
MCP 高级功能
工具拦截器
接下来我们一起来学习 MCP 的高级使用功能,第一个核心能力就是工具拦截器。
之前讲 MCP 服务器时,我们分别定义过工具、资源、提示词模板,也逐一讲解了它们的用法与核心知识点,当时就提到:我们可以借助工具拦截器,对工具返回的结果做自定义更新。
当时我们写过一段拦截器代码,它的作用和我们之前学过的中间件非常相似。逻辑是:调用工具拿到返回结果result后,我们能对result里的content内容做自定义处理【多添加了一个结构化返回字段】,这套处理逻辑全部依靠工具拦截器实现。
使用方式也很简单: 拦截器必须定义为异步函数,然后将拦截器配置到客户端 MultiServerMCPClient 初始化参数里的 tool_interceptors 配置项,值是一个列表,把我们写好的拦截器函数放进列表即可;多拦截器可以依次往列表追加。绑定完成后,后续实际调用 MCP 工具时,就能通过这个拦截器,在工具执行前做前置处理、工具执行后做后置处理。
以上是我们之前简单接触过的工具拦截器,当时只写了一个简易示例,让大家知道有这个功能、能修改工具返回结果。本篇我们就深入拆解,讲清楚工具拦截器真正能落地的各类业务场景,搞明白它到底具备哪些能力。
为什么需要工具拦截器?
MCP 服务器作为独立进程 运行,它们无法直接访问 LangGraph 的运行时信息 ,例如存储(store)、上下文(context)或 Agent 状态(state)。
拦截器(Interceptors)填补了这一空白,它在 MCP 工具执行期间提供了访问这些运行时上下文的途径。同时,拦截器也提供了类似中间件的控制能力:可以修改请求、实现重试逻辑、动态添加请求头,甚至完全中断执行。
核心能力 1:访问运行时上下文
当 MCP 工具在 LangChain Agent(通过 create_agent 创建)内部使用时,拦截器会接收到 ToolRuntime 上下文。 这使得我们可以访问 tool_call_id 工具调用 ID、state 状态、config 配置和 store 存储,从而实现访问用户数据、持久化信息和控制 Agent 行为等强大模式。
典型场景:向 MCP 工具调用注入用户上下文
我们先从一个典型业务场景入手:向 MCP 工具调用中注入用户上下文。
python
from fastmcp import FastMCP
mcp = FastMCP("Weather")
@mcp.tool()
async def get_weather(city: str, user_id: str) -> str:
"""获取天气"""
return f"用户[{user_id}]查询: {city} 天气晴朗!"
if __name__ == "__main__":
mcp.run(transport="streamable-http", port=8000)首先看上面基础 MCP 服务代码,这是一个简易天气 MCP 服务器,通过 8000 端口启动 HTTP 服务,服务内只定义了一个get_weather工具。 这个工具和我们之前写的工具有一处明显区别:除了必填的city城市参数,还新增了user_id参数,最终返回的结果会拼接 "用户 xxx 查询 xx 城市天气" 的文本。
这里就出现了一个关键问题【这也是上面说的为什么需要拦截器的具体体现】: MCP 服务器是独立进程运行的,它没办法直接读取 Agent、LangGraph 图里的运行时上下文信息。MCP 服务本身是独立运行的工具进程,和我们的 Agent、LangGraph 运行环境完全隔离。如果我们想把上下文里的信息(比如这里的用户 ID)传给 MCP 工具,只能通过工具入参手动传递 ;如果不主动把user_id当成参数传给工具,MCP 服务器完全无法从 Agent、Graph 的运行上下文里自动读取这个值。
清楚这个底层限制后,我们再写一段客户端调用代码,完整复现这个问题。我们先创建MultiServerMCPClient客户端实例,填入天气服务的 HTTP 地址,先运行代码测试连通性。调用client.get_tools()拉取服务端工具列表,能打印出get_weather就代表客户端和 MCP 服务连接正常。
python
import asyncio
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
from langchain_mcp_adapters.client import MultiServerMCPClient
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0,
)
client = MultiServerMCPClient({
"Weather": {
"transport": "streamable-http",
"url": "http://localhost:8000/mcp",
}
})
async def main():
tools = await client.get_tools()
# for tool in tools:
# print(tool.name)
agent = create_agent(model=model, tools=tools)
response = await agent.ainvoke(
{
"messages": [{"role": "user", "content": "上海的天气如何?"}]
}
)
for msg in response.get("messages"):
msg.pretty_print()
if __name__ == "__main__":
asyncio.run(main())连通成功后,我们基于拉取到的工具创建 Agent,调用create_agent,传入大模型名称和工具列表。创建完成后,调用agent.ainvoke()发起提问,比如让 Agent 查询上海的天气,Agent 会自主调用get_weather工具,最后打印工具返回的结果。
python
================================ Human Message =================================
上海的天气如何?
