Multi-omics analysis uncovers the molecular basis of "golden-thread" formation in Phoebe zhennan stems
多组学分析揭示楠木茎干 "金丝" 形成的分子机制

研究要点
- 完成楠木端粒到端粒水平完整基因组组装
- 借助代谢组学联合分析,确定桑色素是形成金丝纹理木材的主要色素物质
- PzF3H2、PzF3′HL、PzFLS2 基因在木质部特异性调控下,催化桑色素生物合成
- MYB-bHLH 转录调控模块激活衰老木质部内黄酮类物质合成通路
摘要
楠木为我国特有濒危树种,其特有的金丝楠木材具备极高经济、生态与文化价值,但该特殊木材性状形成的分子机制尚不明确。本研究成功组装获得楠木端粒水平完整基因组,基因组大小 919.42 Mb,序列重叠群 N50 长度达 84.44 Mb。
通过多组学联合代谢组分析证实,黄酮醇类物质桑色素 是造就金丝表型的核心物质。体外酶活实验与瞬时过表达功能验证表明,PzF3′HL 是调控桑色素合成的关键核心基因。转录组与单细胞核转录组测序结果证实,黄酮合成通路基因呈现年龄依赖性 与木质部组织特异性 表达特征,进而促进黄酮类物质大量积累。
本研究还构建了楠木茎干黄酮生物合成相关调控网络。上述研究结果系统阐明了金丝楠性状形成的遗传基础与生化调控机制,同时为楠木种质资源保护与分子定向育种提供重要理论依据与基因资源。
引言
楠木是我国西南亚热带常绿阔叶林区特有的濒危乡土树种。由于长期乱砍滥伐与原生栖息地遭到破坏,该物种已被录入《中国植物红皮书》并列为濒危物种。楠木树干通直、冠形优美,除具备重要生态价值外,也常作为景观绿化树种广泛栽培。同时,楠木也是名贵金丝楠木 的核心原料树种,其木材自带独特金色纹理、气味清香、质地坚韧耐腐,自古便是故宫等皇家古建筑的核心用材。
在中国古代,明清以前金丝楠木专供皇家宫殿营建与祭祀礼制使用,是至高皇权的象征。金丝纹理一般需树龄达到 50 年以上才会逐步显现,这也使得其经济价值居高不下:普通原木市场价约 750 美元 / 立方米,埋藏千年的阴沉金丝楠木料单价更是突破 8000 美元 / 吨。目前学界虽愈发重视楠木种质保护与资源可持续利用,但金丝纹理形成背后的生物学调控机制仍尚不清晰。
木材色泽由木质部细胞合成并储存于细胞壁与细胞腔中的吸光类次生代谢物质决定,主要包含黄酮类、萜类、多酚类化合物。这类物质不仅决定木材外观色泽,还直接影响木材经济价值与物理力学特性。树种间、树体不同生长阶段呈现出的木材色差与色泽深浅差异,本质是次生代谢物种类与积累量不同所致。例如黑胡桃心材呈深褐色、乌木通体漆黑、桑木呈黄色,均由各自特有的多酚类、氧化酚类、萘衍生物及黄酮类物质富集模式决定。
除物种固有化学组分差异外,树体生长发育进程与内外环境调控也会进一步改变木材色泽。诸多研究证实,橡树、日本落叶松等树种均存在树龄越大木材色泽越深的规律,该现象与体内酚类等次生代谢物的组成及含量动态变化密切相关;柚木同样会随树龄增长色泽加深,整体色调由偏黄逐步转为偏红。上述研究表明,树龄介导的代谢物质重塑过程,受年龄依赖性分子调控网络精准调控,但其具体作用机制仍有待深入解析。
已有多项代谢组学研究初步解析了楠木木材化学成分:早期研究认为肉桂酸衍生物、香豆素与黄酮类物质是成年植株金丝性状形成的关键物质;后续研究则更侧重异戊二烯脂质、羧酸及类固醇结合物的作用。两类研究结论存在差异,核心原因是目前缺乏高质量染色体水平参考基因组,无法将代谢物时空积累规律与转录调控通路精准关联。
本研究整合 PacBio HiFi 长读长测序、纳米孔超长读长测序、二代短读长测序及 Hi-C 染色体构象捕获技术,组装获得楠木无缺口端粒到端粒(T2T)完整基因组。结合不同发育时期多组学联合分析,明确黄酮醇类物质桑色素 是形成金丝纹理的核心色素;借助单细胞核转录组技术,鉴定出木质部内专一富集黄酮合成通路全套功能基因的特异细胞类群;通过时序调控网络分析,筛选出调控树龄依赖性色素沉积的关键转录因子。本研究不仅填补了楠木高质量基因组资源空白,也系统阐明了金丝楠木性状形成的分子机理,为楠木野生资源保护与定向分子育种奠定坚实理论基础。
结果
楠木无缺口完整基因组组装与功能注释
本研究选取一株百年树龄楠木植株提取高质量基因组 DNA,开展多平台测序,共获得 63.71 Gb PacBio HiFi 数据、49.25 Gb 纳米孔超长读长数据、84.04 Gb 二代短读长数据以及 135.39 Gb Hi-C 染色体构象捕获数据。
分别利用 Hifiasm 与 Verkko 软件整合 HiFi 及纳米孔数据开展初步基因组组装,组装得到的 contig N50 长度依次为 84.78 Mb、58.89 Mb;鉴于 Hifiasm 组装结果连续性更优,将其作为端粒到端粒基因组骨架。再依托 Juicer 与 3D-DNA 软件分析 Hi-C 数据,完成染色体层级挂载,最终锚定得到 12 条染色体。
利用纳米孔超长序列与 Verkko 组装片段完成序列缺口填充,结合二代测序数据进行碱基纠错与序列打磨,最终得到总大小为 919.42 Mb 的无缺口楠木基因组,与 K-mer 预估基因组大小(约 937 Mb)高度吻合。
以植物保守端粒基序 **5′-TTTAGGG-3′** 为参照,在 12 条染色体上完整鉴定出全部 24 个端粒区域;同时成功预测 12 个着丝粒区域及其串联重复序列,并通过着丝粒重复序列核心片段荧光原位杂交实验,验证了着丝粒组装的完整性。
二代测序数据与 HiFi 长读长数据比对基因组的比对率分别达 96.58%、98.85%;BUSCO 评估显示基因组完整度达 97.46%,LTR 组装指数 LAI 为 17.02,各项指标均达到参考级高质量基因组标准。
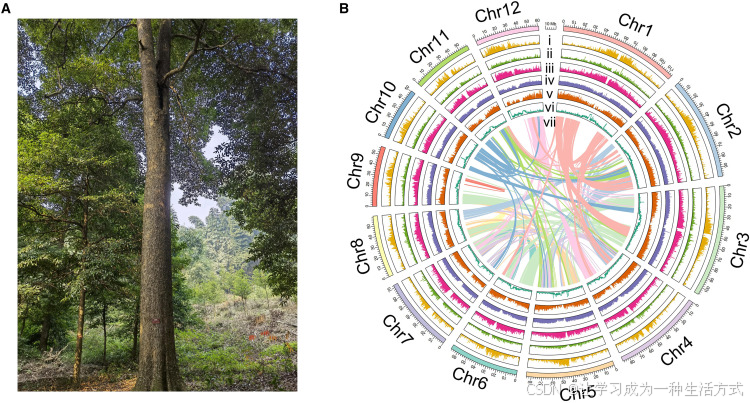
图 1 楠木植株形态与基因组特征
(A) 位于重庆楠木国家级种质资源库的百年古楠木植株(编号 0001)实拍图。 (B) 楠木基因组特征环形图谱。由内至外依次为:(i) Gypsy 类转座子密度;(ii) Copia 类转座子密度;(iii) 长末端重复序列密度;(iv) 全基因组重复序列密度;(v) 基因分布密度;(vi) GC 碱基含量;(vii) 染色体间共线性关系。比例尺:10 Mb。
|--------------------------------|-----------------|
| Assembly ||
| Estimated genome size (Mb) | 936.96 |
| Assembled genome size (Mb) | 953.34 |
| Anchor size (Mb) | 919.42 (96.44%) |
| N50 of contigs (Mb) | 84.70 |
| GC content | 40.79% |
| Repeat region % of assembly | 47.21% |
| LTR Assembly Index | 17.02 |
| Complete BUSCOs | 97.46% |
| Annotation ||
| Number of protein-coding genes | 35,078 |
| Average length of mRNA (bp) | 1,638 |
| Average length of CDS (bp) | 1,195 |
| Average length of exon (bp) | 419 |
| Average length of intron (bp) | 1,639 |
| Average of exon number | 3.9 |
| Annotated to Swiss-Prot | 20,947 (59.72%) |
| Annotated to PFAM | 24,458 (69.72%) |
| Annotated to KEGG | 14,074 (40.12%) |
| Annotated to GO | 21,982 (62.66%) |
本研究共注释得到 35078 个蛋白编码基因,其中95.76% 以上 的基因可在 Swiss-Prot、KEGG、PFAM、GO 任一数据库中获得功能注释(表 1)。研究同时鉴定出楠木基因组中重复序列总长 450.16 Mb,占基因组全长比例为 47.21%,该占比与樟科其他物种相近。
楠木基因组演化与濒危成因分析
