很多团队第一次接 MCP Server,最容易走偏的一步,不是协议没跑通,而是把现有 REST 接口几乎原样包装成工具:
getUserById、listOrder、updateStatus、queryRefund、sendMessage......
看起来模型能调用系统了,实际一用就会发现:工具太碎,参数太多,模型不知道该先调哪个;返回值太像数据库对象,里面混着无关字段;一旦涉及写操作,还会出现"模型以为自己在查询,结果触发了业务变更"的风险。
MCP 的价值不是把所有内部接口都暴露给大模型,而是给 AI 应用提供一组"面向任务"的能力边界。对 Java 后端来说,设计 MCP Tool 更像设计一个给不稳定调用方使用的应用服务接口,而不是简单套一层 Controller。
Tool 的粒度要比 REST 接口更靠近任务
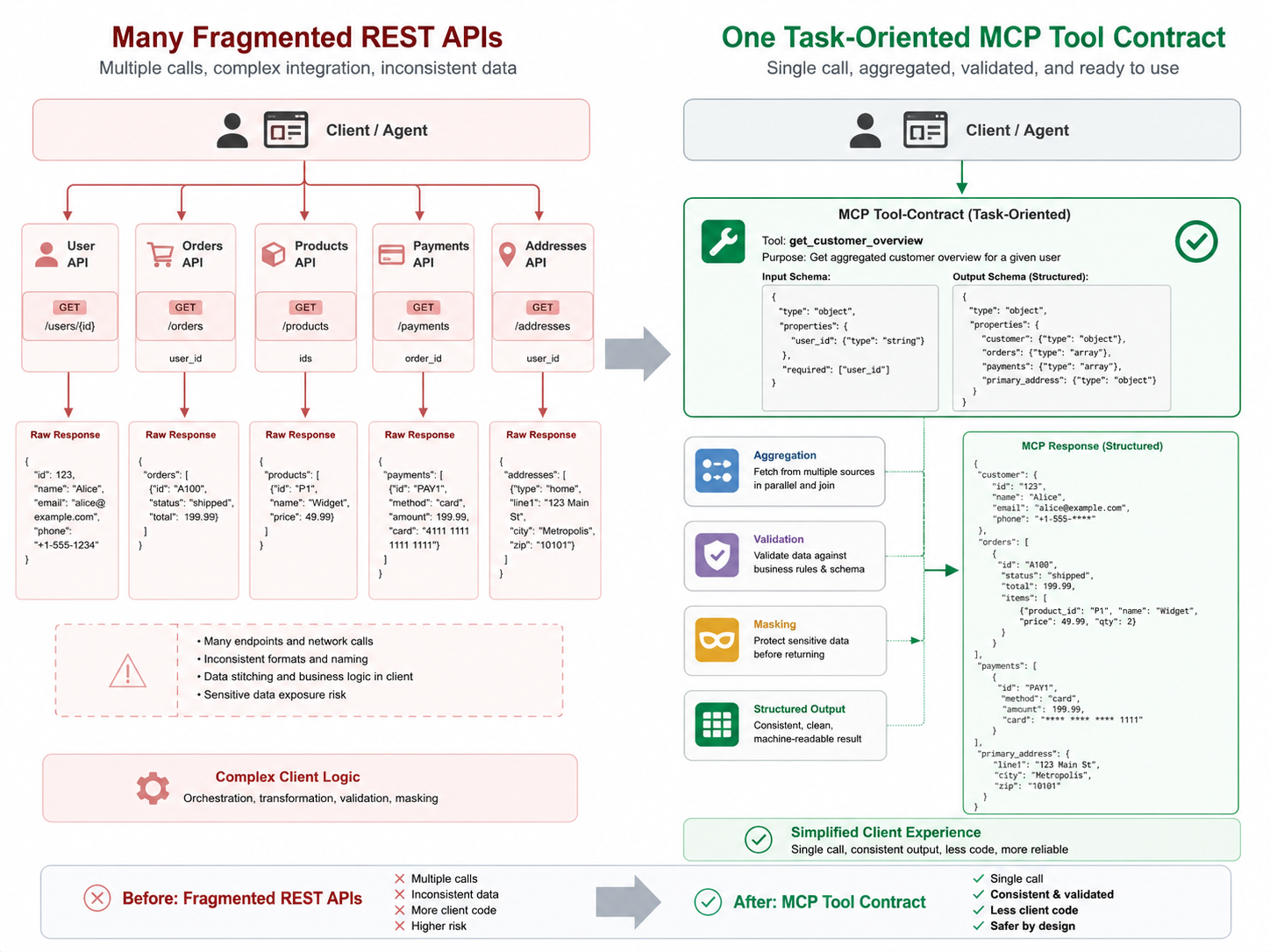
后端接口通常按资源建模,比如订单服务会有订单详情、物流轨迹、售后单、支付记录、用户地址等接口。人类开发者知道这些接口之间的关系,可以按顺序组装。
模型不一样。它看到的是工具名称、描述和参数 Schema。工具越碎,它越容易在调用顺序、参数选择、结果理解上犯错。
比如客服场景里,用户问:"帮我看一下这个订单为什么还没到。"
如果你暴露 5 个接口:
getOrdergetDeliverygetPaymentgetRefundgetAddress
模型需要自己判断先后顺序,还要理解哪些字段有用。更合理的工具应该是:
order.lookup_delivery_issue
这个工具内部再组合订单、物流、售后和风控信息,只返回模型完成回答所需的摘要。
这和我们写应用服务层是同一个思路:Controller 不应该直接暴露 Mapper 拼装细节,MCP Tool 也不应该把领域内部结构直接甩给模型。
一个好 Tool 至少要回答三个问题
设计 MCP Tool 时,不要先问"我有哪些接口可以暴露",而要先问这三个问题。
第一,这个工具解决哪个明确任务?
工具名称和描述要让模型知道什么时候该调用它。MCP 规范中 Tool 由 name、description、inputSchema 等元数据描述,最新规范也对工具命名、结构化输出和输出 Schema 给出了更明确说明。名字最好稳定、短、可读,比如 order.lookup_delivery_issue,不要写成 queryData 或 doOrderOperation。
第二,参数是否足够少且可校验?
模型不是表单用户,参数越多越容易填错。能从上下文推断的参数,不一定要暴露;必须由用户提供的参数,要用清晰描述和类型约束。订单号、用户 ID、时间范围、枚举值,都应该在工具层做校验。
第三,返回值是否面向模型消费?
不要直接返回数据库实体。实体里经常包含手机号、地址、内部状态码、成本字段、风控标签等信息。Tool 返回值应该是脱敏后的任务结果,例如订单状态、物流异常原因、下一步建议、是否需要人工介入。
用 Spring AI 写一个最小 MCP Tool
Spring AI 2.0.0 文档中,MCP Server Boot Starter 支持基于注解的服务端开发,@McpTool 可以把 Spring Bean 方法注册为 MCP 工具,并自动生成 JSON Schema。下面示例只展示关键逻辑,实际项目请以你使用的 Spring AI 版本文档为准。
