、Redis中的Bigkey问题
📝 核心: Bigkey 指那些占用空间非常大的 key。比如一个 list 中包含 200W 个元素,或者一个 string 里放一篇文章。基于 Redis 的单线程为主的核心工作机制,这些 Bigkey 非常容易造成 Redis 的服务阻塞。因此在实际项目中,一定需要特殊关照。
在 Redis 客户端指令中,提供了两个扩展参数,可以帮助快速发现 BigKey:
bash
[root@192-168-65-214 myredis]# redis-cli --help
...
--bigkeys Sample Redis keys looking for keys with many elements (complexity).
--memkeys Sample Redis keys looking for keys consuming a lot of memory.| 参数 | 说明 |
|---|---|
--bigkeys |
采样查找元素数量很多的 key(复杂度维度) |
--memkeys |
采样查找占用内存很多的 key(内存维度) |
📝 注意: 关于 BigKey 的处理,在后续课程中继续深入介绍。
五、Redis线程模型总结
📝 核心总结:
- Redis 的线程模型整体还是多线程 的,只是后台执行指令的核心线程是单线程的。整个线程模型可以理解为还是以单线程为主。基于这种单线程为主的线程模型,不同客户端的各种指令都需要依次排队执行。
- Redis 这种以单线程为主的线程模型,相比其他中间件,还是非常简单的。这使得 Redis 处理线程并发问题要简单高效很多。甚至在很多复杂业务场景下,Redis 都是用来进行线程并发控制的很好的工具。
- 但这并不意味 Redis 就没有线程并发问题,选择合理的指令执行方式非常重要。
- Redis 这种比较简单的线程模型本身是不利于发挥多线程的并发优势的,而且 Redis 的应用场景又通常与高性能深度绑定。所以,在使用 Redis 的时候,要时刻思考 Redis 的这些指令执行方式,这样才能最大限度发挥 Redis 高性能的优势。
📋 全文总结
✅1. Redis 线程模型核心:客户端多线程,服务端单线程
- Redis 基于 epoll 实现 IO 多路复用,核心读写单线程串行执行,无并发问题
- 从 Redis 4.X 纯单线程 → 5.x/6.x/7.x 逐步引入多线程处理持久化、异步删除等耗时操作
- CPU 通常不是瓶颈,内存和网络才是
✅2. 保证指令原子性的五种方式
- 复合指令(MSET、SETNX等):最简单
- 事务(MULTI/EXEC):保证一起执行,不保证一起成功。失败不回滚数据,只回滚操作
- Pipeline:优化 RTT,不保证原子性,不阻塞
- Lua 脚本:最常用的方案,天然原子性,支持自定义逻辑
- Redis Function:Lua 的升级,支持复用,Redis 7 引入
✅3. Bigkey 问题
- 大 key 容易造成服务阻塞,需要特殊关注
- 使用
--bigkeys和--memkeys参数排查
✅4. 关键版本变化
- Redis 2.6.0:支持 Lua 脚本
- Redis 5.x(2018.10):核心代码重构
- Redis 6.x/7.x:引入 IO 多线程、异步操作
- Redis 7.x:Function 机制、只读脚本、lua 5.1