本研究选取 6 种樟科植物(楠木、闽楠、鳄梨、阴香、风车子、樟树)及 10 个外类群物种,基于 206 个单拷贝基因构建高分辨率系统发育树。 系统发育结果明确证实:樟属、鳄梨属依次为楠木属的姐妹类群;楠木与同属近缘物种闽楠聚为一支,进化分支支持度极高(图 2A)。
分子钟推演结果显示:楠木属 - 鳄梨属演化支与樟属物种约在1154 万年前 发生分化;楠木属与鳄梨属约在906 万年前 分化;楠木与闽楠的物种分化时间约为542 万年前 。
同义替换率(Ks)分布分析表明,楠木与其余樟科物种共同经历两次全基因组复制事件,两次事件分别发生于约9400 万年前 与1.45 亿年前 ,该结论与前人研究结果一致。 楠木、闽楠与樟树基因组共线性比对结果显示,樟科物种间染色体重排事件发生频率较低(图 2C)。
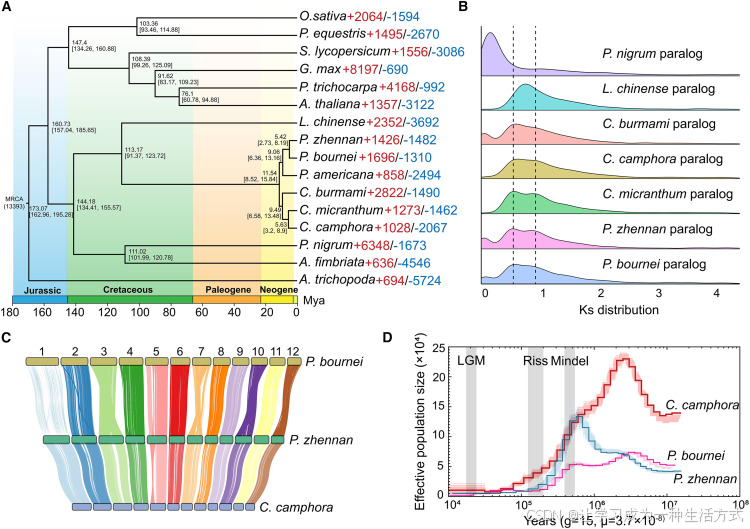
图 2 基因组演化历程
(A) 16 种植物的系统发育关系。时间进化树标注物种分化时间及 95% 置信区间,以基部被子植物无油樟为外类群;红色代表扩张基因家族,蓝色代表收缩基因家族。 (B) 木兰类 7 个物种旁系同源基因的同义替换率(Ks)分布,虚线标注樟科物种共有的全基因组复制事件。 (C) 楠木、闽楠与樟树的基因组共线性分析。 (D) 楠木、闽楠、樟树历史有效种群数量变化;灰色底色区域代表地质历史冰期。Mindel:民德冰期;Riss:里斯冰期;LGM:末次盛冰期。
基因家族分析结果显示,楠木共发生1426 个基因家族扩张、1482 个基因家族收缩 (图 2A)。GO 功能富集表明,这些差异基因主要参与 DNA 复制、次生代谢与环境适应性调控(附图 2A)。 扩张基因按起源分为五类:全基因组复制起源(WGD,28.04%)、串联重复(TD,18.51%)、邻近重复(PD,14.56%)、转座重复(TRD,17.23%)、分散重复(DSD,21.66%)。 其中串联重复与邻近重复基因的Ka/Ks 比值显著偏高 ,说明其受正选择驱动,序列分化速度更快;功能富集显示这类基因主要参与萜类、黄酮类、生物碱等次生代谢物质合成(附图 2C)。
本研究进一步解析濒危物种楠木、易危物种闽楠与无生存危机物种樟树的种群历史动态(图 2D)。 三大物种有效种群数量均在约 60 万年前开始大幅缩减;60 万年前樟树始终维持更大种群规模;楠木自与闽楠分化后,在 70 万 ---250 万年前经历明显种群扩张,长期保有较高有效种群数量。 该种群演化规律与现存物种保护现状相悖,说明近代人为干扰是影响其生存现状的主导因素 。
实地调查现存古楠木野生种群发现,百年以上古树种群碎片化严重,零散分布于四川盆地一带(附图 2D)。现存古树多集中在 100---125 年树龄,150 年以上古树数量锐减,明清时期古古树存量尤为稀少(附图 2E),该年龄结构与古代采伐史料高度吻合,古时皇家营建大肆采伐金丝楠木是主要原因。 物种适宜生境 MaxEnt 模型预测显示,四川盆地及周边长期具备稳定适宜楠木生存的生态环境,排除了气候变迁是其濒危主因的可能性(附图 2F)。 综上,楠木本身具备较强环境适应能力,长期人为过度采伐利用 是其沦为濒危物种的核心诱因。
楠木木材金丝性状的树龄相关特征
为阐明楠木金丝纹理形成的结构基础,本研究开展木材解剖观测与色泽量化分析。 显微观察可见楠木木材表面呈现独特金黄色光泽,明暗相间纹理排布清晰(附图 3A);横切面显微结构显示,亮色区域为切向排布纤维细胞,内腔光滑可形成镜面反射,暗色区域为横向排布细胞壁,以漫反射为主(附图 3D)。 砂纸打磨可褪去表面金色光泽,遇水浸润后光泽恢复,证实金丝光泽由光学反射结构 主导(附图 3B、3C)。 基于 CIE Lab 色彩体系量化结果表明,亮色纹理区域亮度值\(L^*\)、黄蓝轴色度值\(b^*\)更高,与肉眼观测到的金黄色调特征一致(附图 3E)。 综上,楠木金丝性状本质是纤维细胞排布方式造成的黄光反射差异,同时与木材自身黄色色素沉积密切相关(附图 3F)。
树龄是调控木材色泽的关键因子。不同树龄样本分析显示,木材亮度值\(L^*\)、红绿轴色度值\(a^*\)整体波动较小(附图 3G、3H),而黄蓝轴色度值\(b^*\)随树龄增长显著上升,10 年生至 100 年生植株该数值近乎翻倍,说明树龄越大木材黄色调越浓郁。由此可知,金丝纹理性状随树龄逐步凸显,核心诱因是木材黄色素持续积累。
选取树龄 50 年以上成熟木材,对比楠木、闽楠、樟树色泽特征:楠木与闽楠色泽特征高度相近(附图 3I);樟树木材亮度值\(L^*\)、红调值\(a^*\)更高,黄调值\(b^*\)更低,整体色调偏浅偏红(附图 3J)。 证明金丝光学特征为楠木属物种共有性状,樟科近缘树种樟树不具备该特征。
黄酮类物质是楠木木材金丝性状形成的核心物质基础
植物木材色素主要由次生代谢提取物决定。为探明楠木金黄色调形成的生化机制,本研究选取三个发育阶段楠木木材:幼龄期(约 10 年,IS)、过渡期(约 50 年,TS)、稳定成熟期(约 100 年,SS),以樟树为对照开展代谢组检测。 溶剂筛选实验表明,甲醇提取金黄色活性物质效果最优,乙醇次之(附图 4A);楠木木材甲醇提取物颜色随树龄增长不断加深,樟树提取物始终呈浅淡黄色。 对比纯甲醇与 70% 甲醇水溶液提取效果,证实甲醇是提取金丝显色物质的高效溶剂(附图 4B);经甲醇充分浸提后的楠木木材彻底失去金色光泽,直接证明金丝显色物质可溶于甲醇 (附图 4C)。
非靶向代谢组差异分析显示,不同树龄楠木、楠木与樟树之间代谢组分差异显著(图 3A,附表 5),共筛选得到 1132 个差异积累代谢物(附图 4D),主要包含酚酸类、黄酮类、生物碱类与脂质类物质(附图 4E)。 KEGG 通路富集结果证实,相较于幼龄期楠木与樟树,百年成熟楠木体内黄酮类物质合成通路活性显著上调 (图 3B),该结果也被定量检测实验进一步验证(附图 4F)。 盐酸 - 镁粉显色反应证实楠木甲醇提取物中富含黄酮、黄酮醇、二氢黄酮、二氢黄酮醇等物质,反应液由黄转红,而樟树提取物无明显显色变化(附图 4G)。 以上结果充分证实,黄酮类物质大量积累是楠木金丝性状形成的关键生化基础。
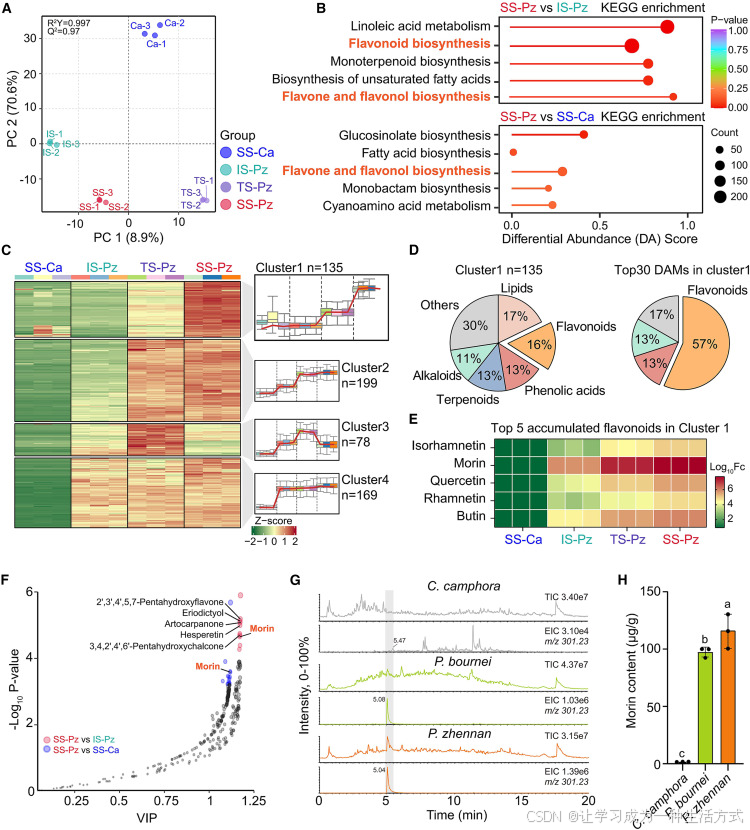
图 3 不同发育阶段楠木与樟树木材代谢组学分析
(A) 四组比较样本代谢物偏最小二乘判别分析(PLS-DA),置换检验结果标注于图左上角。 SS-Ca:成熟期樟树木材;IS-Pz:幼龄期楠木木材;TS-Pz:过渡期楠木木材;SS-Pz:成熟期楠木木材。
(B) 成熟期楠木对比幼龄期楠木、成熟期楠木对比成熟期樟树两组比较中,富集程度排名前五的 KEGG 通路;圆圈大小代表差异积累代谢物数量,颜色代表显著性P 值。
(C) 基于 K 均值算法对差异代谢物进行层次聚类,共划分为 8 个聚类;图中展示表达量呈上升趋势的 4 个聚类(C1~C4),红线为各聚类内代谢物经自标度标准化后的表达趋势。
(D) 聚类 1 中 125 种代谢物的类别占比,以及成熟期 vs 幼龄期差异倍数排名前 30 代谢物的类别分布占比。
(E) 聚类 1 中排名前五黄酮类物质的积累量变化热图。
(F) 基于正交偏最小二乘判别分析(OPLS-DA),统计聚类 1 内 135 种代谢物在两组对比组中的变量重要性投影值(VIP);分别以红色、蓝色标注P 值排名前十的代谢物,并标注所有黄酮类物质。
(G) 成熟期樟树、闽楠、楠木木材甲醇提取物液相色谱 - 质谱联用(LC-MS)总离子流图与提取离子流图;纵轴为相对信号强度(右上角标注最大值百分比),右上角标注提取离子质荷比,灰色区域标注桑色素特征峰(质荷比 m/z=301.23)。
(H) 采用 LC-MS 定量检测成熟期楠木、闽楠、樟树木材内桑色素含量;组间差异采用单因素方差分析结合图基多重检验判定,不同小写字母代表组间存在显著差异,数据为三次生物学重复的平均值 ± 标准差。
为筛选核心功能物质,本研究依据代谢物积累模式对差异代谢物进行聚类分析(图 3C,附表 6)。其中聚类 1 内 135 种代谢物的积累规律与金丝表型高度吻合。 聚类 1 中黄酮类物质占比仅 16%,但在成熟期对比幼龄期差异倍数排名前 30 的上调代谢物里,黄酮类占比超 50%(图 3D,附表 6)。山奈酚、鼠李素、桑色素、槲皮素、异甘草素等排名靠前的富集物质,均属于黄酮、黄酮醇及二氢黄酮类,这类物质在成熟楠木木材中大量积累,在樟树木材中几乎无法检出(图 3E)。