================================== Ai Message ==================================
好的,我来查询上海的天气情况。
Tool Calls:
get_weather (call_00_CwCiRlTKu4HfZNnLhfpO7099)
Call ID: call_00_CwCiRlTKu4HfZNnLhfpO7099
Args:
city: 上海
user_id: user
================================= Tool Message =================================
Name: get_weather
[{'type': 'text', 'text': '用户[user]查询: 上海 天气晴朗!', 'id': 'lc_ef0a668d-4d47-4325-a5a4-e6a440de7b58'}]
================================== Ai Message ==================================
上海的天气情况如下:
🌤 **上海天气:晴朗!**
目前上海天气晴好,阳光明媚,是个不错的好天气!如果您有出行计划,可以放心安排。
请问您还需要了解其他城市的天气吗?这里会暴露出核心矛盾: Agent 本身只会自主填充提问里明确给出的city参数(上海),但工具要求的user_id参数,Agent 没办法自动填充【随机填充】。 我们的用户 ID、密钥这类信息,是存放在 Agent 的运行上下文里的,我们先定义上下文数据结构:用dataclass声明Context类,里面包含两个属性,一个user_id字符串存储用户 ID,再加一个api_key字段存储第三方接口密钥(比如高德地图密钥,这里只是用来丰富上下文结构,做演示)。
python
@dataclass
class Context:
user_id: str
api_key: str定义好上下文类后,创建 Agent 时通过context_schema参数把这个上下文结构绑定到 Agent。后续调用agent.ainvoke()的时候,我们就能手动传入自定义上下文,比如指定user_id="111"、api_key="sk-xxx"。
python
response = await agent.ainvoke(
{
"messages": [{"role": "user", "content": "上海的天气如何?"}]
},
context=Context(user_id="111", api_key="sk-xxx"),
)上下文已经成功传给 Agent 了,我们现在运行代码测试,看看 Agent 能不能自动把上下文里的user_id传给 MCP 工具。 打印工具返回的ToolMessage结果就能发现问题:返回文本里的user_id并不是我们传入的111,还是模型自动生成的随机默认值。
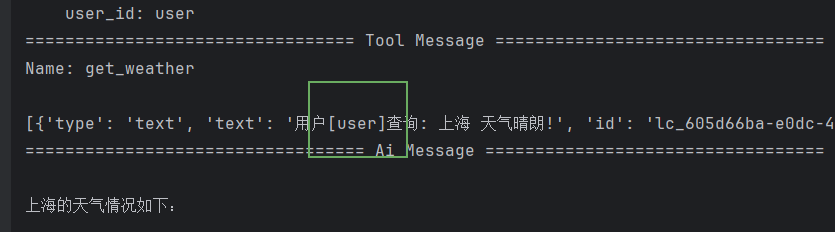
这就说明: 即便 Agent 持有我们传入的上下文,它也无法自动把上下文里的user_id匹配成工具的入参 。 根本原因是大模型没办法自主识别上下文字段的业务含义:不同开发者的命名风格完全不一样,有人存用户 ID 的字段叫user_id,有人简写为uid,还有人直接命名id,大模型无法通过字段名判断这个值是要传给工具的入参,自然不会自动把上下文里的用户 ID 塞进工具调用参数中。
简单总结: 上下文里的字段含义只有开发者自己清楚,大模型没办法自主解析、自动透传给 MCP 工具,必须由我们开发者手动处理上下文数据。
铺垫完所有背景知识,现在解决核心问题:我们已经把user_id=111存入上下文,要怎么把这个值自动传给 MCP 工具的user_id参数? 答案就是工具拦截器,这也是我们铺垫这么多背景,要给大家讲清的拦截器核心用途。
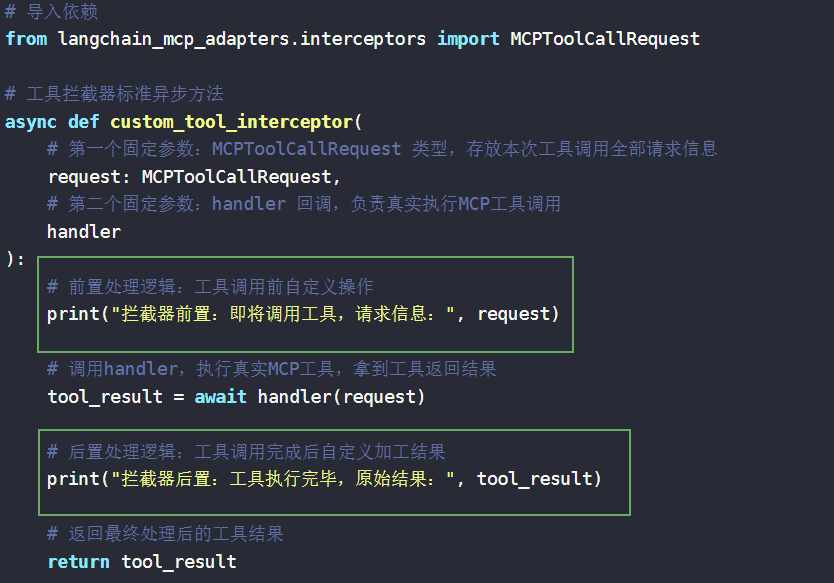
我们先看工具拦截器的标准写法: 拦截器是一个异步方法,固定接收两个参数,第一个是MCPToolCallRequest类型的request(存储本次工具调用的全部请求信息),第二个是handler回调函数,handler才是真正执行 MCP 工具调用的方法。
python
# 导入依赖
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
# 工具拦截器标准异步方法
async def custom_tool_interceptor(
# 第一个固定参数:MCPToolCallRequest 类型,存放本次工具调用全部请求信息
request: MCPToolCallRequest,
# 第二个固定参数:handler 回调,负责真实执行MCP工具调用
handler
):
# 前置处理逻辑:工具调用前自定义操作
print("拦截器前置:即将调用工具,请求信息:", request)
# 调用handler,执行真实MCP工具,拿到工具返回结果
tool_result = await handler(request)
# 后置处理逻辑:工具调用完成后自定义加工结果
print("拦截器后置:工具执行完毕,原始结果:", tool_result)
# 返回最终处理后的工具结果
return tool_result基于这个结构,拦截器可以在调用handler之前执行前置逻辑,也可以在handler执行完、拿到结果后执行后置逻辑,最后返回处理后的结果。
回到我们的需求: 把上下文里的user_id自动注入工具参数,这段逻辑放在拦截器的前置环节处理即可。
从request中取出runtime属性,runtime就是 LangGraph 完整的运行时上下文对象,Agent 本身基于 LangGraph 运行,所以所有运行时数据都存在这里;
python
@dataclass
class MCPToolCallRequest:
"""传递给 MCP 工具调用拦截器的工具执行请求对象。
该工具调用请求的设计模式与 LangChain 的 ToolCallRequest 相近(扁平命名空间),
不会将调用数据、上下文拆分嵌套到多层对象中。
可修改字段(通过 override 方法修改,以此改变工具执行行为):
name: 待调用的工具名称。
args: 工具入参,键值对字典格式。
headers: 适用于 SSE、HTTP 这类传输协议的 HTTP 请求头。
上下文只读字段(仅用于路由分发、日志记录,不可修改):
server_name: 处理本次工具调用的 MCP 服务标识名称。
runtime: LangGraph 运行时上下文(可选,未在图流程内时为 None)。
"""
name: str
args: dict[str, Any]
server_name: str # 上下文只读字段:MCP 服务名称
headers: dict[str, Any] | None = None # 可修改字段:HTTP 请求头
runtime: object | None = None # 上下文只读字段:LangGraph 运行时对象(存在则赋值)
def override(
self, **overrides: Unpack[_MCPToolCallRequestOverrides]
) -> MCPToolCallRequest:
"""基于当前请求生成新请求实例,替换指定属性。
返回全新的 `MCPToolCallRequest` 对象,仅替换传入的指定属性。
采用不可变对象设计模式,原始 request 对象不会被改动。
参数:
**overrides: 关键字参数,用于指定需要覆盖修改的属性。
支持的键名:
- name:工具名称
- args:工具入参字典
- headers:HTTP 请求头
返回:
完成属性覆盖后的全新 MCPToolCallRequest 实例
注意:
server_name、runtime 这类上下文只读字段无法通过该方法覆盖修改。
使用示例:
```python
# 修改工具调用参数
new_request = request.override(args={"value": 10})
# 更换要调用的工具名称
new_request = request.override(name="different_tool")
return replace(self, **overrides)
"""runtime内部包含我们之前定义的context、运行状态state、工具调用 ID 等全部数据,我们通过runtime.context就能拿到传入的user_id和api_key;
这里要注意代码编辑器的语法提示问题: 部分编辑器无法识别runtime.context的类型,会出现波浪警告,但官方源码明确runtime内置context属性,不影响代码实际运行;

拿到上下文里的user_id后,不能直接修改原始request对象(遵循不可变设计模式),要调用request.override()生成全新的请求对象;