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>
XML
spring:
ai:
mcp:
server:
protocol: STREAMABLE
type: SYNC
annotation-scanner:
enabled: true
java
@Component
@RequiredArgsConstructor
public class OrderMcpTools {
private final OrderQueryService orderQueryService;
@McpTool(
name = "order.lookup_delivery_issue",
title = "Order Delivery Issue Lookup",
description = "Query a non-sensitive order delivery summary for customer support by order number.",
generateOutputSchema = true,
annotations = @McpTool.McpAnnotations(
readOnlyHint = true,
destructiveHint = false,
idempotentHint = true,
openWorldHint = false
)
)
public OrderDeliveryIssueResult lookupDeliveryIssue(
@McpToolParam(
description = "Order number, for example SO202606260001",
required = true
)
String orderNo) {
if (!orderNo.matches("^SO\\d{12}$")) {
throw new IllegalArgumentException("Invalid order number format.");
}
return orderQueryService.lookupDeliveryIssue(orderNo);
}
}
java
public record OrderDeliveryIssueResult(
String orderNo,
String orderStatus,
String deliveryStatus,
String issueReason,
String suggestedAction,
boolean needHumanSupport
) {
}这里有几个细节值得注意。
name 使用稳定的业务动作,而不是 Java 方法名。这样以后内部方法改名,不影响客户端使用。
description 明确说明"非敏感订单物流摘要",减少模型误以为可以拿到完整订单详情的概率。
readOnlyHint、destructiveHint、idempotentHint 这类注解提示不能替代权限控制,但能帮助客户端和模型理解工具行为。MCP 规范也提醒客户端不能盲目信任工具注解,真正的校验仍然要落在服务端。
返回值用专门的 record,而不是 OrderDO、OrderEntity 或第三方 API 原始响应。这样既能脱敏,也方便生成结构化输出 Schema。
错误信息要让模型能修正,而不是只方便人看日志