变量重要性投影分析进一步证实,桑色素 是唯一在两组对比中均具备高判别效力的核心标志物(图 3F)。液相色谱 - 质谱定量结果显示,楠木与闽楠木材中桑色素含量显著更高,樟树体内仅存微量桑色素,含量不足楠木的 0.1%(图 3G、3H)。桑色素提取效率变化规律,也与不同溶剂处理下木材色泽变化特征一致(附图 4H)。 综上证实:黄酮类物质,尤以桑色素为核心,是决定楠木木材随树龄形成金黄色纹理性状的关键物质。
黄酮合成通路时空特异性表达调控楠木金丝性状形成
全基因组复制是植物次生代谢演化的重要驱动力,可通过扩张基因家族、催生基因功能分化推动代谢通路多样化。但本研究比较基因组结果显示:具备金丝性状的楠木属物种与无该性状的樟树,经历了一致的全基因组复制事件,物种间染色体重排事件极少(图 2B、2C);苯丙烷通路与黄酮合成通路关键酶基因在物种间也存在高度共线性(附图 5A)。 这说明楠木金黄色木材性状的形成,并非由基因组复制事件主导 ,而是物种演化过程中基因表达调控模式发生特异性分化所致。
为解析金丝性状形成的分子遗传机制,本研究对楠木、闽楠、樟树多组织样本开展比较转录组分析。 樟树体内苯丙烷与黄酮合成通路关键基因主要在叶片、根部表达,茎干中表达量极低(附图 5B);而楠木中此类基因在茎干组织显著上调,且集中在木质部特异高表达(图 4A)。 此外,楠木茎干中花青素合成关键基因PzANS 几乎不表达,与木材中未检测出花青素的结果相互印证(附表 5)。闽楠体内多数黄酮合成基因同样在木质部高表达,仅PbFLS2 表达模式存在差异(附图 5C),表明楠木属物种拥有保守的黄色木材形成转录调控程序。
但闽楠木质部中PbDFR 与PbANS 表达量偏高,会促使部分黄酮醇前体物质流向花青素合成支路,进而弱化金丝纹理表型。 综上可知:楠木体内代谢流大量偏向黄酮及黄酮醇物质合成,最终促成特有金丝纹理性状形成。
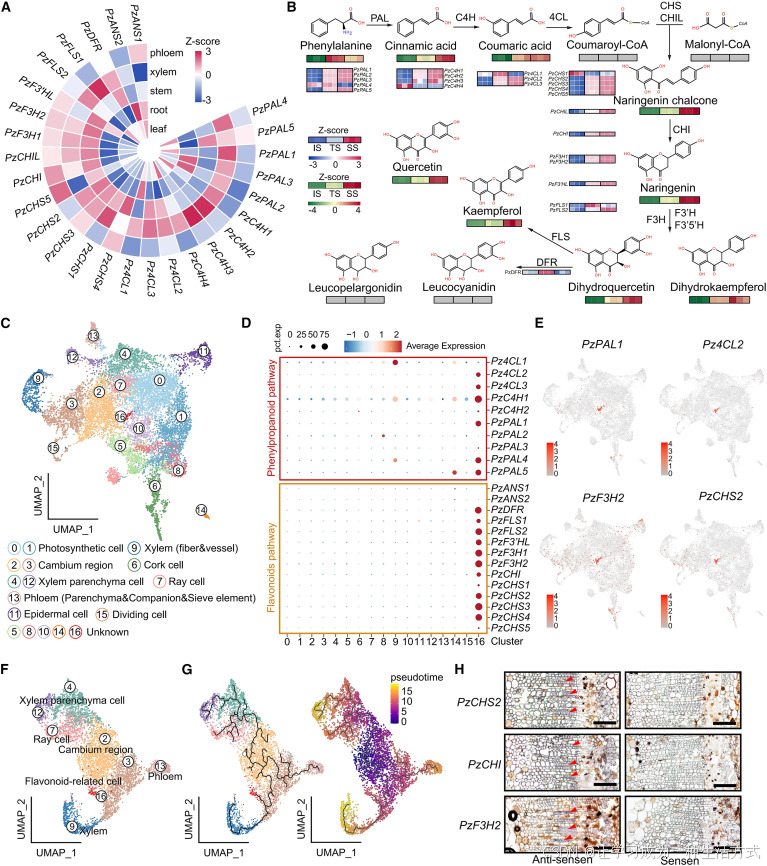
图 4 楠木茎中黄酮通路相关基因的时空表达模式
(A) 苯丙烷与黄酮合成通路关键酶基因在楠木不同组织中的表达特征热图。柱状条代表基因标准化表达量(Z 分数),表达量由低到高以蓝至红色渐变表示。 基因缩写释义: PAL:苯丙氨酸解氨酶;C4H:肉桂酸 - 4 - 羟化酶;4CL:4 - 香豆酸辅酶 A 连接酶; CHS:查尔酮合酶;CHI:查尔酮异构酶;CHIL:类查尔酮异构酶; F3H:黄烷酮 3 - 羟化酶;F3′HL:类黄酮 3′- 羟化酶; DFR:二氢黄酮醇 4 - 还原酶;ANS:花青素合酶
(B) 楠木木材不同发育阶段中,苯丙烷及黄酮通路基因表达量与代谢物积累量的变化规律。柱状图展示幼龄期、过渡期、成熟期三个阶段的基因表达与代谢物含量;基因表达强弱由蓝至红色渐变表示,代谢物积累量由绿至红色渐变表示,灰色柱代表该物质未检出。
(C) 楠木茎组织单细胞核转录组 UMAP 聚类分布图,不同颜色代表不同细胞类群,单个圆点代表一个细胞核,共划分得到 17 类细胞群,各类群已标注数字编号并完成功能注释。
(D) 通路关键酶基因在所有细胞类群中的表达分布点图;颜色梯度代表基因在各类细胞中的平均标准化表达水平,圆点大小代表该基因在对应细胞类群中的表达细胞占比。
(E) 聚类 16 细胞群内苯丙烷、黄酮通路基因表达特征的 UMAP 局部放大图,颜色代表基因在单细胞中的相对表达量。
(F) 基于单细胞核转录组数据划分的组织区域:木质部(4、12、7、9 群)、形成层(2、3 群)、韧皮部(13 群)以及黄酮合成特征细胞(16 群)。
(G) 以形成层细胞(2 群)为起始根细胞,借助 Monocle 3 软件对黄酮特征细胞(16 群)开展拟时序发育轨迹分析。
(H) 原位杂交定位PzCHS2 、PzCHI 、PzF3H2 基因在楠木茎横切面的表达位置,红色箭头指示杂交信号分布区域,比例尺:50 μm。
为探明木材发育过程中基因表达与代谢物质积累的内在关联,本研究对不同树龄楠木开展转录组测序分析。结果显示,除PzPAL4 、PzC4H4 、Pz4CL1 等少数基因拷贝外,绝大多数苯丙烷与黄酮通路基因的表达量均随树龄增长持续上调,平均表达量上调 33 倍,最高可达 76 倍(图 4B)。
与之对应,查尔酮、黄烷酮、黄酮醇等代谢物也呈现阶段性积累特征,其含量变化与合成通路关键酶基因表达水平高度协同(图 4B、附图 6)。以上结果表明,树龄依赖性的转录激活效应,推动桑色素及其衍生物等黄酮类物质不断富集,最终形成楠木木材特有的金黄色色泽。
细胞类型特异性表达决定代谢物质的组织分布特征,本研究进一步利用单细胞核转录组测序 筛选与金丝性状形成密切相关的功能细胞类群。质控后分别获得楠木 11976 个、樟树 9271 个高质量细胞核,单个细胞核平均表达基因数分别为 1242 个、1589 个(附图 7A、7B)。
经标准化处理与 UMAP 降维聚类,楠木茎细胞划分为 17 个类群,樟树划分为 15 个类群;结合杨树、拟南芥同源标记基因及已发表单细胞数据集,完成两类植株多数细胞群功能注释,包含形成层、木质部、射线薄壁细胞、韧皮部等经典细胞类型(图 4C、附图 8A)。
研究在楠木中鉴定出一类尚未被报道的新型细胞类群 ------16 号细胞群 ,该细胞群几乎同步表达整套苯丙烷与黄酮合成通路基因(图 4D、4E,附表 7)。该类群内超半数细胞可表达苯丙烷通路核心基因,除花青素合酶基因外,其余所有黄酮合成基因均在该细胞群中特异性富集,将其命名为黄酮特征细胞(FACs) 。
木质部细胞虽也能检测到部分苯丙烷通路基因表达,但黄酮合成过程仅特异性发生在黄酮特征细胞中,该表达模式在白杨、鹅掌楸等已发表木本植物茎单细胞图谱中尚未发现;而樟树体内不存在此类功能细胞群,苯丙烷通路基因仅在未注释细胞群微弱表达,黄酮合成基因零散表达于光合类细胞中(附图 8B、8C)。
上述差异证实,物种特异性转录调控程序与黄酮特征细胞的分化形成,是楠木木材黄酮大量积累、进而形成金丝纹理的核心细胞学基础。
借助 Monocle3 开展细胞拟时序轨迹分化分析,以形成层细胞为发育起点,结果表明黄酮特征细胞起源于紧邻形成层的 3 号细胞群,该类细胞可分化形成韧皮部与木质部两大细胞谱系,黄酮特征细胞隶属于木质部分化分支,属于木质部衍生的特化细胞类型(图 4F、4G)。
原位杂交实验证实,黄酮特征细胞特异表达基因集中定位于茎干木质部纤维细胞中,导管分子与射线薄壁细胞无明显表达信号(图 4H)。转录组聚类结果与组织原位定位存在位置偏差,推测黄酮特征细胞并非独立固定细胞谱系,而是一种瞬时特化细胞状态 。
利用 AUCell 软件分析各类细胞次生壁合成相关基因表达水平,发现黄酮特征细胞不表达次生壁核心调控因子与木质素合成基因,仅低量表达纤维素合成酶;多分辨率层级聚类也可将其与典型木质部细胞明确区分(附图 9)。
该类细胞群体数量占比偏低,进一步说明其是由细胞异质性分化形成的特殊转录亚型。综上,黄酮特征细胞可定向合成并富集黄酮类物质,持续推动色素沉积,是造就楠木特有金黄色木材性状的关键功能细胞。
调控桑色素生物合成的核心关键酶鉴定
为解析金丝核心色素桑色素的合成机制,本研究梳理推导桑色素合成通路(图 5A):以柚皮素为初始前体物质,依次经过三步修饰反应完成合成:
- 黄烷酮 3 - 羟化酶 F3H 催化 C 环 C3 位羟基化;
- 黄酮醇合酶 FLS 催化 C2-C3 双键形成;
- CYP75 家族蛋白催化 B 环羟基化修饰。
桑色素带有独特的 2′位羟基,而植物已知黄酮 B 环羟化酶均隶属于 P450 家族 CYP75 亚家族,据此推测楠木体内存在具备黄酮 2′- 羟化酶活性的 CYP75 家族蛋白。
全基因组 P450 基因筛选仅鉴定出 1 个 CYP75B 家族成员ZN25034 ;系统进化分析显示,该基因编码蛋白与单子叶、双子叶植物经典 F3′H 蛋白进化分支存在明显分化,推测其发生功能新分化,具备新型羟基化催化活性,将其命名为类黄酮 3′- 羟化酶 PzF3′HL 。
表达模式分析表明,PzF3′HL 与通路另外两个关键基因PzF3H2 、PzFLS2 均在黄酮特征细胞中高表达,且表达量随树龄上调,三者协同构成完整催化合成通路(图 4B、5B)。
体外酶活实验结合标准品验证证实,三种蛋白酶协同作用可将柚皮素催化生成桑色素;缺失PzF3′HL 后合成反应彻底终止,证实该基因为桑色素合成不可或缺的核心基因。
桑色素与槲皮素互为结构同分异构体,易在一级质谱中难以区分,本研究借助高分辨二级质谱特征碎片离子,明确鉴定反应产物中同时存在桑色素与槲皮素两种物质(图 5D)。