重写参数时,先通过**request.args保留工具原本的全部入参(比如这里的city城市参数),再额外追加user_id字段,把从上下文读取到的用户 ID 赋值进去;
生成新的request后,把新请求传给handler执行工具调用,后置逻辑这里暂时不做处理,最后返回工具执行结果。
我们把这个自定义拦截器命名为inject_user_context,功能注释标注为 "将用户上下文注入 MCP 工具调用"。
写完拦截器后,创建MultiServerMCPClient时,通过tool_interceptors参数把拦截器绑定到客户端,完成全部配置。
【完整代码】
python
import asyncio
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
from langchain_mcp_adapters.client import MultiServerMCPClient
from dataclasses import dataclass
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from watchfiles import awatch
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0,
)
@dataclass
class Context:
user_id: str
api_key: str
async def inject_user_context(
request: MCPToolCallRequest,
handler
):
"""将用户凭证注入到 MCP 工具调用中。"""
# 从上下文中读取用户信息
runtime = request.runtime
user_id = runtime.context.user_id
api_key = runtime.context.api_key
# 使用 override() 方式创建修改后的请求(遵循不可变模式)
modify_request = request.override(
args={**request.args, "user_id": user_id}
)
return await handler(modify_request)
client = MultiServerMCPClient(
{
"Weather": {
"transport": "streamable-http",
"url": "http://localhost:8000/mcp",
},
},
tool_interceptors=[inject_user_context],
)
async def main():
tools = await client.get_tools()
# for tool in tools:
# print(tool.name)
agent = create_agent(model=model, tools=tools)
response = await agent.ainvoke(
{
"messages": [{"role": "user", "content": "上海的天气如何?"}]
},
context=Context(user_id="111", api_key="sk-xxx"),
)
for msg in response.get("messages"):
msg.pretty_print()
if __name__ == "__main__":
asyncio.run(main())再次运行代码发起查询,观察打印的ToolMessage结果,就能看到返回文本里的用户 ID 变成了我们手动传入的111,成功实现上下文自动注入工具参数。
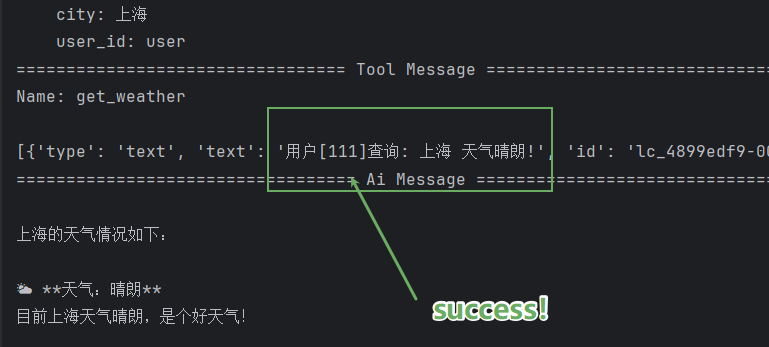
到这里,我们就完整实现了工具拦截器最经典的落地场景: 当 MCP 工具需要依赖 LangGraph 运行上下文的参数时,必须依靠工具拦截器做透传处理。
如果不使用拦截器,只有一种替代方案:把用户 ID、密钥这类信息硬写进提示词,让大模型通过语义推断填充参数,但这种方式稳定性差、不适合生产环境;而通过context结构化传递的上下文数据,大模型无法自主解析,只能由开发者通过拦截器手动读取、重写工具请求参数。
总结这个场景的完整流程: 上下文数据仅开发者知晓业务含义,开发者通过拦截器读取runtime运行时上下文,再通过request.override()重写工具调用参数,完成数据自动注入。
讲完注入用户上下文的场景,我们再拓展runtime运行时上下文里其他可读取的属性: request.runtime除了context上下文,还能读取三大核心数据:state运行状态、store持久化存储、tool_call_id工具调用 ID。
第一,读取state运行状态。
**典型业务场景:**校验用户登录状态,未认证则屏蔽敏感 MCP 工具。
python
import asyncio
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware
from langchain_core.messages import ToolMessage
from langchain_deepseek import ChatDeepSeek
from langchain_mcp_adapters.client import MultiServerMCPClient
from dataclasses import dataclass
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langchain.agents import AgentState
from typing import Any
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0,
)
class State(AgentState):
authenticated: bool
# 创建中间件,关联状态
class CustomMiddleware(AgentMiddleware):
state_schema = State
tools = [] # 可选:为该中间件绑定工具
def before_model(self, state: State, runtime) -> dict[str, Any] | None:
# 在模型调用前可以访问和修改 state
return None
async def authenticate_user(
request: MCPToolCallRequest,
handler
):
"""若用户未通过身份验证,则屏蔽敏感 MCP 工具"""
runtime = request.runtime
state = runtime.state
is_authenticated = state.get("authenticated", False)
if not is_authenticated:
# 返回错误信息,而非调用哦个工具
return ToolMessage(
content="需要进行身份验证,请先登录。",
tool_call_id=runtime.tool_call_id,
)
return await handler(request)
client = MultiServerMCPClient(
{
"Weather": {
"transport": "streamable-http",
"url": "http://localhost:8000/mcp",
},
},
tool_interceptors=[authenticate_user],
)
async def main():
tools = await client.get_tools()
agent = create_agent(model=model, tools=tools, middleware=[CustomMiddleware()])
response = await agent.ainvoke(
{
"messages": [{"role": "user", "content": "上海的天气如何?"}]
}
)
for msg in response.get("messages"):
msg.pretty_print()
if __name__ == "__main__":
asyncio.run(main())拦截器内通过runtime.state.get("authenticated")读取登录状态标识,如果用户未完成身份验证,不需要执行工具调用,直接手动构造ToolMessage返回提示文本 "需要进行身份验证,请先登录";同时从runtime.tool_call_id获取本次工具调用 ID,赋值给消息的tool_call_id字段,保证消息和本次工具调用一一映射,最后直接返回这条提示消息,中断工具执行流程。
python
================================ Human Message =================================
上海的天气如何?
