摘要:
水下音频识别在识别航行中的船只方面发挥着重要作用。水下目标识别任务在海洋环境保护、船舶辐射噪声检测、水下噪声控制和沿海船舶调度等领域有着广泛的应用。传统的UATR(水下声学目标识别)任务涉及训练网络从音频数据中提取特征并预测船只类型。当前的UATR数据集在持续时间和样本数量方面均存在不足。在本文中,我们提出了Oceanship,一个大规模且多样化的水下音频数据集。该数据集包含15个类别,总时长达121小时,并包含坐标、速度、船只类型和时间戳等全面的注释信息。我们通过爬取和整理2021年至2022年间海洋通信网络(ONC)数据库中的原始通信数据编译了该数据集。虽然音频检索任务在通用音频分类中已相当成熟,但在水下音频识别背景下尚未得到探索。利用Oceanship数据集,我们引入了一种名为Oceannet的水下音频检索基线模型。该模型在Deepship数据集上实现了67.11%的top-1召回率(R@1)和99.13%的top-5召回率(R@5)。
关键词:水下声学目标识别,音频检索,零样本分类。
1 引言
水下声学目标识别(UATR)在船舶声学领域至关重要,其旨在自动识别和分析目标发出的声音 1。通过声音对船只进行识别,为水下环境监测系统中的噪声来源提供了宝贵的见解。在UATR发展的早期阶段,由于数据集的稀缺性,大量研究工作是在保密状态下进行的。研究人员采用包括MFCC 2、GFCC 3、CQT 4在内的音频特征提取器来分析水下音频信号 5。然而,在过去十年中,随着深度神经网络的发展以及Deepship 4和Shipsear 6这两个特定数据集的引入,研究人员的焦点已转向水下音频的预处理以及用于监督分类任务的神经网络训练 7。
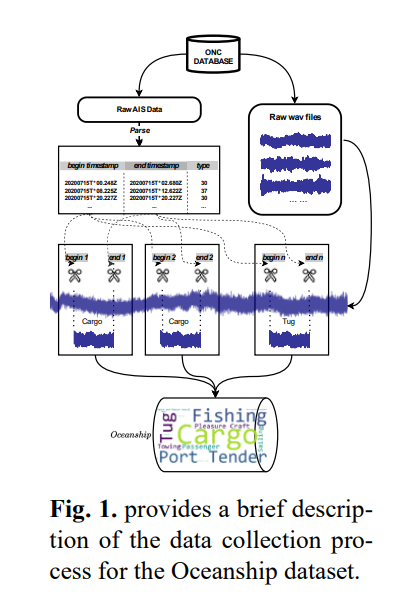
在水下图像识别领域,Liu等人 8 最初强调了水下目标识别的泛化能力。然而,目前尚无研究探讨UATR任务中模型的泛化能力。受CLAP任务 9 的启发,我们可以通过零样本分类和检索任务来评估UATR模型的泛化能力。但是,由于UATR数据的局限性,仅依靠零样本和检索任务设置进行实验是不够的。为了弥补这一差距,我们提出了Oceanship,这是一个以描述丰富性为特征的UATR数据集。它包含107,540个音频 - 文本对。此外,Oceanship在规模上超过了现有数据集230倍以上,使其成为UATR泛化任务预训练数据集的理想选择。Oceanship涵盖了Deepship中的所有类别,同时涵盖了Shipsear中约50%的类别。这种广泛的覆盖简化了跨域模型中的辅助过程,促进了域适应和泛化。值得注意的是,欧盟已经实施了诸如《通用数据保护条例》(GDPR)10 等数据隐私法规,以保护敏感信息。在我们的数据集中,我们精心地将MMSI(海上移动业务识别码)信息转换为ID,以确保不泄露私人船只细节。数据获取过程如图1所示,更多细节见第2节。