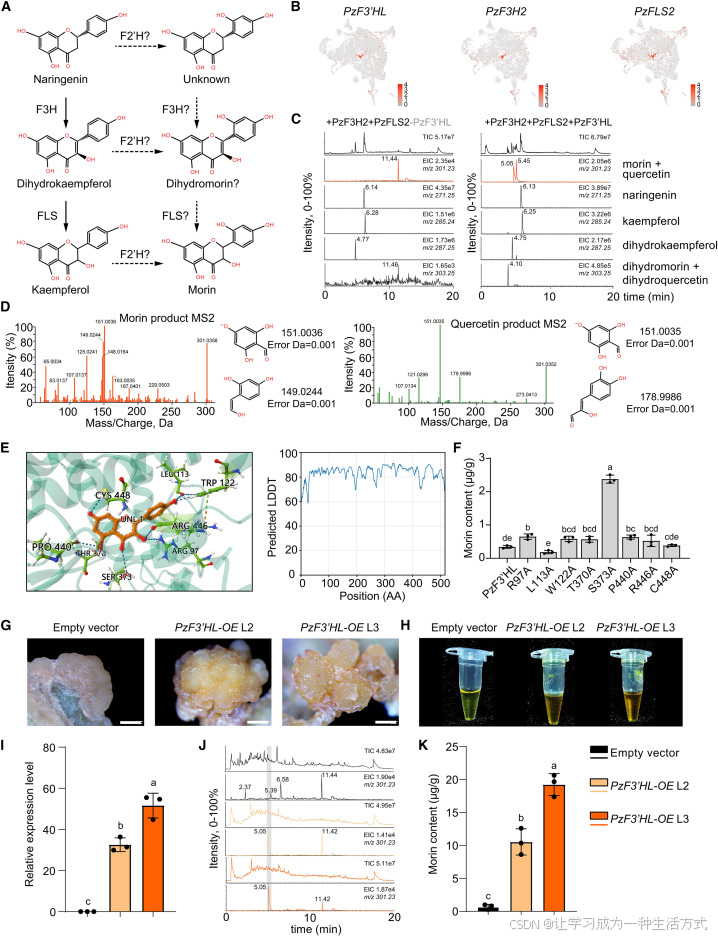
图 5 PzF3′HL 蛋白催化功能验证
(A) 楠木体内桑色素推测生物合成途径,虚线代表尚不明确的合成支路。 (B) 桑色素合成三大关键酶基因在 16 号黄酮特征细胞群中的 UMAP 表达分布,颜色深浅代表基因在单细胞内的相对表达量。 (C) 多酶组合体外反应体系液相色谱总离子流图与提取离子流图;反应体系置于 30℃条件下孵育 4 小时,"+" 代表添加对应重组蛋白,"-" 代表不添加;纵轴为相对信号强度,右上角标注最大信号占比与提取离子质荷比。 (D) 混合酶促反应产物二级质谱图谱,证实产物与桑色素、槲皮素标准品图谱一致。 (E) 山奈酚底物与 PzF3′HL 蛋白结合口袋分子对接模拟;采用局部距离差异分数(LDDT)评估蛋白三维结构预测可信度。 (F) 利用本氏烟草瞬时表达丙氨酸定点突变体,结合液相色谱定量检测突变体系内桑色素含量;组间差异采用单因素方差分析结合图基多重检验判定,不同字母表示差异显著,数据为三次生物学重复平均值 ± 标准差。 (G) PzF3′HL 过表达杨树愈伤组织与空载对照愈伤组织表型对比,比例尺:1 mm。 (H) 过表达株系与空载对照杨树愈伤组织甲醇提取液显色对比。 (I) 异源转化杨树中PzF3′HL 基因相对表达量统计,统计差异检验方式同上。 (J) 杨树愈伤组织甲醇提取物液相色谱总离子流图与提取离子流图,参数标注规则同前文。 (K) 液相色谱定量测定转基因杨树与空载对照提取物中桑色素含量,差异检验方式同上。
为明确各酶蛋白独立催化功能,本研究逐一开展单一蛋白体外酶活实验。结果发现,PzF3′HL 可单独催化山奈酚生成桑色素与槲皮素,且桑色素生成量更高;同时该蛋白可将二氢山奈酚催化转化为二氢槲皮素与二氢桑色素。因两种产物出峰时间高度重合,无法精准定量二者比例。
酶动力学实验证实,PzF3′HL 催化山奈酚生成桑色素的催化效率,是生成槲皮素的约 3 倍;而 PzFLS2 对两种底物催化效率无明显偏好。综上证实,PzF3′HL 是决定楠木高效合成桑色素的核心功能酶 。
为解析该蛋白催化作用机制,通过结构建模与分子对接筛选出 8 个与底物山奈酚直接结合的关键氨基酸位点;进一步采用丙氨酸扫描突变 验证位点功能。 定点突变结合烟草瞬时表达实验结果表明:R97A、W122A、T370A、S373A、P440A 突变可提升酶活性,其中 S373A 增效效果最显著;L113A 突变则显著降低酶活。
动力学数据分析显示,L113 位点突变后,蛋白合成桑色素的催化效率下降约 54%,但对槲皮素合成几乎无影响;S373 位点突变可大幅提升整体催化效率,使槲皮素、桑色素合成效率分别提升约 4.4 倍、2.1 倍。结合分子对接结果可知,L113 位点可直接结合黄酮类物质 B 环 ,是调控 PzF3′HL 行使 2′位羟基化修饰、特异性合成桑色素的核心关键位点。
为验证该基因在木本植物异源体系中的功能,本研究构建毛白杨PzF3′HL 过表达转基因株系。相较于空载对照,过表达株系愈伤组织呈现更深的黄色表型,基因表达量显著上调;其甲醇提取液黄色色泽更浓郁,液相定量结果证实转基因株系桑色素积累量显著高于对照组。 以上结果充分证明,在木本植物中异源表达 PzF3′HL 即可独立驱动桑色素合成积累 。
楠木金丝性状形成的时空转录调控网络
苯丙烷与黄酮通路基因存在明显时空表达差异,表明金丝性状形成受复杂转录调控网络调控。 本研究依托楠木 5 个不同发育时期转录组数据,整合 967 个转录因子与 19342 个结构基因,构建时序基因共表达网络(TO-GCN) 。
结果显示,超过半数转录因子(493 个,占比 51%)在发育早期高表达,而苯丙烷、黄酮合成通路功能酶基因集中在发育后期激活表达。 该表达时序差异说明,发育后期特异性诱导表达的转录因子 ,是启动木材色素沉积、促成金丝表型形成的核心上游调控因子。
进一步筛选与黄酮合成通路基因共表达的晚期转录因子,结果表明:调控苯丙烷通路的核心转录因子共 193 个,以 bHLH、MYB 家族数量最多;调控黄酮合成通路的转录因子中,同样以 MYB、bHLH 家族成员占主导。
综上得出结论:楠木在物种演化过程中重塑MYB-bHLH 转录调控模块 ,通过该核心调控网络时序性激活下游苯丙烷与黄酮整条代谢通路,最终实现黄酮色素定向积累,完成金丝楠木特有表型的建成。
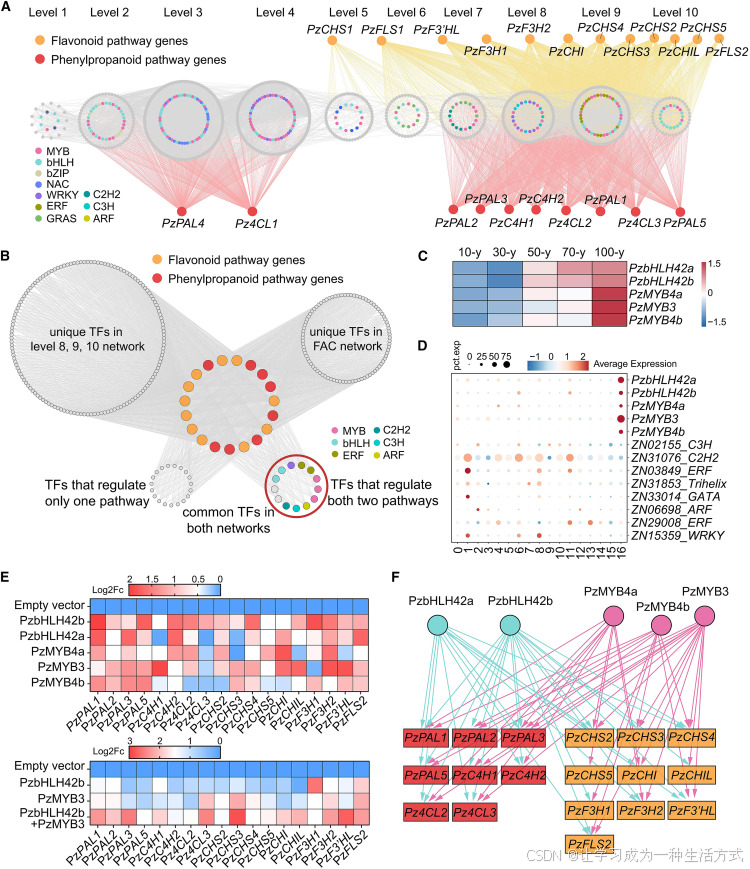
图 6 楠木木材色泽形成相关基因共表达调控网络
(A) 时序性调控网络预测,以及转录因子与苯丙烷、黄酮生物合成通路结构基因的互作关系。灰色圆圈内不同颜色节点代表不同转录因子家族,灰色圆形代表结构基因;圈外橙色节点为黄酮合成通路功能酶基因,底部红色节点为苯丙烷合成通路功能酶基因。1~10 层级代表时序基因共表达网络划分的表达时序等级。 (B) 时序转录网络与细胞特异性调控网络整合关系图。上方灰色圆代表两类网络各自特有转录因子;左下方圆形为两类网络共有、但仅单一调控苯丙烷或黄酮通路的转录因子;右下方彩色圆形为两类网络共有、可同时调控两条通路的转录因子,不同颜色对应不同转录因子家族。 (C) 五大核心转录因子在楠木茎组织中的树龄梯度表达模式。柱状条为基因标准化表达量(Z 分数),表达量由低至高呈蓝至红色渐变。 (D) 两类网络共有的 13 个转录因子在所有细胞类群中的表达分布点图;颜色代表基因在各类细胞中的平均标准化表达水平,圆点大小代表该基因在对应细胞中的表达细胞占比。 (E) 双荧光素酶报告基因转录激活实验热图:分别检测单个 bHLH、MYB 转录因子,以及PzbHLH42b 与PzMYB3 组合对苯丙烷 / 黄酮通路酶基因启动子的激活效应;采用萤火虫荧光素酶报告载体检测,数值为相较于空载对照的对数二倍变化值。 (F) 苯丙烷与黄酮通路基因转录调控模式示意图。方框代表基因启动子,箭头代表转录因子对启动子的激活作用,激活阈值设定为对数二倍变化值≥1。
为解析细胞层面特异性调控机制,本研究依托GRNBoost2 软件,结合 193 个关联苯丙烷、黄酮通路的转录因子,在黄酮特征细胞中构建细胞水平基因调控网络。结果证实 MYB、bHLH 家族转录因子为核心调控枢纽,说明两条代谢通路的时空特异性表达,由保守的核心转录因子群体协同调控。
将时序共表达网络与黄酮特征细胞特异性调控网络联合分析,筛选得到 34 个共有转录因子,其中 13 个可同时调控苯丙烷与黄酮两条通路。结合不同发育时期与单细胞表达特征,最终锁定 2 个 bHLH、3 个 MYB 转录因子为核心调控枢纽。
借助本氏烟草双荧光素酶体系验证转录激活功能,结果显示这 5 个核心转录因子均可显著激活至少 8 个通路基因启动子。其中仅PzMYB4a 可特异性激活PzCHS5 ,其余启动子均可响应多种转录因子调控。启动子顺式作用元件分析发现,通路关键基因启动子区域同时存在 MYB 与 bHLH 结合位点,二者存在协同调控效应;共表达实验也证实,转录因子组合表达对启动子的激活能力远强于单因子表达。
选取与楠木木材性状、木质部黄酮表达模式相近的闽楠开展同源基因比对,闽楠仅鉴定出单个bHLH42 同源基因,且仅PbMYB4a 具备木质部特异表达特性。加权基因共表达网络分析显示,闽楠木质部共表达模块中,仅PbMYB4a 与 13 个黄酮合成基因存在共表达关系。 上述结果表明,楠木属物种内部 MYB-bHLH 调控模块已发生功能分化,这也是不同物种金丝纹理表型存在差异的重要原因。 综上,本研究明确了楠木特有的MYB-bHLH 核心转录调控模块 ,该模块整合植株发育信号与细胞特异性信号,精准调控黄酮物质合成,最终形成楠木独有的金黄色木材色泽。
讨论
木材色泽是名贵用材的核心品质指标,直接决定其观赏价值与经济利用价值。在我国古代,楠木所形成的金黄色金丝纹理使其成为顶级名贵木材,长期专供皇家建筑与礼制建设使用。尽管其文化价值与经济价值极高,但该特有色泽形成的化学物质基础一直缺乏系统解析。
本研究完成楠木端粒水平完整基因组组装,联合代谢组、群体转录组与单细胞核转录组多组学数据,全面阐明了金丝表型形成的遗传基础与细胞学机制。