================================== Ai Message ==================================
好的,我来查询上海的天气情况。
Tool Calls:
get_weather (call_00_QvFWLGoJOJTuGRFs59lX0903)
Call ID: call_00_QvFWLGoJOJTuGRFs59lX0903
Args:
city: 上海
user_id: user
================================= Tool Message =================================
需要进行身份验证,请先登录。
================================== Ai Message ==================================
抱歉,查询天气需要先进行身份验证登录。目前我无法直接获取到上海的天气信息。
建议您可以通过以下方式查看上海天气:
1. **手机天气应用**(如系统自带天气、墨迹天气等)
2. **天气网站**(如中国天气网、weather.com等)
3. **语音助手**(如小爱同学、Siri等)
如果您能提供登录信息或授权,我可以再帮您查询。请问还有其他我可以帮助您的吗?简单来说,我们可以依靠状态字段,在拦截器内提前拦截非法工具调用,自定义返回结果。
第二,读取store持久化存储。
store是 LangGraph 的长期记忆存储,我们可以从存储中读取用户个性化偏好配置,在拦截器内重写工具参数,实现 MCP 工具调用个性化。 比如读取用户偏好的语言、结果分页条数,在override重写参数时追加lang、limit等字段,工具会按照用户偏好执行查询逻辑,全部操作都在拦截器前置环节完成。
【server】
python
from fastmcp import FastMCP
mcp = FastMCP("Weather")
@mcp.tool()
async def get_weather(
city: str,
user_id: str,
# 新增可选偏好参数,兼容拦截器自动注入的个性化配置
lang: str = "zh-CN",
limit: int = 10,
timezone: str = "Asia/Shanghai",
temperature_unit: str = "celsius"
) -> str:
"""
获取城市天气
Args:
city: 需要查询天气的城市名称
user_id: 当前操作用户ID
lang: 返回结果语言偏好
limit: 结果展示条数限制
timezone: 用户所在时区
temperature_unit: 温度单位 celsius/fahrenheit
"""
# 根据用户语言偏好返回对应文案
if lang == "en-US":
return f"User[{user_id}] Query: The weather in {city} is sunny! Timezone: {timezone}, Temp Unit: {temperature_unit}, Result limit: {limit}"
return f"用户[{user_id}]查询: {city} 天气晴朗! 时区:{timezone}, 温度单位:{temperature_unit}, 展示条数限制:{limit}"
if __name__ == "__main__":
# 与客户端端口、传输协议完全对应
mcp.run(transport="streamable-http", port=8000)【client】
python
import asyncio
from dataclasses import dataclass
from typing import Any, Optional, Unpack
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import AgentMiddleware
from langchain_core.messages import ToolMessage
from langchain_deepseek import ChatDeepSeek
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langgraph.store.base import BaseStore
from langgraph.store.memory import InMemoryStore
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0,
)
# ============ 状态定义 ============
class State(AgentState):
authenticated: bool = False
user_id: Optional[str] = None # 用户ID,用于查询个性化配置
# ============ 用户偏好数据类 ============
@dataclass
class UserPreferences:
"""用户个性化偏好"""
language: str = "zh-CN" # 语言偏好
limit: int = 10 # 结果分页条数
timezone: str = "Asia/Shanghai" # 时区
temperature_unit: str = "celsius" # 温度单位
# ============ 从 Store 读取用户偏好(store.get 同步,不可使用 await) ============
async def get_user_preferences_from_store(
store: BaseStore,
user_id: str
) -> UserPreferences:
"""
从 LangGraph Store 读取用户个性化偏好配置
注意:langgraph store 读写是同步方法,不能加 await
"""
try:
namespace = ("user_preferences",)
key = f"user_{user_id}"
stored_item = store.get(namespace, key)
if stored_item and stored_item.value:
# 外层value才是我们存的包装字典,真实偏好存在里面的"value"键
wrapper_dict = stored_item.value
prefs = wrapper_dict.get("value", {})
return UserPreferences(
language=prefs.get("language", "zh-CN"),
limit=prefs.get("limit", 10),
timezone=prefs.get("timezone", "Asia/Shanghai"),
temperature_unit=prefs.get("temperature_unit", "celsius"),
)
except Exception as e:
print(f"读取用户偏好失败: {e},使用默认配置")
return UserPreferences()
# ============ 个性化 MCP 工具拦截器 ============
async def personalize_mcp_tool(
request: MCPToolCallRequest,
handler
):
"""
个性化 MCP 工具调用拦截器
功能:
1. 从 LangGraph Store 读取用户偏好
2. 将偏好参数注入到工具调用中
3. 实现透明化的个性化体验
"""
runtime = request.runtime
state = runtime.state
user_id = state.get("user_id", "user_12345")
store = runtime.store
if store:
preferences = await get_user_preferences_from_store(store, user_id)
personalized_args = {
**request.args,
# 下面这些都是工具调用的参数
"user_id": user_id,
"lang": preferences.language,
"limit": preferences.limit,
"timezone": preferences.timezone,
"temperature_unit": preferences.temperature_unit,
}
personalized_request = request.override(args=personalized_args)
print(f"用户 {user_id} 个性化配置已应用: lang={preferences.language}, limit={preferences.limit}")
return await handler(personalized_request)
return await handler(request)
# ============ 身份验证拦截器 ============
async def authenticate_user(
request: MCPToolCallRequest,
handler
):
"""若用户未通过身份验证,则屏蔽敏感的 MCP 工具"""
runtime = request.runtime
state = runtime.state
is_authenticated = state.get("authenticated", False)
if not is_authenticated:
return ToolMessage(
content="需要进行身份验证,请先登录。",
tool_call_id=runtime.tool_call_id,
)
return await handler(request)
# ============ 用户中间件(修复before_model入参) ============
class UserMiddleware(AgentMiddleware):
"""用户中间件:在模型调用前初始化用户状态"""
state_schema = State
def before_model(self, state: State, runtime, config) -> dict[str, Any] | None:
# config 为独立第三个入参,不再读取 runtime.config
configurable = config.get("configurable", {})
user_id = configurable.get("user_id")
print(user_id)
if user_id:
return {
"user_id": user_id,
"authenticated": True
}
return None
# ============ MCP 客户端配置 ============
client = MultiServerMCPClient(
{
"Weather": {
"transport": "streamable-http",
"url": "http://localhost:8000/mcp",
},
},
tool_interceptors=[
authenticate_user, # 1. 先校验登录身份
personalize_mcp_tool, # 2. 注入用户个性化参数
]
)
# ============ 保存用户偏好工具(修复:store.put 同步,移除 await) ============
async def save_user_preferences(
store: BaseStore,
user_id: str,
preferences: dict
) -> bool:
"""保存用户偏好到 Store"""
try:
namespace = ("user_preferences",)
key = f"user_{user_id}"
# 同步方法,删除 await
store.put(
namespace,
key,
{
"value": preferences,
"updated_at": "2026-01-01T00:00:00Z"
}
)
return True
except Exception as e:
print(f"保存用户偏好失败: {e}")
return False
# ============ 写入测试用户偏好 ============
async def example_update_preferences(store: InMemoryStore):
user_prefs = {
"language": "en-US",
"limit": 20,
"timezone": "America/New_York",
"temperature_unit": "fahrenheit"
}
await save_user_preferences(store, "user_12345", user_prefs)
print("用户偏好已更新完成")
# ============ 主执行函数 ============
async def main():
# 全局唯一内存存储实例
mem_store = InMemoryStore()
# 写入测试用户配置,传入有效store,无None报错
await example_update_preferences(mem_store)
# 加载MCP全部工具
tools = await client.get_tools()
# 创建Agent
agent = create_agent(
model=model,
tools=tools,
middleware=[UserMiddleware()],
store=mem_store,
)
# 用户ID通过configurable传入,不会污染输入messages
response = await agent.ainvoke(
{
"messages": [{"role": "user", "content": "上海的天气如何?"}]
},
config={
"configurable": {
"user_id": "user_12345"
}
}
)
# 打印完整对话消息
for msg in response.get("messages"):
msg.pretty_print()
if __name__ == "__main__":
# 仅执行main,删除独立调用example_update_preferences的代码,消除NoneType报错
asyncio.run(main())
python
用户偏好已更新完成
user_12345
用户 user_12345 个性化配置已应用: lang=en-US, limit=20
user_12345
================================ Human Message =================================
上海的天气如何?