最先进的(SOTA)UATR模型UART 7 是将多模态技术整合到UATR领域的开创性方法。UART通过对从小波谱图、文本和音频模态中提取的特征进行对齐来实现训练。与单模态模型相比,UART表现出更卓越的识别能力和增强的泛化性能。在通用分类任务领域,CLIP 11 引入了大规模预训练的概念以实现文本 - 图像对齐,这对于跨模态检索具有重大意义。在此基础上,AudioCLIP 12 取得了重大进展,它通过间接对齐音频和文本模态,代表了通用音频分类领域中跨模态对齐的开创性工作。更进一步,ImageBind 13 利用统一的嵌入方法涵盖了六种不同的模态,包括图像、文本、音频、深度、热成像和惯性测量单元(IMU)数据。需要注意的是,参考文献已相应更新。
随着ChatGPT和Gemini等大模型的出现,通用训练过程逐渐转向在预训练模型上进行微调 14。为解决这一问题,LoRA适配器 15 在Transformer网络中引入了一种注意力层结构,使得使用少于1%的参数即可对大模型进行微调,从而使其适用于下游任务。受这些进步的启发,我们提出了Oceannet模型,该模型结合了带有谱图块(patch)特征的多模态LoRA微调结构。通过全面的实验,我们证明了Oceannet在零样本学习和检索任务中达到了最先进的性能。
2 数据集与任务定义
2.1 水下音频目标识别数据集
目前,有两个开源的水下音频数据集可用:Deepship 和 ShipsEar。我们将讨论 Oceanship 数据集与现有 UATR(水下声学目标识别)数据集之间的差异,并深入探讨这三个数据集的详细信息。
具体而言,ShipsEar 6 是一个数据集,包含 2012 年秋季和 2013 年夏季在西班牙西北部大西洋沿岸不同路段录制的船舶和船只声音。它包含 90 段录音,涵盖 11 种不同的船只类型,并包括信道深度、风力条件、距离和地理坐标等相关信息。此外,其显著优势在于拥有丰富的补充数据,这些知识可作为有价值的先验知识来增强模型训练。然而,它也存在一个重大缺陷:仅包含 3 小时的音频数据,这对于 11 分类任务构成了相当大的挑战。为了缓解这一局限性,该数据集提供了两种分类模式:11 分类和 5 分类。为了满足特定需求,可以根据数据子集将数据归为 5 个主要类别。随后的研究主要集中在实现 5 分类上,而对 11 分类任务的水下音频分类探索仍然有限。
DeepShip 4 建立于 2021 年,是一个源自海洋网络加拿大(ONC)数据的基准数据集 ,专为水下船舶分类而设计。它包含 47 小时 4 分钟的录音,涵盖四个不同类别的 265 艘不同船只。该数据集是其领域内最具权威性的分类资源。值得注意的是,其音频数据时长是 ShipsEar 数据集的 15 倍,且每个类别的实例分布非常均衡。这一特性使得研究人员能够专注于提取音频谱图特征和设计模型。尽管如此,DeepShip 也有其局限性。首先,它包含的类别数量有限,仅占 AIS(自动识别系统)数据集中记录的通信船只类别的 22%。因此,DeepShip 数据集的泛化能力有限