黄酮类物质是植物体内经典黄色色素,其中黄酮、黄酮醇为主要呈色物质。不同树龄对比、楠木与樟树物种对比代谢组结果均证实,黄酮类物质是楠木木材中上调最为显著的色素大类。 桑色素作为一种五羟基黄酮醇,早在十九世纪就被证实是天然黄色植物染料,其含量随树龄稳步积累,与金丝表型高度绑定;槲皮素、异甘草素等其他黄酮类物质也同步显著富集,各类黄酮物质协同发挥呈色作用。 黄酮醇主要吸收近紫外至蓝光波段光线,从而呈现黄色;多种黄酮共存时,可通过氢键、π-π 堆积等分子间作用发生光谱红移与增色效应,形成黄酮共着色现象。 由此证实,楠木木材金黄色调以桑色素为核心基底,其余黄酮物质协同增强并稳定色泽饱和度。 此外显微结构观测证实,黄色色素均匀沉积于木材次生细胞壁内部;而肉眼所见明暗相间纹理,并非色素分布不均导致,而是木材切面纤维排布方式不同引发的光学反射差异,该结论修正了以往相关研究的传统认知,明确了次生代谢物质组成 + 木材微观解剖结构 共同决定木材外观色泽。该结论也为木材色泽定向改良、林木资源保护与用材培育提供了全新思路。
楠木茎组织单细胞核测序结果揭示了极高的细胞异质性,首次鉴定出可完整表达整套苯丙烷与黄酮合成通路基因的黄酮特征细胞。 但该细胞类群的拟时序分化轨迹,与原位杂交组织定位结果并不完全吻合,这也印证了单细胞生物学中的核心问题:转录组聚类划分的细胞类群,不一定等同于形态学上固定的细胞类型。 细胞聚类结果更多反映细胞所处发育分化阶段、生理代谢状态与空间位置差异,而非严格的形态分类。 类似代谢特化细胞在植物中普遍存在:贯叶连翘的贯叶金丝桃素合成细胞、长春花生物碱合成特异细胞、茶树萜类合成腺毛细胞,均是形态一致组织内分化出的特异代谢功能细胞。 本研究发现的黄酮特征细胞,属于木质部组织内形成的特异代谢细胞状态 ,依靠代谢通路重编程实现功能分化,而非形态结构彻底改变。该发现不仅明确了木材黄酮色素的合成场所,也为利用细胞特异性启动子定向改良木材性状、构建其他名贵用材单细胞转录组图谱奠定了细胞学基础。
楠木木材黄酮合成受双层级转录调控体系 管控:时序共表达网络显示,通路结构基因集中在发育后期高表达,而半数以上转录因子在发育早期启动表达,说明后期特异性转录因子是启动色素合成的关键开关。 在黄酮特征细胞内,两类网络共有的 34 个核心转录因子中,2 个 bHLH 与 3 个 R2R3-MYB 同时具备树龄响应与细胞特异性表达特征。 双荧光素酶实验证实,这类转录因子可广谱激活通路下游多个基因,且 MYB 与 bHLH 存在典型协同激活效应,符合植物经典 MBW 黄酮调控通路模式。 同时研究还鉴定出 WRKY、ERF 等胁迫响应类转录因子,证实外界环境信号可通过胁迫调控网络交叉互作,微调木材黄酮积累量。
近缘物种闽楠同样在木质部表达 MYB-bHLH 调控模块,但同源基因拷贝数与表达强度均显著低于楠木,这也是闽楠极少形成典型金丝纹理的重要原因。 闽楠体内虽存在PzF3′HL 同源基因且与MYB4a 共表达,但其合成桑色素效率偏低,具体是基因发生功能分化,还是上游表达调控受到抑制,仍有待深入解析。 此外,MYB-bHLH 通路随树龄启动表达的上游年龄感应机制尚不明确,植物保守的 miR156-SPL 年龄调控通路在楠木中作用有限,而松树年龄调控同源基因PzDAL1 虽在成熟茎中高表达,但与黄酮通路关联性较弱,推测表观遗传修饰等衰老分子时钟通路,可能主导年龄依赖性黄酮合成激活,后续可围绕年龄感知通路与表观调控开展深入研究。
综上,本研究构建了高质量楠木参考基因组,整合多组学数据系统解析木材色素形成机制:树龄诱导下木质部特异代谢细胞定向合成以桑色素为主的黄酮类色素,该过程受 MYB-bHLH 核心转录模块精准调控。研究成果完善了金丝楠性状形成的生化、细胞与分子调控理论,为楠木种质资源保育、遗传改良与林木代谢育种提供了核心基因资源与理论支撑。
研究局限性
楠木因其珍稀金丝用材价值备受关注,但受物种濒危、基因组资源匮乏限制,相关基础研究进展缓慢。本研究完成楠木 T2T 完整基因组组装,鉴定出桑色素合成关键酶PzF3′HL 及其上游 MYB-bHLH 调控通路,但基因在植株体内的真实生物学功能仍需活体实验验证;目前楠木尚未建立成熟稳定遗传转化体系,极大限制了体内功能验证与代谢定向改良研究。
不同树龄样本转录组差异虽可反映年龄依赖性表达规律,但难以排除植株遗传背景、生长环境、长期逆境胁迫等混杂因素干扰;多年生古树长期积累的环境记忆,会与内源衰老程序相互叠加,无法精准区分纯年龄调控效应,后续可利用无性系植株、可控栽培试验进一步剥离干扰因素。
同时本研究缺少古代皇家金丝楠木遗存样本的多组学比对分析,无法建立现代栽培植株与古建用材之间的遗传与代谢关联;后续可结合古木材代谢组、古 DNA 测序与谱系地理分析,追溯古今楠木种质演化规律,进一步完善相关研究的文化价值与进化研究内涵。
Data and code availability
•
All raw sequence data have been deposited in the National Genome Data Center (NGDC; https://bigd.big.ac.cn/bioproject) under BioProject accession number PRJCA039563. The genome assembly file and all the annotation files of P. zhennan are available at Figshare (https://figshare.com/s/e417b222c99937f4416d).
•
The LC-MS datasets have been deposited to MetaboLights repository with the study identifier MTBLS14137 (https://www.ebi.ac.uk/metabolights/MTBLS14137).
Key resources table
|--------------------------------------------------------------------------------|-------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| REAGENT or RESOURCE | SOURCE | IDENTIFIER |
| Bacterial and virus strains |||
| E.coli DH5α | TOLOBIO | Cat# CC96102 |
| E.coli Rosetta | TOLOBIO | Cat# CC96109 |
| Agrobacterium tumefaciens GV3101 | TOLOBIO | Cat# CC96304 |
| Saccharomyces cerevisiae WAT11 | Coolaber | Cat# CC311 |
| Chemicals, peptides, and recombinant proteins |||
| HIS-PzF3′HL | This paper | N/A |
| HIS-PzF3H2 | This paper | N/A |
| HIS-PzFLS2 | This paper | N/A |
| Protease Inhibitor Cocktail | YEASEN | Cat# 20124ES03 |
| PMSF | Biosharp | Cat# BL507A |
| Critical commercial assays |||
| Ni-NT Aagarose | QIAGEN | Cat# 30210 |
| Biospin Plant Total RNA Extraction Kit | Bioflux | Cat# BSC65 |
| Hieff® qPCR SYBR Green Master Mix Kit | YEASEN | Cat# 11201ES08 |
| Dual Luciferase Reporter Gene Assay Kit | YEASEN | Cat# 11402ES60 |
| Hifair® Ⅲ 1st Strand cDNA Synthesis SuperMix for qPCR (gDNA digester plus) Kit | YEASEN | Cat# 11141ES60 |
| QuickMutation™ Site-Directed Mutagenesis Kit | Beyotime | Cat# D0206M |
| 2 × Phanta Flash Master Mix (Dye Plus) | Vazyme | Cat# P520-02 |
| Deposited data |||