================================== Ai Message ==================================
好的,我来查询上海的天气信息。
Tool Calls:
get_weather (call_00_YANDvig3eXJNO0zNFAUT8068)
Call ID: call_00_YANDvig3eXJNO0zNFAUT8068
Args:
city: 上海
user_id: user
================================= Tool Message =================================
Name: get_weather
[{'type': 'text', 'text': 'User[user_12345] Query: The weather in 上海 is sunny! Timezone: America/New_York, Temp Unit: fahrenheit, Result limit: 20', 'id': 'lc_a3976391-18de-4aac-b2df-4238e13b6a47'}]
================================== Ai Message ==================================
上海的天气情况如下:
🌤️ **天气状况:晴天**
不过目前返回的信息中没有显示具体的温度数值。如果您需要更详细的天气信息(如温度、湿度、风力等),请告诉我,我可以进一步为您查询!第三,读取tool_call_id工具调用 ID。
除了上面身份校验场景用来映射返回消息,还能实现接口限流、调用次数统,可以用来限制昂贵的 MCP 工具调用次数。
python
# 拦截器
async def interceptor(request: MCPToolCallRequest, handler):
"""限制昂贵的 MCP 工具调用的次数。"""
runtime = request.runtime
tool_call_id = runtime.tool_call_id
# 检查速率限制(简化示例)
if is_rate_limited(request.name):
return ToolMessage(
content="速率限制已超。请稍后再试。",
tool_call_id=tool_call_id,
)
result = await handler(request)
# 工具调用成功记录
log_tool_execution(tool_call_id, request.name, success=True)
return result拦截器内先获取工具名称,匹配限流规则,如果当前工具调用超出频率限制,直接构造ToolMessage提示 "速率限制已超,请稍后再试";工具调用正常执行完毕后,用tool_call_id记录本次调用日志,留存调用记录方便后续排查。
以上三类场景核心逻辑一致: 读取runtime里的运行时数据,在工具执行前做自定义业务判断,按需重写请求参数、或者直接拦截工具调用、自定义返回消息。
| 可以获取的元素 | 使用场景举例 |
|---|---|
| state | 若用户未通过身份验证,则屏蔽敏感的 MCP 工具 |
| store | 使用 store 的偏好设置来个性化 MCP 工具的调用操作。 |
| Tool call ID | 限制昂贵的 MCP 工具调用的次数。 |
到这里,我们就讲完了工具拦截器的第一个核心能力:访问 LangGraph 运行时上下文 ,依靠runtime读取context、state、store、tool_call_id等数据,自定义改造工具调用的完整链路。
核心能力 2:状态更新与流程控制 (Commands)
接下来我们继续学习工具拦截器的第二个核心能力:状态更新与流程控制。
先给大家拆解这句话的含义: 上面我们写的拦截器,所有操作都属于前置处理 ------ 也就是在工具真正执行之前,读取context上下文、state运行状态这类信息。
但拦截器不止能做前置逻辑,还能在工具执行完成后做后置操作,下面讲解后置逻辑对应的两大能力。
我们先做知识回顾: 之前讲过拦截器的设计思路和中间件高度相似,参数结构、返回规则都是统一的。之前讲 MCP 工具调用MCPToolCallRequest时提到过,拦截器的返回值只有两种合法选择,二选一:第一种是返回ToolMessage工具消息,第二种是返回Command命令对象。拦截器最终返回什么对象,直接决定了后置环节的执行逻辑。
第一种返回类型ToolMessage我们上面已经实操过,它的作用是自定义工具返回的内容、拦截原有工具执行流程;第二种全新的返回类型Command命令,它包含两大核心功能:更新 Agent 运行状态、控制图执行流程跳转。
Command 对象功能 1:更新 Agent 运行状态
先讲Command里的update参数,它的作用是更新 LangGraph 图里的运行状态。上面我们已经知道,在拦截器的request.runtime里可以读取当前state状态;既然能读取状态,自然也支持主动修改、更新状态,这个修改操作就必须依靠Command对象的update字段完成。
这里有一个前置前提:想要更新状态,当前创建 Agent 时必须绑定了状态结构。分两种情况:
-
默认状态: 框架内置的
AgentState,无需自定义,开箱即用; -
自定义状态: 需要我们提前用
dataclass或TypedDict自己定义一套 State 数据结构,创建 Agent 时通过参数绑定,才能在拦截器中修改自定义字段。
举个实操场景: 工具执行完毕后,我们想给状态里的消息列表追加一条记录、或者修改任务进度字段,就可以在Command的update中传入键值对,框架会自动覆盖 / 追加到全局 State 里。
【server】
python
from fastmcp import FastMCP
mcp = FastMCP("OrderServer")
@mcp.tool()
async def submit_order(goods_id: str, user_id: str) -> str:
"""提交订单"""
return f"订单提交成功!用户:{user_id}, 商品:{goods_id}"
if __name__ == "__main__":
mcp.run(transport="stdio")【client】
python
import asyncio
from typing import Any, Optional
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import AgentMiddleware
from langchain.messages import ToolMessage
from langchain_deepseek import ChatDeepSeek
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langgraph.types import Command
from langgraph.store.memory import InMemoryStore
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0,
)
# ====================== 1. 自定义图状态 ======================
class CustomState(AgentState):
authenticated: bool = False
task_status: str = "pending" # pending / completed / failed
# ====================== 2. 修复后的Command拦截器 ======================
async def handle_task_update_interceptor(
request: MCPToolCallRequest,
handler
) -> ToolMessage | Command:
"""
自动填充user_id到工具参数
下单完成仅更新task_status,不手动修改messages,避免消息上下文断裂报错
"""
tool_response = await handler(request)
if request.name == "submit_order":
return Command(
# 更新状态
update={
"messages": [ToolMessage(content=tool_response.content[-1].text, tool_call_id=request.runtime.tool_call_id)],