Oceanship( ours,即我们的数据集),如表 2 所示,我们将我们的数据集与现有的两个数据集 Deepship 和 Shipsear 进行了比较。Oceanship 在总时长上是最大的数据集,包含 15 个类别 ,覆盖了遵循 AIS 命名协议后可识别船只名称的 83%。因此,Oceanship 数据集涵盖了 AIS 命名协议规定的所有高频船只。在数据量方面,Oceanship 的时长是 Deepship 数据集的 2.5 倍,是 Shipsear 数据集的 70 倍。因此,与上述数据集相比,Oceanship 数据集的内容呈现出更大的多样性。该数据提供三个版本:细粒度版本包含 53,771 个带有详细注释的音频样本;粗粒度版本包含 53,769 个缺乏航向和速度信息的音频样本 ;最后,完整版(Full)包含 107,540 个带有粗略注释的音频样本。Oceanship (Full) 数据集的样本量至少是 ShipsEar 数据集的 1,000 倍,是 DeepShip 数据集的 200 多倍。
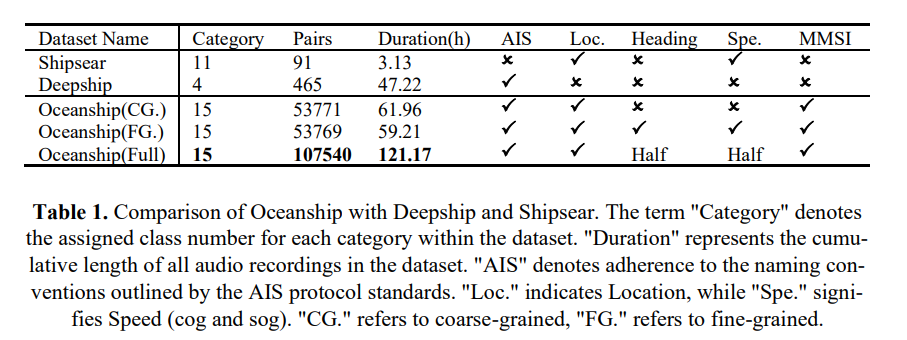
如图 2 所示,展示了 Oceanship 各类别的统计分析。在这些类别中,"货船"(Cargo)和"拖船"(Tug)包含的数据最为丰富,而"潜水船"(Diving ship)和"备用/其他"(Spare)的数据量最少。观察到的数据不平衡源于作者解析了 2020 年 7 月 15 日至 2021 年 2 月 18 日期间几乎所有的船只数据。数据集中每个类别的时长对应于该时间段内的出现频率。
Oceanship 使用的所有数据均源自 ONC(加拿大海洋网络协会,2017)。作者通过令牌访问 ONC 数据库,下载相应年份编码的 AIS 通信消息和对应的音频。如图 1a 所示,第一步是解码 AIS 编码的通信数据以提取可读信息。例如,原始通信数据显示为 "34eG;tE000o:pUBKr00hf's l0Drb,024",并附有相应的时间戳:20200715T000000.036Z,格式为 "YYYYMMDDTHHMMSS...z"。解码此数据需要解析 AIS 通信字段,考虑各种属性,例如:{" x ": -123.4514 , " y ":48.7697 , " sog ":0.0 , "cog":18.6000 , "true_heading":285 , "ais_timestamp":"20200715T 000000.036 Z", "mmsi":"*" , " id ":3}。
鉴于海上移动业务识别码(MMSI)是船只的独特标识符,必要时会使用问号替换船只代码。随后,我们保留相关信息,特别是时间戳细节和船只类型数据 。在所示场景中,由于 MMSI 查询可能失败,导致无法获取包括船只类型数据在内的船只特定细节,因此船只类型仍不确定。
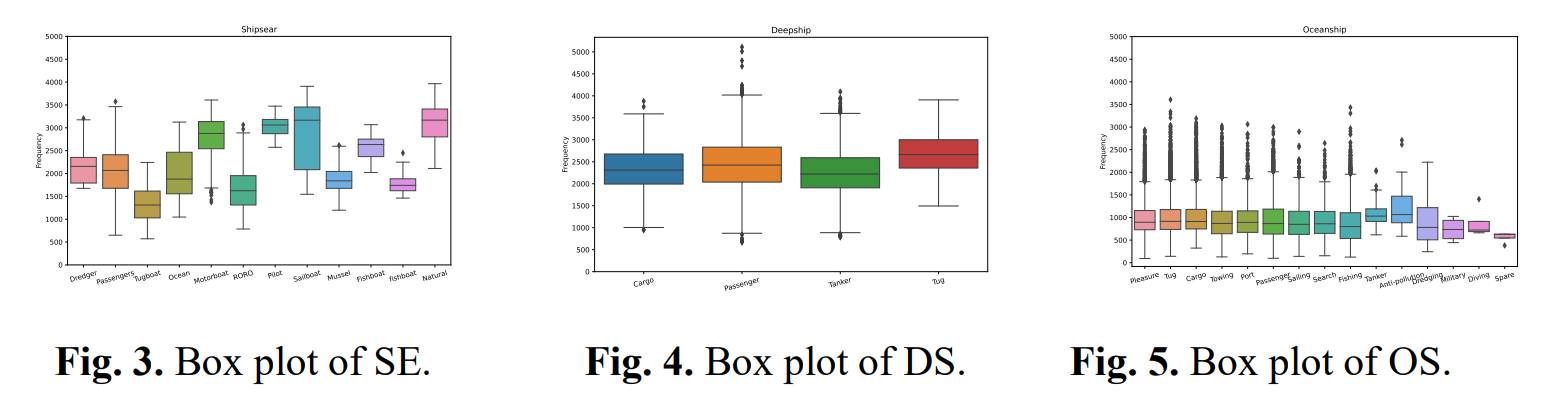