| RNA-seq data | This paper | PRJCA039563 |
| Genome sequencing data | This paper | PRJCA039563 |
| LC-MS data | This paper | MTBLS14137 |
| Experimental models: Organisms/strains |||
| Wild type (Popoulus tomentosa) | Widely distributed | N/A |
| Wild type (Phoebe zhennan) | Widely distributed | N/A |
| Wild type (Cinnamomum camphora) | Widely distributed | N/A |
| Wild type (Phoebe bournei) | Widely distributed | N/A |
| PzF3′HL-OE | This paper | N/A |
| Oligonucleotides |||
| See href="#mmc1" Table S11 | | N/A |
| Recombinant DNA |||
| pET30a-PzF3′HL | This paper | N/A |
| pET30a-PzF3H2 | This paper | N/A |
| pET30a-PzFLS2 | This paper | N/A |
| PzF3′HL-SER373mut | This paper | N/A |
| PzF3′HL-CYS448mut | This paper | N/A |
| PzF3′HL-THR370mut | This paper | N/A |
| PzF3′HL-PRO440mut | This paper | N/A |
| PzF3′HL-ARG97mut | This paper | N/A |
| PzF3′HL-ARG446mut | This paper | N/A |
| PzF3′HL-LEU113mut | This paper | N/A |
| PzF3′HL-TRP122mut | This paper | N/A |
| 1305k-PzF3′HL | This paper | N/A |
| PCXSN-PzF3′HL | This paper | N/A |
| 1305k-PzbHLH42a | This paper | N/A |
| 1305k-PzbHLH42b | This paper | N/A |
| 1305k-PzMYB3 | This paper | N/A |
| 1305k-PzMYB4a | This paper | N/A |
| 1305k-PzMYB4b | This paper | N/A |
| pG0800-proPzPAL1 | This paper | N/A |
| pG0800-proPzPAL2 | This paper | N/A |
| pG0800-proPzPAL3 | This paper | N/A |
| pG0800-proPzPAL5 | This paper | N/A |
| pG0800-proPzC4H1 | This paper | N/A |
| pG0800-proPzC4H2 | This paper | N/A |
| pG0800-proPz4CL3 | This paper | N/A |
| pG0800-proPz4CL2 | This paper | N/A |
| pG0800-proPzCHS2 | This paper | N/A |
| pG0800-proPzCHS3 | This paper | N/A |
| pG0800-proPzCHS4 | This paper | N/A |
| pG0800-proPzCHS5 | This paper | N/A |
| pG0800-proPzCHI | This paper | N/A |
| pG0800-proPzCHIL | This paper | N/A |
| pG0800-proPzF3H1 | This paper | N/A |
| pG0800-proPzF3H2 | This paper | N/A |
| pG0800-proPzF3′HL | This paper | N/A |
| pG0800-proPzFLS2 | This paper | N/A |
| Software and algorithms |||
| GenomeScope | Ranallo-Benavidez et al. href="#bib56" 56 | GitHub - schatzlab/genomescope: Fast genome analysis from unassembled short reads · GitHub |
| Hifiasm | Cheng et al. href="#bib19" 19 | GitHub - chhylp123/hifiasm: Hifiasm: a haplotype-resolved assembler for accurate Hifi reads · GitHub |
| Verkko | Rautiainen et al. href="#bib20" 20 | GitHub - marbl/verkko: Telomere-to-telomere assembly of accurate long reads (PacBio HiFi, Oxford Nanopore Duplex, HERRO corrected Oxford Nanopore Simplex) and Oxford Nanopore ultra-long reads. · GitHub |
| Juicebox Assembly Tools | Robinson et al. href="#bib57" 57 | GitHub - aidenlab/Juicebox: Visualization and analysis software for Hi-C data - · GitHub |
| TGS-GapCloser | Xu et al. href="#bib58" 58 | GitHub - BGI-Qingdao/TGS-GapCloser: A gap-closing software tool that uses long reads to enhance genome assembly. · GitHub |
| RepeatModeler | Flynn et al. href="#bib59" 59 | GitHub - Dfam-consortium/RepeatModeler: De-Novo Repeat Discovery Tool · GitHub |
| Augustus | Stanke et al. href="#bib60" 60 | GitHub - Gaius-Augustus/Augustus: Genome annotation with AUGUSTUS · GitHub |
| HISAT2 | Kim et al. href="#bib61" 61 | GitHub - DaehwanKimLab/hisat2: Graph-based alignment (Hierarchical Graph FM index) · GitHub |
| HMMER | Potter et al. href="#bib62" 62 | GitHub - EddyRivasLab/hmmer: HMMER: biological sequence analysis using profile HMMs · GitHub. |
| InterProScan | Jones et al. href="#bib63" 63 | GitHub - ebi-pf-team/interproscan: Genome-scale protein function classification · GitHub |
| BUSCO | Dudchenko et al. href="#bib23" 23 | GitHub - metashot/busco: Assessing the quality of genomes using busco · GitHub |