"task_status": "completed",
},
)
return tool_response
# ====================== 用户中间件 ======================
class UserMiddleware(AgentMiddleware):
state_schema = CustomState
# ====================== MCP客户端 ======================
client = MultiServerMCPClient(
{
"OrderServer": {
"transport": "stdio",
"command": "python",
"args": ["E:/pythonPlace/WorkSpace/LangChain V1/MCP/状态更新【server】.py"]
}
},
tool_interceptors=[
handle_task_update_interceptor,
]
)
# ====================== 主函数 ======================
async def main():
tools = await client.get_tools()
agent = create_agent(
model=model,
tools=tools,
middleware=[UserMiddleware()],
store=InMemoryStore(),
state_schema=CustomState
)
# prompt携带user_id,保证模型触发submit_order工具
response = await agent.ainvoke(
{
"messages": [{"role": "user", "content": "我的用户id是user_666,帮我提交订单,商品ID: 10086"}],
},
)
print("===== 更新后的全局运行状态 =====")
final_state = response
print(f"任务状态 task_status: {final_state.get('task_status')}")
print(f"消息列表长度: {len(final_state.get('messages', []))}")
for msg in final_state.get("messages"):
msg.pretty_print()
if __name__ == "__main__":
asyncio.run(main())
python
===== 更新后的全局运行状态 =====
任务状态 task_status: completed
消息列表长度: 4
================================ Human Message =================================
我的用户id是user_666,帮我提交订单,商品ID: 10086
================================== Ai Message ==================================
好的,我来帮您提交订单。
Tool Calls:
submit_order (call_00_sfmtqkdqeVAvtmo9gTMM4118)
Call ID: call_00_sfmtqkdqeVAvtmo9gTMM4118
Args:
goods_id: 10086
user_id: user_666
================================= Tool Message =================================
Name: submit_order
订单提交成功!用户:user_666, 商品:10086
================================== Ai Message ==================================
订单已成功提交!以下是订单信息:
- **用户ID**:user_666
- **商品ID**:10086
- **状态**:✅ 提交成功
请问还有其他需要帮忙的吗?那我们可以直接改状态吗?
绝对不能直接修改 request.runtime.state["xxx"],强制要求用 Command 更新状态,分三层底层原理讲清楚
底层设计 :LangGraph 的 State 是不可变 (Immutable) 数据结构
LangGraph 图运行时的 runtime.state 并不是普通字典,而是冻结、只读的快照对象:
- 每一轮图执行节点(包括拦截器、Agent、工具调用)拿到的
state都是当前执行快照副本; - 你写
request.runtime.state["task_status"] = "completed"试图原地赋值,要么直接抛「对象不可修改」异常,要么修改仅作用于本地临时副本,不会同步到全局图状态; - 所有对图全局状态的变更,必须产出一份「状态变更描述」交给图调度器,由调度器统一合并、生成全新的下一轮状态快照,这就是
Command(update={})的作用。
简单类比: runtime.state = 只读试卷,只能看不能涂写; Command(update={...}) = 答题卡,你填写要修改的字段,交给系统统一更新整张试卷。
**拦截器执行时机特殊:**直接改 runtime.state 生命周期失效
MCP 工具拦截器的执行时序:
拦截器触发 → 执行 await handler(request) 调用 MCP 工具;
拦截器 return 数据,才会把变更提交给 LangGraph 调度器;
如果你在拦截器中间写 runtime.state["task_status"] = "xxx":
-
只是修改了拦截器函数内的局部临时 state 副本;
-
函数执行完毕后,这个局部修改直接销毁,主图流程完全感知不到;
-
下一个节点、下一轮工具调用读取
runtime.state依旧是旧值。
而 Command 是拦截器的返回值载体 : 框架会识别拦截器返回 Command 对象,提取里面 update 字典,调度器统一合并进全局状态,永久生效到下一轮图执行。
图流程调度器需要感知状态变更,实现链路联动
LangGraph 不止单纯存数据,还依靠状态做:
-
分支跳转、多 Agent 切换 (
Command(goto="xxx")); -
节点条件判断(比如
task_status == completed就跳转到总结节点); -
状态持久化、日志记录、中间件回调;
如果你原地偷偷修改 runtime.state:
-
调度器无法捕获本次状态变更,不会触发分支判断、不会记录变更日志;
-
无法配合
goto实现流程跳转,状态更新和图执行流程割裂;
只有通过 Command 返回变更,调度器才能一次性拿到「要改哪些字段 + 跳转到哪个节点」完整指令,统一调度整张图的后续走向。
方式 1:直接赋值(无效 / 报错)
python
async def bad_interceptor(request: MCPToolCallRequest, handler):
runtime = request.runtime
# 错误写法:试图原地修改state
runtime.state["task_status"] = "completed"
result = await handler(request)
# 直接返回工具结果,无Command
return result现象:
-
要么抛出
TypeError: cannot assign to State field; -
无报错时,后续节点读取
runtime.state["task_status"]依旧是pending,修改完全丢失。
方式 2:Command 标准写法(全局永久生效)
python
async def good_interceptor(request: MCPToolCallRequest, handler):
runtime = request.runtime
result = await handler(request)
if request.name == "submit_order":
# 通过Command告知调度器需要更新的字段
return Command(
update={"task_status": "completed", "messages": [result]}
# 还可以搭配goto控制图跳转,原地修改做不到
# goto="summary_agent"
)
return result现象: 下一轮任意节点、拦截器读取 runtime.state["task_status"] 都是 completed,变更全局生效,同时支持流程跳转。
补充:那中间件 before_model 为什么可以直接返回字典改状态?