MCP 工具调用里有两类错误:协议层错误和工具执行错误。对业务来说,更常见的是参数不合法、查不到数据、状态不允许操作、下游服务超时。
如果直接抛一个"系统异常",模型很难自我修正。更好的做法是把可修正错误表达清楚:
- 订单号格式不正确,请提供以 SO 开头的 14 位订单号
- 该订单不存在或当前用户无权查询
- 物流系统暂时不可用,可以稍后重试
- 该订单已进入人工处理,不建议继续自动查询
这些信息不应该泄露内部实现,但要足够让模型决定下一步:追问用户、换参数、重试,还是转人工。
在 Java 项目里,可以把 MCP Tool 的异常处理收敛到统一层:参数校验错误返回可读原因,权限错误返回模糊提示,下游错误打日志并返回稳定的业务说明。不要把堆栈、SQL、内部服务名返回给模型。
不要让 Tool 继承内部系统的复杂性
很多 MCP 工具难用,不是因为协议复杂,而是因为它把内部系统多年积累的复杂性直接暴露了出去。
比如一个订单查询接口原本支持 20 个条件:用户 ID、商户 ID、渠道、状态、时间、分页、排序、扩展标记。人类开发者知道哪些组合有效,模型却不一定知道。把这些参数全部放进 inputSchema,等于把业务规则考试题交给模型。
更好的处理方式是按 AI 场景拆工具:
| 场景 | 工具设计 |
|---|---|
| 用户问订单到哪了 | order.lookup_delivery_issue(orderNo) |
| 客服核对退款进度 | refund.lookup_progress(refundNo) |
| 运营查看异常订单数量 | order.count_delivery_exceptions(dateRange) |
| 人工审核前读取摘要 | order.read_risk_summary(orderNo) |
每个工具只暴露一个稳定任务。内部可以调多个服务,可以做缓存,可以做字段映射,也可以加入审计。模型只需要理解任务,不需要理解你的微服务拆分。
写操作先别急着开放
查询类工具最适合作为 MCP Server 的第一批能力。它们风险低、容易审计,也能快速验证模型是否真的能帮业务提效。
写操作不是不能做,但要满足更高要求:明确的人类确认、幂等键、权限校验、审计日志、回滚策略、限流和灰度。比如"取消订单""发起退款""修改地址"这类工具,不应该只靠一句 prompt 约束模型。
一个务实的落地顺序是:
- 先开放只读摘要工具。
- 再开放带强校验的草稿生成工具,比如生成工单草稿、生成回复建议。
- 最后再考虑带确认流程的写操作。
MCP 让模型能够"行动",但企业项目真正需要的是可控行动。Tool 设计越克制,后续扩展越稳。
真正的设计产物不是代码,而是工具契约
如果团队要认真落地 MCP,可以给每个 Tool 建一份很短的契约文档:
- 工具名
- 适用场景
- 不适用场景
- 参数说明
- 返回字段
- 是否只读
- 是否需要用户确认
- 权限范围
- 审计字段
- 失败时模型应该怎么处理
这份文档比代码更重要。因为 MCP Tool 一旦被客户端、Agent 或 Prompt 引用,就会变成 AI 应用的一部分公共契约。随意改名、改字段、改语义,带来的影响不亚于改一个外部 API。
Java 后端做 MCP,不缺把方法注册成工具的能力,真正缺的是把业务能力重新整理成"模型能稳定理解、系统能安全执行、团队能长期维护"的工具契约。把这一步做好,MCP 才不是一层新包装,而是 AI 应用接入企业系统的工程边界。