我们根据类别对三个 UATR 数据集进行了频率统计,并生成了箱线图进行可视化。Shipsear 数据集的箱线图如图 3 所示。数据的集中趋势表现出显著变化,但几乎没有异常值,表明数据场景相对稳定。如图 4 所示,与 Shipsear 的表现相比,Deepship 数据的中心频率点在 2000Hz-2500Hz 范围内几乎保持不变。然而,存在大量异常值,表明数据具有更高的多样性。如图 5 所示,Oceanship 数据集展现出最广泛的异常值范围,最高异常值频率超过中心频率点的三倍。这种广泛的频率范围可归因于采样水下场景的动态性质。Oceanship 数据集提供了更丰富的场景多样性,且其 1000Hz 的中心频率点与水下船舶机械声呐的频率范围非常吻合 。
2.2 任务定义
我们将介绍水下声学目标识别(UATR)领域中的历史监督任务,并提出两项新颖的任务:零样本分类任务和检索任务。
这段文字描述的UATR(水下声学目标识别)中的检索任务,本质上是一个跨模态匹配问题。它的核心思想不再是传统的"训练一个分类器来预测类别标签",而是"通过计算音频和文本的相似度,从文本库中找到最匹配的描述"。
以下是对该任务的详细解读:
- 核心目标
在真实的沿海检测场景中,船只类型极其多样(可能有成百上千种),如果为每一种船都训练一个专门的分类节点,或者要求模型必须见过所有类别的样本才能识别,是非常困难且不灵活的。
检索任务的目标是: 给定一段未知的水下音频(比如听到了某种引擎声),模型不需要直接输出"这是货船"这个标签,而是去一个包含各种船只名称描述的文本库中,找出与这段声音最匹配的那个文本描述。 - 工作流程分解
这个任务可以分为三个关键步骤:
第一步:构建文本查询库 (Text Query Set)
研究者预先定义了一个包含 26种 常见船只或噪声类型的文本列表。这不仅仅是简单的标签,而是基于AIS(自动识别系统)命名法的自然语言描述。
例子:'Fishing' (渔船), 'Cargo' (货船), 'Tanker' (油轮), 'Natural ambient noise' (自然背景噪声) 等。
作用:这个列表构成了检索的"字典"或"数据库"。
第二步:双模态嵌入生成 (Embedding Generation)
模型需要同时处理两种不同形式的数据,并将它们映射到同一个数学空间(向量空间)中:
音频端 ( Epa ):输入一段水下录音,模型将其转换为一个向量(音频嵌入)。这个向量代表了这段声音的特征。
文本端 ( Eqt):输入那26个文本描述,模型将它们也分别转换为向量(文本嵌入)。
关键点:训练的目标是让"货船的声音向量"和"货船的文本向量"在空间距离上非常接近,而与其他无关的文本向量距离较远。
第三步:相似度匹配 (Similarity Matching)
计算方法:使用余弦相似度 (Cosine Similarity) 函数。这是一种衡量两个向量方向一致性的数学方法,值越接近1表示越相似。
检索过程:
拿着音频向量 Epa 。依次计算它与文本库中所有26个文本向量
{E1t,...,EMt}的相似度。结果:找出相似度得分最高的那个文本向量 E qt 。
结论:这个得分最高的文本对应的船只类型,就是模型认为的音频来源。 - 这个任务的优势与创新点
零样本/少样本潜力 (Zero-shot/Few-shot Capability):