| eggNOG-mapper | Cantalapiedra et al. href="#bib64" 64 | GitHub - eggnogdb/eggnog-mapper: Fast genome-wide functional annotation through orthology assignment · GitHub |
| quarTeT | Lin et al. href="#bib65" 65 | GitHub - aaranyue/quarTeT: A telomere-to-telomere toolkit for gap-free genome assembly and centromeric repeat identification · GitHub |
| OrthoFinder | Emms et al. href="#bib66" 66 | GitHub - davidemms/OrthoFinder: Phylogenetic orthology inference for comparative genomics · GitHub |
| RAxML | Stamatakis et al. href="#bib67" 67 | GitHub - amkozlov/raxml-ng: RAxML Next Generation: faster, easier-to-use and more flexible · GitHub |
| CAFE5 | Mendes et al. href="#bib68" 68 | GitHub - hahnlab/CAFE5: Version 5 of the CAFE phylogenetics software · GitHub |
| MCScanX | Wang et al. href="#bib69" 69 | GitHub - wyp1125/MCScanX: MCScanX: Multiple Collinearity Scan toolkit X version. The most popular synteny analysis tool in the world! · GitHub |
| DupGen_finder | Qiao et al. href="#bib70" 70 | GitHub - qiao-xin/DupGen_finder: A pipeline used to identify different modes of duplicated gene pairs · GitHub |
| GraphPad Prism 8.0.2 | N/A | Home - GraphPad |
| Seurat | Satija et al. href="#bib71" 71 | GitHub - satijalab/seurat: R toolkit for single cell genomics · GitHub |
实验材料与研究对象
植物材料与培养条件
毛白杨无性系 741 无菌扦插苗,栽植于添加0.1 mg/L 萘乙酸 的木本植物培养基中,培养温度 25℃,光照时长 16 小时、黑暗 8 小时,光照强度 4500 勒克斯。
楠木木材样本采集自重庆国家楠木种质资源库 ,选取树龄 10~100 年植株,每 10 年为一个梯度;在植株胸高 1 米处钻取木芯,钻取深度为茎干半径(4~20 厘米),取样后立即液氮速冻保存。
樟树木材样本采自西南大学南区成熟樟树林,选取 70~100 年生健康植株,同样在胸高处采集 20 厘米长木芯。所有植株均自然露天生长,无人工灌溉与施肥,均为野生型天然植株,无人工遗传改造;本研究不区分植株雌雄,该物种无明显雌雄形态差异,且性别不影响实验结果。
每个树龄梯度均采集 9 株独立植株样本;靠近髓心向内 2 厘米木芯用于代谢组检测,靠近树皮向外 2 厘米部位用于转录组测序。闽楠 70 年生成熟木材样本由浙江农林大学童再康教授馈赠。所有植物材料采集与使用均严格遵守机构及国家相关管理规范。
微生物菌株与培养条件
质粒构建、原核蛋白表达使用大肠杆菌 DH5α、BL21 (DE3)、Rosetta (DE3) ;植物遗传转化使用农杆菌 GV3101 ;真核蛋白表达使用酿酒酵母 WAT11 。 大肠杆菌与农杆菌分别置于 LB 培养基中,37℃、28℃恒温培养;酿酒酵母采用 YPD 培养基,30℃条件培养。
实验方法详述
木材色泽测定
利用徕卡振动切片机将木芯切成200 微米 厚横切切片,采用国产 CS-520 便携式分光光度计,基于CIE Lab 色彩空间系统 测定色泽参数: \(L^*\):明度值,0 代表纯黑,100 代表纯白; \(a^*\):红 - 绿色相轴,正值偏红,负值偏绿; \(b^*\):黄 - 蓝色相轴,正值偏黄,负值偏蓝。
木材色泽相关活性物质提取
参考已有方法并优化提取体系,选用甲醇、乙醇、丙酮、纯水、乙酸乙酯、石油醚六种溶剂对比提取效率。 木材样品粉碎后过 100 目筛,称取 1g 粉末置于离心管,加入 5mL 提取溶剂,室温超声提取 4 小时;12000 转 / 分钟离心 15 分钟,吸取上清液,经 0.22μm 有机滤膜过滤后,用于色泽检测与液相色谱 - 质谱联用检测。
代谢组检测与数据分析
选取 10 年生幼龄期、50 年生过渡期、100 年生成熟期楠木,以及 100 年生樟树开展非靶向代谢组学分析。每组 9 株植株样本混合分为 3 组生物学重复。 样本冻干研磨粉碎,精准称取 50 mg,加入预冷含内标的 70% 甲醇溶液提取,经振荡、静置、多次萃取、高速离心、滤膜过滤后,采用超高效液相色谱串联质谱 完成物质定性定量检测。
代谢物质谱图谱比对代谢组数据库完成物质鉴定,采用多反应监测模式定量;使用 Analyst 1.6.3 软件处理原始数据,借助正交偏最小二乘判别分析筛选差异代谢物,筛选标准:变量重要性投影值≥1、差异倍数对数值≥1 。
基因组测序
采集国家楠木种质资源库编号 0001 号健康植株新鲜叶片,CTAB 法提取高质量基因组 DNA。
- 二代短片段测序:构建双端文库,DNBSEQ-T7 平台测序,获得约 84 Gb 150 bp 测序数据;
- 纳米孔超长读长测序:建库后于 PromethION 平台测序,产出约 49 Gb 超长序列;
- PacBio HiFi 高精度测序:制备环形模板文库,Sequel II 平台测序,获得约 63 Gb 高准确度长读长数据;
- Hi-C 染色体构象测序:叶片甲醛交联固定,酶切、生物素标记、连接纯化后建库,DNBSEQ-T7 平台测序,产出约 135 Gb 交互测序数据。
基因组组装
利用二代数据结合 GenomeScope 软件预估楠木基因组大小约936 Mb 。 组装分为三步:序列拼接、Hi-C 染色体挂载、序列纠错打磨。整合 PacBio HiFi 与 ONT 超长读长,使用 Hifiasm、Verkko 软件完成杂合基因组组装,筛选最优 N50 拼接序列,获得近染色体水平序列。
Trimmomatic 过滤 Hi-C 测序数据,Juicer 完成序列比对;借助 3D-DNA 校正组装错误,结合 Juicebox 人工微调排序;筛选含端粒重复基序的超长序列完成染色体端粒定位与延伸,TGS-GapCloser 填补序列间隙,最终通过 T2T-Polish 完成全局纠错,获得无间隙端粒到端粒完整参考基因组 。
基因组注释
联合从头预测与同源比对两种方式注释重复序列,RepeatModeler 构建物种特异性重复序列库,RepeatMasker 结合 Repbase 数据库完成全基因组重复区域屏蔽。
基因结构预测整合三种策略:Augustus 完成从头基因预测;比对闽楠、樟树、杨树、拟南芥蛋白序列完成同源注释;依托转录组数据优化基因结构模型。 整合所有预测结果得到非冗余基因集,比对 SwissProt、PFAM、KEGG、GO 等公共数据库,完成基因功能注释。
基因组组装质量评估
使用 BUSCO 软件结合双子叶植物保守基因集评估基因组完整度;二代、三代测序数据分别比对基因组,统计测序覆盖深度与比对效率;LTR_retriever 评估长末端重复反转座子组装完整性;quarTeT 鉴定染色体标准端粒序列,TRASH 软件识别着丝粒区域与串联重复序列。
荧光原位杂交实验