你之前写的 UserMiddleware.before_model 返回 {"user_id":"xxx","authenticated":True} 看起来像直接修改,本质逻辑和 Command 完全同源:
-
中间件的返回字典 = 简化版 Command.update;
-
底层框架会自动把返回字典封装成内部变更指令,交给调度器合并状态;
-
拦截器不支持直接返回字典,MCP 工具拦截器规范强制只能返回:
ToolMessage/ 原始工具结果 /Command对象,因此只能靠 Command 传递状态变更。
Command 对象功能 2:goto 流程跳转控制
Command第二个核心属性是goto,专门用来控制 LangGraph 图的执行流向,实现节点跳转,分两种使用场景:
场景 1:goto="end" 提前终止整个 Agent 流程
官方文档标注,给goto赋值特殊值"__end__",就能直接跳转到 LangGraph 的终止节点,整个图的执行流程直接结束,不再继续走后续逻辑,和我们之前学 LangGraph 时设置终止节点的原理完全一致。
我这里给大家实测踩坑结果: 我按照官方示例编写代码测试这个能力时,直接返回Command(goto="__end__")会直接报错。
python
openai.BadRequestError: Error code: 400 - {'error': {'message': "An assistant message with 'tool_calls' must be followed by tool messages responding to each 'tool_call_id'. (insufficient tool messages following tool_calls message)", 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
During task with name 'model' and id '4a72354b-27c5-2de4-173b-bbf4ef710377'报错信息提示: 缺少匹配的ToolMessage工具消息。【其实我们注意上面我们也是加上了对应的ToolMessage + tool_call_id,否则一样的报错】
我们来拆解报错根源: 当前 Graph 的消息队列里,已经存在用户输入的HumanMessage、负责决策调用工具的AIMessage,流程走到拦截器时,原本预期会执行 MCP 工具、生成一条对应的ToolMessage存入消息列表。但我们直接用goto跳到结束节点,跳过了工具执行,消息列表里缺少和本次工具调用匹配的ToolMessage,状态结构不完整,框架校验失败抛出异常。
解决方案:更新状态补充 ToolMessage
想要消除报错,必须在Command的update参数里手动补一条ToolMessage写入消息列表,补齐状态数据:
-
从
request.runtime.tool_call_id获取本次工具调用唯一 ID; -
在
update中给messages消息列表追加一条手动构造的ToolMessage; -
ToolMessage必须绑定刚才拿到的tool_call_id,和之前 AIMessage 里的工具调用 ID 一一对应,完成消息匹配。
python
return Command(
# 更新状态
update={
"messages": [ToolMessage(content=tool_response.content[-1].text, tool_call_id=request.runtime.tool_call_id)],
"task_status": "completed",
},
goto="__end__"
)补齐消息后代码不会再报错,状态更新功能可以正常生效。但我们继续运行验证goto="__end__"终止能力,发现流程并不会直接结束: 代码执行顺序依旧是:HumanMessage → AIMessage → 我们手动补充的ToolMessage → 大模型再次发起新一轮工具决策,重新进入拦截器逻辑,循环往复,完全没有触发终止。【打印结果跟上面的 Command 对象功能 1:更新 Agent 运行状态打印结果一样】
结合实测结论给大家说明: 截至我写这篇博客当前,goto="__end__"提前结束流程的官方写法存在框架 Bug,无法正常生效。或许后面大家可以自行拉取最新代码测试,如果新版本修复了 Bug,这个写法就能正常使用;即便目前无法生效,我们也要掌握官方标准用法,作为知识点记下来。
场景 2:goto 跳转到其他子 Agent(多智能体场景)
除了终止流程,goto还支持跳转到 Graph 里其他自定义节点,最典型的落地场景就是多 Agent 协同系统。
这块内容需要等我们后面完整学习多智能体章节才能彻底吃透,这里先简单铺垫概念: 复杂业务场景不会只靠单个 Agent 完成全部任务,通常会搭建一套多智能体架构:
-
**1 个主路由 Agent:**负责接收用户问题,判断任务类型,做路由分发;
-
**多个子任务 Agent(A/B/C):**分别处理不同细分业务。
在这套架构里,我们就可以在工具拦截器返回Command,通过goto="子Agent节点名"手动控制流程跳转到指定子 Agent,实现任务路由分发。这个属于高阶拓展能力,大家先记住拦截器支持跨 Agent 跳转这个特性即可。
python
if request.name == "submit_order":
return Command(
update={
# 将工具结果添加到消息列表,并更新自定义状态字段
"messages": [result] if isinstance(result, ToolMessage) else [],
"task_status": "completed",
},
goto="summary_agent", # 指定跳转的目标节点
)总结: 拦截器可以返回 Command 对象,用于更新 Agent State 或控制 LangGraph 图的执行流向。这在跟踪任务进度、在 Agent 间切换或提前结束执行时非常有用。
工具拦截器第二个核心能力「状态更新与流程控制」整体分为两块:
1. 状态更新: 依靠Command.update修改全局 State,实测功能稳定可用;
2. 流程控制: 依靠Command.goto实现节点跳转,分两种用法
-
**
goto="__end__":**官方推荐提前终止流程,但当前版本存在 Bug 无法生效; -
**
goto="其他节点名称":**多智能体架构下,跳转到其他子 Agent 完成任务分发。
到这里,工具拦截器的两大核心能力就全部讲解完毕: 第一是访问运行时上下文(前置处理),第二是通过返回Command实现状态更新、流程跳转(后置流程控制)。
编写自定义拦截器:模式与最佳实践
接下来我们一起学习,手动编写 MCP 工具拦截器时的各类通用最佳实践,下面内容都是知识点总结,我们逐条梳理理解即可。
基本拦截器模式
首先明确拦截器固定入参:所有拦截器统一接收两个参数,分别是request和handler。
-
request: 本次 MCP 工具调用的请求对象,类型为MCPToolCallRequest,存储本次工具调用全部请求信息; -
**
handler:**回调函数,调用它才会真正发起 MCP 工具请求。
基于这个基础结构,第一种通用实践:全链路日志打印。
我们可以在调用handler执行工具之前打印前置日志,记录工具名称、入参;在handler执行完成拿到返回结果后打印后置日志,记录工具返回内容。依靠日志完整记录工具调用全流程,方便后续调试、排查问题。
所以我们可以在调用 handler 前后执行逻辑,或者完全跳过它。
python
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
async def logging_interceptor(
request: MCPToolCallRequest,
handler,
):
"""在执行前后记录工具调用日志。"""
print(f"[calling tool] {request.name} with args: {request.args}")
result = await handler(request)
print(f"[finished tool] {request.name}: {result}")
return result
# 将拦截器列表传递给客户端
client = MultiServerMCPClient(
{
"math": {"transport": "stdio", "command": "python", "args": ["./math_tool_server.py"]},
},
tool_interceptors=[logging_interceptor],
)修改请求参数
第二种核心实践: 修改工具调用的请求内容,统一使用request.override()方法,可修改两类内容:
-
工具本身的业务入参(函数参数);
-