传统分类任务如果遇到了训练集中没出现过的船型(比如"医疗运输船"),通常无法识别。但在检索任务中,只要我们在文本库里加上"Medical Transport"这个描述,并且模型理解语义,它就有机会通过声音特征匹配到这个新类别,而不需要重新训练整个网络。
灵活性:
如果需要增加新的检测类别,只需在文本列表中添加新的描述即可,无需重新采集大量该类别的音频数据进行训练 。
符合实际场景:
在海洋监测中,往往先有船舶的AIS文本信息(知道有什么船经过),然后去验证听到的声音是否匹配。这种"以文搜音"或"以音搜文"的模式更符合多模态融合的实际应用逻辑。
3 模型架构
受 CLIP 在文本 - 图像分类任务中迁移知识取得部分成功的启发,我们选择直接使用完整的 ImageBind 音频和文本编码器来初始化我们的 Oceannet 模型。这一方法旨在增强其固有的跨模态对齐能力。此外,在预训练阶段,我们利用 LoRA(低秩自适应)适配器同时训练音频和文本模态分支,同时保持 ImageBind 主干网络的参数冻结。如图 6 所示,该框架支持从音频和文本数据中提取特征,并通过评估音频嵌入与文本嵌入之间的余弦相似度来确定音频与文本的对应关系。
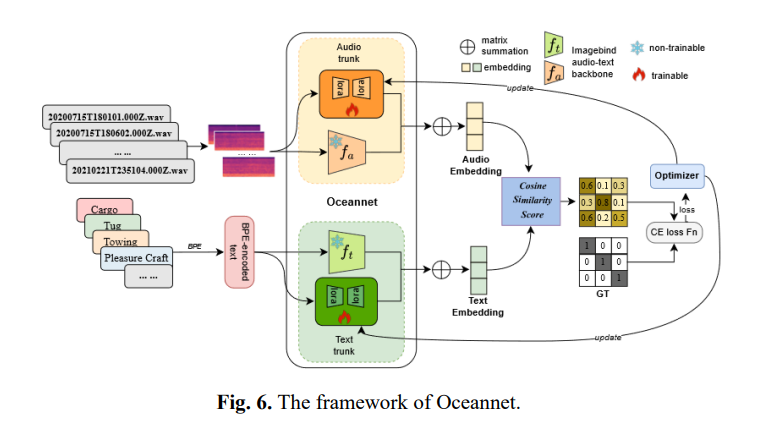

3.3 LoRA微调

3.4 损失函数

4 实验
4.1 超参数与训练细节
如第3节所述,Oceanship 数据集作为我们模型的训练数据。对于音频数据,我们采用5秒的输入时长、240的步长(hop size)、1024的窗长(window size)以及64个梅尔频带(mel-bins)来计算梅尔频谱图。因此,输入到音频编码器的每个样本维度为 (T=1024, F=64)。对于文本数据,我们使用最大长度为77的分词器进行分词。训练过程中,我们采用 AdamW 优化器(β₁ = 0.99,β₂ = 0.9),并配合余弦学习率衰减策略,基础学习率为 1e⁻⁵。模型在 Oceanship 数据集上以批大小64进行训练,共训练200个epoch。所有训练和测试均在 NVIDIA Tesla V100 GPU 上完成。
4.2 音频到文本检索
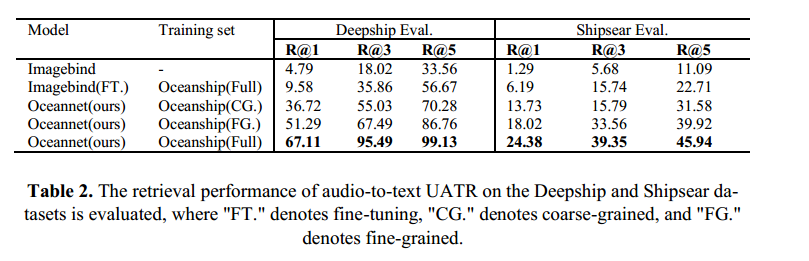
我们开展了一项实验,对比原始 ImageBind 模型、全参数微调(fine-tuned)版本和 LoRA 微调(LoRA-tuned)版本在音频到文本检索任务上的性能。表2中的结果表明:与对包含4.4亿参数的 ImageBind 模型在音频和文本模态上进行全参数微调不同,Oceannet 在 ImageBind 模型基础上仅通过 LoRA 微调(仅训练240万参数)便取得了当前最优(state-of-the-art)的结果 。这是因为对具有大量参数的预训练模型进行全参数微调在收敛性和计算负担方面存在显著挑战。
4.3 数据集规模