取楠木萌发幼苗根尖,经 8 - 羟基喹啉预处理、卡诺氏固定液固定,纤维素酶 - 果胶酶 - 蜗牛酶混合酶液酶解后制备染色体制片。 对着丝粒串联重复保守序列设计荧光探针并标记,37℃恒温杂交过夜,DAPI 染核后使用蔡司荧光显微镜观察成像,ZEN 软件采集图像。
系统发育与分化时间分析
选取 8 种木兰类植物、4 种双子叶植物、2 种单子叶植物蛋白序列,以无油樟为外类群;OrthoFinder 筛选同源基因家族,MAFFT 序列比对后串联构建超级矩阵,RAxML 构建最大似然进化树。 利用 PAML 软件估算物种分化速率,结合已发表化石分化时间进行时间矫正,MCMCtree 估算物种分化年代;CAFE5 分析基因家族扩张与收缩趋势。
共线性与全基因组复制分析
MCScanX 分析楠木、闽楠、樟树基因组共线性关系,NGenomeSyn 绘制共线性图谱;计算同义替换率 Ks 值判定全基因组复制事件;DupGen_finder 区分全基因组复制、串联复制、邻近复制、转座复制、散在复制五类基因复制模式;借助 KaKs_Calculator 计算复制基因对的进化选择压力。
种群历史动态分析
过滤二代测序数据并比对参考基因组,SAMtools 与 BCFtools 提取群体一致性序列;基于 PSMC 模型推演楠木、闽楠、樟树历史种群数量变化,设定世代时长 15 年、突变速率\(3.75\times10^{-8}\),自举法重复 100 次评估结果误差。
转录组测序
采集五年生楠木根、茎、叶、木质部、韧皮部组织,同时选取幼龄、过渡、成熟三个树龄木材样本;试剂盒提取总 RNA,富集 mRNA 后构建转录组文库,质控合格后上机测序。 HISAT2 比对基因组,StringTie 计算基因 TPM、FPKM 表达量,edgeR 去除批次效应。
单细胞核制备
选用五年生健康楠木与樟树木质茎组织,使用专用细胞核分离试剂盒低温提取完整细胞核,经 Percoll 密度梯度离心纯化;AO/PI 双染后检测细胞核活性与纯度,仅选取核膜完整、杂质少的样本开展后续建库实验。
单细胞核转录组建库与测序
采用微流控单细胞 3' 端建库试剂盒完成文库构建,细胞核与反转录试剂混合形成油包水液滴,液滴内完成反转录;纯化扩增 cDNA,片段化加接头,扩增富集带有细胞条形码与唯一分子标签的文库,最终使用 Illumina NovaSeq 6000 平台完成双端 150 bp 测序。
单细胞核转录组数据处理与轨迹分析
利用 SeekSoul Tools 1.2.0 软件将楠木与樟树的单细胞核转录组原始测序读段比对至各自参考基因组,得到基因 - 细胞表达矩阵后采用Seurat 4.3.0 开展下游分析。 过滤标准:剔除在 3 个以下细胞中表达的基因;剔除基因数低于 500 个或高于 9000 个、唯一分子标签数量低于 500 或高于 70000 的细胞核;借助 DoubletFinder 2.0.3 去除双细胞杂质。 基于 2000 个高变异基因,通过锚点整合算法合并多组生物学重复样本;依次完成对数标准化与数据均一化处理,选取前 30 个主成分结合 UMAP 算法(维度参数设为 20)完成细胞分群。采用FindAllMarkers筛选细胞群特征标记基因,参数设置:最小表达占比 0.25、对数倍变化阈值 0.58。
使用Monocle3 1.3.1 进行细胞发育轨迹分析,先后执行数据预处理、数据集对齐、降维聚类,再通过轨迹学习构建细胞分化发育路径,并完成可视化绘图。
蛋白异源表达
扩增楠木PzF3H2 、PzFLS2 全长编码序列(特异性引物见表 S11),分别插入 pET-30a 载体,转化大肠杆菌 Rosetta (DE3) 菌株进行融合蛋白表达。 加入 0.1 mM 异丙基 -β-D - 硫代半乳糖苷,16℃低温诱导表达 20 h;收集菌体超声破碎,取上清液经镍离子亲和层析柱纯化,洗脱液体系:50 mM 磷酸二氢钠、300 mM 氯化钠、250 mM 咪唑,pH 调至 8.0。 使用超滤管浓缩蛋白,布拉德福德法标定浓度至 1 μg/μL,置于 - 80℃低温保存。
将细胞色素 P450 家族基因PzF3′HL 全长序列克隆至 pESC-URA 载体,转入酿酒酵母 WAT11 菌株;参照已有方法培养酵母,添加 20 g/L 半乳糖的尿嘧啶缺陷型液体培养基诱导蛋白表达 16 h,分离制备酵母微粒体蛋白,重悬于储存缓冲液中,标定蛋白终浓度为 10 mg/mL 备用。
体外酶活实验
参照并优化经典反应体系测定酶催化活性。300 μL 标准反应体系:1 mM 柚皮素、20 mM 还原型辅酶 Ⅱ、10 mM 抗坏血酸、10 mMα- 酮戊二酸、0.5 mM 硫酸亚铁、50 mM 三羟甲基氨基甲烷缓冲液(pH7.4)。 加入 10 μg 纯化PzF3H2 、PzFLS2 蛋白与 2 mgPzF3′HL 微粒体蛋白启动反应,30℃孵育 4 h。 单独测定两种黄酮合成酶活性时去除还原型辅酶 Ⅱ;单独测定PzF3′HL 活性时剔除 α- 酮戊二酸与硫酸亚铁。
酶动力学实验体系同上,PzF3H2 与PzFLS2 底物浓度梯度 10~150 μM,反应时长缩至 30 min;PzF3′HL 底物浓度梯度 1~30 μM,反应时长 15 min。 所有反应加入等体积乙酸乙酯终止反应,萃取有机相旋干后用甲醇复溶,上机开展液相色谱 - 质谱检测。
色谱条件:采用沃特世 HSS T3 色谱柱,柱温 40℃;流动相 A 为 0.1% 甲酸水溶液,流动相 B 为乙腈;洗脱梯度:0~0.5 min 保持 10% 乙腈,13 min 升至 95% 乙腈,维持至 16.5 min,17 min 回调至 10% 乙腈,平衡至 20 min。 质谱采用电喷雾电离正离子模式,毛细管电压 2.6 kV,采样锥电压 40 V,离子源温度 130℃,脱溶剂气温度 450℃,全程采集质荷比 50~1000 范围内质谱信号,使用 MassLynx 4.2 软件完成数据采集与图谱导出。
分子对接与定点突变
借助 Robetta 在线平台预测PzF3′HL 蛋白三维结构,POCASA 软件定位蛋白活性中心;利用 AutoDock Vina 1.5.6 完成底物柚皮素与蛋白的分子对接,筛选结合能最低的最优构象,PyMOL 完成可视化分析。 使用定点突变试剂盒构建 8 个氨基酸突变体(R97A、L113A、W122A、T370A、S373A、P440A、R446A、C448A),突变引物详见附表;将野生型与突变型基因构建至 pCAMBIA1305 载体,在本氏烟草叶片中瞬时表达,通过液质联用定量检测植株体内桑色素合成量。
转录因子瞬时激活实验
扩增楠木 18 个黄酮通路关键基因启动子序列,插入双荧光素酶报告载体 pGreenII 0800-LUC 中,构建报告载体;将候选 MYB、bHLH 类转录因子全长序列构建至 pCXSN 载体作为效应载体。 农杆菌介导侵染本氏烟草叶片,共侵染培养 3 天后,采用双荧光素酶检测试剂盒测定萤火虫荧光素酶与海肾荧光素酶活性,以二者比值判定转录因子对下游启动子的激活 / 抑制能力。
共表达调控网络分析
利用楠木 5 个不同发育时期转录组数据构建时序基因共表达网络 ,剔除平均 TPM 值低于 1 的低表达基因降低背景噪音;依托 PlantTFDB 数据库鉴定转录因子家族基因。 计算转录因子与结构基因间皮尔逊相关系数,筛选相关系数绝对值达显著水平的基因互作关系,导入 Cytoscape 绘制调控网络图。 提取黄酮特征细胞群表达矩阵,运用 GRNBoost2 算法预测细胞水平基因调控关系,构建细胞特异性转录调控网络。
定量统计分析
各项物质定量、酶活测定具体方法均详见对应实验方法部分;图注内统一标注所用统计方法、显著性判定标准与生物学样本量,所有数据绘图及统计学差异分析均使用 GraphPad Prism 8.0.2 完成。
All raw sequence data have been deposited in the National Genome Data Center (NGDC; BioProject - CNCB-NGDC) under BioProject accession number PRJCA039563. The genome assembly file and all the annotation files of P. zhennan are available at Figshare (https://figshare.com/s/e417b222c99937f4416d).