远程 HTTP 类型 MCP 服务的 HTTP 请求头。
这里有一条硬性注意事项:严格遵循不可变设计模式,禁止直接修改原始request对象。
不能直接写request.args["xxx"] = xxx这种代码修改原始请求,原始对象只读 ;必须调用override()生成全新的请求实例,在新实例上覆盖参数、请求头,再把新请求传给handler执行。
python
async def double_args_interceptor(
request: MCPToolCallRequest,
handler,
):
"""对工具执行前,将所有数值参数翻倍。"""
modified_args = {k: v * 2 for k, v in request.args.items()}
modified_request = request.override(args=modified_args)
return await handler(modified_request)
# 原始调用:add(a=2, b=3) → 实际执行:add(a=4, b=6)根据运行时的具体内容修改 HTTP 请求头
很多线上 MCP 服务会做接口鉴权,需要在 HTTP 请求头携带 Token、密钥等凭证,我们可以用拦截器统一处理鉴权头,实现全量工具统一权限管控,分两种业务场景给大家区分:
MCP 工具自身自带鉴权逻辑: MCP 服务内部会校验请求头里的 Token,校验通过才执行工具逻辑。这种场景下,我们需要在拦截器通过override自动追加鉴权请求头,给每一次工具调用带上合法凭证,完成服务端鉴权校验。
**MCP 工具本身无鉴权逻辑,但业务要求所有工具调用必须受保护:**即便工具本身不校验请求头,业务侧要求 Agent 侧统一管控访问权限,也可以依靠拦截器实现全局权限拦截:
-
在拦截器内从
request.runtime读取运行时state、context上下文,取出当前用户身份、权限标识; -
增加权限判断逻辑,如果用户无对应工具访问权限,直接返回
ToolMessage告知用户无权限,不执行handler、不发起工具调用; -
如果校验通过,再正常调用
handler执行工具。
这种方案的优势: 不用改造每一个 MCP 服务,在 Agent 客户端一层统一做权限拦截,全局管控所有工具的访问权限。如果工具本身自带鉴权、同时拦截器又追加鉴权头,会形成双重校验,安全性更高。
python
async def auth_header_interceptor(
request: MCPToolCallRequest,
handler,
):
"""根据被调用的工具名称动态添加相应的 header。"""
token = get_token_for_tool(request.name) # 假设这是获取令牌的自定义函数
modified_request = request.override(
headers={"Authorization": f"Bearer {token}"}
)
return await handler(modified_request)错误处理与重试机制
**第三种生产级实践:**异常捕获、自动重试、错误降级。 调用远程 MCP 工具时很容易出现网络超时、连接失败、服务报错等异常,拦截器可以统一处理异常逻辑:
**重试机制:**捕获工具调用抛出的异常,设置最大重试次数、重试间隔;循环发起调用,调用成功则直接返回结果;如果达到最大重试次数依旧报错,再进入降级逻辑。
**错误降级兜底:**区分不同异常类型做差异化返回:超时异常、连接异常分别返回对应的友好提示文本,把报错信息封装成正常的返回内容,不会直接抛出崩溃中断 Agent 流程。即便工具调用失败,Agent 依旧能正常向下执行,只是返回异常说明给大模型,避免整个智能体任务直接中断。
使用拦截器捕获工具执行时的异常,并实现健壮的重试逻辑。
python
import asyncio
async def retry_interceptor(
request: MCPToolCallRequest,
handler,
max_retries: int = 3,
delay: float = 1.0,
):
"""重试失败的工具调用,采用指数退避策略。"""
last_exception = None
for attempt in range(max_retries):
try:
return await handler(request)
except Exception as e:
last_exception = e
print(f"工具 {request.name} 调用失败 (尝试 {attempt+1}/{max_retries}): {e}")
await asyncio.sleep(delay * (2 ** attempt))
raise last_exception错误降级处理
捕获特定异常后,可以不抛出错误,而是返回一个兜底值,保证流程继续。
python
async def fallback_interceptor(
request: MCPToolCallRequest,
handler,
):
"""工具执行失败时返回一个兜底响应。"""
try:
return await handler(request)
except TimeoutError:
return f"工具 {request.name} 超时。请稍后再试。"
except ConnectionError:
return f"无法连接到 {request.name} 服务。使用缓存数据。"组合多个拦截器:洋葱模型
第四种实践: 多个拦截器同时配置时,执行顺序遵循洋葱模型(和我们之前学的多层中间件执行规则完全一致)。
举个例子: 客户端配置tool_interceptors=[outer_interceptor, inner_interceptor],外层拦截器在前,内层拦截器在后:
-
**执行前置逻辑顺序:**外层拦截器前置逻辑 → 内层拦截器前置逻辑;
-
执行核心逻辑: 调用
handler执行真实 MCP 工具; -
**执行后置逻辑顺序:**内层拦截器后置逻辑 → 外层拦截器后置逻辑。
简单流程数字示意:outer_before → inner_before → 工具执行 handler → inner_after → outer_after。 大家配置多个拦截器时,一定要按照业务优先级排序,需要最先执行、最后收尾的逻辑放在列表最外层。
python
async def outer_interceptor(request, handler):
print("outer: before")
result = await handler(request)
print("outer: after")
return result
async def inner_interceptor(request, handler):
print("inner: before")
result = await handler(request)
print("inner: after")
return result
# 客户端配置
client = MultiServerMCPClient(
{...},
tool_interceptors=[outer_interceptor, inner_interceptor],
)
# 执行顺序:outer:before → inner:before → 实际工具执行 → inner:after → outer:after总结
最后我们梳理三大核心能力,把全部知识点汇总:
访问运行时上下文: 通过request.runtime读取context、state、store、tool_call_id等运行时数据,实现用户上下文注入、身份校验、限流等前置业务逻辑;
状态更新与流程控制: 拦截器可返回Command对象,通过update更新 Agent 全局状态,通过goto控制流程图跳转,支持提前终止任务、多 Agent 路由分发;
自定义拦截器标准化编写规范: 统一入参request, handler;使用override修改请求;增加日志、鉴权、重试、降级等通用逻辑;多拦截器遵循洋葱模型排序执行。
| 核心功能 | 关键点与原文描述 |
|---|---|
| 访问运行时上下文 | 通过 request.runtime 访问 state、config、store、context、tool_call_id;原文案例:向工具注入用户上下文 |
| 状态更新与流程控制 | 返回 Command 对象更新 Agent 状态;goto 跳转节点;goto="__end__" 提前终止执行;原文案例:任务完成跳转、成功提前结束 |
| 编写自定义拦截器 | 基本结构:async def func(request, handler): ... 修改请求:使用 request.override() 错误处理:捕获异常、重试、兜底降级 组合执行:洋葱模型按列表顺序嵌套执行 |
到这里,MCP 工具拦截器全部核心知识点、实操案例、生产最佳实践就全部讲解完毕,大家可以结合不同业务场景,套用上面的规范和思路开发拦截器。