因此,我们以 Oceannet 作为基线模型,在表2中开展了全面的音频到文本检索实验。我们采用标准指标计算不同排序位置下的召回率(Recall)。Oceanship (CG.) 数据集包含53,769个文本-音频对,而 Oceanship (FG.) 数据集包含53,771个文本-音频对,二者规模几乎相当。实验结果表明,在文本模态输入中引入细粒度标签可有效提升模型的检索性能。尽管 Oceannet 在 Deepship 数据集上的无监督音频-文本检索(UATR)任务中达到了近乎完美的表现,但在 Shipsear 验证集上的检索性能提升却面临困难。其中一个关键原因是 Oceanship 与 Shipsear 数据集之间存在显著差异------包括数据采集地点不同、所用传感器不同,且两个数据集在类别上几乎没有重叠。因此,在 Shipsear 这一具有显著领域差异的数据集上,上述模型的 R@1(Top-1 Recall)得分仍然相对较低。
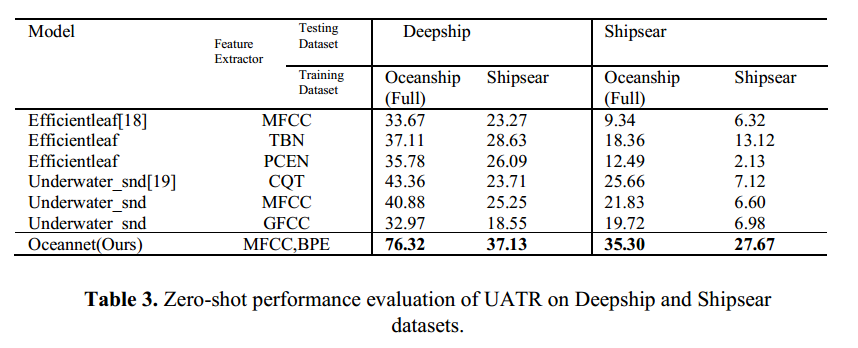
4.4 零样本分类
为评估模型的泛化能力及数据集的适用性,我们在表3中详细展示了相关实验。评估在两个公认的 UATR 数据集(Deepship 和 Shipsear)上进行,采用 Top-1 Recall 作为评价指标。Efficientleaf 和 Underwater_snd 是当前在有监督 UATR 任务中表现优异的开源模型。我们与这些模型以及所提出的 Oceannet 一同进行了四组零样本分类实验,具体包括:
在 Oceanship 上训练,在 Deepship 上测试;
在 Shipsear 上训练,在 Deepship 上测试;
在 Oceanship 上训练,在 Shipsear 上测试;
在 Deepship 上训练,在 Shipsear 上测试。
实验结果表明,我们的模型 Oceannet 在 Deepship 和 Shipsear 两个数据集上的零样本水下音频分类任务中均建立了新的性能标杆。基于上述实验发现,相较于使用 Deepship 或 Shipsear 作为预训练数据集,采用 Oceanship 作为预训练数据集在 UATR 零样本分类任务中展现出更优越的泛化性能。因此,Oceanship 数据集在样本泛化能力方面优于现有的两个数据集。
5 结论与未来工作
本文针对水下音频分类任务中的泛化挑战,首次在水下音频领域明确定义了有监督任务、零样本分类任务和检索任务。为解决零样本分类与检索任务,我们提出了一个名为 Oceannet 的基线模型,并在 Oceanship 数据集上进行预训练。我们的 Oceanship 数据集是目前公开可用的最大规模多标签 UATR 数据集,包含107,540个音频-文本对。与 Deepship 和 Shipsear 相比,Oceanship 不仅标注更为精细、船舶类型更加丰富,而且展现出更强的泛化能力。因此,Oceanship 是当前最适合用于 UATR 泛化任务的预训练数据集。Oceannet 在 Deepship 零样本分类任务上达到76.32%的准确率,在 Shipsear 上达到35.30%。未来的工作将致力于收集更大规模的 UATR 数据集用于训练,并探索在测试集中应用少样本(few-shot)学习方法。